







1.两个独立正态样本的均值t检验
两种方法:
- t.test(y~x,data=) y是含有两种类的变量值,x则是一个factor类,标记y中的类别(一般只有在有formula参数的时候可以在括号里面加data=)
- t.test(y1,y2) 直接给出两个类的变量值
注:default假设两类的方差不同,需要用var.equal进行设定。alternative 可以选“less”,”greater”,”two sides”用来表示双边或单边检验,恒正的t值要用单边
2.
对于两组样本间非独立的,如年长人的犯罪率和年轻人的犯罪率、实验前后对象的表现(也就是成对比较检验)
t.test(y1,y2,paired=T)3.非参数检验(对于分布未知,但是可以检验是否来自同一个概率分布)
wilcox.test(y~x,data= , paired = ) 两对的秩和检验
kruskal.test(y~x, data = ) 多于两队的秩和检验
(npmc()函数可以对多组变量两两进行秩和检验)
回归分析
LM<-lm(height~weight, data = women)
summary(LM)
> summary(LM)
Call:
lm(formula = height ~ weight, data = women)
Residuals:
Min 1Q Median 3Q Max
-0.83233 -0.26249 0.08314 0.34353 0.49790
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 25.723456 1.043746 24.64 2.68e-12 ***
weight 0.287249 0.007588 37.85 1.09e-14 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.44 on 13 degrees of freedom
Multiple R-squared: 0.991, Adjusted R-squared: 0.9903
F-statistic: 1433 on 1 and 13 DF, p-value: 1.091e-14每项系数用t检验,p值表明回归系数不显著的概率,若很大,则显著为0
?残差标准误 residual standard error
R^2 表示测定系数,可以解释为y与预测值之间的相关系数,也可以解释为回归模型解释因变量方差的比例
F 统计量,检验回归模型的显著性
用fitted(LM)可以快速得到预测变量
注:用lines可以把拟合曲线加入到现有图片中,abline只是加一条直线,line只是返回拟合参数
1.
当我们希望用一些变量的n次方或者其他形式进行回归时,要用I(x^n)
比如
LM<-lm(weight~height + I(height^2), data = women)2.
scatterplot() 和 scatterplotMatrix()一个是两变量,一个是多对变量间两两生成图
对角线给出rug图和核密度图。 从非对角元图可以观察出两两变量之间的变化趋势,绿线是直线拟合,红线是曲线光滑拟合
交互项(lm(y~x1+x2+x1:x2),怎么理解交互项)
3.回归之后我们要检验回归的假设是否成立:
回归诊断 regressiondiagnosis
- 正态? 学生化残差QQ图
fit <-lm(Murder~Population+Illiteracy+Income+Frost, data = states)
qqPlot(fit,labels = row.names(states),id.method = “identify”)
注:常常用labels标记点的名字
residuals(fit)
fitted(fit)
rstudent(fit) 学生化残差表
durbinWatsonTest(fit) 检验自变量间独立性
crPlots(fit) 检验每个自变量线性性 (呈现线性关系)
ncvTest(fit) (common variance)
spreadLevelPlot(fit):在拟合值周围呈水平随机分布 (返回变换幂次)
几个图都不太理解
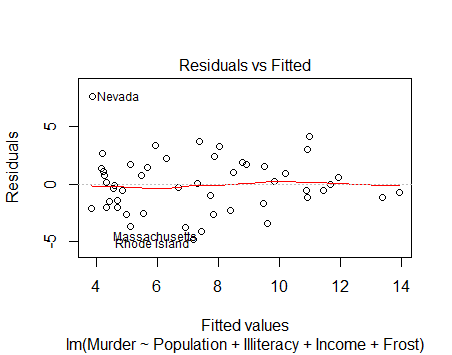
4.或者直接由lm的plot图读出信息
这个图是判断线性性
plot(fit,which = 1)
5.判断离群点
outlierTest(fit)
6.强影响点
这个图判断强影响点,但是无法判断通过哪些变量影响的
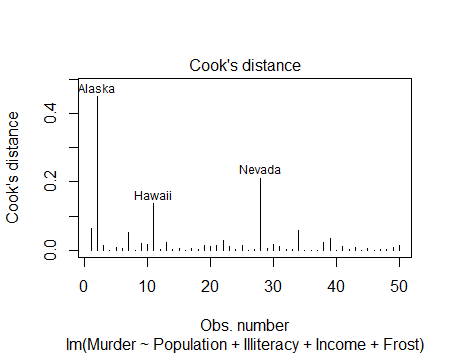
所谓变量添加图,即对于每个预测变量Xk,绘制Xk 在其他k-1个预测变量上回归的残差值相
对于响应变量在其他k-1个预测变量上回归的残差值的关系图
利用avPlots()
(回想回归分析中的两个残差值回归拟合的系数就是该变量在全模型中的系数)
常用id.method来决定标记点的方式,onepage表示是否一次显示一个
7.通过变换来调整模型
- 对y变换
> summary(powerTransform(states$Murder))
bcPower Transformation to Normality
Est.Power Std.Err. Wald Lower Bound Wald Upper Bound
