







文章目录
- PO
- OOP
- python
- RBAC
- Django
- DRFTODO
- FlaskTODO
- cookie session token
- Mysql
- ES
- 消息队列TODO
- redis
- 分布式 id (UUID)
- CDN
- 计算机网络
- 提高并发的方法
- linux 常用命令
- Docker 常用命令
- 常见安全漏洞
- nginx + uwsgi 部署
PO
-
面向过程(Procedure Oriented 简称PO :如C语言)
-
传统的面向过程的编程思想总结起来就八个字——自顶向下,逐步细化!实现步骤如下:
-
将要实现的功能描述为一个从开始到结束按部就班的连续的步骤(过程)
-
依次逐步完成这些步骤,如果某一步的难度较大,又可以将该步骤再次细化为若干个子步骤,以此类推,一直到结束得到想要的结果
-
程序的主体是函数,一个函数就是一个封装起来的模块,可以实现一定的功能,各个子步骤往往就是通过各个函数来完成的,从而实现代码的重用和模块
化编程
-
OOP
-
面向对象编程(英文Object Oriented Programming),所以也叫做OOP
-
早期的计算机编程是基于面向过程的,因为早期计算机处理的问题都不是很复杂,所以一个算法,一个数据结构就能够很好的解决当时的问题
但是随着计算机技术的发展,要处理的计算机问题越来越复杂。为了更好的解决这样的问题,就出现了一切皆对象的面向对象编程,把计算机中的东西比喻成
现实生活中的一样事物,一个对象,那现实生活中的对象都会有属性跟行为,这就对应着计算机中的属性和方法(函数)
把对象作为一个程序的基本单元,把数据和功能封装在里面,能够实现很好的复用性,灵活性和扩展性
-
OOP中2个基本概念
- 类和对象
- 类是描述如何创建一个对象的代码段,用来描述具有相同的属性和方法的对象的集合,它定义了该集合中每个对象所共有的属性和方法
- 对象是类的实例(Instance)
-
OOP的三大特征
-
封装
- 对类中成员属性和方法的保护 , 控制外界对内部成员的访问 , 修改 , 删除等操作
- 一个类就是一个封装了数据以及操作这些数据的代码的逻辑实体
-
多态
- 不同的子类对象 , 调用相同的父类方法 , 产生不同的执行结果
-
继承
-
一个类除了自身所拥有的属性方法之外 , 还获取了另外一个类的成员属性和方法
继承正如其名,继承上一代的东西。继承了某对象将拥有该对象的属性和方法,并且还可以自己拓展添加自己的属性和方法
可以增加代码的可重用性,拓展,修改
-
继承概念的实现方式有二类:实现继承与接口继承
- 实现继承是指直接使用父类的属性和方法而无需额外编码的能力
- 接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力
-
-
-
OOP的五大基本原则
-
单一职责原则SRP(Single Responsibility Principle)
- 一个类的功能要单一,不能包罗万象
-
开放封闭原则OCP(Open-Close Principle)
- 一个模块在扩展性方面应该是开放的而在更改性方面应该是封闭的
-
里式替换原则LSP(the Liskov Substitution Principle LSP)
- 子类应当可以替换父类并出现在父类能够出现的任何地方
-
依赖倒置原则DIP(the Dependency Inversion Principle DIP)
-
具体依赖抽象,上层依赖下层
假设B是较A低的模块,但B需要使用到A的功能,这个时候,B不应当直接使用A中的具体类
而应当由B定义一个抽象接口,并由A来实现这个抽象接口,B只使用这个抽象接口
这样就达到了依赖倒置的目的,B也解除了对A的依赖,反过来是A依赖于B定义的抽象接口
通过上层模块难以避免依赖下层模块,假如B也直接依赖A的实现,那么就可能造成循环依赖
一个常见的问题就是编译A模块时需要直接包含到B模块的cpp文件,而编译B时同样要直接包含到A的cpp文件
-
-
接口分离原则ISP(the Interface Segregation Principle ISP)
- 模块间要通过抽象接口隔离开,而不是通过具体的类强耦合起来
-
PO和OOP
面向过程
-
优点
- 性能比面向对象高,因为类调用时需要实例化,开销比较大
- 比较消耗资源;比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素
-
缺点
- 没有面向对象易维护、易复用、易扩展
面向对象
-
优点
- 易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
-
缺点
- 性能比面向过程低
区别
- 都可以实现代码重用和模块化编程,但是面对对象的模块化更深,数据更封闭,也更安全,因为面向对象的封装性更强
- 面对对象的思维方式更加贴近于现实生活,更容易解决大型的复杂的业务逻辑
- 从前期开发角度上来看,面对对象远比面向过程要复杂,但是从维护和扩展功能的角度上来看,面对对象远比面向过程要简单
python
闭包函数
-
简介
如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内部的我们叫他内函数。
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
闭包中外部函数返回的不是一个具体的值,而是一个函数。一般情况下,返回的函数会赋值给一个变量,这个变量可以在后面被继续执行调用。
-
作用
函数开头需要做一些额外工作,当多次调用该函数时,如果将额外工作的代码放在外部函数,就可以减少多次调用导致的不必要开销,提高程序的运行效率。
-
装饰器
例如工作中写了一个登录功能,我们想统计这个功能执行花了多长时间,可以用装饰器装饰这个登录模块,装饰器帮我们完成登录函数执行之前和之后取时间。
-
面向对象
经历了上面的分析,我们发现外函数的临时变量送给了内函数。类对象有好多类似的属性和方法,用类创建出来的对象都具有相同的属性方法
闭包也是实现面向对象的方法之一。在python当中虽然我们不这样用,在其他编程语言入比如avaScript中,经常用闭包来实现面向对象编程。
-
# 闭包函数,其中 exponent 称为自由变量
def nth_power(exponent):
def exponent_of(base):
return base ** exponent
return exponent_of # 返回值是 exponent_of 函数
square = nth_power(2) # 计算一个数的平方
cube = nth_power(3) # 计算一个数的立方
print(square(2)) # 计算 2 的平方
print(cube(2)) # 计算 2 的立方
# 运行结果为
4
8
"""
在上面程序中,外部函数 nth_power() 的返回值是函数 exponent_of(),而不是一个具体的数值。
需要注意的是,在执行完 square = nth_power(2) 和 cube = nth_power(3) 后,外部函数 nth_power() 的参数 exponent 会和内部函数 exponent_of 一起赋值给 squre 和 cube,这样在之后调用 square(2) 或者 cube(2) 时,程序就能顺利地输出结果,而不会报错说参数 exponent 没有定义。
"""
# Python闭包的__closure__属性
"""
闭包比普通的函数多了一个 __closure__ 属性,该属性记录着自由变量的地址。
当闭包被调用时,系统就会根据该地址找到对应的自由变量,完成整体的函数调用。
以 nth_power() 为例,当其被调用时,可以通过 __closure__ 属性获取自由变量(也就是程序中的 exponent 参数)存储的地址
"""
print(square.__closure__)
单例模式
- 实现方式: 1. 使用__new__; 2. 使用装饰器; 3. 使用元类(metaclass)
使用__new__

class Singleton(object):
def __new__(cls):
# 关键在于这,每一次实例化的时候,我们都只会返回这同一个 instance 对象
if not hasattr(cls, 'instance'):
cls.instance = super(Singleton, cls).__new__(cls)
return cls.instance
使用装饰器
def singleton(cls):
instances = {}
def getinstance(*args,**kwargs):
if cls not in instances:
instances[cls] = cls(*args,**kwargs)
return instances[cls]
return getinstance
@singleton
class MyClass:
a = 1
c1 = MyClass()
c2 = MyClass()
print(c1 == c2) # True
"""
在上面,我们定义了一个装饰器 singleton,它返回了一个内部函数 getinstance,该函数会判断某个类是否在字典 instances 中,如果不存在,则会将 cls 作为 key,cls(*args, **kw) 作为 value 存到instances 中,否则,直接返回 instances[cls]。
"""
使用元类
class Singleton2(type):
def __init__(self, *args, **kwargs):
self.__instance = None
super(Singleton2,self).__init__(*args, **kwargs)
def __call__(self, *args, **kwargs):
if self.__instance is None:
self.__instance = super(Singleton2,self).__call__(*args, **kwargs)
return self.__instance
class Foo(object):
__metaclass__ = Singleton2
#在代码执行到这里的时候,元类中的__new__方法和__init__方法其实已经被执行了,而不是在 Foo 实例化的时候执行。且仅会执行一次。
foo1 = Foo()
foo2 = Foo()
#_Singleton__instance': <__main__.Foo object at 0x100c52f10> 存在一个私有属性来保存属性
print (Foo.__dict__)
print (foo1 is foo2) # True
装饰器
闭包
-
要想了解装饰器,首先要了解闭包。闭包就是在函数中再嵌套一个函数,并且引用外部函数的变量,这就是闭包
def outer(x): def inner(y): return x + y return inner print(outer(6)(5)) # 11如代码所示,在outer函数内,又定义了一个inner函数,并且inner函数又引用了外部函数outer的变量x,这就是一个闭包
在输出时,outer(6)(5),第一个括号传进去的值返回inner函数,其实就是返回6 + y,所以再传第二个参数进去,就可以得到返回值,6 + 5
装饰器
-
装饰器就是一个闭包,装饰器是闭包的一种应用
简言之,python 装饰器就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数
使用 python 装饰器的好处就是在不用更改原函数的代码前提下给函数增加新的功能
# 装饰器给函数加上一个进入函数的debug模式,不用修改原函数代码就完成了这个功能 def debug(func): def wrapper(): print("[DEBUG]: enter {}()".format(func.__name__)) return func() return wrapper @debug def hello(): print("hello") hello() """ [DEBUG]: enter hello() hello """
带参数的装饰器
-
装饰器可以加参数,另外装饰的函数也是可以传参数的
def logging(level): # 装饰器可传入参数 def outwrapper(func): # 多一层方法嵌套 def wrapper(*args, **kwargs): # 使用 *args, **kwargs 适应所有参数 print("[{0}]: enter {1}()".format(level, func.__name__)) return func(*args, **kwargs) # 传递参数给真实调用的方法 return wrapper return outwrapper @logging(level="INFO") def hello(a, b, c): print(a, b, c) hello("hello,","good","morning") """ [INFO]: enter hello() hello, good morning """
类装饰器
-
装饰器不一定只用函数写,也可以使用类装饰器,用法与函数装饰器并没有太大区别,实质是使用了类方法中的call魔法方法来实现类的直接调用
类利用了
__init__和__call__方法__init__定义了装饰器的参数__call__会在调用logging对象的方法时触发- 可以这样理解:
t=logging(level="TEST")会调用__init__,而调用t(hello)会调用__call__(hello)
class logging(object): def __init__(self, func): self.func = func def __call__(self, *args, **kwargs): print("[DEBUG]: enter {}()".format(self.func.__name__)) return self.func(*args, **kwargs) @logging def hello(a, b, c): print(a, b, c) hello("hello,","good","morning") """ [DEBUG]: enter hello() hello, good morning """ -
类装饰器也是可以带参数的
class logging(object): def __init__(self, level): self.level = level def __call__(self, func): def wrapper(*args, **kwargs): print("[{0}]: enter {1}()".format(self.level, func.__name__)) return func(*args, **kwargs) return wrapper @logging(level="TEST") def hello(a, b, c): print(a, b, c) hello("hello,","good","morning") """ [TEST]: enter hello() hello, good morning """
装饰器使用场景
-
知道了如何实现一个装饰器,那么可以在不修改原方法的情况下,给方法增加额外的功能,这就非常适合给方法集成一些通用的逻辑
例如记录日志、记录执行耗时、本地缓存、路由映射等功能
-
记录日志
import logging from functools import wraps def logging(func): @wraps(func) def wrapper(*args, **kwargs): # 记录调用日志 logging.info('call method: %s %s %s', func.func_name, args, kwargs) return func(*args, **kwargs) return wrapper -
记录方法执行耗时
from functools import wraps def timeit(func): @wraps(func) def wrapper(*args, **kwargs): start = time.time() result = func(*args, **kwargs) duration = int(time.time() - start) # 统计耗时 print 'method: %s, time: %s' % (func.func_name, duration) return result return wrapper -
记录方法执行次数
from functools import wraps def counter(func): @wraps(func) def wrapper(*args, **kwargs): wrapper.count = wrapper.count + 1 # 累计执行次数 print 'method: %s, count: %s' % (func.func_name, wrapper.count) return func(*args, **kwargs) wrapper.count = 0 return wrapper -
本地缓存
from functools import wraps def localcache(func): cached = {} miss = object() @wraps(func) def wrapper(*args): result = cached.get(args, miss) if result is miss: result = func(*args) cached[args] = result return result return wrapper -
路由映射
class Router(object): def __init__(self): self.url_map = {} def register(self, url): def wrapper(func): self.url_map[url] = func return wrapper def call(self, url): func = self.url_map.get(url) if not func: raise ValueError('No url function: %s', url) return func() router = Router() @router.register('/page1') def page1(): return 'this is page1' @router.register('/page2') def page2(): return 'this is page2' print router.call('/page1') print router.call('/page2') -
除此之外,装饰器还能用在权限校验、上下文处理等场景中
总结
-
基于 Python 中一切皆对象的概念,我们理解了实现装饰器的本质:闭包
闭包可以传入一个方法对象,然后返回一个增强功能的方法对象,然后配合 Python 提供的
@语法糖,就可以实现一个装饰器 -
除了用函数实现一个装饰器之外,还可以通过 Python 的魔法方法,用类来实现一个装饰器
-
使用装饰器的常见场景,主要包括权限校验、日志记录、方法调用耗时、本地缓存、路由映射等功能
-
使用装饰器的好处是,可以把我们的业务逻辑和控制逻辑分离开,业务开发人员可以更好地关注业务逻辑
装饰器可以方便地实现对控制逻辑的统一定义,这种方式也遵循了设计模式中的单一职责
推导式
列表:
[val for val in Iterable]
lst = [i for i in range(1,101)]
集合:
{val for val in Iterable}
字典:
{k:v for k,v in Iterable}
# 枚举 ,将索引号和 iterable 中的值,一个一个拿出来配对组成元组放入迭代器中
enumerate(iterable,[start=0])
# 参数:
iterable : 可迭代性数据 (迭代器 , 容器类型数据 , 可迭代对象range)
start : 可以选择开始的索引号(默认从0开始索引)
# zip 拉链式,将多个 iterable 中的值,一个一个拿出来配对组成元组放入迭代器中
zip(iterable, ... ...)
# 参数:
iterable : 可迭代性数据 (迭代器 , 容器类型数据 , 可迭代对象range)
# zip 形成字典推导式 变成字典
lst1 = ["苏大强","小明","小花","小蔡","小新"]
lst2 = ["苏明成","小小明","大花","小保姆"]
dic = {k:v for k,v in zip(lst1,lst2)}
匿名函数
-
匿名函数 lambda
是指一类无需定义标识符(函数名)的函数或子程序。lambda 函数可以接收任意多个参数 (包括可选参数) 并且返回单个表达式的值。
-
语法
lambda [arg1 [,arg2,.....argn]]: expression lambda x, y: x*y # 函数输入是x和y,输出是它们的积x*y lambda:None # 函数没有输入参数,输出是None lambda *args: sum(args) # 输入是任意个数参数,输出是它们的和(隐性要求输入参数必须能进行算术运算) lambda **kwargs: 1 # 输入是任意键值对参数,输出是1冒号前是参数,可以有多个,用逗号隔开,冒号右边的为表达式(只能为一个)。其实lambda返回值是一个函数的地址,也就是函数对象。
高阶函数
- 定义 : 能够把函数当成参数传递的就是高阶函数
map
# 语法:
map(func,Iterable)
# 功能:
处理数据
把可迭代型数据中的数据一个一个拿出来,放到到函数中做处理,把处理之后的结果放到迭代器当中,最后返回迭代器
# 参数:
func : 自定义函数
Iterable: 可迭代型数据(容器类型数据,range对象,迭代器)
# 返回值:
迭代器
# 1. lst = ["1","2","3","4"] => [1,2,3,4]
lst = ["1","2","3","4"]
# 常规写法
lst_new = []
for i in lst:
lst_new.append(int(i))
print(lst_new)
# map 改造
it = map(int,lst)
"""
代码解析:
先把"1"扔到int当中做处理,将强转后的结果扔到迭代器中
然后把"2"扔到int当中做处理,将强转后的结果扔到迭代器中
然后把"3"扔到int当中做处理,将强转后的结果扔到迭代器中
然后把"4"扔到int当中做处理,将强转后的结果扔到迭代器中
最终返回迭代器
"""
# 获取迭代器中的数据
# 方法1. next
res = next(it)
print(res)
# 方法2. for
for i in it:
print(i)
# 方法3. for + next
for i in range(4):
res = next(it)
print(res)
# list强转
print(list(it))
# 2. [1,2,3,4] => [2,8,24,64]
lst = [1,2,3,4]
"""
1 * 2^1 = 2
2 * 2^2 = 8
3 * 2^3 = 24
4 * 2^4 = 64
"""
# 常规写法
lst_new = []
for i in lst:
res = i << i
lst_new.append(res)
print(lst_new)
# map 改造
"""参数和返回值return一定要写"""
def func(n):
return n << n
lst = [1,2,3,4]
it = map(func,lst)
print(list(it))
# lambda + map
it = map(lambda n : n << n,lst)
print(list(it))
filter
# 语法:
filter(func,Iterable)
# 功能:
过滤数据
return True 当前这个数据保留
return False 当前这个数据舍弃
# 参数:
func : 自定义函数
Iterable: 可迭代型数据(容器类型数据,range对象,迭代器)
# 返回值:
迭代器
lst = [1,2,3,4,5,6,7,8,9,10]
# 常规写法
lst_new = []
for i in lst:
if i % 2 == 0:
lst_new.append(i)
print(lst_new)
# filter 改写
def func(i):
if i % 2 == 0:
return True
else:
return False
it = filter(func,lst)
# 1.next
res = next(it)
print(res)
# 2. for
for i in it:
print(i)
# 3. for + next
it = filter(func,lst)
for i in range(5):
res = next(it)
print(res)
# 4. list 强转
res = list(it)
print(res)
# filter + lambda 改写
it = filter(lambda i : True if i % 2 == 0 else False , lst)
print(list(it))
reduce
# 语法:
reduce(func,Iterable)
# 功能:
计算数据
先把可迭代型数据中的前两个值拿出来,放到函数当中做运算,把计算结果和可迭代型数据中的第三个元素再扔进函数当中做运算
再把结果算出来,和第四个元素做运算,以此类推,直到所有结果运算完毕,返回该结果
# 参数:
func : 自定义函数
Iterable: 可迭代型数据(容器类型数据,range对象,迭代器)
# 返回值:
计算之后的结果
# 从 ... 导入 ...
from functools import reduce
# 练习1
lst = [5,4,8,8] # => 整型 5488
def func(x,y):
return x*10 + y
res = reduce(func,lst)
print(res , type(res))
"""
代码解析 :
先拿出5和4两个元素,扔到 func 当中做运算,结果是54
再拿54和8两个元素,扔到 func 当中做运算,结果是548
再拿548和8两个元素,扔到 func 当中做运算,结果5488
返回最终结果 : 5488 程序结束
"""
# reduce + lambda 改造
res = reduce(lambda x,y : x*10 + y , lst)
print(res)
# 练习2
""" "789" => 789 禁止使用int强转 """
def func(x,y):
return x*10 + y
strvar = "789"
res = reduce(func,list(strvar))
print(res , type(res))
"""
代码运行结果:
77777777778 * 10 + 9
777777777787777777777877777777778777777777787777777777877777777778777777777787777777777877777777778777777777789 <class 'str'>
"""
# "789" -> 数字7 数字8 数字9
def func1(x,y):
return x*10 + y
def func2(n):
dic = {"0":0,"1":1,"2":2,"3":3,"4":4,"5":5,"6":6,"7":7,"8":8,"9":9}
return dic[n]
it = map(func2,"789") # [7,8,9]
res = reduce(func1,it)
print(res , type(res))
sorted
# 功能:
排序
# 语法:
sorted( Iterable , key=函数 , reverse=False )
# 参数:
Iterable : 可迭代型数据(容器类型数据,range对象,迭代器)
key : 自定义函数 或 内置函数
reverse : 代表升序或者降序,默认是升序(从小到大排序) reverse=False
# 返回值:
排序后的结果
# 1. 默认是从小到大排序
lst = [1,2,3,4,5,-65,-100,-3,-7,22]
res = sorted(lst)
# 2. reverse 从大到小排序
res = sorted(lst,reverse=True)
# 3. 指定函数进行排序
# 按照绝对值排序 abs
lst = [-65,-8,4,-77,9,-5,6]
res = sorted(lst,key=abs)
# 4. 使用自定义函数进行排序
lst = [23,78,64,52,85]
def func(n):
return n % 10
lst = sorted(lst,key=func)
# 5. 使用 `sorted` 函数按年龄进行排序
student_tuples = [
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
]
student_tuples_sort = sorted(student_tuples, key=lambda x:x[2])
sorted 和 sort 之间的区别
- sorted 可以排序一切容器类型数据 , sort 只能排列表
- sorted 返回的是新列表 , sort 是基于原有的列表进行修改(推荐使用sorted)
偏函数
官方解释
functools.partial(func, *args, **keywords)
Return a new partial object which when called will behave like func called with the positional arguments args and keyword arguments keywords.
If more arguments are supplied to the call, they are appended to args. If additional keyword arguments are supplied, they extend and override keywords.
Roughly equivalent to:
-
返回一个偏函数对象,这个对象和 func 一样,可以被调用,同时在调用的时候可以指定位置参数 (*args) 和 关键字参数(**kwargs)
如果有更多的位置参数提供调用,会被附加到 args 中
如果有额外的关键字参数提供,将会扩展并覆盖原有的关键字参数
# 定义一个函数,接受三个参数
def partial(func, *args, **keywords):
def newfunc(*fargs, **fkeywords):
newkeywords = keywords.copy()
newkeywords.update(fkeywords)
return func(*args, *fargs, **newkeywords)
newfunc.func = func
newfunc.args = args
newfunc.keywords = keywords
return newfunc
定义
partial_func = functools.partial(func, *args, **keywords)
# partial 接受三个参数
func: 需要被扩展的函数,返回的函数其实是一个类 func 的函数
*args: 需要被固定的位置参数
**kwargs: 需要被固定的关键字参数
# 如果在原来的函数 func 中关键字参数不存在,将会扩展,如果存在,则会覆盖
def add(*args, **kwargs):
# 打印位置参数
for n in args:
print(n)
print("-"*20)
# 打印关键字参数
for k, v in kwargs.items():
print('%s:%s' % (k, v))
# 暂不做返回,只看下参数效果,理解 partial 用法
# 普通调用
add(1, 2, 3, v1=10, v2=20)
"""
1
2
3
--------------------
v1:10
v2:20
"""
# partial
add_partial = partial(add, 10, k1=10, k2=20)
add_partial(1, 2, 3, k3=20)
"""
10
1
2
3
--------------------
k1:10
k2:20
k3:20
"""
add_partial(1, 2, 3, k1=20)
"""
10
1
2
3
--------------------
k1:20
k2:20
"""
作用
-
和装饰器一样,它可以扩展函数的功能,但又不完成等价于装饰器
通常应用的场景是当我们要频繁调用某个函数时,其中某些参数是已知的固定值,通常我们可以调用这个函数多次,但这样看上去似乎代码有些冗余,而偏函
数的出现就是为了很少的解决这一个问题
场景
-
partial 有个专有名词,叫做科里化,实际上python的对象方法绑定就是用类似partial的方式完成的,对象在生成的时候,方法和对象是无关的,对象方法在
new的时候通过partial绑定在对象上,所以python永远不愿意取消self的方法参数,本身就在说明这点
而且你的对象同时也可以包含和生成类无关的对象方法,说明对象方法在内存中和类定义是无关的
事实上python中的类更像是一种生成对象的原型工厂,方法是预编译后绑定在对象上的,而不像是一个通常面向对象的编程语言
-
flask 有 redirect(path, code=302),假如要写十几个 if 语句,全要加 302, 会很麻烦。但是 redirect_302 = partial(redirect, code=302) 后就变成单参函数了
-
flask 利用 local() 为线程或协程开辟资源空间,并用 stack 栈存储维护,内部再使用偏函数 functools.partial(func1, 10) 拆分各属性值
-
flask LocalProxy 代理对象使用偏函数
LocalProxy就是flask框架的werkzeug工具实现的一个代理对象,它接收一个可调用的无参数函数作为参数,内部实现了object对象所有的魔法方法的重写,
理论上可以代理任何的对象,不管这个对象的结构是怎么样的
_request_ctx_err_msg = '''\ Working outside of request context. This typically means that you attempted to use functionality that needed an active HTTP request. Consult the documentation on testing for information about how to avoid this problem.\ ''' _app_ctx_err_msg = '''\ Working outside of application context. This typically means that you attempted to use functionality that needed to interface with the current application object in some way. To solve this, set up an application context with app.app_context(). See the documentation for more information.\ ''' def _lookup_req_object(name): top = _request_ctx_stack.top if top is None: raise RuntimeError(_request_ctx_err_msg) return getattr(top, name) def _lookup_app_object(name): top = _app_ctx_stack.top if top is None: raise RuntimeError(_app_ctx_err_msg) return getattr(top, name) def _find_app(): top = _app_ctx_stack.top if top is None: raise RuntimeError(_app_ctx_err_msg) return top.app # context locals _request_ctx_stack = LocalStack() _app_ctx_stack = LocalStack() current_app = LocalProxy(_find_app) request = LocalProxy(partial(_lookup_req_object, 'request')) session = LocalProxy(partial(_lookup_req_object, 'session')) g = LocalProxy(partial(_lookup_app_object, 'g'))
实例
-
100 加任意数的和
# 常规做法 """ 两种做法都会存在有问题: 第一种,100这个固定值会返回出现,代码总感觉有重复 第二种,就是当我们想要修改 100 这个固定值的时候,我们需要改动 add 这个方法 """ # 一 def add(*args): return sum(args) print(add(1, 2, 3) + 100) print(add(5, 5, 5) + 100) # 二 def add(*args): # 对传入的数值相加后,再加上100返回 return sum(args) + 100 print(add(1, 2, 3)) # 106 print(add(5, 5, 5)) # 115 # parital from functools import partial def add(*args): return sum(args) add_100 = partial(add, 100) print(add_100(1, 2, 3)) # 106 add_101 = partial(add, 101) print(add_101(1, 2, 3)) # 107
魔法方法
构造方法
-
最为熟知的基本的魔法方法就是 _init_ ,可以用它来指明一个对象初始化的行为
当调用 x = SomeClass() 的时候, _init_ 并不是第一个被调用的方法
事实上,第一个被调用的是 _new_ ,这个 方法才真正地创建了实例
当这个对象的生命周期结束的时候,_del_ 会被调用
-
_new_(cls,[…)
- _new_ 是对象实例化时第一个调用的方法,它只取 cls 参数,并把其他参数传给 _init_
- _new_ 很少使用,但是也有它适合的场景,尤其是当类继承自一个像元组或者字符串这样不经常改变的类型的时候
-
_init_(self,[…])
- 类的初始化方法
- 它获取任何传给构造器的参数(比如我们调用 x = SomeClass(10, ‘foo’) , _init_ 就会接到参数 10 和 ‘foo’
-
_del_(self)
-
_new_ 和 _init_ 是对象的构造器, _del_ 是对象的销毁器
-
它并非实现了语句 del x (因此该语句不等同于 x.del())
-
而是定义了当对象被垃圾回收时的行为
当对象需要在销毁时做一些处理的时候这个方法很有用,比如 socket 对象、文件对象
但是需要注意的是,当Python解释器退出但对象仍然存活的时候, _del_ 并不会执行
-
可调用对象
-
在Python中,函数是一等的对象
这意味着它们可以像其他任何对象一样被传递到函数和方法中,这是一个十分强大的特性
-
_call_(self, [args…])
允许类的一个实例像函数那样被调用
注意 _call_ 可以有多个参数,这代表你可以像定义其他任何函数一样,定义 _call_
class Entity: '''表示一个实体的类,调用它的实例,可以更新实体的位置''' def __init__(self, size, x, y): self.x, self.y = x, y self.size = size def __call__(self, x, y): self.x, self.y = y, x
深浅拷贝
-
_copy_(self)
定义对类的实例使用 copy.copy() 时的行为
copy.copy() 返回一个对象的浅拷贝,这意味着拷贝出的实例是全新的,然而里面的数据全都是引用的
也就是说,对象本身是拷贝的,但是它的数据还是引用的(所以浅拷贝中的数据更改会影响原对象)
-
_deepcopy_(self, memodict=)
定义对类的实例使用 copy.deepcopy() 时的行为
copy.deepcopy() 返回一个对象的深拷贝,这个对象和它的数据全都被拷贝了一份
memodict 是一个先前拷贝对象的缓存,它优化了拷贝过程,而且可以防止拷贝递归数据结构时产生无限递归
当你想深拷贝一个单独的属性时,在那个属性上调用 copy.deepcopy() ,使用 memodict 作为第一个参数
上下文管理器
- _enter_() 和 _exit_() 方法的对象都可称之为上下文管理器,上下文管理器对象可以使用 with 关键字。显然,文件(file)对象也实现了上下文管理器
-
_enter_ 和 __ exit__
-
当 with 对象时, 就会触发这个对象的**_enter_**方法
-
当离开 with 代码块, 会触发这个对象的 __ exit__ 方法
-
with open('foo.txt') as bar: pass
-
-
示例(可关闭的连接)
class Closer: '''一个上下文管理器,可以在with语句中使用close()自动关闭对象''' def __init__(self, obj): self.obj = obj def __enter__(self, obj): return self.obj # 绑定到目标 def __exit__(self, exception_type, exception_value, traceback): try: self.obj.close() except AttributeError: # obj不是可关闭的 print 'Not closable.' return True # 成功地处理了异常 # 一个 Closer 在实际使用中的例子,使用一个FTP连接来演示 >>> from magicmethods import Closer >>> from ftplib import FTP >>> with Closer(FTP('ftp.somesite.com')) as conn: ... conn.dir() ... # 为了简单,省略了某些输出 >>> conn.dir() # 很长的 AttributeError 信息,不能使用一个已关闭的连接 >>> with Closer(int(5)) as i: ... i += 1 ... Not closable. >>> i 6
描述符
简介
-
在 Python 中,**允许把一个类属性,托管给一个类,这个属性就是一个「描述符」。**换句话说,「描述符」是一个「绑定行为」的属性
也可以把「描述符」理解为:对象的属性不再是一个具体的值,而是交给了一个方法去定义
# 在类 A 中定义了一个类属性 x,然后打印它的值
class A:
x = 10
print(A.x) # 10
# 除了直接定类属性之外,还可以这样定义一个类属性:
# 类属性 x 不再是一个具体的值,而是一个类 Ten。Ten 中定义了一个 __get__ 方法,返回具体的值
class Ten:
def __get__(self, obj, objtype=None):
return 10
class A:
x = Ten() # 属性换成了一个类
print(A.x) # 10
# 可以根据不同的条件,在方法内给属性赋予不同的值
# age 类属性被另一个类托管了,在这个类的 __get__ 中,它会根据 Person 类的属性 name,决定 age 是什么值
# 通过描述符的使用,我们可以轻易地改变一个类属性的定义方式
class Age:
def __get__(self, obj, objtype=None):
if obj.name == 'zhangsan':
return 20
elif obj.name == 'lisi':
return 25
else:
return ValueError("unknow")
class Person:
age = Age()
def __init__(self, name):
self.name = name
p1 = Person('zhangsan')
print(p1.age) # 20
p2 = Person('lisi')
print(p2.age) # 25
p3 = Person('wangwu')
print(p3.age) # unknow
协议
-
一个类属性想要托管给一个类,这个类内部实现的方法不能是随便定义的,它必须遵守「描述符协议」,也就是要实现以下几个方法:
-
__get__(self, obj, type=None) -> value -
__set__(self, obj, value) -> None -
__delete__(self, obj) -> None
只要是实现了以上几个方法的其中一个,那么这个类属性就可以称作描述符
-
-
描述符又可以分为「数据描述符」和「非数据描述符」:
- 只定义了
__get___,叫做非数据描述符 - 除了定义
__get__之外,还定义了__set__或__delete__,叫做数据描述符
- 只定义了
# coding: utf8
class Age:
def __init__(self, value=20):
self.value = value
def __get__(self, obj, type=None):
print('call __get__: obj: %s type: %s' % (obj, type))
return self.value
def __set__(self, obj, value):
if value <= 0:
raise ValueError("age must be greater than 0")
print('call __set__: obj: %s value: %s' % (obj, value))
self.value = value
class Person:
age = Age()
def __init__(self, name):
self.name = name
p1 = Person('zhangsan')
print(p1.age)
# call __get__: obj: <__main__.Person object at 0x1055509e8> type: <class '__main__.Person'>
# 20
print(Person.age)
# call __get__: obj: None type: <class '__main__.Person'>
# 20
p1.age = 25
# call __set__: obj: <__main__.Person object at 0x1055509e8> value: 25
print(p1.age)
# call __get__: obj: <__main__.Person object at 0x1055509e8> type: <class '__main__.Person'>
# 25
p1.age = -1
# ValueError: age must be greater than 0
-
上述示例中,类属性
age是一个描述符,它的值取决于Age类从输出结果来看,当我们获取或修改
age属性时,调用了Age的__get__和__set__方法:- 当调用
p1.age时,__get__被调用,参数obj是Person实例,type是type(Person) - 当调用
Person.age时,__get__被调用,参数obj是None,type是type(Person) - 当调用
p1.age = 25时,__set__被调用,参数obj是Person实例,value是25 - 当调用
p1.age = -1时,__set__没有通过校验,抛出ValueError
其中,调用
__set__传入的参数,比较容易理解,但对于__get__方法,通过类或实例调用,传入参数是不同的,这就需要了解描述符的工作原理 - 当调用
工作原理
-
要解释描述符的工作原理,首先我们需要先从属性的访问说起。
在开发时,不知道你有没有想过这样一个问题:通常我们写这样的代码
a.b,其背后到底发生了什么?这里的
a和b可能存在以下情况:- a 可能是一个类,也可能是一个实例,我们这里统称为对象
- b 可能是一个属性,也可能是一个方法,方法其实也可以看做是类的属性
-
无论是以上哪种情况,在 Python 中,都有一个统一的调用逻辑:
- 先调用
__getattribute__尝试获得结果 - 如果没有结果,调用
__getattr__
- 先调用
-
用代码表示:
def getattr_hook(obj, name): try: return obj.__getattribute__(name) except AttributeError: if not hasattr(type(obj), '__getattr__'): raise return type(obj).__getattr__(obj, name) -
这里需要重点关注一下
__getattribute__,因为它是所有属性查找的入口,它内部实现的属性查找顺序是这样的:- 要查找的属性,在类中是否是一个描述符
- 如果是描述符,再检查它是否是一个数据描述符
- 如果是数据描述符,则调用数据描述符的
__get__ - 如果不是数据描述符,则从
__dict__中查找 - 如果
__dict__中查找不到,再看它是否是一个非数据描述符 - 如果是非数据描述符,则调用非数据描述符的
__get__ - 如果也不是一个非数据描述符,则从类属性中查找
- 如果类中也没有这个属性,抛出
AttributeError异常
-
用代码表示:
# 获取一个对象的属性 def __getattribute__(obj, name): null = object() # 对象的类型 也就是实例的类 objtype = type(obj) # 从这个类中获取指定属性 cls_var = getattr(objtype, name, null) # 如果这个类实现了描述符协议 descr_get = getattr(type(cls_var), '__get__', null) if descr_get is not null: if (hasattr(type(cls_var), '__set__') or hasattr(type(cls_var), '__delete__')): # 优先从数据描述符中获取属性 return descr_get(cls_var, obj, objtype) # 从实例中获取属性 if hasattr(obj, '__dict__') and name in vars(obj): return vars(obj)[name] # 从非数据描述符获取属性 if descr_get is not null: return descr_get(cls_var, obj, objtype) # 从类中获取属性 if cls_var is not null: return cls_var # 抛出 AttributeError 会触发调用 __getattr__ raise AttributeError(name) -
到这里我们可以看到,在一个对象中查找一个属性,都是先从
__getattribute__开始的在
__getattribute__中,它会检查这个类属性是否是一个描述符,如果是一个描述符,那么就会调用它的__get__方法但具体的调用细节和传入的参数是下面这样的:
# 如果 a 是一个实例,调用细节为: type(a).__dict__['b'].__get__(a, type(a)) # 如果 a 是一个类,调用细节为: a.__dict__['b'].__get__(None, a)
数据和非数据描述符
-
定义的区别:
- 只定义了
__get___,叫做非数据描述符 - 除了定义
__get__之外,还定义了__set__或__delete__,叫做数据描述符
此外,我们从上面描述符调用的顺序可以看到,在对象中查找属性时,数据描述符要优先于非数据描述符调用
在之前的例子中,我们定义了
__get__和__set__,所以那些类属性都是数据描述符。 - 只定义了
-
非数据描述符 示例:
class A: def __init__(self): self.foo = 'abc' def foo(self): return 'xyz' print(A().foo) """ 这段代码定义了一个相同名字的属性和方法 foo,如果现在执行 A().foo,会输出答案 abc,这就和非数据描述符有关系了 """ # 执行 dir(A.foo),观察结果 print(dir(A.foo)) # [... '__get__', '__getattribute__', ...] """ A 的 foo 方法其实实现了 __get__,在上面的分析已经得知: 只定义 __get__ 方法的对象,它其实是一个非数据描述符,也就是说,在类中定义的方法,其实本身就是一个非数据描述符 所以,在一个类中,如果存在相同名字的属性和方法,按照上面所讲的 __getattribute__ 中查找属性的顺序,这个属性就会优先从实例中获取,如果实例中不存在,才会从非数据描述符中获取,所以在这里优先查找的是实例属性 foo 的值 """
总结关于描述符的相关知识点:
- 描述符必须是一个类属性
__getattribute__是查找一个属性(方法)的入口__getattribute__定义了一个属性(方法)的查找顺序:数据描述符、实例属性、非数据描述符、类属性- 如果我们重写了
__getattribute__方法,会阻止描述符的调用 - 所有方法其实都是一个非数据描述符,因为它定义了
__get__
使用场景-属性校验器
-
用描述符实现了一个属性校验器
class Validator: def __init__(self): self.data = {} def __get__(self, obj, objtype=None): return self.data[obj] def __set__(self, obj, value): # 校验通过后再赋值 self.validate(value) self.data[obj] = value def validate(self, value): pass -
定义两个校验类,继承
Validator,然后实现自己的校验逻辑class Number(Validator): def __init__(self, minvalue=None, maxvalue=None): super(Number, self).__init__() self.minvalue = minvalue self.maxvalue = maxvalue def validate(self, value): if not isinstance(value, (int, float)): raise TypeError(f'Expected {value!r} to be an int or float') if self.minvalue is not None and value < self.minvalue: raise ValueError( f'Expected {value!r} to be at least {self.minvalue!r}' ) if self.maxvalue is not None and value > self.maxvalue: raise ValueError( f'Expected {value!r} to be no more than {self.maxvalue!r}' ) class String(Validator): def __init__(self, minsize=None, maxsize=None): super(String, self).__init__() self.minsize = minsize self.maxsize = maxsize def validate(self, value): if not isinstance(value, str): raise TypeError(f'Expected {value!r} to be an str') if self.minsize is not None and len(value) < self.minsize: raise ValueError( f'Expected {value!r} to be no smaller than {self.minsize!r}' ) if self.maxsize is not None and len(value) > self.maxsize: raise ValueError( f'Expected {value!r} to be no bigger than {self.maxsize!r}' ) -
使用这个校验类
class Person: # 定义属性的校验规则 内部用描述符实现 name = String(minsize=3, maxsize=10) age = Number(minvalue=1, maxvalue=120) def __init__(self, name, age): self.name = name self.age = age # 属性符合规则 p1 = Person('zhangsan', 20) print(p1.name, p1.age) # 属性不符合规则 p2 = person('a', 20) # ValueError: Expected 'a' to be no smaller than 3 p3 = Person('zhangsan', -1) # ValueError: Expected -1 to be at least 1 "当对 Person 实例进行初始化时,就可以校验这些属性是否符合预定义的规则了"
function与method
-
在开发时经常看到的
function、unbound method、bound method,它们之间的区别代码示例
class A: def foo(self): return 'xyz' print(A.__dict__['foo']) # <function foo at 0x10a790d70> print(A.foo) # <unbound method A.foo> print(A().foo) # <bound method A.foo of <__main__.A object at 0x10a793050>> -
从结果可以看出它们的区别:
-
function准确来说就是一个函数,并且它实现了__get__方法,因此每一个function都是一个非数据描述符,而在类中会把function放到__dict__中存储 -
当
function被实例调用时,它是一个bound method -
当
function被类调用时, 它是一个unbound method
-
-
function是一个非数据描述符而
bound method和unbound method的区别就在于调用方的类型是什么如果是一个实例,那么这个
function就是一个bound method,否则它是一个unbound method
property/staticmethod/classmethod
-
property、staticmethod、classmethod 这些装饰器的实现,默认是 C 来实现的
其实,也可以直接利用 Python 描述符的特性来实现这些装饰器
-
property的 Python 版实现class property: def __init__(self, fget=None, fset=None, fdel=None, doc=None): self.fget = fget self.fset = fset self.fdel = fdel self.__doc__ = doc def __get__(self, obj, objtype=None): if obj is None: return self.fget if self.fget is None: raise AttributeError(), "unreadable attribute" return self.fget(obj) def __set__(self, obj, value): if self.fset is None: raise AttributeError, "can't set attribute" return self.fset(obj, value) def __delete__(self, obj): if self.fdel is None: raise AttributeError, "can't delete attribute" return self.fdel(obj) def getter(self, fget): return type(self)(fget, self.fset, self.fdel, self.__doc__) def setter(self, fset): return type(self)(self.fget, fset, self.fdel, self.__doc__) def deleter(self, fdel): return type(self)(self.fget, self.fset, fdel, self.__doc__) -
staticmethod的 Python 版实现class staticmethod: def __init__(self, func): self.func = func def __get__(self, obj, objtype=None): return self.func -
classmethod的 Python 版实现class classmethod: def __init__(self, func): self.func = func def __get__(self, obj, klass=None): if klass is None: klass = type(obj) def newfunc(*args): return self.func(klass, *args) return newfunc -
由此可见,通过描述符可以实现强大而灵活的属性管理功能,对于一些要求属性控制比较复杂的场景,可以选择用描述符来实现
总结
-
一个类属性是可以托管给另外一个类的,这个类如果实现了描述符协议方法,那么这个类属性就是一个描述符
此外,描述符又可以分为数据描述符和非数据描述符
-
分析获取一个属性的过程,一切的入口都在
__getattribute__中,这个方法定义了寻找属性的顺序其中实例属性优先于数据描述符调用,数据描述符要优先于非数据描述符调用
-
方法其实就是一个非数据描述符,如果在类中定义了相同名字的实例属性和方法,按照
__getattribute__中的属性查找顺序,实例属性优先访问 -
分析了
function和method的区别,以及使用 Python 描述符也可以实现property、staticmethod、classmethod装饰器 -
Python 描述符提供了强大的属性访问控制功能,我们可以在需要对属性进行复杂控制的场景中去使用它
类的表示
-
使用字符串来表示类是一个相当有用的特性
在Python中有一些内建方法可以返回类的表示,相对应的,也有一系列魔法方法可以用来自定义在使用这些内建函数时类的行为
-
_str_(self)
定义对类的实例调用 str() 时的行为
-
_repr_(self)
定义对类的实例调用 repr() 时的行为。 str() 和 repr() 最主要的差别在于“目标用户”
repr() 的作用是产生机器可读的输出(大部分情况下,其输出可以作为有效的Python代码),而 str() 则产生人类可读的输出
-
_unicode_(self)
定义对类的实例调用 unicode() 时的行为。 unicode() 和 str() 很像,只是它返回unicode字符串
注意,如果调用者试图调用 str() 而你的类只实现了 **_unicode_() ,那么类将不能正常工作。所有你应该总是定义 **_str_()
-
_format_(self)
定义当类的实例用于新式字符串格式化时的行为
例如, “Hello, 0:abc!”.format(a) 会导致调用 a._format_(“abc”)
当定义你自己的数值类型或字符串类型时,你可能想提供某些特殊的格式化选项,这种情况下这个魔法方法会非常有用
-
_hash_(self)
定义对类的实例调用 hash() 时的行为
它必须返回一个整数,其结果会被用于字典中键的快速比较
实现这个魔法方法通常也需要实现 __eq__ ,并且遵守如下的规则: a == b 意味着 hash(a) == hash(b)
-
_nonzero_(self)
定义对类的实例调用 bool() 时的行为
根据你自己对类的设计,针对不同的实例,这个魔法方法应该相应地返回True或False
-
_dir_(self)
定义对类的实例调用 dir() 时的行为,这个方法应该向调用者返回一个属性列表
一般来说,没必要自己实现 __dir__
但是如果你重定义了 __getattr__ 或者 __getattribute__ ,乃至使用动态生成的属性,以实现类的交互式使用,那么这个魔法方法是必不可少的
访问控制
-
_getattr_(self, name)
当用户试图访问一个根本不存在(或者暂时不存在)的属性时,你可以通过这个魔法方法来定义类的行为
这个可以用于捕捉错误的拼写并且给出指引,使用废弃属性时给出警告(如果你愿意,仍然可以计算并且返回该属性),以及灵活地处理AttributeError
只有当试图访问不存在的属性时它才会被调用,所以这不能算是一个真正的封装的办法
-
_setattr_(self, name, value)
和 _getattr_ 不同,_setattr_ 可以用于真正意义上的封装
它允许你自定义某个属性的赋值行为,不管这个属性存在与否,也就是说你可以对任意属性的任何变化都定义自己的规则
-
_delattr_(self, name)
这个魔法方法和 _setattr_ 几乎相同,只不过它是用于处理删除属性时的行为
和 _setattr_ 一样,使用它时也需要多加小心,防止产生无限递归(在 _delattr_ 的实现中调用 del self.name 会导致无限递归)
-
_getattribute_(self, name)
_getattribute_ 只能用于新式类,在最新版的Python中所有的类都是新式类,在老版Python中你可以通过继承 object 来创建新式类
_getattribute_ 允许你自定义属性被访问时的行为,它也同样可能遇到无限递归问题(通过调用基类的 _getattribute_ 来避免)
_getattribute_ 基本上可以替代 _getattr_
只有当它被实现,并且显式地被调用,或者产生 AttributeError 时它才被使用
-
递归调用问题
def __setattr__(self, name. value): # 因为每次属性幅值都要调用 __setattr__(),所以这里的实现会导致递归 # 这里的调用实际上是 self.__setattr('name', value) # 因为这个方法一直在调用自己,因此递归将持续进行,直到程序崩溃 self.name = value # 解决方案 def __setattr__(self, name, value): # 定义自定义行为 self.__dict__[name] = value # 使用 __dict__ 进行赋值
容器类型
-
_len_(self)
返回容器的长度,可变和不可变类型都需要实现
-
_getitem_(self, key)
定义对容器中某一项使用 self[key] 的方式进行读取操作时的行为这也是可变和不可变容器类型都需要实现的一个方法
它应该在键的类型错误式产生 TypeError 异常,同时在没有与键值相匹配的内容时产生 KeyError 异常
-
_setitem_(self, key)
定义对容器中某一项使用 self[key] 的方式进行赋值操作时的行为它是可变容器类型必须实现的一个方法
同样应该在合适的时候产生 KeyError 和 TypeError 异常
-
_iter_(self, key)
它应该返回当前容器的一个迭代器迭代器以一连串内容的形式返回
最常见的是使用 iter() 函数调用,以及在类似 for x in container: 的循环中被调用迭代器是他们自己的对象,需要定义 __iter__ 方法并在其中返回自己
-
_reversed_(self)
定义了对容器使用 reversed() 内建函数时的行为它应该返回一个反转之后的序列当你的序列类是有序时,类似列表和元组,再实现这个方法
-
_contains_(self, item)
_contains_ 定义了使用 in 和 not in 进行成员测试时类的行为
你可能好奇为什么这个方法不是序列协议的一部分,原因是,如果 _contains_ 没有定义,Python就会迭代整个序列,如果找到了需要的一项就返回 True
-
_missing_(self ,key)
_missing_ 在字典的子类中使用,它定义了当试图访问一个字典中不存在的键时的行
目前为止是指字典的实例,例如我有一个字典 d , “george” 不是字典中的一个键,当试图访问 d[“george’] 时就会调用 d._missing_(“george”) )
反射
-
_instancecheck_(self, instance)
检查一个实例是否是你定义的类的一个实例(例如 isinstance(instance, class) )
-
_subclasscheck_(self, subclass)
检查一个类是否是你定义的类的子类(例如 issubclass(subclass, class) )
操作符
- 使用Python魔法方法的一个巨大优势就是可以构建一个拥有Python内置类型行为的对象
比较操作符
- _cmp_(self, other)
- _cmp_* 是所有比较魔法方法中最基础的一个,它实际上定义了所有比较操作符的行为(<,==,!=,等等),但是它可能不能按照你需要的方式工作
- 例如,判断一个实例和另一个实例是否相等采用一套标准,而与判断一个实例是否大于另一实例采用另一套
- _cmp_ 应该在 self < other 时返回一个负整数,在 self == other 时返回 0,在 self > other 时返回正整数
- 最好只定义你所需要的比较形式,而不是一次定义全部
- 如果你需要实现所有的比较形式,而且它们的判断标准类似,那么 _cmp_ 是一个很好的方法,可以减少代码重复,让代码更简洁
- _eq_(self, other)
- 定义等于操作符 (==) 的行为
- _ne_(self, other)
- 定义不等于操作符 (!=) 的行为
- _lt_(self, other)
- 定义小于操作符 (<) 的行为
- _gt_(self, other)
- 定义大于操作符 (>) 的行为
- _le_(self, other)
- 定义小于等于操作符 (<=) 的行为
- _ge_(self, other)
- 定义大于等于操作符 (>=) 的行为
数值操作符
-
数值操作符五类:一元操作符,常见算数操作符,反射算数操作符,增强赋值操作符,类型转换操作符
-
一元操作符
-
_pos_(self)
实现取正操作,例如 +some_object
-
_neg_(self)
实现取负操作,例如 -some_object
-
_abs_(self)
实现内建绝对值函数 abs() 操作
-
_invert_(self)
实现取反操作符 ~。
-
_round_(self, n)
实现内建函数 round() ,n 是近似小数点的位数
-
_floor_(self)
实现 math.floor() 函数,即向下取整
-
_ceil_(self)
实现 math.ceil() 函数,即向上取整
-
_trunc_(self)
实现 math.trunc() 函数,即距离零最近的整数
-
-
常见算数操作符(二元操作符)
-
_add_(self, other)
实现加法操作
-
_sub_(self, other)
实现减法操作
-
_mul_(self, other)
实现乘法操作
-
_floordiv_(self, other)
实现使用 // 操作符的整数除法
-
_div_(self, other)
实现使用 / 操作符的除法
-
_truediv_(self, other)
实现 true 除法,这个函数只有使用 from __future__ import division 时才有作用
-
_mod_(self, other)
实现 % 取余操作
-
_divmod_(self, other)
实现 divmod 内建函数
-
__pow__
实现 ** 操作符
-
_lshift_(self, other)
实现左移位运算符 <<
-
_rshift_(self, other)
实现右移位运算符 >>
-
_and_(self, other)
实现按位与运算符 &
-
_or_(self, other)
实现按位或运算符 |
-
_xor_(self, other)
实现按位异或运算符 ^
-
-
反射算数操作符
-
_radd_(self, other)
实现反射加法操作
-
_rsub_(self, other)
实现反射减法操作
-
_rmul_(self, other)
实现反射乘法操作
-
_rfloordiv_(self, other)
实现使用 // 操作符的整数反射除法
-
_rdiv_(self, other)
实现使用 / 操作符的反射除法
-
_rtruediv_(self, other)
实现 true 反射除法,这个函数只有使用 from __future__ import division 时才有作用
-
_rmod_(self, other)
实现 % 反射取余操作符
-
_rdivmod_(self, other)
实现调用 divmod(other, self) 时 divmod 内建函数的操作
-
_rpow_
实现 ** 反射操作符
-
_rlshift_(self, other)
实现反射左移位运算符 << 的作用
-
_rshift_(self, other)
实现反射右移位运算符 >> 的作用
-
_rand_(self, other)
实现反射按位与运算符 &
-
_ror_(self, other)
实现反射按位或运算符 |
-
_rxor_(self, other)
实现反射按位异或运算符 ^
-
-
增强赋值操作符
-
x += 1 # 也就是 x = x + 1
-
_iadd_(self, other)
实现加法赋值操作
-
_isub_(self, other)
实现减法赋值操作
-
_imul_(self, other)
实现乘法赋值操作
-
_ifloordiv_(self, other)
实现使用 //= 操作符的整数除法赋值操作
-
_idiv_(self, other)
实现使用 /= 操作符的除法赋值操作
-
_itruediv_(self, other)
实现 true 除法赋值操作,这个函数只有使用 from future import division 时才有作用
-
_imod_(self, other)
实现 %= 取余赋值操作
-
_ipow_
**实现 **= 操作
-
_ilshift_(self, other)
实现左移位赋值运算符 <<=
-
_irshift_(self, other)
实现右移位赋值运算符 >>=
-
_iand_(self, other)
实现按位与运算符 &=
-
_ior_(self, other)
实现按位或赋值运算符 |
-
_ixor_(self, other)
实现按位异或赋值运算符 ^=
-
-
类型转换操作符
-
_int_(self)
实现到int的类型转换
-
_long_(self)
实现到long的类型转换
-
_float_(self)
实现到float的类型转换
-
_complex_(self)
实现到complex的类型转换
-
_oct_(self)
实现到八进制数的类型转换
-
_hex_(self)
实现到十六进制数的类型转换
-
_index_(self)
实现当对象用于切片表达式时到一个整数的类型转换
-
_trunc_(self)
当调用 math.trunc(self) 时调用该方法, _trunc_ 应该返回 self 截取到一个整数类型(通常是long类型)的值
-
_coerce_(self)
该方法用于实现混合模式算数运算,如果不能进行类型转换, _coerce_ 应该返回 None
反之,它应该返回一个二元组 self 和 other ,这两者均已被转换成相同的类型
-
-
反射
简介
- 通过字符串去操作对象的属性和方法
四个方法
- hasattr、getattr、setattr、delattr
实例化对象的反射操作
class A:
country = "中国"
area = "深圳"
def __init__(self, name, age):
self.name = name
self.age = age
def func(self):
print(666)
a = A("Jane", 18)
# 对象的属性
print(a.name) # Jane
# 注意这个变量名也要用字符串形式
print(hasattr(a, "name")) # True
# 不是这样用,而是字符串形式的属性名
print(hasattr(a, "Jane")) # False
# 一般 hasattr 与 getattr 结合起来使用
if hasattr(a, "name"):
print(getattr(a, "name")) # Jane
# 可以设置一个默认值,目的是防止程序报错,如果没有该属性,就返回默认值
print(getattr(a, "sex", None)) # None
print(a.country) # 中国
print(getattr(a, "country")) # 中国
ret = getattr(a, "func")
# 注意这里 ret() 相当于 func()
print(ret()) # 666
# 给对象添加一个属性
setattr(a, "sex", "男")
print(a.sex) # 男
# 删除对象的某个属性
delattr(a, "name")
print(a.name) # AttributeError: 'A' object has no attribute 'name'
类名的反射操作
class A:
country = "中国"
area = "深圳"
def __init__(self, name, age):
self.name = name
self.age = age
def func(self):
print(666)
# 获取类 A 的静态属性 country
print(getattr(A, "country")) # 中国
# 获取类 A 的静态属性 area
print(getattr(A, "area")) # 深圳
# 获取类 A 的动态方法并执行
getattr(A, "func")(23) # 666
getattr __getattr__ __getattribute__ _get_ 区别
-
getattr()
- python内置的一个函数,它可以用来获取对象的属性和方法
-
_getattr_()、__getattribute()__
-
类对象的魔法方法,在访问对象属性的时候会被调用
class A(object): def __init__(self, x): self.x = x def hello(self): return 'hello func' def __getattr__(self, item): print('in __getattr__') return 100 def __getattribute__(self, item): print('in __getattribute__') return super(A, self).__getattribute__(item) a = A(10) print(a.x) print(a.y) # 输出 in __getattribute__ 10 in __getattribute__ in __getattr__ 100可以看出,在获到对象属性时,
__getattribute__()是一定会被调用的,无论属性存不存在,首先都会调用这个魔法方法如果调用像
a.y这种不存在的对象时,调用**_getattribute_()**找不到y这个属性,就会再调用__getattr__()这个魔法方法可以通过这个方法设置属性不存在时的默认值
使用上面的getattr()方法获取属性时,也是同样的调用关系,只不过只有在
getattr()带第三个参数作为默认值时,才会调用__getattr__()方法
-
-
__get__()
-
描述符方法之一,经常配套使用的是
__set__()方法通过描述符,可以将访问对象属性转变为调用描述符方法。这在ORM中被经常使用, 可以通过描述符方法进行参数格式验证
import random class Die(object): def __init__(self, sides=6): self.sides = sides def __get__(self, instance, owner): print('Die __get__()') return int(random.random() * self.sides) + 1 def __set__(self, instance, value): print('Die __set__()') class Game(object): d6 = Die() d10 = Die(sides=10) d20 = Die(sides=20) game = Game() print(game.d6) game.d6 = 10 print(game.d6) # 输出 Die __get__() 5 Die __set__() 10使用描述符可以让我们在获取或者给对象赋值时对数据值进行一些特殊的加工和处理
python里经常使用的
@property装饰器其实就是通过描述符的方式实现的
-
is 和 ==
-
官方文档中说 is 表示的是对象标示符(object identity),而 == 表示的是相等(equality)
is 的作用是用来检查对象的标示符是否一致,也就是比较两个对象在内存中的地址是否一样,而 == 是用来检查两个对象是否相等
检查 a is b 的时候,其实相当于检查 id(a) == id(b),而检查 a == b 的时候,实际是调用了对象 a 的 eq() 方法,a == b 相当于 a.eq(b)
一般情况下,如果 a is b 返回True的话,即 a 和 b 指向同一块内存地址的话,a == b 也返回True,即 a 和 b 的值也相等
a = "hello" b = "hello" print(id(a)) # 输出 140506224367496 print(id(b)) # 输出 140506224367496 print(a is b) # 输出 True print(a == b) # 输出 True a = "hello world" b = "hello world" print(id(a)) # 输出 140506208811952 print(id(b)) # 输出 140506208812208 print(a is b) # 输出 False print(a == b) # 输出 True a = [1, 2, 3] b = [1, 2, 3] print(id(a)) # 输出 140506224299464 print(id(b)) # 输出 140506224309576 print(a is b) # 输出 False print(a == b) # 输出 True a = [1, 2, 3] b = a print(id(a)) # 输出 140506224305672 print(id(b)) # 输出 140506224305672 print(a is b) # 输出 True print(a == b) # 输出 True # 结论 只要 a 和 b 的值相等,a == b 就会返回True,而只有 id(a) 和 id(b) 相等时,a is b 才返回 True
进程、线程、协程
进程
-
一个程序的执行实例就是一个进程
每一个进程提供执行程序所需的所有资源(进程本质上是资源的集合,资源分配的最小单位)
每一个进程都有它自己的内存空间和系统资源;在OS的眼里,进程就是一个担当分配系统资源CPU时间、内存的实体
线程
-
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位(CPU调度的最小单位)
-
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,
任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量
from concurrent.futures import ThreadPoolExecutor import threading def action(max): my_sum = 0 for i in range(max): print(threading.current_thread().name + ' ' + str(i)) my_sum += i return my_sum with ThreadPoolExecutor(max_workers=4) as pool: # submit results = [pool.submit(action, i) for i in [300000, 100, 50]] # map # results = pool.map(action, [3000, 100, 50]) for r in results: print(r.result()) # map # print(list(results))
进程与线程区别
- 同一个进程中的线程共享同一内存空间, 但是进程之间是独立的
- 同一进程中的所有线程的数据是共享的(进程通讯),进程之间的数据是独立的
- 对主线程的修改可能会影响其他线程的行为,但是父进程的修改(除了删除以外)不会影响其他子进程
- 同一进程的线程之间可以直接通信,但是进程之间的交流需要借助中间代理来实现
- 线程是一个上下文的执行指令,而进程则是与运算相关的一簇资源
- 创建新的线程很容易,但是创建新的进程需要对父进程做一次复制
- 一个线程可以操作同一进程的其他线程,但是进程只能操作其子进程
- 线程启动速度快,进程启动速度慢
协程
简介
-
协程是一种用户级的轻量级线程。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保
存的寄存器上下文和栈
-
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处
逻辑流的位置
-
在并发编程中,协程与线程类似,每个协程表示一个执行单元,有自己的本地数据,与其它协程共享全局数据和其它资源
-
协程是用户自己来编写调度逻辑的,对CPU来说,协程其实是单线程,所以CPU不用去考虑怎么调度、切换上下文,这就省去了CPU的切换开销,所以协程在
一定程度上又好于多线程
-
Python对协程的支持是通过generator实现的。generator也叫生成器,生成器又是基于迭代器实现的
迭代器
-
能被next()方法调用,并不断返回下一个值的对象,叫做迭代器
-
迭代器是一个带状态的对象,调用next()方法的时候返回容器中的下一个值,任何实现了iter和next()方法的对象都是迭代器,iter返回迭代器自身,next
返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常。
-
特征:并不依赖索引,而通过next指针迭代所有数据,一次只取一个值,非常节省空间
-
Python中当容器对象提供了对迭代的支持时,可以通过
container.__iter__()来返回一个迭代器对象。迭代器需要支持以下两个方法,这两个方法共同构成了迭代器协议:
-
iterator._iter_()
该方法返回迭代器本身,这个方法是配合for和in使用所必须的 -
iterator._next_()
该方法返回下一项,如果已没有可返回的内容则引发StopIteration异常
-
生成器
-
生成器本质是迭代器, 允许自定义逻辑的迭代器
-
不需要再像上面的类一样写iter()和next()方法了,只需要一个yiled关键字
生成器一定是迭代器,因此任何生成器也是以一种懒加载的模式生成值
gevent
-
Python通过yield提供了对协程的基本支持,但是不完全。而第三方的gevent为Python提供了比较完善的协程支持
-
gevent它是一个并发网络库。它的协程是基于greenlet的,并基于libev实现快速事件循环
-
基本思想:
当一个greenlet(协程/微线程)遇到IO操作时,比如访问网络,就自动切换到其他的greenlet(协程/微线程),等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO
-
由于切换是在IO操作时自动完成,所以gevent需要修改Python自带的一些标准库,这一过程在启动时通过monkey patch完成
Monkey patch
-
猴子补丁(monkey patch)的主要功能就是动态的属性的替换
-
monkey patch 允许程序在运行期间动态修改一个类或模块
-
一个比较实用的例子,很多代码用到 import json,后来发现ujson性能更高,如果觉得把每个文件的import json 改成 import ujson as json成本较高,或者
说想测试一下用ujson替换json是否符合预期,只需要在入口加上
import json import ujson def monkey_patch_json(): json.__name__ = 'ujson' json.dumps = ujson.dumps json.loads = ujson.loads monkey_patch_json()
windows 和 linux fork
- Unix系统中,我们通常用fork来创建一个进程,相应的,在Windows操作系统里,我们用的是CreateProcess
fork 过程
-
当fork()系统调用发生时,子进程会拷贝其父进程的所有页面,并将其加载入操作系统为它分配的一片独立内存中。这些拷贝的动作很消耗时间,而且在某些
情况下并不需要这么做。如果子进程马上执行了"exec"系统调用(用来执行任何可执行文件)或者Fork()之后就退出进程,拷贝父进程的页面就很不划算,因
为exec后包括代码段,数据段和堆栈等都已经被新的内容取代,只留下进程ID等一些表面上的信息仍保持原样,而如果fork完之后我们马上就调用exec,这些
辛辛苦苦拷贝来的东西又会被立刻抹掉。
-
这种情况下,一种叫 copy-on-write (写时复制)(COW)的技术被采用了,当fork发生时,父进程的页面并没有被拷贝到子进程中,相反,这些页面被父进程
和子进程所共享。无论父子进程中谁要去修改页面,系统就为该进程拷贝一个独立的特定页面,然后再对其进行修改。该进程以后就只使用这个新拷贝的页面
而不再是共享的那个,而别的进程则继续使用共享的页面。这项技术就叫写时复制,因为当有进程要写页面的时候,就需要先拷贝页面。
-
采用了COW技术,Fork时,子进程只需要拷贝父进程的页面表就可以了。产生这种设计是因为有时兼容POSIX的操作系统在Fork之后,并不需要执行Exec,比
如apache Web Server就因此而受益,有点接近Windows的CreateThread。
-
COW技术使得创建子进程的代价小了许多,但是现实情况下,很多时候Fork会紧跟着一个EXEC,因为Exec必须装载所有的映像,unix还是得花很大的代价来
创建一个进程。比较公平的比较是 fork 近似于 NtCreateThread 而 CreateProcess 近似于 fork + execve。
windows
-
相对于Unix,Windows的设计更有弹性,它是一个多层次的而且更加组件化的操作系统,Windows拥有许多子系统,我们通常说的Windows,只是它的子系
统之一,称为WoW(Windows On Windows),其他子系统还包括Wow64,Posix和OS2。 Windows NT内核也支持COW fork,但是只为SFU(Microsoft’s UNIX
environment for Windows)所使用,SFU进程和Win32进程是不同的东西。
-
Win32的进程创建,需要通知CSRSS进程被创建,CSRSS又调用了LPC,而它要求至少kernel32(NTDll.dll)等动态库要被加载,然后它又要处理许多预保留的工
作项目,之后该进程才能被认为是一个Win32进程,之后还有许多枝节要去处理比如解析manifests,程序兼容性检查,程序的限制策略等等等等,这些附加在原
始进程创建过程之后枝节,无疑拖累了进程创建速度。
-
不带任何子系统的原生进程的创建速度是很快的,而创建SFU进程要比Win32进程简单得多,也快得多,尽管Win32花了许多力气在加载这些枝节之上,但是
一方面,它提高了对客户的友好,另一方面,运行库的预加载使得图形界面的处理速度更快,或者Win32进程天生就是为图形处理做准备的。
区别
-
在windows系统中不可以用fork来创建进程,linux可以
-
linux
-
当你调用
fork()最初只有你的虚拟机被复制,所有的页面被标记为copy-on write (写时复制)。新子进程将拥有父进程虚拟机的逻辑副本,但在您真正开始写入之前,它不会消耗任何额外的RAM。
至于线程,
fork在子进程中只创建一个类似于调用线程副本的新线程。另外,只要你调用任何一个
exec系列的调用,那么你的整个过程映像被替换为一个新的,只有文件描述符被保留。这些副本是“写时复制”的,所以如果你的子进程没有修改数据,除了父进程的内存之外,它不会使用任何内存。
通常,在
fork(),子进程使得exec()用另一个进程替换这个进程的程序,然后所有的内存都被丢弃。 -
fork基本上把你的进程分成两部分,在fork函数调用之后,父进程和子进程都继续执行指令。但是,子进程中的返回值是0,而父进程中的返回值是子进程的进程ID。
-
子进程的创建非常快,因为它使用与父进程相同的页面。
这些页面被标记为写时拷贝(COW),这样如果任一进程改变了页面,那么另一个就不会受到影响。
一旦子进程存在,它通常会调用一个
exec函数来替换映像。 -
fork()不是一个确切的进程副本。 它创建一个子进程,但是子进程在与父进程相同的指令处开始执行,并从那里继续。
-
-
windows
- Windows没有
fork的平等,而CreateProcess调用只允许你启动一个新的进程。 - 新的进程会从头开始执行复制的程序。
- Windows没有
GIL锁
设计初衷
-
解决线程间数据一致性和状态同步的困难
-
改进
-
为了让各个线程能够平均利用CPU时间,python会计算当前已执行的微代码数量,达到一定阈值后就强制释放GIL
而这时也会触发一次操作系统的线程调度,是否真正进行上下文切换由操作系统自主决定
-
产生背景
-
GIL产生在垃圾回收机制的背景下
Python 使用引用计数来进行内存管理(垃圾回收)
Python 里创建的所有对象,都有一个变量(reference count)记录着当前有多少个引用指向了这个对象,当引用数变成 0 的时候
Python 就会回收这个对象所占用的内存
Python 的引用计数需要避免资源竞争的问题,需要在有两个或多个线程同时增加或减少引用计数的情况下,依然保证引用计数的结果是正确的
当有多个线程同时改一个对象的引用计数的时候,有可能导致内存泄漏(对象的引用计数永远没有归零的机会)
还有可能导致对象提前释放,程序崩溃(一个对象存在引用的情况下引用计数变成了 0,导致此对象提前释放)
通过对不同线程访问、修改引用计数增加锁,我们就可以保证引用计数总是被正确的修改(可以联想一下数据库的锁机制)
但是,如果我们对每一个对象或者每一组对象都增加锁,这就意味在在你的 Python 程序中有很多个锁同时存在
多个锁同时存在会有其他的风险–死锁(死锁只会在有多个锁存在的情况下发生,参考数据的死锁)
除此之外,性能下降也是多个锁存在的一大弊端。因为申请锁和释放锁都是一笔不小的开销
GIL 是一把锁(这里强调单个),这把锁加载了 Python 的解释器上,它要求任何 Python 代码在执行的时候需要先申请这把锁,否则就别想执行
只有一把锁,带来的好处就是
- 不会有死锁
- 对因为引入锁而导致的性能下降影响不大
然而坏处就是 GIL 这把锁让计算密集型的代码也只能使用单线程执行
垃圾回收机制
- python 采用的是引用计数机制为主,标记-清除和**分代收集(隔代回收)**两种机制为辅的策略
引用计数
-
引用计数的原理:
每个对象维护一个对象引用 ob_ref 字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_ref加1,每当该对象的引用失效
时计数ob_ref减1,一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。它的缺点是需要额外的空间维护引用计数,这个问题是其次
的,不过最主要的问题是它不能解决对象的“循环引用”。
-
引用计数的优点:
-
1、简单
-
2、实时性:一旦没有引用,内存就直接释放了,不用像其他机制得等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
-
-
引用计数的缺点:
-
1、维护引用计数消耗资源
-
2、循环引用
-
标记清除
- 标记清除算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。
- 它分为两个阶段:
- 第一阶段是标记阶段,GC会把所有的活动对象打上标记
- 第二阶段是把那些没有标记的非活动对象进行回收
分代回收
-
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为
年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率随着对象存活时间的增大而减小。
-
新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象
就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
-
同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
简介
-
GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念
-
GIL的问题其实是由于近十几年来应用程序和操作系统逐步从多任务单核心演进到多任务多核心导致的 , 在单核CPU上调度多个线程任务,大家相互共享一个全
局锁,谁在CPU执行,谁就占有这把锁,直到这个线程因为IO操作或者Timer Tick到期让出CPU,没有在执行的线程就安静的等待着这把锁(除了等待之外,
他们应该也无事可做)
-
防止多线程并发执行机器码的互斥锁(mutex)
GIL锁的释放
- 一个线程有两种情况下会释放全局解释器锁
- 一种情况是在该线程进入IO操作之前,会主动释放GIL
- 另一种情况是解释器不间断运行了1000字节码(Py2)或运行15毫秒(Py3)后,该线程也会放弃GIL
如何避免GIL的影响
-
在以IO操作为主的IO密集型应用中,多线程和多进程的性能区别并不大,原因在于即使在Python中有GIL锁的存在,由于线程中的IO操作会使得线程立即释放
GIL,切换到其他非IO线程继续操作,提高程序执行效率。相比进程操作,线程操作更加轻量级,线程之间的通讯复杂度更低,建议使用多线程
-
如果是计算密集型的应用,尽量使用多进程或者协程来代替多线程
守护进程
简介
-
守护进程是脱离于终端并且在后台运行的进程,脱离终端是为了避免在执行的过程中的信息在终端显示,并且进程也不会被任何终端所产生的信息所打断
-
守护进程一般的生命周期是系统启动到系统停止运行
-
在Linux服务器实际应用中,经常会有需要长时间执行的任务。若在前台运行,用户无法进行其他操作或者断开与服务器的连接,否则任务将被中止
此时适合使用守护进程
特性
-
后台运行
-
与其运行前的环境隔离开来
这些环境包括未关闭的文件描述符、控制终端、会话和进程组、工作目录以及文件创建掩码等
这些环境通常是守护进程从执行它的父进程(特别是shell)中继承下来的
-
启动方式特殊,它可以在系统启动时从启动脚本 /etc/rc.d 中启动,可以由 inetd 守护进程启动,可以由 crond 启动,还可以由用户终端(通常是 shell)执行
编程规则
- 在后台运行,调用 fork ,然后使父进程 exit
- 脱离控制终端,登录会话和进程组,调用 setsid() 使进程成为会话组长
- 禁止进程重新打开控制终端
- 关闭打开的文件描述符,调用 fclose()
- 将当前工作目录更改为根目录
- 重设文件创建掩码为 0
- 处理 SIGCHLD 信号
python实现
# coding=utf8
import os
import sys
import atexit
def daemonize(pid_file=None):
"""
创建守护进程
:param pid_file: 保存进程id的文件
:return:
"""
# 从父进程fork一个子进程出来
pid = os.fork()
# 子进程的pid一定为0,父进程大于0
if pid:
# 退出父进程
sys.exit(0)
# 子进程默认继承父进程的工作目录,最好是变更到根目录,否则回影响文件系统的卸载
os.chdir('/')
# 子进程默认继承父进程的umask(文件权限掩码),重设为0(完全控制),以免影响程序读写文件
os.umask(0)
# 让子进程成为新的会话组长和进程组长
os.setsid()
# 注意了,这里是第2次fork,也就是子进程的子进程,我们把它叫为孙子进程
_pid = os.fork()
if _pid:
# 退出子进程
sys.exit(0)
# 此时,孙子进程已经是守护进程了,接下来重定向标准输入、输出、错误的描述符(是重定向而不是关闭, 这样可以避免程序在 print 的时候出错)
# 刷新缓冲区先,小心使得万年船
sys.stdout.flush()
sys.stderr.flush()
# dup2函数原子化地关闭和复制文件描述符,重定向到/dev/nul,即丢弃所有输入输出
with open('/dev/null') as read_null, open('/dev/null', 'w') as write_null:
os.dup2(read_null.fileno(), sys.stdin.fileno())
os.dup2(write_null.fileno(), sys.stdout.fileno())
os.dup2(write_null.fileno(), sys.stderr.fileno())
# 写入pid文件
if pid_file:
with open(pid_file, 'w+') as f:
f.write(str(os.getpid()))
# 注册退出函数,进程异常退出时移除pid文件
atexit.register(os.remove, pid_file)
开源项目
简介
-
Github 开源项目: python-daemon 提供了 Python 版本的守护进程化实现。提供以下方法:
-
start() - starts the daemon (creates PID and daemonizes)
-
stop() - stops the daemon (stops the child process and removes the PID)
-
restart() - does stop() then start()
-
使用示例
from daemon import Daemon
class pantalaimon(Daemon):
def run(self):
# Do stuff
pass
# 指定 pid 文件的路径
pineMarten = pantalaimon('/path/to/pid.pid')
pineMarten.start()
python用法
守护进程
-
什么是守护进程
-
主进程创建子进程,然后将该进程设置成守护自己的进程,守护进程会在主进程代码执行结束后就终止
-
如果我们有两个任务需要并发执行,那么开一个主进程和一个子进程分别去执行就可以了
-
主进程在其代码结束后就已经运行完毕了,守护进程在此时就被回收,然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源
才会结束,否则会产生僵尸进程
-
如果子进程的任务在主进程任务结束后就没有存在的必要了,那么该子进程应该在开启前就被设置成守护进程
主进程代码运行结束,守护进程随即终止
-
守护进程内无法再开启子进程,否则抛出异常
-
-
使用守护进程
- 守护进程本身就是一个子进程,所以在主进程需要将任务并发执行的时候需要开启子进程
- 当该子进程执行的任务生命周期伴随着主进程的生命周期时,就需要将该子进程做成守护进程
-
使用示例
from multiprocessing import Process
import os
import time
def task(x):
print('%s is running ' %x)
time.sleep(3)
print('%s is done' %x)
if __name__ == '__main__':
p1=Process(target=task,args=('守护进程',))
p2=Process(target=task,args=('子进程',))
p1.daemon=True # 设置p1为守护进程
p1.start()
p2.start()
print('主')
# 当主进程的代码运行完毕后,守护进程就会立马结束掉,而不会去管其他子进程是否运行完毕
>>:主
>>:子进程 is running
>>:子进程 is done
守护线程
-
什么是守护线程
-
守护线程会在该进程内所有非守护线程全部都运行完毕后,守护线程才会挂掉,并不是主线程运行完毕后守护线程挂掉
-
守护线程守护的是:当前进程内所有的子线程
-
主线程在其他非守护线程运行完毕后才算运行完毕守护线程在此时就被回收
因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束
-
-
主线程与进程的关系
-
主线程的生命周期就是一个进程的生命周期
-
主进程等待子进程是因为主进程要负责回收子进程的系统资源,主线程等待子线程是因为主线程要等待子线程运行完毕,子线程运行完毕后,这个进程
才算运行完毕后,主线程才结束
-
-
使用示例
# 当只有一个子线程并且为守护线程,那么这个守护线程就会等待主线程运行完毕后挂掉
from threading import Thread
import os
import time
def task(x):
print('%s is running ' %x)
time.sleep(3)
print('%s is done' %x)
if __name__ == '__main__':
t1=Thread(target=task,args=('守护线程',))
t1.daemon=True # 设置p1为守护进程
t1.start()
print('主')
>>:守护线程 is running
>>:主
# 当有多个子线程时,守护线程就会等待所有的子线程运行完毕后,守护线程才会挂掉(这一点和主线程是一样的,都是等待所有的子线程运行完毕后才会挂掉)
from threading import Thread
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon=True
t1.start()
t2.start()
print("main-------")
>>:123
>>:456
>>:main-------
>>:end123
>>:end456
守护进程与后台进程
- 通过&符号,可以把命令放到后台执行。它与守护进程是不同的:
- 守护进程与终端无关,是被init进程收养的孤儿进程;而后台进程的父进程是终端,仍然可以在终端打印
- 守护进程在关闭终端时依然坚挺;而后台进程会随用户退出而停止,除非加上nohup
- 守护进程改变了会话、进程组、工作目录和文件描述符,后台进程直接继承父进程(shell)
os.path 和 sys.path
- os.path 主要是用于用户对系统路径文件的操作
- sys.path 主要用户对 Python 解释器的系统环境参数的操作
元类 metaclass
简介
-
metaclass(元类),元类可以控制类的创建过程,它主要做三件事:
-
拦截类的创建
-
修改类的定义
-
返回修改后的类
-

