






背景
部门一个项目结束了,让我和测试的同事帮忙压测调优一下。
该项目是一个类似决策引擎项目,配置规则/模型进行决策输出结果。
该项目我全程没有参与过开发。
调优过程
压测工具:jemeter
启动项目并走通业务流程tps-2
现象:流程正常走通后压测发现cpu利用率低且消费kafka很慢
原因是监听kafka没有使用多线程监听消费
kafkatopic 创建时将partitions参数加大命令如下:
将原来的1改为40,消费线程数建议和分区数量保持一致/分区数量是线程的整数倍,因为一个分区只能由同一个线程消费
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic testeventtransaction_dtl --partitions 40 --replication-factor 1添加java并行消费配置
application-dev.yml文件中添加如下配置s

第一阶段 压测结果
8c16g cpu此时利用率超过700%,此时tps:15
优化1
由于开发期间程序员打印了大量的调试日志,故先调高日志的输出级别warn
调整jvm启动参数,将年轻代内存加大到8G
沟通逻辑后发现有一段mock流水表的逻辑已经用不上注释掉
第二阶段 压测结果
8c16g cpu此时利用率超过750%,此时tps:200
优化2
启动命令:
java -jar arthas-boot.jar压测通过arthas命令:thread -n 5 查看到大部分的cpu消耗都是在与mysql连接上
添加flink指定配置
因为有发现到执行不是flink的sql逻辑,故在外置配置文件中添加以下配置

由于大部分cpu被sql连接消耗,将变量执行逻辑查库数据添加到缓存
将变量查询数据逻辑全部提取到缓存类CacheVariableServiceImpl
再次压测会偶然出现异常
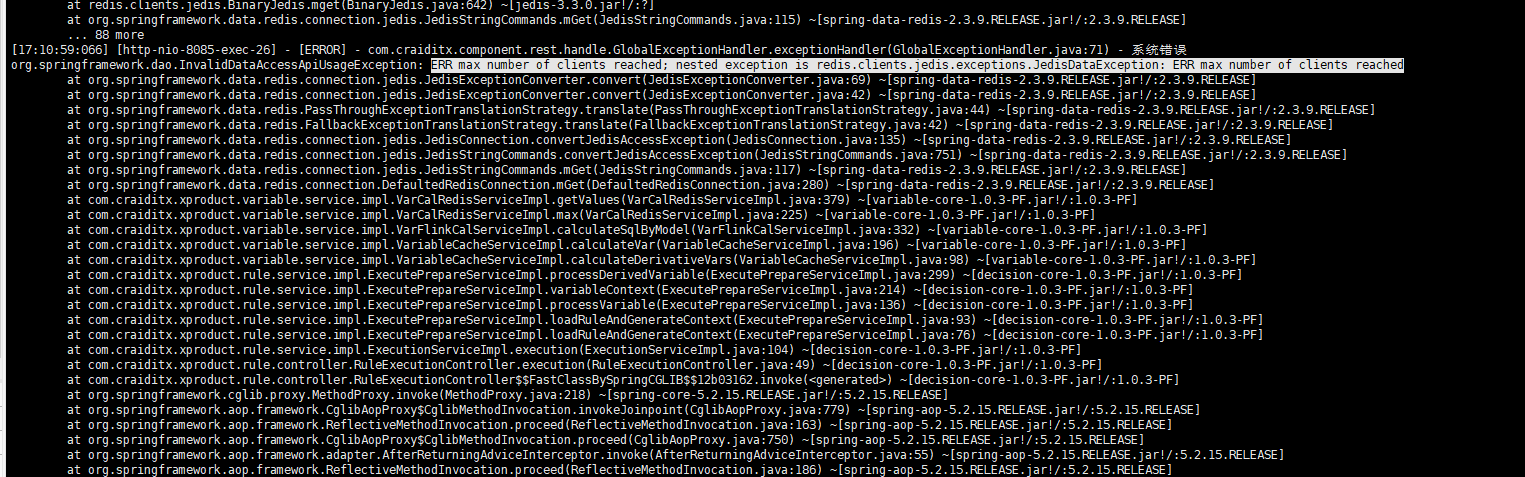
显示redis连接数不够,查看redisn内设置的最大连接数有10000,表示问题并不在的redis

