







 该博客围绕提升CNN对未见类别物体的医学图像分割泛化性能展开。提出基于深度学习的框架,结合特定分割方法,采用特定图像微调及加权损失函数。介绍了2D和3D图像的CNN训练、测试过程,基于Caffe实现模型,实验表明该方法效果优于其他对比方法。
该博客围绕提升CNN对未见类别物体的医学图像分割泛化性能展开。提出基于深度学习的框架,结合特定分割方法,采用特定图像微调及加权损失函数。介绍了2D和3D图像的CNN训练、测试过程,基于Caffe实现模型,实验表明该方法效果优于其他对比方法。
论文:《Interactive Medical Image Segmentation using Deep Learning with Image-specific Fine-tuning》TMI2018
文章目录
该方法也称为 BIFSeg (Bounding box and Image-specific Fine-tuning-based Segmentation)
BIFSeg 基于作者之前的一篇文章 DeepIGeoS,DeepIGeoS 已经结合了 CNN 与用户交互操作,但无法泛化到未见类别的物体上,而 BIFSeg 与 DeepIGeoS 的联系与区别:网络结构基于 DeepIGeoS 之上稍微做出了修改,且本文的目标在于解决对于未见类别物体的泛化问题。
代码:https://github.com/tcyhx/DeepiSeg
概览
目前存在的问题:
CNN 做医学图像分割缺乏对未见图像的泛化性能,也就是无法举一反三,比如给一道例题学会了,还是这道题换个问法就不会做了,这是 CNN 做分割的一大问题。
本文目标:
提升 CNN 对未见类别物体的泛化性能。
主要方法:
- 提出基于深度学习的框架,将 bounding box-based 和 scribble-based 分割方法结合到 CNN 中
- 提出基于特定图像(image-specific)的 fine-tuning,使 CNN 能够适应于特定的测试图像,这一过程可以是无监督(没有用户交互操作)的也可以是有监督的(有用户交互操作)
- 提出加权损失函数,能够考虑到在用户进行 fine-tuning 时,交互操作的不确定性
实现效果:
对于 2D 图像,P-Net 模型仅在 placenta 和 fetal brain 上进行了训练,但是在测试阶段,对于未见图像 fetal lungs 和 maternal kidneys 的分割效果也很好。对于 3D 图像,PC-Net 仅在 tumor cores in T1c 上进行了训练,但是在测试未见图像 whole tumors in FLAIR 时的效果也不错。
另外,与以前的交互式分割方法相比:需要人为操作的时间更少,且能够达到甚至高于之前分割方法的精度。
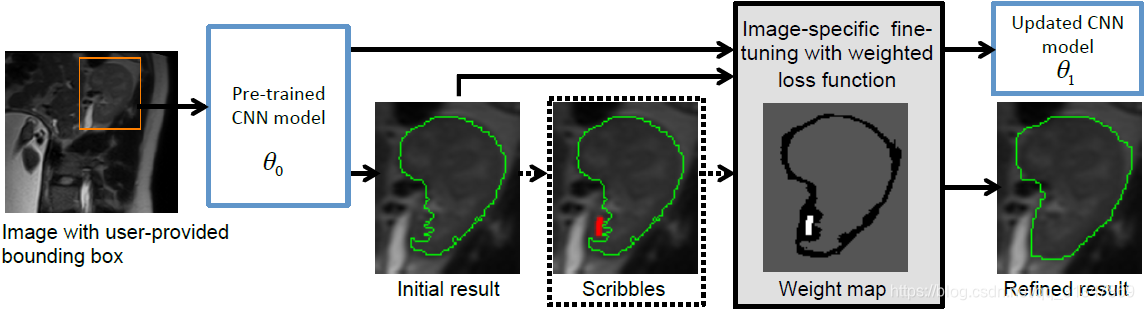
训练过程:

训练图像中包括了实例的分割 label 和检测 bbox(左图),将 bbox 里的内容裁剪下来(中图),前景图像为1,背景为0,然后训练 CNN 网络的参数
θ
0
\theta_0
θ0(右图)。
测试过程:
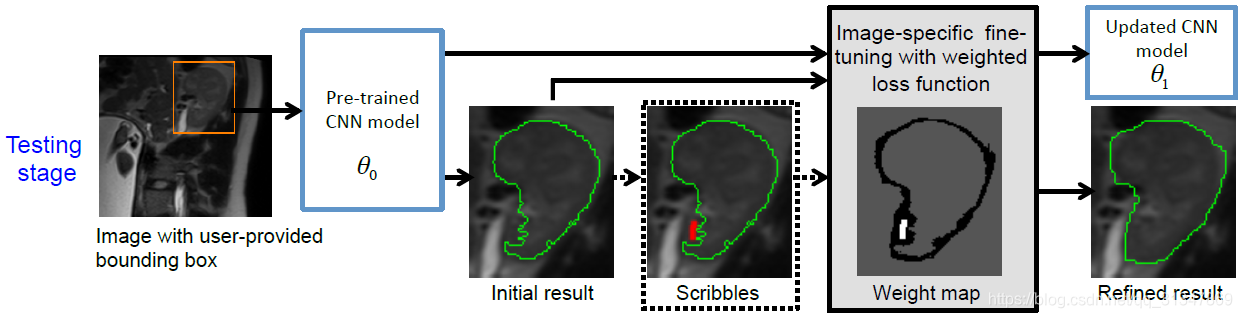
测试时,由用户提供一个 bbox,输入训练好的 CNN 模型中(参数为
θ
0
\theta_0
θ0)可以得到一个初始的分割结果(Initial result),再由用户进行有监督的微调或无监督的微调(Scribbles),对初始的分割结果进行调整,得到一个更新后的 CNN 模型(参数为
θ
1
\theta_1
θ1,Refined result)
