






一、规则引擎的选型
(一)、自己用简单规则去写
优点:
(1)不用配置文件,用数据库来存储规则信息
(2)会比较轻量级,业务亲和性最好
缺点:
(1)需要一定的工程量,需要时间
(2)开发起来考虑的东西可能会不够周全
(3)假如设计不好,后期扩展会很麻烦
(二)使用第三方的开源框架
1、drools
用于解决if-else的硬编码问题,把规则判断提取到配置文件,通过修改发布配置文件方式更新规则,实现规则配置和程序服务解耦。官方的做法是用WorkBench去生成一个规则jar包,存到WorkBench的库中,然后用url给客户端远程调用
中文文档:
https://github.com/HappySnailSunshine/JavaInterview/blob/master/docs/Drools.md
官方文档:
特点:利用规则文件drl或者excel的方式编写规则配置,可以让程序动态的加载规则
优点:
(1)不用硬编码的方式编写规则,规则可以写在配置文件中
(2)配置文件可以通过WorkBench可视化规则编辑器web页面编写,打成jar包,提供远程链接,规则代码可以通过远程加载jar包的方式去动态修改规则,不用重新部署服务
(3)配置的规则丰富多样
缺点:
(1)配置文件的编写也比较复杂
(2)WorkBench不适合产品使用,配置也比较复杂
(3)全英文的文档,学习成本也比较高,入门容易,精通有点难度
(4)规则配置文件还得考虑存在哪里,得用云存储
(5)规则文件的配置是面向开发的,面向产品的话,还得我们加一层转换
接入方式:
(1)先预先编写好一些java节点,然后和前端约定好规则,用模板引擎去修改规则配置文件,动态接入
接入难点:
1、如何用模板引擎去定义配置文件?
2、如何定义数据模型上下文对象?
3、规则配置文件还得考虑存在哪里
4、规则文件配置还是挺复杂的
2、LiteFlow
官方文档:
特点:利用规则文件方式代替硬编码,可以让程序动态加载规则
优点:
(1)不用硬编码的方式编写规则,规则可以写在配置文件中
(2)提供了mysql,redis等多种规则存储源,可以把规则定义在源中,通过调用api通知规则变化
(3)支持平滑热更新
(4)有详细的中文文档,还有详细的样例代码支持,学习成本较低
(5)支持多种脚本语言,编写规则
缺点:
(1)还是要编写规则配置文件
(2)如何定义好模板去修改配置文件?
(3)如何定义好数据模型上下文对象?
(4)规则文件的配置是面向开发的,面向产品的话,还得我们加一层转换
接入难点:
1、如何用模板引擎去定义配置文件?
2、如何定义数据模型上下文对象?
3、ice-rule
官方文档:
特点:利用ice-server页面通过配置规则,通过预先写好java节点,然后配置规则发布规则
优点:
(1)通过ice-server的web页面去配置规则
(2)官方文档的说明,意思是配置方式比drools更加灵活,变更规则更加便捷