-
对象由类产生,类由元类产生
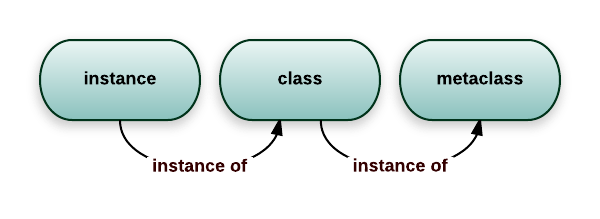
-
元类示例
class HelloMeta2(type): def __init__(cls, name, bases, attrs): super(HelloMeta2, cls).__init__(name, bases, attrs) attrs_ = {} for k, v in attrs.items(): if not k.startswith('__'): attrs_[k] = v setattr(cls, '_new_dict', attrs_) class New_Hello2(metaclass=HelloMeta2): a = 1 b = True In : New_Hello2._new_dict Out: {'a': 1, 'b': True} In : h2 = New_Hello2() In : h2._new_dict Out: {'a': 1, 'b': True}在Python里类使用 _new_ 方法创建实例,_init_ 负责初始化一个实例
对于type也是一样的效果,只不过针对的是类,在上面的HelloMeta中只使用了**_new_** 创建类
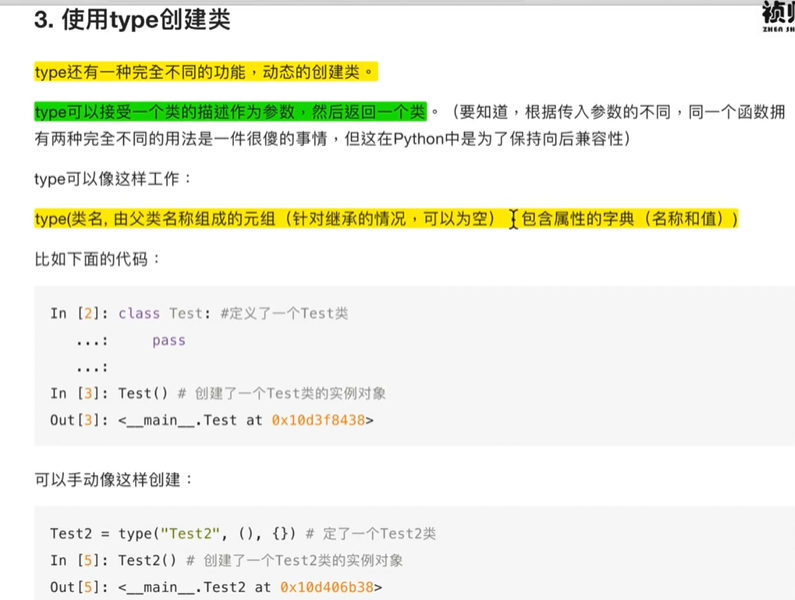
type创建类
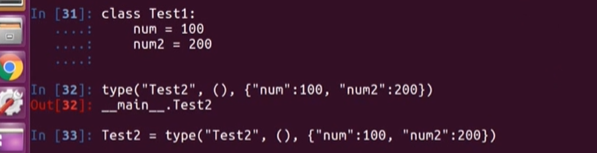
示例1
- Test1 等同于 Test2