【在测试阶段需要用户提供 bounding box,但是也可以研究一下自动生成 bbox 来进一步提高效率】
细节说明
1. Training of CNNs
1.1 2D images
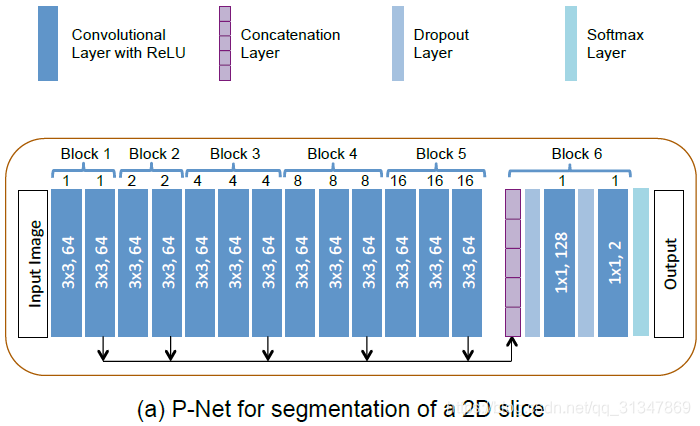
对于 2D 图像,采用 P-Net 做基于 bbox 的二值分割。
P-Net:《DeepIGeoS: A Deep Interactive Geodesic Framework for Medical Image Segmentation》, TPAMI 2018
网络结构:
1)采用了 dilated convolution(空洞卷积/膨胀卷积/带孔卷积)保存图像分辨率,避免细节损失;
2)网络包括 6 个 block,receptive field 为 181x181;
3)前 5 个 block 的 dilation parameter 分别为 1、2、4、8、16,这样就可以从不同的尺度上提取特征;
4)卷积层采用 ReLu 激活函数;
5)前 5 个 block 提取的特征连接后输入第 6 个 block,block 6 可以看作一个分类器;
6)最后一层为 softmax layer,得到概率输出;
Dilated Convolution:《Multi-Scale Context Aggregation by Dilated Convolutions》,ICLR 2016
测试阶段:
根据特定图像对训练得到的模型进行 fine-tuning,更新 CNN 模型参数。为了保证效率和对用户操作快速做出相应,仅 fine-tuning 分类器(block 6)的参数。
1.2 3D images
对于 3D 图像,需要在感受野、推理时间和存储效率进行 trade-off。
网络结构: 与 P-Net 类似,共有 6 个 block,在第 6 个 block 上进行 fine-tuning等
1)使用各向异性的感受野 85x85x9;
2)采用了 3D context(与之相对的是 slice-based networks);
3)前 2 个 block 使用 3x3x3 的 kernel,第 3、4、5 个 block 使用 3x3x1 的 kernel;
4)为了节省存储空间,在每个 block 的输出下面接一个 1x1x1, 16 的卷积,对输出特征进行压缩之后再进行连接;
5)由于在 P-Net 添加了压缩(compress)操作,所以给处理 3D 图像的网络起名为 PC-Net;

1.3 CNN 模型的训练
整张图片并不是直接作为 CNN 的训练数据,而是先进行了一些处理。
- T = T = T= { ( X 1 , Y 1 ) , ( X 2 , Y 2 ) , . . . (X_1,Y_1), (X_2,Y_2),... (X1,Y1),(X2,Y2),... },初始训练集,size 为训练集的图片个数(注意与后面 T ^ \hat T T^ 的 size 做区分)
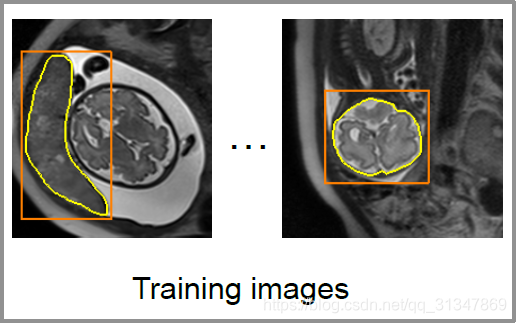
- X p X_p Xp:表示训练集的图片,比如下图的每一张都是一个单独的图像,且每张图像里都可能有多个属于不同类别的实例
- Y p Y_p Yp:训练集图片对应的 label map,也就是 segmentation label(可能有多个 label),对应每张图像里亮黄色的分割线
- l a b e l s e t : T = label\ set:T= label set:T={ 0 , 1 , 2 , . . . , k − 1 0, 1, 2, ... , k-1 0,1,2,...,k−1 }:训练集的类别标签,表示训练集共有 k-1 个类别,每个类对应一个数字标签,背景类标签为 0