查看从redis获取值的逻辑

发现没有调用close方法,连接打开了没有关闭
第三阶段 压测结果
8c16g cpu此时利用率超过100%,此时tps:250
分析为什么cpu利用率无法提高
怀疑是redis连接
注释从redis返回结果代码。发现压测结果无改变
9怀疑是是某块java代码(如缓存\锁)
分逻辑挨个将java代码注释,最后测试到已经把所有逻辑都注释了,controller只返回success。
压测结果依然无改变
怀疑是拦截器内有特别的逻辑导致
将内部拦截器全部去掉,压测结果无改变
怀疑是服务器之间网络/jmeter性能受限
重新创建一个spring boot项目提供一个只返回success接口。压测时发现该项目tps3w
怀疑是压测决策引擎的脚本可能有问题
查看压测脚本,发现里面有两块逻辑比较可疑,
1,请求体的报文是指定从某文件获取的。
2,对接口响应结果有断言
将以上两个逻辑都去掉,再分开去掉测试,发现是由于报文从文件获取导致的。
去掉报文从文件获取后:tps :1500,cpu 600%
第四阶段 压测结果
8c16g cpu此时利用率超过600%,此时tps:1500
使用arthas工具分析cpu占用较高代码
此时通过arthas命令 thread -n 5发现有较多的cpu消耗在redis连接上
使用arthas输出火焰图
通过arthas命令在压测的时候生成火焰图输出未.svg的文件浏览器能打开操作,火焰图上单个方法越宽表示压测时间内的cpu占用时间越长,我们就优先看火焰图中相对较宽的方法:
profiler start
profiler getSamples
profiler status
profiler stop

