







一、列表 list
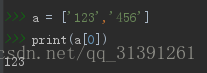
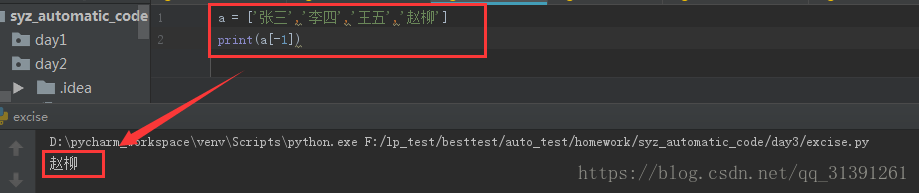
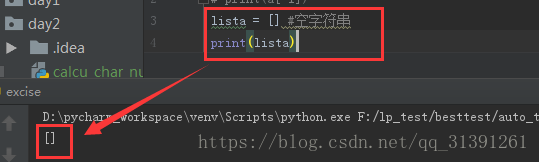
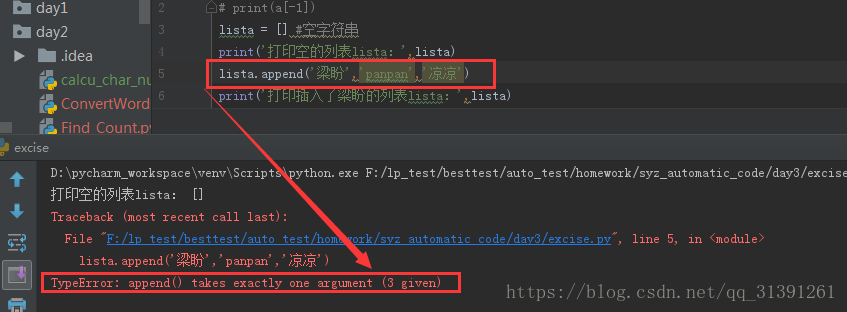
1.定义:列表、list、数组、array其实都是指的同一个事物; 2.特点: 1)列表的定界符为一对中括号 如a=['123','456']那么a就是一个列表 2)列表索引的下标是从0开始计时的,如 print(a[0]) 则为123 e.g.1 3)下标为-1,表示取最后一个元素 e.g.2 3.列表的操作 1)定义空列表 , list = [] , e.g.3 2)增加_给列表增加元素 >append()方法 :在列表末尾增加一个元素 e.g.4 可通过循环查看append后的效果,e.g.5 注意:append()方法里面只能写一个参数
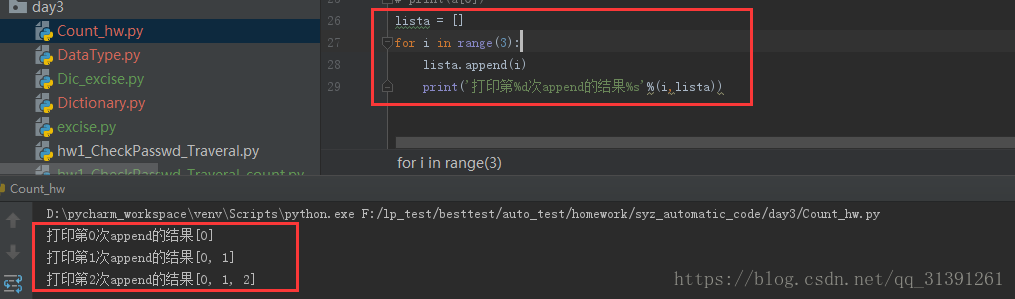
lista = [] #定义空列表 for i in range(3): #循环3次 lista.append(i) #将每次循环的添加到lista中 print('打印第%d次append的结果%s'%(i,lista)) #打印lista > insert()方法,定义的格式insert(index,object),在列表的第x个索引位置添加 e.g.6 注意: a.如果索引为负数表示从右开始的第x个角标插入,但是最后一个位置不能通过-0插入 b.如果index的绝对值大于列表长度,则将值插在list的第一个位置或者最后一个位置 c.这种负值操作应该属于非人操作,可忽略 3)删除操作 >pop(),删除指定索引位置的元素,默认是最后一个,并返回元素,即xxx.pop()的作用是将xxxlist最后一个元素删除 e.g.7 说明: b.如果list的下标索引值在list中找不到或者list为空都会报错,如下图 e.g.8 > remove() 删除列表中的某个元素 格式:xxx.remove(value) def remove(self, value): # real signature unknown; restored from __doc__ """ L.remove(value) -> None -- remove first occurrence of value. Raises ValueError if the value is not present. """ pass说明:如果列表中不存在要查找的value则会报错 e.g.9 PS: a. pop()与remove()的区别: pop()利用角标进行删除 remove()根据入参的值进行删除 b. pop()与remove()的共同点: 如果检索不到下标或者value均会报错 e.g.10 >clear() 清空整个列表 e.g.11 def clear(self): # real signature unknown; restored from __doc__ """ L.clear() -> None -- remove all items from L """ pass>del list[下标] 使用del关键字,通过list的下标删除元素 |
4)修改
格式:list[x]='xxx'
说明:修改列表某个位置的内容,如果列表无对应下标则会报错
5)查找
> 获取元素的下标
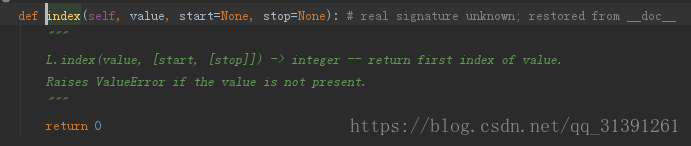
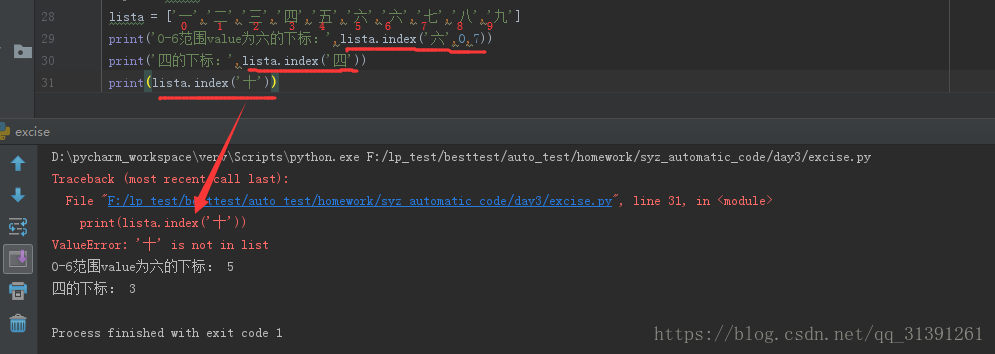
格式:list.index(value,[start,[stop]])
说明:
a.返回value在列表中第一次匹配到的下标值(列表中允许有重复的value),
b.value是必须填写的参数;
c.start,stop为列表的下标,必须为int类型;
c.如果value在列表中找不到对应的值,则会报错
> 根据下标获取对应value
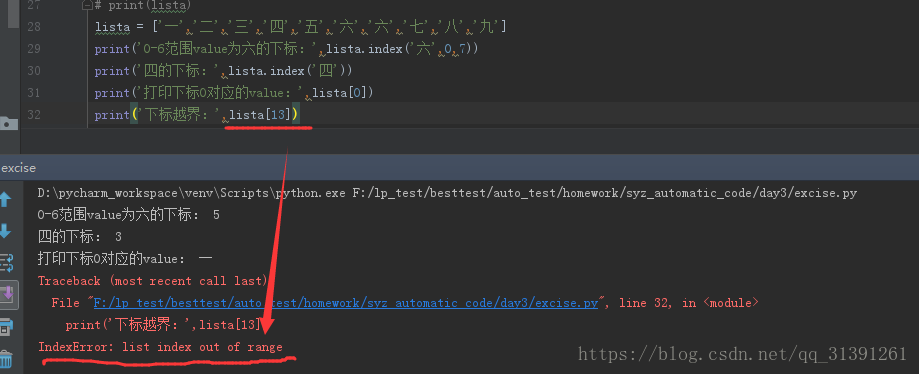
格式:list[x]
说明:x为列表中的某个下标,如果下标越界会报错
6)其他操作
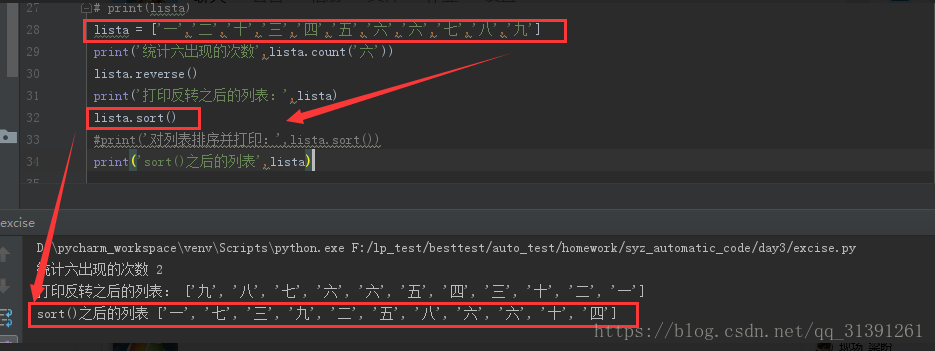
>list.count('value') 统计某个value出现的次数
>list.reverse() 反转列表
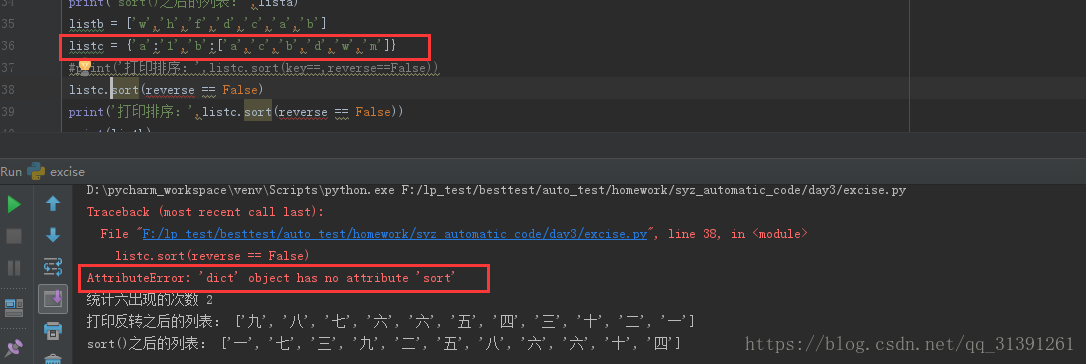
>list.sort() 列表原地排序(存疑)
>list1+list2 合并列表,列表2挂在列表1之后
>list*n 复制列表
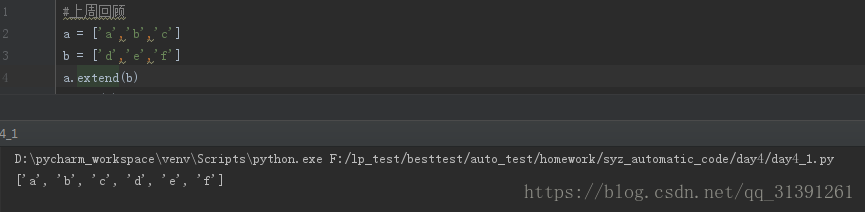
>lista.extend(listb) #将listb列表合并到lista列表之后,练习见
>len(list) #统计列表中的数据项的个数 如:a =['123','456','789'] 那么len(a) =3
def extend(self, iterable): # real signature unknown; restored from __doc__ """ L.extend(iterable) -> None -- extend list by appending elements from the iterable """ pass
说明:sort()可排序数字和字母,汉字的排序还打不到预想的效果
e.g.1
e.g.2
e.g.3
e.g.4
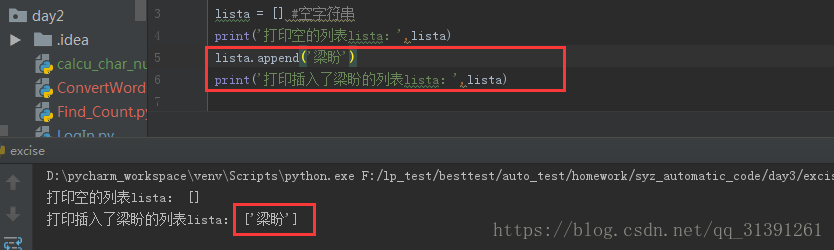
e.g.5 通过循环查询append()方法的效果
注意:append()方法里面只能写一个参数
e.g6 insert()
lista = [] #空list #lista.insert(0,'lp') lista.insert(1,'index1') print(lista) lista.insert(0,'index0') print(lista) lista.insert(-0,'index0') print(lista) lista.insert(-2,'index右2') print(lista) lista.insert(-1,'index右1') print(lista) lista.insert(-3,'index右3') print(lista) lista.insert(-6,'index右6') print(lista) lista.insert(-10,'index右10')#如果index的绝对值大于列表长度,则将值插在list的第一个位置或者最后一个位置 print(lista) lista.insert(20,'index二十') print(lista)
运行结果:

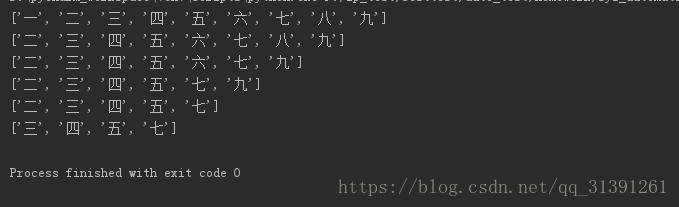
e.g.7 pop(),删除指定索引位置的元素,默认是最后一个,即xxx.pop()的作用是将xxxlist最后一个元素删除
lista = ['一','二','三','四','五','六','七','八','九'] print(lista) # L.pop([index]) -> item -- remove and return item at index (default last). Raises IndexError if list is empty or index is out of range. lista.pop(-0) print(lista) lista.pop(-2) print(lista) lista.pop(-3) print(lista) lista.pop() print(lista) lista.pop(0) print(lista)
运行结果:
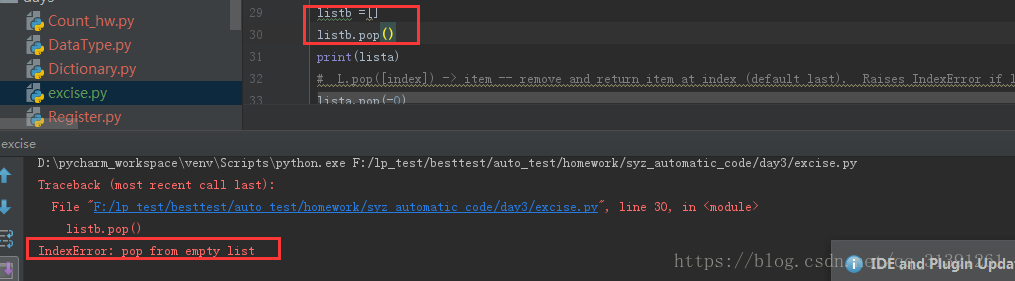
e.g.8 如果list的下标索引值在list中找不到或者list为空都会报错,如下图

下标越界
对空list进行pop操作
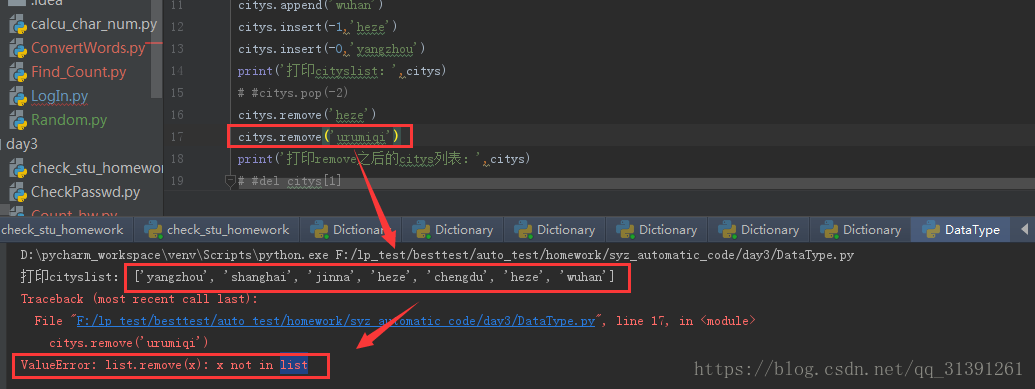
e.g.9 remove() 如果列表中不存在要查找的value则会报错,如下所示:
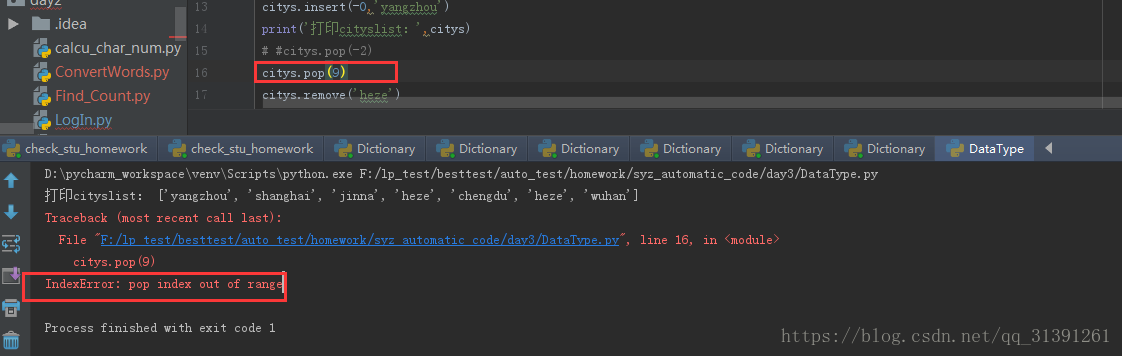
e.g.10 pop(index)如果下标不存在会报错
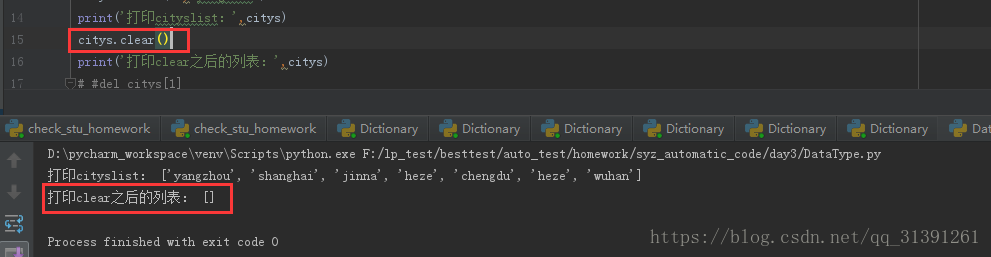
e.g.11 clear 清空列表
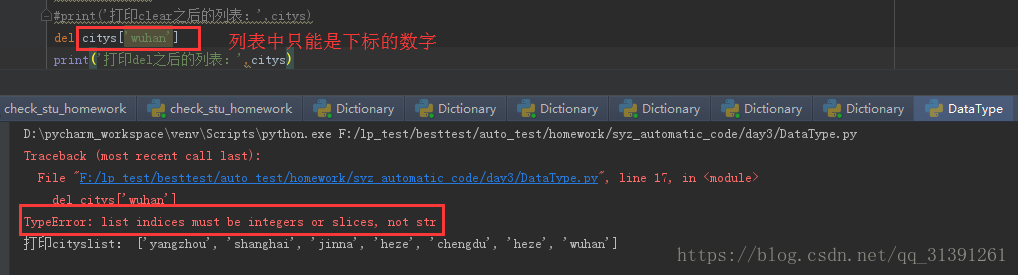
e.g.12 del list[下标]
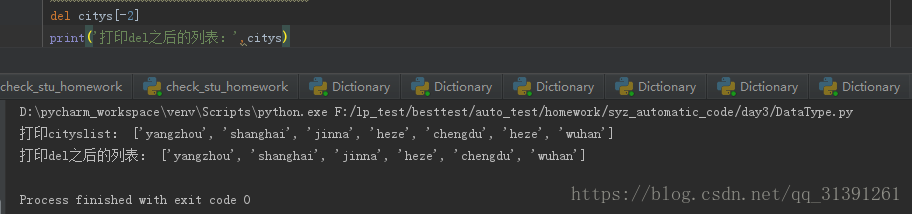
ps:
-号表示从右侧开始的角标位置(-1表示最后一个即从右边数的第一个,-2表示从右边数的第2个),纯属自己试验猜测
4)修改
格式:list[x]='xxx'
说明:修改列表某个位置的内容,如果列表无对应下标则会报错

5)查找
> 获取元素的下标
格式:list.index(value,[start,[stop]])
说明:
a.返回value在列表中第一次匹配到的下标值(列表中允许有重复的value),
b.value是必须填写的参数;
c.start,stop为列表的下标,必须为int类型;
c.如果value在列表中找不到对应的值,则会报错
> 根据下标获取对应value
格式:list[x]
说明:x为列表中的某个下标,如果下标越界会报错
6)其他操作
>list.count('value') 统计某个value出现的次数
>list.reverse() 反转列表
>list.sort() 列表原地排序(存疑)
>list1+list2 合并列表,列表2挂在列表1之后
>list*n 复制列表
说明:sort()可排序数字和字母,汉字的排序还打不到预想的效果



练习:
列表的合并,listb+lista 复制n次

问题:字典没有参数,这个以后再研究
e.g.13
二、字典
1.概念
字典是以key-value形式存在的数据类型
特点:
> 取数据方便
> 速度快(比list快)
> 字典是无序的
2.查询取值方法
1)get('key')

get('key')后面还可以跟一个默认值,即get('key',default),如:dic.get('xxx','NULL'),如果dic字典中找不到xxx对应的key那么返回NULL