- N k N_k Nk:属于第 k 类标签的实例个数
- N ^ = ∑ k N k \hat N = \sum_k N_k N^=∑kNk:训练实例的总个数
- l p q l_{pq} lpq:第 p p p 张图像 X p X_p Xp 的第 q q q 个实例的 label 记作 l p q l_{pq} lpq
- Y p q Y_{pq} Ypq:第 p p p 张图像 X p X_p Xp 的第 q q q 个实例的 label map 的二值图像,它是根据在 Y p Y_p Yp 和 l p q l_{pq} lpq 的每个像素的值是否相同得到的
-
B
p
q
B_{pq}
Bpq:各个实例的 bounding box,基于
Y
p
q
Y_{pq}
Ypq 自动生成,即在其边界随机扩大 0 - 10 个 pixel 或 voxel 得到一个矩形框
将 X p X_p Xp 和 Y p q Y_{pq} Ypq 基于 B p q B_{pq} Bpq 进行裁剪,下图左边是原图 X p X_p Xp 的裁剪结果,右边是二值的 l a b e l m a p Y p q label\ map\ Y_{pq} label map Ypq 的裁剪结果。
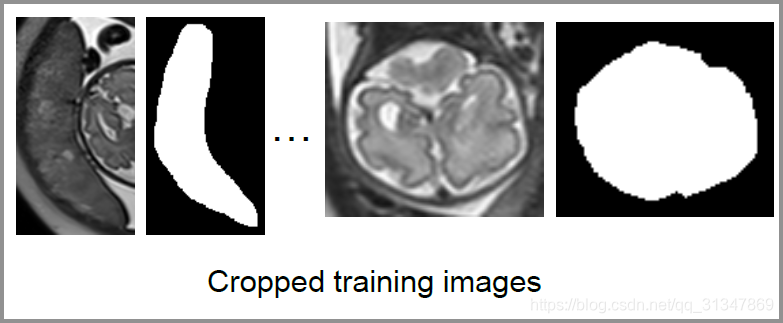
- T ^ \hat T T^ = { ( X ^ 1 , Y ^ 1 ) , ( X ^ 2 , Y ^ 2 ) , . . . (\hat X_1,\hat Y_1),(\hat X_2,\hat Y_2), ... (X^1,Y^1),(X^2,Y^2),...} 为裁剪后的训练集, X ^ p \hat X_p X^p 就是上图中的原图实例片段, Y ^ p \hat Y_p Y^p 就是其对应的二值分割 label,裁剪集的 size 为 N ^ \hat N N^,因为此时每个元组代表一个分割实例,上面已经说过了实例总数就是 N ^ \hat N N^
- l a b e l s e t o f T ^ label\ set\ of\ \hat T label set of T^ = { 0 , 1 0,1 0,1 }:裁剪集的标签,0 表示背景,1 表示前景
将裁剪后的训练集
T
^
\hat T
T^ 输入 CNN 网络,训练网络参数
θ
0
\theta_0
θ0

这样做处理的好处:CNN 如果输入原始图像及其标签,那么在做分割时还要考虑其类别信息(共 k 个类),这样做处理之后 CNN 只需要从每一个 bounding box 中分割目标,转换成了一种不需要考虑目标类别的二值分割问题。
训练的损失函数: cross entropy loss function
2. Image-specific Fine-tuning
在第一步训练好 CNN 模型参数 θ 0 \theta_0 θ0 以后,接着就在测试阶段对模型进行 fine-tuning,也就是更新参数 θ 0 \theta_0 θ0,最终要得到更新后的参数 θ 1 \theta_1 θ1。
在测试阶段,用户为测试图像提供一个 bounding box 然后输入到训练好的 CNN model ( θ 0 \theta_0 θ0 ) 中,CNN 根据 bbox 得出一个初步的分割结果 Y ^ 0 \hat Y_0 Y^0。
接着对分割结果 Y ^ 0 \hat Y_0 Y^0 进行有监督或无监督的 fine-tuning,即画一些修正的 scribbles,根据这些 scribbles 对结果再修改。