从火焰图上可以看到redis在进行频繁的创建连接,和close。表示没有使用连接池。经过查看代码是某程序配置redis错误了导致连接池配置并未生效,调整redis连接池配置:
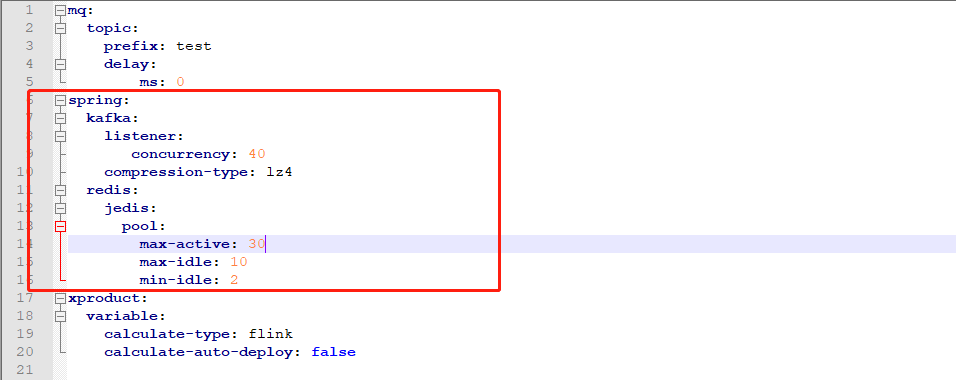
类似重火焰图查看到的比较占用cpu较高的还有以下几点(都是开发人员写代码不正确导致的资源浪费)
com/craiditx/xproduct/variable/service/impl/VarFlinkCalServiceImpl.calculateSqlByModel:去掉parallelStream
2. com/craiditx/xproduct/common/enumrator/BaseTypeEnum.getBaseTypeEnum:Optional取值前需要先判断是否有值
3. com/craiditx/xproduct/common/enumrator/BaseTypeEnum.getDefault:Long.valueOf转换前做空值判断
4. com/craiditx/xproduct/variable/service/impl/VariableCacheServiceImpl.calculateNameListVars: com/craiditx/component/common/utils/JacksonUtil.readValue,缓存model
5. com/craiditx/xproduct/variable/service/impl/VariableCacheServiceImpl.calculateDerivativeVars: com/craiditx/component/common/utils/JacksonUtil.readValue,缓存model
6. 日志打印行号:改成打印logger
注:在修改第5点后再次压测时,在以下红框出现空异常(同样是偶然异常,并不是必然):
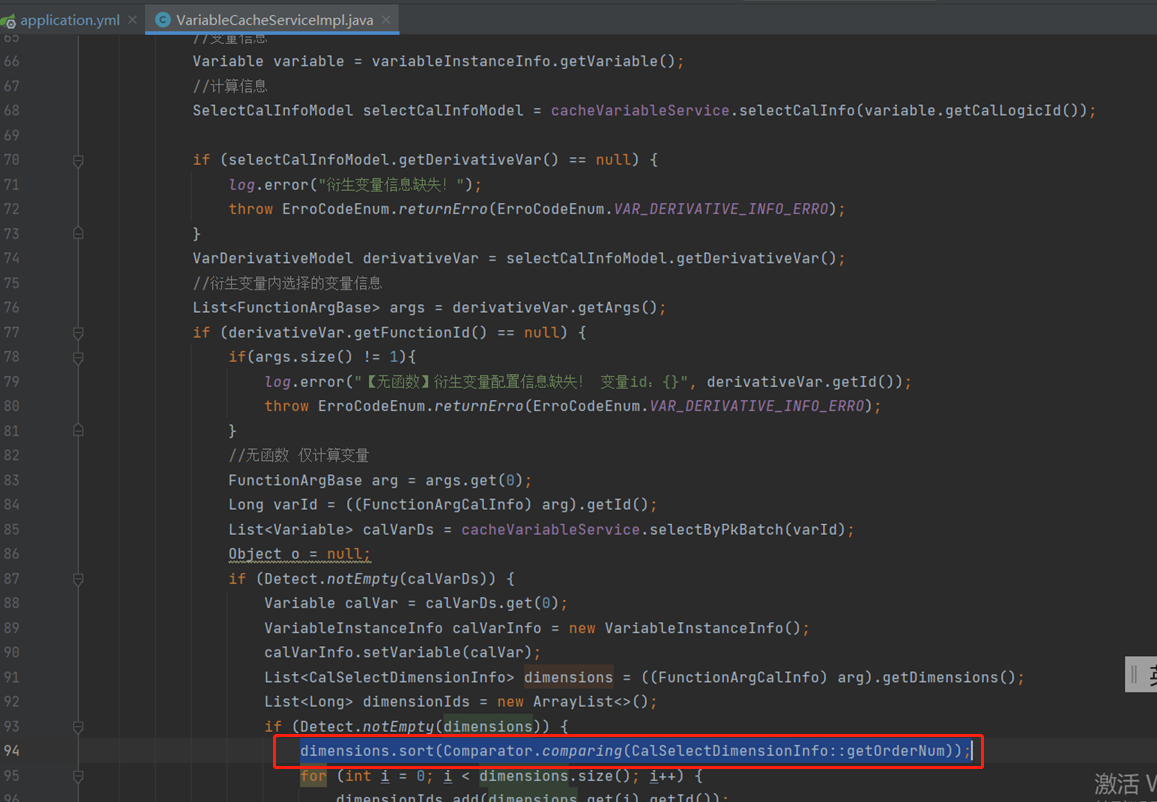
之前的代码改动如下,将第二个红框内的字符串转换对象放到缓存对象中,这样每次获取就拿的缓存,不用每次都字符串转对象
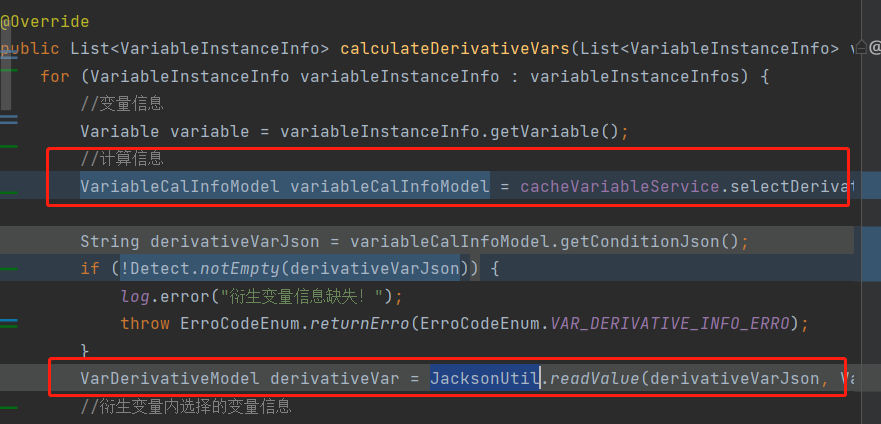
这里出现空异常是很让人疑惑的,经排查代码。发现该行是对对象内的list进行排序,由于是高并发压测。那么就是多线程对同一个对象内的list进行排序。故在排序前先复制一个list。再次压测异常消除
第五阶段 压测结果
8c16g cpu此时利用率超过700%,此时tps:4000
火焰图优化第二版
举例分析