2)dic['key']
注意:
方法 get('key'),dic['key']的区别是,['key']如果在字典中取不到key的值,程序会报错,get('key')取不到key不会报错
e.g
脚本:
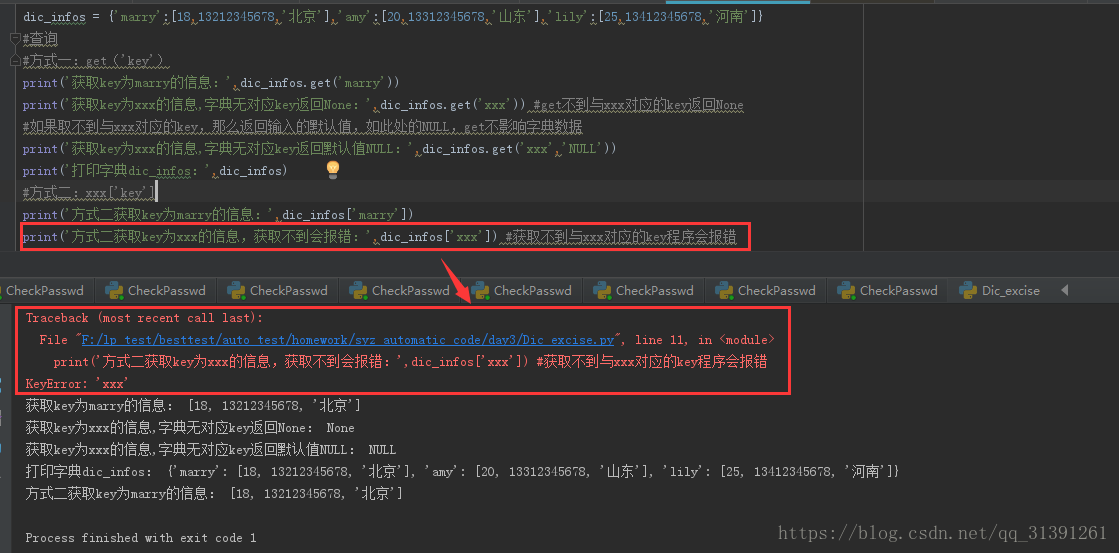
dic_infos = {'marry':[18,13212345678,'北京'],'amy':[20,13312345678,'山东'],'lily':[25,13412345678,'河南']}
#查询
#方式一:get('key')
print('获取key为marry的信息:',dic_infos.get('marry'))
print('获取key为xxx的信息,字典无对应key返回None:',dic_infos.get('xxx')) #get不到与xxx对应的key返回None
#如果取不到与xxx对应的key,那么返回输入的默认值,如此处的NULL,get不影响字典数据
print('获取key为xxx的信息,字典无对应key返回默认值NULL:',dic_infos.get('xxx','NULL'))
print('打印字典dic_infos:',dic_infos)
#方式二:xxx['key']
print('方式二获取key为marry的信息:',dic_infos['marry'])
print('方式二获取key为xxx的信息,获取不到会报错:',dic_infos['xxx']) #获取不到与xxx对应的key程序会报错
>多维字典获取值
people = {
'张三':{
'age':18,
'money':200000,
'clothes':'100套',
'hzp':'n多',
'shoes':['nike','addis','lv','chanle']
},
'李四':{
'金库':'2000w',
'house':['三环一套','4环2套'],
'cars': {
'japan':['普拉多','兰德酷路泽'],
'usa':['林肯','凯迪拉克','福特'],
'china':['五菱宏光','qq','红旗']
}
}
}
e.g
#获取字典中的qq车

#给张三增加400
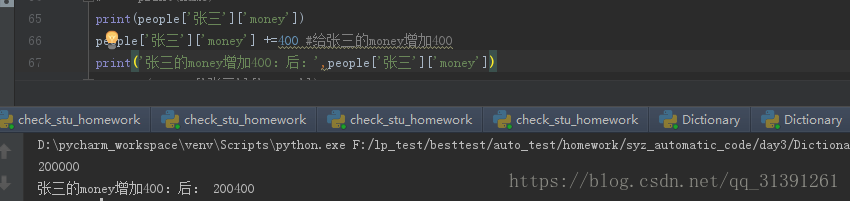
#for循环直接循环字典,in只能判断key是不是存在与字典中
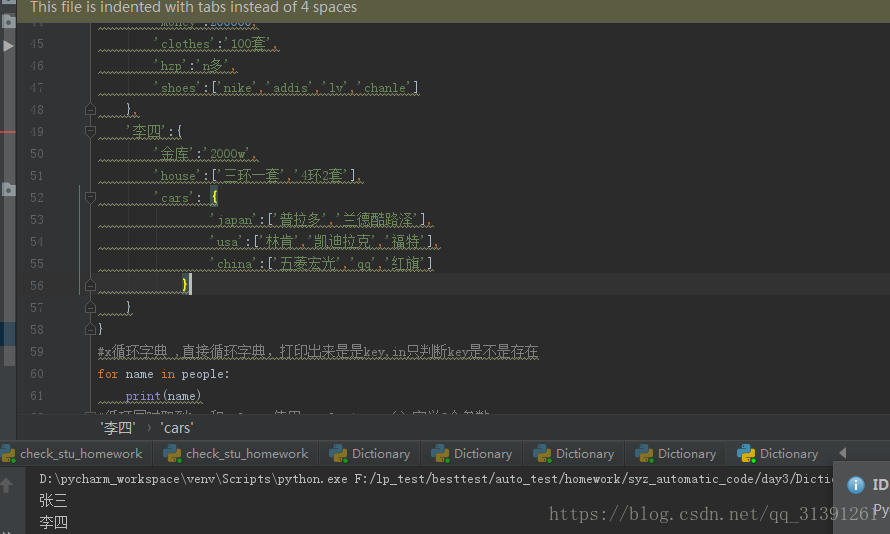
#使用for循环字典的item(),判断key和value是否存在与字典中
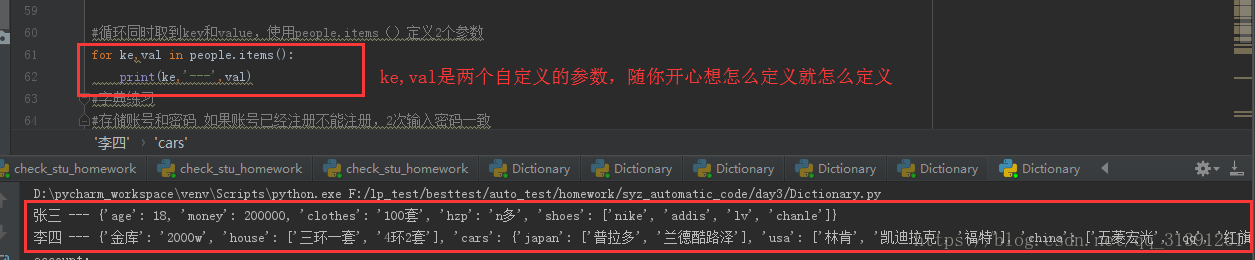
脚本:
#循环同时取到key和value,使用people.items()定义2个参数 for ke,val in people.items(): print(ke,'---',val)
3)获取所有的key,value 级key-value
> dic.values() 获取到字典中所有的value值并存放到元组中

>dic.keys() 获取到字典中所有的key并存放到元组中

>dic.items() 获取字典中所有的字典项的key-value并存放到元组中

e.g
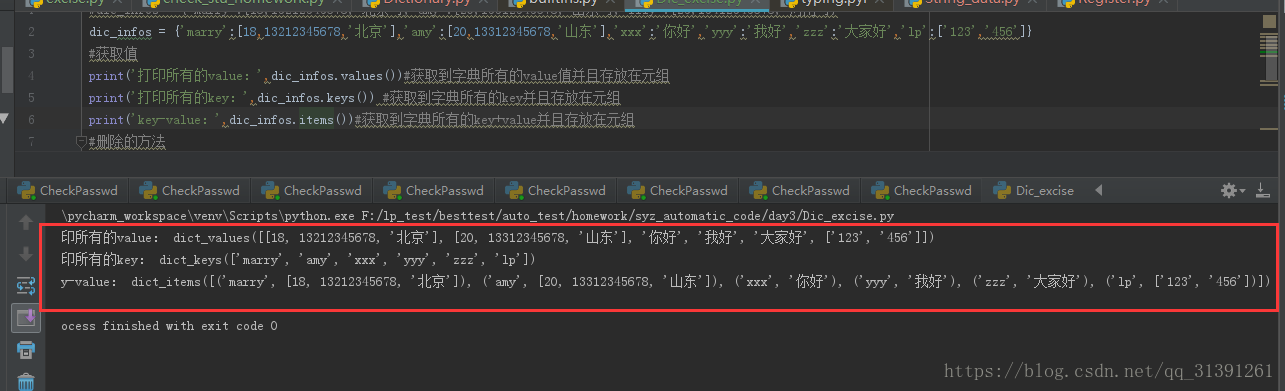
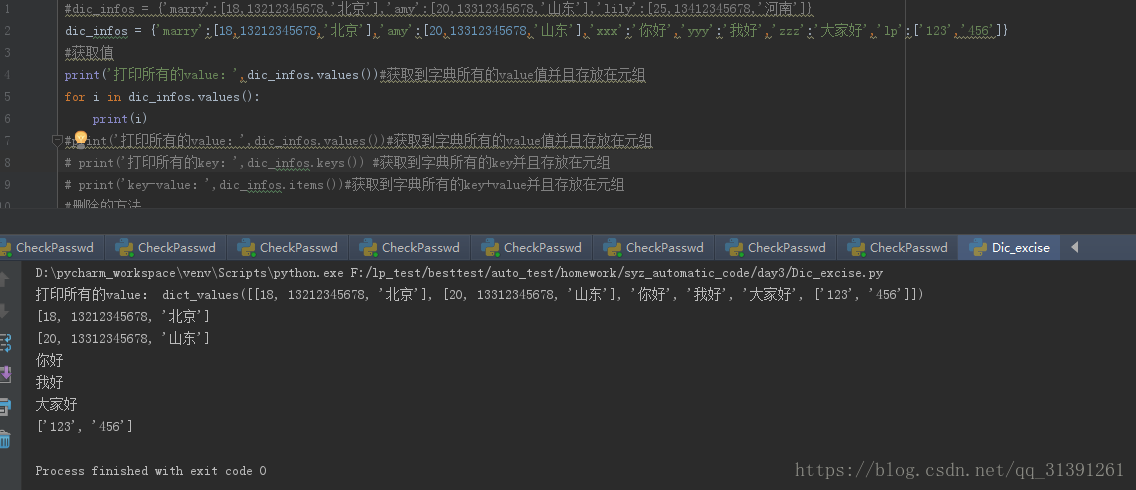
脚本:
dic_infos = {'marry':[18,13212345678,'北京'],'amy':[20,13312345678,'山东'],'xxx':'你好','yyy':'我好','zzz':'大家好','lp':['123','456']}
#获取值
print('打印所有的value:',dic_infos.values())#获取到字典所有的value值并且存放在元组
for i in dic_infos.values():
print(i)
#print('打印所有的value:',dic_infos.values())#获取到字典所有的value值并且存放在元组
# print('打印所有的key:',dic_infos.keys()) #获取到字典所有的key并且存放在元组
# print('key-value:',dic_infos.items())#获取到字典所有的key+value并且存放在元组
3.字典的新增操作
1)dic['key'] = value key与value将插入到字典的末尾,
2)dic.setdefault('key',[default value]) key与value将插入到字典的末尾,default value可以缺省,如果不写则默认插入None