- S S S:scribbles 的集合, S = S f ⋃ S b S = S_f \bigcup S_b S=Sf⋃Sb
- S f S_f Sf:代表前景的 scribbles
- S b S_b Sb:代表背景的 scribbles
-
s
i
s_i
si:代表用户提供的 scribbles 中各像素的 label,若
i
∈
S
f
i \in S_f
i∈Sf,则
s
i
=
1
s_i = 1
si=1;若
i
∈
S
b
i \in S_b
i∈Sb,则
s
i
=
0
s_i = 0
si=0(即若一个像素属于前景,那么它的标签就是1,反之为0)
最小化目标函数:
一看到最小化能量函数,就往概率图模型方向靠了,实际上图像分割的一大分支就是概率图模型。
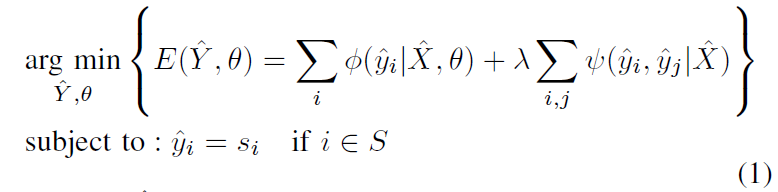
- X ^ \hat X X^ 为用户提供的 bbox 内的 sub-image(论文是这么说的),实际上就是一个 bbox 里的内容,它作为了全局观测,来计算第一项条件概率【这些概念来自CRF,可以搜相关论文看看】
- Y ^ \hat Y Y^ 为 X ^ \hat X X^ 的 target label,更贴切一点说应该是 X ^ \hat X X^ 中各个像素的预测 label 组成的一种 “分配方案”,此时的 Y ^ \hat Y Y^ 是根据用户给的 bbox 自动分割出的结果
- 一元项 ϕ \phi ϕ 也叫一致性项,可以看作是给第 i i i 个像素分配的标签为 y ^ i \hat y_i y^i 的概率(属于前景还是背景)
- 二元项 ψ \psi ψ 衡量了两个像素 i i i 和 j j j 之间的差异
- λ \lambda λ 为二元项的权重,也就是希望二元项对目标函数的影响有多大
对能量函数的优化方法类似于 DeepCut 中弱监督的学习方法,但是在 DeepCut 中能量函数是基于训练集中所有图像的概率和 label map 进行优化的,而在本文是基于单个 test image 进行优化。
DeepCut: 《DeepCut: Object Segmentation From Bounding Box Annotations Using Convolutional Neural Networks》, TMI 2017
这里关于二元项
ψ
\psi
ψ 函数的定义如下:
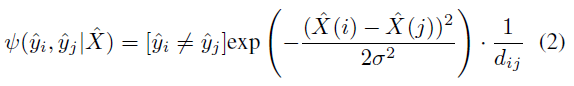
- [ y ^ i ≠ y ^ j ] [\hat y_i ≠ \hat y_j] [y^i=y^j]:当 y ^ i ≠ y ^ j \hat y_i ≠ \hat y_j y^i=y^j 时取 1,相等时取 0
- d i j d_{ij} dij 是像素 i i i 和 j j j 之间的欧式距离
- σ \sigma σ 控制了强度差的影响程度, σ \sigma σ 越大强度差的影响就越大,感觉就相当于给了个权值
我的理解是判断两个像素属于同一类时,不进行惩罚;当判断两个像素不属于同一类时,根据像素间的距离、强度差等因素进行惩罚。从公式里能看出当判断两个像素被判为不同类(即一个属于前景一个属于背景)时,它们之间的距离 d i j d_{ij} dij 越小,惩罚就越大;类似地两个像素的强度差(比如灰度图像的灰度值)越小,给出的惩罚就越大,惩罚越大说明这两个像素的类别越可能产生了误判。
ψ
\psi
ψ 函数定义参考:
《Interactive graph cuts for optimal boundary & region segmentation of objects in N-D images》, ICCV 2001