查看代码发现,每次调用该方法都会进行过滤匹配,调整为初始化两个map,之间从map获取
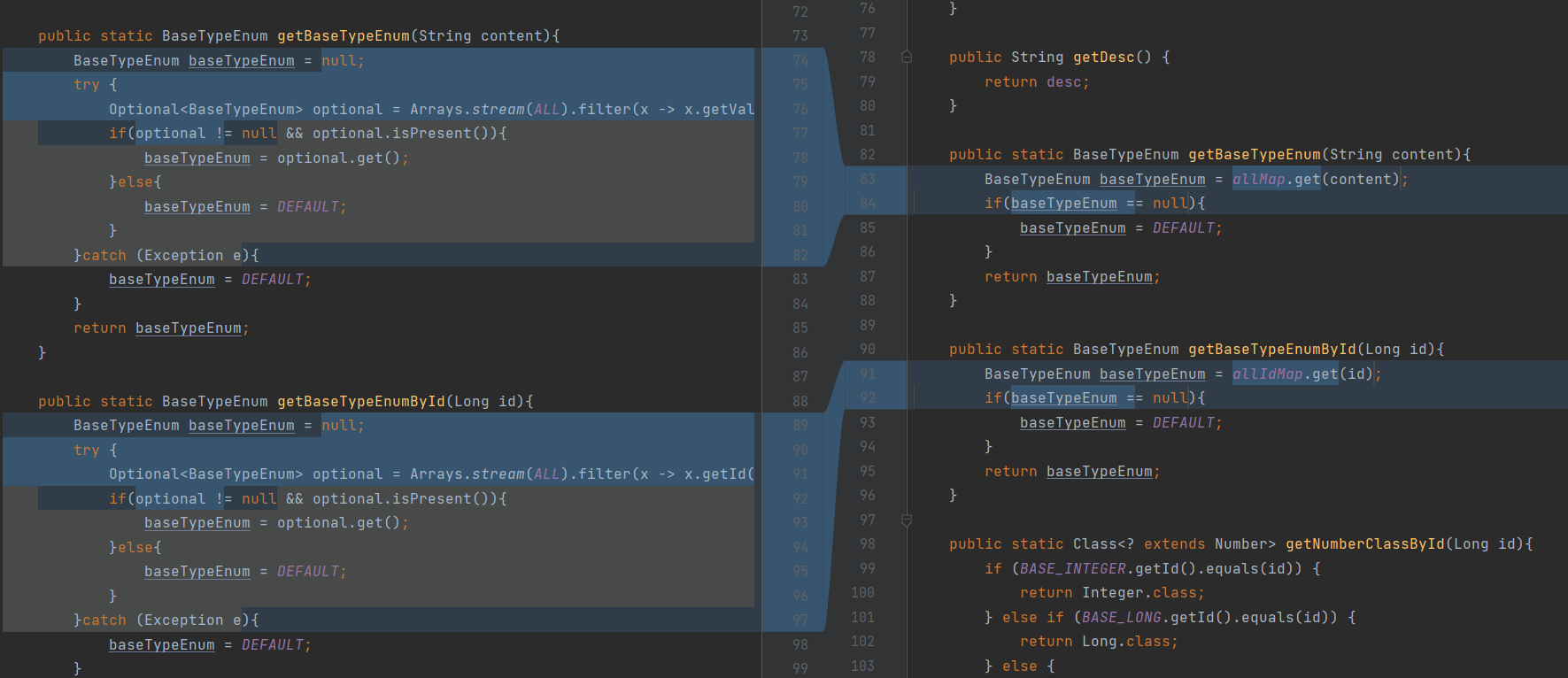
类似重火焰图查看到的比较占用cpu较高的还有以下几点
1. VarFlinkCalServiceImpl.calculateSqlByModel: collect方法优化;
2. Cache类型:pom加入caffeine依赖,yml文件中从simple改成caffeine;
3. com/craiditx/xproduct/variable/service/impl/VarCalRedisServiceImpl.getKeys: logger优化,interval优化
4. com/craiditx/xproduct/variable/service/impl/VarCalRedisServiceImpl.max/min/sum:number转BigDecimal前做类型判断,日志优化
5. com/craiditx/xproduct/common/enumrator/BaseTypeEnum.getBaseTypeEnum: 基于ALL数组生成2个map,查询时走Map而不是数组
第六阶段 压测结果
4c4g 30并发
summary = 292803 in 00:02:00 = 2438.1/s Avg: 12 Min: 2 Max: 102 Err: 0 (0.00%)
4c4g 25
summary = 297292 in 00:02:00 = 2476.3/s Avg: 10 Min: 1 Max: 84 Err: 0 (0.00%)
1c2g 20
summary = 53420 in 00:02:00 = 444.7/s Avg: 44 Min: 1 Max: 299 Err: 0 (0.00%)
1c2g 10
summary = 62615 in 00:02:00 = 521.3/s Avg: 19 Min: 1 Max: 102 Err: 0 (0.00%)
1c2g 5
summary = 73025 in 00:02:00 = 608.1/s Avg: 8 Min: 1 Max: 84 Err: 0 (0.00%)
结语
合理的使用工具可以帮助我们找出代码中很多 程序员开发时觉得功能正常 但在高并发下漏洞百出的问题。提升我们系统性能和编码水平















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