示例2

示例3

使用场景
-
日常的业务逻辑开发是不太需要使用到元类的,因为元类是用来拦截和修改类的创建的,用到的场景很少
-
最典型的使用场景就是 ORM
**ORM就是「对象 关系 映射」**的意思,简单的理解就是把关系数据库的一张表映射成一个类,一行记录映射为一个对象
ORM框架中的Model只能动态定义,因为这个模式下这些关系只能是由使用者来定义,元类再配合描述符就可以实现ORM了
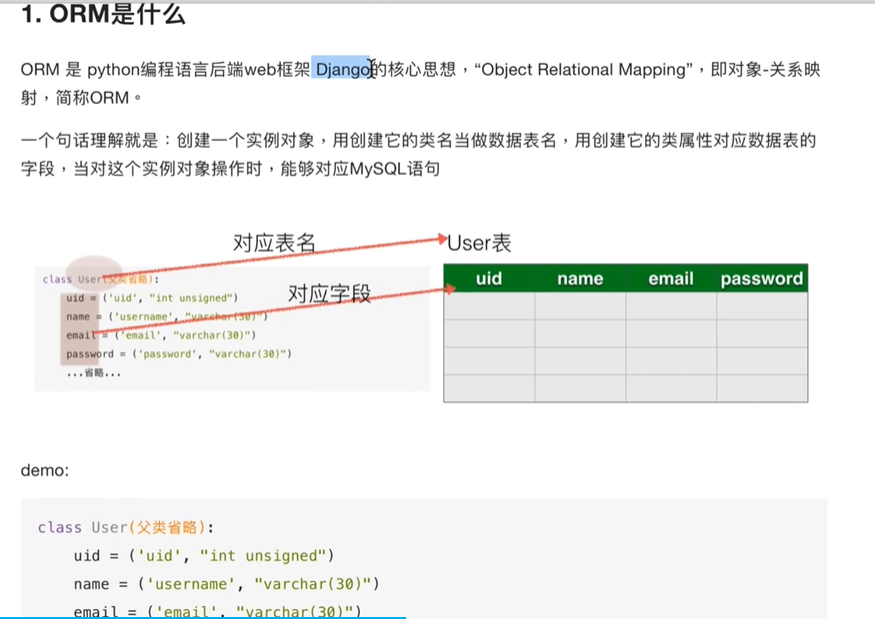
元类实现ORM
简介
- 参考资料:《mini-web框架》-5.元类和orm_哔哩哔哩_bilibili ------在此感谢王铭东老师的视频讲解
示例
- 示例: 类实例化对象调用相应的方法转化为对数据库的操作
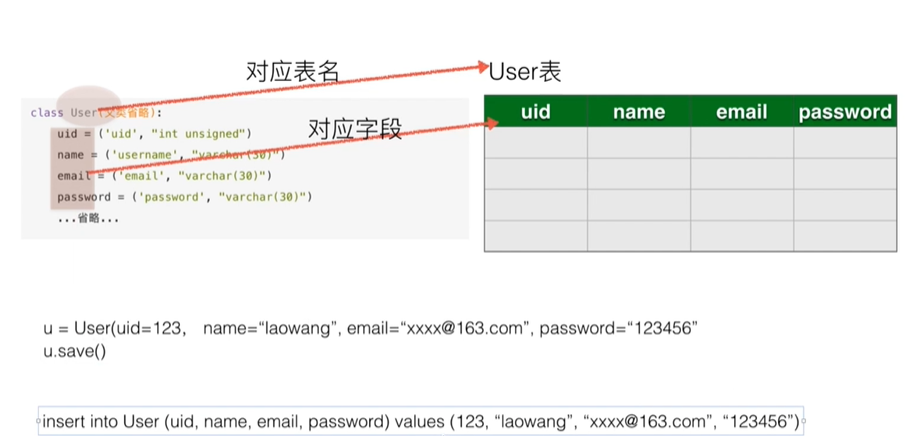
ORM-save 实现
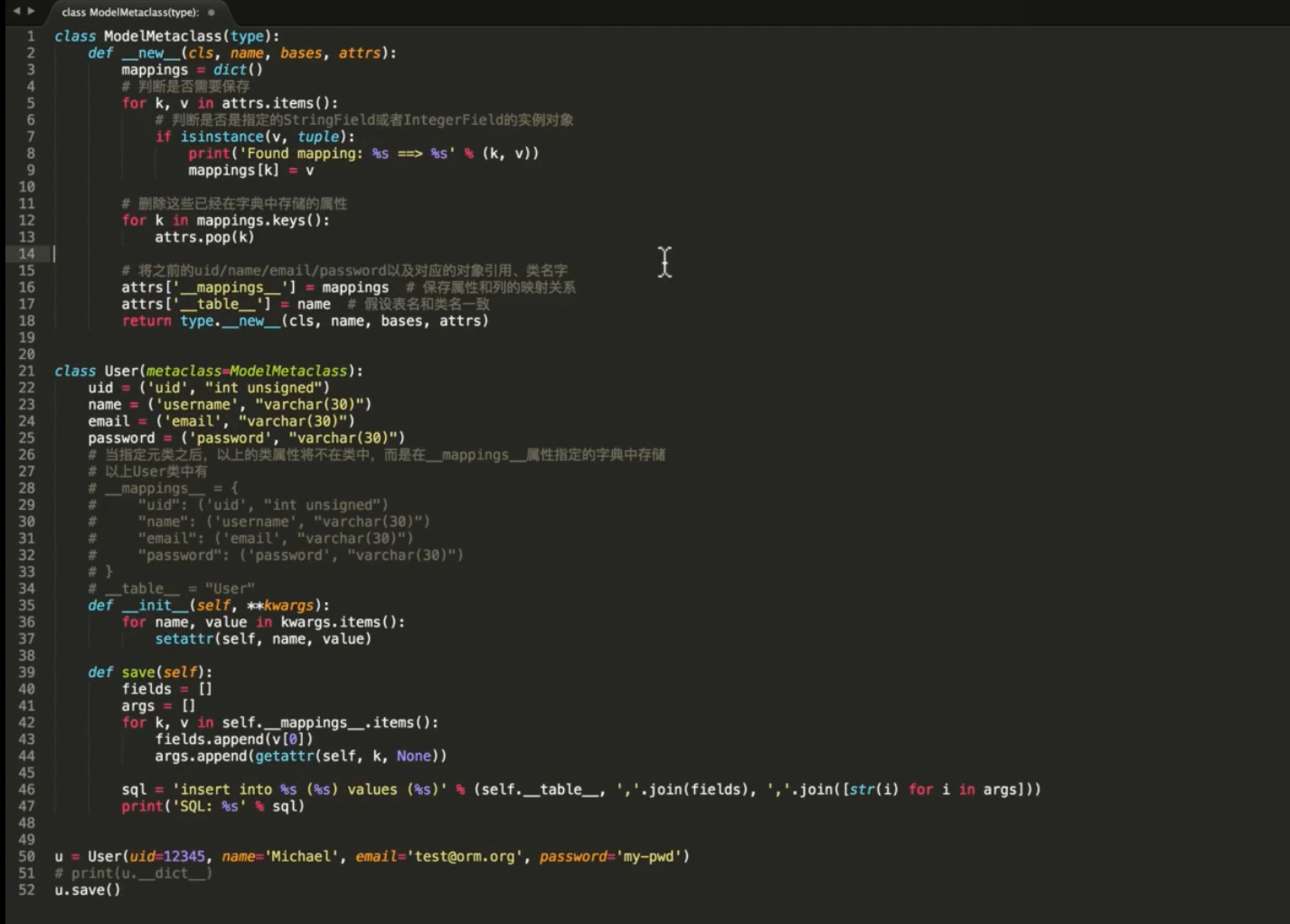
- 通过元类实现 ORM 的 save 方法
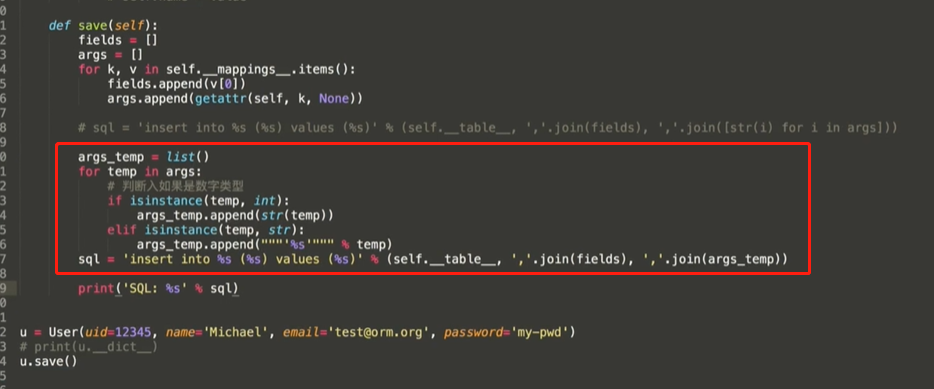
- 拼接原生 sql ,value 值字符串添加引号,整型不作处理
序列化
简介
- 序列化: 把不能够直接存储的数据变得可存储,这个过程叫做序列化
- 反序列化: 把文件中的数据拿出来,恢复成原来的数据类型,这个过程叫做反序列化
json 和 pickle 的区别
-
json 序列化之后的数据类型是 str ,所有编程语言都能识别
但仅限于 ( int float bool ) ( str list tuple dict None )
json 不能连续 load , 只能一次性拿出所有数据
-
pickle 序列化之后的数据类型是 bytes
所有数据类型都可以转化,但仅限于 python 之间的存储传输
pickle 可以连续 load , 多套数据放到同一个文件中
-
json 使用的广泛性比 pickle 更强
json 用在不同编程语言的数据交流中
pickle 用于 python 中数据的存储传输
RBAC
RBAC模型
-
Role-Based Access Control
- 基于角色的访问控制
- 面向企业安全策略的一种有效的访问控制方式
-
基本思想
-
对系统操作的各种权限不是直接授予具体的用户,而是在用户集合与权限集合之间建立一个角色集合
每一种角色对应一组相应的权限
一旦用户被分配了适当的角色后,该用户就拥有此角色的所有操作权限
这样不必在每次创建用户时都进行分配权限的操作,只要分配用户相应的角色即可
而且角色的权限变更比用户的权限变更要少得多,这样将简化用户的权限管理,减少系统的开销
-
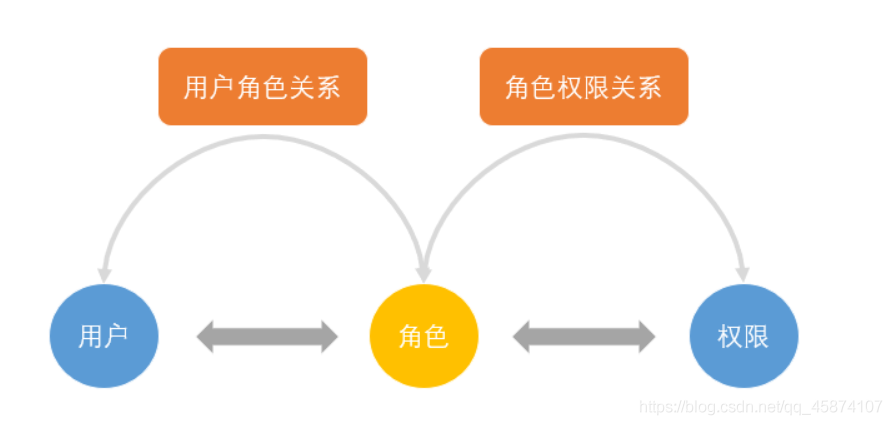
RBAC的组成
- RBAC模型有3个基础组成部分
- 用户、角色、权限
- RBAC通过定义角色的权限,并对用户授予某个角色从而来控制用户的权限,实现了用户和权限的逻辑分离,极大地方便了权限的管理
- User(用户): 每个用户都有唯一的UID识别,并被授予不同的角色
- Role(角色): 不同角色具有不同的权限
- Permission(权限):访问权限
- 用户-角色映射: 用户和角色之间的映射关系
- 角色-权限映射: 角色和权限之间的映射关系
- 示例
- 管理员和普通用户被授予不同的权限,普通用户只能去修改和查看个人信息,而不能创建创建用户和冻结用户,而管理员由于被授予所有权限
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mKJdQtn1-1673840082938)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/rbac_02.jpg)]
RBAC安全原则
-
最小权限原则
- RBAC可以将角色配置成其完成任务所需的最小权限集合
-
责任分离原则
-
可以通过调用相互独立互斥的角色来共同完成敏感的任务
例如要求一个计账员和财务管理员共同参与统一过账操作
-
-
数据抽象原则
-
可以通过权限的抽象来体现
例如财务操作,用借款、存款等抽象权限,而不是使用典型的读、写、执行权限
-
RBAC优缺点
-
优点
-
简化了用户和权限的关系
-
易扩展、易维护
-
-
缺点
- RBAC模型没有提供操作顺序的控制机制,这一缺陷使得RBAC模型很难适应哪些对操作次序有严格要求的系统
Django
多数据库实现
-
settings.py
try: environment = os.getenv('PY_ENV') if environment == 'PRODUCT': DATABASE_ROUTERS = ['mainsys.dbconfig_product.MasterSlaveRouter'] from mainsys.dbconfig_product import * elif environment == 'TEST': DATABASE_ROUTERS = ['mainsys.dbconfig_test.MasterSlaveRouter'] from mainsys.dbconfig_test import * elif not is_linux: DATABASE_ROUTERS = ['mainsys.dbconfig_develop.MasterSlaveRouter'] from mainsys.dbconfig_local import * else: DATABASE_ROUTERS = ['mainsys.dbconfig_develop.MasterSlaveRouter'] from mainsys.dbconfig_develop import * except ImportError as e: if "dbconfig" not in str(e): raise e -
db_dev.py
""" 本文件记录数据库相关配置 """ import platform is_linux = platform.system().lower() == 'linux' elasticsearch_host = '' # MongoDB MONGO_DB = { 'host': '10.32.177.2', 'port': 27017, 'maxPoolSize': 100 } # 数据库配置 DATABASES = { 'default': { 'ENGINE': 'mainsys.mysqlpool', "NAME": "hdjmrh-gaoJingJian-data", "USER": "hdjmrh-gaojingjian", "PASSWORD": "Lingxi@123", "HOST": "10.32.177.1", }, 'base_data': { 'ENGINE': 'mainsys.mysqlpool', "NAME": "hdgjj_base_data", "USER": "select_user", "PASSWORD": "select_user@321", "HOST": "10.32.176.33", }, "jmrh": { "ENGINE": "mainsys.mysqlpool", "NAME": "xm_jmrh", "USER": "select_user", "PASSWORD": "select_user@321", "HOST": "10.32.176.33", }, 'hdjmrh-gaoJingJian-data': { "ENGINE": "mainsys.mysqlpool", "NAME": "hdjmrh-gaoJingJian-data", "USER": "hdjmrh-gaojingjian", "PASSWORD": "Lingxi@123", "HOST": "10.32.177.1", } } class MasterSlaveRouter(object): def db_for_read(self, model, **hints): if model._meta.app_label in ['final', 'court', 'dataplus', 'codes', 'company', 'ministry', 'el_listed']: return 'base_data' elif model._meta.app_label in ['survey', 'analyse_report']: return 'hdjmrh-gaoJingJian-data' elif model._meta.app_label in ['jmrh', ]: return 'jmrh' return 'default' def db_for_write(self, model, **hints): if model._meta.app_label in ['final', 'court', 'dataplus', 'codes', 'company', 'ministry', 'el_listed']: return 'base_data' elif model._meta.app_label in ['survey', 'analyse_report']: return 'hdjmrh-gaoJingJian-data' elif model._meta.app_label in ['jmrh', ]: return 'jmrh' return 'default' def allow_relation(self, obj1, obj2, **hints): return True def allow_migrate(self, db, app_label, model_name=None, **hints): if app_label in ['final', 'court', 'dataplus', 'codes', 'company', 'ministry', 'el_listed']: return 'base_data' elif app_label in ['survey', 'analyse_report']: return 'hdjmrh-gaoJingJian-data' elif app_label in ['jmrh', ]: return 'jmrh' return 'default' # 如需启用配置的多数据库路由规则,则反注释掉下面语句 DATABASE_ROUTERS = ['mainsys.dbconfig_develop.MasterSlaveRouter']
ORM
- 参考python 元类简单实现orm 按住ctrl 跳转
生命周期
版本1
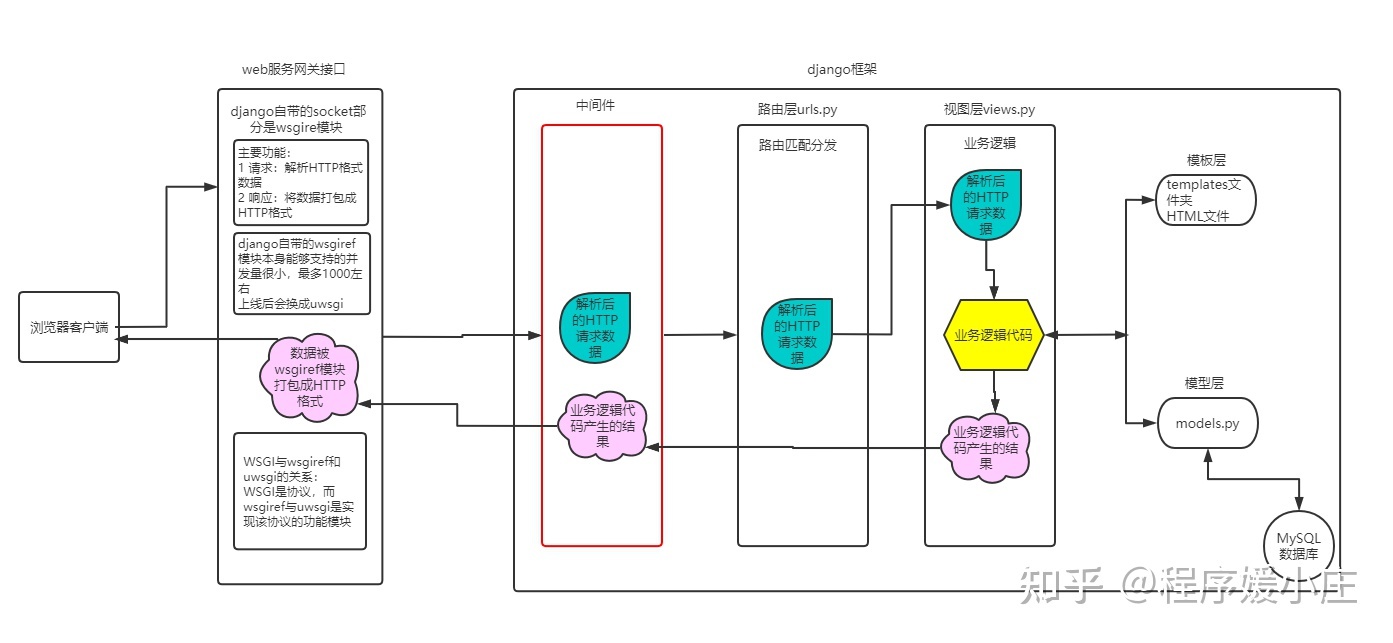
- 客户端浏览器向django服务端发送请求之后,首先回经过web网关接口,将客户端的请求解析成HTTP格式的数据封装到request对象中
- 解析后的数据回来到应用程序部分,首先会经过django的中间件,请求来的时候会经过每个中间件中的process_request方法,到达django后端
- 请求会经过路由层,在进行路由匹配后执行对应的视图函数,在经过视图函数的业务逻辑后会产生response对象
- 响应对象也会通过中间件中的每个process_response方法,回到web服务网关接口,将response对象打包成HTTP格式的数据返回给客户端浏览器
版本2
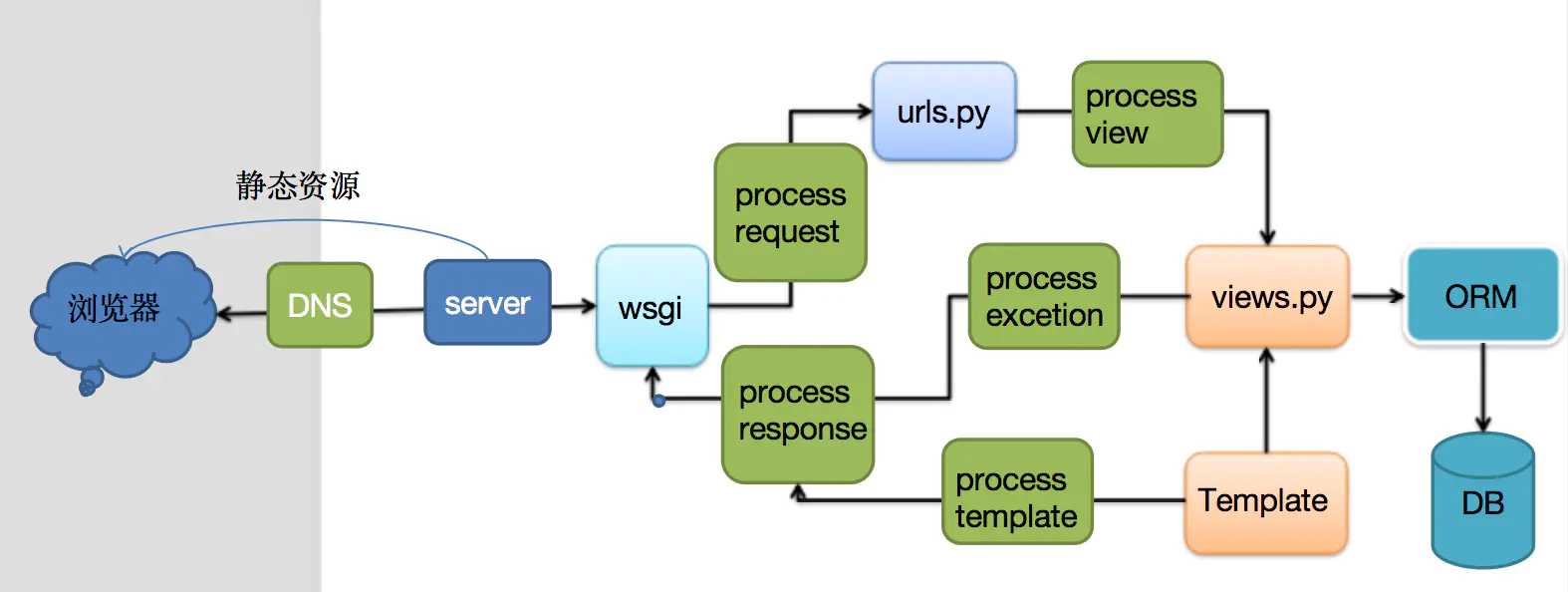
中间件
概述
- 中间件是一个用来处理Django的请求和响应的框架级别的钩子
- 它是一个轻量、低级别的插件系统,用于在全局范围内改变Django的输入和输出
- 每个中间件组件负责做一些特定的功能
五种方法
process_request
-
执行时间
- 在视图函数之前,在路由匹配之前
-
参数
- request:请求对象,与视图中用到的request参数是同一个对象
-
返回值
- None:按照正常的流程走
- HttpResponse:接着倒序执行当前中间件的以及之前执行过的中间件的process_response方法,不再执行其它的所有方法
-
执行顺序
- 按照MIDDLEWARE中的注册的顺序执行,也就是此列表的索引值
process_response
- 执行时间
- 最后执行
- 参数
- request:请求对象,与视图中用到的request参数是同一个对象
- response:响应对象,与视图中返回的response是同一个对象
- 返回值
- response:必须返回此对象,按照正常的流程走
- 执行顺序
- 按照注册的顺序倒序执行
process_view
- 执行时间
- 在process_request方法及路由匹配之后,视图之前
- 参数
- request:请求对象,与视图中用到的request参数是同一个对象
- view_func:将要执行的视图函数(它是实际的函数对象,而不是函数的名称作为字符串)
- view_args:url路径中将传递给视图的位置参数的元组
- view_kwargs:url路径中将传递给视图的关键值参数的字典
- 返回值
- None:按照正常的流程走
- HttpResponse:它之后的中间件的process_view,及视图不执行,执行所有中间件的process_response方法
- 执行顺序
- 按照注册的顺序执行
process_template_response
- 此方法必须在视图函数返回的对象有一个render()方法(或者表明该对象是一个TemplateResponse对象或等价方法)时,才被执行
- 执行时间
- 视图之后,process_exception之前
- 参数
- request:请求对象,与视图中用到的request参数是同一个对象
- response:是TemplateResponse对象(由视图函数或者中间件产生)
- 返回值
- response:必须返回此对象,按照正常的流程走
- 执行顺序
- 按照注册的顺序倒序执行
process_exception
- 此方法只在视图中触发异常时才被执行
- 执行时间
- 视图之后,process_response之前
- 参数
- request:请求对象,与视图中用到的request参数是同一个对象
- exception:视图函数异常产生的Exception对象
- 返回值
- None:按照正常的流程走
- HttpResponse对象:不再执行后面的process_exception方法
- 执行顺序
- 按照注册的顺序倒序执行
MVC/MTV
MVC模型
- Web服务器开发领域里著名的MVC模式
- MVC就是把Web应用分为 模型(M),控制器© 视图(V) 三层,他们之间以一种插件式的、松耦合的方式连接在一起
- 模型负责业务对象与数据库的映射(ORM)
- 视图负责与用户的交互(页面)
- 控制器接受用户的输入调用模型和视图完成用户的请求
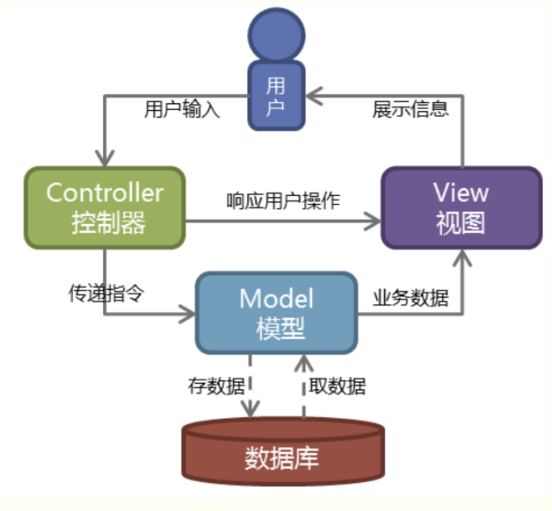
MTV模型
- Django的MTV分别代表:
- Model(模型):负责业务对象与数据库的对象(ORM)
- Template(模版):负责如何把页面展示给用户
- View(视图):负责业务逻辑,并在适当的时候调用Model和Template
- 此外,Django还有一个urls分发器,它的作用是将一个个URL的页面请求分发给不同的view处理,view再调用相应的Model和Template
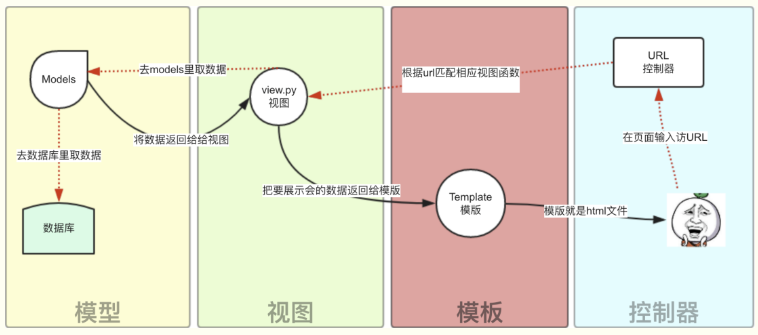
路由分发
- Django 的 url 路由分发:解析请求的url,匹配找到对应的view函数来处理
# test/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('app01/',include('app01.urls')),
path('app02/',include('app02.urls')),
path('admin/', admin.site.urls),
]
# app01/urls.py
from django.urls import path
from app01 import views
urlpatterns = [
path('index/',views.index),
]
# app02/urls.py
from django.urls import path
from app02 import views
urlpatterns = [
path('index/',views.index),
]
F/Q查询
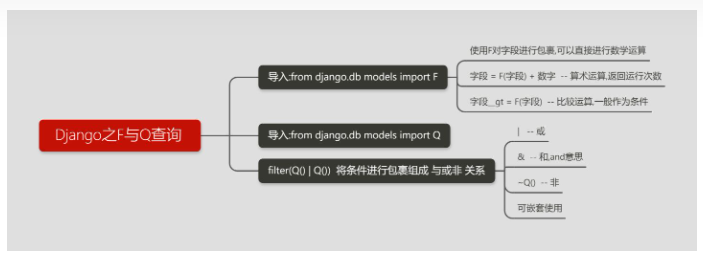
F 查询
-
使用 F 对字段进行包裹,可以直接进行数学运算
-
from django.db.models import F,Q # 查询评论数大于阅读数的书籍 res = models.Bbook.objects.all().filter(commit_num__gt=F('read_num')) # 查询评论数大于阅读数2倍的书籍 res = models.Bbook.objects.all().filter(commit_num__gt=F('read_num')*2)
Q查询
-
Q查询:制造 与或非 的条件,filter(Q() | Q()) 将条件进行包裹组成 与或非 关系
-
from django.db.models import F,Q # 查询作者名字是猎虎或者价格大于5000的书 -- 或 | res = models.Bbook.objects.filter(Q(authors__name='猎虎')|Q(price__gt=5000)) # 查询作者名字是猎虎并且价格大于5000的书 -- 与 & res = models.Bbook.objects.filter(Q(authors__name='猎虎') & Q(price__gt=5000)) or res = models.Bbook.objects.filter(Q(authors__name='猎虎', price__gt=5000)) # 查询作者名字不是猎虎的书 -- 非 ~ res = models.Bbook.objects.filter(~Q(authors__name='猎虎')) # Q 可以嵌套 res = models.Bbook.objects.filter((Q(authors__name='猎虎') & Q(price__gt=100)) | Q(id__lt=29))
信号量
信号量定义
- Django 提供一个了“信号分发器”机制,允许解耦的应用在框架的其它地方发生操作时会被通知到。
- Django自带一套信号机制来帮助我们在框架的不同位置之间传递信息。
- 也就是说,当某一事件发生时,信号系统可以允许一个或多个发送者(senders)将通知或信号(signals)发送给一组接受者(receivers)。
信号量使用场景
- Django信号的应用场景很多,尤其是用于不同模型或程序间的联动。
- 常见例子包括创建User对象实例时创建一对一关系的UserProfile对象实例,或者每当用户下订单时触发给管理员发邮件的动作。
常用内置信号
- django.db.models.signals.pre_save & post_save在模型调用 save()方法之前或之后发送。
- django.db.models.signals.pre_delete & post_delete在模型调用delete()方法或查询集调用delete() 方法之前或之后发送。
- django.core.signals.request_started & request_finished Django建立或关闭HTTP 请求时发送。
示例:利用信号实现不同模型的联动更新
-
假设我们有一个Profile模型,与User模型是一对一的关系。
我们希望创建User对象实例时也创建Profile对象实例,而使用post_save更新User对象时不创建新的Profile对象。
这时我们就可以自定义create_user_profile和save_user_profile两个监听函数,同时监听sender(User模型)发出的post_save信号。
由于post_save可同时用于模型的创建和更新,我们用if created这个判断来加以区别。
from django.db import models
from django.db.models.signals import post_save
from django.dispatch import receiver
class Profile(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE)
birth_date = models.DateField(null=True, blank=True)
@receiver(post_save, sender=User)
def create_user_profile(sender, instance, created, **kwargs):
if created:
Profile.objects.create(user=instance)
@receiver(post_save, sender=User)
def save_user_profile(sender, instance, **kwargs):
instance.profile.save()
DRFTODO
FlaskTODO
cookie session token
跨域认证
- 互联网服务离不开用户认证。流程如下
1、用户向服务器发送用户名和密码
2、服务器验证通过后,在当前对话(session)里面保存相关数据,比如用户角色、登录时间等等
3、服务器向用户返回一个 session_id,写入用户的 Cookie
4、用户随后的每一次请求,都会通过 Cookie,将 session_id 传回服务器
5、服务器收到 session_id,找到前期保存的数据,由此得知用户的身份
-
这种模式的问题在于,扩展性(scaling)不好
单机当然没有问题,如果是服务器集群,或者是跨域的服务导向架构,就要求 session 数据共享,每台服务器都能够读取 session
-
举例来说
-
A 网站和 B 网站是同一家公司的关联服务。现在要求,用户只要在其中一个网站登录,再访问另一个网站就会自动登录,请问怎么实现?
-
一种解决方案是 session 数据持久化,写入数据库或别的持久层
各种服务收到请求后,都向持久层请求数据
这种方案的优点是架构清晰,缺点是工程量比较大。另外,持久层万一挂了,就会单点失败
-
另一种方案是服务器索性不保存 session 数据了,所有数据都保存在客户端,每次请求都发回服务器。JWT 就是这种方案的一个代表
-
cookie
-
一个 Web 站点可能会为每一个访问者产生一个唯一的ID, 然后以 Cookie 文件的形式保存在每个用户的机器上。
HTTP协议本身是无状态的,服务器无法判断用户身份。Cookie实际上是一小段的文本信息(key-value格式)。
客户端向服务器发起请求,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。
客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。
服务器检查该Cookie,以此来辨认用户状态。
-
当用户第一次访问并登陆一个网站的时候,cookie的设置以及发送会经历以下4个步骤:
- 客户端发送一个请求到服务器
- 服务器发送一个HttpResponse响应到客户端,其中包含Set-Cookie的头部
- 客户端保存cookie,之后向服务器发送请求时,HttpRequest请求中会包含一个Cookie的头部
- 服务器返回响应数据
-
Cookie只能被放置它的网站读取。这一点是浏览器保证的,这也是浏览器的一个重要的安全机制。
session
-
在计算机中,尤其是在网络应用中,称为“会话控制”。Session对象存储特定用户会话所需的属性及配置信息,存储到服务器。
服务器为了保存用户状态而创建的一个特殊的对象,在无连接(HTTP)协议基础之上实现在用户状态管理。
-
当浏览器第一次访问服务器时,服务器创建一个session对象(该对象有一个唯一的id,一般称之为sessionId)
服务器会将sessionId 以cookie的方式发送给浏览器。
当浏览器再次访问服务器时,会将sessionId发送过来,服务器依据 sessionId就可以找到对应的session对象。
-
cookie和session都是用来保存用户状态的,cookie在客户端,session在服务器端,所以也会占用服务器资源
session虽然数据是保存在服务器端,但是客户端也会存一个cookie文件存放sessionId
token
-
Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需
带上这个Token前来请求数据即可,无需再次带上用户名和密码。
-
使用Token的目的:
Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
-
token在服务器时可以不用存储用户信息的,token传递的方式也不限于cookie传递,token也可以保存起来。
session的存储是需要空间的,session的传输一般都是通过cookie来传输,或url重写的方式。
-
token的生成方式
浏览器第一次访问服务器时,会传过来一个唯一表示ID,服务端通过算法,加密钥,生成一个token。
通过BASE64编码后将 token 发送给客户端。
客户端将token保存起来,下次请求带着token,服务器收到请求会用相同的算法取验证toekn,如果通过就继续执行。
token组成
- uid (用户唯一的身份标识)
- time (当前时间的时间戳)
- sign (签名,由token的前几位+盐以哈希算法压缩成一定长的十六进制字符串,可以防止恶意第三方拼接token请求服务器)
-
token和session的区别
共同点:都是保存了用户身份信息,都有过期时间。
session翻译为会话,token翻译为令牌。
session是空间换时间,token是时间换空间。
session和sessionid:服务器会保存一份,可能保存到缓存/数据库/文件。
token:服务器不需要记录任何东西,每次都是一个无状态的请求,每次都是通过解密来验证是否合法。
sessionid:一般是随机字符串,要到服务器检索id的有效性。
jwt 原理
简介
-
**JSON Web Token(缩写 JWT)**是目前最流行的跨域认证解决方案
-
实施 Token 验证的方法挺多的,还有一些标准方法,比如 JWT,表示:JSON Web Tokens 。JWT 标准的 Token 有三个部分:
- header(头部),头部信息主要包括(参数的类型–JWT,签名的算法–HS256)
- poyload(负荷),负荷基本就是自己想要存放的信息 (因为信息会暴露,不应该在载荷里面加入任何敏感的数据)
- sign(签名),签名的作用就是为了防止恶意篡改数据
-
中间用点分隔开,并且都会使用 Base64 编码,所以真正的 Token 看起来像这样:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJuaW5naGFvLm5ldCIsImV4cCI6IjE0Mzg5NTU0NDUiLCJuYW1lIjoid2FuZ2hhbyIsImFkbWluIjp0cnVlfQ.SwyHTEx_RQppr97g4J5lKXtabJecpejuef8AqKYMAJc
Header
-
Header 部分主要是两部分内容,一个是 Token 的类型,另一个是使用的算法,比如下面类型就是 JWT,使用的算法是 HS256。
{ "typ" : "JWT", "alg" : "HS256" } # Base64 编码 eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9
Payload
-
Payload 里面是 Token 的具体内容,这些内容里面有一些是标准字段,你也可以添加其它需要的内容。
iss:Issuer,发行者 sub:Subject,主题 aud:Audience,观众 exp:Expiration time,过期时间 nbf:Not before iat:Issued at,发行时间 jti:JWT ID # iss 发行人,exp 过期时间,自定义的字段 name,admin { "iss" : "csdn.net", "exp" : "201511205211314", "name" : "维C果糖", "admin" : true } # Base64 编码 eyJpc3MiOiJuaW5naGFvLm5ldCIsImV4cCI6IjE0Mzg5NTU0NDUiLCJuYW1lIjoid2FuZ2hhbyIsImFkbWluIjp0cnVlfQ
Signature
-
JWT 的最后一部分是 Signature ,这部分内容有三个部分,先是用 Base64 编码的 header 和 payload ,再用加密算法加密一下,加密的时候要放进去一个 Secret ,这个相当于是一个密码,这个密码秘密地存储在服务端。
header payload secret var encodedString = base64UrlEncode(header) + "." + base64UrlEncode(payload); HMACSHA256(encodedString, 'secret'); # HMACSHA256 SwyHTEx_RQppr97g4J5lKXtabJecpejuef8AqKYMAJc # token eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJuaW5naGFvLm5ldCIsImV4cCI6IjE0Mzg5NTU0NDUiLCJuYW1lIjoid2FuZ2hhbyIsImFkbWluIjp0cnVlfQ.SwyHTEx_RQppr97g4J5lKXtabJecpejuef8AqKYMAJc
详细参考资料: JSON Web Token 入门教程 - 阮一峰的网络日志 (ruanyifeng.com)
Web安全
-
Token,我们称之为“令牌”,其最大的特点就是随机性,不可预测。一般黑客或软件无法猜测出来。
-
Token 一般用在两个地方:
- 防止表单重复提交
- Anti CSRF 攻击(跨站点请求伪造)
-
两者在原理上都是通过 session token 来实现的。当客户端请求页面时,服务器会生成一个随机数 Token,并且将 Token 放置到 session 当中,然后将
Token 发给客户端(一般通过构造 hidden 表单)。下次客户端提交请求时,Token 会随着表单一起提交到服务器端。
-
如果应用于“Anti CSRF攻击”,则服务器端会对 Token 值进行验证,判断是否和session中的Token值相等,若相等,则可以证明请求有效,不是伪造的。
不过,如果应用于“防止表单重复提交”,服务器端第一次验证相同过后,会将 session 中的 Token 值更新下,若用户重复提交,第二次的验证判断将失败,
因为用户提交的表单中的 Token 没变,但服务器端 session 中 Token 已经改变了。
-
上面的 session 应用相对安全,但也叫繁琐,同时当多页面多请求时,必须采用多 Token 同时生成的方法,这样占用更多资源,执行效率会降低。
因此,也可用 cookie 存储验证信息的方法来代替 session Token。比如,应对“重复提交”时,当第一次提交后便把已经提交的信息写到 cookie 中,当第二次
提交时,由于 cookie 已经有提交记录,因此第二次提交会失败。
不过,cookie 存储有个致命弱点,如果 cookie 被劫持(XSS 攻击很容易得到用户 cookie),那么又一次 game over,黑客将直接实现 CSRF 攻击。
-
此外,要避免“加 token 但不进行校验”的情况,在 session 中增加了 token,但服务端没有对 token 进行验证,这样根本起不到防范的作用。还需注意的是,
对数据库有改动的增、删、改操作,需要加 token 验证,对于查询操作,一定不要加 token,防止攻击者通过查询操作获取 token 进行 CSRF攻击。但并不是
这样攻击者就无法获得 token,只是增大攻击成本而已。
Mysql
查询优化
- 通过慢查询日志发现速度慢的sql,使用 explain 分析慢 sql
-
示例1:
-
like 区分大小写 LIKE BINARY ‘110%’
- 模糊查询是区分大小的,导致查询效率变慢(类似严格匹配)
-
like 不区分大小写 LIKE ‘110%’
- 大小写不敏感查询速度提升很大,sql 执行效率高
-
-
示例2:
- 多个字段条件查询(字段均建立索引),单个条件数据量最少的应放在最前面,提高 sql 查询效率
- 公司某项目中查询接口没考虑字段顺序,导致接口响应30s
- 多个字段条件查询(字段均建立索引),单个条件数据量最少的应放在最前面,提高 sql 查询效率
-
示例3:
- 多个字段条件查询(字段均建立索引),sql 查询未正确使用索引,接口响应时间过长,可以通过强制指定索引优化
-
索引原理
简介
-
什么是索引
- 索引(在MySQL中也叫“键key”)是存储引擎快速找到记录的一种数据结构 ——《高性能MySQL》
-
索引设计的原则
-
适合索引的列是出现在where子句中的列,或者连接子句中指定的列
-
基数较小的类,索引效果较差,没有必要在此列建立索引
-
使用短索引
- 如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间
-
不要过度索引
- 索引需要额外的磁盘空间,并降低写操作的性能
- 在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长,所以只保持需要的索引有利于查询即可
-
-
B Tree 和 B+Tree
-
目前大部分数据库系统及文件系统都采用 B Tree 或其变种 B+Tree 作为索引结构
-
文件系统及数据库系统普遍采用 B Tree / B+Tree 的原因
-
一般来说,索引本身也很大,不可能全存内存,往往以索引文件的形式存在磁盘
-
索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是
在查找过程中磁盘I/O操作次数的渐进复杂度
-
索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数
-
-
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式不同,本节主要讨论 MyISAM 和 InnoDB 两个存储引擎的索引实现方式
-
-
最左前缀匹配原则
- 在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配
最左前缀匹配原理
简介
-
要想理解联合索引的最左匹配原则,先来理解下索引的底层原理
- 索引的底层是一颗B+树,那么联合索引的底层也就是一颗B+树,只不过联合索引的B+树节点中存储的是键值
- 由于构建一棵B+树只能根据一个值来确定索引关系,所以数据库依赖联合索引最左的字段来构建
-
示例
-
创建一个(a,b)的联合索引,那么它的索引树就是下图的样子
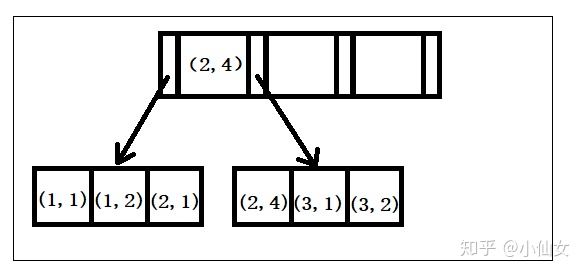
-
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2
但是我们又可发现a在等值的情况下,b值又是按顺序排列的,但是这种顺序是相对的
这是因为MySQL创建联合索引的规则是首先会对联合索引的最左边第一个字段排序,在第一个字段的排序基础上,然后在对第二个字段进行排序
所以 b=2 这种查询条件没有办法利用索引
-
由于整个过程是基于explain结果分析的,那接下来在了解下 explain 中的 type 字段和 key_lef 字段
-
type
- 联接类型(下面给出各种联接类型,按照从最佳类型到最坏类型进行排序:(重点看ref,rang,index))
- system:
- 表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,可以忽略不计
- const:
- 表示通过索引一次就找到了,const用于比较primary key 或者 unique索引
- 因为只需匹配一行数据,所有很快。如果将主键置于where列表中,mysql就能将该查询转换为一个const
- eq_ref:
- 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描
- 注意:ALL全表扫描的表记录最少的表如t1表
- ref:
- 非唯一性索引扫描,返回匹配某个单独值的所有行
- 本质是也是一种索引访问,它返回所有匹配某个单独值的行,然而他可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体
- range:
- 只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引
- 一般就是在where语句中出现了bettween、<、>、in等的查询
- 这种索引列上的范围扫描比全索引扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引
- index:
- Full Index Scan,index与ALL区别为index类型只遍历索引树
- 这通常为ALL块,应为索引文件通常比数据文件小(Index与ALL虽然都是读全表,但index是从索引中读取,而ALL是从硬盘读取)
- ALL:
- Full Table Scan,遍历全表以找到匹配的行
- system:
key_len
-
显示MySQL实际决定使用的索引的长度
-
如果索引是NULL,则长度为NULL。如果不是NULL,则为使用的索引的长度。所以通过此字段就可推断出使用了那个索引
-
计算规则:
-
定长字段,int占用4个字节,date占用3个字节,char(n)占用n个字符
-
变长字段varchar(n),则占用n个字符+两个字节
-
不同的字符集,一个字符占用的字节数是不同的
Latin1编码的,一个字符占用一个字节,gdk编码的,一个字符占用两个字节,utf-8编码的,一个字符占用三个字节
-
对于所有的索引字段,如果设置为NULL,则还需要1个字节
-
示例
- 创建表
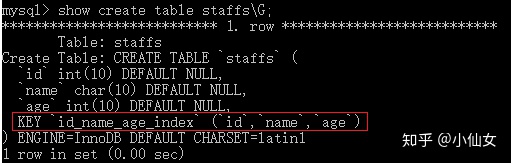
- 表中对id列、name列、age列建立了一个联合索引 id_name_age_index,实际上相当于建立了三个索引(id)(id_name)(id_name_age)
全值匹配查询
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vvkX1S9Y-1673840082942)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/mysql_index_03.jpg)]


-
通过观察上面的结果可知,where后面的查询条件,不论是使用(id,age,name)(name,id,age)还是(age,name,id)顺序
在查询时都使用到了联合索引, 这是因为MySQL中有查询优化器explain,所以sql语句中字段的顺序不需要和联合索引定义的字段顺序相同
查询优化器会判断纠正这条SQL语句以什么样的顺序执行效率高,最后才能生成真正的执行计划,所以不论以何种顺序都可使用到联合索引
另外通过观察上面三个图中的key_len字段,也可说明在搜索时使用的联合索引中的(id_name_age)索引,因为id为int型,允许null,所以占5个字节
name为char(10),允许null,又使用的是latin1编码,所以占11个字节,age为int型允许null,所以也占用5个字节,所以该索引长度为21(5+11+5)
而上面key_len的值也正好为21,可证明使用的(id_name_age)索引
匹配最左列

-
该搜索是遵循最左匹配原则的
通过key字段也可知,在搜索过程中使用到了联合索引,且使用的是联合索引中的(id)索引,因为key_len字段值为5,而id索引的长度正好为5

-
由于id到name是从左边依次往右边匹配,这两个字段中的值都是有序的,所以也遵循最左匹配原则
通过key字段可知,在搜索过程中也使用到了联合索引,但使用的是联合索引中的(id_name)索引

- 由于上面三个搜索都是从最左边id依次向右开始匹配的,所以都用到了id_name_age_index联合索引

-
通过key字段可知,在搜索过程中也使用到了联合索引,但使用的是联合索引中的(id)索引,从key_len字段也可知
因为联合索引树是按照id字段创建的,但age相对于id来说是无序的,只有id只有序的,所以他只能使用联合索引中的id索引

-
通过观察发现上面key字段发现在搜索中也使用了id_name_age_index索引
可能许多同学就会疑惑它并没有遵守最左匹配原则,按道理会索引失效,为什么也使用到了联合索引?
因为没有从id开始匹配,且name单独来说是无序的,所以它确实不遵循最左匹配原则,然而从type字段可知,它虽然使用了联合索引,但是它是对整个索引
树进行了扫描,正好匹配到该索引,与最左匹配原则无关,一般只要是某联合索引的一部分,但又不遵循最左匹配原则时,都可能会采用index类型的方式扫
描,但它的效率远不如最做匹配原则的查询效率高,index类型类型的扫描方式是从索引第一个字段一个一个的查找,直到找到符合的某个索引,与all不同的
是,index是对所有索引树进行扫描,而all是对整个磁盘的数据进行全表扫描


- 这两个结果跟上面的是同样的道理,由于它们都没有从最左边开始匹配,所以没有用到联合索引,使用的都是index全索引扫描
匹配列前缀
- 如果id是字符型,那么前缀匹配用的是索引,中坠和后缀用的是全表扫描
- **select * from staffs where id like ‘A%’; ** // 前缀都是排好序的,使用的都是联合索引
- select * from staffs where id like ‘%A%’; // 全表查询
- select * from staffs where id like ‘%A’; // 全表查询
匹配范围值

-
在匹配的过程中遇到 <>= 号,就会停止匹配
id本身就是有序的,所以通过 possible_keys 字段和 key_len 字段可知,在该搜索过程中使用了联合索引的id索引,且进行的是range范围查询
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J1G1Y0UC-1673840082948)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/mysql_index_14.jpg)]
- 由于不遵循最左匹配原则,且在id<4的范围中,age是无序的,所以使用的是 index 全索引扫描