一元项
ϕ
\phi
ϕ 函数定义如下:
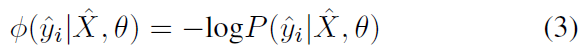
- P ( y ^ i ∣ X ^ , θ ) P(\hat y_i | \hat X, \theta) P(y^i∣X^,θ):是 CNN 的 softmax layer 的输出概率
当 P P P 越大, ϕ \phi ϕ 就越小,这样就达到了最小化能量函数的目的。
令
p
i
=
P
(
y
^
i
=
1
∣
X
^
,
θ
)
p_i = P(\hat y_i=1|\hat X,\theta)
pi=P(y^i=1∣X^,θ),即像素
i
i
i 属于前景的概率,则(3)中的
l
o
g
P
(
y
^
i
∣
X
^
,
θ
)
logP(\hat y _i | \hat X, \theta)
logP(y^i∣X^,θ) 可以改写为:
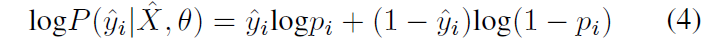
有点类似于逻辑回归的分解方法,当像素
i
i
i 确实属于前景时,只会计算(4)式的第一项;当像素
i
i
i 属于背景时,计算
l
o
g
(
1
−
p
i
)
log(1-p_i)
log(1−pi),此时的
p
i
p_i
pi 为像素属于背景的概率。
此时就可以将优化目标函数(1)分解为两步,一是 label update step,二是 network update step:
(1)label update step
对分割目标
Y
^
\hat Y
Y^ 进行单独优化:将网络参数
θ
\theta
θ 固定,这样优化目标(1)简化成 CRF 问题:
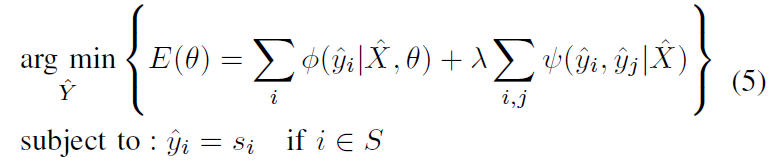
为方便实现,将等式(5)转换为无约束优化等式:
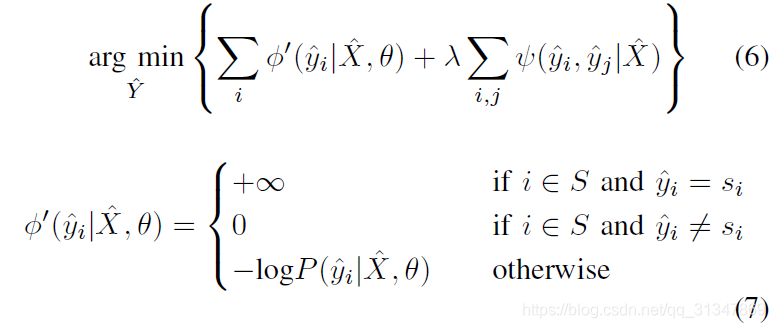
(2)network update step
对 CNN 网络参数进行单独优化:将
Y
^
\hat Y
Y^ 固定,此时优化目标(1)简化为:

将等式(8)也转换成无约束的优化等式:
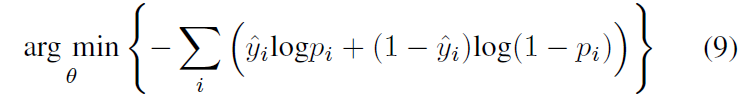
但是这还不是最终的目标函数,作者还根据像素的重要程度进行了改进。
3. Weighted Loss Function during Network Update Step
在 CNN 网络的更新阶段,会根据当前的分割结果 Y ^ \hat Y Y^ 进行 fine-tuning。作者提出的 fine-tuning 不是对所有像素都进行处理,而是根据各像素的 confidence 对它们进行处理(对比之前有的方法是对所有像素都进行处理)。
比如说,用户提供的 scribbles 相比其他像素要具有更高的 confidence,所以就对 loss function 有更大的影响,因此对公式(3)即一元项进行加权:
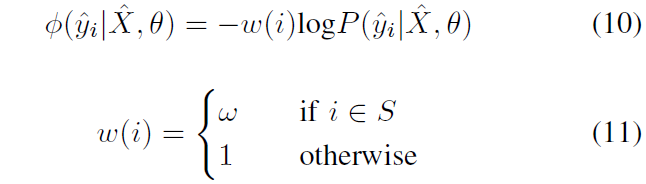
权重为
w
(
i
)
w(i)
w(i),其函数定义表示了若像素
i
i
i 属于用户提供的 Scribble,则其权重为
w
w
w,否则权重为 1。
对公式(9)进行加权得到:
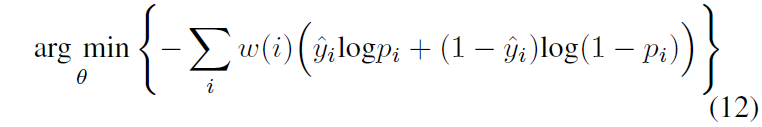
--------最终我们需要优化的目标函数就是 (10) , (12)---------
另外,作者认为 Y ^ \hat Y Y^ 可能包括了误分类的像素点,为解决这个问题作者提出将 高不确定性(低 confidence) 的像素点忽略掉,然后再更新网络参数。