3)update() a.update(b) #相当于把b字典元素添加到a中
4)三种新增方式的区别:
> 如果字典中不存在与新增key同名的key值,那么1)2)3)的效果一致,都是在字典的尾部插入字典项
>如果字典中存在于与新增key同名的key值,那么方法一与方法二效果不同,如下所示:
1)3)新增字典项,如果key在字典中已经存在,那么后面key的value会将字典中同名的key的value修改
2)新增字典项,如果key在字典中已经存在,那么后面key的value不会将字典中同名的key的value修改
e.g
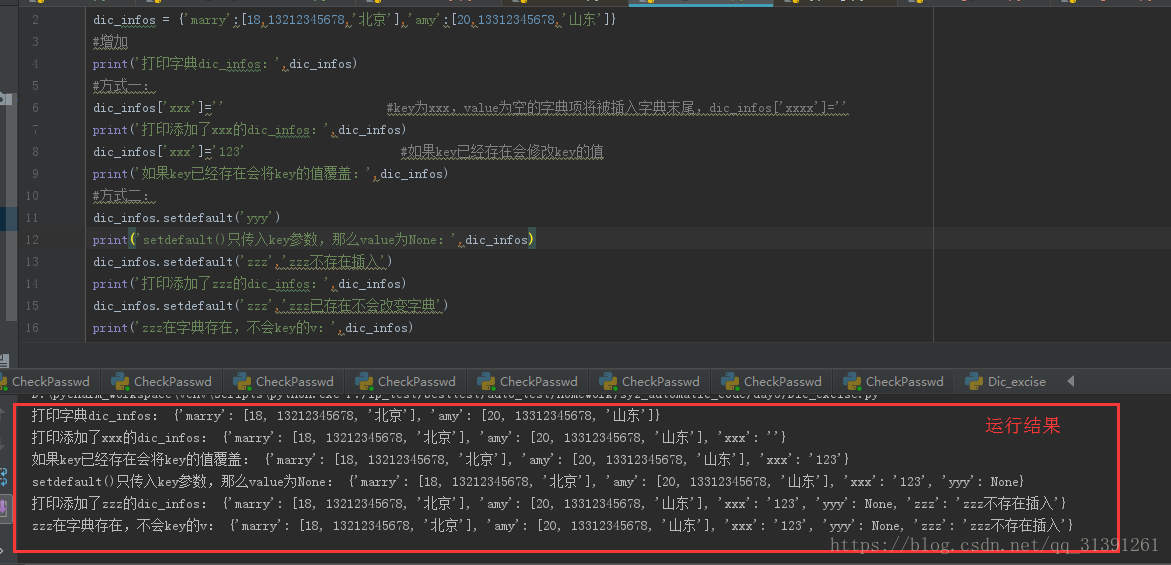
脚本:
dic_infos = {'marry':[18,13212345678,'北京'],'amy':[20,13312345678,'山东']}
#增加
print('打印字典dic_infos:',dic_infos)
#方式一:
dic_infos['xxx']='' #key为xxx,value为空的字典项将被插入字典末尾,dic_infos['xxxx']=''
print('打印添加了xxx的dic_infos:',dic_infos)
dic_infos['xxx']='123' #如果key已经存在会修改key的值,相当于修改操作
print('如果key已经存在会将key的值覆盖:',dic_infos)
#方式二:
dic_infos.setdefault('yyy')
print('setdefault()只传入key参数,那么value为None:',dic_infos)
dic_infos.setdefault('zzz','zzz不存在插入')
print('打印添加了zzz的dic_infos:',dic_infos)
dic_infos.setdefault('zzz','zzz已存在不会改变字典')
print('zzz在字典存在,不会key的v:',dic_infos)
#如果key不存在[]与setdefault的效果一致
#dic_infos['xxx']='update' #如果key已经存在会修改key的值,
#dic_infos.setdefault('xxx','update?')#如果默认已经有了key ,则不会更改
#dic_infos['aaa']= ['aaa的value','aaa的value为列表'] #value也可以是列表
#print('打印添加了aaa的dic_infos:',dic_infos)
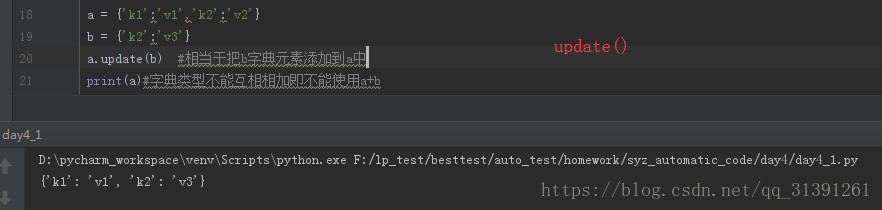
4.字典的修改操作
方式:dic['key'] = value
方式:dic.update('key':'value')
def update(self, E=None, **F): # known special case of dict.update """ D.update([E, ]**F) -> None. Update D from dict/iterable E and F. If E is present and has a .keys() method, then does: for k in E: D[k] = E[k] If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v In either case, this is followed by: for k in F: D[k] = F[k] """ pass
e.g

脚本:
dic_infos = {'marry':[18,13212345678,'北京'],'amy':[20,13312345678,'山东']}
#增加
print('打印字典dic_infos:',dic_infos)
#方式一:
dic_infos['xxx']='abc' #key为xxx,value为abc的字典项将被插入字典末尾
print('插入xxx后的字典:',dic_infos)
dic_infos['xxx']='我是修改,修改前是abc' #修改xxx的value为efg
print('修改xxx后的字典:',dic_infos)
5.字典的删除操作
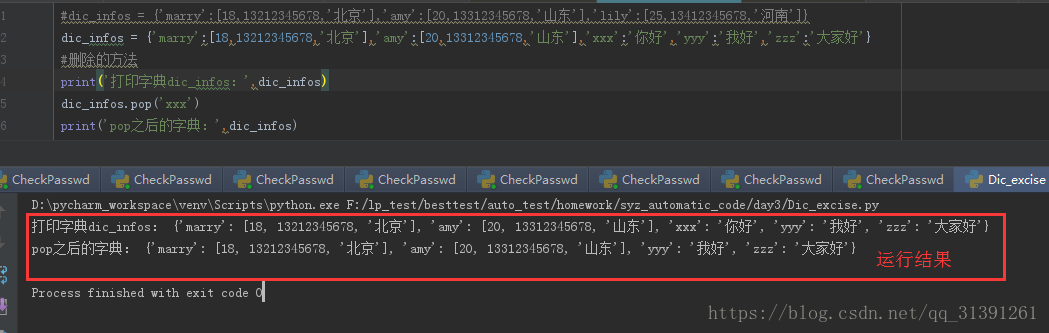
1)pop('key') 删除字典中的某个key的字典项

e.g
2)popitem() ,方法中没有入参,随机删除字典中的某个字典项,如果字典为空,此方法会报错(不常用)
e.g
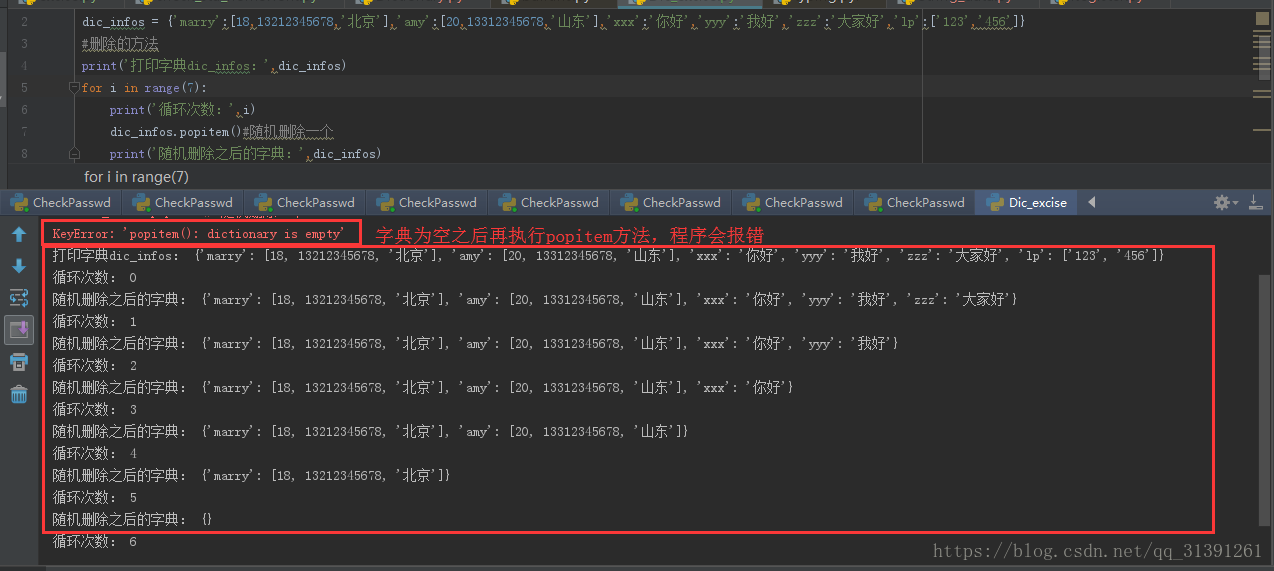
说明:字典本无序,无所谓前后,此处只是巧合从感官上每次都是pop的最后一个
脚本:
dic_infos = {'marry':[18,13212345678,'北京'],'amy':[20,13312345678,'山东'],'xxx':'你好','yyy':'我好','zzz':'大家好','lp':['123','456']}
#删除的方法
print('打印字典dic_infos:',dic_infos)
for i in range(7):
print('循环次数:',i)
dic_infos.popitem()#随机删除一个
print('随机删除之后的字典:',dic_infos)
3)del dic['key'] 使用del删除字典,如果在字典中没有对应的key那么程序会报错
e.g
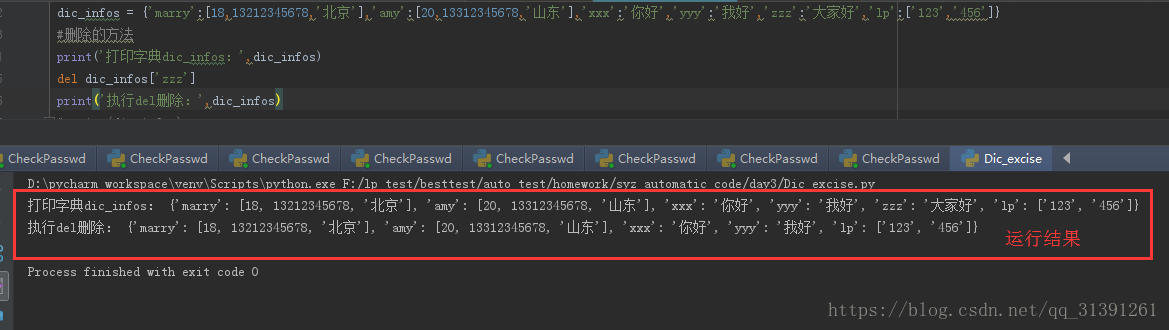
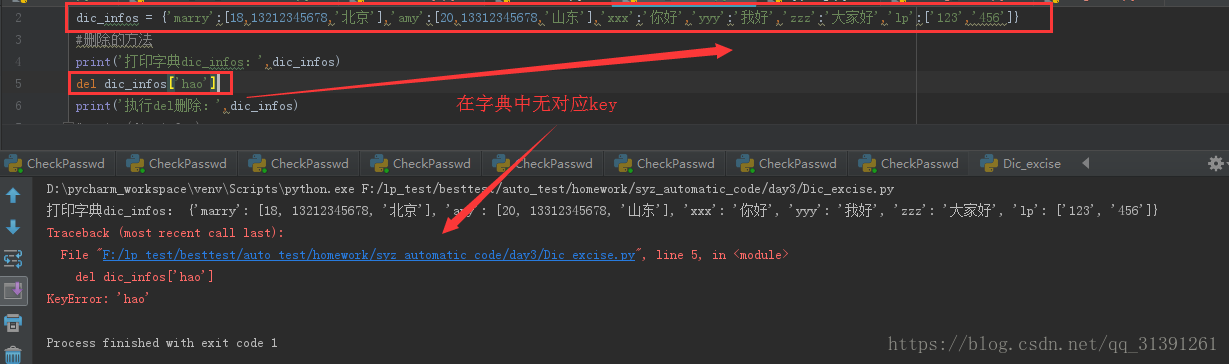
4)clear() 清空字典,字典为空字典,执行clear()也不会报错