- 不遵循最左匹配原则,但在数据库中id<2的只有一条(id),所以在id<2的范围中,age是有序的,所以使用的是range范围查询

- 不遵循最左匹配原则,而age又是无序的,所以使用的是 index 全索引扫描
准确匹配第一列并范围匹配其他某一列

- 由于搜索中有id=1,所以在id范围内age是无序的,所以只使用了联合索引中的id索引
参考资料:https://zhuanlan.zhihu.com/p/142852474
MyISAM索引实现
- MyISAM引擎使用B+Tree作为索引结构,叶节点data域存放数据记录的地址
InnoDB索引实现
-
InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同
-
第一个重大区别是InnoDB的数据文件本身就是索引文件,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址
在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录,这个索引的key是数据表的主键,
因此InnoDB表数据文件本身就是主索引
-
第二个与MyISAM索引的不同是InnoDB的辅索引data域存储相应记录主键的值而不是地址
换句话说,InnoDB的所有辅助索引都引用主键作为data域
-
索引优化
-
查看索引详情
- SHOW INDEX FROM table_name;
-
索引类型
- 主键索引 PRIMARY KEY
- 它是一种特殊的唯一索引,不允许有空值
- 一般是在建表的时候同时创建主键索引
- 注意:一个表只能有一个主键
- 唯一索引 UNIQUE
- 唯一索引列的值必须唯一,但允许有空值
- 如果是组合索引,则列值的组合必须唯一
- 创建唯一索引 ALTER TABLE table_name ADD UNIQUE (column);
- 创建唯一组合索引 ALTER TABLE table_name ADD UNIQUE (column1,column2);
- 普通索引 INDEX
- 这是最基本的索引,它没有任何限制
- 创建普通索引 ALTER TABLE table_name ADD INDEX index_name (column);
- 组合索引 INDEX
- 即一个索引包含多个列,多用于避免回表查询
- 创建组合索引 ALTER TABLE table_name ADD INDEX index_name(column1,column2, column3);
- 全文索引 FULLTEXT
- 也称全文检索,是目前搜索引擎使用的一种关键技术
- 创建全文索引 ALTER TABLE table_name ADD FULLTEXT (column);
- 主键索引 PRIMARY KEY
-
删除索引
- 索引一经创建不能修改,如果要修改索引,只能删除重建
- 删除索引 DROP INDEX index_name ON table_name;
-
命中索引
-
返回表中30%内的数据会走索引,返回超过30%数据就使用全表扫描
当然这个结论太绝对了,也并不是绝对的30%,只是一个大概的范围
-
-
回表
-
当对一个列创建索引之后,索引会包含该列的键值及键值对应行所在的rowid。通过索引中记录的rowid访问表中的数据就叫回表
回表次数太多会严重影响SQL性能,如果回表次数太多,就不应该走索引扫描,应该直接走全表扫描
EXPLAIN 命令结果中的 **Using Index **意味着不会回表,通过索引就可以获得主要的数据。Using Where 则意味着需要回表取数据
-
-
索引优化规则
-
如果MySQL估计使用索引比全表扫描还慢,则不会使用索引
返回数据的比例是重要的指标,比例越低越容易命中索引。记住这个范围值——30%
-
前导模糊查询不能命中索引
- EXPLAIN SELECT * FROM user WHERE name LIKE ‘%s%’;
-
非前导模糊查询则可以使用索引,可优化为使用非前导模糊查询
- EXPLAIN SELECT * FROM user WHERE name LIKE ‘s%’;
-
数据类型出现隐式转换的时候不会命中索引,特别是当列类型是字符串,一定要将字符常量值用引号引起来
- 发生隐式转换,不命中索引 EXPLAIN SELECT * FROM user WHERE name=1;
- 命中索引 EXPLAIN SELECT * FROM user WHERE name=‘1’;
-
复合索引的情况下,查询条件不包含索引列最左边部分(不满足最左前缀原则),不会命中符合索引
-
name,age,status 列创建复合索引
ALTER TABLE user ADD INDEX index_name (name,age,status);
-
根据最左原则,可以命中复合索引 index_name
EXPLAIN SELECT * FROM user WHERE name=‘swj’ AND status=1;
-
最左原则并不是说是查询条件的顺序,而是查询条件中是否包含索引最左列字段
可命中 EXPLAIN SELECT * FROM user WHERE status=1 AND name=‘swj’;
不命中 EXPLAIN SELECT * FROM user WHERE status=2 ;
-
-
负向条件查询不能使用索引,可以优化为 in 查询
负向条件有:** !=、not in、not exists、not like** 等
-
范围条件查询可以命中索引
范围条件有:** <、<=、>、>=、between** 等
-
范围条件查询可以命中索引
EXPLAIN SELECT * FROM user WHERE status>5;
-
范围列可以用到索引(联合索引必须是最左前缀),但是范围列后面的列无法用到索引,索引最多用于一个范围列
如果查询条件中有两个范围列则无法全用到索引
EXPLAIN SELECT * FROM user WHERE status>5 AND age<24;
-
如果是范围查询和等值查询同时存在,优先匹配等值查询列的索引
EXPLAIN SELECT * FROM user WHERE status>5 AND age=24;
-
-
数据库执行计算不会命中索引
- 命中:EXPLAIN SELECT * FROM user WHERE age>24;
- 未命中:EXPLAIN SELECT * FROM user WHERE age+1>24;
- 计算逻辑应该尽量放到业务层处理,节省数据库的CPU的同时最大限度的命中索引
-
利用覆盖索引进行查询,避免回表
-
被查询的列,数据能从索引中取得,而不用通过行定位符row-locator再到row上获取,即“被查询列要被所建的索引覆盖”,这能够加速查询速度
-
当查询其他列时,就需要回表查询,这也是为什么要避免 SELECT* 的原因之一
EXPLAIN SELECT * FROM user where status=1;
-
-
建立索引的列,不允许为null
-
单列索引不存null值,复合索引不存全为null的值,如果列允许为null,可能会得到“不符合预期”的结果集,所以,请使用not null约束以及默认值
-
IS NULL可以命中索引
EXPLAIN SELECT * FROM user WHERE remark IS NULL;
-
IS NOT NULL不能命中索引
EXPLAIN SELECT * FROM user WHERE remark IS NOT NULL;
-
-
-
总结
- 更新十分频繁的字段上不宜建立索引
- 区分度不大的字段上不宜建立索引
- 业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引
- 多表关联时,要保证关联字段上一定有索引
- 创建索引时避免以下错误观念:索引越多越好,认为一个查询就需要建一个索引
- 对于自己编写的SQL查询语句,要尽量使用EXPLAIN命令分析一下,做一个对SQL性能有追求的程序员
主从复制读写分离
主从复制
目的
- 主从复制、读写分离就是为了数据库能支持更大的并发
原理
- 当Master节点进行insert、update、delete操作时,会按顺序写入到 binlog (二进制日志) 中
- salve从库连接master主库,Master有多少个slave就会创建多少个binlog dump线程
- 当Master节点的binlog发生变化时,binlog dump 线程会通知所有的salve节点,并将相应的binlog内容推送给slave节点
- I/O线程接收到 binlog 内容后,将内容写入到本地的 relay-log (中继日志)
- SQL线程读取I/O线程写入的relay-log,并且根据 relay-log 的内容对从数据库做对应的操作
实现
简介
-
用三台虚拟机(Linux)演示,IP分别是104(Master),106(Slave),107(Slave)
预期的效果是一主二从
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nw0pl1xr-1673840082950)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/mysql_master_slave_02.jpg)]
Master
- 使用命令行进入mysql:
mysql -u root -p
- 接着输入root用户的密码(密码忘记的话就网上查一下重置密码吧~),然后创建用户:
// 192.168.0.106是slave从机的IP
GRANT REPLICATION SLAVE ON *.* to 'root'@'192.168.0.106' identified by 'Java@1234';
// 192.168.0.107是slave从机的IP
GRANT REPLICATION SLAVE ON *.* to 'root'@'192.168.0.107' identified by 'Java@1234';
// 刷新系统权限表的配置
FLUSH PRIVILEGES;
-
创建的这两个用户在配置slave从机时要用到
-
接下来在找到mysql的配置文件/etc/my.cnf,增加以下配置:
# 开启binlog
log-bin=mysql-bin
server-id=104
# 需要同步的数据库,如果不配置则同步全部数据库
binlog-do-db=test_db
# binlog日志保留的天数,清除超过10天的日志
# 防止日志文件过大,导致磁盘空间不足
expire-logs-days=10
- 配置完成后,重启mysql:
service mysql restart
- 可以通过命令行
show master status\G;查看当前binlog日志的信息(后面有用)
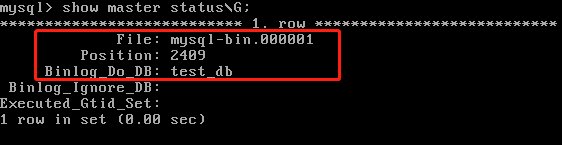
Slave
- Slave配置相对简单一点。从机肯定也是一台MySQL服务器,所以和Master一样,找到/etc/my.cnf配置文件,增加以下配置:
# 不要和其他mysql服务id重复即可
server-id=106
- 接着使用命令行登录到mysql服务器:
mysql -u root -p
- 然后输入密码登录进去,进入到mysql后,再输入以下命令:
CHANGE MASTER TO
MASTER_HOST='192.168.0.104', // 主机IP
MASTER_USER='root', // 之前创建的用户账号
MASTER_PASSWORD='Java@1234', // 之前创建的用户密码
MASTER_LOG_FILE='mysql-bin.000001', // master主机的binlog日志名称
MASTER_LOG_POS=862, // binlog日志偏移量
master_port=3306; // 端口
- 还没完,设置完之后需要启动:
# 启动slave服务
start slave;
- 启动完之后怎么校验是否启动成功呢?使用以下命令:
show slave status\G;
- 可以看到如下信息(摘取部分关键信息):
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.0.104
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 619
Relay_Log_File: mysqld-relay-bin.000001
Relay_Log_Pos: 782
Relay_Master_Log_File: mysql-bin.000001 // binlog日志文件名称
Slave_IO_Running: Yes // Slave_IO线程、SQL线程都在运行
Slave_SQL_Running: Yes
Master_Server_Id: 104 // master主机的服务id
Master_UUID: 0ab6b3a6-e21d-11ea-aaa3-080027f8d623
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Auto_Position: 0
- 另一台slave从机配置一样,不再赘述
测试
- 在master主机执行sql:
CREATE TABLE `tb_commodity_info` (
`id` varchar(32) NOT NULL,
`commodity_name` varchar(512) DEFAULT NULL COMMENT '商品名称',
`commodity_price` varchar(36) DEFAULT '0' COMMENT '商品价格',
`number` int(10) DEFAULT '0' COMMENT '商品数量',
`description` varchar(2048) DEFAULT '' COMMENT '商品描述',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品信息表';
- 接着我们可以看到两台slave从机同步也创建了商品信息表:
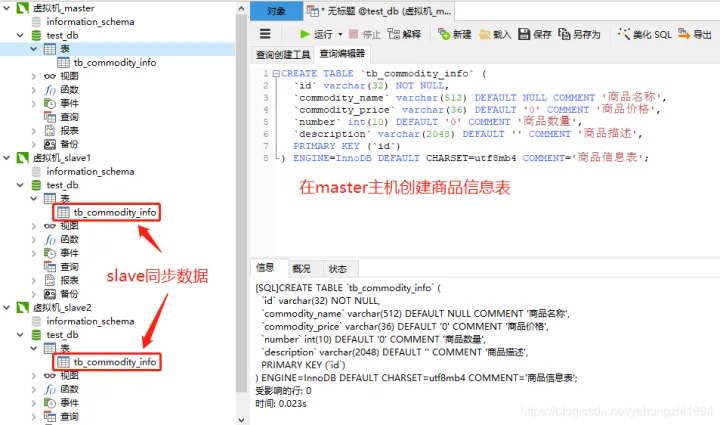
读写分离
- master负责写入数据,两台slave负责读取数据
实现方式
- Amoeba读写分离
- MySQL-Proxy读写分离是MySQL官方提供的中间件服务,支持无数客户端连接,后端可以连接多个Mysql-Server服务器
- Mycat读写分离
- 基于程序读写分离
悲观锁乐观锁
简介
-
乐观锁(Optimistic Locking)
- 对加锁持有一种乐观的态度,即先进行业务操作,不到最后一步不进行加锁,"乐观"的认为加锁一定会成功的,在最后一步更新数据的时候再进行加锁
-
悲观锁(Pessimistic Lock)
-
悲观锁对数据加锁持有一种悲观的态度。因此,在整个数据处理过程中,将数据处于锁定状态
悲观锁的实现,往往依靠数据库提供的锁机制
也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据
-
实现方式
-
乐观锁
-
version 方式
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一
当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,
否则重试更新操作,直到更新成功
-
sql 实现代码
update table set x=x+1, version=version+1 where id=#{id} and version=#{version};
-
CAS 操作方式
即compare and swap 或者 compare and set,涉及到三个操作数,数据所在的内存值,预期值,新值
当需要更新时,判断当前内存值与之前取到的值是否相等,若相等,则用新值更新,若失败则重试,一般情况下是一个自旋操作,即不断的重试
-
-
悲观锁
-
是由数据库自己实现,要用的时候,我们直接调用数据库的相关语句就可以了
原理:共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程,如行锁、读锁和写锁等,都是在操作之前加锁
在Java中,synchronized的思想也是悲观锁
-
使用场景
-
乐观锁
-
比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数
据,这样会增加大量的查询操作,降低了系统的吞吐量,因此一般乐观锁只用在高并发、多读少写的场景
-
-
悲观锁
-
比较适合写入操作比较频繁的场景,如果出现大量的读取操作,每次读取的时候都会进行加锁,这样会增加大量的锁的开销,降低了系统的吞吐量
如果要对一个具有锁属性的资源执行访问时,在更新操作时,需要持锁权才能进行操作,但是往往这种操作可以保证数据的一致性和完整性
例如数据库表的行锁
-
特点
-
乐观锁
-
乐观锁的特点先进行业务操作,不到万不得已不去拿锁
即“乐观”的认为拿锁多半是会成功的,因此在进行完业务操作需要实际更新数据的最后一步再去拿一下锁就好
-
-
悲观锁
-
悲观锁的特点是先获取锁,再进行业务操作
即“悲观”的认为获取锁是非常有可能失败的,因此要先确保获取锁成功再进行业务操作。通常所说的“一锁二查三更新”即指的是使用悲观锁
-
死锁
-
MySQL有三种锁的级别:页级、表级、行级
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
-
是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产
生了死锁,这些永远在互相等待的进程称为死锁进程。
-
死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
-
那么对应的解决死锁问题的关键就是:让不同的session加锁有次序。
-
举例来说A 事务持有x1锁 ,申请x2锁,B 事务持有x2锁,申请x1 锁。A和B 事务持有锁并且申请对方持有的锁进入循环等待,就造成死锁。
事务
简介
-
数据库通常借助日志来实现事务,常见的有undo log、redo log,undo/redo log都能保证事务特性,这里主要是原子性和持久性
即事务相关的操作,要么全做,要么不做,并且修改的数据能得到持久化
四大特性
-
原子性(Atomicity)
- 原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败
-
一致性(Consistency)
-
事务的执行不能破坏数据库的一致性,一致性也称为完整性
一个事务在执行后,数据库必须从一个一致性状态转变为另一个一致性状态
-
-
隔离性(Isolation)
- 事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离
-
持久性(Durability)
- 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
隔离级别
-
读未提交
-
在读未提交隔离级别下,事务A可以读取到事务B修改过但未提交的数据
可能发生脏读、不可重复读和幻读问题,一般很少使用此隔离级别
-
-
读已提交
-
在读已提交隔离级别下,事务B只能在事务A修改过并且已提交后才能读取到事务B修改的数据
读已提交隔离级别解决了脏读的问题,但可能发生不可重复读和幻读问题,一般很少使用此隔离级别
-
-
可重复读
-
在可重复读隔离级别下,事务B只能在事务A修改过数据并提交后,自己也提交事务后,才能读取到事务B修改的数据
可重复读隔离级别解决了脏读和不可重复读的问题,但可能发生幻读问题
-
提问:为什么上了写锁(写操作),别的事务还可以读操作?
因为InnoDB有MVCC机制(多版本并发控制),可以使用快照读,而不会被阻塞
-
-
可串行化
- 各种问题(脏读、不可重复读、幻读)都不会发生,通过加锁实现(读锁和写锁)
-
MySQL的默认隔离级别(可重复读)
- 通过多版本并发控制(MVCC,Multiversion Concurrency Control)解决了幻读的问题
脏读、幻读、不可重复读
-
脏读
-
事务能够看到其他事务没有提交的修改,当另一个事务又回滚了修改后的情况,被称为脏读 dirty read
-
会话B开启一个事务,把id=1的name为武汉市修改成温州市,此时另外一个会话A也开启一个事务,读取id=1的name,此时的查询结果为温州市,
会话B的事务最后回滚了刚才修改的记录,这样会话A读到的数据是不存在的,这个现象就是脏读。(脏读只在读未提交隔离级别才会出现)
-
-
不可重复读
-
一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值,这时会出现一个
事务内两次读取数据可能因为其他事务提交的修改导致不一致的情况,称为不可重复读(不可重复读在读未提交和读已提交隔离级别都可能会出现)
-
会话A开启一个事务,查询id=1的结果,此时查询的结果name为武汉市。接着会话B把id=1的name修改为温州市(隐式事务,因为此时的autocommit为
1,每条SQL语句执行完自动提交),此时会话A的事务再一次查询id=1的结果,读取的结果name为温州市。会话B再此修改id=1的name为杭州市,会话
A的事务再次查询id=1,结果name的值为杭州市,这种现象就是不可重复读
-
-
幻读
-
一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插
入的记录也读出来(幻读在读未提交、读已提交、可重复读隔离级别都可能会出现)
-
会话A开启一个事务,查询id>0的记录,此时会查到name=武汉市的记录。接着会话B插入一条name=温州市的数据(隐式事务,因为此时的autocommit
为1,每条SQL语句执行完自动提交),这时会话A的事务再以刚才的查询条件(id>0)再一次查询,此时会出现两条记录(name为武汉市和温州市的记
录),这种现象就是幻读
-
sql 注入
-
SQL 注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语
句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。
-
SQL注入的产生需要两个条件
-
传递给后端的参数是可以控制的
-
参数内容会被带入到数据库查询
-
-
SQL注入的防御
- 采用预编译技术
- 严格控制数据类型
- 对特殊的字符进行转义
表设计原则
-
数据库设计的三大范式:
-
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式
范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式
-
-
标准的数据库的表设计原则是:
-
“One Fact in One Place” 即某个表只包括其本身基本的属性,当不是它们本身所具有的属性时需进行分解
表之间的关系通过外键相连接
-
-
满足三大范式
- 第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解
- 第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性
- 第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余
-
表与表之间的关系
- 一对一、一对多、多对多
- 选择键和索引
-
键选择原则
- 关联字段创建外键并且唯一
- 使用系统生成的主键,设计数据库的时候采用系统生成的键作为主键,那么实际控制了数据库的索引完整性
-
索引使用原则
- 逻辑主键使用唯一的成组索引,对系统键(作为存储过程)采用唯一的非成组索引,对任何外键列采用非成组索引
- 索引外键也是经常使用的键,比如运行查询显示主表和所有关联表的某条记录就用得上
- 不要索引大型字段(有很多字符),这样作会让索引占用太多的存储空间
- 不要索引常用的小型表,假如经常有插入和删除操作,对这些插入和删除操作的索引维护可能比扫描表空间消耗更多的时间
-
-
数据库设计
- 表名,全部小写,采用简单的单词做前缀,用来区分业务
- 表中必须有 id, gmt_create, gmt_update 这三个字段
- 字段,小写字母加下划线组成,不用简写(用image,不用img)
- 字段名单词尽量简单,不用生僻单词,不用拼音
- 字段类型尽量选择小的,能用tinyint时不用int
- 字段要有注释
- 表编码采用UTF-8
MVCC
简介
- MySQL 架构,从概念上可以分为四层
- 接入层,不同语言的客户端通过mysql的协议与mysql服务器进行连接通信,接入层进行权限验证、连接池管理、线程管理等
- 服务层,包括sql解析器、sql优化器、数据缓冲、缓存等
- 存储引擎层,mysql中存储引擎是基于表的
- 系统文件层,保存数据、索引、日志等
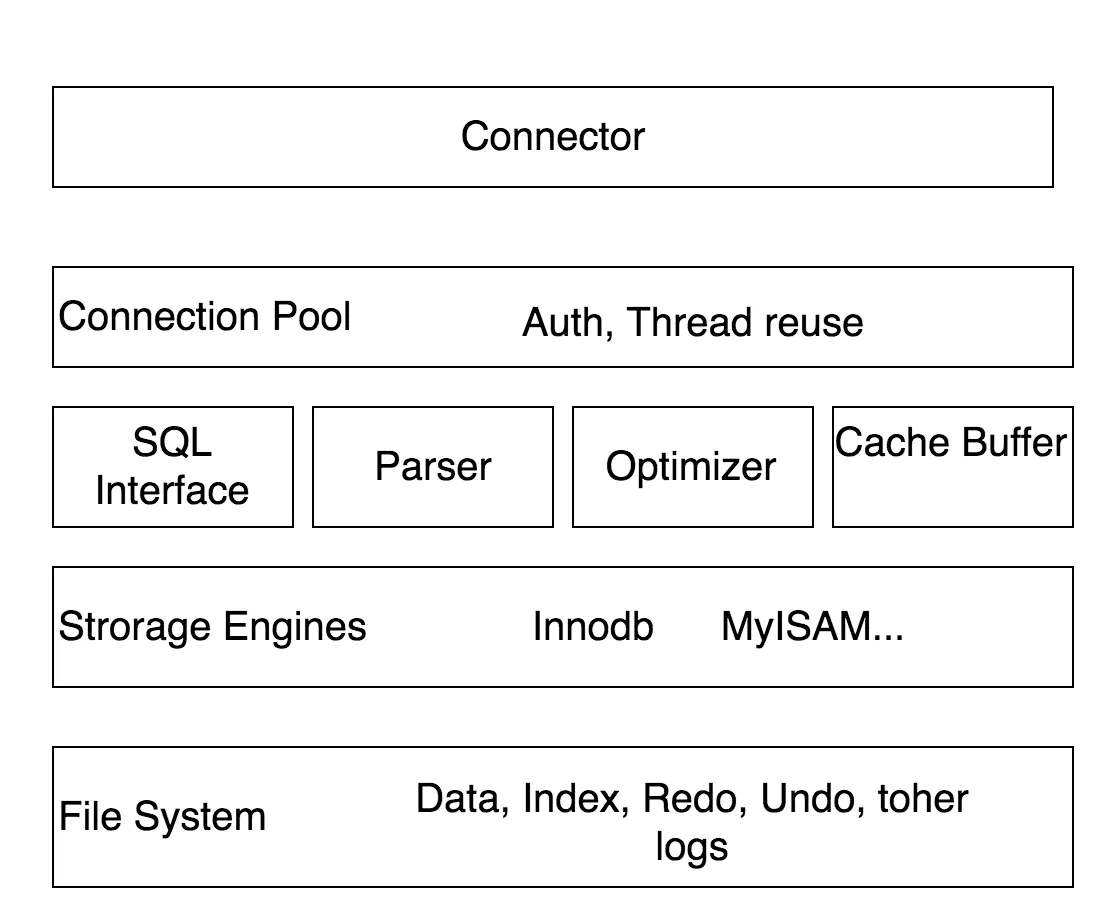
-
MVCC(Multi Version Concurrency Control的简称),代表多版本并发控制
与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control
-
MVCC最大的优势
- 读不加锁,读写不冲突
- 在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能
-
mysql 在可重复读隔离级别下事务的实现方式 – MVCC
-
实现原理 – undolog
-
Innodb的MVCC机制就是乐观锁的一种体现,读不加锁,读写不冲突
在不加锁的情况下能让多个事务进行并发读写,并且解决读写冲突问题,极大的提高系统的并发性
总结
-
mvcc在不加锁的情况下解决了脏读、不可重复读和快照读下的幻读问题,一定不要认为幻读完全是mvcc解决的
-
对当前读、快照读理解,简单点说加锁就是当前读,不加锁的就是快照读
-
mvcc实现的三大要素:两个隐式字段、回滚日志、read-view
-
两个隐式字段:
- DB_TRX_ID:记录创建这条记录最后一次修改该记录的事务ID
- DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本
-
undo log 在更新数据时会产生版本链,是read-view获取数据的前提
-
read-view当SQL执行查询语句时产生的,是由未提交的事务ID组成的数组和创建的最大事务ID组成的
-
mvcc可以解决脏读,不可重复读,mvcc使用快照读解决了部分幻读问题
但是在修改时还是使用当前读,所以还是存在幻读问题,幻读问题最终就是使用间隙锁解决
redolog
-
重做日志
-
redo log是指在回放日志的时候把已经COMMIT的事务重做一遍,对于没有commit的事务按照abort处理,不进行任何操作
-
要求数据库在写磁盘之前要把事务所有的操作都先记录下来
比如修改什么数据、数据物理上位于哪个内存页和磁盘块中、从什么值改成什么值等等,以日志的形式先写到磁盘中
只有在日志记录全部都安全落盘,然后在最后写上“Commit Record”后,表示所有的操作记录都写完了
这时候数据库才会根据日志上的信息,对真正的数据进行修改,修改完成后,在日志中加入一条“End Record”,事务持久化的工作也就做完了
这种事务实现方法被称为“Commit Logging”
-
-
实现数据持久性、原子性的原理
-
首先, 一旦日志成功写入了Commit Record,那就表示事务相关的所有信息都已经写到日志中了
如果修改数据的过程中系统崩溃了,重启后只要再根据日志的内容重新操作一遍就行了,这就保证了持久性
-
其次,如果日志还没写完系统就崩溃了,系统重启后,数据库一看日志里没有Commit Record,这话就说明日志是不全的,还没有写完
那么就将这部分日志标记为回滚状态,整个事务就回滚了,这就保证了原子性
换句话说就是,先把我要改的东西记录在日志里,再根据日志统一写到磁盘中,万一我在写入磁盘的过程中崩溃,等恢复的时候,先查看日志的完整性
如果日志是完整的,里面有Commit Record,我就照着日志重新做一遍,最后也能成功
如果日志是不完整的,里面没有Commit Record,我就回滚整个事务,什么都不做
-
这个日志就叫做 Redo Log,也就是“重做日志”,中途崩溃的数据库,根据这个日志把事务重做一遍
-
undolog
-
回滚日志
-
undo log是把所有没有COMMIT的事务回滚到事务开始前的状态
系统崩溃时,可能有些事务还没有COMMIT
在系统恢复时,这些没有COMMIT的事务就需要借助undo log来进行回滚
-
数据库对数据的所有真实修改,都必须发生在事务提交之后,并且在日志写入了 Commit Record 之后才能进行
没有写完Redo Log,数据库是不允许先写的
-
数据组成
-
在MySQL的设定中,同一个表空间内的一组连续的数据页为一个extent(区),默认区的大小为1MB,页的大小为16KB
16*64=1024,也就是说一个区里面会有64个连续的数据页
连续的256个数据区为一组数据区
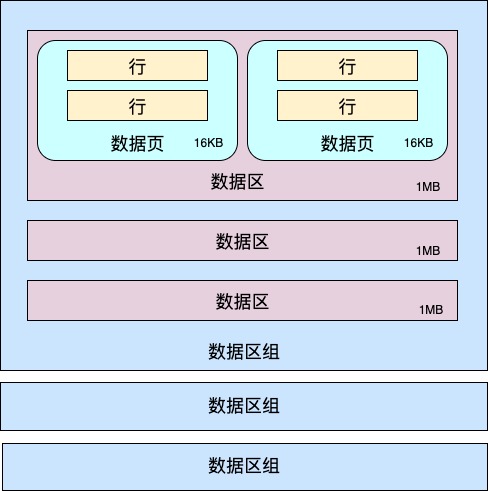
数据页分裂问题
-
假设你现在已经有两个数据页了。并且你正在往第二个数据页中写数据
关于B+Tree,你肯定知道B+Tree中的叶子结点之间是通过双向链表关联起来的
在InnoDB索引的设定中,要求主键索引是递增的,这样在构建索引树的时候才更加方便
如果按1、2、3…递增的顺序给你这些数。是不是很方便的构建一棵树。然后你可以自由自在的在这棵树上玩二分查找
那假设你自定义了主键索引,而且你自定义的这个主键索引并不一定是自增的
那就有可能出现下面这种情况 如下图:
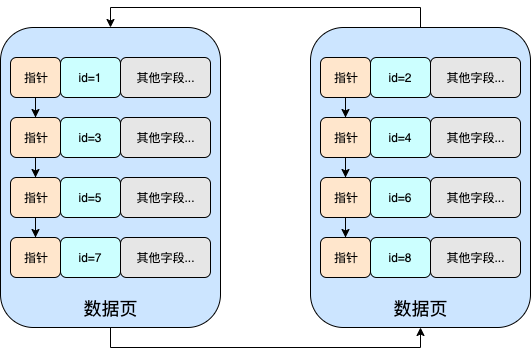
假设上图中的id就是你自定义的不会自增的主键
然后随着你将数据写入。就导致后一个数据页中的所有行并不一定比前一个数据页中的行的id大,这时就会触发页分裂的逻辑
-
页分裂的目的就是保证:后一个数据页中的所有行主键值比前一个数据页中主键值大
经过分裂调整,可以得到下面的这张图
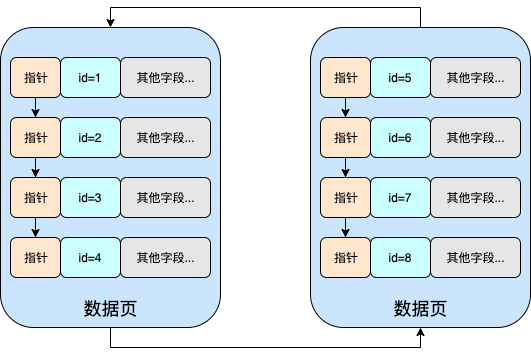
ES
简介
- Elasticsearch是一个近实时分布式搜索引擎,其底层基于开源全文搜索库Lucene;Elasticsearch对Lucene进行封装,对外提供REST API 的操作接口
- 基于 ES,可以快速的搭建全文搜索引擎;除了搜索功能,ES还可以对数据进行分析:如日志分析、指标分析,同时还提供了机器学习功能
- Elasticsearch有一个完整的生态圈(ELK),形成了从数据采集(logstash,filebeat)、数据存储(Elasticsearch)、数据可视化(kibana)的闭环
基础
-
ES集群Elasticsearch是一个分布式系统,具有高可用性及可扩展性,当集群中有节点停止或丢失时不会影响集群服务或造成数据丢失
同时当访问量或数据量增加时可用采用横向扩展的方式增加节点,将请求或数据分散到集群的各个节点上
不同的集群可以通过不同的名字来区分,集群默认名为“elasticsearch“,如果节点配置的集群名称一样,则这些节点组成为一个ES集群
-
ES一个节点是一个ElasticSearch的实例,本质上是一个Java进程
ES根据功能不同分为不同的节点类型,在生产环境中,建议根据数据量,写入及查询吞吐量,选择合适的部署方式,最好将节点设置为单一角色
-
节点类型
Master Node
- node.master
- 管理节点,进行创建、删除索引等操作,决定分片被分配到哪个节点,负责索引创建删除,维护并更新集群状态
Data Node
- node.data
- 数据节点,处理与数据相关的操作,如索引的CRUD、搜索和聚合,数据节点的操作属于I/O、内存和CPU密集型操作
Ingest Node
-
node.ingest
-
提取节点,具有数据预处理的能力,可拦截Index或Bulk Api的请求,可对数据进行转换,并重新返回Index或Bulk Api
默认配置下,所有节点都是Ingest Node
Coordinating Node
- 协调节点,负责接受客户端的请求,并将请求分发到合适的节点,并将各节点返回的数据汇聚到一起
- 每个节点都默认是Coordinating Node,设置master、data、ingest全为false
Maching Learning Node
- node.ml
- 机器学习节点,用于运行作业和处理机器学习API请求,需要enable x-pack
-
-
ES文档是ES的最小单位,通常用JSON方式的数据结构表示,类似于数据库中的一条记录,文档具有以下特征
- 自我包含,一篇文档同时包含字段和它们的取值
- 层次型结构,文档中可以包含新的文档
- 灵活的结构,不依赖于预先定义的模式,文档是无模式的,并非所有的文档都需要拥有相同的字段
-
ES类型是文档的逻辑容器,类似于数据库中的表,类型在 Elasticsearch中表示一类相似的文档,每个类型中字段的定义称为映射
ES7.x已经将类型移除,7.x中一个索引只能有一个类型,默认为_doc
-
ES映射 mapping, 就像数据库中的 schema ,定义索引中字段的名称、字段的数据类型(如 string, integer 或 date),设置字段倒排索引的相关配置
当索引文档遇到未定义的字段,会使用dynamic mapping 来确定字段的数据类型,并自动把新增加的字段添加到类型映射
在实际生产中一般或禁用dynamic mapping,避免过多的字段导致cluster state占用过多
同时禁止自动创建索引的功能,创建索引时必须提供Mapping信息或者通过Index Template创建
-
ES索引是映射类型的容器,类似于数据库
-
ES分片,一个分片是一个运行的Lucene的实例,是一个包含倒排索引的文件目录
一个ES索引由一个或多个主分片以及零个或多个副本分片组成,主分片数在索引创建时指定,后续不允许修改
副本分片主要用于解决数据高可用的问题,是主分片的拷贝,一定程度上提高服务的可读性
分片的设定:生产环境中主分片数的设定,需要提前做好容量规划,因为主分片的数量是不可修改的
如果分片数设置过小,则无法通过增加节点实现水平扩展,单个分片的数据量太大,导致数据重新分片耗时
如果分片数设置过大,则会影响搜索结果的相关性打分,浪费资源,同时影响性能
索引
概念
- ES中的索引(index)定义了文档的逻辑存储和字段类型,索引是一种虚拟空间,类似于数据库中的表
- 一个索引可以包含不同的数据结构的数据,且由一到多个分片组成
- 索引(index)
- 存储文档归类的逻辑空间,由多个分片组成,相当于数据库中的表
- 分片(shard)
- 相当于Lucene中的索引文件,适当增加分片数可以提升索引性能
- 段(segment)
- 一个shard有多个段,一个段是Lucene中存储数据最小单位,一个段对应Lucene中的一个倒排索引
- 文档(document)
- 一条ES记录,相当于数据库中的行
- 副本(replicas)
- 备份。设置副本后,在索引的时候,会写入主分片,并同步到副本分片。有了副本分片可以提升检索效率,和保障数据高可用
- 索引(index)
创建方式
动态创建
- 定义
- 索引不用提前创建,插入的第一条(批)数据后,完成创建
- 场景
- 非业务逻辑场景,对数据结构定义要求不高的场景
- 备注
- 使用动态创建,es会根据第一条数据来对字段进行动态结构映射,如果对字段数据结构要求较高的,需要提前定义好类型
- 动态创建,索引的分片数默认为1(7.x),副本数为1
静态创建
- 定义
- 提前创建好索引,可以指定索引的分片数,副本数,字段数据结构等信息
- 场景
- 业务系统数据需要严格定义好结构,海量时序性索引可以提前创建索引,避免集中写入创建,影响集群性能
- 备注
- 静态创建没有动态创建灵活,但是可以做很多限制和参数调整,适用性高。通常会根据常用的时序性索引创建template,辅助创建索引
注: 索引一旦创建,无论以什么方式创建,都无法更改已经生成的数据结构mapping
元数据
-
_index: 代表当前的索引名(唯一标识索引的数据)
-
_type:代表数据的type类型,7.x后默认都为 _doc
- 在 7.0 以及之后的版本中 Type 被废弃了。一个 index 中只有一个默认的 type,即
_doc - ES 的Type 被废弃后,库表合一,Index 既可以被认为对应 MySQL 的 Database,也可以认为对应 table
- ES 实例:对应 MySQL 实例中的一个 Database
- Index 对应 MySQL 中的 Table
- Document 对应 MySQL 中表的记录
- 在 7.0 以及之后的版本中 Type 被废弃了。一个 index 中只有一个默认的 type,即
-
_id: 索引字段的唯一id,可以自定义,但是不能重复
- 自动生成 id:长度为20个字符,URL安全,base64编码,GUID,分布式生成不冲突
-
_version:文档的版本号,如果进行更新等操作,会增加版本数
- document数据每次变化,代表一次版本的变更。版本变更可以避免数据并发冲突,同时提高ElasticSearch的搜索效率
- es内部基于_version乐观锁控制,多线程情况下,es同样会出现并发冲突问题
- es对于文档的增删改都是基于版本号
- 延迟删除策略,如果删除一条数据立马删除的话,所有分片和副本都要立马删除,对es集群压力太大
-
_seqno:严格递增的顺序号。保证后写入的Doc的seqno比之前的大
-
_primary_term: 代表主分片上数据重新分配的次数。比如重启节点,重新分配都会触发这个参数累加
-
_routing: 路由规则,写入和查询要保证路由是一致
-
_source: 就是查询的document中的field值。也就是document的json字符串。此元数据可以定义显示结果(field)
文档
- document 默认自带字段解析
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 10,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Bootstrap开发教程1",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel" : "201002",
"price" : 38.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"bootstrap",
"开发"
]
}
}
doc_values/fielddata
-
ES 除了强大的搜索功能外,还可以支持排序,聚合之类的操作
-
搜索需要用到倒排索引,而排序和聚合则需要使用 “正排索引”
-
倒排索引的优势在于查找包含某个项的文档,而反过来确定哪些项在单个文档里并不高效
-
doc_values和fielddata就是用来给文档建立正排索引的
区别是,前者的工作地盘主要在磁盘,而后者的工作地盘在内存
| 维度 | doc_values | fielddata |
|---|---|---|
| 创建时间 | index时创建 | 使用时动态创建 |
| 创建位置 | 磁盘 | 内存(jvm heap) |
| 优点 | 不占用内存空间 | 不占用磁盘空间 |
| 缺点 | 索引速度稍低(相比于 fielddata) | 文档很多时,动态创建开销比较大,而且占内存 |
- ES 1.x版本的官方说法
Doc values are now only about 10–25% slower than in-memory fielddata
-
虽然速度稍慢,doc_values的优势还是非常明显的
-
一个很显著的点就是他不会随着文档的增多引起OOM问题
-
正如前面说的,doc_values在磁盘创建排序和聚合所需的正排索引
这样我们就避免了在生产环境给ES设置一个很大的HEAP_SIZE,也使得JVM的GC更加高效,这个又为其它的操作带来了间接的好处
随着ES版本的升级,对于doc_values的优化越来越好,索引的速度已经很接近fielddata了,而且我们知道硬盘的访问速度也是越来越快(比如SSD)
所以 doc_values 现在可以满足大部分场景,也是ES官方重点维护的对象
ES2.x 之后,支持聚合的字段属性默认都使用doc_values,而不是fielddata
-
-
doc_values其实是Lucene在构建倒排索引时,会额外建立一个有序的正排索引(基于document => field value的映射列表)
分片备份
简介
分片
- 有时候一个索引的数据量非常大,甚至超出了单机的存储能力,这个时候需要对索引分片存储,分别存到不同机器上
备份
- 为了防止节点故障到时索引分片丢失,一般会对分片进行备份。备份除了可以保障数据安全性,还可以分担搜索的压力
配置
- ES创建索引默认5个分片,1个备份,分片只能在创建索引的时候指定而备份可以后期动态修改
设计规范
分片数量
- 索引分片数量不超过节点数量,1个索引40个分片等同于40个1分片索引
副本数量
- 索引副本数量少于节点数量,副本数量取决于集群节点数,最少一个(保证高可用)
分片容量
- 数据容量
- 单个分片数据量不要超过50GB,推荐在20-40GB
- 数据条数
- 单分片限制最大条数不超过2^32 - 1
并发控制
- es内部主从同步时,是多线程异步。乐观锁机制
CRUD
批量查询 mget
- 单条查询 GET /test_index/_doc/1,如果查询多个id的文档一条一条查询,网络开销太大
# mget 批量查询
GET /_mget
{
"docs" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : 1
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : 7
}
]
}
"""
# 无需添加 type, 7.x 以后默认都是 _doc
GET /_mget
{
"docs" : [
{
"_index" : "test_index",
"_id" : 2
},
{
"_index" : "test_index",
"_id" : 3
}
]
}
"""
# 返回
{
"docs" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"_version" : 6,
"_seq_no" : 12,
"_primary_term" : 1,
"found" : true,
"_source" : {
"test_field" : "test12333123321321"
}
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "3",
"_version" : 6,
"_seq_no" : 18,
"_primary_term" : 1,
"found" : true,
"_source" : {
"test_field" : "test3213"
}
}
]
}
# 同一索引下批量查询
GET /test_index/_mget
{
"docs" : [
{
"_id" : 2
},
{
"_id" : 3
}
]
}
# 搜索写法
post /test_index/_doc/_search
{
"query": {
"ids" : {
"values" : ["1", "7"]
}
}
}
批量增删改 bulk
- Bulk 操作解释将文档的增删改查一些列操作,通过一次请求全都做完。减少网络传输次数
# 语法
POST /_bulk
{"action": {"metadata"}}
{"data"}
# 示例,删除5,新增14,修改2
POST /_bulk
{ "delete": { "_index": "test_index", "_id": "5" }}
{ "create": { "_index": "test_index", "_id": "14" }}
{ "test_field": "test14" }
{ "update": { "_index": "test_index", "_id": "2"} }
{ "doc" : {"test_field" : "bulk test"} }
倒排索引
概述
-
正排索引
-
文档ID到文档内容和单词的关联
-
从文档角度看其中的单词,表示每个文档都含有哪些单词
以及每个单词出现了多少次 (词频) 及其出现位置 (相对于文档首部的偏移量)
-
-
倒排索引
-
单词到文档ID的关联
-
从单词角度看文档,标识每个单词分别在那些文档中出现(文档ID)
以及在各自的文档中每个单词分别出现了多少次 (词频) 及其出现位置 (相对于该文档首部的偏移量)
-
ES中为所有字段默认都建了倒排索引
-
- 组成
-
Lucene 倒排索引由单词词典及倒排列表组成
-
单词词典
- 记录所有文档的单词,记录单词到倒排列表的关系,数据量比较大,一般采用B+树,哈希拉链法实现
-
倒排列表
- 记录单词对应的文档集合,由倒排索引项组成
- 倒排索引项结构如表所示
- 文档ID:DocId(文档ID),记录单词所在文档的ID,用于去正排索引中查询原始数据
- 词频:TF(词频),记录单词在文档中出现的次数,用于后续相关性算分
- 位置:position(位置),记录单词在文档中的位置,用于做词语搜索(Phrase Query)
- 偏移:offset(偏移),记录单词的开始位置,结束位置,用于高亮显示等
-
示例
-
倒排索引的生成过程
-
假设目前有以下两个文档内容
- 苏州街维亚大厦
- 桔子酒店苏州街店
-
生成正排索引
给每个文档进行编号,作为其唯一的标识
| 文档 id | content |
|---|---|
| 1 | 苏州街维亚大厦 |
| 2 | 桔子酒店苏州街店 |
-
生成倒排索引
首先要对字段的内容进行分词,分词就是将一段连续的文本按照语义拆分为多个单词
这里两个文档包含的关键词有:苏州街、维亚大厦
然后按照单词来作为索引,对应的文档 id 建立一个链表,就能构成上述的倒排索引结构
| Word | 文档 id |
|---|---|
| 苏州街 | 1,2 |
| 维亚大厦 | 1 |
| 维亚 | 1 |
| 桔子 | 2 |
| 酒店 | 2 |
| 大赛 | 1 |
例如,查询 苏州街桔子 ,可以通过分词后 苏州街 查到 1、2,通过 桔子 查到 2,然后再进行取交取并等操作得到最终结果
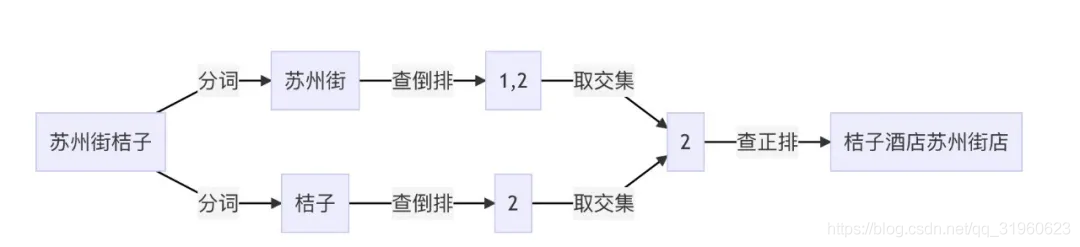
结构
- 根据倒排索引的概念,我们可以用一个 Map 来简单描述这个结构
- Map 的 Key 即是分词后的单词 Term,一系列的 Term 组成了倒排索引的第一个部分 Term Dictionary (索引表,可简称为 Dictionary)
- Map 的 Value 即是倒排索引的另一部分为 Postings List(记录表),记录表由所有的 Term 对应的数据(Postings) 组成
实现
Posting List 实现
简介
- PostingList 包含文档 id、词频、位置等多个信息,这些数据之间本身是相对独立的,因此 Lucene 将 Postings List 被拆成三个文件存储:
- doc后缀文件:记录 Postings 的 docId 信息和 Term 的词频
- pay后缀文件:记录 Payload 信息和偏移量信息
- pos后缀文件:记录位置信息
- 基本所有的查询都会用 .doc 文件获取文档 id,且一般的查询仅需要用到 .doc 文件就足够了,只有对于近似查询等位置相关的查询则需要用位置相关数据
- 三个文件整体实现差不太多,这里以.doc 文件为例分析其实现
- .doc 文件存储的是每个 Term 对应的文档 Id 和词频。每个 Term 都包含一对 TermFreqs 和 SkipData 结构
- 其中 TermFreqs 存放 docId 和词频信息,SkipData 为跳表信息,用于实现 TermFreqs 内部的快速跳转
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-25gce5rE-1673840082955)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/es_index_06.jpg)]
TermFreqs
-
TermFreqs 存储文档号和对应的词频,它们两是一一对应的两个 int 值
-
Lucene 为了尽可能的压缩数据,采用的是混合存储 ,由 PackedBlock 和 VIntBlocks 两种结构组成
-
PackedBlock
-
PackedBlock其采用 PackedInts 结构将一个 int[] 压缩打包成一个紧凑的 Block
-
它的压缩方式是取数组中最大值所占用的 bit 长度作为一个预算的长度,然后将数组每个元素按这个长度进行截取,以达到压缩的目的
-
例如:
一个包含128个元素的 int 数组中最大值是 2,那么预算长度为2个 bit, PackedInts 的长度仅是 2 * 128 / 8 = 32个字节,然后就可通过4个 long 值存储
-
-
VIntBlock
-
VIntBlock 是采用 VInt 来压缩 int 值,对于绝大多数语言,int 型都占4个字节,不论这个数据是1、100、1000、还是1000,000
-
VInt 采用可变长的字节来表示一个整数。数值较大的数,使用较多的字节来表示,数值较少的数,使用较少的字节来表示
-
每个字节仅使用第1至第7位(共7 bits)存储数据,第8位作为标识,表示是否需要继续读取下一个字节
-
例如:
整数130为 int 类型时需要4个字节,转换成 VInt 后仅用2个字节,其中第一个字节的第8位为1,标识需要继续读取第二个字节
-
-
根据上述两种 Block 的特点,Lucene 会每处理包含 Term 的128篇文档,将其对应的 DocId 数组和 TermFreq 数组分别处理为 PackedDocDeltaBlock 和
PackedFreqBlock 的 PackedInt 结构,两者组成一个 PackedBlock,最后不足128的文档则采用 VIntBlock 的方式来存储
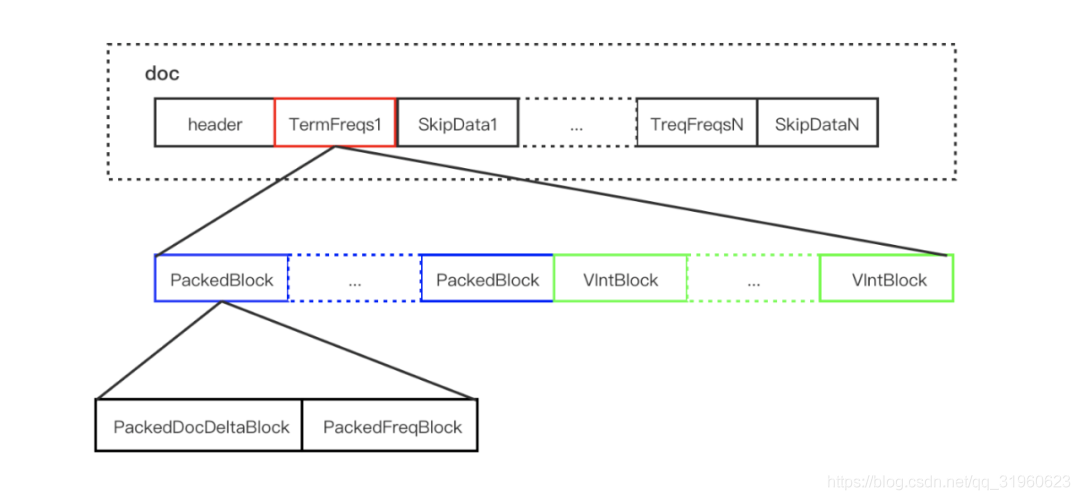
SkipData
-
Lucene 为了减少扫描和比较的次数,采用了 SkipData 这个跳表结构来实现快速跳转
-
在搜索中存在将每个 Term 对应的 DocId 集合进行取交集的操作,即判断某个 Term 的 DocId 在另一个 Term 的 TermFreqs 中是否存在
TermFreqs 中每个 Block 中的 DocId 是有序的,可以采用顺序扫描的方式来查询,但是如果 Term 对应的 doc 特别多时搜索效率就会很低
同时由于 Block 的大小是不固定的,我们无法使用二分的方式来进行查询
因此 Lucene 为了减少扫描和比较的次数,采用了 SkipData 这个跳表结构来实现快速跳转
-
-
跳表是在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。实质就是一种可以进行二分查找的有序链表
-
SkipData结构
-
在 TermFreqs 中每生成一个 Block 就会在 SkipData 的第0层生成一个节点,然后第0层以上每隔 N 个节点生成一个上层节点
每个节点通过 Child 属性关联下层节点,节点内 DocSkip 属性保存 Block 的最大的 DocId 值
DocBlockFP、PosBlockFP、PayBlockFP 则表示 Block 数据对应在 .pay、.pos、.doc 文件的位置
-
最终数据
- Posting List 采用多个文件进行存储,最终我们可以得到每个 Term 的如下信息
- SkipOffset:用来描述当前 term 信息在 .doc 文件中跳表信息的起始位置
- DocStartFP:是当前 term 信息在 .doc 文件中的文档 ID 与词频信息的起始位置
- PosStartFP:是当前 term 信息在 .pos 文件中的起始位置
- PayStartFP:是当前 term 信息在 .pay 文件中的起始位置
Term Dictionary 实现
简介
-
Terms Dictionary(索引表)存储所有的 Term 数据,同时它也是 Term 与 Postings 的关系纽带,存储了每个 Term 和其对应的 Postings 文件位置指针
数据存储
-
Terms Dictionary 通过 .tim 后缀文件存储,其内部采用 NodeBlock 对 Term 进行压缩前缀存储,处理过程会将相同前缀的的 Term 压缩为一个 NodeBlock,
NodeBlock 会存储公共前缀,然后将每个 Term 的后缀以及对应 Term 的 Posting 关联信息处理为一个 Entry 保存到 Block
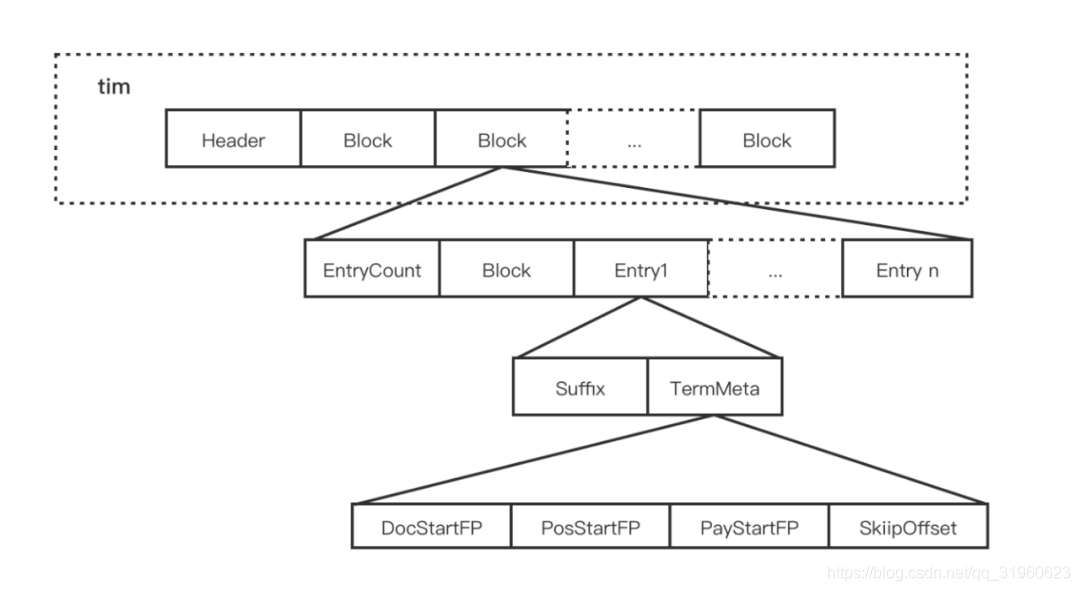
- 在上图中可以看到 Block 中还包含了 Block,这里是为了处理包含相同前缀的 Term 集合内部部分 Term 又包含了相同前缀
- 举个例子,在下图中为公共前缀为 a 的 Term 集合,内部部分 Term 的又包含了相同前缀 ab,这时这部分 Term 就会处理为一个嵌套的 Block
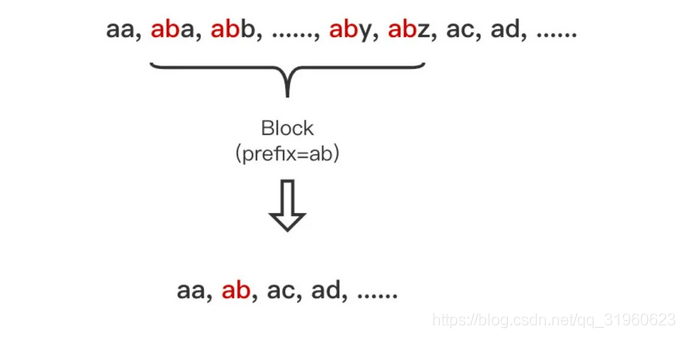
数据查找
-
Terms Dictionary 是按 NodeBlock 存储在.tim 文件上
当文档数量越来越多的时,Dictionary 中的 Term 也会越来越多,那查询效率必然也会逐渐变低
因此需要一个很好的数据结构为 Dictionary 建构一个索引,这就是 Terms Index(.tip文件存储),Lucene 采用了 FST 这个数据结构来实现这个索引
-
FST, 全称 Finite State Transducer(有限状态转换器),它具备以下特点:
- 给定一个 Input 可以得到一个 output,相当于 HashMap
- 共享前缀、后缀节省空间,FST 的内存消耗要比 HashMap 少很多
- 词查找复杂度为 O(len(str))
- 构建后不可变更
-
如下图为 mon/1,thrus/4,tues/2 生成的 FST,可以看到 thrus 和 tues 共享了前缀 t 以及后缀 s
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KFlL6biD-1673840082960)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/es_index_14.jpg)]
-
根据 FST 就可以将需要搜索 Term 作为 Input,对其途径的边上的值进行累加就可以得到 output,下述为以 input 为 thrus 的读取逻辑:
- 初始状态0
- 输入t, FST 从0 -> 3, output=2
- 输入h,FST 从3 -> 4, output=2+2=4
- 输入r, FST 从4 -> 5, output=4+0
- 输入u,FST 从5 -> 7, output=4+0
- 输入s, FST 到达终止节点,output=4+0=4
-
那么 Term Dictionary 生成的 FST 对应 input 和 output 是什么呢?
可能会误认为 FST 的 input 是 Dictionary 中所有的 Term,这样通过 FST 就可以找到具体一个 Term 对应的 Posting 数据。
-
实际上 FST 是通过 Dictionary 的每个 NodeBlock 的前缀构成,所以通过 FST 只可以直接找到这个 NodeBlock 在 .tim 文件上具体的 File Pointer, 然后还需要
在 NodeBlock 中遍历 Entry 匹配后缀进行查找
-