不确定性分成两种:
- network-based uncertainty:基于网络的不确定性,其依据网络 softmax 层的输出来确定
- scribble-based uncertainty:基于 scribble 的不确定性
(1)network-based uncertainty
基于 softmax 的输出,如果 p i p_i pi(像素 i i i 属于前景的概率)接近 0.5,就说明该像素点具有较高的不确定性(因为在概率接近 0.5 时无法判断到底属于前景还是背景,相当于瞎猜了)
定义一个像素集合 U p = { i ∣ t 0 < p i < t 1 } U_p = \{ i | t_0<p_i<t_1 \} Up={i∣t0<pi<t1}, t 0 t_0 t0 和 t 1 t_1 t1 是阈值,这个范围内包含了所有不确定性高的像素点 p i p_i pi,而在 p i < t 0 p_i < t_0 pi<t0 时能够确定它是背景,在 p i > t 1 p_i > t_1 pi>t1 时能够确定它是前景。
(2)scribble-based uncertainty
基于到 scribbles 的 geodesic distance(即最小距离)
- G ( i , S f ) G(i,S^f) G(i,Sf):从像素 i i i 到前景像素集 S f S^f Sf 的 geodesic distance
- G ( i , S b ) G(i,S^b) G(i,Sb):从像素 i i i 到背景像素集 S b S^b Sb 的 geodesic distance
设 ϵ \epsilon ϵ 为关于 geodesic distance 的阈值,定义 U s U_s Us 为具有较高 scribble-based 不确定性的像素点的集合, U s = U s f ⋃ U s b U_s = U_s^f \bigcup U_s^b Us=Usf⋃Usb,即分为了前景和背景不确定的点,其分别定义为:
- U s f = { i ∣ i ∉ S , G ( i , S f ) < ϵ , y ^ i = 0 } U_s^f = \{i|i\notin S, G(i, S^f) < \epsilon, \hat y_i = 0\} Usf={i∣i∈/S,G(i,Sf)<ϵ,y^i=0},
- U s b = { i ∣ i ∉ S , G ( i , S b ) < ϵ , y ^ i = 1 } U_s^b = \{i|i\notin S, G(i, S^b) < \epsilon, \hat y_i = 1\} Usb={i∣i∈/S,G(i,Sb)<ϵ,y^i=1}
加权参数可以表示为:
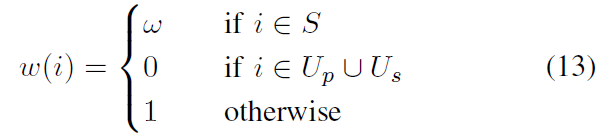
在 fine-tuning 时的权重图(weight map):
- 当像素点具有较高的不确定性时(黑色区域),权重设置为 0;
- 对用户提供的 scribbles(白色线条),权重设置为 ω \omega ω;
- 对分类正确的像素点(灰色部分),权重设置为 1。
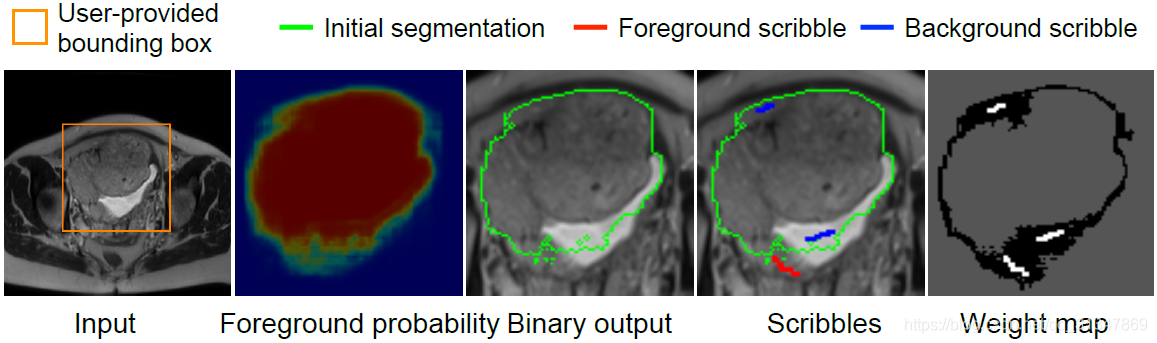
具体实现
基于 Caffe 实现 P-Net 和 PC-Net
1. 训练过程
硬件配置:
用 Emerald cluster 的一个节点进行训练,8 核 E5-2623v3 Intel Haswells,K80 NVIDIA GPU 以及 128G 内存
训练设置:
随机梯度下降(Stochastic gradient decent)
momentum = 0.9
batch size = 1