states$Murder 0.6055 0.2639 0.0884 1.1227
Likelihood ratio tests about transformation parameters
LRT df pval
LR test, lambda = (0) 5.665991 1 0.01729694
LR test, lambda = (1) 2.122763 1 0.14512456Est.Power表明幂次,而下面的0.145表明需要变换并不显著
- boxTidwell() 得到预测变量的幂次
8.选择模型
(1)参数:有
R2
,
adjusted R2
,Mellow Cp 准则,AIC准则作为参考参数
(2)方法:逐步,向前向后,全集
简单的两个嵌套模型可以直接用anova评价
fit <-lm(Murder~Population+Illiteracy+Income+Frost, data = states)
summary(fit)
##Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.235e+00 3.866e+00 0.319 0.7510
Population 2.237e-04 9.052e-05 2.471 0.0173 *
Illiteracy 4.143e+00 8.744e-01 4.738 2.19e-05 ***
Income 6.442e-05 6.837e-04 0.094 0.9253
Frost 5.813e-04 1.005e-02 0.058 0.9541
######################
fit2<- lm(Murder ~ Population + Illiteracy,
data = states)
summary (fit2)
####Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.652e+00 8.101e-01 2.039 0.04713 *
Population 2.242e-04 7.984e-05 2.808 0.00724 **
Illiteracy 4.081e+00 5.848e-01 6.978 8.83e-09 ***
##################
> anova(fit2, fit)
Analysis of Variance Table
Model 1: Murder ~ Population + Illiteracy
Model 2: Murder ~ Population + Illiteracy + Income + Frost
Res.Df RSS Df Sum of Sq F Pr(>F)
1 47 289.25
2 45 289.17 2 0.078505 0.0061 0.9939
##(F很不显著说明model1 更合理)注:可以用交叉验证的方法检验模型是否有效(看相应参数在较差验证得到的预测值下的变化是否很大)
9.解释一下one-way anova
> summary(aov(response~trt,data = cholesterol))
Df Sum Sq Mean Sq F value Pr(>F)
trt 4 1351.4 337.8 32.43 9.82e-13 ***
Residuals 45 468.8 10.4
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1- trt作为分类标识,在trt一行中表示的组间解释的方差
- Sum Sq 表示该SS
- Mean Sq为SS均值
- Residuals一行则是误差解释的方差
- F value 用的是F统计量(类似于回归中 SSreg 和 RSS )
- Signif. codes: 方便我们直观地看出哪些量显著
10.通过las改变坐标轴上刻度的方向,用par(mar)使图形更美观
par(mar = c(5,8,4,2))
plot(TukeyHSD(fit),las = 1)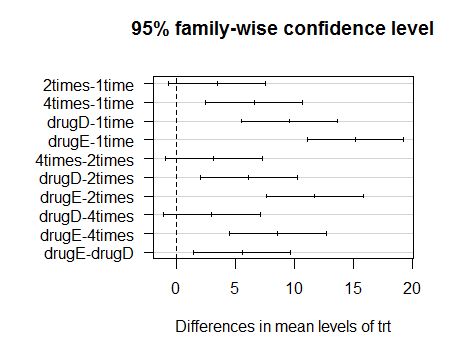
ANOVA
-
anova跟回归分析最大的差别就在于anova只是采用了x的分组,是对分组效应进行了分析(也即占方差比例),分析的数据完全来自于y,而回归则是对把x当做自变量进行分析
1.不管是one-way anova 还是two-way anova,都要会展示不同组的response value的差异
推荐two-way anova中用HH包的interaction2wt()
interaction2wt(len~ dose*supp)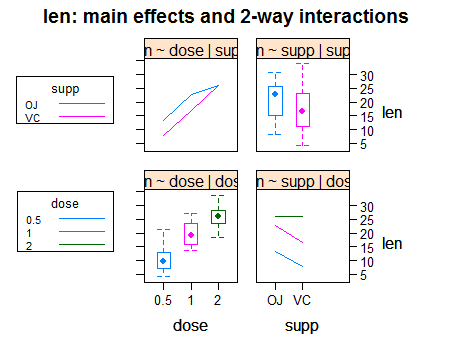
完美地展示了关于每一个因素分类的response value 的箱形图以及交叉项1影响
2.注意需要在anova 或者是manova中检验因变量的单或多元正态性以及方差齐性检验
通常单变量用bartlett.test()
多变量用Box.M.test()
- interaction如果没有交叉项影响的话,那么比如对于第一个因素分类的response value 对于第二个因素应该全部都一样,不一样则有interaction ↩














 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