因此它在 Lucene 中充当以下功能:
-
快速试错,即是在 FST 上找不到可以直接跳出不需要遍历整个 Dictionary,类似于 BloomFilter
-
快速定位 Block 的位置,通过 FST 是可以直接计算出 Block 的在文件中位置
-
FST 也是一个 Automation(自动状态机),这是正则表达式的一种实现方式,所以 FST 能提供正则表达式的能力
通过 FST 能够极大的提高近似查询的性能,包括通配符查询、SpanQuery、PrefixQuery 等
-
查询逻辑
- 在介绍了索引表和记录表的结构后,就可以得到 Lucene 倒排索引的查询步骤:
- 通过 Term Index 数据(.tip文件)中的 StartFP 获取指定字段的 FST
- 通过 FST 找到指定 Term 在 Term Dictionary(.tim 文件)可能存在的 Block
- 将对应 Block 加载内存,遍历 Block 中的 Entry,通过后缀(Suffix)判断是否存在指定 Term
- 存在则通过 Entry 的 TermStat 数据中各个文件的 FP 获取 Posting 数据
- 如果需要获取 Term 对应的所有 DocId 则直接遍历 TermFreqs,如果获取指定 DocId 数据则通过 SkipData 快速跳转
Lucene 数值类型处理
简介
- 上述 Terms Dictionary 与 Posting List 的实现都是处理字符串类型的 Term,而对于数值类型,如果采用上述方式实现会存在以下问题:
- 数值潜在的 Term 可能会非常多,比如是浮点数,导致查询效率低
- 无法处理多维数据,比如经纬度
- 所以 Lucene 为了支持高效的数值类或者多维度查询,引入了 BKDTree
KDTree
- kd-tree,是k维的二叉树。其中的每一个节点都是k维的数据,数据结构如下所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vV63ijAk-1673840082961)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/es_index_17.jpg)]
-
BKDTree 是基于 KDTree,KDTree 实现起来很像是一个二叉查找树。主要的区别是,KDTree 在不同的层使用的是不同的维度值
-
下面是一个2维树的样例 ,其第一层以 x 为切分维度,将 x>30的节点传递给右子树,x<30的传递给左子树,第二层再按 y 维度切分,不断迭代到所有数据都
被建立到 KD Tree 的节点上为止
BKDTree
-
BKD 树是 KD 树和 B+ 树的组合,拥有以下特性:
-
内部 node 必须是一个完全二叉树
-
叶子节点存储点数据,降低层高度,减少磁盘 IO
-
参考资料: ES之倒排索引详解_wh柒八九的博客-CSDN博客_es倒排索引
脑裂
概述
-
一个正常es集群中只有一个主节点,主节点负责管理整个集群,集群的所有节点都会选择同一个节点作为主节点
所以无论访问那个节点都可以查看集群的状态信息
而脑裂问题的出现就是因为从节点在选择主节点上出现分歧导致一个集群出现多个主节点从而使集群分裂,使得集群处于异常状态
原因
网络原因
- 内网一般不会出现此问题,可以监控内网流量状态。外网的网络出现问题的可能性大些
节点负载
-
主节点既负责管理集群又要存储数据
当访问量大时可能导致es实例反应不过来而停止响应,此时其他节点在向主节点发送消息时得不到主节点的响应就会认为主节点挂了,从而重新选择主节点
回收内存
- 大规模回收内存时也会导致es集群失去响应
ES 主动选举机制
-
elasticsearch集群一旦建立起来以后,会选举出一个master,其他都为slave节点
但是具体操作的时候,每个节点都提供写和读的操作。就是说,你不论往哪个节点中做写操作,这个数据也会分配到集群上的所有节点中
-
这里有某个节点挂掉的情况
-
如果是slave节点挂掉了,那么首先关心,数据会不会丢呢?不会
如果你开启了replicate,那么这个数据一定在别的机器上是有备份的
别的节点上的备份分片会自动升格为这份分片数据的主分片(这里要注意的是这里会有一小段时间的yellow状态时间)
-
-
如果是主节点挂掉
-
当从节点们发现和主节点连接不上了,那么他们会自己决定再选举出一个节点为主节点,但是这里有个脑裂的问题
-
假设有5台机器,3台在一个机房,2台在另一个机房,当两个机房之间的联系断了之后,每个机房的节点会自己聚会,推举出一个主节点
这个时候就有两个主节点存在了,当机房之间的联系恢复了之后,这个时候就会出现数据冲突了
-
预防方案
角色分离
- 在es集群中配置2到3个主节点并且让它们只负责管理不负责存储,从节点只负责存储
- 另外从节点禁用自动发现机制并为其指定主节点,在elasticsearch.yml文件中
- 主节点:node.master =true node.data=false
- 从节点:node.master =false node.data=ture
- discovery.zen.ping.multicast.enabled:false
- discovery.zen.ping.unicast.hosts:[“host1”, “host2:port”]
参数配置
-
discovery.zen.ping_timeout:3
此参数指定从节点访问主节点后如果3秒之内没有回复则默认主节点挂了,我们可以适当的把它改大,这样可以减少出现脑裂的概率
-
discovery.zen.minimum_master_nodes:1
该参数的意思是,当具备成为主节点的从节点的个数满足这个数字且都认为主节点挂了则会进行选举产生新的主节点
例如
- es集群有三个从节点有资格成为主节点,这时这三个节点都认为主节点挂了则会进行选举,此时如果这个参数的值是4则不会进行选举
- 我们可以适当的把这个值改大,减少出现脑裂的概率,官方给出的建议是(n/2)+1,n为有资格成为主节点的节点数node.master=true
打分机制
-
确定文档和查询有多么相关的过程被称为打分(scoring)
-
文档打分的运作机制:** TF-IDF**
-
Lucene和es的打分机制是一个公式-
将查询作为输入,使用不同的手段来确定每一篇文档的得分,将每一个因素最后通过公式综合起来,返回该文档的最终得分
这个综合考量的过程,就是我们希望相关的文档被优先返回的考量过程
在开始计算得分之前,
es使用了被搜索词条的频率和它有多常见来影响得分,从两个方面理解- 一个词条在某篇文档中出现的次数越多,该文档就越相关
- 一个词条如果在不同的文档中出现的次数越多,它就越不相关
- 我们称之为
TF-IDF,TF是词频(term frequency),而IDF是逆文档频率(inverse document frequency)
-
-
词频:TF
- 考虑一篇文档得分的首要方式,是查看一个词条在文档中出现的次数
- 比如某篇文章围绕
es的打分展开的,那么文章中肯定会多次出现相关字眼,当查询时,我们认为该篇文档更符合,所以,这篇文档的得分会更高
-
逆文档频率:IDF
- 相对于词频,逆文档频率稍显复杂,如果一个词条在索引中的不同文档中出现的次数越多,那么它就越不重要
消息队列TODO
Kafka
Celery
RabbitMQ
Queue
MultiProcess Queue
Kafka 和 rabbitmq 区别
Kafka 和 rabbitmq 场景
redis
缓存过期处理
-
(主动)定时删除
定时随机的检查过期的key,如果过期则清理删除。
-
(被动)惰性删除
当客户端请求一个已经过期的key的时候,那么redis会检查这个key是否过期,如果过期了,则删除,然后返回一个nil。
这种策略对cpu比较友好,不会有太多的损耗,但是内存占用会比较高。
-
缓存淘汰机制
lru: Least Recently Used 最近最少使用
lfu: Least Frequently Used 最少频繁使用
缓存一致性
引入缓存提高性能
最简单的场景
引入缓存架构模型
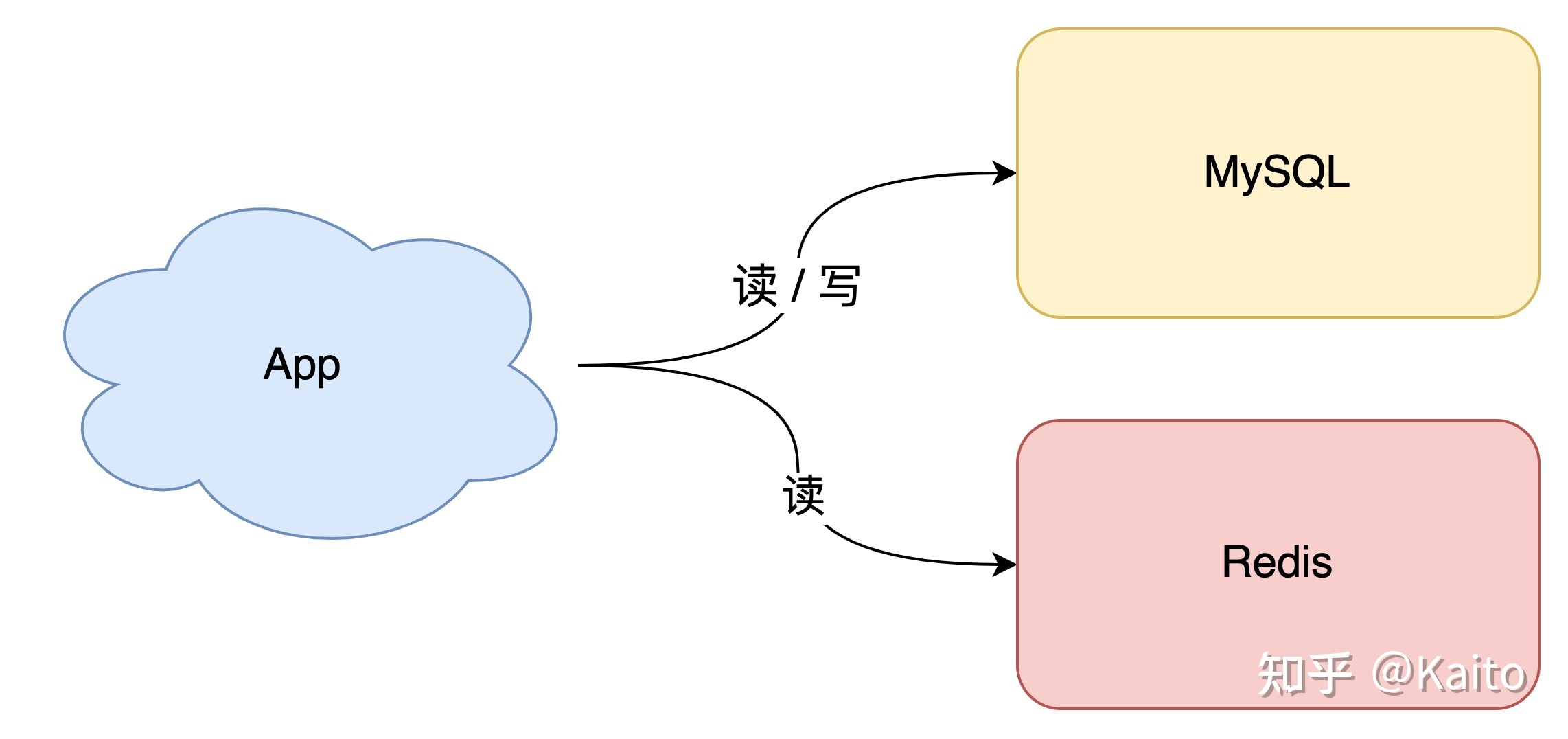
缓存和数据库同步
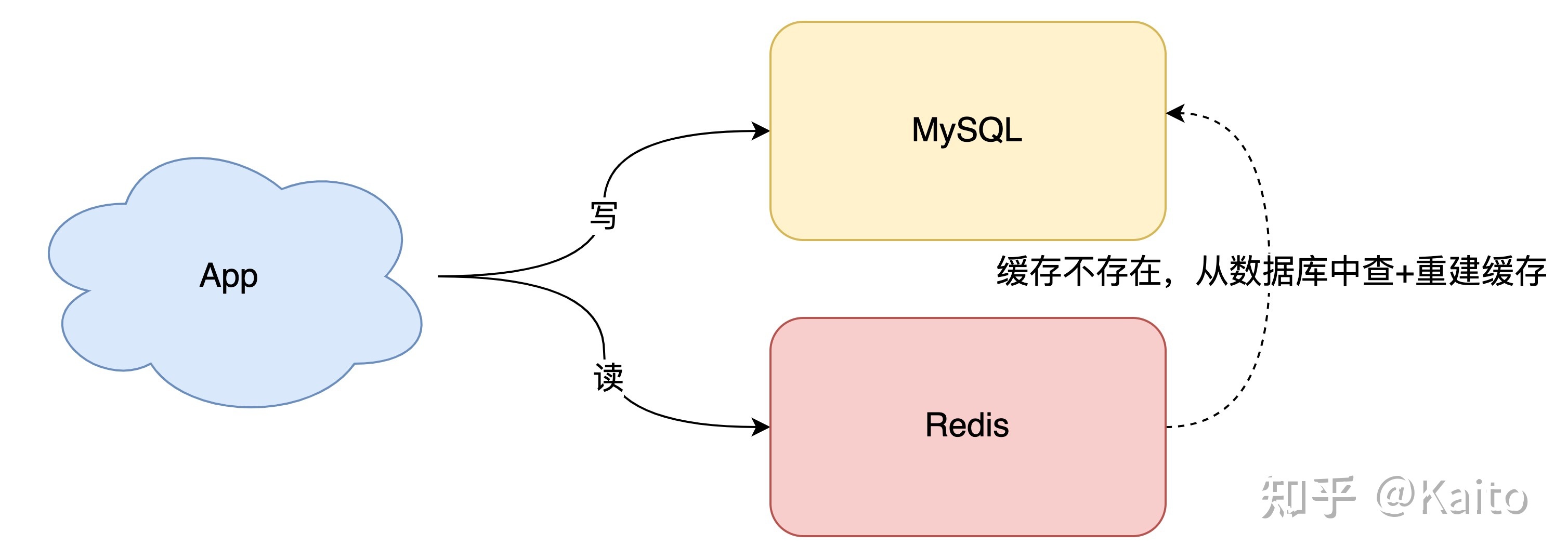
三种方式
- 更新:先更新数据库,再更新缓存
- 每次数据发生变更,都更新缓存,但是缓存中的数据不一定会被马上读取,这就会导致缓存中可能存放了很多不常访问的数据,浪费缓存资源。
- 删除:先删缓存,再更新数据库
- 先删除缓存,数据库还没有更新成功,此时如果读取缓存,缓存不存在,去数据库中读取到的是旧值,缓存不一致发生。
- 删除:先更新数据库,再删除缓存
- 更新数据库成功,如果删除缓存失败或者还没有来得及删除,那么,其他线程从缓存中读取到的就是旧值,还是会发生不一致。
并发引发的一致性问题
先更新数据库,再更新缓存
-
有线程 A 和线程 B 两个线程,需要更新「同一条」数据,会发生这样的场景:
- 线程 A 更新数据库(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 更新缓存(X = 2)
- 线程 A 更新缓存(X = 1)
-
最终 X 的值在缓存中是 1,在数据库中是 2,发生不一致。
也就是说,A 虽然先于 B 发生,但 B 操作数据库和缓存的时间,却要比 A 的时间短,执行时序发生「错乱」,最终这条数据结果是不符合预期的。
同样地,采用「先更新缓存,再更新数据库」的方案,也会有类似问题,这里不再详述。
-
那怎么解决这个问题呢?这里通常的解决方案是,加「分布式锁」。
两个线程要修改同一条数据,每个线程在改之前,先去申请分布式锁,拿到锁的线程才允许更新数据库和缓存,拿不到锁的线程,返回失败,等待下次重试。
这么做的目的,就是为了只允许一个线程去操作数据和缓存,避免并发问题。
-
更新数据库 + 更新缓存的方案,不仅缓存利用率不高,还会造成机器性能的浪费。
从缓存利用率的角度来评估这个方案,也是不太推荐的。
这是因为每次数据发生变更,都更新缓存,但是缓存中的数据不一定会被马上读取,这就会导致缓存中可能存放了很多不常访问的数据,浪费缓存资源。
所以此时我们需要考虑另外一种方案:** 删除缓存**。
先删除缓存,后更新数据库
- 如果有 2 个线程要并发「读写」数据,可能会发生以下场景:
- 线程 A 要更新 X = 2(原值 X = 1)
- 线程 A 先删除缓存
- 线程 B 读缓存,发现不存在,从数据库中读取到旧值(X = 1)
- 线程 A 将新值写入数据库(X = 2)
- 线程 B 将旧值写入缓存(X = 1)
-
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。
可见,先删除缓存,后更新数据库,当发生「读+写」并发时,还是存在数据不一致的情况。
先更新数据库,后删除缓存
-
依旧是 2 个线程并发「读写」数据:
- 缓存中 X 不存在(数据库 X = 1)
- 线程 A 读取数据库,得到旧值(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 删除缓存
- 线程 A 将旧值写入缓存(X = 1)
-
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),也发生不一致。
-
其实这种情况发生概率「很低」,这是因为它必须满足 3 个条件:
- 缓存刚好已失效
- 读请求 + 写请求并发
- 更新数据库 + 删除缓存的时间(步骤 3-4),要比读数据库 + 写缓存时间短(步骤 2 和 5)
-
因为写数据库一般会先「加锁」,所以写数据库,通常是要比读数据库的时间更长的。
这么来看,「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的。
如何保证两步都执行成功
-
前面我们分析到,无论是更新缓存还是删除缓存,只要第二步发生失败,那么就会导致数据库和缓存不一致。
-
保证第二步成功执行,就是解决问题的关键。
想一下,程序在执行过程中发生异常,最简单的解决办法是什么?
答案是:** 重试**。
无论是先操作缓存,还是先操作数据库,但凡后者执行失败了,我们就可以发起重试。
那这是不是意味着,只要执行失败,我们「无脑重试」就可以了呢?
答案是否定的。现实情况往往没有想的这么简单,失败后立即重试的问题在于:
- 立即重试很大概率「还会失败」
- 「重试次数」设置多少才合理?
- 重试会一直「占用」这个线程资源,无法服务其它客户端请求
看到了么,虽然我们想通过重试的方式解决问题,但这种「同步」重试的方案依旧不严谨。
-
那更好的方案应该怎么做?
答案是:** 异步重试**。
异步重试就是把重试请求写到「消息队列」中,然后由专门的消费者来重试,直到成功。
或者更直接的做法,为了避免第二步执行失败,我们可以把操作缓存这一步,直接放到消息队列中,由消费者来操作缓存。
-
到这里你可能会问,写消息队列也有可能会失败啊?而且,引入消息队列,这又增加了更多的维护成本,这样做值得吗?
-
这个问题很好,但我们思考这样一个问题:
如果在执行失败的线程中一直重试,还没等执行成功,此时如果项目「重启」了,那这次重试请求也就「丢失」了,那这条数据就一直不一致了。
所以,这里我们必须把重试消息或第二步操作放到另一个「服务」中,这个服务用「消息队列」最为合适。
这是因为消息队列的特性,正好符合我们的需求:
- 消息队列保证可靠性:写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)
- 消息队列保证消息成功投递:下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的需求)
-
至于写队列失败和消息队列的维护成本问题:
- 写队列失败:操作缓存和写消息队列,「同时失败」的概率其实是很小的
- 维护成本:我们项目中一般都会用到消息队列,维护成本并没有新增很多
所以,引入消息队列来解决这个问题,是比较合适的。这时架构模型就变成了这样:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4jvjBRdV-1673840082964)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/app-mysql-mq-redis.jpg)]
-
那如果你确实不想在应用中去写消息队列,是否有更简单的方案,同时又可以保证一致性呢?
方案还是有的,这就是近几年比较流行的解决方案:** 订阅数据库变更日志,再操作缓存**。
具体来讲就是,我们的业务应用在修改数据时,「只需」修改数据库,无需操作缓存。
-
拿 MySQL 举例
当一条数据发生修改时,MySQL 就会产生一条变更日志(Binlog),订阅这个日志,拿到具体操作的数据,然后再根据这条数据,去删除对应的缓存。
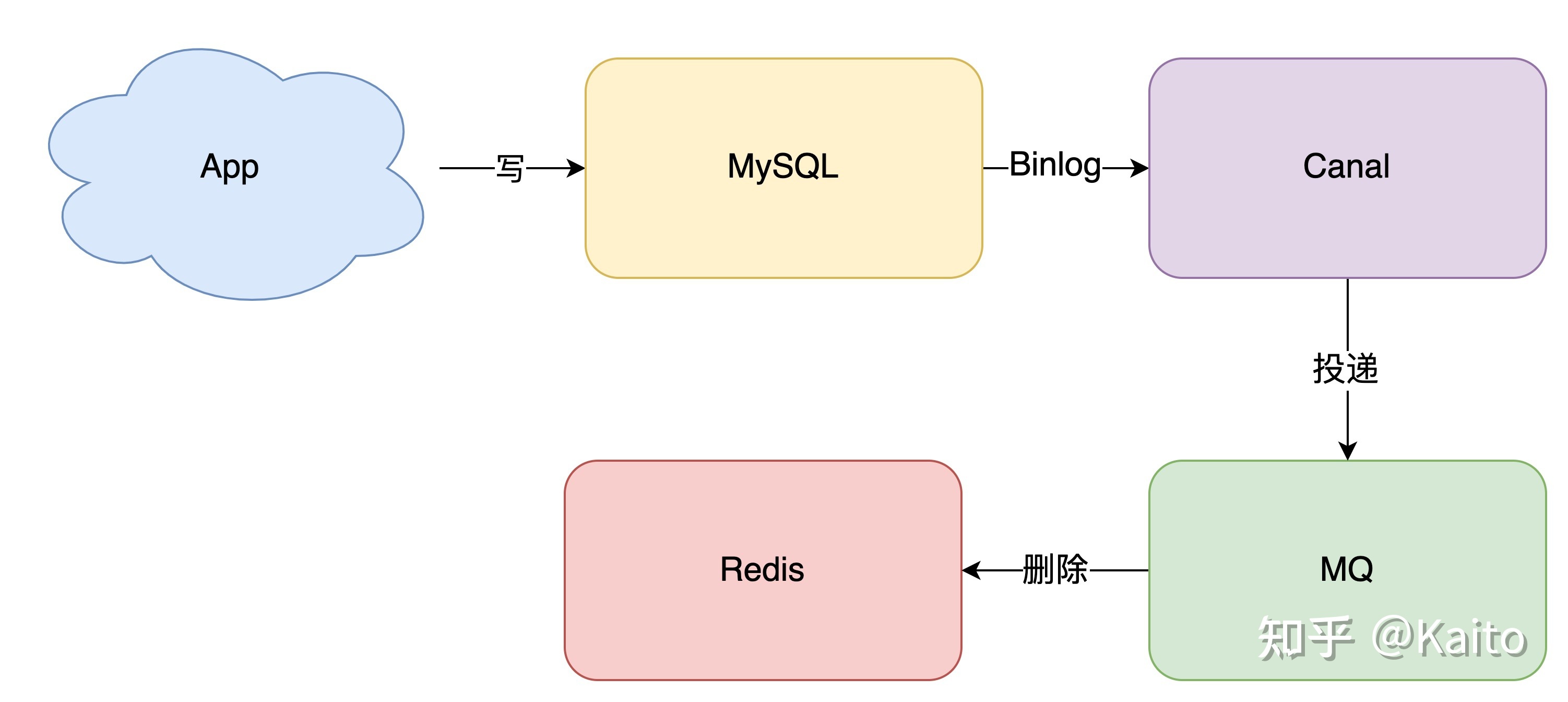
-
订阅变更日志,目前也有了比较成熟的开源中间件,例如阿里的 canal,使用这种方案的优点在于:
-
无需考虑写消息队列失败情况:只要写 MySQL 成功,Binlog 肯定会有
-
自动投递到下游队列:canal 自动把数据库变更日志「投递」给下游的消息队列
-
-
当然,与此同时,我们需要投入精力去维护 canal 的高可用和稳定性。
如果你有留意观察很多数据库的特性,就会发现其实很多数据库都逐渐开始提供「订阅变更日志」的功能了,相信不远的将来,我们就不用通过中间件来拉取日志,自己写程序就可以订阅变更日志了,这样可以进一步简化流程。
至此,我们可以得出结论,想要保证数据库和缓存一致性,推荐采用「先更新数据库,再删除缓存」方案,并配合「消息队列」或「订阅变更日志」的方式来做。
主从库延迟和延迟双删问题
先删除缓存,再更新数据库
-
2 个线程要并发「读写」数据,可能会发生以下场景:
- 线程 A 要更新 X = 2(原值 X = 1)
- 线程 A 先删除缓存
- 线程 B 读缓存,发现不存在,从数据库中读取到旧值(X = 1)
- 线程 A 将新值写入数据库(X = 2)
- 线程 B 将旧值写入缓存(X = 1)
-
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。
读写分离 + 主从复制延迟
-
如果使用「先更新数据库,再删除缓存」方案,其实也发生不一致:
- 线程 A 更新主库 X = 2(原值 X = 1)
- 线程 A 删除缓存
- 线程 B 查询缓存,没有命中,查询「从库」得到旧值(从库 X = 1)
- 从库「同步」完成(主从库 X = 2)
- 线程 B 将「旧值」写入缓存(X = 1)
-
最终 X 的值在缓存中是 1(旧值),在主从库中是 2(新值),也发生不一致。
看到了么?这 2 个问题的核心在于:** 缓存都被回种了「旧值」**。
-
那怎么解决这类问题呢?
最有效的办法就是,把缓存删掉。但不能立即删,而是需要延迟删,这就是业界给出的方案:** 缓存延迟双删策略**。
-
按照延时双删策略,这 2 个问题的解决方案是这样的:
- 解决第一个问题:在线程 A 删除缓存、更新完数据库之后,先「休眠一会」,再「删除」一次缓存。
- 解决第二个问题:线程 A 可以生成一条「延时消息」,写到消息队列中,消费者延时「删除」缓存。
-
这两个方案的目的,都是为了把缓存清掉,这样一来,下次就可以从数据库读取到最新值,写入缓存。
-
但问题来了,这个「延迟删除」缓存,延迟时间到底设置要多久呢?
- 问题1:延迟时间要大于「主从复制」的延迟时间
- 问题2:延迟时间要大于线程 B 读取数据库 + 写入缓存的时间
-
但是,这个时间在分布式和高并发场景下,其实是很难评估的。
很多时候,我们都是凭借经验大致估算这个延迟时间,例如延迟 1-5s,只能尽可能地降低不一致的概率。
所以采用这种方案,也只是尽可能保证一致性而已,极端情况下,还是有可能发生不一致。
所以实际使用中,我还是建议你采用「先更新数据库,再删除缓存」的方案,同时,要尽可能地保证「主从复制」不要有太大延迟,降低出问题的概率。
总结
-
想要提高应用的性能,可以引入缓存来解决
-
引入缓存后,需要考虑缓存和数据库一致性问题,可选的方案有:更新数据库 + 更新缓存、更新数据库 + 删除缓存
-
更新数据库 + 更新缓存方案,在并发场景下无法保证缓存和数据一致性,解决方案是加分布锁,但这种方案存在缓存资源浪费和机器性能浪费的情况
-
采用先删除缓存,再更新数据库方案,在并发场景下依旧有不一致问题,解决方案是延迟双删,但这个延迟时间很难评估
-
采用先更新数据库,再删除缓存方案,为了保证两步都成功执行,需配合消息队列或订阅变更日志的方案来做,本质是通过重试的方式保证数据最终一致
-
采用先更新数据库,再删除缓存方案,读写分离 + 主从库延迟也会导致缓存和数据库不一致,缓解此问题的方案是延迟双删,凭借经验发送延迟消息到队列
中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率
持久化
持久化原因
- Redis是内存数据库,宕机后数据会消失,Redis重启后快速恢复数据,要提供持久化机制。
Redis的两种持久化方式:
-
RDB 和 AOF
-
Redis持久化不保证数据的完整性,有可能会丢数据。
当Redis用作DB时,DB数据要完整,所以一定要有一个完整的数据源(文件、mysql),在系统启动时,从这个完整的数据源中将数据load到Redis中。
-
RDB
RDB(Redis DataBase),是redis默认的存储方式,RDB方式是通过快照( snapshotting )完成的。它保存的是某一时刻的数据并不关注过程。
RDB保存redis某一时刻的数据的快照
-
RDB的优缺点
优点
- RDB是二进制压缩文件,占用空间小,便于传输(传给slaver)
- 主进程fork子进程,可以最大化Redis性能
- 使用RDB文件来恢复数据较快
缺点
- 不保证数据完整性,会丢失最后一次快照以后更改的所有数据
- 父进程在fork子进程的时候如果主进程比较大会阻塞
-
AOF
AOF(append only file)是Redis的另一种持久化方式。Redis默认情况下是不开启的。
开启AOF持久化后Redis 将所有对数据库进行过写入的命令(及其参数)(RESP)记录到 AOF 文件, 以此达到记录数据库状态的目的,这样当Redis重启后
只要按顺序回放这些命令就会恢复到原始状态了。AOF会记录过程,RDB只管结果
-
AOF 保存模式
AOF_FSYNC_NO :不保存
在这种模式下, 每次调用 flushAppendOnlyFile 函数, WRITE 都会被执行, 但 SAVE 会被略过。当出现Redis 被关闭、AOF 功能被关闭 、 系统的写缓存被
刷新(可能是缓存已经被写满,或者定期保存操作被执行)中任意一种情况都会触发save执行,并且会Redis 主进程阻塞。
AOF_FSYNC_EVERYSEC :每一秒钟保存一次(默认)
在这种模式中, SAVE 原则上每隔一秒钟就会执行一次, 因为 SAVE 操作是由后台子线程(fork)调用的, 所以它不会引起服务器主进程阻塞**。**
AOF_FSYNC_ALWAYS :每执行一个命令保存一次(不推荐)
在这种模式下,每次执行完一个命令之后, WRITE 和 SAVE 都会被执行。
-
AOF重写
因为随着Redis执行的写命令越来越多,AOF日志的文件大小会越来越大,会带来以下问题:
- 系统本身对文件大小有限制,无法保存过大的文件。
- 当文件过大时,往后面追加内容的性能就会变差。
- 当文件过大时,通过其进行数据恢复时,过程会比较慢
从本质上来说,要解决该问题,就要限制文件的大小。其实AOF日志文件中的很多记录是没有用的,比如我们对同一个key进行一百万次SET操作,然后进行
一百万次DEL操作,最终的结果是这个key不存在,但是AOF日志文件中却有两百万条记录。为了解决这个问题,Redis引入了AOF重写机制。
所以AOF重写机制,其实是重新生成一个AOF日志文件(AOF重写日志),只将当前有效并存在的数据转义成符合AOF日志格式的记录(上面提及过),接着
依次写入该日志文件,最后通过fsync系统调用刷入硬盘。这些操作都是在子进程中进行的,应该不会阻塞主进程,而导致无法处理新的请求。
子进程还带来了一个问题,就是在子进程在生成AOF重写日志的时候,主进程还在处理新的请求,那么这段区间的写命令是没有记录下来的。Linux的进程之
间的通信可以pipe机制进行,Redis通过该机制,主进程将该段区间执行的命令传递给子进程,然后子进程将这些命令追加到AOF重写日志的末尾,因而解决
了这个问题。
Redis可以在 AOF体积变得过大时,自动地在后台(Fork子进程)对 AOF进行重写。重写后的新 AOF文件包含了恢复当前数据集所需的最小命令集合。
Redis 不希望 AOF 重写造成服务器无法处理请求, 所以 Redis 决定将 AOF 重写程序放到(后台)子进程里执行, 这样处理的最大好处是:
- 1、子进程进行 AOF 重写期间,主进程可以继续处理命令请求。
- 2、子进程带有主进程的数据副本,使用子进程而不是线程,可以在避免锁的情况下,保证数据的安全性。
使用子进程也有一个问题需要解决:
因为子进程在进行 AOF 重写期间, 主进程还需要继续处理命令, 而新的命令可能对现有的数据进行修改, 这会让当前数据库的数据和重写后的 AOF 文件中
的数据不一致。
为了解决这个问题, Redis 增加了一个 AOF 重写缓存, 这个缓存在 fork 出子进程之后开始启用,Redis 主进程在接到新的写命令之后, 除了会将这个写命
令的协议内容追加到现有的 AOF 文件之外,还会追加到这个缓存中。
系统调用 fork,它的作用是创建一个子进程,理论上该子进程会有父进程内存空间的完整拷贝,但Linux对fork做了优化,引入了Copy on Write机制(写时复
制),也就是只有当主进程修改了内存页(操作系统对内存是进行分页管理的)的时候,操作系统会在此操作前拷贝一个副本,将其复制到另一个内存页中,供
子进程使用。
单线程模型
-
因为 Redis 是基于内存的操作,CPU不是 Redis 的瓶颈。Redis 的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章地采用单线程的方案了。
-
不需要各种锁的性能消耗
-
单线程多进程的集群方案
-
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。
-
Redis 客户端对服务端的每次调用都经历了
发送命令,执行命令,返回结果三个过程。其中执行命令阶段,由于 Redis 是单线程来处理命令的,所有到达服务端的命令都不会立刻执行,所有的命令都会进入一个队列中,然后逐个执行,并且多个客户端发送的命令的执行顺序是不确定的,但是可以确定的是不会有两条
命令被同时执行,不会产生并发问题,这就是 Redis 的单线程基本模型。
Redis 服务器通过 socket (套接字)与客户端或其他 Redis 服务器进行连接,而文件事件就是服务器对 socket 操作的抽象。服务器与客户端或其他服务器的通
信会产生相应的文件事件,而服务器通过监听并处理这些事件来完成一系列网络通信操作。
Redis 基于 Reactor 模式开发了自己的网络事件处理器——文件事件处理器,文件事件处理器使用 I/O 多路复用程序来同时监听多个 socket,并根据 socket
目前执行的任务来为 socket 关联不同的事件处理器。当被监听的 socket 准备好执行连接应答、读取、写入、关闭等操作时,与操作相对应的文件事件就会产
生,这时文件事件处理器就会调用 socket 之前已关联好的事件处理器来处理这些事件。
-
文件事件处理器的构成
单线程Redis为何高并发快
-
Redis 是纯内存数据库,内存的读写速度非常快。
-
Redis 是单线程的,保证了每个操作的原子性,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种
锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
-
Redis 使用非阻塞的 IO多路复用技术,可以处理并发的连接。使用了单线程来轮询描述符,非阻塞 IO 部实现采用 epoll,采用了 epoll 和自己实现的简单的事
件框架。epoll 中的读、写、关闭、连接都转化成了事件,然后利用 epoll 的多路复用特性,不在 IO 上浪费一点时间。
-
数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的,使用 hash 结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优
化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。
-
Redis 采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
IO 多路复用保证高吞吐量
-
Redis 采用网络 I/O 多路复用技术,来保证在多连接的时候系统的高吞吐量。
-
关于 I/O 多路复用(又被称为“事件驱动”),首先要理解的是,操作系统为你提供了一个功能,当你的某个 socket 可读或者可写的时候,它可以给你一个通知。
这样当配合非阻塞的 socket 使用时,只有当系统通知我哪个描述符可读了,才去执行 read 操作,可以保证每次 read 都能读到有效数据。
-
操作系统的这个功能是通过 select/poll/epoll/kqueue 之类的系统调用函数来实现,这些函数都可以同时监视多个描述符的读写就绪状况,这样,多个描述
符的 I/O 操作都能在一个线程内并发交替地顺序完成,这就叫 I/O 多路复用。多路指的是多个 socket 连接,复用指的是复用同一个 Redis 处理线程。
-
多路复用主要有三种技术:select,poll,epoll。epoll 是最新的也是目前最好的多路复用技术。
-
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 I/O 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内
的操作不会成为影响 Redis 性能的瓶颈,基于这两点 Redis 具有很高的吞吐量。
数据类型
- string(字符串),hash(哈希),list(列表),set(集合),zset(sorted set:有序集合)
事务
-
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证
- 批量操作在发送 EXEC 命令前被放入队列缓存
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中
-
一个事务从开始到执行会经历以下三个阶段
-
开始事务
-
命令入队
-
执行事务
-
-
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做
排行榜TODO
GEO
简介
- Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增
操作方法
- geoadd:添加地理位置的坐标
- geopos:获取地理位置的坐标
- geodist:计算两个位置之间的距离
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
- georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合
- geohash:返回一个或多个位置对象的 geohash 值
geoadd
- geoadd 用于存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中
# 语法格式
GEOADD key longitude latitude member [longitude latitude member ...]
# 以下实例中 key 为 Sicily,Palermo 和 Catania 为位置名称
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEODIST Sicily Palermo Catania
"166274.1516"
redis> GEORADIUS Sicily 15 37 100 km
1) "Catania"
redis> GEORADIUS Sicily 15 37 200 km
1) "Palermo"
2) "Catania"
redis>
geopos
- geopos 用于从给定的 key 里返回所有指定名称 (member) 的位置(经度和纬度),不存在的返回 nil
# 语法格式
GEOPOS key member [member ...]
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEOPOS Sicily Palermo Catania NonExisting
1) 1) "13.36138933897018433"
2) "38.11555639549629859"
2) 1) "15.08726745843887329"
2) "37.50266842333162032"
3) (nil)
redis>
geodist
- geodist 用于返回两个给定位置之间的距离
# 语法格式
GEODIST key member1 member2 [m|km|ft|mi]
# 参数说明
member1 member2 为两个地理位置
距离单位
m :米 (默认单位)
km :千米
mi :英里
ft :英尺
# 计算 Palermo 与 Catania 之间的距离
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEODIST Sicily Palermo Catania
"166274.1516"
redis> GEODIST Sicily Palermo Catania km
"166.2742"
redis> GEODIST Sicily Palermo Catania mi
"103.3182"
redis> GEODIST Sicily Foo Bar
(nil)
redis>
georadius
- georadius 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素
# 语法格式
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
# 参数说明
m :米 (默认单位)
km :千米
mi :英里
ft :英尺
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回
WITHCOORD: 将位置元素的经度和纬度也一并返回
WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。这个选项主要用于底层应用或者调试,实际中的作用并不大
COUNT: 限定返回的记录数。
ASC: 查找结果根据距离从近到远排序
DESC: 查找结果根据从远到近排序
# 实例
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEORADIUS Sicily 15 37 200 km WITHDIST
1) 1) "Palermo"
2) "190.4424"
2) 1) "Catania"
2) "56.4413"
redis> GEORADIUS Sicily 15 37 200 km WITHCOORD
1) 1) "Palermo"
2) 1) "13.36138933897018433"
2) "38.11555639549629859"
2) 1) "Catania"
2) 1) "15.08726745843887329"
2) "37.50266842333162032"
redis> GEORADIUS Sicily 15 37 200 km WITHDIST WITHCOORD
1) 1) "Palermo"
2) "190.4424"
3) 1) "13.36138933897018433"
2) "38.11555639549629859"
2) 1) "Catania"
2) "56.4413"
3) 1) "15.08726745843887329"
2) "37.50266842333162032"
redis>
georadiusbymember
-
georadiusbymember 和 GEORADIUS 命令一样, 都可以找出位于指定范围内的元素
但 georadiusbymember 的中心点是由给定的位置元素决定的, 而不是使用经度和纬度来决定中心点
# 语法格式
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key]
[STOREDIST key]
# 实例
redis> GEOADD Sicily 13.583333 37.316667 "Agrigento"
(integer) 1
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEORADIUSBYMEMBER Sicily Agrigento 100 km
1) "Agrigento"
2) "Palermo"
redis>
geohash
- Redis GEO 使用 geohash 来保存地理位置的坐标,geohash 用于获取一个或多个位置元素的 geohash 值
# 语法格式
GEOHASH key member [member ...]
# 实例
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEOHASH Sicily Palermo Catania
1) "sqc8b49rny0"
2) "sqdtr74hyu0"
redis>
连接池TODO
pipelineTODO
主从搭建TODO
高可用(哨兵)TODO
集群TODO
发布订阅
-
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发布者 (pub) 发布消息,订阅者 (sub) 接收消息
-
Redis 客户端可以订阅任意数量的频道
-
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端: client2 、 client5 和 client1 之间的关系
-
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端
布隆过滤器TODO
-
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的
它实际上是一个很长的二进制向量(位图 bitmap)和一系列随机映射函数。主要用于判断一个元素是否在一个集合中
它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难
hyperloglog
-
HyperLogLog 是一种概率数据结构,它使用概率算法来统计集合的近似基数。而它算法的最本源则是伯努利过程
伯努利过程就是一个抛硬币实验的过程。抛一枚正常硬币,落地可能是正面,也可能是反面,二者的概率都是
1/2 -
Redis HyperLogLog 是用来做基数统计的算法
HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数
这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素
-
什么是基数
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数
缓存穿透
-
我们使用Redis大部分情况都是通过Key查询对应的值,假如发送的请求传进来的key是不存在Redis中的,那么就查不到缓存,查不到缓存就会去数据库查询。
假如有大量这样的请求,这些请求像“穿透”了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。
-
解决方案:
-
1、把无效的Key存进Redis中。如果Redis查不到数据,数据库也查不到,我们把这个Key值保存进Redis,设置value=“null”,当下次再通过这个Key查询
时就不需要再查询数据库。这种处理方式肯定是有问题的,假如传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。
-
2、使用布隆过滤器。布隆过滤器的作用是某个 key 不存在,那么就一定不存在,它说某个 key 存在,那么很大可能是存在(存在一定的误判率)。于是我们
可以在缓存之前再加一层布隆过滤器,在查询的时候先去布隆过滤器查询 key 是否存在,如果不存在就直接返回。
-
缓存击穿
-
其实跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而缓存击穿是一个热点的Key,有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全
部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
-
解决方案:
- 1、上面说过了,如果业务允许的话,对于热点的key可以设置永不过期的key。
- 2、使用互斥锁。如果缓存失效的情况,只有拿到锁才可以查询数据库,降低了在同一时刻打在数据库上的请求,防止数据库宕机。
缓存雪崩
-
当某一个时刻出现大规模的缓存失效的情况,那么就会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导
致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
-
解决方案:
- 1、在原有的失效时间上加上一个随机值,比如1-5分钟随机。这样就避免了因为采用相同的过期时间导致的缓存雪崩。
- 2、使用熔断机制。当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
- 3、提高数据库的容灾能力,可以使用分库分表,读写分离的策略。
- 4、为了防止Redis宕机导致缓存雪崩的问题,可以搭建Redis集群,提高Redis的容灾性。
分布式锁
- 日常开发中,秒杀下单、抢红包等等业务场景,都需要用到分布式锁。而 Redis 非常适合作为分布式锁使用
简介
-
分布式锁其实就是控制分布式系统不同进程共同访问共享资源的一种锁的实现。
如果不同的系统或同一个系统的不同主机之间共享了某个临界资源,往往需要互斥来防止彼此干扰,以保证一致性。
特性
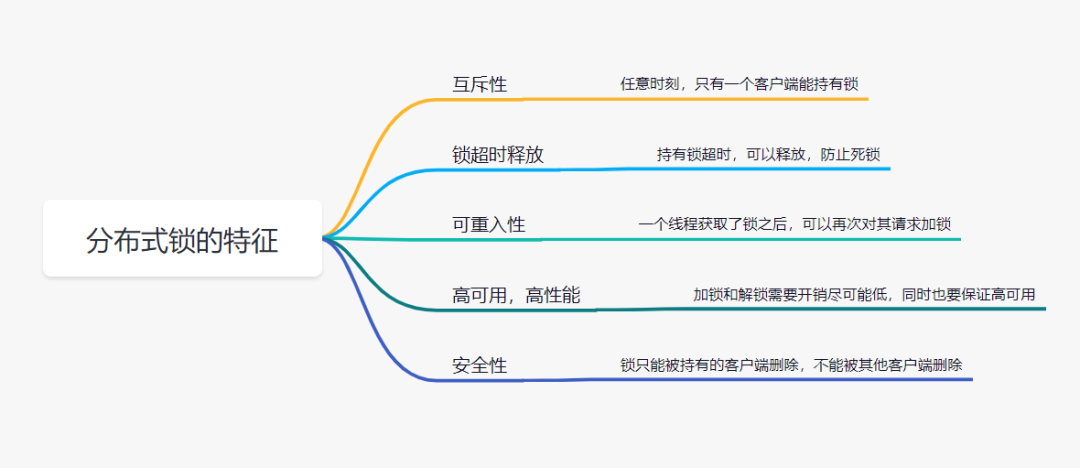
- 「互斥性」: 任意时刻,只有一个客户端能持有锁。
- 「锁超时释放」:持有锁超时,可以释放,防止不必要的资源浪费,也可以防止死锁。
- 「可重入性」: 一个线程如果获取了锁之后,可以再次对其请求加锁。
- 「高性能和高可用」:加锁和解锁需要开销尽可能低,同时也要保证高可用,避免分布式锁失效。
- 「安全性」:锁只能被持有的客户端删除,不能被其他客户端删除
方案一 SETNX + EXPIRE
-
即先用
setnx来抢锁,如果抢到之后,再用expire给锁设置一个过期时间,防止锁忘记了释放。 -
SETNX 是SET IF NOT EXISTS的简写,日常命令格式是SETNX key value,如果 key不存在,则SETNX成功返回1,如果这个key已经存在,则返回0。
-
方案中,
setnx和expire两个命令分开了,「不是原子操作」。如果执行完
setnx加锁,正要执行expire设置过期时间时,进程crash或者要重启维护了,那么这个锁就一直存在,「别的线程永远获取不到」。
方案二:SETNX + (系统时间+过期时间)
- 为了解决方案一,「发生异常锁得不到释放的场景」,可以把过期时间放到
setnx的value值里面。如果加锁失败,再拿出value值校验一下即可。 - 方案的优点是移除
expire单独设置过期时间的操作,把**「过期时间放到setnx的value值」**里面。解决了方案一发生异常,锁得不到释放的问题。 - 缺点:
- 过期时间是客户端自己生成的(System.currentTimeMillis()是当前系统的时间),必须要求分布式环境下,每个客户端的时间必须同步。
- 如果锁过期的时候,并发多个客户端同时请求过来,都执行jedis.getSet(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。
- 该锁没有保存持有者的唯一标识,可能被别的客户端释放/解锁。
方案三:使用Lua脚本 (包含SETNX + EXPIRE两条指令)
- 使用Lua脚本来保证原子性(包含setnx和expire两条指令)
方案四:SET的扩展命令(SET EX PX NX)
-
保证
SETNX + EXPIRE两条指令的原子性,可以用Redis的SET指令扩展参数 -
SET key value [EX seconds] [PX milliseconds] [NX|XX],它也是原子性的
- NX : 表示key不存在的时候,才能set成功,也即保证只有第一个客户端请求才能获得锁,而其他客户端请求只能等其释放锁,才能获取。
- EX seconds : 设定key的过期时间,时间单位是秒。
- PX milliseconds: 设定key的过期时间,单位为毫秒
- XX: 仅当key存在时设置值
-
方案可能存在的问题:
-
问题一:** 「锁过期释放了,业务还没执行完」**。
假设线程a获取锁成功,一直在执行临界区的代码。但是100s过去后,它还没执行完。但是,这时候锁已经过期了,此时线程b又请求过来。
显然线程b就可以获得锁成功,也开始执行临界区的代码。那么问题就来了,临界区的业务代码都不是严格串行执行的啦。
-
问题二:** 「锁被别的线程误删」**。
假设线程a执行完后,去释放锁。但是它不知道当前的锁可能是线程b持有的(线程a去释放锁时,有可能过期时间已经到了,此时线程b进来占有了锁)。
那线程a就把线程b的锁释放掉了,但是线程b临界区业务代码可能都还没执行完呢。
-
方案五:SET EX PX NX + 校验唯一随机值,再删除
- 既然锁可能被别的线程误删,给value值设置一个标记当前线程唯一的随机数,在删除的时候,校验一下
- 判断是不是当前线程加的锁和释放锁不是一个原子操作。如果调用jedis.del()释放锁的时候,可能这把锁已经不属于当前客户端,会解除他人加的锁。
方案六:Redisson框架
-
方案五还是可能存在**「锁过期释放,业务没执行完」**的问题。
-
是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。
-
Redisson底层原理图
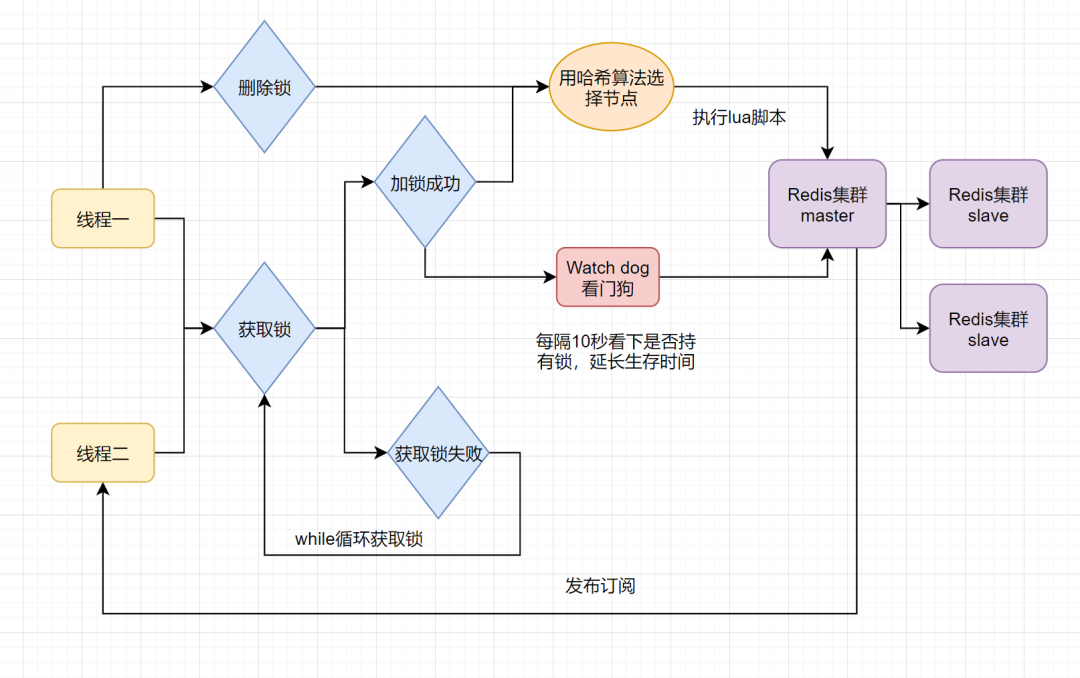
-
只要线程一加锁成功,就会启动一个
watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了**「锁过期释放,业务没执行完」**问题。
方案七:多机实现的分布式锁Redlock+Redisson
-
前面六种方案都只是基于单机版的讨论,还不是很完美。Redis一般都是集群部署的
-
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节
点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
-
为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock。
-
Redlock核心思想:
- 搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。
- 同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
-
RedLock的实现步骤:
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁
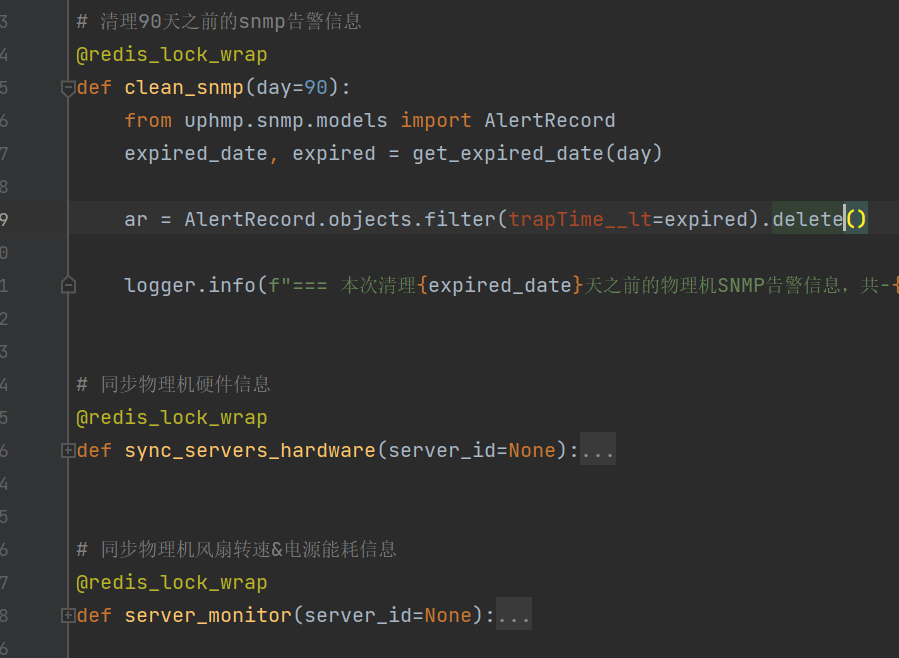
# 定制定时任务redis锁
def redis_lock_wrap(func):
@wraps(func)
def inner(*args, **kwargs):
hostname = socket.gethostname()
random_sleep(hostname)
name = func.__name__
res = dict()
try:
with redis_lock.Lock(check_redis(), name, expire=60, id=hostname):
logger.info(f'>>> hostname: {hostname} scheduler job < {name} > execute START...')
close_old_connections()
res = func(*args, **kwargs)
logger.info(f'>>> hostname: {hostname} scheduler job < {name} > execute OVER!!!')
except redis_lock.AlreadyAcquired:
logger.info(f'>>> Other service already execute this job: {name} !!!')
except redis_lock.NotAcquired:
logger.info(f'>>> Redis lock already release: {name} !!!')
except Exception as e:
traceback.print_exc()
logger.error(e)
return res
return inner
Pool_leader = redis.ConnectionPool(host=REDIS_CONFIG["redis_server"],
port=REDIS_CONFIG["redis_port"],
password=REDIS_CONFIG["redis_password"],
max_connections=REDIS_CONFIG["max_connections"],
decode_responses=True)
Pool_slave = redis.ConnectionPool(host=REDIS_CONFIG["redis_slave"],
port=REDIS_CONFIG["redis_slave_port"],
password=REDIS_CONFIG["redis_slave_password"],
max_connections=REDIS_CONFIG["max_connections"],
decode_responses=True)
def check_redis():
try:
redis_client = redis.Redis(connection_pool=Pool_leader, decode_responses=True)
redis_client.ping()
except ConnectionError:
redis_client = redis.Redis(connection_pool=Pool_slave, decode_responses=True)
return redis_client
分布式 id (UUID)
简介
-
UUID 是指 Universally Unique Identifier,翻译为中文是通用唯一识别码
UUID 的目的是让分布式系统中的所有元素都能有唯一的识别信息,尤其在分布式环境下,该ID需要不依赖中心认证即可自动生成全局唯一ID
如此一来,每个人都可以创建不与其它人冲突的 UUID,就不需考虑数据库创建时的名称重复问题
-
twitter 的 snowflake 可以看作是是 UUID1 的简化版
-
优势:
- 无需网络,单机自行生成
- 速度快,QPS高(支持100ns级并发)
- 各语言均有相应实现库供直接使用
-
缺点:
-
String存储,占空间,DB查询及索引效率低
-
无序,可读性差
-
根据实现方式不同可能泄露信息
-
实现版本
-
UUID1:
- 严格按照 UUID 定义的每个字段的意义来实现,使用的变量因子是 时间戳Timestamp+时钟序列Clock Sequence+node节点信息(Mac地址)
- 在一些分布式系统场景下是能严格保证全局唯一的,基本保证全球唯一性
- 缺点:使用了Mac地址,因此会暴露Mac地址和生成时间
-
UUID2:
- 基本和版本1一致,但是它主要适合 DCE( IBM 的一套分布式计算环境)
- 缺点:很少使用,常用库基本没有实现
-
UUID3:
- 基于 name 和 namespace 的 hash 实现变量因子,使用的是 md5 进行 hash 算法
- 不同名字空间或名字下的UUID是唯一的,相同名字空间及名字下得到的UUID保持重复
- 缺点:MD5碰撞问题,只用于向后兼容,后续不再使用
-
UUID4:
- 使用随机或者伪随机实现变量因子,实现简单
- 缺点:重复几率可计算
-
UUID5:
- 基于 name 和 namespace 的 hash 实现变量因子,使用的是 sha1 进行 hash 算法
- 不同名字空间或名字下的UUID是唯一的,相同名字空间及名字下得到的UUID保持重复
- 缺点:SHA1计算相对耗时
-
总结
-
版本 1/2 基于时间的UUID,适用于需要高度唯一性且无需重复的场景
-
版本 3/5 基于名称哈希的UUID,适用于一定范围内唯一,具有名称不可变性,可重复生成
-
版本 4 适用于对唯一性要求不太严格且追求简单的场景
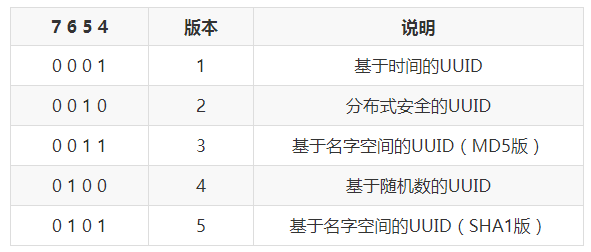
-
版本区别
-
version4,timestamp,clock sequence, node 都是随机或者伪随机的
-
version3和5,是基于name和namesapce 的hash算法生成
其中的name 和 namespace 基本上和我们很多语言的命名空间,类名一样,它的基本要求就是,name + namespace 才是唯一确定hash串的标准。
换句话说,一样的 namespace + name 使用相同的 hash 算法(比如version3的md5)计算出来的结果必须是一样的,但是不同的 namespace 中的同样的
name 生成的结果是不一样的。
version3 和 version5 中的三个变量因子都是由hash 算法保证的,version3是md5, version5是sha1。
基本结构
-
UUID 长度是128 bit( 16字节(128位)),换算为16进制数值 (每4位代表一个数值) 就是有32个16进制数值组成
中间使用 4个 - 进行分隔,按照 8-4-4-4-12 的顺序进行分隔,加上中间的横杆,UUID 有36个字符
如:** 3e350a5c-222a-11eb-abef-0242ac110002**
# UUID的格式:
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
M 位置,代表版本号,由于UUID的标准实现有5个版本,所以只会是1,2,3,4,5
N 位置,只会是 8,9,a,b
- UUID 结构图
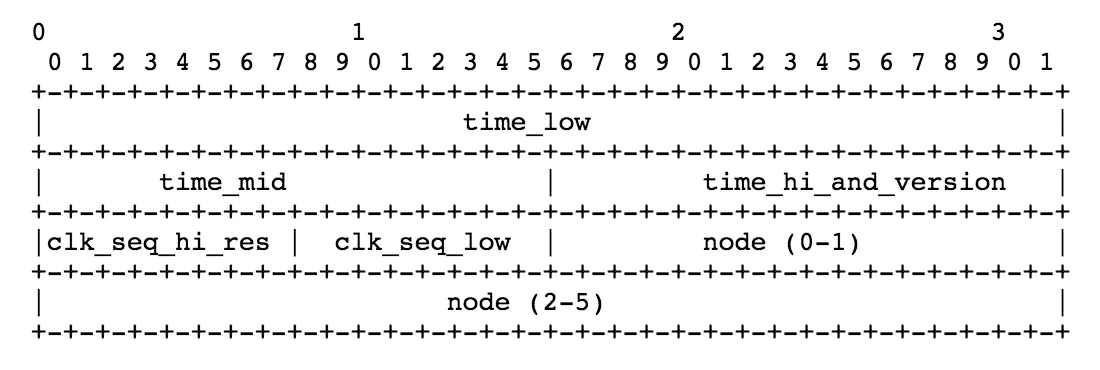
结构详解
Timestamp - 时间戳
- Timestamp 是一个 60 bits 的无符号数。对于 version 为 1 的 UUID,它从 1582-10-15 00:00:000000000 起到当前 UTC 时间,每隔 100 纳秒加一
- 对于无法获取UTC时间的系统,由于获取不到UTC,那么你可以统一采用 localtime。(实际上一个系统时区相同就可以了)
time_low
- timestamp 60bit 中的 0~31bit,共32bit
time_mid
- timestamp 60bit 中的 32~47bit,共16bit
time_hi_and_version
- 包含两个部分,time_hi 和 version。version 占用 bit 数为4,代表它最多可以支持31个版本。time_hi 就是 timestamp 剩余的12bit,一共是16bit
Clock Sequence - 时钟序列
-
不同于时间值,时钟序列实际上是表示一种逻辑序列,用于标识事件发生的顺序。
-
“时钟序列"似乎是一个真正令人误解的名称。 根据其定义,更好的名称可能是” uuid的随机组件"。
-
如果计算 UUID 的机器进行了时间调整,或者是nodeId变化了(主机更换网卡),和其他的机器冲突
这个时候,就需要有个变量因子进行变化来保证再次生成的 UUID 的唯一性
其实 Clock Sequence 的变化算法很简单,当时间调整,或者 nodeId 变化的时候,直接使用一个随机数
或者,在原先的 Clock Sequence 值上面自增加一
-
Clock Sequence 一共是14bit
clock_seq_low
- Clock Sequence 中的 0~7 bit 共 8bit
clock_seq_hi_and_reserved
- 包含两个部分,reserved 和 clock_seq_hi
- 其中 clock_seq_hi 为 Clock Sequence 中的 8~13 bit 共6个bit,reserved 是2bit,reserved 一般设置为10
node - 节点信息
-
Node 是一个 48 bits 的无符号数,对于 version 为 1 的 UUID,它选取 IEEE 802 MAC 地址,即网卡的 MAC 地址
当系统有多块网卡时,任何一块有效的网卡都可被做 Node 数据;对于没有网卡的系统,取值为随机数
雪花算法
- 定义一个64bit的数,对指定机器 & 同一时刻 & 某一并发序列,是唯一的,其极限QPS约为400w/s