weight decay =
5
×
1
0
−
4
5 \times 10^{-4}
5×10−4
最大迭代次数:60k
初始学习率:
1
0
−
3
10^{-3}
10−3,每 5k 次迭代后减半
图像预处理:
根据训练图像的均值和标准差,对所有图像进行预处理
关于 bounding box 的生成:
每个目标的 bounding box 基于 ground truth 自动生成(随机扩大边界 0 到 10 个 pixel 或 voxel)
2. 测试过程
硬件配置:
MacBook Pro(OS X 10.9.5)
16GB RAM
Intel Core
测试设置:
bounding box 由用户提供
在 image-specific fine-tuning 阶段,
Y
^
\hat Y
Y^ 和
θ
\theta
θ 分别迭代更新 4 次
在每个 network update step,学习率为
1
0
−
2
10^{-2}
10−2,迭代次数为 20
使用 grid search 获取合适的参数值:
λ
\lambda
λ,
σ
\sigma
σ,
t
0
t_0
t0,
t
1
t_1
t1,
ϵ
\epsilon
ϵ,
ω
\omega
ω
图形界面:
2D 交互:Matlab GUI
3D 交互:PyQt
实验结果
给出同样的 bounding box,作者将 P-Net 和之前的 FCN、U-Net 进行比较(2D分割),将 PC-Net 和 DeepMedic、HighRes3DNet 进行比较(3D分割)。
比较 BIFSeg 和 1)P-Net/PC-Net 的初始分割结果;2)用 CRF 处理之后的分割结果;3)BIFSeg(-w) 的分割结果(基于 Eq(1),所有像素的权重 w ( i ) = 1 w(i) = 1 w(i)=1),以及其他交互式分割方法:用于 2D 分割的 GrabCut,SlicSeg,Random Walks;用于 3D 分割的 GeoS,GrowCut,GrabCut 3D
用分割结果和真实标签值之间的 Dice score 进行定量分析:
D
i
c
e
=
2
∣
R
a
⋂
R
b
∣
/
(
∣
R
a
∣
+
∣
R
b
∣
)
Dice = 2|R_a \bigcap R_b|/(|R_a| + |R_b|)
Dice=2∣Ra⋂Rb∣/(∣Ra∣+∣Rb∣)
- R a R_a Ra 表示分割的区域
- R b R_b Rb 表示真实标签
Dice 值越大,说明效果越好。
1. 2D 图像分割
基于 P-Net 进行分割,用户提供 bounding box,但没有进行 image-specific Fine-tuning 时的初始分割结果。
(1)对比 GrabCut,FCN,U-Net 和本文提出的 P-Net 的初始分割结果:
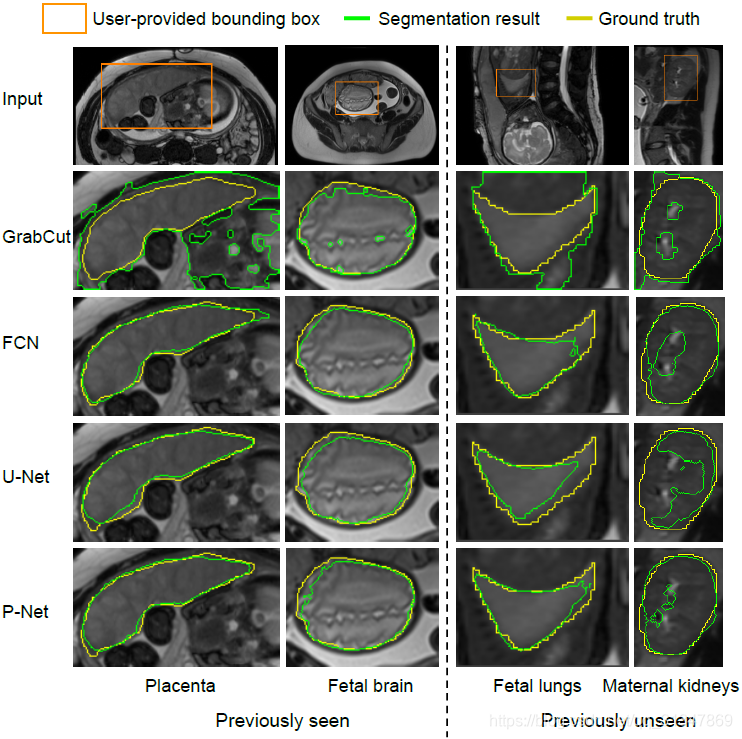
GrabCut 只有在对比度比较大的脑部图像上分割效果比较好
对于训练过的特定目标:Placenta 和 Fetal brain,FCN、U-Net 和 P-Net 取得的分割效果差不多,都很接近 ground truth
但是对于未见目标:Fetal lungs 和 Maternal kidneys,P-Net 的分割结果明显比 FCN 和 U-Net 好很多
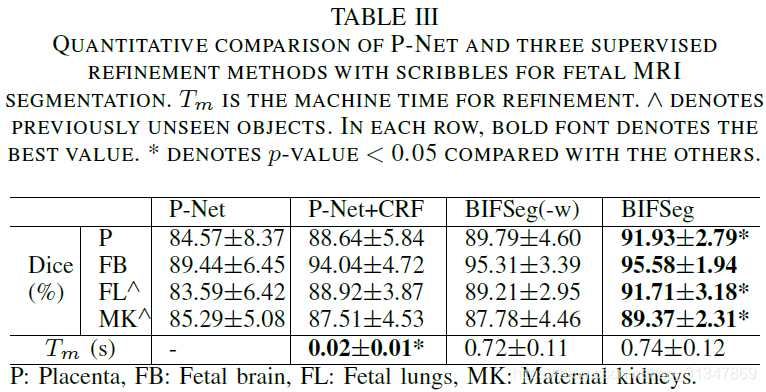
具体比较如下:从表中可以看出 P-Net 虽然在 Placenta 和 Fetal brain 上的分割效果不比 FCN,但是对于未见目标的分割效果是最好的。