e.g
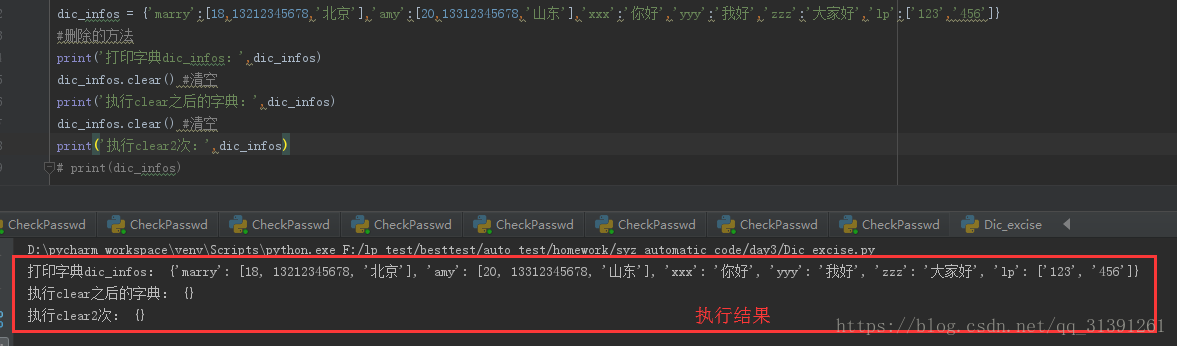
脚本:
dic_infos = {'marry':[18,13212345678,'北京'],'amy':[20,13312345678,'山东'],'xxx':'你好','yyy':'我好','zzz':'大家好','lp':['123','456']}
#删除的方法
print('打印字典dic_infos:',dic_infos)
dic_infos.clear() #清空
print('执行clear之后的字典:',dic_infos)
dic_infos.clear() #清空
print('执行clear2次:',dic_infos)
三、切片
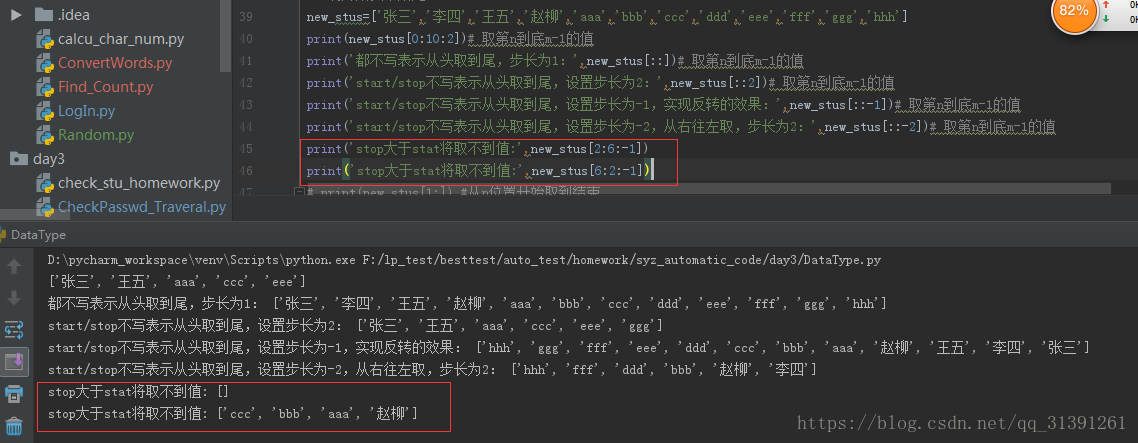
1.列表/字符串取值的一种方式; 2.格式:list[start:stop[:setp]] 3.说明: 1)start起始下标(包含),stop结束下标(不包含),step步长(可选,默认步长为1) e.g.1 list[0:10:2] 获取list列表中下标为0,2,4,6,8,的value 2)若start,stop均不写,则表示取值范围为整个列表 e.g.2 list[::] 3)若step为负值,则表示在start - stop 的范围从右往左取值,绝对值表示步长 e.g.3 list[::-1] / list[::-2] 4)若步长为负数,stop大于start将取到空的列表 e.g.4 new_stus[2:6:-1] 取不到值,因为2的左侧只有0和1这2个下标;new_stus[6:2:-1] 可以取到值 |
结果截图:
e.g.1