-
雪花算法将64 bit分为了四部分
- 其中时间戳有时间上限(69年)
- 机器id只有10位,能记录1024台机器,常用前几位表示数据中心id,后几位表示数据中心内的机器id
- 序列号用来对同一个毫秒之内的操作产生不同的ID,最多4095个
-
这种结构是雪花算法提出者Twitter的分法,但实际上这种算法使用可以很灵活,根据自身业务的并发情况、机器分布、使用年限等,可以自由地重新决定各部
分的位数,从而增加或减少某部分的量级。
比如百度的UidGenerator、美团的Leaf等,都是基于雪花算法做一些适合自身业务的变化。
-
由于雪花算法是强依赖于时间的,在分布式环境下,如果发生时钟回拨,很可能会引起id冲突的问题。
-
解决方案:
-
将ID生成交给少量服务器,并关闭时钟同步
-
直接报错,交给上层业务处理。
-
如果回拨时间较短,在耗时要求内,比如5ms,那么等待回拨时长后再进行生成。
-
如果回拨时间很长,那么无法等待,可以匀出少量位(1~2位)作为回拨位,一旦时钟回拨,将回拨位加1,可得到不一样的ID,2位回拨位允许标记三次时钟回拨,基本够使用。如果超出了,可以再选择抛出异常。
-
总结
- 常用的分布式唯一ID生成思路基本是利用一个长串数字或字符串,将其分割成多个部分,分别记录时间信息、机器/名字信息、随机信息、序列信息等
- 时间信息部分决定了该策略能使用的时长
- 机器/名字信息支持了分布式环境下的独自生成唯一ID与识别能力
- 序列信息保证了事件的顺序记录以及同一时间单位下的并发数
- 而随机信息则加大了ID整体的不可识别性
CDN
简介
-
CDN的全称是Content Delivery Network,即内容分发网络
其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络"边缘",使用户可以就近取得所需的内容,解决Internet网络
拥塞状况,提高用户访问网站的响应速度。从技术上解决由于网络带宽小、用户访问量大、网点分布不均等问题,解决用户访问网站的响应速度慢的根本原因
CDN网络是在用户和服务器之间增加Cache层,如何将用户的请求引导到Cache上获得源服务器的数据,主要是通过接管DNS实现
-
多台Cache加速服务器分布在不同地域,需要通过有效地机制管理Cache网络,引导用户就近访问,全局负载均衡流量,这就是CDN内容传输网络的基本思想
-
网络缓存技术,其目的就是减少网络中冗余数据的重复传输,使之最小化,将广域传输转为本地或就近访问
-
缓存服务器能比Web服务器获得更高的性能,缓存服务器不仅能提高响应速度,节约带宽,对于加速Web服务器,有效减轻源服务器的负荷是非常有效的
用户访问流程
-
用户向浏览器提供要访问的域名,经过本地DNS系统解析(CDN对域名解析过程进行了调整),解析函数库得到该域名对应的CNAME记录,对获得的
CNAME域名进行解析以得到实际的IP地址,DNS系统会最终将域名的解析权交给CNAME指向的CDN专用DNS服务器,在此过程中,使用的全局负载均衡DNS
解析,如根据地理位置信息解析对应的IP地址,使得用户能就近访问
-
A记录,即Address记录,它并不是一个IP或者一个域名,我们可以把它理解为一种指向关系:
域名 http://www.xx.com → 111.111.111.111 主机名 DD → 222.222.222.222
也就是当你访问这些域名或者主机名的时候,DNS服务器上会通过A记录会帮你解析出相应的IP地址,以达到后续访问目的
所以A记录是IP解析,直接将域名或主机名指向某个IP
-
CNAME 别名记录,也被称为规范名字,这种记录允许将多个名字映射到同一台计算机
当需要将域名指向另一个域名,再由另一个域名提供 ip地址,就需要添加 CNAME 记录
CNAME会解析到另一个域名,之后再对另一个域名继续解析,直到解析出节点
-
CDN全局负载均衡设备根据用户ip和url,选择一台用户所属区域的区域负载均衡设备
-
区域负载均衡设备会为用户选择一台合适的缓存服务器提供服务,选择的依据包括:
-
根据用户IP地址,判断哪一台服务器距用户最近
-
根据用户所请求的URL中携带的内容名称,判断哪一台服务器上有用户所需内容
-
查询各个服务器当前的负载情况,判断哪一台服务器尚有服务能力
-
基于以上这些条件的综合分析之后,区域负载均衡设备会向全局负载均衡设备返回一台缓存服务器的IP地址
-
全局负载均衡设备把服务器的IP地址返回给用户
-
-
-
解析得到CDN缓存服务器的IP地址,浏览器在得到实际的IP地址以后,向缓存服务器发出访问请求
-
缓存服务器根据浏览器提供的要访问的域名,通过Cache内部专用DNS解析得到此域名的实际IP地址,再由缓存服务器向此实际IP地址提交访问请求
-
缓存服务器从实际IP地址得得到内容以后,一方面在本地进行保存,以备以后使用,二方面把获取的数据返回给客户端,完成数据服务过程
-
用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端
-
如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追
溯到网站的源服务器将内容拉到本地
-
-
客户端得到由缓存服务器返回的数据以后显示出来并完成整个浏览的数据请求过程
总结
- DNS服务器根据用户IP地址,将域名解析成相应节点的缓存服务器IP地址,实现用户就近访问
- 使用CDN服务的网站,只需将其域名解析权交给CDN的GSLB设备,将需要分发的内容注入CDN,就可以实现内容加速
缓存机制
-
当用户访问一个网站时,客户端直接从源站点获取数据,当服务器访问量大时会影响访问速度,影响用户体验,且无法保证客户端与源站点间的距离足够短,
适合传输数据。CDN(内容分发网络),解决的正是如何将数据快速可靠地从源站点传递到客户端。通过数据分发,用户可以从一个距离较近的服务器获取数
据,而不是源站点,从大达实现快速访问,减少源站点负载均衡的压力
-
用户第一次访问网站后,网站的一些静态资源如图片等会被下载到本地,作为缓存,当用户第二次访问该网站的时候,浏览器就会从缓存中加载资源,不用向
服务器请求资源,从而提高了网站的访问速度。若使用了CDN缓存,当浏览器本地缓存的资源过期后,浏览器不是直接向源站点请求资源,而是向CDN边缘请
求资源。若CDN中的缓存过期,那就由CDN边缘节点向源站点发出回源请求来获取最新资源
-
CDN节点缓存机制在不同服务商中是不同的,但一般都遵循HTTP协议,通过http响应头中的Cache-Control:max-age的字段来设置CDN节点文件缓存时间。
当客户端向CDN节点请求数据时,CDN会判断缓存数据是否过期,若没有过期,则直接将缓存数据返回给客户端,否则就向源站点发出请求,从源站点拉取最
新数据,更新本地缓存,并将最新数据返回给客户端。CDN服务商一般会提供基于文件后缀、目录多个维度来指定CDN缓存时间,为用户提供更精细化的缓存
管理。CDN缓存时间会对“回源率”产生直接的影响,若CDN缓存时间短,则数据经常失效,导致频繁回源,增加了源站的负载,同时也增大了访问延时;若缓
存时间长,数据更新时间慢,因此需要针对不同的业务需求来选择特定的数据缓存管理
适用场景
- 用户与业务服务器地域间物理距离较远,需要进行多次网络转发,传输延时较高且不稳定
- 用户使用运营商与业务服务器所在运营商不同,请求需要运营商之间进行互联转发
- 业务服务器网络带宽、处理能力有限,当接收到海量用户请求时,会导致响应速度降低、可用性降低
跨域问题
- HTTP Response Headers:access-control-allow-origin:*
- 通配符 ***** 表示允许被任何网站引用。如果想让资源只被指定域名访问,只需把 ***** 改为域名
计算机网络
OSI 七层协议