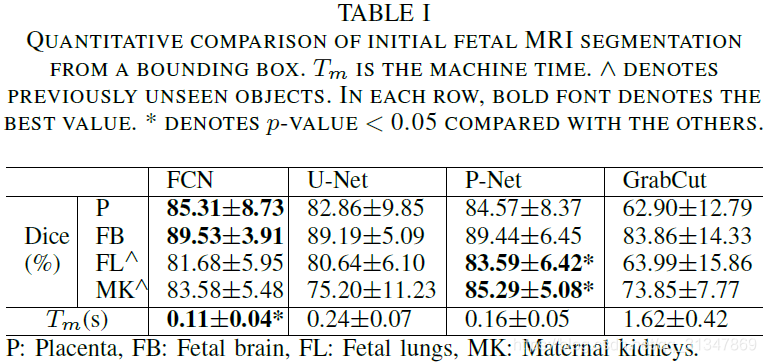
(2)Unsupervised Image-specific Fine-tuning:
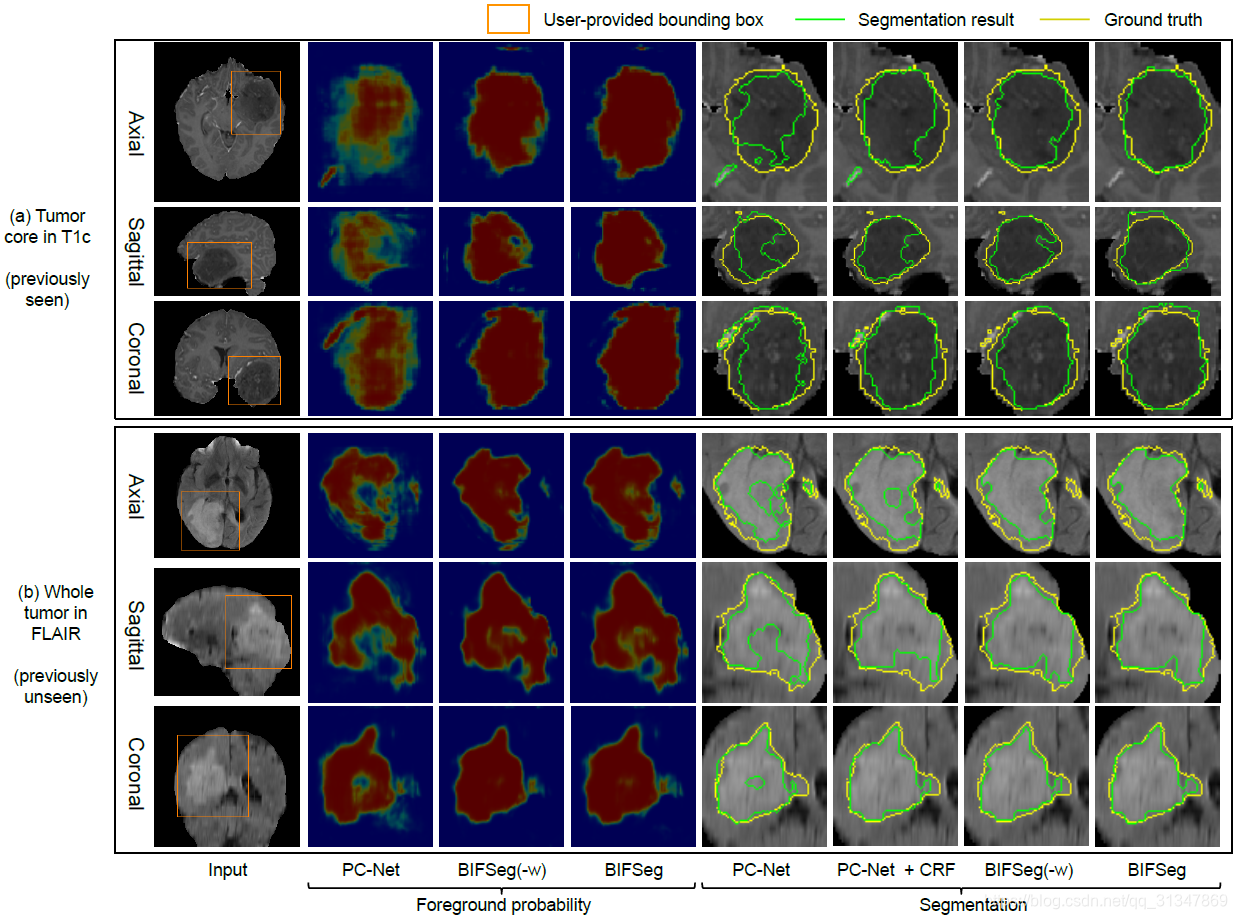
对于无监督的微调,P-Net 获得的初始分割结果分别经过 CRF、BIFSeg(-w) 和 BIFSeg 进行调整,结果如下:
第 2 行为 P-Net 获得的初始前景概率图,红色区域周边存在很多概率接近 0.5 的像素点,说明初始分割结果有很高的不确定性。
第 3、4 行分别为经过 BIFSeg(-w) 和 BIFSeg 调整后的前景概率图
接下来就分别是 P-Net、P-Net+CRF、BIFSeg(-w) 和 BIFSeg 的分割结果。
虽然后面三个都是对 P-Net 初始分割结果的调整,但是明显 BIFSeg 的调整结果是最好的。
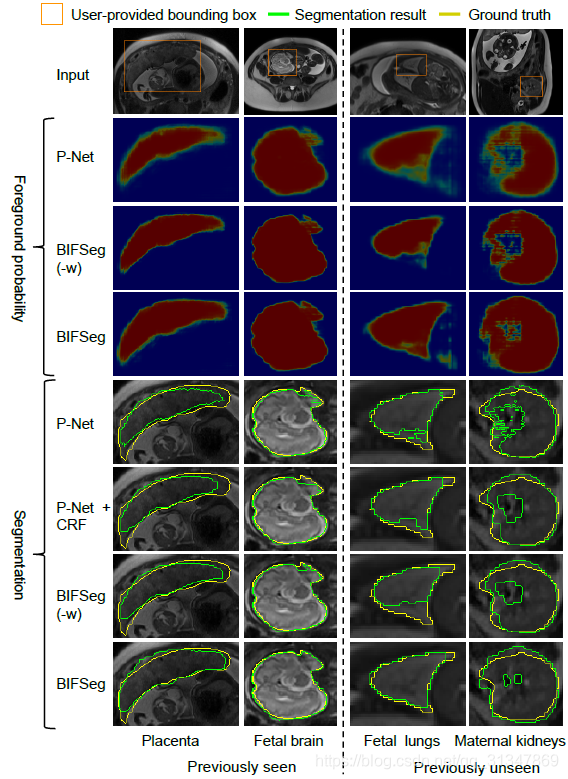

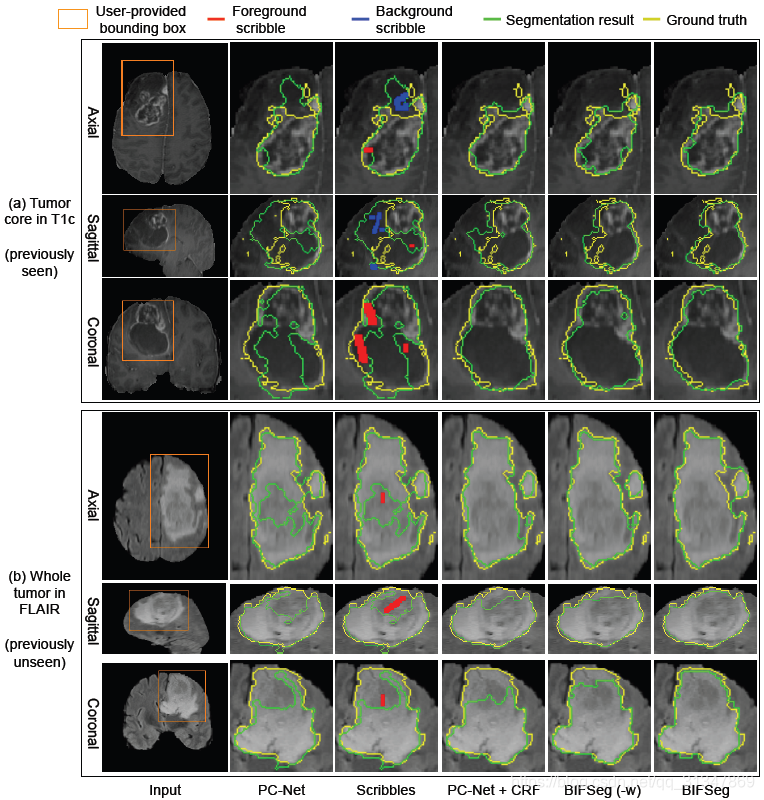
(3)Supervised Image-specific Fine-tuning:
有监督的微调需要用户在初始分割结果上画出分割不准确的地方,蓝线表示应该划分为背景,红线表示应该划分为前景。
同一个初始分割结果,同样的 scribbles,对比三种调整方法,虽然都有效果上的提升,但依然发现是 BIFSeg 的分割结果最好。
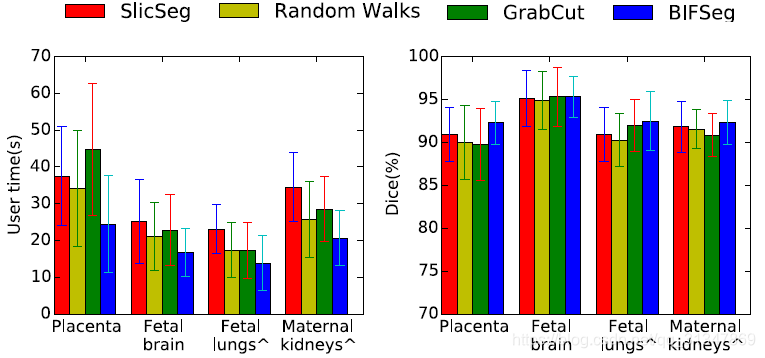
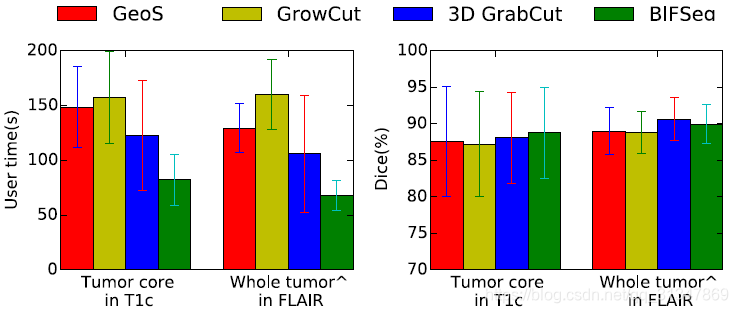
(4)与其他交互式分割方法的比较:
BIFSeg 可以实现花费更少的用户时间,但精度上与其他方法相近或更高。
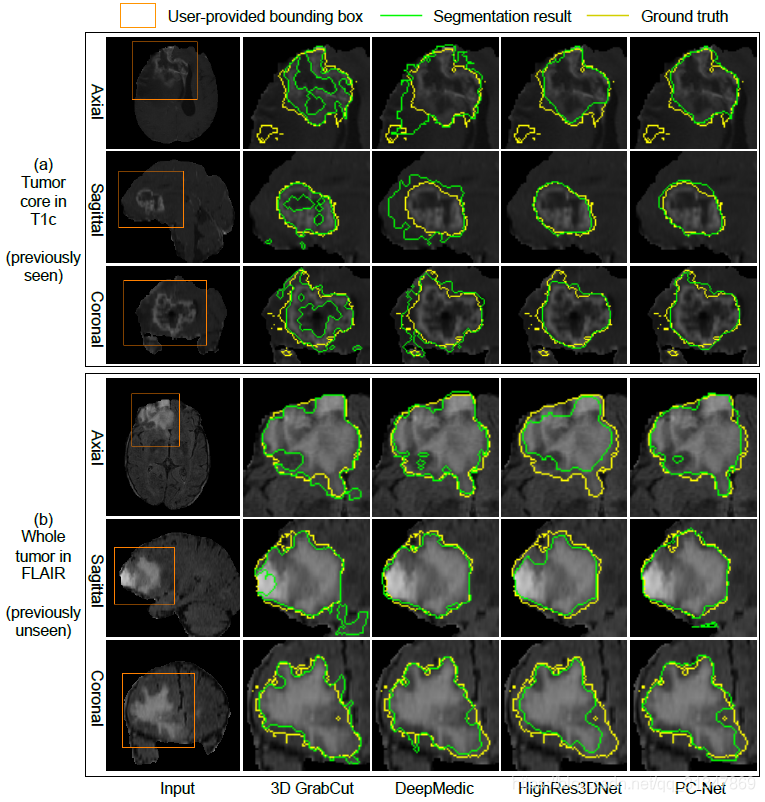
2. 3D 图像分割
数据集:2015 Brain Tumor Segmentation Challenge (BRATS) training set
(1)PC-Net 实现的初始分割结果与其他方法的对比:
(a)图:3D GrabCut 和 DeepMedic 效果都不好,前者比 ground truth 小,后者比 ground truth 大。HighRes3DNet 虽然和 PC-Net 效果差不多,但是 PC-Net 计算消耗存储空间小。
(b)图,对于未见图像的分割,由于肿瘤区域强度的不一致,3D GrabCut分割效果不好。
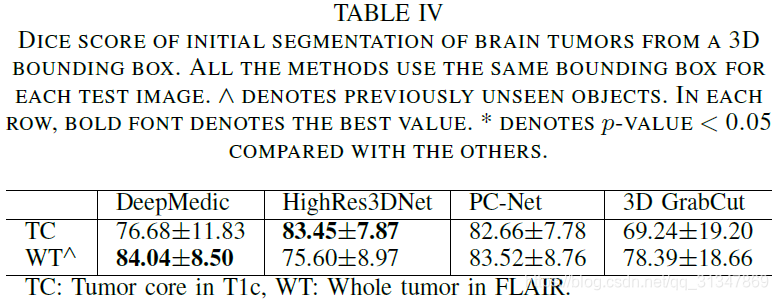
从下表看出,DeepMedic 在 T1c 上的准确率比较低,在 FLAIR 上的准确率较高,HighRes3DNet 刚好和它相反。
原因:DeepMedic 的感受野比较小,比较依赖局部特征,T1c 的图像比较复杂,所以处理效果不好。
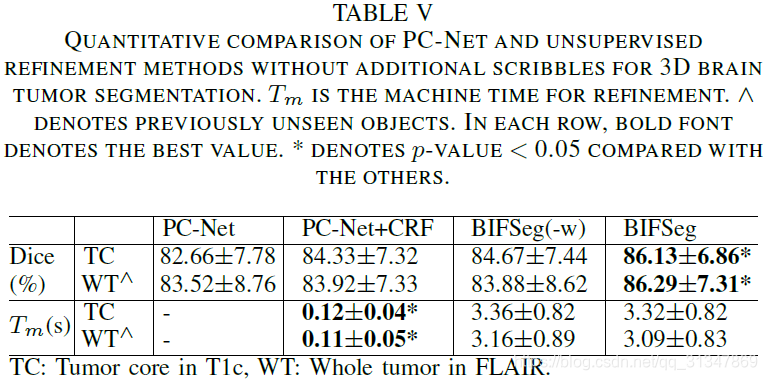
(2)Unsupervised Image-specific Fine-tuning:
基于 PC-Net 得到的初始分割结果,仍然用其他三种方式进行无监督的调整。
不管对于见过的还是没见过的图像,BIFSeg 仍然是表现最好的,其他两种方法相比初始结果有提升,但是不够好。
(3)Supervised Image-specific Fine-tuning:
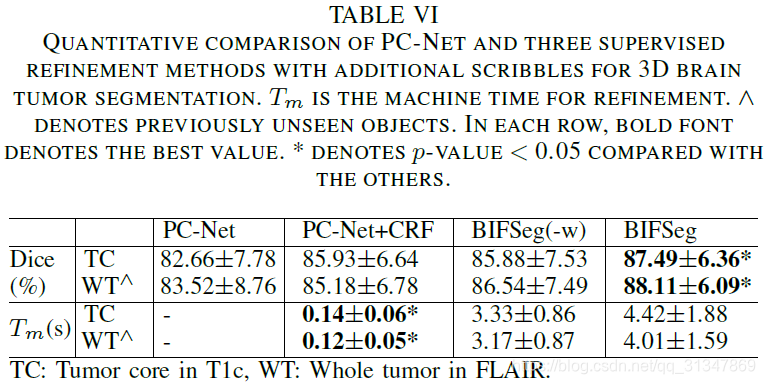
(4)与其他交互式分割方法的比较:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