e.g.2
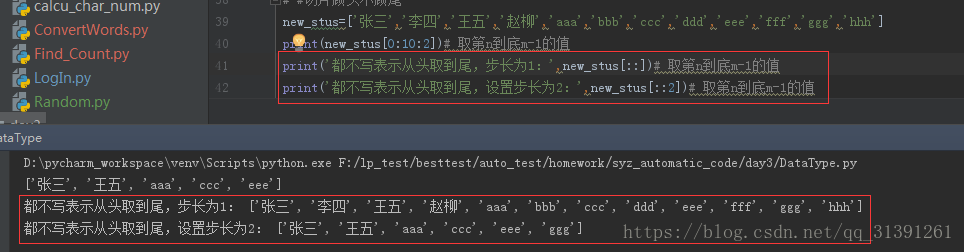
e.g.3
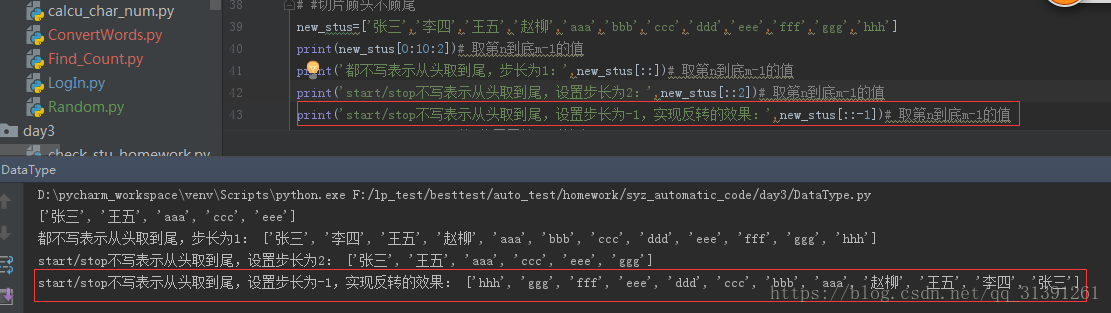
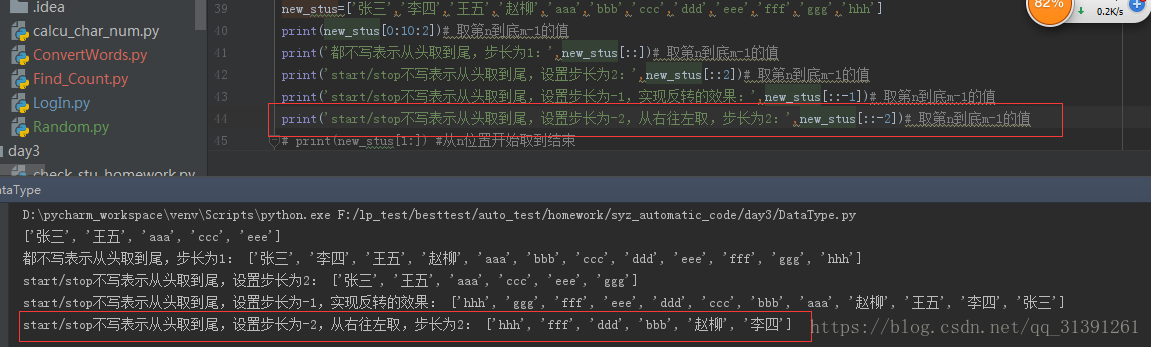
e.g.4
四、类型转换
1.int(param) 将参数param转成int类型 2.list(param) 将参数param转成list类型 3.bool(param) 将参数param转成布尔类型 |
五、判断参数的类型
1.type(param) == list 判断参数是否为list列表 2.type(param) == int 判断参数是否为int类型 3.type(param) == float 判断参数是否为float类型 |
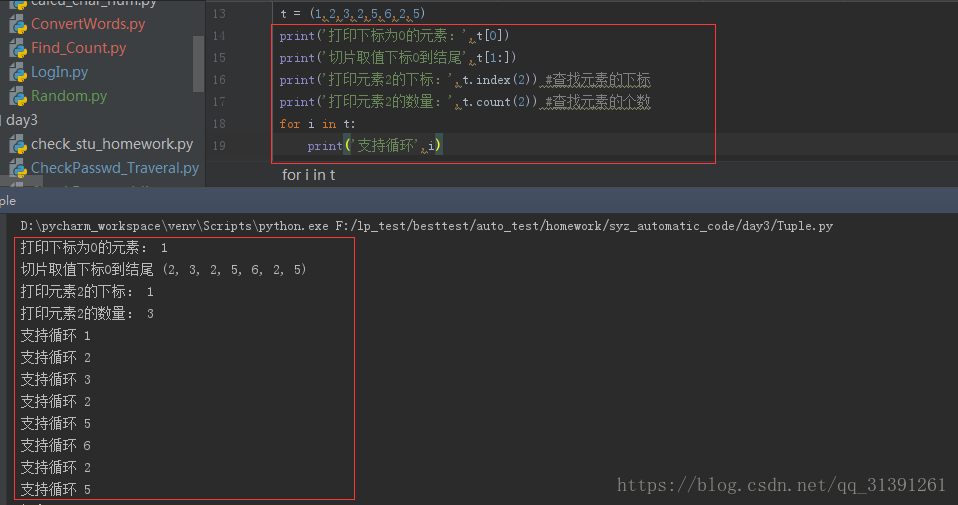
六、元组
1.元祖也是一个list,它与list的区别是,元组里面元素无法修改; 2.定界符,一对小括号(),如果 t =(1,2,3) 那么t为1个元组 3.如果元组中只有一个元素,元素的后面需要添加一个逗号才表示元组类型,不然就等于元素的类型;如e.g.1 4.元组不支持修改操作,元组定义好之后,不能修改其中的元素;e.g.2 5.元组可进行的操作:循环、切片、下标取值,统计数量;e.g.3 6.优点:存放不可修改的数据,避免修改导致的不必要的麻烦 |
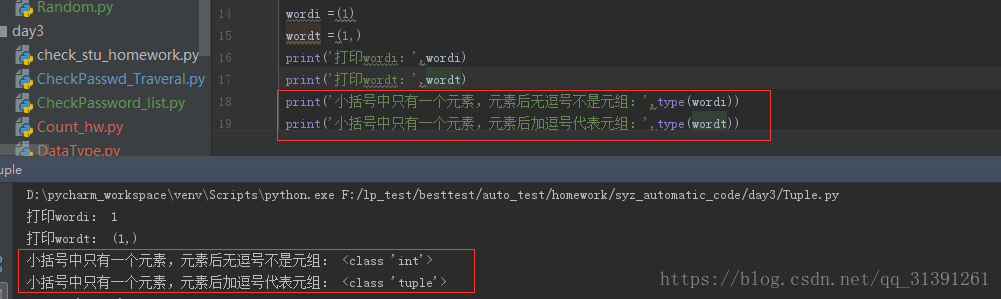
e.g.2
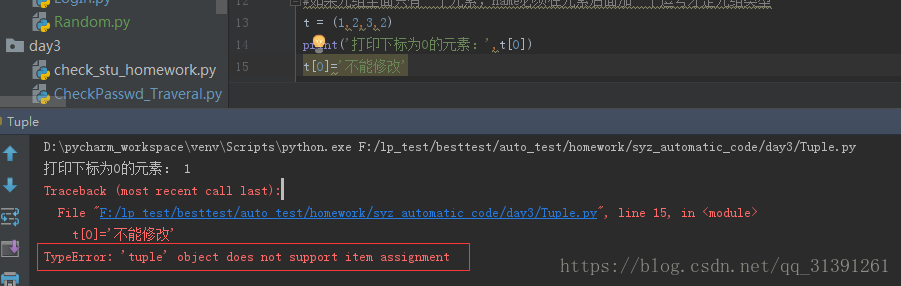
e.g.3
七、布尔类型
1.布尔类型,只有2个值 True 和False 2.python中True首字母大写才是关键字,true只是个普通的变量 |
八、字符串
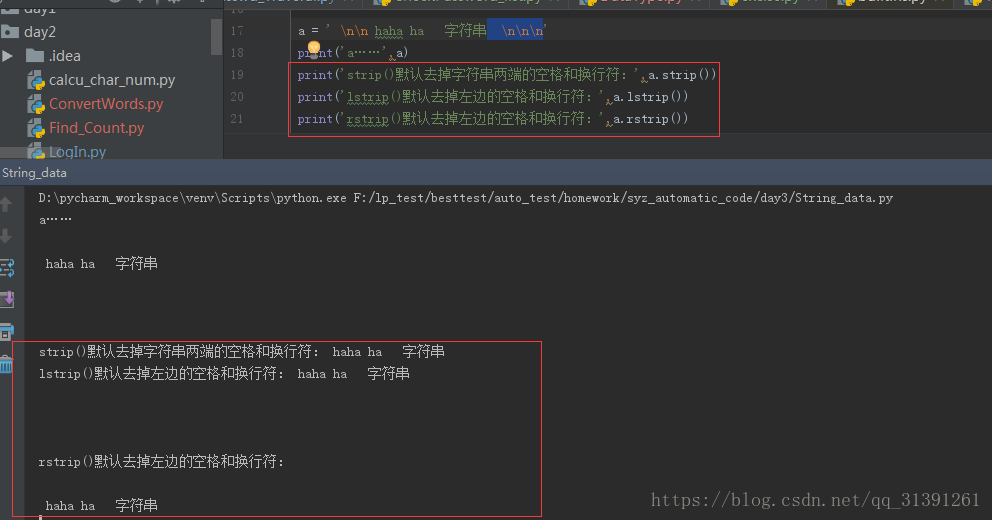
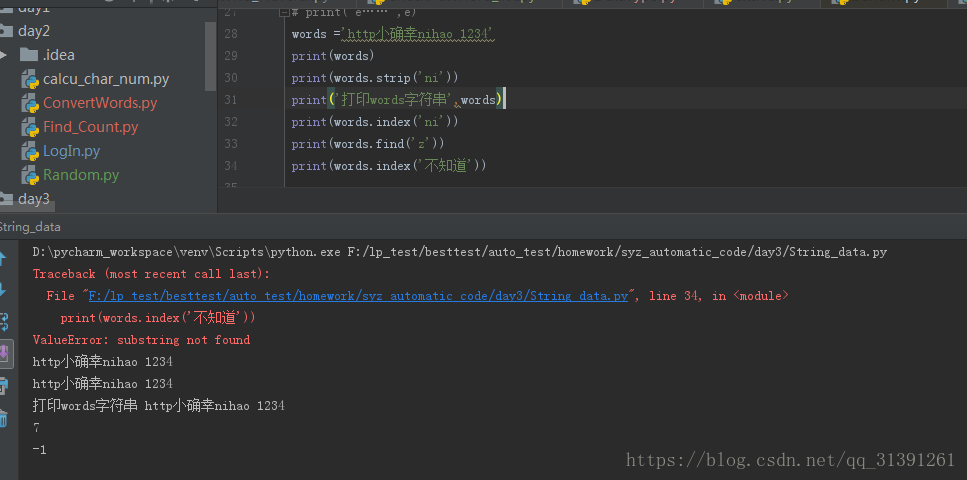
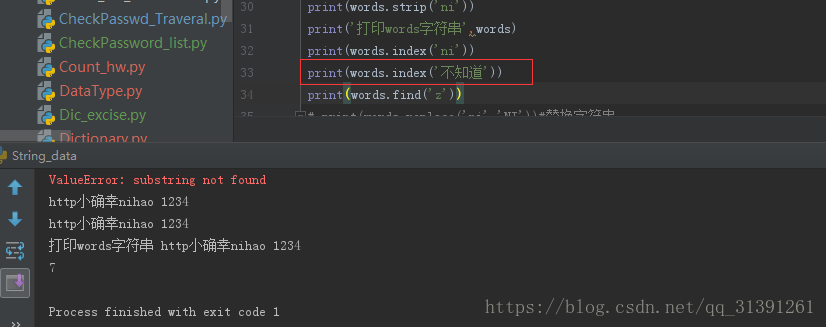
1.字符串常用方法 e.g.1 # strip() #默认去掉字符串两端的空格和换行符 # rstrip() #默认去掉右边的空格和换行符 e.g.2 # strip('xxx')#删除指定的字符串,不改变原有字符串的元素,字符串不能被修改# .count('a')#统计字符串出现的次数 # .index('x')#查找字符串的位置,如果元素找不到会报错 (ValueError: substring not found) # .find('x')#如果元素找不到不会报错,返回-1 #所以,查找元素,只用find()方法要优于index() e.g.3 # .replace('old'.'new') #替换字符串,同样不改变原字符串,但是可以将结果赋值给另外一个变量 e.g.4 # .startswith() 匹配返回True,不匹配返回False# .endswith() 匹配返回True,不匹配返回False e.g.5 # .upper()变成大写,不改变原字符串,但是可以将结果赋值给另外一个变量# .lower()变成小写,不改变原字符串,但是可以将结果赋值给另外一个变量 e.g.6 字符串判断 print('判断数字:',words_digit.isdigit()) #字符串全部内容均为数字才为真 print('判断数字:',words.isdigit()) #判断是否为数字 print('字符串存在大小写混合,判断小写:',words.islower())#判断是否为小写 print('字符串中的字母全部为小写,判断小写:',words_lower.islower())#字符串中的字母全部为小写即可 print('字符串存在大小写混合,判断大写:',words.isupper())#判断是否为大写 print('字符串中的字母全部为大写,判断大写:',words_upper.isupper())#字符串中的字母全部为大写即可 #istitle()判断首字母是否大写 #isprintable()判断是否可打印 (有疑问) #isidentifier()判断是否有定义 (有疑问) #isdecimal()判断是否为十进制 #isspace()判断字符串是否全部为空格,空字符串也为False #isnumeric()判断字符串仅包含数字,其他任何字符的存在都返回False #isalpha()判断字符串是否全部为字母,全部为字母(也可包含汉字)则为True,包含数字、空格等符号均为False #isalnum()字符串为大写、小写、数字(此3者为或的关系)则为真,若包含其他则为假,汉字不再判断列表中,字母数字夹杂汉字也为True e.g.7 字符串连接: ''.join('') 1)''表示用什么符号进行连接join()里面的元素,单引号中什么都不写则表示把join()里面的元素连接成字符串 3)只要是可以循环的,join都可以连接,字典、list 、string都可以使用join e.g.8 分割字符串:string.split('x') 1)根据x字符分割字符串,返回一个列表list e.g.9 格式化字符串 方式一: %s ;此方法参数要和%s位置一一对应,不然就会传错参数 方式二:format()方法,需要先用花括号{}声明 e.g.10 字符串居中方法 方法:string.center(len,'x') 如果string长度 > = len那么输出string,不够len那么则将string居中,2端补齐x |
方法简介:
e.g.1
e.g.2
e.g.3
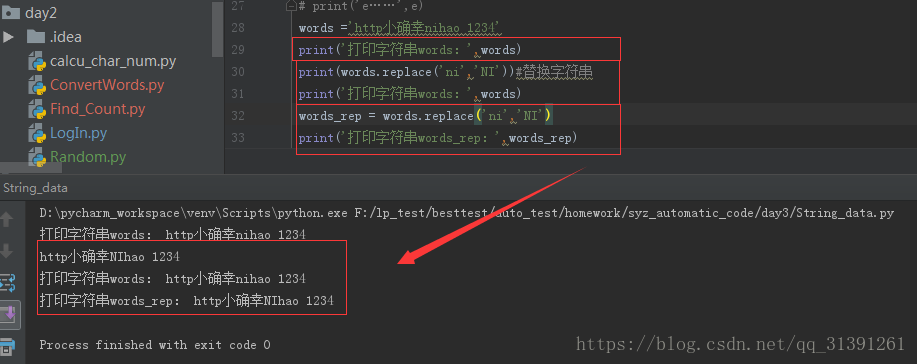
e.g.4
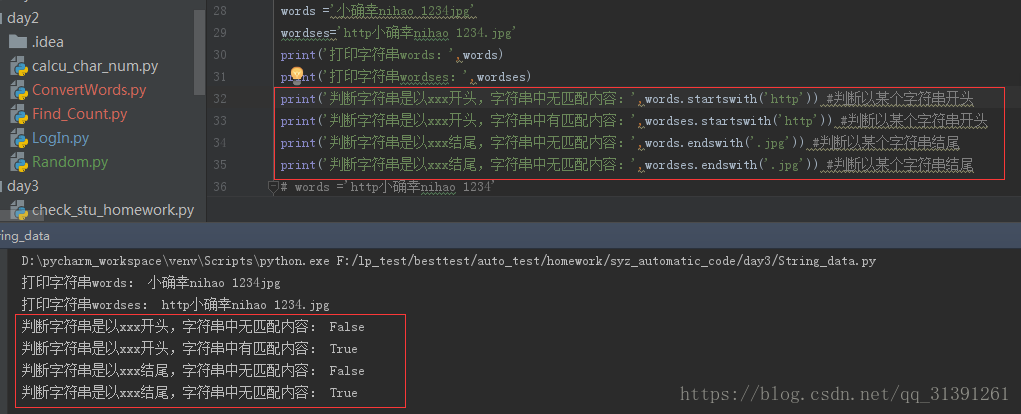
e.g.5
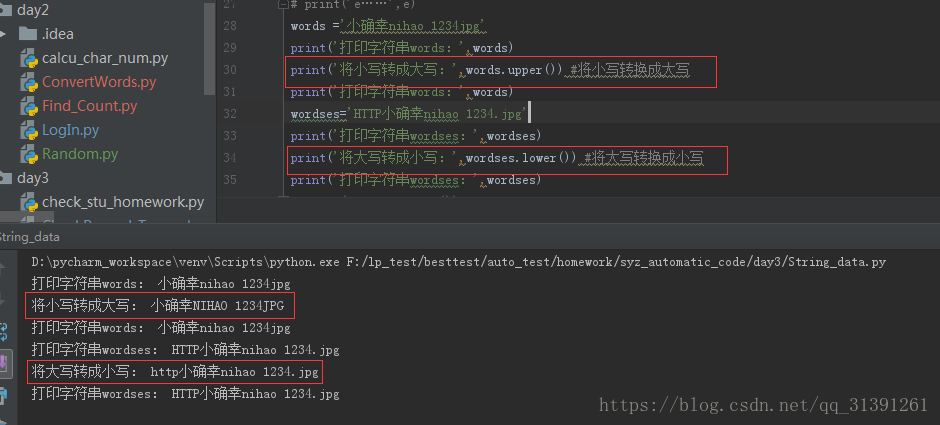
e.g.6 脚本练习