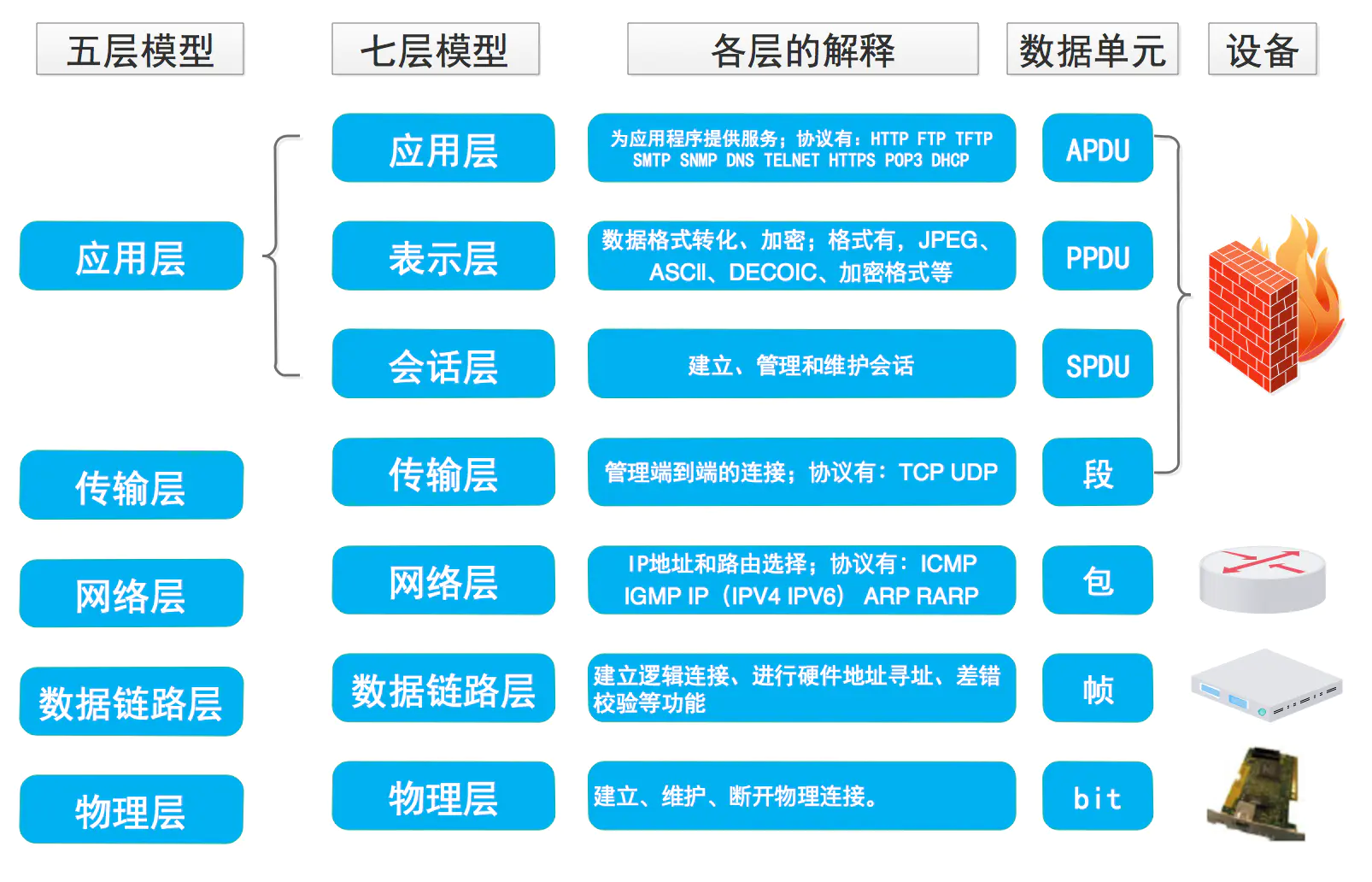
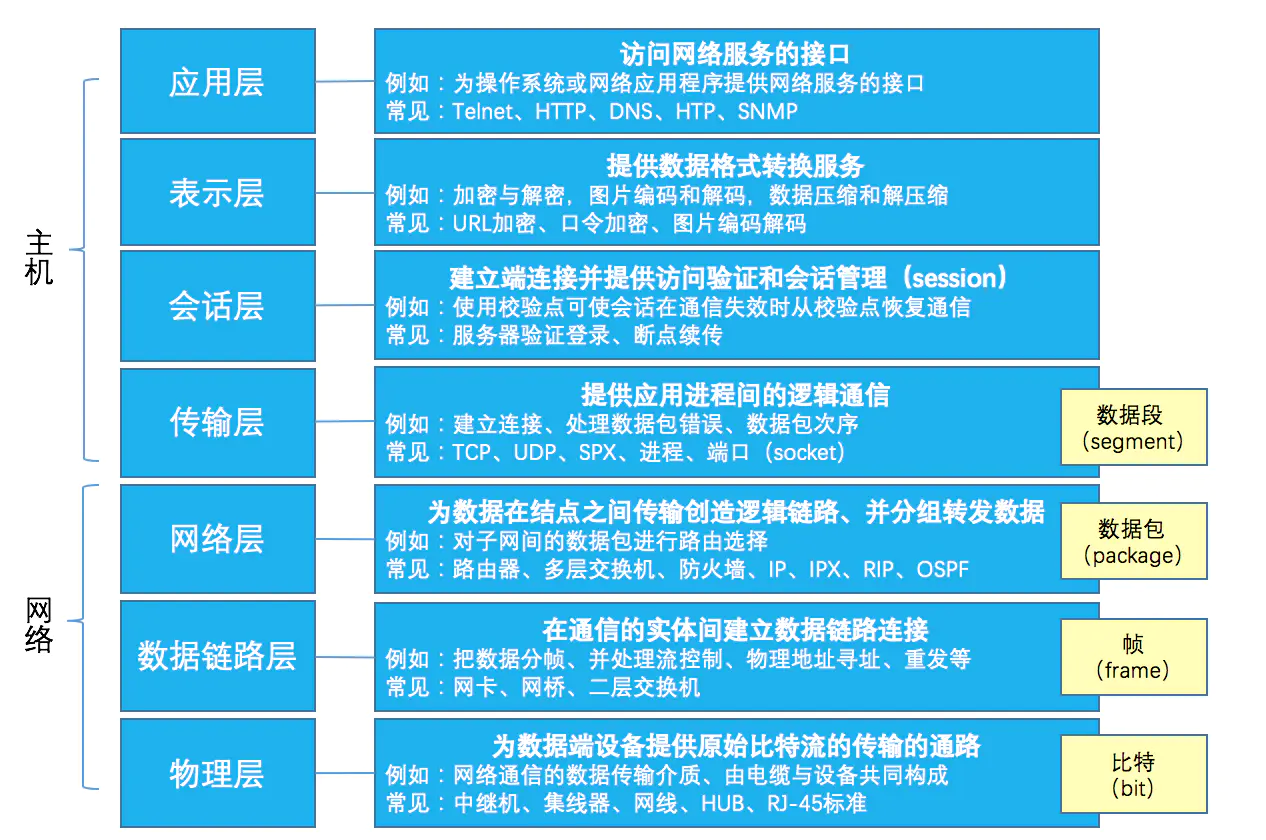
-
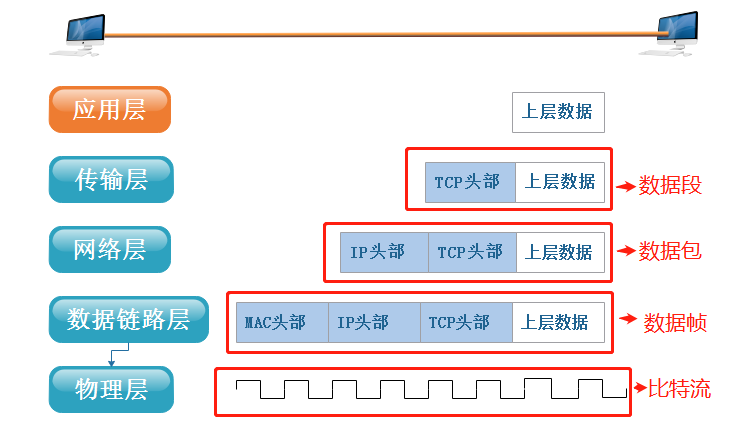
-
七层模型传输数据过程
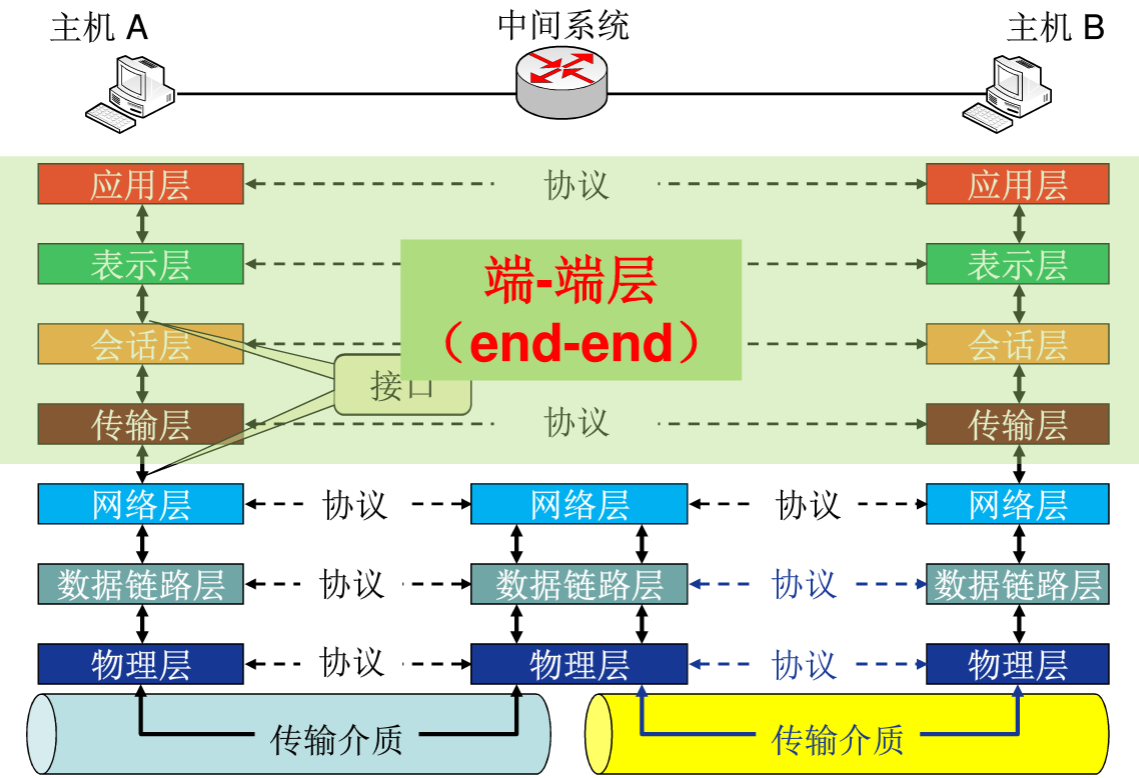

-
发送端想要发送数据到接收端
- 首先应用层准备好要发送的数据,然后给了传输层
- 传输层的主要作用就是为发送端和接收端提供可靠的连接服务,传输层将数据处理完后就给了网络层
- 网络层的功能就是管理网络,其中核心的功能就是路径的选择(路由),从发送端到接收端有很多条路,网络层就负责管理下一步数据应到哪个路由器
- 选择好了路径之后,数据就来到了数据链路层,这一层就是负责将数据从一个路由器送到另一个路由器
- 然后就是物理层,可以简单的理解,物理层就是网线一类的最基础的设备
HTTP
简介
-
HTTP 协议即超文本传送协议(Hypertext Transfer Protocol ),是 Web 联网的基础,HTTP 协议是建立在 TCP 协议之上的一种应用
-
HTTP 是应用层协议,主要解决如何包装数据
-
HTTP协议是无状态的
-
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态
从另一方面讲,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系
-
HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(无连接)
-
从HTTP/1.1起,默认都开启了Keep-Alive(Connection: keep-alive),保持连接特性
简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭
如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间
-
HTTP是一个无状态协议,这意味着每个请求都是独立的
Keep-Alive(服务器处理完客户的请求后,并收到客户端的应答后,不会立即断开)没能改变这个结果
-
请求流程
- 域名解析
- 与服务器建立连接
- 发起HTTP请求
- 服务器响应HTTP请求,浏览器得到html代码
- 浏览器解析html代码,并请求html代码中的资源(如js、css、图片)
- 浏览器对页面进行渲染呈现给用户
HTTP 前端
-
当我们在浏览器里输入一个 URL 后,最终会呈现一个完整的网页。这中间会经历如下的过程:
-
HTML的加载
输入URL后,最先拿到的是 HTML 文件。HTML是一个网页的基础,所以要在最开始的时候下载它。HTML下载完成以后就会开始对它进行解析
-
其他静态资源下载
HTML在解析的过程中,如果发现 HTML 文本里面夹杂的一些外部的资源链接,比如CSS、JS 和图片等时,会立即启用别的线程下载这些静态资源
这里有个特殊的是JS 文件,当遇到 JS 文件的时候,HTML 的解析会停下来,等 JS 文件下载结束并且执行完HTML的解析工作再接着来
这样做是因为JS 里可能会出现修改已经完成的解析结果有白白浪费资源的风险,所以HTML 解析器脆等JS 折腾完了再干
-
DOM树构建
在HTML 解析的同时,解析器会把解析完的HTML转化成DOM 对象,再进一步构建DOM树
-
CSSOM 树构建
当CSS 下载完,CSS 解析器就开始对 CSS 进行解析,把 CSS 解析成 CSS 对象,然后把这些 CSS 对象组装起来,构建出一棵 CSSOM 树
-
渲染树构建
DOM树和CSSOM树都构建完成以后,浏览器会根据这两棵树构建出一棵渲染树
-
布局计算
渲染树构建完成以后,所有元素的位置关系和需要应用的样式就确定了。这时候浏览器会计算出所有元素的大小和绝对位置
-
布局计算完成以后,浏览器就可以在页面上渲染元素了
比如从(x1,y1)到(x2y2)的正方形区域渲染成蓝色。经过渲染引擎的处理后,整个页面就显示在了屏幕上
-
TCP/IP
-
TCP/IP(TCP(传输控制协议)和IP(网际协议))提供点对点的链接机制,将数据应如何封装、定址、传输、路由以及在目的地如何接收,都加以标准化。
-
TCP(Transmission Control Protocol)协议是传输层协议,主要解决数据如何在网络中传输
-
是一种面向连接的、可靠的、基于字节流的通信协议
-
数据在传输前要建立连接,传输完毕后还要断开连接
客户端在收发数据前要使用 connect() 函数和服务器建立连接
建立连接的目的是保证IP地址、端口、物理链路等正确无误,为数据的传输开辟通道
-
-
IP (Internet Protocol)协议对应于网络层
TCP/UDP
TCP
- TCP是面向连接的,无论哪一方向另一方发送数据之前,都必须先在双方之间建立一条连接。
- 在TCP/IP协议中,TCP协议提供可靠的连接服务,连接是通过三次握手进行初始化的。
- 三次握手的目的是同步连接双方的序列号和确认号并交换 TCP窗口大小信息。
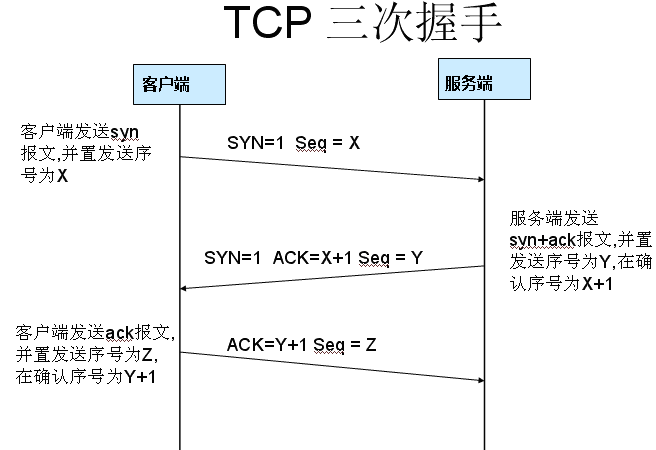
第一次握手:
-
建立连接。客户端发送连接请求报文段,将SYN位置为1,Sequence Number为x;然后,客户端进入SYN_SEND状态,等待服务器的确认;
SYN=1 时,说明这是一个请求建立连接或同意建立连接的报文。 只有在前两次握手中 SYN 才为 1。
第二次握手:
-
服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置Acknowledgment Number为x+1(Sequence Number+1);
同时,自己自己还要发送SYN请求信息,将SYN位置为1,Sequence Number为y;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并
发送给客户端,此时服务器进入SYN_RECV状态;
第三次握手:
-
客户端收到服务器的SYN+ACK报文段。然后将Acknowledgment Number设置为y+1,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器
端都进入ESTABLISHED状态,完成TCP三次握手。
三次握手原因
-
为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
-
具体例子
-
已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到
连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新
的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并
没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。
这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。
server由于收不到确认,就知道client并没有要求建立连接。
-
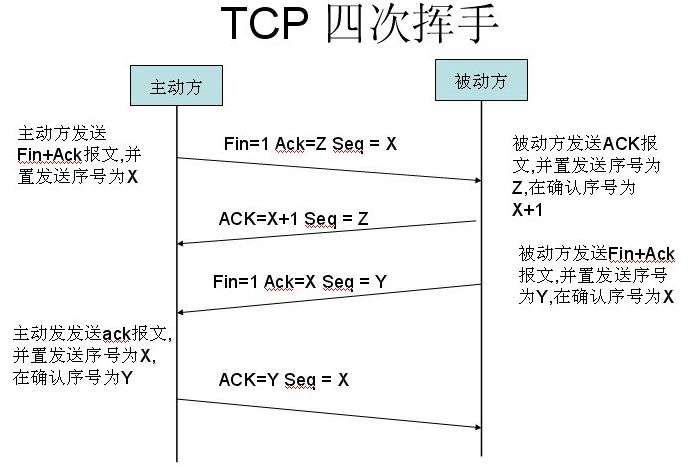
当客户端和服务器通过三次握手建立了TCP连接以后,当数据传送完毕,肯定是要断开TCP连接的啊。那对于TCP的断开连接,这里就有了“四次分手”。
第一次分手:
-
m主机1(可以使客户端,也可以是服务器端),设置Sequence Number,向主机2发送一个FIN报文段;此时,主机1进入FIN_WAIT_1状态;这表示主机1没
有数据要发送给主机2了;
第二次分手:
-
主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入FIN_WAIT_2状态;主机2
告诉主机1,我“同意”你的关闭请求;
第三次分手:
- 主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入LAST_ACK状态;
第四次分手:
-
主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机
1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。
四次分手原因
-
TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。
-
TCP是全双工模式,这就意味着,当主机1发出FIN报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;但
是,这个时候主机1还是可以接受来自主机2的数据;当主机2返回ACK报文段时,表示它已经知道主机1没有数据发送了,但是主机2还是可以发送数据到主机1
的;当主机2也发送了FIN报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP
连接。
-
第四次挥手后为了保证发送的ack成功被对方接收需要等待2MSL的时间。
(MSL:报文的最长生存时间(Maximum Segment Lifetime),规定是MSL为2分钟,2MSL就是4分钟,但是实际中30秒、1分钟、2分钟都在使用)
客户端最后一次向服务器回传ACK包时,有可能会因为网络问题导致服务器收不到,服务器会再次发送 FIN 包,如果这时客户端完全关闭了连接,那么服务器
无论如何也收不到ACK包了,所以客户端需要等待片刻、确认对方收到ACK包后才能进入CLOSED状态。
数据包在网络中是有生存时间的,超过这个时间还未到达目标主机就会被丢弃,并通知源主机,这称为报文最大生存时间。
TIME_WAIT 要等待 2MSL 才会进入 CLOSED 状态,ACK 包到达服务器需要 MSL 时间,服务器重传 FIN 包也需要 MSL 时间,2MSL 是数据包往返的最大时
间,如果 2MSL 后还未收到服务器重传的 FIN 包,就说明服务器已经收到了 ACK 包。
客户端的最后一个ACK报文在传输的时候丢失,服务器并没有接收到这个报文。这时服务器就会超时重传这个FIN消息,接着客户端再重传一次确认,重新启动时间等待计时器。
UDP
- UDP是一个无状态的传输协议,所以它在传递数据时非常快。
- 不可靠,不稳定,因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。
TCP与UDP的区别
- 基于连接与无连接;
- 对系统资源的要求(TCP较多,UDP少);
- UDP程序结构较简单;
- 流模式与数据报模式 ;
- TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证。
TCP 粘包问题
简介
-
TCP粘包就是指发送方发送的若干包数据到达接收方时粘成了一包,从接收缓冲区来看,后一包数据的头紧接着前一包数据的尾,出现粘包的原因是多方面
的,可能是来自发送方,也可能是来自接收方。
-
TCP是面向字节流的协议,就是没有界限的一串数据,本没有“包”的概念,“粘包”和“拆包”一说是为了有助于形象地理解这两种现象。
-
粘包拆包问题在数据链路层、网络层以及传输层都有可能发生。日常的网络应用开发大都在传输层进行
由于UDP有消息保护边界,不会发生粘包拆包问题,因此粘包拆包问题只发生在TCP协议中
补充
长连接
- Client方与Server方先建立通讯连接,连接建立后不断开, 然后再进行报文发送和接收。
短连接
- Client方与Server每进行一次报文收发交易时才进行通讯连接,交易完毕后立即断开连接。
场景
- 因为TCP是面向流,没有边界,而操作系统在发送TCP数据时,会通过缓冲区来进行优化,例如缓冲区为1024个字节大小。
- 如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题。
- 如果一次请求发送的数据量比较大,超过了缓冲区大小,TCP就会将其拆分为多次发送,这就是拆包。
关于粘包和拆包可以参考下图的几种情况:
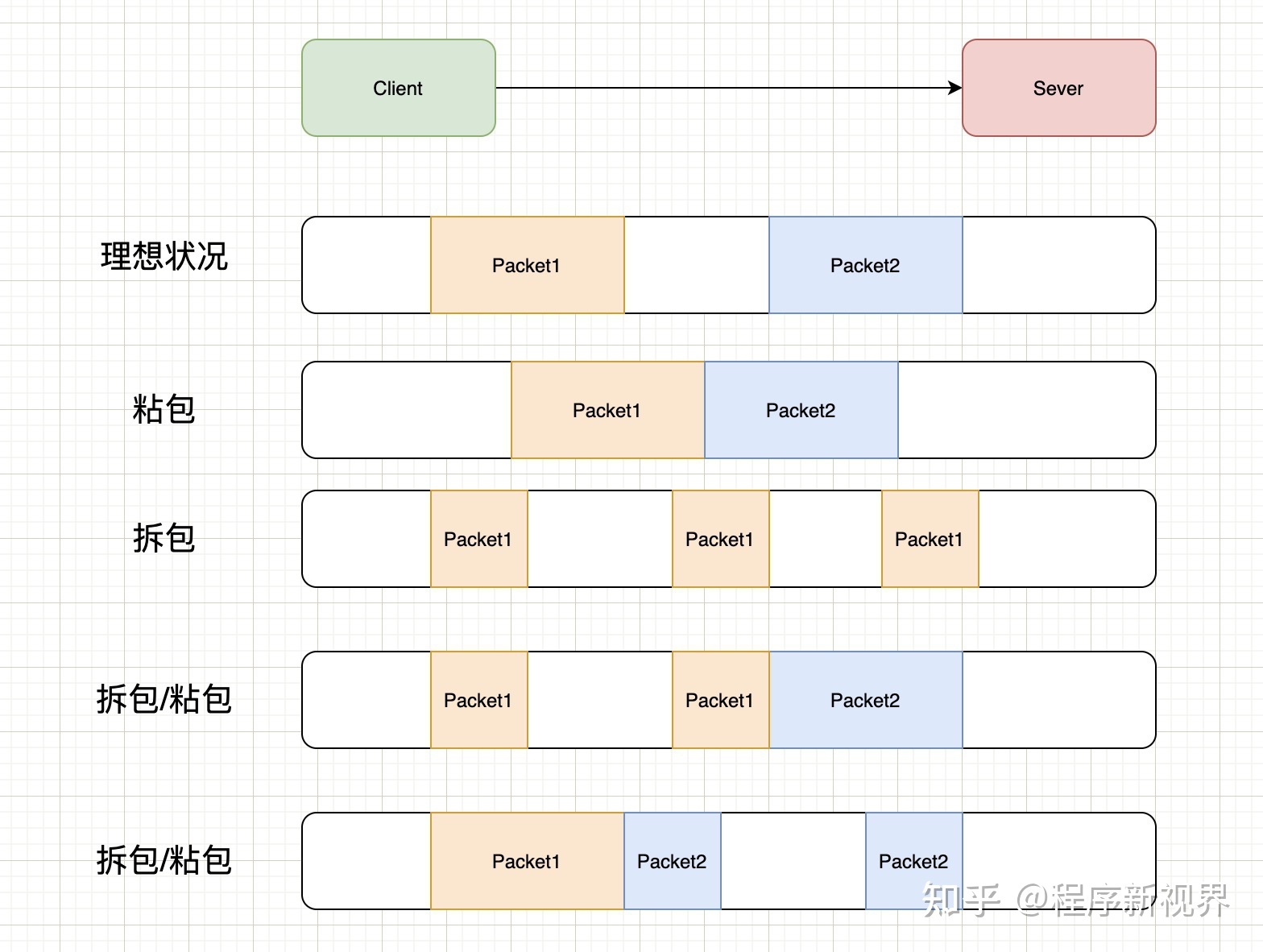
上图中演示了以下几种情况:
- 正常的理想情况,两个包恰好满足TCP缓冲区的大小或达到TCP等待时长,分别发送两个包
- 粘包:两个包较小,间隔时间短,发生粘包,合并成一个包发送
- 拆包:一个包过大,超过缓存区大小,拆分成两个或多个包发送
- 拆包和粘包:Packet1过大,进行了拆包处理,而拆出去的一部分又与Packet2进行粘包处理
解决方案
对于粘包和拆包问题,常见的解决方案有四种:
- 发送端将每个包都封装成固定的长度,比如100字节大小。如果不足100字节可通过补0或空等进行填充到指定长度
- 发送端在每个包的末尾使用固定的分隔符,例如\r\n。如果发生拆包需等待多个包发送过来之后再找到其中的\r\n进行合并;例如,FTP协议
- 将消息分为头部和消息体,头部中保存整个消息的长度,只有读取到足够长度的消息之后才算是读到了一个完整的消息
- 通过自定义协议进行粘包和拆包的处理
UDP 丢包问题
丢包原因
-
接收端处理时间过长导致丢包
-
调用recv方法接收端收到数据后,处理数据花了一些时间,处理完后再次调用recv方法,在这二次调用间隔里,发过来的包可能丢失
服务器程序启动之出,开辟两个线程
- 一个线程专门用于接收数据包,并存放在应用层的缓存区
- 另外一个线程用于专门处理和响应数据包请求,避免因为处理数据造成数据丢包
- 其本质上还是增大了缓冲区大小,只是将系统缓冲区转移到了应用层自己的缓冲区。
-
-
发送的包巨大丢包
-
虽然send方法会帮你做大包切割成小包发送的事情,但包太大也不行。例如超过50K的一个udp包,不切割直接通过send方法发送也会导致这个包丢失
这种情况需要切割成小包再逐个send
-
-
发送的包较大,超过接受者缓存导致丢包
-
包超过mtu size (最大传输单元 Maximum Transmission Unit) 数倍,几个大的udp包可能会超过接收者的缓冲,导致丢包
这种情况可以设置socket接收缓冲,增加系统发送或接收缓冲区大小
-
-
发送的包频率太快
-
虽然每个包的大小都小于mtu size 但是频率太快,例如40多个mut size的包连续发送中间不sleep,也有可能导致丢包
这种情况也有时可以通过设置socket接收缓冲解决,但有时解决不了
增加应答机制,处理完一个包后,在继续发包(类似TCP的握手)
-
-
在应用层实现丢包重发机制和超时机制,确保数据包不丢失(类似TCP协议),要保证数据安全可靠最好的就是使用TCP
QUIC
QUIC(Quick UDP Internet Connection)
- 由 Google 设计提出,目前由 IETF 工作组推动进展,其设计的目标是替代 TCP 成为 HTTP/3 的数据传输层协议
- QUIC 是一种使用 udp 进行多路并发传输(多路复用)和安全的通用传输协议
- 功能:
- 流(stream)多路复用
- 流(stream)和连接(connection)级别的流量控制
- 建立低延迟连接(1-RTT 或者 0-RTT)
- 连接迁移(Connection migration)和弹性 NAT 重绑定
- 经过身份验证和加密的头部(header) 和有效载荷(payload)
- Quic 相比现在广泛应用的 http2+tcp+tls 协议有如下优势 :
- 减少了 TCP 三次握手及 TLS 握手时间。
- 改进的拥塞控制。
- 避免队头阻塞的多路复用。
- 连接迁移。
- 前向冗余纠错。
- QUIC 建立了客户端(client)和服务端(server)之间有状态的交互连接。连接的主要目的是通过应用协议支持结构化的数据交换。
ARP
-
地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。
-
主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;
收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。
地址解析协议是建立在网络中各个主机互相信任的基础上的,局域网络上的主机可以自主发送ARP应答消息,其他主机收到应答报文时不会检测该报文的真实
性就会将其记入本机ARP缓存。
DNS 查询原理详解
-
通过 DNS 查询,得到域名的 IP 地址,才能访问网站
DNS 服务器
-
域名对应的 IP 地址,都保存在 DNS 服务器
我们输入域名,浏览器就会在后台,自动向 DNS 服务器发出请求,获取对应的 IP 地址。这就是 DNS 查询
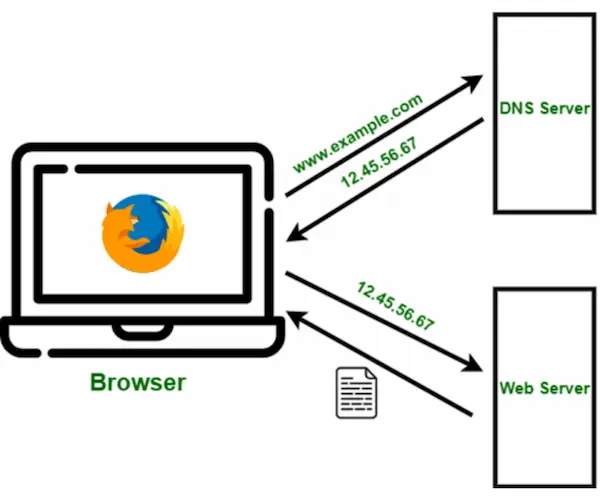
-
举例来说,我输入
es6.ruanyifeng.com这个域名,浏览器就要向 DNS 服务器查询,它的 IP 地址是什么,然后向该 IP 发出访问请求
dig 命令
-
命令行工具 dig 可以跟 DNS 服务器互动,我们就用它演示 DNS 查询。如果你还没有安装,可以搜一下安装方法,在 Linux 系统下是非常容易的
它的查询语法如下(美元符号
$是命令行提示符)
$ dig @[DNS 服务器] [域名]
- 向 1.1.1.1 查询域名,就执行下面的命令
$ dig @1.1.1.1 es6.ruanyifeng.com
- 正常情况下,它会输出一大堆内容
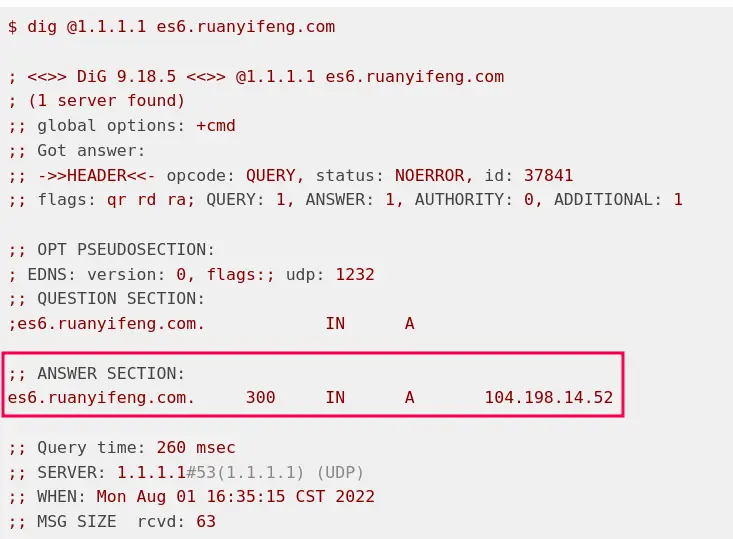
- 在其中找到 ANSWER SECTION 这个部分,它给出了查询的答案,域名对应的 IP 地址是 104.198.14.52
域名的树状结构
-
DNS 是一个分布式系统,1.1.1.1 只是用户查询入口,它也需要再向其他 DNS 服务器查询,才能获得最终的 IP 地址
要说清楚 DNS 完整的查询过程,就必须了解 域名是一个树状结构
最顶层的域名是根域名(root),然后是顶级域名(top-level domain,简写 TLD),再是一级域名、二级域名、三级域名
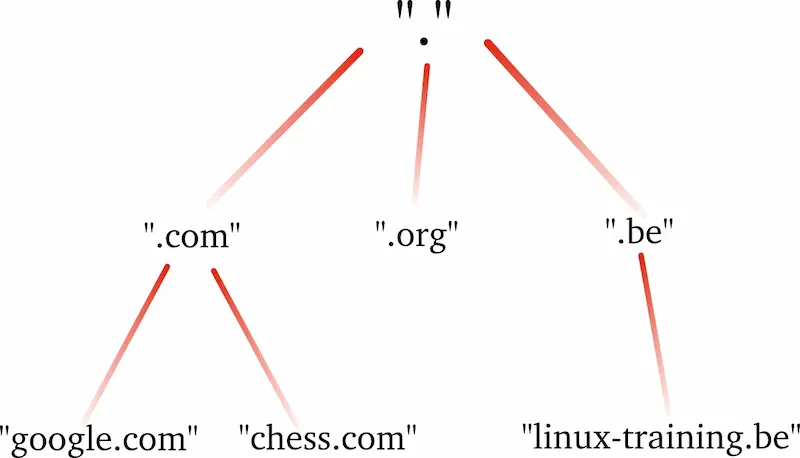
(1)根域名
-
所有域名的起点都是根域名,它写作一个点
.,放在域名的结尾因为这部分对于所有域名都是相同的,所以就省略不写了,比如
example.com等同于example.com.(结尾多一个点)你可以试试,任何一个域名结尾加一个点,浏览器都可以正常解读
(2)顶级域名
- 根域名的下一级是顶级域名,分成两种
- 通用顶级域名(gTLD,比如 .com 和 .net)
- 国别顶级域名(ccTLD,比如 .cn 和 .us)
- 顶级域名由国际域名管理机构 ICANN 控制,它委托商业公司管理 gTLD,委托各国管理自己的国别域名
(3)一级域名
-
一级域名就是你在某个顶级域名下面,自己注册的域名
比如,
ruanyifeng.com就是我在顶级域名.com下面注册的
(4)二级域名
-
二级域名是一级域名的子域名,是域名拥有者自行设置的,不用得到许可
比如,
es6就是ruanyifeng.com的二级域名
域名的逐级查询
-
这种树状结构的意义在于,只有上级域名,才知道下一级域名的 IP 地址,需要逐级查询
每一级域名都有自己的 DNS 服务器,存放下级域名的 IP 地址
所以,如果想要查询二级域名
es6.ruanyifeng.com的 IP 地址,需要三个步骤
第一步,查询根域名服务器,获得顶级域名服务器
.com(又称 TLD 服务器)的 IP 地址第二步,查询 TLD 服务器
.com,获得一级域名服务器ruanyifeng.com的 IP 地址第三步,查询一级域名服务器
ruanyifeng.com,获得二级域名es6的 IP 地址
根域名服务器
- 根域名服务器全世界一共有13台(都是服务器集群)。它们的域名和 IP 地址如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9OBXML2M-1673840082976)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/DNS_04.jpg)]
- 根域名服务器的 IP 地址是不变的,集成在操作系统里面。操作系统会选其中一台,查询 TLD 服务器的 IP 地址
$ dig @192.33.4.12 es6.ruanyifeng.com
- 上面示例中,我们选择
192.33.4.12,向它发出查询,询问es6.ruanyifeng.com的 TLD 服务器的 IP 地址,dig 命令的输出结果如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F86baBTm-1673840082976)(https://gitee.com/lifei_free/pic_storage_gitee/raw/master/picture/DNS_05.jpg)]
-
因为它给不了
es6.ruanyifeng.com的 IP 地址,所以输出结果中没有 ANSWER SECTION,只有一个 AUTHORITY SECTION,给出了com.的13台 TLD 服务器的域名。下面还有一个 ADDITIONAL SECTION,给出了这13台 TLD 服务器的 IP 地址(包含 IPv4 和 IPv6 两个地址)
TLD 服务器
- 有了 TLD 服务器的 IP 地址以后,我们再选一台接着查询
$ dig @192.41.162.30 es6.ruanyifeng.com
- 上面示例中,192.41.162.30 是随便选的一台 .com 的 TLD 服务器,我们向它询问
es6.ruanyifeng.com的 IP 地址。返回结果如下