(3)比较轻量级,代码量看上去不多,可以阅读一下源码,对他进行修改
缺点:
(1)比较强依赖于ice-server,这个页面本质上还是面向开发人员的
(2)如果要用这一套,还得阅读一下源码,对他进行理解和修改,强依赖于ice-server还是不是很好,得找到一个更好的接入方式
接入难点:
1、如何通过不依赖于ice-server去发布规则
2、如何定义数据模型上下文对象?
4、jvs-rule
官方文档:
特点:面向在线决策的规则引擎,定义好源,计算规则,最后生成api,通过调用api,得到决策结果
优点:
(1)有完整的源码
(2)功能强大丰富
缺点:
(1)使用文档不够详细(几乎没找到,只有一些图片)
(2)按说是需要付费,才能够合法商用
(3)和我们自己开发的预警系统集成也比较复杂
(4)规则配置如果面向产品,也有一定的学习成本
5、urule
https://github.com/youseries/urule
特点:也是提供面向决策的规则引擎,定义好计算规则,生成api,最后可以通过调用api,传入参数作为数据上下文对象,得到结果集=
优点:
(1)开源
(2)功能丰富
(3)部署相对jvs-rule会方便
缺点:
(1)也是和告警平台分开两套平台部署,接入流程还是繁琐
综合考虑:
其实思考了具体实现以后,倾向于自己实现,因为其他方案的还需要拼接规则文件,感觉比较复杂,他设计的这么复杂,其实是兼考虑了条件判断和流程编排的,而我们流程编排可以自己实现,这里只是把条件判断抽象出来,所以可以自己实现。
如果要接入规则引擎,使用模板引擎去写配置文件,然后存储起来,前端如何传参,如何拼接配置文件其实都很复杂。
二、Rete算法
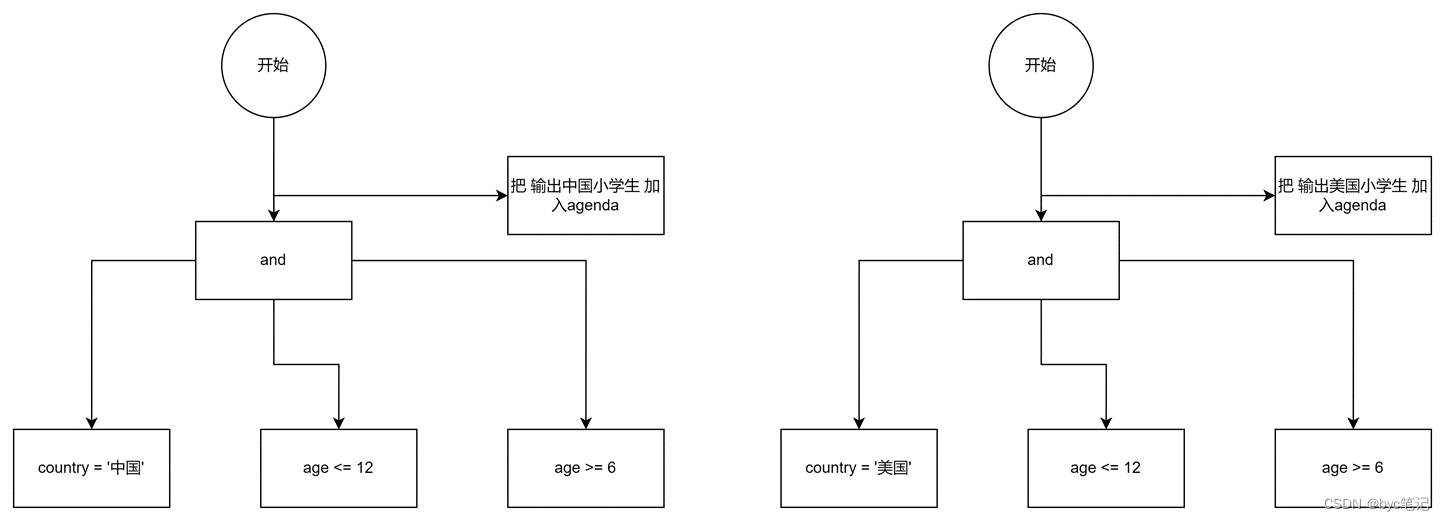
假设规则如下:
if country = '中国' and age<=12 and age >= 6 then 输出 中国小学生
if country = ‘美国’ and age <= 12 and age >=6 then 输出美国小学生
普通的没有经过优化的深度优先遍历方式需要遍历2遍,走过每一个节点
缺点:同样的节点要遍历2遍,缓存也要缓存2遍
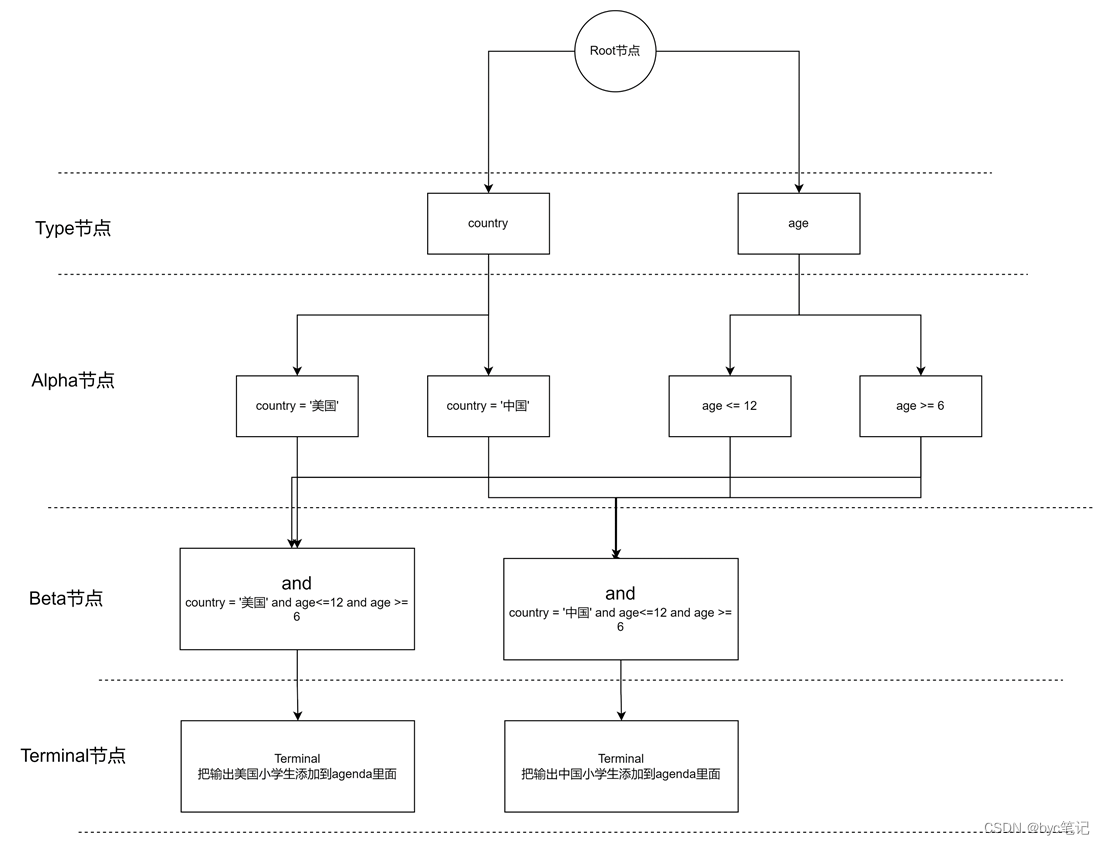
修改为Rete算法以后的好处:
1、同样的节点得到了复用
2、做缓存也只需要存一遍数据
3、不会因为类似规则的增加而
导致节点的大量增加
总结:Rete算法的优势
1、比较适用于并列执行多个规则的场景
2、可以做到节点的复用
3、不会因为同类规则的增加导致节点的大量增加
4、可以减少缓存的数据量
算法的不足:
1、如果使用事实缓存,不适用于事实变化范围特别大的数据,都缓存下来容易资源
耗尽
2、不适用于规则频繁变化的场景,频繁的网络变更会特别麻烦















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