words ='HTTP小确幸nihao 1234jpg' words_digit = '1234561' words_lower ='http小确幸nihao 1234jpg' words_upper = 'HTTP小确幸NIHAO 1234JPG' words_alnum ='aT1 你23' words_alpha ='aT你好zz' words_title ='Tabc' words_space =' ' print('判断数字:',words_digit.isdigit()) #字符串全部内容均为数字才为真 print('判断数字:',words.isdigit()) #判断是否为数字 print('字符串存在大小写混合,判断小写:',words.islower())#判断是否为小写 print('字符串中的字母全部为小写,判断小写:',words_lower.islower())#字符串中的字母全部为小写即可 print('字符串存在大小写混合,判断大写:',words.isupper())#判断是否为大写 print('字符串中的字母全部为大写,判断大写:',words_upper.isupper())#字符串中的字母全部为大写即可 print('判断字母与数字:',words.isalnum()) #isalnum()字符串为大写、小写、数字(此3者为或的关系)则为真,若包含其他则为假,汉字不再判断列表中,字母数字夹杂汉字也为True print('判断字符串是否仅包含字符和数字,包含其他符号则为False:',words_alnum.isalnum()) #isalpha()判断字符串是否全部为字母,全部为字母(也可包含汉字)则为True,包含数字、空格等符号均为False print('判断字符串是否为字母,不是:',words_alnum.isalpha()) print('判断字符串是否为字母,是:',words_alpha.isalpha()) #isnumeric()判断字符串仅包含数字,其他任何字符的存在都返回False print('判断字符串只包含数字,不是:',words_alnum.isnumeric()) print('判断字符串只包含数字,是:',words_digit.isnumeric()) #isspace()判断字符串是否全部为空格,空字符串也为False print('判断字符串只包含空格,是:',words_alnum.isspace()) print('判断字符串只包含空格,是:',words_space.isspace()) #isdecimal()判断是否为十进制 print('isdecimal,否:',words_alnum.isdecimal()) print('isdecimal,是:',words_digit.isdecimal()) #isidentifier()判断是否有定义 (有疑问) print('isidentifier,是:',words_alnum.isidentifier()) #isprintable()判断是否可打印 (有疑问) print('isprintable,是:',words_alnum.isprintable()) #istitle()判断首字母是否大写 print('istitle,是:',words_title.istitle())
e.g.7
l = ['a','b','c'] print(type(l)) res = '-'.join(l) #以中划线连接 print(res) print(type(res))
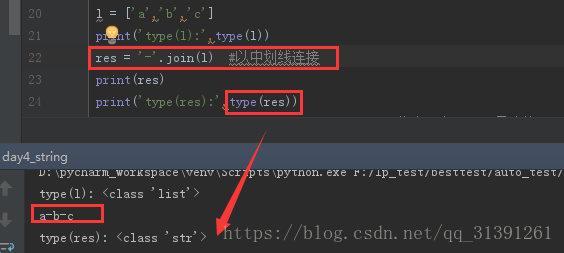
e.g.8 分割字符串
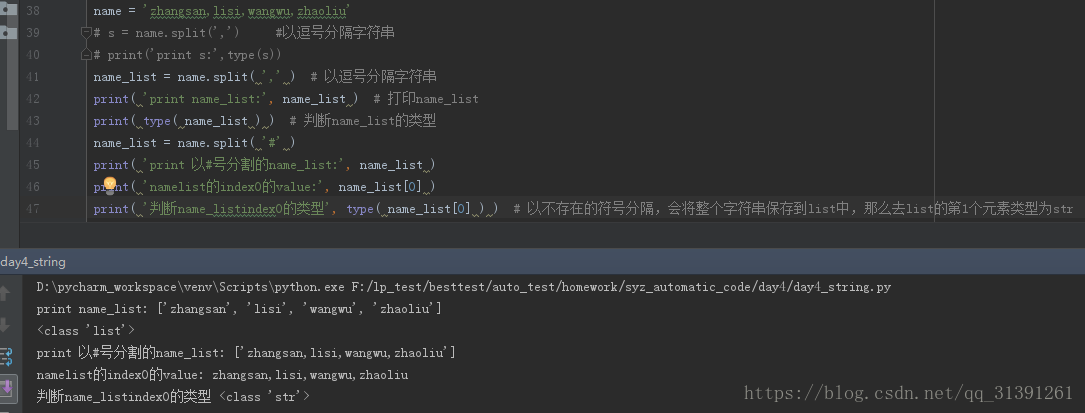
name = 'zhangsan,lisi,wangwu,zhaoliu' # s = name.split(',') #以逗号分隔字符串 # print('print s:',type(s)) name_list = name.split(',') #以逗号分隔字符串 print('print name_list:',name_list) #打印name_list print (type(name_list)) #判断name_list的类型 name_list = name.split('#') print('print 以#号分割的name_list:',name_list) print('namelist的index0的value:',name_list[0]) print('判断name_listindex0的类型',type(name_list[0]))
#以不存在的符号分隔,会将整个字符串保存到list中,那么去list的第1个元素类型为str
运行结果:
e.g.9 字符串格式化的2中方式
# 5.字符串格式化 + 连接 或 %s username = 'zhansan' sex = 'male' age = '18' addr = 'address' money = 'milion' cars = 'car' words = 'insert into user values ("%s","%s","%s","%s","%s","%s");'%(username,sex,age,addr,money,cars) print(words) # 5.字符串转换.format() 需要使用花括号{}先声明 username = 'zhansan' sex = 'male' age = '18' addr = 'address' money = 'milion' cars = 'car' sql = 'insert into user values("{name}","{sex}","{age}","{addr}","{money}","{cars}")' #不指定列 sql.format(name = username,sex = sex,age = age,addr = addr,money = money,cars = cars) print(sql.format(name = username,sex = sex,age = age,addr = addr,money = money,cars = cars))
运行结果:

e.g.10 字符串居中
print('XXXXXXXXXXXXXXXXXXXX'.center(20,'*')) #如果XXXX长度够20那么输入XXXX,不够20那么则将XXXX居中,2端补齐*
九、杂记
1.针对修改操作,数据变量的分为“可变变量”和“不可变变量” 2.可变变量:变量元素任意修改,如list、字典 3.不可变变量:变量元素不能被修改,如字符串,元组 4.pycharm运行脚本,某行代码出错后,其之后的代码将不再执行;e.g.1 5.元组和列表中没有update()方法 list(列表)使用update()的错误信息:AttributeError: 'list' object has no attribute 'update' tuple(列表)使用update()的错误信息:AttributeError: 'tuple' object has no attribute 'update' 6.python命令标识符规则:可以以一个字母字符或者一个下划线开头,接下来可以包括任意个字母字符、数字和/或者下划线。但是不允许有奇怪的字符如%$等 7.python大小写敏感,命名时一定要注意。标识符只有赋值后才能在代码中使用,未赋值就使用标识符python会指出NameError错误。 8.isinstance(),检查某个特定标识符是否包含某个特定类型的数据,如isinstance(a,list),即判断a是否为list类型的数据。 |
e.g.1
十、python中的一些判断规则
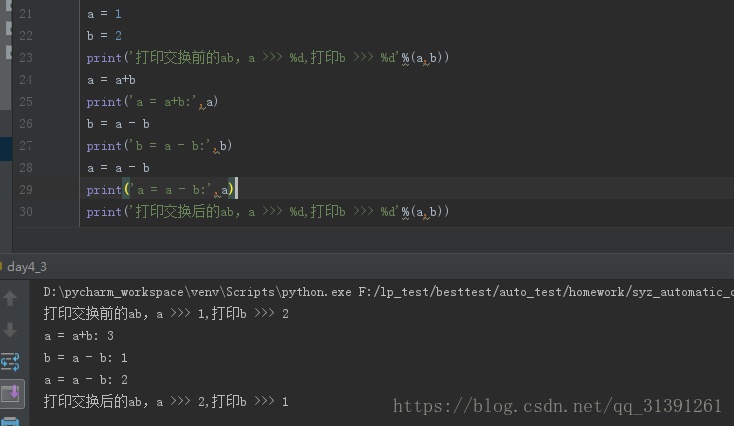
#1.非空即真,非0即真 判断对错返回的boolean类型 boolean e.g.1 如定义了一个列表,列表不是空列表那么则表示为真,列表,字符串,字典均使用 只要数值的绝对值大于0均为真 #2.多个变量一起定义赋相同的初始值 ,如: a = b = c = 0 e.g.2 #3.交换变量的方法 1)引入第三方变量 如:a = 1 b = 2 交换ab引入第三个变量c ,c = a a = b b = c 即可交换a , b的值 2)python交换2个变量,python底层实现的第三方交换 a,b = b,a 注:list也可以交换,但是整体交换,见:e.g.3 3)不引入第三方变量 a = 1 b =2 a = a+b # a= 3 b = a - b # b = 3-2 = 1 a = a - b # a = 3 -1 =2 交换完毕 见 e.g.4 |
e.g.1 #1_1.非空即真,非0,只要字符串不为空则为真 # name = input('please input your name:').strip() # a = [] #False # d = {} #False # c = 0 #False # f = tuple() #False # e = '' #False # print('a should be False:',bool(a)) # print('d should be False:',bool(d)) # print('c should be False:',bool(c)) # print('f should be False:',bool(f)) # print('e should be False:',bool(e)) # if name: #name里面是不是有内容 # print('right') # else: # print('wrong') #1_2.类型转换 bool() print('empty string is False:',bool('')) print('non empty string is True:',bool('a')) list_empty = [] list_nemp = [1] print('判断空列表的布尔值:',bool(list_empty)) print('判断非空列表的布尔值:',bool(list_nemp))
print('minus num is true or false?:',bool(-1))
e.g.2
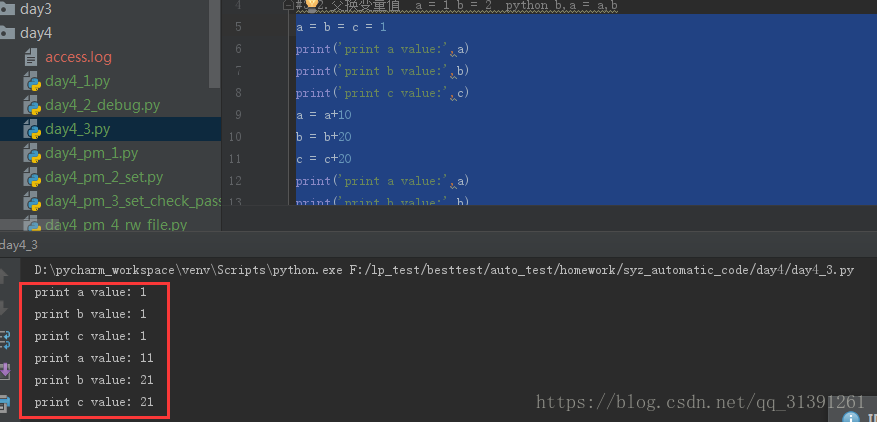
a = b = c = 1 #定义a,b,c3个变量并赋初始值为1 print('print a value:',a) print('print b value:',b) print('print c value:',c) a = a+10 b = b+20 c = c+20 print('print a value:',a) print('print b value:',b) print('print c value:',c)
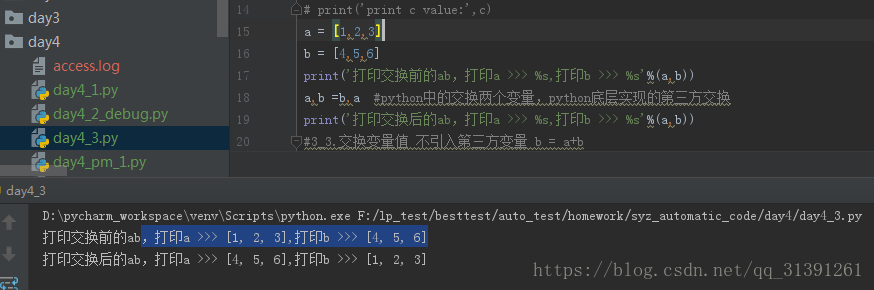
e.g.3 python交换2个变量
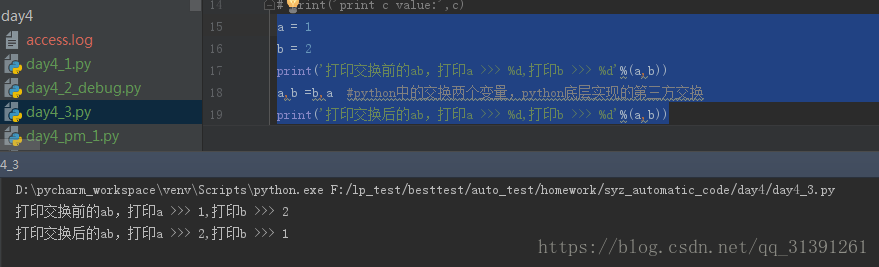
a = 1 b = 2 print('打印交换前的ab,打印a >>> %d,打印b >>> %d'%(a,b)) a,b =b,a #python中的交换两个变量,python底层实现的第三方交换 print('打印交换后的ab,打印a >>> %d,打印b >>> %d'%(a,b))
e.g.4 不借助第三方交换数据
十一、类型转换
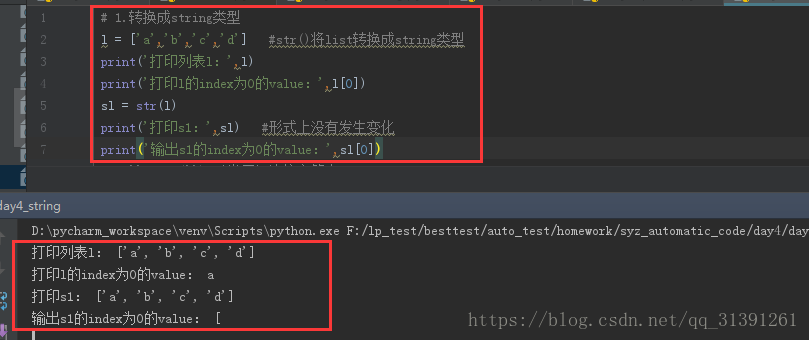
1.int() #转换成int类型 2.str() #转换成string类型 如:e.g.1 3.list() #转换成list(列表)类型 4.bool() # 转换成布尔类型 5.set() #转换成集合 |
e.g.1
十二、集合
1.集合天生去重,e.g.1 2.集合也是无序的 3.定义空集合,s = set() #即定义了一个空的集合 4.{}内部的元素以逗号分隔,带冒号的是集合,如e.g.2 5.集合的操作 ,如e.g.3 1)取交集(两个集合中相同的部分) a.使用 & 符号 b.使用方法intersection() 2)取并集 (把两个集合合并在一起,并且去重) a.使用 | 符号 b.使用方法union() |
3)取差集 (去掉A集合中A与B集合重合的部分)
a.使用 - 符号
b.使用方法difference()
4)对称差集 将2个集合合并然后去掉交集
a.使用 ^ 符号
b.使用方法symmetric_difference()
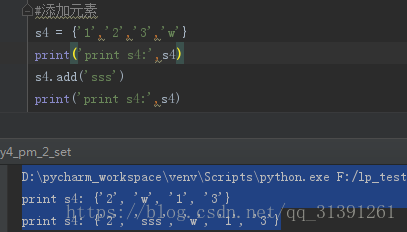
5)集合添加元素
方法:add (),如 set.add('value')
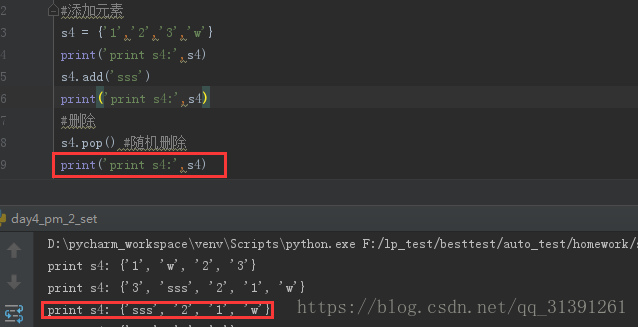
6)随机删除集合元素
方法:pop(),如set.pop()
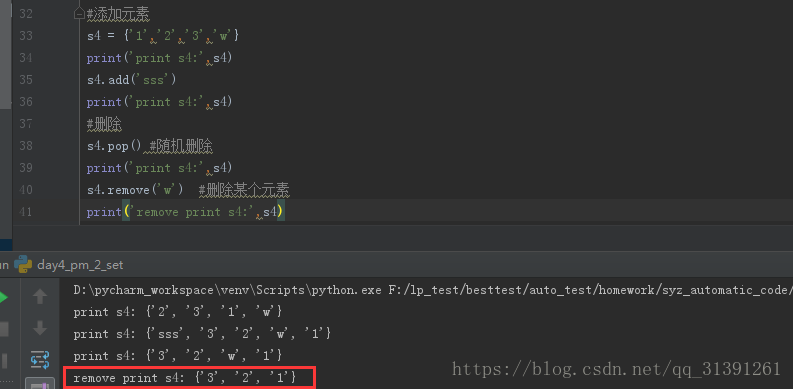
7)删除集合指定元素
方法:remove(value)
说明:若value在集合中不存在,此方法会报错,KeyError: 'value'
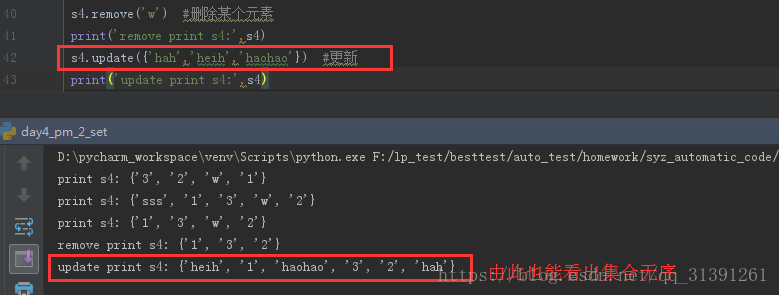
8)更新集合元素
方法:update(value)
方法解释:
def update(self, *args, **kwargs): # real signature unknown """ Update a set with the union of itself and others. """ pass
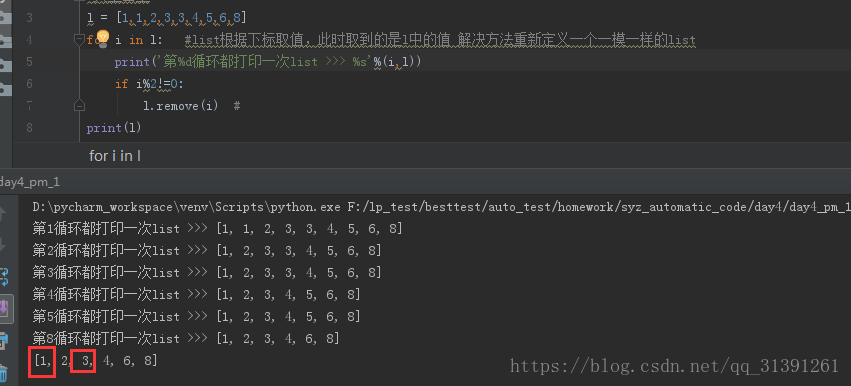
列表: l = [1,1,2,3,3,4,5,6,8] 1)直接使用for循环遍历list删除,如下所示: l = [1,1,2,3,3,4,5,6,8] for i in l: #list根据下标取值,此时取到的是l中的值 解决方法重新定义一个一模一样的list print('第%d循环都打印一次list >>> %s'%(i,l)) if i%2!=0: l.remove(i) # print(l) 问题:重复的奇数没有被删除
原因:list取值是根据下标取值的,第一次获取到的是index为0的数值即1,那么第二个1将往前移动,所以在删除第一个1之后,第二个1的下标变为了0,但此时下标的值已经变为1,所以第二个不会被判断到,后面的3也是同样的道理,那么如何解决呢,请看方法二和方法三,如下所示。 2)定义一个一模一样的list,循环遍历list2,删除list1(会牺牲一点内存空间) l1 = [1,1,2,3,3,4,5,6,8] print('print l1 memory address:',id(l1))#查看内存地址 l2 = [1,1,2,3,3,4,5,6,8] print('print l2 memory address:',id(l2))#查看内存地址 for i in l2: #list根据下标取值,此时取到的是l中的值 解决方法重新定义一个一模一样的list print('第%d循环i是list的值都打印一次list >>> %s'%(i,l1)) if i%2!=0: l1.remove(i) # print('print romve odd number:',l1) 运行结果: |
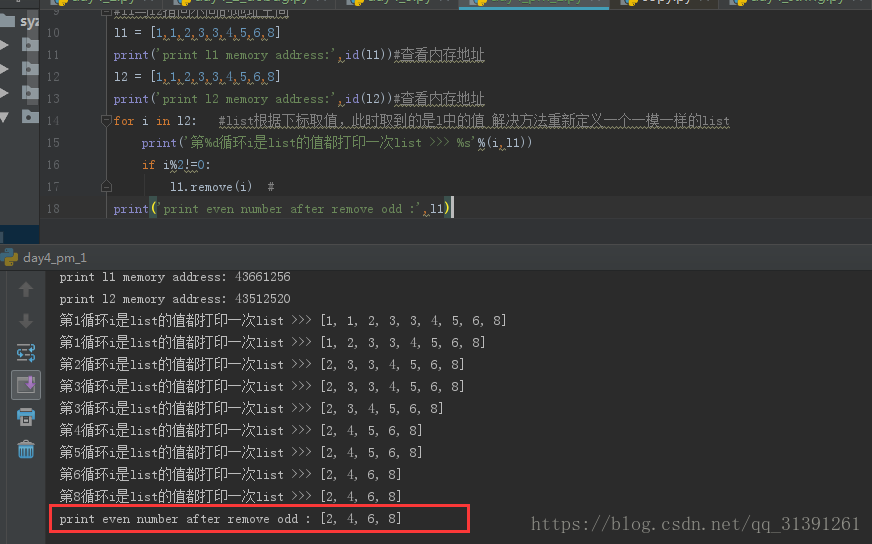
3)定义一个集合,遍历集合元素,删除list中的元素
 |
#1_2.将字符串转换成集合,并且去重 ss='1234342q231a38' sss = set(ss) print('打印集合sss:',sss) #s3 = {1,2,3,4,5} print(ss & s3) 类型不一致,错误信息:TypeError: unsupported operand type(s) for &: 'str' and 'set' s4 = {'1','2','3','w'} print('打印type(s4)',type(s4)) #取交集 & print(sss & s4) #方法一 print(sss.intersection(s4)) #方法二 #取并集 把两个集合合并在一起,并且去重 print('并集方法1:',sss | s4) #方法一 print('并集方法2:',sss.union(s4)) #方法二 #取差集 去掉A集合中A与B集合重合的部分 print('差集方法1:',sss - s4) #方法一 print('差集方法2:',sss.difference(s4)) #方法二 print('差集方法1:',s4 - sss) #方法一 #对称差集 将2个集合合并然后去掉交集 print('对称差集方法1:',sss ^ s4) #方法一 print('对称差集方法2:',sss.symmetric_difference(s4)) #方法二 添加元素
随机删除元素
删除某个元素
更新集合元素
|
十三、参考链接
牛牛杂货铺:http://www.nnzhp.cn/archives/162


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