-
依然没有 ANSWER SECTION 的部分,只有 AUTHORITY SECTION,给出了一级域名 ruanyifeng.com 的两台 DNS 服务器
下面的 ADDITIONAL SECTION 就是这两台 DNS 服务器对应的 IP 地址
一级域名的 DNS 服务器
- 第三步,再向一级域名的 DNS 服务器查询二级域名的 IP 地址
$ dig @172.64.32.123 es6.ruanyifeng.com
- 返回结果如下
- 这次终于有了 ANSWER SECTION,得到了最终的二级域名的 IP 地址,至此,三个步骤的 DNS 查询全部完成
DNS 服务器的种类
- 总结一下,上面一共提到了四种服务器
1.1.1.1
根域名服务器
TLD 服务器
一级域名服务器
它们都属于 DNS 服务器,都用来接受 DNS 查询。但是作用不一样,属于不同的类别
递归 DNS 服务器
-
后三种服务器只用来查询下一级域名的 IP 地址,而 1.1.1.1 则把分步骤的查询过程自动化,方便用户一次性得到结果
所以它称为递归 DNS 服务器(recursive DNS server),即可以自动递归查询
我们平常说的 DNS 服务器,一般都是指递归 DNS 服务器。它把 DNS 查询自动化了,只要向它查询就可以了
它内部有缓存,可以保存以前查询的结果,下次再有人查询,就直接返回缓存里面的结果。所以它能加快查询,减轻源头 DNS 服务器的负担
权威 DNS 服务器
- 一级域名服务器的正式名称叫做权威域名服务器(Authoritative Name Server)
- "权威"的意思是域名的 IP 地址由它给定,不像递归服务器自己做不了主。我们购买域名后,设置 DNS 服务器就是在设置该域名的权威服务器
四种 DNS 服务器
- 综上所述,DNS 服务器可以分成四种:
- 根域名服务器
- TLD 服务器
- 权威域名服务器
- 递归域名服务器
- 它们的关系如下图
- 知道了 DNS 查询的原理,完全可以自己写一个 DNS 的递归服务器,这是不难的。网上有很多参考资料,有兴趣的话,大家可以试试看
DNS污染
简介
-
DNS污染,又称为域名污染或者域名服务器缓存污染(DNS cache pollution)又或者域名服务器快照侵害(DNS cache poisoning)
DNS污染是指一些刻意制造或无意中制造出来的域名服务器分组,把域名指往不正确的IP地址
DNS(Domain Name System)污染是防火墙让一般用户由于得到虚假目标主机IP而不能与其通信的方法
-
一般来说,网站在互联网上一般都有可信赖的域名DNS服务器,但为减免网络上的交通,一般的域名都会把外界的域名服务器数据暂存起来,待下次有其他机
器要求解析域名时,可以立即提供服务。一旦有相关网域的局域域名服务器的缓存受到污染,就会把网域内的电脑引导往错误的服务器或服务器的网址
-
某些网络运营商为了某些目的,对DNS进行了某些操作,导致使用**ISP(Internet Service Provider)**即“互联网服务提供商”的正常上网设置无法通过域名取得
正确的IP地址
-
某些国家或地区出于某些目的为了防止某网站被访问,而且其又掌握部分国际DNS根目录服务器或镜像,也会利用此方法进行屏蔽
-
DNS污染指的是用户访问一个地址,国内的服务器(非DNS)监控到用户访问的已经被标记地址时,服务器伪装成DNS服务器向用户发回错误的地址的行为
范例,访问油管、脸书之类网站等出现的状况
你使用一个不存在的 IP (肯定不是 DNS )作为 DNS 去解析某个域名的时候,理应没有任何返回,但是却能返回一个错误 IP
为了证明是污染不是劫持,你再用这个不存在的 IP 去解析不存在的域名,这个时候你会发现没有任何返回,这就说明这个不存在的域名没有被污染
常用手段
- DNS劫持
- DNS污染
防除方法
-
对付DNS劫持,只需要把系统的DNS设置手动切换为国外的DNS服务器的IP地址即可解决
-
对于DNS污染,(早前的方法)一般除了使用代理服务器和VPN之类的软件之外,并没有什么其它办法
但利用我们对DNS污染的了解,还是可以做到不用代理服务器和VPN之类的软件就能解决DNS污染问题,从而在不使用代理服务器或VPN的情况下访问原本访
问不了的一些网站。当然这无法解决所有问题,当一些无法访问的网站本身并不是由DNS污染问题导致的时候,还是需要使用代理服务器或VPN才能访问的
-
DNS污染的数据包并不是在网络数据包经过的路由器上,而是在其旁路产生的
所以DNS污染并无法阻止正确的DNS解析结果返回,但由于旁路产生的数据包发回的速度较国外DNS服务器发回的快,操作系统认为第一个收到的数据包就是
返回结果,从而忽略其后收到的数据包,从而使得DNS污染得逞
而某些国家的DNS污染在一段时期内的污染IP却是固定不变的,从而可以忽略返回结果是这些IP地址的数据包,直接解决DNS污染的问题
-
某国家防火墙的两种“dns污染”(“域名污染”的原理,那种形式不妨称之为“直接污染”。但由于某些国家防火墙的特殊性,它不但可以做到“直接污染”,还可以做
到“间接污染”。而普通的骇客顶多只能做到“直接污染”,难以做到“大范围的间接dns污染”)
验证方法
-
在命令行下通过这样一条命令
-
nslookup http://780822.com 144.223.234.234
-
即可判断该域名是否被污染,由于144.223.234.234不存在,理应没有任何返回
但我们却得到了一个错误的IP(不确定)。即可证明这个域名已经被DNS污染了
-
解决方案
-
使用各种SSH加密代理,在加密代理里进行远程DNS解析,或者使用VPN上网
-
修改hosts文件,操作系统中Hosts文件的权限优先级高于DNS服务器,操作系统在访问某个域名时,会先检测HOSTS文件,然后再查询DNS服务器
可以在hosts添加受到污染的DNS地址来解决DNS污染和DNS劫持
-
通过一些软件编程处理,可以直接忽略返回结果是虚假IP地址的数据包,直接解决DNS污染的问题
总结
-
以上的方法都是早前域名污染的处理方法,但由于互联网的不断完善,随之的国家应用防火墙也跟着相应的革新,所以以上的方法都已无法解决污染
但新的域名污染处理技术也就随着诞生,虽然污染无法完全处理掉,但处理后恢复访问,这方面还是可以做到的
Restful API 规范
1、动作
GET (SELECT): 从服务器检索特定资源,或资源列表。
POST (CREATE): 在服务器上创建一个新的资源。
PUT (UPDATE): 更新服务器上的资源,提供整个资源。
PATCH (UPDATE):更新服务器上的资源,仅提供更改的属性。
DELETE (DELETE):从服务器删除资源。
2、路径(接口命名)
路径又称"终点"(endpoint),表示API的具体网址。
在RESTful架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词,而且所用的名词往往与数据库的表格名对应。
一般来说,数据库中的表都是同种记录的"集合"(collection),所以API中的名词也应该使用复数。
3、版本(Versioning)
将API的版本号放入URL
https://api.example.com/v1/
4、过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
?limit=10:指定返回记录的数量
?offset=10:指定返回记录的开始位置。
?page_number=2&page_size=100:指定第几页,以及每页的记录数。
?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
?animal_type_id=1:指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,
GET /zoo/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
5、状态码(Status Codes)
1xx 信息,请求收到,继续处理。范围保留用于底层HTTP的东西,你很可能永远也用不到。
2xx 成功,行为被成功地接受、理解和采纳
3xx 重定向,为了完成请求,必须进一步执行的动作
4xx 客户端错误,请求包含语法错误或者请求无法实现。范围保留用于响应客户端做出的错误,例如。他们提供不良数据或要求不存在的东西。这些请求应该是幂等的,而不是更改服务器的状态。
5xx 范围的状态码是保留给服务器端错误用的。这些错误常常是从底层的函数抛出来的,甚至开发人员也通常没法处理,发送这类状态码的目的以确保客户端获得某种响应。
当收到5xx响应时,客户端不可能知道服务器的状态,所以这类状态码是要尽可能的避免。
接口幂等性
-
幂等性原本是数学上的概念,用在接口上就可以理解为:** 同一个接口,多次发出同一个请求,必须保证操作只执行一次。**
调用接口发生异常并且重复尝试时,总是会造成系统所无法承受的损失,所以必须阻止这种现象的发生。
-
HTTP 请求的方法的接口幂等性
-
GET方法用于获取资源,不应有副作用,所以是幂等的。
-
DELETE方法用于删除资源,有副作用,但它应该满足幂等性。
-
PUT方法具有幂等性
PUT请求的幂等性可以这样理解,将A修改为B,它第一次请求值变为了B,再进行多次此操作,最终的结果还是B,与一次执行的结果是一样的,所以PUT是幂等操作。
-
POST 非幂等,因为一次请求添加一份新资源,二次请求则添加了两份新资源,多次请求会产生不同的结果,因此POST不是幂等操作。
-
PATCH 非幂等:用于更新资源,即数据实体的一部分属性,该数据必然存在,否则失去更新意义。
-
IO 多路复用
简介
-
IO多路复用(IO Multiplexing)一种同步IO模型,单个进程/线程就可以同时处理多个IO请求。
最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程。
一个进程/线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;
没有文件句柄就绪时会阻塞应用程序,交出cpu。多路是指网络连接,复用指的是同一个进程/线程。
一个进程/线程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来
看,多个请求复用了一个进程/线程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做分时多路复用。
IO多路复用三种实现
前言
-
用户态和内核态是操作系统的两种运行状态
-
内核态
- 处于内核态的 CPU 可以访问任意的数据,包括外围设备,比如网卡、硬盘等
- 处于内核态的 CPU 可以从一个程序切换到另外一个程序,并且占用 CPU 不会发生抢占情况,一般处于特权级 0 的状态我们称之为内核态
-
用户态
- 处于用户态的 CPU 只能受限的访问内存,并且不允许访问外围设备,用户态下的 CPU 不允许独占,也就是说 CPU 能够被其他程序获取
-
用户态和内核态存在的原因
- 主要是访问能力限制的考量
- 计算机中有一些比较危险的操作,比如设置时钟、内存清理,这些都需要在内核态下完成,如果随意进行危险操作,极容易导致系统崩坏
select
基本原理:
-
客户端操作服务器时就会产生这三种文件描述符(简称fd):writefds(写)、readfds(读)、和 exceptfds(异常)。select 会阻塞住监视 3 类文件描述符,等有数据
可读、可写、出异常或超时就会返回;返回后通过遍历 fdset 整个数组来找到就绪的描述符 fd,然后进行对应的 IO 操作。
优点:
- 几乎在所有的平台上支持,跨平台支持性好
缺点:
-
由于是采用轮询方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
每次调用 select(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
单个进程打开的 FD 是有限制(通过FD_SETSIZE设置)的,默认是 1024 个,可修改宏定义,但是效率仍然慢。
poll
基本原理:
- 与 select 一致,也是轮询+遍历。唯一的区别就是 poll 没有最大文件描述符限制(使用链表的方式存储 fd)。
缺点:
-
由于是采用轮询方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
每次调用 poll(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
epoll
基本原理:
- 用户态拷贝到内核态只需要一次,使用时间通知机制来触发。通过 epoll_ctl 注册 fd,一旦 fd 就绪就会通过回调机制来激活对应 fd,进行相关的 io 操作。
- epoll 之所以高性能是得益于它的三个函数:
- epoll_create() 系统启动时,在 Linux 内核里面申请一个B+树结构文件系统,返回 epoll 对象,也是一个 fd。
- epoll_ctl() 每新建一个连接,都通过该函数操作 epoll 对象,在这个对象里面修改添加删除对应的链接 fd,绑定一个 callback 函数
- epoll_wait() 轮训所有的 callback 集合,并完成对应的 IO 操作
优点:
-
没 fd 这个限制,所支持的 FD 上限是操作系统的最大文件句柄数,1G 内存大概支持 10 万个句柄。
效率提高,使用回调通知而不是轮询的方式,不会随着 FD 数目的增加效率下降。
内核和用户空间 mmap 同一块内存实现(mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间)
缺点:
- 只能工作在linux下
应用:
- redis、nginx
总结
- epoll并不一定比select好,这个需要结合具体情况来分析
- 在并发高的情况下,且连接活跃度不是很高(如Web系统),此时epoll就比select好
- 当并发性不是很高,但连接活跃度很高的时,select就比epoll好
python 的使用
-
事件循环,不停的请求socket状态,并调用对应的回调函数,事件循环模式在使用IO多路复用的时候都会存在
比如Twisted,Tornado,Gevent,协程,asyncIO等,都是这种模式,即 回调+事件循环+select(poll/epoll) 模式
import select
"select"
# select轮询等待读socket集合
inputs = [server]
# select轮询等待写socket集合
outputs = []
message_queues = {}
# select超时时间
timeout = 20
# "等待活动连接......"
readable , writable , exceptional = select.select(inputs, outputs, inputs, timeout)
//
selecter = select.select()
"poll"
# 新建轮询事件对象
poller = select.poll()
# 注册本机监听socket到等待可读事件事件集合
poller.register(server,READ_ONLY)
# 文件描述符到socket映射
fd_to_socket = {server.fileno():server,}
# 轮询注册的事件集合
events = poller.poll(timeout)
"epoll"
# 新建epoll事件对象,后续要监控的事件添加到其中
epoll = select.epoll()
# 添加服务器监听fd到等待读事件集合
epoll.register(serversocket.fileno(), select.EPOLLIN)
# 文件描述符到socket映射
fd_to_socket = {serversocket.fileno():serversocket,}
# 轮询注册的事件集合
events = epoll.poll(timeout)
进程间通信 IPC
本地进程间通信
-
管道
-
最简单的方式就是管道,管道的本质是存放在内存中的特殊的文件。也就是说,内核在内存中开辟了一个缓冲区,这个缓冲区与管道文件相关联,对管道
文件的操作,被内核转换成对这块缓冲区的操作。管道分为匿名管道和有名管道,匿名管道只能在父子进程之间进行通信,而有名管道没有限制。
-
但是管道效率比较低,不适合进程间频繁地交换数据,并且管道只能传输无格式的字节流。
-
-
消息队列
-
消息队列的本质就是存放在内存中的消息的链表,而消息本质上是用户自定义的数据结构。如果进程从消息队列中读取了某个消息,这个消息就会被从消
息队列中删除。
-
消息队列的速度比较慢,因为每次数据的写入和读取都需要经过用户态与内核态之间数据的拷贝过程。
-
-
共享内存 (最快的方式)
-
两个不同进程的逻辑地址通过页表映射到物理空间的同一区域,它们所共同指向的这块区域就是共享内存。如果某个进程向共享内存写入数据,所做的改
动将立即影响到可以访问同一段共享内存的任何其他进程。
对于共享内存机制来说,仅在建立共享内存区域时需要系统调用,一旦建立共享内存,所有的访问都可作为常规内存访问,无需借助内核。这样,数据就
不需要在进程之间来回拷贝,所以这是最快的一种进程通信方式。
共享内存速度虽然非常快,但是存在冲突问题,为此,可以使用信号量和 PV 操作来实现对共享内存的互斥访问,并且还可以实现进程同步。
-
-
数据库
-
信号
-
信号是进程通信机制中唯一的异步通信机制,它可以在任何时候发送信号给某个进程。通过发送指定信号来通知进程某个异步事件的发送,以迫使进程执
行信号处理程序。信号处理完毕后,被中断进程将恢复执行。用户、内核和进程都能生成和发送信号。
-
-
远程过程调用 RPC
-
RPC 是指计算机 A 上的进程,调用另外一台计算机 B 上的进程,其中 A 上的调用进程被挂起,而 B 上的被调用进程开始执行,当值返回给 A 时,A 进程
继续执行。调用方可以通过使用参数将信息传送给被调用方,而后可以通过传回的结果得到信息。
-
RPC在OSI网络通信7层模型中,位于传输层与应用层之间,即位于会话层。
-
RPC是广义的,RPC可以发生在不同的主机之间,也可以发生在同一台主机上,发生在同一台主机上就是LPC。
-
RPC是建立在Socket之上的,在一台机器上运行的主程序,可以调用另一台机器上准备好的子程序,就像LPC(本地过程调用)。
-
网络中进程通信
- 网络中进程间如何通信,即利用三元组【ip地址,协议,端口】
- TCP/IP 协议族已经帮我们解决了这个问题,网络层的“ip地址”可以唯一标识网络中的主机
- 传输层的“协议+端口”可以唯一标识主机中的应用程序(进程)
Socket
-
上面介绍的方法都是用于同一台主机上的进程之间进行通信的,Socket 可跨网络与不同主机上的进程进行通信,Socket 也能完成同主机上的进程通信。
-
Socket 起源于 Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。
在计算机通信领域,Socket 被翻译为套接字,它是计算机之间进行通信的一种约定或一种方式。
通过 Socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据。
-
从计算机网络层面来说,Socket 套接字是网络通信的基石,是支持 TCP/IP 协议的网络通信的基本操作单元。它是网络通信过程中端点的抽象表示,包含进行
网络通信必须的五种信息:连接使用的协议,本地主机的 IP 地址,本地进程的协议端口,远地主机的 IP 地址,远地进程的协议端口。
-
Socket 的本质其实是一个编程接口(API),是应用层与 TCP/IP 协议族通信的中间软件抽象层,它对 TCP/IP 进行了封装。
它把复杂的 TCP/IP 协议族隐藏在 Socket 接口后面。对用户来说,只要通过一组简单的 API 就可以实现网络的连接。
-
套接字(socket)是一个介于应用层和传输层的抽象层
应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作,并与网络中的其他应用程序进行通信
可以把Socket编程理解为对TCP协议的具体实现,将TCP协议简化一下,就只有三个核心功能:** 建立连接、发送数据以及接收数据**
-
Socket通信的数据传输方式:
-
SOCK_STREAM:
-
表示面向连接的数据传输方式。
-
数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送,但效率相对较慢。
常见的 http 协议就使用 SOCK_STREAM 传输数据,因为要确保数据的正确性,否则网页不能正常解析。
-
-
SOCK_DGRAM:
-
表示无连接的数据传输方式。
-
计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。也就是说,数据错了就错了,无法重传。因为 SOCK_DGRAM 所做的校验工作少,所以效率比 SOCK_STREAM 高。
-
-
-
示例:
-
QQ 视频聊天和语音聊天就使用 SOCK_DGRAM 传输数据
首先要保证通信的效率,尽量减小延迟,而数据的正确性是次要的
即使丢失很小的一部分数据,视频和音频也可以正常解析,最多出现噪点或杂音,不会对通信质量有实质的影响
-
-
图解socket函数
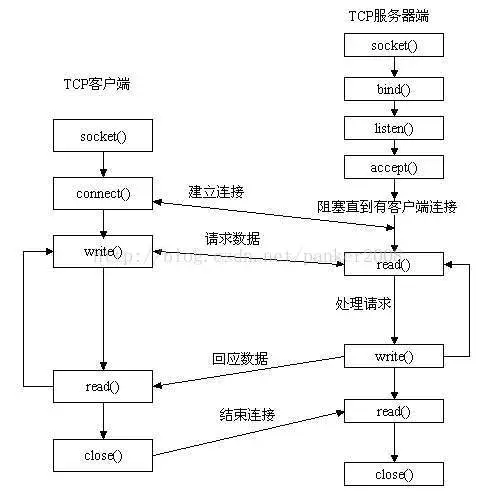
-
扩展
内核,是一个操作系统的核心。是基于硬件的第一层软件扩充,提供操作系统的最基本的功能,是操作系统工作的基础,它负责管理系统的进程、内存、设备
驱动程序、文件和网络系统,决定着系统的性能和稳定性。
数据传输安全TODO
数据传输安全的要求
- 消息的发送方能够确定消息只有预期的接收方可以解密(不保证第三方无法获得,但保证第三方无法解密)。
- 消息的接收方可以确定消息的发送方。
- 必须确认消息的完整性,消息的接收方可以确定消息在途中没有被篡改过。
关于加密
-
对称加密
-
非对称加密
关于签名
关于认证模式
证书机制
SSH SSL与HTTPS
长连接/短连接TODO
- 长连接
- 短连接
跨源资源共享-CORS
简介
-
CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)
它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制
-
CORS需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10
整个CORS通信过程,都是浏览器自动完成,不需要用户参与。对于开发者来说,CORS通信与同源的AJAX通信没有差别,代码完全一样
浏览器一旦发现AJAX请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉
因此,实现CORS通信的关键是服务器。只要服务器实现了CORS接口,就可以跨源通信
两种请求
-
浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)
-
简单请求
-
请求方法是以下三种方法之一:
- HEAD
- GET
- POST
-
HTTP的头信息不超出以下几种字段:
-
Accept
-
Accept-Language
-
Content-Language
-
Last-Event-ID
-
Content-Type:只限于三个值
application/x-www-form-urlencoded、multipart/form-data、text/plain
-
-
-
非简单请求
- 凡是不同时满足上面两个条件,就属于非简单请求
-
提高并发的方法
方法
- 动静资源分离
- 数据库与项目代码分开部署 (对CPU和磁盘都有消耗)
- 增加 Redis 缓存 (热点数据缓存,减少数据库压力)
- Mysql 主从读写分离、集群
- sql 语句优化
- 对慢查询进行监测,对速度慢的sql语句使用 explain 分析
- 避免使用外键约束(影响数据库的写性能)
- 页面静态化 (一般用在页面内容固定的情况)
- 接口响应时间监测
- 分库分表
- Nginx 做负载均衡
秒杀系统TODO
高可用
-
高可用追求系统在运行过程中尽量少的出现系统服务不可用的情况,就是说当机器/进程出现异常或者崩溃时,不会影响集群的整体可用。
-
在系统设计的过程中避免单点。
-
方法论上,高可用保证的原则是“集群化”,只有一个单点,挂了服务会受影响;如果有备份,挂了还有其他backup能够顶上。
-
通过“自动故障转移”来实现系统的高可用。
-
鲁棒是Robust的音译,也就是健壮和强壮的意思。它也是在异常和危险情况下系统生存的能力。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意
攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。
高并发
-
高并发相关常用的一些指标有响应时间(Response Time),每秒查询率QPS(Query Per Second),并发用户数等。
-
响应时间
- 系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
-
QPS
- 每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
-
并发用户数
- 同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
-
-
提升系统的并发能力
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
-
垂直扩展:
-
提升单机处理能力
-
垂直扩展的方式又有两种:
-
增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G
-
提升单机架构性能,例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间
-
-
在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略
往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。
-
不管是提升单机硬件性能,还是提升单机架构性能,都有一个致命的不足:单机性能总是有极限的。所以互联网分布式架构设计高并发终极解决方案
还是水平扩展。
-
-
水平扩展:
- 只要增加服务器数量,就能线性扩充系统性能。
-
-
常见的互联网分层架构
-
分层水平扩展架构实践
-
反向代理层的水平扩展
- 通过“DNS轮询”实现的:dns-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问dns-server,会轮询返回这些ip。
- 当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发。
-
站点层的水平扩展
- 站点层的水平扩展,是通过“nginx”实现的。通过修改nginx.conf,可以设置多个web后端。
- 当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能。
-
服务层的水平扩展
- 站点层通过RPC-client调用下游的服务层RPC-server时,RPC-client中的连接池会建立与下游服务多个连接
- 当服务成为瓶颈的时候,只要增加服务器数量,新增服务部署,在RPC-client处建立新的下游服务连接,就能扩展服务层性能。
-
数据层的水平扩展
在数据量很大的情况下,数据层(缓存,数据库)涉及数据的水平扩展,将原本存储在一台服务器上的数据(缓存,数据库)水平拆分到不同服务器上
去,以达到扩充系统性能的目的。
-
按照范围水平拆分
-
按照哈希水平拆分
-
通过水平拆分扩展数据库性能
(1)每个服务器上存储的数据量是总量的1/n,所以单机的性能也会有提升;
(2)n个服务器上的数据没有交集,那个服务器上数据的并集是数据的全集;
(3)数据水平拆分到了n个服务器上,理论上读性能扩充了n倍,写性能也扩充了n倍(其实远不止n倍,因为单机的数据量变为了原来的1/n);
-
通过主从同步读写分离扩展数据库性能
(1)每个服务器上存储的数据量是和总量相同;
(2)n个服务器上的数据都一样,都是全集;
(3)理论上读性能扩充了n倍,写仍然是单点,写性能不变
-
-
-
总结
**高并发(**High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
前者垂直扩展可以通过提升单机硬件性能,或者提升单机架构性能,来提高并发性,但单机性能总是有极限的,互联网分布式架构设计高并发终极解决方
案还是后者:水平扩展。
互联网分层架构中,各层次水平扩展的实践又有所不同:
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(2)站点层可以通过nginx来进行水平扩展;
(3)服务层可以通过服务连接池来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展;
各层实施水平扩展后,能够通过增加服务器数量的方式来提升系统的性能,做到理论上的性能无限。
linux 常用命令
Linux 文件基本属性
chown (change owner)
# 修改所属用户与组,也可以同时更改文件属组
# 用户可以是用户名或者用户 ID,组可以是组名或者组 ID,文件是以空格分开的要改变权限的文件列表,支持通配符
chown [–R] 属主名 文件名
chown [-R] 属主名:属组名 文件名
# 把 /var/run/httpd.pid 的所有者设置 root:
chown root /var/run/httpd.pid
# 将文件 file1.txt 的拥有者设为 runoob,群体的使用者 runoobgroup :
chown runoob:runoobgroup file1.txt
# 将当前前目录下的所有文件与子目录的拥有者皆设为 runoob,群体的使用者 runoobgroup:
chown -R runoob:runoobgroup *
# 把 /home/runoob 的关联组设置为 512 (关联组ID),不改变所有者:
chown :512 /home/runoob
chmod (change mode)
# 修改用户的权限
# Linux/Unix 的文件调用权限分为三级 : 文件所有者(Owner)、用户组(Group)、其它用户(Other Users)
chmod [-R] mode 文件或目录
mode : 就是刚刚提到的数字类型的权限属性,为 rwx 属性数值的相加。
-R : 进行递归(recursive)的持续变更,以及连同次目录下的所有文件都会变更
chmod u=rwx,g=rx,o=r test1
chmod a-x test1 ( +(加入) -(除去) =(设定) )
# 将文件 file1.txt 设为所有人皆可读取 :
chmod ugo+r file1.txt == chmod a+r file1.txt
chmod 777 file
chgrp(change group)
# 更改文件属组
chgrp -v bin log2012.log
# 根据指定文件改变文件的群组属性
chgrp --reference=log2012.log log2013.log
rwx 的三个参数的组合
# r 代表可读(read)、 w 代表可写(write)、 x 代表可执行(execute)
r = 4、w = 2、x = 1
Linux 目录常用命令
ls(英文全拼:list files):
# 列出目录及文件名
-a :全部的文件,连同隐藏文件( 开头为 . 的文件) 一起列出来(常用)
-d :仅列出目录本身,而不是列出目录内的文件数据(常用)
-l :长数据串列出,包含文件的属性与权限等等数据(常用)
# 将目录下的所有文件列出来(含属性与隐藏档)
[root@www ~]# ls -al ~
cd(英文全拼:change directory):
# 切换目录
cd [相对路径或绝对路径]
pwd(英文全拼:print work directory):
# 显示目前的目录
-P :显示出确实的路径,而非使用链接 (link) 路径
mkdir(英文全拼:make directory):
# 创建一个新的目录
-m :配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的脸色
mkdir -m 711 test2
-p :帮助你直接将所需要的目录(包含上一级目录)递归创建起来
mkdir -p test1/test2/test3/test4
rmdir(英文全拼:remove directory):
# 删除一个空的目录
-p :从该目录起,一次删除多级空目录
rmdir -p test1/test2/test3/test4
cp(英文全拼:copy file):
# 复制文件或目录
-a:相当於 -pdr 的意思(常用)
-d:若来源档为链接档的属性(link file),则复制链接档属性而非文件本身;
-f:为强制(force)的意思,若目标文件已经存在且无法开启,则移除后再尝试一次;
-i:若目标档(destination)已经存在时,在覆盖时会先询问动作的进行(常用)
-l:进行硬式链接(hard link)的链接档创建,而非复制文件本身;
-p:连同文件的属性一起复制过去,而非使用默认属性(备份常用);
-r:递归持续复制,用於目录的复制行为;(常用)
-s:复制成为符号链接档 (symbolic link),亦即『捷径』文件;
-u:若 destination 比 source 旧才升级 destination
# 用 root 身份,将 root 目录下的 .bashrc 复制到 /tmp 下,并命名为 bashrc
[root@www ~]# cp ~/.bashrc /tmp/bashrc
[root@www ~]# cp -i ~/.bashrc /tmp/bashrc
cp: overwrite `/tmp/bashrc'? n <==n不覆盖,y为覆盖
rm(英文全拼:remove):
# 删除文件或目录
-f :就是 force 的意思,忽略不存在的文件,不会出现警告信息;
-i :互动模式,在删除前会询问使用者是否动作
-r :递归删除啊!最常用在目录的删除了!这是非常危险的选项
mv(英文全拼:move file):
# 移动文件与目录,或修改文件与目录的名称
[root@www ~]# mv mvtest mvtest2
-f :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖;
-i :若目标文件 (destination) 已经存在时,就会询问是否覆盖!
-u :若目标文件已经存在,且 source 比较新,才会升级 (update)
# 使用 man [命令] 来查看各个命令的使用文档,如 :
man cp
Linux 文件内容查看
cat
# 由第一行开始显示文件内容
-A :相当於 -vET 的整合选项,可列出一些特殊字符而不是空白而已;
-b :列出行号,仅针对非空白行做行号显示,空白行不标行号
-E :将结尾的断行字节 $ 显示出来;
-n :列印出行号,连同空白行也会有行号,与 -b 的选项不同;
-T :将 [tab] 按键以 ^I 显示出来;
-v :列出一些看不出来的特殊字符
[root@www ~]# cat /etc/issue
CentOS release 6.4 (Final)
Kernel \r on an \m
tac
# 从最后一行开始显示,可以看出 tac 是 cat 的倒着写
[root@www ~]# tac /etc/issue
Kernel \r on an \m
CentOS release 6.4 (Final
nl
# 显示的时候,顺道输出行号
-b :指定行号指定的方式
-n :列出行号表示的方法
-w :行号栏位的占用的位数
[root@www ~]# nl /etc/issue
1 CentOS release 6.4 (Final)
2 Kernel \r on an \m
more
# 一页一页的显示文件内容
[root@www ~]# more /etc/man_db.config
空白键 (space): 代表向下翻一页
Enter :代表向下翻『一行』
/字串 : 代表在这个显示的内容当中,向下搜寻『字串』这个关键字
:f :立刻显示出档名以及目前显示的行数
q :代表立刻离开 more ,不再显示该文件内容
b 或 [ctrl]-b :代表往回翻页,不过这动作只对文件有用,对管线无用
less
# 与 more 类似,比 more 更好的是可以往前翻页
[root@www ~]# less /etc/man.config
空白键 : 向下翻动一页;
[pagedown]:向下翻动一页;
[pageup] :向上翻动一页;
/字串 : 向下搜寻『字串』的功能;
?字串 : 向上搜寻『字串』的功能;
n :重复前一个搜寻 (与 / 或 ? 有关!)
N :反向的重复前一个搜寻 (与 / 或 ? 有关!)
q :离开 less 这个程序
head
# 只看头几行
head [-n number] 文件
-n :后面接数字,代表显示几行的意思
# 默认的情况中,显示前面 10 行, 若要显示前 20 行:
[root@www ~]# head -n 20 /etc/man.config
tail
# 只看尾几行
tail [-n number] 文件
-n :后面接数字,代表显示几行的意思
-f :表示持续侦测后面所接的档名,要等到按下[ctrl]-c 才会结束 tail 的侦测
[root@www ~]# tail /etc/man.config
# 默认的情况中,显示最后的十行, 若要显示最后的 20 行:
[root@www ~]# tail -n 20 /etc/man.config
Linux 用户和用户组管理
# Linux系统用户账号的管理
# 添加新的用户账号使用useradd命令
useradd 选项 用户名
参数说明:
选项:
-c comment 指定一段注释性描述。
-d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
-g 用户组 指定用户所属的用户组。
-G 用户组,用户组指定用户所属的附加组。
-s Shell文件 指定用户的登录Shell。
-u 用户号 指定用户的用户号,如果同时有-o选项,则可以重复使用其他用户的标识号。
用户名:
指定新账号的登录名。
# useradd -s /bin/sh -g group –G adm,root gem
此命令新建了一个用户gem,该用户的登录Shell是 /bin/sh,它属于group用户组,同时又属于adm和root用户组,其中group用户组是其主组。
这里可能新建组:#groupadd group及groupadd adm
增加用户账号就是在/etc/passwd文件中为新用户增加一条记录,同时更新其他系统文件如/etc/shadow, /etc/group等。
Linux提供了集成的系统管理工具userconf,它可以用来对用户账号进行统一管理。
# 删除帐号
userdel 选项 用户名
常用的选项 -r,它的作用是把用户的主目录一起删除
userdel -r sam
# 修改帐号
usermod 选项 用户名
# 用户口令的管理
passwd 选项 用户名
选项:
-l 锁定口令,即禁用账号。
-u 口令解锁。
-d 使账号无口令。
-f 强迫用户下次登录时修改口令。
# 如果默认用户名,则修改当前用户的口令,例如假设当前用户是sam,则下面的命令修改该用户自己的口令:
$ passwd
Old password:******
New password:*******
Re-enter new password:*******
# 如果是超级用户,可以用下列形式指定任何用户的口令:
# passwd sam
New password:*******
Re-enter new password:*******
# 为用户指定空口令时,执行下列形式的命令:
# passwd -d sam
# passwd 命令还可以用 -l(lock) 选项锁定某一用户,使其不能登录,例如:
# passwd -l sam
# Linux系统用户组的管理
# 添加新的用户账号使用useradd命令,其语法如下:
groupadd 选项 用户组
# groupadd group1
参数说明:
-g GID 指定新用户组的组标识号(GID)。
-o 一般与-g选项同时使用,表示新用户组的GID可以与系统已有用户组的GID相同。
# 删除一个已有的用户组
groupdel 用户组
例如:
# groupdel group1
# 修改用户组的属性
groupmod 选项 用户组
选项:
-g GID 为用户组指定新的组标识号。
-o 与-g选项同时使用,用户组的新GID可以与系统已有用户组的GID相同。
-n 新用户组将用户组的名字改为新名字
实例:
# groupmod –g 10000 -n group3 group2
此命令将组group2的标识号改为10000,组名修改为group3
# 一个用户同时属于多个用户组,那么用户可以在用户组之间切换
$ newgrp root
# 用户账号有关的系统文件
# /etc/passwd 文件是用户管理工作涉及的最重要的一个文件
Linux系统中的每个用户都在/etc/passwd文件中有一个对应的记录行,它记录了这个用户的一些基本属性。
这个文件对所有用户都是可读的。它的内容类似下面的例子:
# cat /etc/passwd
root:x:0:0:Superuser:/:
daemon:x:1:1:System daemons:/etc:
bin:x:2:2:Owner of system commands:/bin:
sys:x:3:3:Owner of system files:/usr/sys:
adm:x:4:4:System accounting:/usr/adm:
uucp:x:5:5:UUCP administrator:/usr/lib/uucp:
auth:x:7:21:Authentication administrator:/tcb/files/auth:
cron:x:9:16:Cron daemon:/usr/spool/cron:
listen:x:37:4:Network daemon:/usr/net/nls:
lp:x:71:18:Printer administrator:/usr/spool/lp:
sam:x:200:50:Sam san:/home/sam:/bin/sh
# 从上面的例子我们可以看到,/etc/passwd中一行记录对应着一个用户,每行记录又被冒号(:)分隔为7个字段,其格式和具体含义如下:
用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
# /etc/shadow 中的记录行与/etc/passwd中的一一对应,它由pwconv命令根据/etc/passwd中的数据自动产生
把加密后的口令字分离出来,单独存放在一个文件中,这个文件是/etc/shadow文件
登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志
# 用户组的所有信息都存放在/etc/group 文件中
组名:口令:组标识号:组内用户列表
Linux 磁盘管理
# Linux 磁盘管理好坏直接关系到整个系统的性能问题, Linux 磁盘管理常用三个命令为 df、du 和 fdisk。
df(英文全称:disk free):
列出文件系统的整体磁盘使用量
检查文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息
# 选项与参数:
-a :列出所有的文件系统,包括系统特有的 /proc 等文件系统;
-k :以 KBytes 的容量显示各文件系统;
-m :以 MBytes 的容量显示各文件系统;
-h :以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示;
-H :以 M=1000K 取代 M=1024K 的进位方式;
-T :显示文件系统类型, 连同该 partition 的 filesystem 名称 (例如 ext3) 也列出;
-i :不用硬盘容量,而以 inode 的数量来显示
# 将系统内所有的文件系统容量结果以易读的容量格式显示出来
[root@www ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/hdc2 9.5G 3.7G 5.4G 41% /
/dev/hdc3 4.8G 139M 4.4G 4% /home
/dev/hdc1 99M 11M 83M 12% /boot
tmpfs 363M 0 363M 0% /dev/shm
du(英文全称:disk used):
检查磁盘空间使用量
Linux du 命令也是查看使用空间的,但是与 df 命令不同的是 Linux du 命令是对文件和目录磁盘使用的空间的查看
# 选项与参数:
-a :列出所有的文件与目录容量,因为默认仅统计目录底下的文件量而已。
-h :以人们较易读的容量格式 (G/M) 显示;
-s :列出总量而已,而不列出每个各别的目录占用容量;
-S :不包括子目录下的总计,与 -s 有点差别。
-k :以 KBytes 列出容量显示;
-m :以 MBytes 列出容量显示
# 检查根目录底下每个目录所占用的容量
[root@www ~]# du -sm /*
7 /bin
6 /boot
.....中间省略....
1 /tmp
3859 /usr <== 系统初期最大就是他了啦
fdisk:
用于磁盘分区
语法:
fdisk [-l] 装置名称
-l :输出后面接的装置所有的分区内容。若仅有 fdisk -l 时, 则系统将会把整个系统内能够搜寻到的装置的分区均列出来。
# 磁盘格式化
格式化的命令非常的简单,使用 mkfs(make filesystem) 命令
mkfs [-t 文件系统格式] 装置文件名
-t :可以接文件系统格式,例如 ext3, ext2, vfat 等(系统有支持才会生效)
# 磁盘检验
fsck(file system check)用来检查和维护不一致的文件系统, 若系统掉电或磁盘发生问题,可利用fsck命令对文件系统进行检查。
fsck [-t 文件系统] [-ACay] 装置名称
Linux vi/vim
所有的 Unix Like 系统都会内建 vi 文书编辑器,但是目前我们使用比较多的是 vim 编辑器
vim 具有程序编辑的能力,可以主动的以字体颜色辨别语法的正确性,方便程序设计
# vi/vim 的使用
基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。
# 命令模式
用户刚刚启动 vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被Vim识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,i被当作了一个命令。
# 常用命令
i 切换到输入模式,以输入字符。
x 删除当前光标所在处的字符。
: 切换到底线命令模式,以在最底一行输入命令。
# 输入模式
在命令模式下按下 i 就进入了输入模式
# 底线命令模式
在命令模式下按下:(英文冒号)就进入了底线命令模式。
底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。
在底线命令模式中,基本的命令有(已经省略了冒号):
q 退出程序
w 保存文件
按 ESC 键可随时退出底线命令模式
# 使用 vi/vim 进入一般模式
如果你想要使用 vi 来建立一个名为 runoob.txt 的文件时,你可以这样做:
$ vim runoob.txt
# vim 快捷键补充(插入模式)
自动补全:ctrl + n
:set nu
显示行号,设定之后,会在每一行的前缀显示该行的行号
:set nonu
与 set nu 相反,为取消行号
Linux yum 命令
yum 语法
yum [options] [command] [package ...]
options:可选,选项包括-h(帮助),-y(当安装过程提示选择全部为 "yes"),-q(不显示安装的过程)等等。
command:要进行的操作。
package:安装的包名。
yum常用命令
1. 列出所有可更新的软件清单命令:
yum check-update
2. 更新所有软件命令:
yum update
3. 仅安装指定的软件命令:
yum install <package_name>
4. 仅更新指定的软件命令:
yum update <package_name>
5. 列出所有可安裝的软件清单命令:
yum list
6. 删除软件包命令:
yum remove <package_name>
7. 查找软件包命令:
yum search <keyword>
8. 清除缓存命令:
yum clean packages: 清除缓存目录下的软件包
yum clean headers: 清除缓存目录下的 headers
yum clean oldheaders: 清除缓存目录下旧的 headers
yum clean, yum clean all (= yum clean packages; yum clean oldheaders) : 清除缓存目录下的软件包及旧的 headers
Linux 常用命令
file
命令用于辨识文件类型
[root@localhost ~]# file install.log
install.log: UTF-8 Unicode text
find
命令用来在指定目录下查找文件
# 将当前目录及其子目录下所有文件后缀为 **.c** 的文件列出来
# find . -name "*.c"
ln(英文全拼:link files)
为某一个文件在另外一个位置建立一个同步的链接
ln [参数][源文件或目录][目标文件或目录]
# 参数
-d 允许超级用户制作目录的硬链接
-f 强制执行
-i 交互模式,文件存在则提示用户是否覆盖
-n 把符号链接视为一般目录
-s 软链接(符号链接)
-v 显示详细的处理过程
# 命令功能
Linux文件系统中,有所谓的链接(link),我们可以将其视为档案的别名,而链接又可分为两种 : 硬链接(hard link)与软链接(symbolic link)
硬链接的意思是一个档案可以有多个名称,而软链接的方式则是产生一个特殊的档案,该档案的内容是指向另一个档案的位置。
硬链接是存在同一个文件系统中,而软链接却可以跨越不同的文件系统。
不论是硬链接或软链接都不会将原本的档案复制一份,只会占用非常少量的磁碟空间。
# 软链接:
1.软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
2.软链接可以 跨文件系统 ,硬链接不可以
3.软链接可以对一个不存在的文件名进行链接
4.软链接可以对目录进行链接
# 硬链接:
1.硬链接,以文件副本的形式存在。但不占用实际空间。
2.不允许给目录创建硬链接
3.硬链接只有在同一个文件系统中才能创建
# 给文件创建软链接,为log2013.log文件创建软链接link2013,如果log2013.log丢失,link2013将失效:
ln -s log2013.log link2013
# 给文件创建硬链接,为log2013.log创建硬链接ln2013,log2013.log与ln2013的各项属性相同
ln log2013.log ln2013
split
用于将一个文件分割成数个
该指令将大文件分割成较小的文件,在默认情况下将按照每1000行切割成一个小文件
# 使用指令"split"将文件"README"每6行切割成一个文件:
$ split -6 README
which
用于查找文件
# 使用指令"which"查看指令"bash"的绝对路径:
$ which bash
/bin/bash
whereis
用于查找文件
# 使用指令"whereis"查看指令"bash"的位置:
$ whereis bash
bash:/bin/bash/etc/bash.bashrc/usr/share/man/man1/bash.1.gz
scp
用于 Linux 之间复制文件和目录
scp [可选参数] file_source file_target
# 从本地复制到远程
scp -r local_file remote_username@remote_ip:remote_folder # 指定了远程的目录
scp local_file remote_username@remote_ip:remote_file # 指定了远程文件名
rhmask
用于对文件进行加密和解密操作
rhmask [加密文件] [输出文件] 或 rhmask [-d] [加密文件] [源文件] [输出文件]
# 使用指令"rhmask"将加密文件"code.txt"进行加密后,另存为输出文件"demo.txt":
$ rhmask code.txt demo.txt
awk
是一种处理文本文件的语言,是一个强大的文本分析工具
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
grep
用于查找文件里符合条件的字符串
# 在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行:
grep test *file
# 以递归的方式查找符合条件的文件
grep -r update /etc/acpi
# 反向查找, 通过"-v"参数可以打印出不符合条件行的内容, 查找文件名中包含 test 的文件中不包含test 的行:
grep -v test *test*
comm
用于比较两个已排过序的文件
look
用于查询单词
# 查找在testfile文件中以字母L开头的所有的行:
$ look L testfile
sort
用于将文本文件内容加以排序, sort 可针对文本文件的内容,以行为单位来排序
$ sort testfile
uniq
# 用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用
参数:
-c或--count 在每列旁边显示该行重复出现的次数。
-d或--repeated 仅显示重复出现的行列。
-u或--unique 仅显示出一次的行列。
$ cat testfile # 原有内容
test 30
test 30
test 30
Hello 95
Hello 95
Hello 95
Hello 95
Linux 85
Linux 85
$ uniq testfile # 删除重复行后的内容
test 30
Hello 95
Linux 85
# 检查文件并删除文件中重复出现的行,并在行首显示该行重复出现的次数:
$ uniq -c testfile # 删除重复行后的内容
3 test 30 # 前面的数字的意义为该行共出现了3次
4 Hello 95 # 前面的数字的意义为该行共出现了4次
2 Linux 85 # 前面的数字的意义为该行共出现了2次
# 当重复的行并不相邻时,uniq 命令是不起作用的,即若文件内容为以下时,uniq 命令不起作用:
$ cat testfile1 # 原有内容
test 30
Hello 95
Linux 85
test 30
Hello 95
Linux 85
test 30
Hello 95
Linux 85
# 这时我们就可以使用 sort:
$ sort testfile1 | uniq
Hello 95
Linux 85
test 30
# 统计各行在文件中出现的次数:
$ sort testfile1 | uniq -c
3 Hello 95
3 Linux 85
3 test 30
# 在文件中找出重复的行:
$ sort testfile1 | uniq -d
Hello 95
Linux 85
test 30
wc
用于计算字数
wc [-clw][--help][--version][文件...]
参数:
-c或--bytes或--chars 只显示Bytes数
-l或--lines 显示行数
-w或--words 只显示字数
$ wc testfile # testfile文件的统计信息
3 92 598 testfile # testfile文件的行数为3、单词数92、字节数598
mount
用于挂载Linux系统外的文件
# 将 /dev/hda1 挂在 /mnt 之下
# mount /dev/hda1 /mnt
# 将 /dev/hda1 用唯读模式挂在 /mnt 之下
# mount -o ro /dev/hda1 /mnt
umount
可卸除目前挂在Linux目录中的文件系统
# umount -v /dev/sda1 通过设备名卸载
/dev/sda1 umounted
# umount -v /mnt/mymount/ 通过挂载点卸载
/tmp/diskboot.img umounted
telnet
用于远端登入
执行telnet指令开启终端机阶段作业,并登入远端主机
# telnet 192.168.0.5 登录IP为 192.168.0.5 的远程主机
ifconfig
# 用于显示或设置网络设备
显示网络设备信息
# ifconfig
启动关闭指定网卡
# ifconfig eth0 down
# ifconfig eth0 up
为网卡配置和删除IPv6地址
# ifconfig eth0 add 33ffe:3240:800:1005::2/ 64 //为网卡设置IPv6地址
# ifconfig eth0 del 33ffe:3240:800:1005::2/ 64 //为网卡删除IPv6地址
用ifconfig修改MAC地址
# ifconfig eth0 down //关闭网卡
# ifconfig eth0 hw ether 00:AA:BB:CC:DD:EE //修改MAC地址
# ifconfig eth0 up //启动网卡
# ifconfig eth1 hw ether 00:1D:1C:1D:1E //关闭网卡并修改MAC地址
# ifconfig eth1 up //启动网卡
配置IP地址
# ifconfig eth0 192.168.1.56 //给eth0网卡配置IP地址
# ifconfig eth0 192.168.1.56 netmask 255.255.255.0 // 给eth0网卡配置IP地址,并加上子掩码
# ifconfig eth0 192.168.1.56 netmask 255.255.255.0 broadcast 192.168.1.255 // 给eth0网卡配置IP地址,加上子掩码,加上个广播地址
启用和关闭ARP协议
# ifconfig eth0 arp //开启
# ifconfig eth0 -arp //关闭
设置最大传输单元
# ifconfig eth0 mtu 1500 //设置能通过的最大数据包大小为 1500 bytes
ps (英文全拼:process status)
用于显示当前进程的状态,类似于 windows 的任务管理器 (-aux 显示所有包含其他使用者的进程)
# ps -ef | grep php //显示 php 的进程
# ps -u root //显示root进程用户信息
top
用于实时显示 process 的动态
pstree (英文全称:display a tree of processes)
将所有进程以树状图显示
reboot
用于用来重新启动计算机
shutdown
# 可以用来进行关机程序
立即关机
# shutdown -h now
指定 10 分钟后关机
# shutdown -h 10
重新启动计算机
# shutdown -r now
sudo
以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行
swatch
用于系统监控程序
tload
用于显示系统负载状况
uname(英文全拼:unix name)
可显示电脑以及操作系统的相关信息
参数:
-a或--all 显示全部的信息。
-m或--machine 显示电脑类型。
-n或--nodename 显示在网络上的主机名称。
-r或--release 显示操作系统的发行编号。
-s或--sysname 显示操作系统名称。
-v 显示操作系统的版本。
who
用于显示系统中有哪些使用者正在上面,显示的资料包含了使用者 ID、使用的终端机、从哪边连上来的、上线时间、呆滞时间、CPU 使用量、动作等等。
whoami
用于显示自身用户名称
whois
用于查找并显示用户信息
whois [帐号名称]
su(英文全拼:switch user)
用于变更为其他使用者的身份,除 root 外,需要键入该使用者的密码。
free
显示内存的使用情况,包括实体内存,虚拟的交换文件内存,共享内存区段,以及系统核心使用的缓冲区等。
clear
用于清除屏幕
alias
用于设置指令的别名
用户可利用alias,自定指令的别名。
若仅输入alias,则可列出目前所有的别名设置。
alias的效力仅及于该次登入的操作。
若要每次登入是即自动设好别名,可在.profile或.cshrc中设定指令的别名。
alias [别名]=[指令名称]
unalias
# 用于删除别名
unalias 为 shell 内建指令,可删除别名设置
unalias [-a] [别名]
-a 删除全部的别名
# 给命令设置别名
[root@runoob.com ~]# alias lx=ls
[root@runoob.com ~]# lx
anaconda-ks.cfg Desktop install.log install.log.syslog qte
# 删除别名
[root@runoob.com ~]# alias lx // 显示别名
alias lx='ls'
[root@runoob.com ~]# unalias lx // 删除别名
[root@runoob.com ~]# lx
-bash: lx: command not found
chroot (英文全称:change root)
把根目录换成指定的目的目录
clock
用于调整 RTC 时间,RTC 是电脑内建的硬件时间,执行这项指令可以显示现在时刻
# clock //获取当前的时间
# clock -utc //显示UTC时间
tar(英文全拼:tape archive )
# tar 是用来建立,还原备份文件的工具程序,它可以加入,解开备份文件内的文件
参数:
-c或--create 建立新的备份文件
-x或--extract或--get 从备份文件中还原文件
-z或--gzip或--ungzip 通过gzip指令处理备份文件
-v或--verbose 显示指令执行过程
-f<备份文件>或--file=<备份文件> 指定备份文件
-t或--list 列出备份文件的内容
压缩文件 非打包
# tar -czvf test.tar.gz a.c //压缩 a.c文件为test.tar.gz
a.c
列出压缩文件内容
# tar -tzvf test.tar.gz
-rw-r--r-- root/root 0 2010-05-24 16:51:59 a.c
解压文件
# tar -xzvf test.tar.gz
a.c
zip
用于压缩文件
参数:
-d 从压缩文件内删除指定的文件
-f 更新现有的文件
-q 不显示指令执行过程
-r 递归处理,将指定目录下的所有文件和子目录一并处理
-v 显示指令执行过程或显示版本信息
# 将 /home/html/ 这个目录下所有文件和文件夹打包为当前目录下的 html.zip
zip -q -r html.zip /home/html
# 从压缩文件 cp.zip 中删除文件 a.c
zip -dv cp.zip a.c
unzip
用于解压缩zip文件
unzip [-Z]
zipinfo
用于列出压缩文件信息
zipinfo cp.zip
poweroff
用于关闭计算器并切断电源
export
# 用于设置或显示环境变量
export [-fnp] [变量名称]=[变量设置值]
# 参数说明:
-f 代表[变量名称]中为函数名称。
-n 删除指定的变量。变量实际上并未删除,只是不会输出到后续指令的执行环境中。
-p 列出所有的shell赋予程序的环境变量。
# 注意:
在 shell 中执行程序时,shell 会提供一组环境变量。
export 可新增,修改或删除环境变量,供后续执行的程序使用。
export 的效力仅限于该次登陆操作。
setenv (set environment variable)
用于查询或显示环境变量
setenv 为 tsch 中查询或设置环境变量的指令
# 语法
setenv [变量名称][变量值]
# 实例
显示环境变量
# setenv
设置环境变量
# setenv USER lx138
chkconfig
用于检查,设置系统的各种服务
# 语法
chkconfig [--add][--del][--list][系统服务] 或 chkconfig [--level <等级代号>][系统服务][on/off/reset]
# 参数:
--add 增加所指定的系统服务,让 chkconfig 指令得以管理它,并同时在系统启动的叙述文件内增加相关数据。
--del 删除所指定的系统服务,不再由 chkconfig 指令管理,并同时在系统启动的叙述文件内删除相关数据。
--level<等级代号> 指定读系统服务要在哪一个执行等级中开启或关闭。
# 实例
列出chkconfig 所知道的所有命令
# chkconfig --list
开启服务
# chkconfig telnet on // 开启 Telnet 服务
# chkconfig --list // 列出 chkconfig 所知道的所有的服务的情况
关闭服务
# chkconfig telnet off // 关闭 Telnet 服务
# chkconfig --list // 列出 chkconfig 所知道的所有的服务的情况
timeconfig
命令用于设置时区
# 语法
timeconfig [--arc][--back][--test][--utc][时区名称]
# 参数:
--arc 使用Alpha硬件结构的格式存储系统时间。
--back 在互动式界面里,显示Back钮而非Cancel钮。
--test 仅作测试,并不真的改变系统的时区。
--utc 把硬件时钟上的时间视为CUT,有时也称为UTC或UCT。
# 实例
# timeconfig // 设置时区
Linux corntab 任务调度命令
crontab
用来定期执行程序的命令
# crontab [ -u user ] file
# crontab [ -u user ] { -l | -r | -e }
参数:
-u user 是指设定指定 user 的时程表,这个前提是你必须要有其权限(比如说是 root)才能够指定他人的时程表。
如果不使用 -u user 的话,就是表示设定自己的时程表。
-e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑器
则请先设定 VISUAL 环境变数来指定使用那个文字编辑器(比如说 setenv VISUAL joe)
-r : 删除目前的时程表
-l : 列出目前的时程表
crond 进程每分钟会定期检查是否有要执行的工作,如果有要执行的工作便会自动执行该工作。
注意:
新创建的 cron 任务,不会马上执行,至少要过 2 分钟后才可以,当然你可以重启 cron 来马上执行。
# linux 任务调度的工作主要分为以下两类:
1、系统执行的工作:系统周期性所要执行的工作,如备份系统数据、清理缓存
2、个人执行的工作:某个用户定期要做的工作,例如每隔 10 分钟检查邮件服务器是否有新信,这些工作可由每个用户自行设置
# 时间格式如下:
f1 f2 f3 f4 f5 program
f1 是表示分钟
f2 表示小时
f3 表示一个月份中的第几日
f4 表示月份
f5 表示一个星期中的第几天
program 表示要执行的程序
# 用法介绍:
当 f1 为 * 时表示每分钟都要执行 program,f2 为 * 时表示每小时都要执行程序,其馀类推
当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其馀类推
当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为 */n 表示每 n 小时个时间间隔执行一次,其馀类推
当 f1 为 a, b, c,... 时表示第 a, b, c,... 分钟要执行,f2 为 a, b, c,... 时表示第 a, b, c...个小时要执行,其馀类推
* * * * *
- - - - -
| | | | |
| | | | +----- 星期中星期几 (0 - 6) (星期天 为0)
| | | +---------- 月份 (1 - 12)
| | +--------------- 一个月中的第几天 (1 - 31)
| +-------------------- 小时 (0 - 23)
+------------------------- 分钟 (0 - 59)
# 使用者也可以将所有的设定先存放在文件中,用 crontab file 的方式来设定执行时间
执行时间 格式
每分钟定时执行一次 * * * * *
每小时定时执行一次 0 * * * *
每天定时执行一次 0 0 * * *
每周定时执行一次 0 0 * * 0
每月定时执行一次 0 0 1 * *
每月最后一天定时执行一次 0 0 L * *
每年定时执行一次 0 0 1 1 *
# 实例
# 每一分钟执行一次 /bin/ls:
* * * * * /bin/ls
# 在 12 月内, 每天的早上 6 点到 12 点,每隔 3 个小时 0 分钟执行一次 /usr/bin/backup:
0 6-12/3 * 12 * /usr/bin/backup
# 周一到周五每天下午 5:00 寄一封信给 alex@domain.name:
0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata
# 每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha":
20 0-23/2 * * * echo "haha"
# 意思是每两个小时重启一次apache
0 */2 * * * /sbin/service httpd restart
# 意思是每天7:50开启ssh服务
50 7 * * * /sbin/service sshd start
# 意思是每天22:50关闭ssh服务
50 22 * * * /sbin/service sshd stop
# 每月1号和15号检查/home 磁盘
0 0 1,15 * * fsck /home
# 每小时的第一分执行 /home/bruce/backup这个文件
1 * * * * /home/bruce/backup
# 每周一至周五3点钟,在目录/home中,查找文件名为*.xxx的文件,并删除4天前的文件。
00 03 * * 1-5 find /home "*.xxx" -mtime +4 -exec rm {} \;
# 意思是每月的1、11、21、31日是的6:30执行一次ls命令
30 6 */10 * * ls
注意:
当程序在你所指定的时间执行后,系统会发一封邮件给当前的用户,显示该程序执行的内容
若是你不希望收到这样的邮件,请在每一行空一格之后加上 > /dev/null 2>&1 即可,如:
20 03 * * * . /etc/profile;/bin/sh /var/www/runoob/test.sh > /dev/null 2>&1
"""
null 是一个名叫 null 小桶的东西,将输出重定向到它的好处是不会因为输出的内容过多而导致文件大小不断的增加。
其实,你就认为 null 就是什么都没有,也就是,将命令的输出扔弃掉了。
1 表示标准输出,2 表示标准错误输出,2>&1 表示将标准错误输出重定向到标准输出,程序或者命令的正常输出和错误输出就可以在标准输出输出
"""
# 脚本无法执行问题
如果我们使用 crontab 来定时执行脚本,无法执行,但是如果直接通过命令(如:./test.sh)又可以正常执行,这主要是因为无法读取环境变量的原因。
# 解决方法:
1、所有命令需要写成绝对路径形式,如:
/usr/local/bin/docker
2、在 shell 脚本开头使用以下代码:
#!/bin/sh
. /etc/profile
. ~/.bash_profile
3、在 /etc/crontab 中添加环境变量,在可执行命令之前添加命令 . /etc/profile;/bin/sh,使得环境变量生效,例如:
20 03 * * * . /etc/profile;/bin/sh /var/www/runoob/test.sh
Linux 查看端口占用情况
Linux 查看端口占用情况可以使用 lsof 和 netstat 命令
# lsof (list open files)
是一个列出当前系统打开文件的工具
# lsof 查看端口占用语法格式:
lsof -i:端口号
# 查看服务器 8000 端口的占用情况:
# lsof -i:8000 (可以看到 8000 端口已经被轻 nodejs 服务占用)
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nodejs 26993 root 10u IPv4 37999514 0t0 TCP *:8000 (LISTEN)
# 更多 lsof 的命令如下:
lsof -i:8080: 查看8080端口占用
lsof abc.txt: 显示开启文件abc.txt的进程
lsof -c abc: 显示abc进程现在打开的文件
lsof -c -p 1234: 列出进程号为1234的进程所打开的文件
lsof -g gid: 显示归属gid的进程情况
lsof +d /usr/local/:显示目录下被进程开启的文件
lsof +D /usr/local/:同上,但是会搜索目录下的目录,时间较长
lsof -d 4: 显示使用fd为4的进程
lsof -i -U: 显示所有打开的端口和UNIX domain文件
# netstat
netstat -a 显示详细的网络状况
netstat -tunlp 用于显示 tcp,udp 的端口和进程等相关情况
# netstat 查看端口占用语法格式:
netstat -tunlp | grep 端口号
# 参数:
-t (tcp) 仅显示tcp相关选项
-u (udp) 仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化为数字
-l 仅列出在Listen(监听)的服务状态
-p 显示建立相关链接的程序名
# 例如查看 8000 端口的情况,使用以下命令:
# netstat -tunlp | grep 8000
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN 26993/nodejs
# 更多命令:
netstat -ntlp // 查看当前所有tcp端口
netstat -ntulp | grep 80 // 查看所有80端口使用情况
netstat -ntulp | grep 3306 // 查看所有3306端口使用情况
防火墙的命令
service firewalld start # 开启
service firewalld restart # 重启
service firewalld stop # 关闭
firewall-cmd --list-all # 查看防火墙规则
firewall-cmd --query-port=8080/tcp # 查询端口是否开放
firewall-cmd --permanent --add-port=80/tcp # 开放80端口
firewall-cmd --permanent --remove-port=8080/tcp # 移除端口
firewall-cmd --reload # 重启防火墙(修改配置后要重启防火墙)
Docker 常用命令
Docker 三个基本概念
- 镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
- 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
Docker 基本信息
Docker version 命令
docker version :显示 Docker 版本信息。
语法
docker version [OPTIONS]
OPTIONS说明:
- -f : 指定返回值的模板文件。
实例
$ docker version
Client:
Version: 1.8.2
API version: 1.20
Go version: go1.4.2
Git commit: 0a8c2e3
Built: Thu Sep 10 19:19:00 UTC 2015
OS/Arch: linux/amd64
Server:
Version: 1.8.2
API version: 1.20
Go version: go1.4.2
Git commit: 0a8c2e3
Built: Thu Sep 10 19:19:00 UTC 2015
OS/Arch: linux/amd64
Docker info 命令
docker info : 显示 Docker 系统信息,包括镜像和容器数。
语法
docker info [OPTIONS]
实例
$ docker info
Containers: 12
Images: 41
Storage Driver: aufs
Root Dir: /var/lib/docker/aufs
Backing Filesystem: extfs
Dirs: 66
Dirperm1 Supported: false
Execution Driver: native-0.2
Logging Driver: json-file
Kernel Version: 3.13.0-32-generic
Operating System: Ubuntu 14.04.1 LTS
CPUs: 1
Total Memory: 1.954 GiB
Name: iZ23mtq8bs1Z
ID: M5N4:K6WN:PUNC:73ZN:AONJ:AUHL:KSYH:2JPI:CH3K:O4MK:6OCX:5OYW
Docker 本地镜像管理
Docker images 命令
docker images : 列出本地镜像。
语法
docker images [OPTIONS] [REPOSITORY[:TAG]]
OPTIONS说明:
- -a : 列出本地所有的镜像(含中间映像层,默认情况下,过滤掉中间映像层);
- –digests : 显示镜像的摘要信息;
- -f : 显示满足条件的镜像;
- –format : 指定返回值的模板文件;
- –no-trunc : 显示完整的镜像信息;
- -q : 只显示镜像ID。
实例
# 查看本地镜像列表
runoob@runoob:~$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mymysql v1 37af1236adef 5 minutes ago 329 MB
runoob/ubuntu v4 1c06aa18edee 2 days ago 142.1 MB
<none> <none> 5c6e1090e771 2 days ago 165.9 MB
httpd latest ed38aaffef30 11 days ago 195.1 MB
alpine latest 4e38e38c8ce0 2 weeks ago 4.799 MB
mongo 3.2 282fd552add6 3 weeks ago 336.1 MB
redis latest 4465e4bcad80 3 weeks ago 185.7 MB
php 5.6-fpm 025041cd3aa5 3 weeks ago 456.3 MB
python 3.5 045767ddf24a 3 weeks ago 684.1 MB
...
列出本地镜像中 REPOSITORY 为 ubuntu 的镜像列表。
root@runoob:~# docker images ubuntu
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu 14.04 90d5884b1ee0 9 weeks ago 188 MB
ubuntu 15.10 4e3b13c8a266 3 months ago 136.3 MB
Docker rmi 命令
docker rmi : 删除本地一个或多个镜像。
语法
docker rmi [OPTIONS] IMAGE [IMAGE...]
OPTIONS说明:
- -f : 强制删除;
- –no-prune : 不移除该镜像的过程镜像,默认移除;
实例
# 强制删除本地镜像 runoob/ubuntu:v4
root@runoob:~# docker rmi -f runoob/ubuntu:v4
Untagged: runoob/ubuntu:v4
Deleted: sha256:1c06aa18edee44230f93a90a7d88139235de12cd4c089d41eed8419b503072be
Deleted: sha256:85feb446e89a28d58ee7d80ea5ce367eebb7cec70f0ec18aa4faa874cbd97c73
Docker tag 命令
docker tag : 标记本地镜像,将其归入某一仓库。
语法
docker tag [OPTIONS] IMAGE[:TAG] [REGISTRYHOST/][USERNAME/]NAME[:TAG]
实例
将镜像ubuntu:15.10标记为 runoob/ubuntu:v3 镜像。
root@runoob:~# docker tag ubuntu:15.10 runoob/ubuntu:v3
root@runoob:~# docker images runoob/ubuntu:v3
REPOSITORY TAG IMAGE ID CREATED SIZE
runoob/ubuntu v3 4e3b13c8a266 3 months ago 136.3 MB
Docker build 命令
docker build 命令用于使用 Dockerfile 创建镜像。
语法
docker build [OPTIONS] PATH | URL | -
OPTIONS说明:
- –build-arg=[] : 设置镜像创建时的变量;
- –cpu-shares : 设置 cpu 使用权重;
- –cpu-period : 限制 CPU CFS周期;
- –cpu-quota : 限制 CPU CFS配额;
- –cpuset-cpus : 指定使用的CPU id;
- –cpuset-mems : 指定使用的内存 id;
- –disable-content-trust : 忽略校验,默认开启;
- -f : 指定要使用的Dockerfile路径;
- –force-rm : 设置镜像过程中删除中间容器;
- –isolation : 使用容器隔离技术;
- –label=[] : 设置镜像使用的元数据;
- -m : 设置内存最大值;
- –memory-swap : 设置Swap的最大值为内存+swap,"-1"表示不限swap;
- –no-cache : 创建镜像的过程不使用缓存;
- –pull : 尝试去更新镜像的新版本;
- –quiet, -q : 安静模式,成功后只输出镜像 ID;
- –rm : 设置镜像成功后删除中间容器;
- –shm-size : 设置/dev/shm的大小,默认值是64M;
- –ulimit : Ulimit配置。
- –squash : 将 Dockerfile 中所有的操作压缩为一层。
- –tag, -t: 镜像的名字及标签,通常 name:tag 或者 name 格式;可以在一次构建中为一个镜像设置多个标签。
- –network: 默认 default。在构建期间设置RUN指令的网络模式
实例
使用当前目录的 Dockerfile 创建镜像,标签为 runoob/ubuntu:v1。
docker build -t runoob/ubuntu:v1 .
使用URL github.com/creack/docker-firefox 的 Dockerfile 创建镜像。
docker build github.com/creack/docker-firefox
也可以通过 -f Dockerfile 文件的位置:
$ docker build -f /path/to/a/Dockerfile .
在 Docker 守护进程执行 Dockerfile 中的指令前,首先会对 Dockerfile 进行语法检查,有语法错误时会返回:
$ docker build -t test/myapp .
Sending build context to Docker daemon 2.048 kB
Error response from daemon: Unknown instruction: RUNCMD
Docker history 命令
docker history : 查看指定镜像的创建历史。
语法
docker history [OPTIONS] IMAGE
OPTIONS说明:
- -H : 以可读的格式打印镜像大小和日期,默认为true
- –no-trunc : 显示完整的提交记录
- -q : 仅列出提交记录ID
实例
查看本地镜像runoob/ubuntu:v3的创建历史。
root@runoob:~# docker history runoob/ubuntu:v3
IMAGE CREATED CREATED BY SIZE COMMENT
4e3b13c8a266 3 months ago /bin/sh -c #(nop) CMD ["/bin/bash"] 0 B
<missing> 3 months ago /bin/sh -c sed -i 's/^#\s*\(deb.*universe\)$/ 1.863 kB
<missing> 3 months ago /bin/sh -c set -xe && echo '#!/bin/sh' > /u 701 B
<missing> 3 months ago /bin/sh -c #(nop) ADD file:43cb048516c6b80f22 136.3 MB
Docker save 命令
docker save : 将指定镜像保存成 tar 归档文件。
语法
docker save [OPTIONS] IMAGE [IMAGE...]
OPTIONS 说明:
- -o : 输出到的文件。
实例
将镜像 runoob/ubuntu:v3 生成 my_ubuntu_v3.tar 文档
runoob@runoob:~$ docker save -o my_ubuntu_v3.tar runoob/ubuntu:v3
runoob@runoob:~$ ll my_ubuntu_v3.tar
-rw------- 1 runoob runoob 142102016 Jul 11 01:37 my_ubuntu_v3.ta
Docker load 命令
docker load : 导入使用 docker save 命令导出的镜像。
语法
docker load [OPTIONS]
OPTIONS 说明:
- –input , -i : 指定导入的文件,代替 STDIN。
- –quiet , -q : 精简输出信息。
实例
导入镜像:
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
$ docker load < busybox.tar.gz
Loaded image: busybox:latest
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest 769b9341d937 7 weeks ago 2.489 MB
$ docker load --input fedora.tar
Loaded image: fedora:rawhide
Loaded image: fedora:20
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest 769b9341d937 7 weeks ago 2.489 MB
fedora rawhide 0d20aec6529d 7 weeks ago 387 MB
fedora 20 58394af37342 7 weeks ago 385.5 MB
fedora heisenbug 58394af37342 7 weeks ago 385.5 MB
fedora latest 58394af37342 7 weeks ago 385.5 MB
Docker import 命令
docker import : 从归档文件中创建镜像。
语法
docker import [OPTIONS] file|URL|- [REPOSITORY[:TAG]]
OPTIONS说明:
- -c : 应用docker 指令创建镜像
- -m : 提交时的说明文字
实例
从镜像归档文件my_ubuntu_v3.tar创建镜像,命名为runoob/ubuntu:v4
runoob@runoob:~$ docker import my_ubuntu_v3.tar runoob/ubuntu:v4
sha256:63ce4a6d6bc3fabb95dbd6c561404a309b7bdfc4e21c1d59fe9fe4299cbfea39
runoob@runoob:~$ docker images runoob/ubuntu:v4
REPOSITORY TAG IMAGE ID CREATED SIZE
runoob/ubuntu v4 63ce4a6d6bc3 20 seconds ago 142.1 MB
Docker 镜像仓库
Docker login/logout 命令
docker login : 登陆到一个Docker镜像仓库,如果未指定镜像仓库地址,默认为官方仓库 Docker Hub
docker logout : 登出一个Docker镜像仓库,如果未指定镜像仓库地址,默认为官方仓库 Docker Hub
语法
docker login [OPTIONS] [SERVER]
docker logout [OPTIONS] [SERVER]
OPTIONS说明:
- -u : 登陆的用户名
- -p : 登陆的密码
实例
登陆到Docker Hub
docker login -u 用户名 -p 密码
登出Docker Hub
docker logout
Docker pull 命令
docker pull : 从镜像仓库中拉取或者更新指定镜像
语法
docker pull [OPTIONS] NAME[:TAG|@DIGEST]
OPTIONS说明:
- -a : 拉取所有 tagged 镜像
- –disable-content-trust : 忽略镜像的校验,默认开启
实例
从Docker Hub下载java最新版镜像。
docker pull java
从Docker Hub下载REPOSITORY为java的所有镜像。
docker pull -a java
Docker push 命令
docker push : 将本地的镜像上传到镜像仓库,要先登陆到镜像仓库
语法
docker push [OPTIONS] NAME[:TAG]
OPTIONS说明:
- –disable-content-trust : 忽略镜像的校验,默认开启
实例
上传本地镜像myapache:v1到镜像仓库中
docker push myapache:v1
Docker search 命令
docker search : 从Docker Hub查找镜像
语法
docker search [OPTIONS] TERM
OPTIONS说明:
- –automated : 只列出 automated build类型的镜像;
- –no-trunc : 显示完整的镜像描述;
- **-f <过滤条件>:**列出收藏数不小于指定值的镜像。
实例
从 Docker Hub 查找所有镜像名包含 java,并且收藏数大于 10 的镜像
runoob@runoob:~$ docker search -f stars=10 java
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
java Java is a concurrent, class-based... 1037 [OK]
anapsix/alpine-java Oracle Java 8 (and 7) with GLIBC ... 115 [OK]
develar/java 46 [OK]
isuper/java-oracle This repository contains all java... 38 [OK]
lwieske/java-8 Oracle Java 8 Container - Full + ... 27 [OK]
nimmis/java-centos This is docker images of CentOS 7... 13 [OK]
参数说明:
NAME: 镜像仓库源的名称
DESCRIPTION: 镜像的描述
OFFICIAL: 是否 docker 官方发布
stars: 类似 Github 里面的 star,表示点赞、喜欢的意思。
AUTOMATED: 自动构建。
Docker 容器生命周期管理
Docker run 命令
docker run : 创建一个新的容器并运行一个命令
语法
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
OPTIONS说明:
- -a stdin: 指定标准输入输出内容类型,可选 STDIN/STDOUT/STDERR 三项;
- -d: 后台运行容器,并返回容器ID;
- -i: 以交互模式运行容器,通常与 -t 同时使用;
- -P: 随机端口映射,容器内部端口随机映射到主机的端口
- -p: 指定端口映射,格式为:** 主机(宿主)端口:容器端口**
- -t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用;
- –name=“nginx-lb”: 为容器指定一个名称;
- –dns 8.8.8.8: 指定容器使用的DNS服务器,默认和宿主一致;
- –dns-search example.com: 指定容器DNS搜索域名,默认和宿主一致;
- -h “mars”: 指定容器的hostname;
- -e username=“ritchie”: 设置环境变量;
- –env-file=[]: 从指定文件读入环境变量;
- –cpuset=“0-2” or --cpuset=“0,1,2”: 绑定容器到指定CPU运行;
- -m : 设置容器使用内存最大值;
- –net=“bridge”: 指定容器的网络连接类型,支持 bridge/host/none/container: 四种类型;
- –link=[]: 添加链接到另一个容器;
- –expose=[]: 开放一个端口或一组端口;
- –volume , -v: 绑定一个卷
实例
使用docker镜像nginx:latest以后台模式启动一个容器,并将容器命名为mynginx。
docker run --name mynginx -d nginx:latest
使用镜像nginx:latest以后台模式启动一个容器,并将容器的80端口映射到主机随机端口。
docker run -P -d nginx:latest
使用镜像 nginx:latest,以后台模式启动一个容器,将容器的 80 端口映射到主机的 80 端口,主机的目录 /data 映射到容器的 /data。
docker run -p 80:80 -v /data:/data -d nginx:latest
绑定容器的 8080 端口,并将其映射到本地主机 127.0.0.1 的 80 端口上。
$ docker run -p 127.0.0.1:80:8080/tcp ubuntu bash
使用镜像nginx:latest以交互模式启动一个容器,在容器内执行/bin/bash命令。
runoob@runoob:~$ docker run -it nginx:latest /bin/bash
root@b8573233d675:/#
服务开启自启动
创建容器时没有添加参数 –restart=always ,导致的后果是:当 Docker 重启时,容器未能自动启动。
# Docker update 添加或是修改启动命令:
docker update --restart=always ea8
# 查看修改后的效果
[root@vm10-0-1-212 ~]# docker inspect ea8 |grep RestartPolicy -A 3
"RestartPolicy": {
"Name": "always",
"MaximumRetryCount": 0
}
# 其他示例
"""
Docker restart 参数用于指定自动重启docker容器策略,包含3个选项:
no
on-failure[:times]
always
unless-stopped
"""
# no
# 默认值,表示容器退出时,docker不自动重启容器
docker run --restart=no [容器名]
# on-failure
# 若容器的退出状态非0,则docker自动重启容器,还可以指定重启次数,若超过指定次数未能启动容器则放弃
docker run --restart=on-failure:3 [容器名]
# always
# 容器退出时总是重启
docker run --restart=always [容器名]
# unless-stopped
# 容器退出时总是重启,但不考虑Docker守护进程启动时就已经停止的容器
docker run --restart=unless-stopped [容器名]
# 如果容器启动时没有设置–restart参数,则通过下面命令进行更新
docker update --restart=always [容器名]
Docker start/stop/restart 命令
docker start : 启动一个或多个已经被停止的容器
docker stop : 停止一个运行中的容器
docker restart : 重启容器
语法
docker start [OPTIONS] CONTAINER [CONTAINER...]
docker stop [OPTIONS] CONTAINER [CONTAINER...]
docker restart [OPTIONS] CONTAINER [CONTAINER...]
实例
启动已被停止的容器myrunoob
docker start myrunoob
停止运行中的容器myrunoob
docker stop myrunoob
重启容器myrunoob
docker restart myrunoob
Docker kill 命令
docker kill : 杀掉一个运行中的容器。
语法
docker kill [OPTIONS] CONTAINER [CONTAINER...]
OPTIONS说明:
-s : 向容器发送一个信号
实例
杀掉运行中的容器mynginx
runoob@runoob:~$ docker kill -s KILL mynginx
mynginx
Docker rm 命令
docker rm : 删除一个或多个容器。
语法
docker rm [OPTIONS] CONTAINER [CONTAINER...]
OPTIONS说明:
- -f : 通过 SIGKILL 信号强制删除一个运行中的容器。
- -l : 移除容器间的网络连接,而非容器本身。
- -v : 删除与容器关联的卷。
实例
强制删除容器 db01、db02:
docker rm -f db01 db02
移除容器 nginx01 对容器 db01 的连接,连接名 db:
docker rm -l db
删除容器 nginx01, 并删除容器挂载的数据卷:
docker rm -v nginx01
删除所有已经停止的容器:
docker rm $(docker ps -a -q)
Docker pause/unpause 命令
docker pause :暂停容器中所有的进程。
docker unpause :恢复容器中所有的进程。
语法
docker pause CONTAINER [CONTAINER...]
docker unpause CONTAINER [CONTAINER...]
实例
暂停数据库容器db01提供服务。
docker pause db01
恢复数据库容器 db01 提供服务。
docker unpause db01
Docker create 命令
docker create : 创建一个新的容器但不启动它
用法同 [docker run]
语法
docker create [OPTIONS] IMAGE [COMMAND] [ARG...]
语法同 [docker run]
实例
使用docker镜像nginx:latest创建一个容器,并将容器命名为myrunoob
runoob@runoob:~$ docker create --name myrunoob nginx:latest
09b93464c2f75b7b69f83d56a9cfc23ceb50a48a9db7652ee4c27e3e2cb1961f
Docker exec 命令
docker exec : 在运行的容器中执行命令
语法
docker exec [OPTIONS] CONTAINER COMMAND [ARG...]
OPTIONS说明:
- -d : 分离模式: 在后台运行
- -i : 即使没有附加也保持STDIN 打开
- -t : 分配一个伪终端
实例
在容器 mynginx 中以交互模式执行容器内 /root/runoob.sh 脚本:
runoob@runoob:~$ docker exec -it mynginx /bin/sh /root/runoob.sh
http://www.runoob.com/
在容器 mynginx 中开启一个交互模式的终端:
runoob@runoob:~$ docker exec -i -t mynginx /bin/bash
root@b1a0703e41e7:/#
也可以通过 docker ps -a 命令查看已经在运行的容器,然后使用容器 ID 进入容器。
查看已经在运行的容器 ID (第一列的 9df70f9a0714 就是容器 ID):
# docker ps -a
...
9df70f9a0714 openjdk "/usercode/script.sh…"
...
通过 exec 命令对指定的容器执行 bash:
# docker exec -it 9df70f9a0714 /bin/bash
Docker 容器操作
Docker ps 命令
docker ps : 列出容器
语法
docker ps [OPTIONS]
OPTIONS说明:
- -a : 显示所有的容器,包括未运行的。
- -f : 根据条件过滤显示的内容。
- –format : 指定返回值的模板文件。
- -l : 显示最近创建的容器。
- -n : 列出最近创建的n个容器。
- –no-trunc : 不截断输出。
- -q : 静默模式,只显示容器编号。
- -s : 显示总的文件大小。
实例
# 列出所有在运行的容器信息
runoob@runoob:~$ docker ps
CONTAINER ID IMAGE COMMAND ... PORTS NAMES
09b93464c2f7 nginx:latest "nginx -g 'daemon off" ... 80/tcp, 443/tcp myrunoob
96f7f14e99ab mysql:5.6 "docker-entrypoint.sh" ... 0.0.0.0:3306->3306/tcp mymysql
输出详情介绍:
CONTAINER ID: 容器 ID。
IMAGE: 使用的镜像。
COMMAND: 启动容器时运行的命令。
CREATED: 容器的创建时间。
STATUS: 容器状态。
7种状态:
created(已创建)restarting(重启中)running(运行中)removing(迁移中)paused(暂停)exited(停止)dead(死亡)
PORTS: 容器的端口信息和使用的连接类型(tcp\udp)。
NAMES: 自动分配的容器名称。
列出最近创建的5个容器信息
runoob@runoob:~$ docker ps -n 5
CONTAINER ID IMAGE COMMAND CREATED
09b93464c2f7 nginx:latest "nginx -g 'daemon off" 2 days ago ...
...
a63b4a5597de 860c279d2fec "bash" 2 days ago ...
列出所有创建的容器ID
runoob@runoob:~$ docker ps -a -q
09b93464c2f7
ba52eb632bbd
...
Docker inspect 命令
docker inspect : 获取容器/镜像的元数据。
语法
docker inspect [OPTIONS] NAME|ID [NAME|ID...]
OPTIONS说明:
- -f : 指定返回值的模板文件。
- -s : 显示总的文件大小。
- –type : 为指定类型返回JSON。
实例
获取镜像mysql:5.6的元信息
runoob@runoob:~$ docker inspect mysql:5.6
[
{
"Id": "sha256:2c0964ec182ae9a045f866bbc2553087f6e42bfc16074a74fb820af235f070ec",
"RepoTags": [
"mysql:5.6"
],
"RepoDigests": [],
"Parent": "",
"Comment": "",
"Created": "2016-05-24T04:01:41.168371815Z",
"Container": "e0924bc460ff97787f34610115e9363e6363b30b8efa406e28eb495ab199ca54",
"ContainerConfig": {
"Hostname": "b0cf605c7757",
"Domainname": "",
"User": "",
"AttachStdin": false,
"AttachStdout": false,
"AttachStderr": false,
"ExposedPorts": {
"3306/tcp": {}
},
...
获取正在运行的容器mymysql的 IP
runoob@runoob:~$ docker inspect --format='{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' mymysql
172.17.0.3
Docker top 命令
docker top : 查看容器中运行的进程信息,支持 ps 命令参数。
语法
docker top [OPTIONS] CONTAINER [ps OPTIONS]
容器运行时不一定有/bin/bash终端来交互执行top命令,而且容器还不一定有top命令,可以使用docker top来实现查看container中正在运行的进程。
实例
查看容器mymysql的进程信息
runoob@runoob:~/mysql$ docker top mymysql
UID PID PPID C STIME TTY TIME CMD
999 40347 40331 18 00:58 ? 00:00:02 mysqld
查看所有运行容器的进程信息
for i in `docker ps |grep Up|awk '{print $1}'`;do echo \ &&docker top $i; done
Docker attach 命令
docker attach : 连接到正在运行中的容器。
语法
docker attach [OPTIONS] CONTAINER
要attach上去的容器必须正在运行,可以同时连接上同一个container来共享屏幕(与screen命令的attach类似)。
官方文档中说attach后可以通过CTRL-C来detach,但实际上经过我的测试,如果container当前在运行bash,CTRL-C自然是当前行的输入,没有退出;如果container当前正在前台运行进程,如输出nginx的access.log日志,CTRL-C不仅会导致退出容器,而且还stop了。这不是我们想要的,detach的意思按理应该是脱离容器终端,但容器依然运行。好在attach是可以带上–sig-proxy=false来确保CTRL-D或CTRL-C不会关闭容器。
实例
容器mynginx将访问日志指到标准输出,连接到容器查看访问信息。
runoob@runoob:~$ docker attach --sig-proxy=false mynginx
192.168.239.1 - - [10/Jul/2016:16:54:26 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36" "-"
Docker events 命令
docker events : 从服务器获取实时事件
语法
docker events [OPTIONS]
OPTIONS说明:
- -f : 根据条件过滤事件;
- –since : 从指定的时间戳后显示所有事件;
- –until : 流水时间显示到指定的时间为止;
实例
显示docker 2016年7月1日后的所有事件。
runoob@runoob:~/mysql$ docker events --since="1467302400"
2016-07-08T19:44:54.501277677+08:00 network connect 66f958fd13dc4314ad20034e576d5c5eba72e0849dcc38ad9e8436314a4149d4 (container=b8573233d675705df8c89796a2c2687cd8e36e03646457a15fb51022db440e64, name=bridge, type=bridge)
...
2016-07-08T19:46:22.137250899+08:00 container die b8573233d675705df8c89796a2c2687cd8e36e03646457a15fb51022db440e64 (exitCode=0, image=nginx:latest, name=elegant_albattani)
显示docker 镜像为mysql:5.6 2016年7月1日后的相关事件。
runoob@runoob:~/mysql$ docker events -f "image"="mysql:5.6" --since="1467302400"
2016-07-11T00:38:53.975174837+08:00 container start 96f7f14e99ab9d2f60943a50be23035eda1623782cc5f930411bbea407a2bb10 (image=mysql:5.6, name=mymysql)
...
2016-07-11T01:06:01.395365098+08:00 container top a404c6c174a21c52f199cfce476e041074ab020453c7df2a13a7869b48f2f37e (image=mysql:5.6, name=mymysql)
如果指定的时间是到秒级的,需要将时间转成时间戳。如果时间为日期的话,可以直接使用,如–since=“2016-07-01”。
Docker logs 命令
docker logs : 获取容器的日志
语法
docker logs [OPTIONS] CONTAINER
OPTIONS说明:
- -f : 跟踪日志输出
- –since : 显示某个开始时间的所有日志
- -t : 显示时间戳
- –tail : 仅列出最新N条容器日志
实例
跟踪查看容器mynginx的日志输出。
runoob@runoob:~$ docker logs -f mynginx
192.168.239.1 - - [10/Jul/2016:16:53:33 +0000] "GET / HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36" "-"
...
192.168.239.1 - - [10/Jul/2016:16:53:59 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36" "-"
...
查看容器mynginx从2016年7月1日后的最新10条日志。
docker logs --since="2016-07-01" --tail=10 mynginx
Docker wait 命令
docker wait : 阻塞运行直到容器停止,然后打印出它的退出代码。
语法
docker wait [OPTIONS] CONTAINER [CONTAINER...]
实例
docker wait CONTAINER
Docker export 命令
docker export : 将文件系统作为一个tar归档文件导出到STDOUT。
语法
docker export [OPTIONS] CONTAINER
OPTIONS说明:
- -o : 将输入内容写到文件。
实例
将id为a404c6c174a2的容器按日期保存为tar文件。
runoob@runoob:~$ docker export -o mysql-`date +%Y%m%d`.tar a404c6c174a2
runoob@runoob:~$ ls mysql-`date +%Y%m%d`.tar
mysql-20160711.tar
Docker port 命令
docker port 用于列出指定的容器的端口映射,或者查找将 PRIVATE_PORT NAT 到面向公众的端口。
语法
docker port [OPTIONS] CONTAINER [PRIVATE_PORT[/PROTO]]
实例
查看容器 mymysql 的端口映射情况:
runoob@runoob:~$ docker port mymysql
3306/tcp -> 0.0.0.0:3306
Docker stats 命令
docker stats : 显示容器资源的使用情况,包括:CPU、内存、网络 I/O 等。
语法
docker stats [OPTIONS] [CONTAINER...]
OPTIONS 说明:
- –all , -a : 显示所有的容器,包括未运行的。
- –format : 指定返回值的模板文件。
- –no-stream : 展示当前状态就直接退出了,不再实时更新。
- –no-trunc : 不截断输出。
实例
# 列出所有在运行的容器信息
runoob@runoob:~$ docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
b95a83497c91 awesome_brattain 0.28% 5.629MiB / 1.952GiB 0.28% 916B / 0B 147kB / 0B 9
4bda148efbc0 random.1.vnc8on831idyr42slu578u3cr 0.00% 1.672MiB / 1.952GiB 0.08% 110kB / 0B 578kB / 0B 2
输出详情介绍:
CONTAINER ID 与 NAME: 容器 ID 与名称。
CPU % 与 MEM %: 容器使用的 CPU 和内存的百分比。
MEM USAGE / LIMIT: 容器正在使用的总内存,以及允许使用的内存总量。
NET I/O: 容器通过其网络接口发送和接收的数据量。
BLOCK I/O: 容器从主机上的块设备读取和写入的数据量。
PIDs: 容器创建的进程或线程数。
根据容器等 ID 或名称显示信息:
runoob@runoob:~$ docker stats awesome_brattain 67b2525d8ad1
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
b95a83497c91 awesome_brattain 0.28% 5.629MiB / 1.952GiB 0.28% 916B / 0B 147kB / 0B 9
67b2525d8ad1 foobar 0.00% 1.727MiB / 1.952GiB 0.09% 2.48kB / 0B 4.11MB / 0B 2
以 JSON 格式输出:
runoob@runoob:~$ docker stats nginx --no-stream --format "{{ json . }}"
{"BlockIO":"0B / 13.3kB","CPUPerc":"0.03%","Container":"nginx","ID":"ed37317fbf42","MemPerc":"0.24%","MemUsage":"2.352MiB / 982.5MiB","Name":"nginx","NetIO":"539kB / 606kB","PIDs":"2"}
输出指定的信息:
runoob@runoob:~$ docker stats --all --format "table {{.Container}}\t{{.CPUPerc}}\t{{.MemUsage}}" fervent_panini 5acfcb1b4fd1 drunk_visvesvaraya big_heisenberg
{"BlockIO":"0B / 13.3kB","CPUPerc":"0.03%","Container":"nginx","ID":"ed37317fbf42","MemPerc":"0.24%","MemUsage":"2.352MiB / 982.5MiB","Name":"nginx","NetIO":"539kB / 606kB","PIDs":"2"}
CONTAINER CPU % MEM USAGE / LIMIT
fervent_panini 0.00% 56KiB / 15.57GiB
5acfcb1b4fd1 0.07% 32.86MiB / 15.57GiB
drunk_visvesvaraya 0.00% 0B / 0B
big_heisenberg 0.00% 0B / 0B
Docker 容器 rootfs 命令
Docker commit 命令
docker commit : 从容器创建一个新的镜像。
语法
docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
OPTIONS说明:
- -a : 提交的镜像作者;
- -c : 使用Dockerfile指令来创建镜像;
- -m : 提交时的说明文字;
- -p : 在commit时,将容器暂停。
实例
将容器 a404c6c174a2 保存为新的镜像,并添加提交人信息和说明信息。
runoob@runoob:~$ docker commit -a "runoob.com" -m "my apache" a404c6c174a2 mymysql:v1
sha256:37af1236adef1544e8886be23010b66577647a40bc02c0885a6600b33ee28057
runoob@runoob:~$ docker images mymysql:v1
REPOSITORY TAG IMAGE ID CREATED SIZE
mymysql v1 37af1236adef 15 seconds ago 329 MB
Docker cp 命令
docker cp : 用于容器与主机之间的数据拷贝。
语法
docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH|-
docker cp [OPTIONS] SRC_PATH|- CONTAINER:DEST_PATH
OPTIONS说明:
- -L : 保持源目标中的链接
实例
将主机/www/runoob目录拷贝到容器96f7f14e99ab的/www目录下。
docker cp /www/runoob 96f7f14e99ab:/www/
将主机/www/runoob目录拷贝到容器96f7f14e99ab中,目录重命名为www。
docker cp /www/runoob 96f7f14e99ab:/www
将容器96f7f14e99ab的/www目录拷贝到主机的/tmp目录中。
docker cp 96f7f14e99ab:/www /tmp/
Docker diff 命令
docker diff : 检查容器里文件结构的更改。
语法
docker diff [OPTIONS] CONTAINER
实例
查看容器mymysql的文件结构更改。
runoob@runoob:~$ docker diff mymysql
A /logs
C /run/mysqld
A /run/mysqld/mysqld.pid
C /tmp
Dockerfile
命令
# 常用命令
FROM
指定基础镜像
COPY
复制文件
RUN
执行一个
CMD
在容器启动后执行的命令
EXPORT
容器中,对外提供服务的端口
WORKDIR
命令工作的目录
# 其他命令
AS 别名
ENV
设置镜像运行时的环境变量
ADD
类似于COPY,但可以获取网络文件或者解压压缩包
ENTRYPOINT
类似于CMD,但不可以被docker run 的命令覆盖
# 构建镜像
docker build -t docker-registry.xxx.virtual/xxx/[镜像名称]:[版本号] .
# 上传镜像
docker push docker-registry.xxx.virtual/xxx/[镜像名称]:[版本号]
编写及优化
编写技巧
-
当复制文件时,可以将不经常变动的文件,放在前边,可以使构建时,可以用到上次构建的缓存,提高构建速度
-
使用 .dockerignore 文件来忽略非必要的文件,以提高copy命令的的效率
-
尽量将多个命令放到一块,可以减少镜像的层数。
-
可以考虑使用多阶段构建,来减少不必要的命令。
多阶段构建作用:
-
a. 减少镜像的体积
-
每一条 FROM 指令都是一个构建阶段,多条 FROM 就是多阶段构建,虽然最后生成的镜像只能是最后一个阶段的结果
-
但是,能够将前置阶段中的文件拷贝到后边的阶段中,这就是多阶段构建的最大意义
-
e.g.
Docker 17.05版本以后(多阶段构建):
============================================================================================== # 多阶段的玄妙之处就在于 COPY 指令的 --from=0 参数,从前边的阶段中拷贝文件到当前阶段,多个FROM语句时,0代表第一个阶段 # 编译阶段 FROM golang:1.10.3 COPY server.go /build/ WORKDIR /build RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 GOARM=6 go build -ldflags '-w -s' -o server # 运行阶段 FROM scratch # 从编译阶段的中拷贝编译结果到当前镜像中 COPY --from=0 /build/server / ENTRYPOINT ["/server"] ============================================================================================== ============================================================================================== # 除了使用数字,我们还可以给阶段命名,比如: # 编译阶段 命名为 builder FROM golang:1.10.3 as builder # ... 省略 # 运行阶段 FROM scratch # 从编译阶段的中拷贝编译结果到当前镜像中 COPY --from=builder /build/server / ============================================================================================== ============================================================================================== # 更为强大的是,COPY --from 不但可以从前置阶段中拷贝,还可以直接从一个已经存在的镜像中拷贝。比如: FROM ubuntu:16.04 COPY --from=quay.io/coreos/etcd:v3.3.9 /usr/local/bin/etcd /usr/local/bin/ ==============================================================================================
-
-
b. 当一个项目需要生成不同的镜像时,写在一个dokcerfile文件中即可(docker build --target [阶段名称] -t [镜像名称]:[镜像标签] .)
-
-
可以使用该命令来查看镜像的层级及每层的大小
docker image history 【镜像名称:tag】
注意:
-
只有COPY、RUN、ADD 会增加镜像的大小
-
需要有1个程序前台运行,作为容器的pid为1的进程,当该进程结束,则容器也运行结束
BUILDKIT
-
BuildKit 是 Docker 官方社区推出的下一代镜像构建神器–可以更加快速,有效,安全地构建 Docker 镜像。Docker v18.06已经集成了该组件。
-
作用: 提高构建速度
-
优点:
- 提高10%左右的构建速度
- 日志更清晰
- 可以更好的与多阶段构建配合
Docker-Slim
功能
- 不修改镜像内容前提下, 缩小30倍镜像。
- 其官方通过静态分析跟动态分析来实现镜像的缩小。
静态分析
- 通过docker镜像自带镜像历史信息,获取生成镜像的dockerfile文件及相关的配置信息。
动态分析
- 通过内核工具ptrace(跟踪系统调用)、pevent(跟踪文件或目录的变化)、fanotify(跟踪进程)解析出镜像中必要的文件和文件依赖,将对应文件组织成新镜像。
安装Docker-Slim
-
下载地址: https://github.com/docker-slim/docker-slim/releases 下载最新版本
-
其程序分为 docker-slim docker-slim-sensor 两个, 添加执行权限即可执行
-
建议将其添加到环境变量PATH中,或者直接放到/usr/bin目录下
使用说明
简单操作
# 查看镜像
docker images [image-name]:[tag]
# 镜像瘦身
docker-slim build --http-probe=false [image-name]:[tag] # 生成后的镜像名称为: [image-name].slim
官方示例
$ head -n 1 Dockerfile
FROM ubuntu:14.04
$ docker images my/sample-node-app
REPOSITORY TAG IMAGE ID CREATED SIZE
my/sample-node-app latest 31be09316a19 4 minutes ago 432MB
$ docker-slim build my/sample-node-app
docker-slim[build]: state=started
docker-slim[build]: info=params target=my/sample-node-app continue.mode=enter
docker-slim[build]: state=inspecting.image
docker-slim[build]: state=inspecting.container
docker-slim[build]: info=container ... target.port.list=[32908] target.port.info=[8000/tcp => 0.0.0.0:32908]
docker-slim[build]: info=prompt message='press <enter> when you are done using the container'
docker-slim[build]: state=http.probe.starting
docker-slim[build]: info=http.probe.call status=200 method=GET target=http://127.0.0.1:32908/ attempt=1 error=none
docker-slim[build]: state=http.probe.done
docker-slim[build]: state=processing
docker-slim[build]: state=building message='building minified image'
docker-slim[build]: state=completed
docker-slim[build]: info=results status='MINIFIED BY 30.88X [432330078 (432 MB) => 14002579 (14 MB)]'
docker-slim[build]: info=results image.name=my/sample-node-app.slim image.size='14 MB' data=true
$ docker images my/sample-node-app.slim
REPOSITORY TAG IMAGE ID CREATED SIZE
my/sample-node-app.slim latest b72b685be7fe 1 minute ago 14 MB
详细操作
NAME:
docker-slim – optimize and secure your Docker containers!
USAGE:
docker-slim [global options] command [command options] [arguments…]
VERSION:
darwin|Transformer|1.26.1|2ec04e169b12a87c5286aa09ef44eac1cea2c7a1|2019-11-28_04:37:59PM
COMMANDS:
version, v Shows docker-slim and docker version information
update, u Update docker-slim
info, i Collects fat image information and reverse engineers its Dockerfile
build, b Collects fat image information and builds a slim image from it
profile, p Collects fat image information and generates a fat container report
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
–report value command report location (enabled by default; set it to “off” to disable it) (default: “slim.report.json”)
–check-version check if the current version is outdated [$DSLIM_CHECK_VERSION]
–debug enable debug logs
–verbose enable info logs
–log-level value set the logging level (‘debug’, ‘info’, ‘warn’ (default), ‘error’, ‘fatal’, ‘panic’) (default: “warn”)
–log value log file to store logs
–log-format value set the format used by logs (‘text’ (default), or ‘json’) (default: “text”)
–tls use TLS
–tls-verify verify TLS
–tls-cert-path value path to TLS cert files
–host value Docker host address
–state-path value DockerSlim state base path
–in-container DockerSlim is running in a container
–archive-state value archive DockerSlim state to the selected Docker volume (default volume – docker-slim-state). By default, enabled when DockerSlim is running in a container (disabled otherwise). Set it to “off” to disable explicitly.
–help, -h show help
–version, -v print the version
常见安全漏洞
XSS
-
XSS攻击全称跨站脚本攻击,是一种在web应用中的计算机安全漏洞,它允许恶意web用户将代码植入到提供给其它用户使用的页面中。
-
常见的 XSS 攻击有三种:
- 反射型XSS攻击
- 反射型 XSS 一般是攻击者通过特定手法(如电子邮件),诱使用户去访问一个包含恶意代码的 URL,当受害者点击这些专门设计的链接的时候,恶意代码会直接在受害者主机上的浏览器执行。
- 反射型XSS通常出现在网站的搜索栏、用户登录口等地方,常用来窃取客户端 Cookies 或进行钓鱼欺骗。
- 存储型XSS攻击
- 持久型XSS,主要将XSS代码提交存储在服务器端(数据库,内存,文件系统等),下次请求目标页面时不用再提交XSS代码。当目标用户访问该页面获取数据时,XSS代码会从服务器解析之后加载出来,返回到浏览器做正常的HTML和JS解析执行,XSS攻击就发生了。
- 存储型 XSS 一般出现在网站留言、评论、博客日志等交互处,恶意脚本存储到客户端或者服务端的数据库中。
- DOM-based 型XXS攻击
- 是一种基于文档对象模型(Document Object Model,DOM)的Web前端漏洞,简单来说就是JavaScript代码缺陷造成的漏洞。
- 基于 DOM 的 XSS 攻击是指通过恶意脚本修改页面的 DOM 结构,是纯粹发生在客户端的攻击。DOM 型 XSS 攻击中,取出和执行恶意代码由浏览器端完成,属于前端 JavaScript 自身的安全漏洞。
- 反射型XSS攻击
-
防御XSS攻击
-
对输入内容的特定字符进行编码,例如表示 html标记的 < > 等符号。
-
对重要的 cookie设置 httpOnly, 防止客户端通过document.cookie读取 cookie,此 HTTP头由服务端设置。
-
将不可信的值输出 URL 参数之前,进行 URLEncode 操作,而对于从 URL 参数中获取值一定要进行格式检测
(比如你需要的URL,就判读是否满足URL格式)。
-
不要使用 Eval 来解析并运行不确定的数据或代码,对于 JSON解析请使用 JSON.parse() 方法。
-
后端接口也应该要做到关键字符过滤的问题。
-
CSRF
-
CSRF (Cross-Site Request Forgery),跨站请求伪造,跟XSS漏洞攻击一样,存在巨大的危害性。
-
可以这么理解:攻击者盗用了你的身份,以你的名义发送恶意请求,对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作,比如
以你的名义发送邮件、发消息,盗取你的账号,添加系统管理员,甚至于购买商品、虚拟货币转账等
-
-
CSRF攻击原理
- 两个条件:用户访问站点A并产生了cookie,用户没有退出A同时访问了B
- 用户输入账号信息请求登录A网站。
- A网站验证用户信息,通过验证后返回给用户一个cookie
- 在未退出网站A之前,在同一浏览器中请求了黑客构造的恶意网站B
- B网站收到用户请求后返回攻击性代码,构造访问A网站的语句
- 浏览器收到攻击性代码后,在用户不知情的情况下携带cookie信息请求了A网站。此时A网站不知道这是由B发起的。
-
CSRF攻击的防御
-
验证 HTTP Referer 字段
-
在请求地址中添加 token 并验证
-
这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,
与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。
-
-
在 HTTP 头中自定义属性并验证
-
这种方法也是使用 token 并进行验证,和上一种方法不同的是,这里并不是把 token 以参数的形式置于 HTTP 请求之中,而是把它放到 HTTP 头中自
定义的属性里。
-
通过 XMLHttpRequest 这个类,可以一次性给所有该类请求加上 CSRFToken 这个 HTTP 头属性,并把 token 值放入其中。
这样解决了上种方法在请求中加入 token 的不便,同时,通过 XMLHttpRequest 请求的地址不会被记录到浏览器的地址栏,也不用担心 token 会透
过 Referer 泄露到其他网站中去。
-
-
nginx + uwsgi 部署
概念介绍
什么是WSGI
-
WSGI是一种python专用的web协议,和 http 类似
-
WSGI是一种规范,它定义了使用python编写的web app(django)与web server(uWSGI)之间接口格式,实现web app与web server间的解耦。
-
WSGI 没有官方的实现, 因为WSGI更像一个协议. 只要遵照这些协议,WSGI应用(Application)都可以在任何服务器(Server)上运行
-
WSGI实质:WSGI是一种描述web服务器(如nginx,uWSGI等服务器)如何与web应用程序(如用Django、Flask框架写的程序)通信的规范、协议。
为什么需要web协议
- 不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。
- 这样,服务器程序就需要为不同的框架提供不同的支持,只有支持它的服务器才能被开发出的应用使用,显然这是不可行的。
- web协议本质:就是定义了Web服务器和Web应用程序或框架之间的一种简单而通用的接口规范。
Web协议介绍
- Web协议出现顺序: CGI -> FastCGI -> WSGI -> uwsgi
- CGI: 最早的协议
- FastCGI: 比CGI快
- WSGI: Python专用的协议
- uwsgi: 比FCGI和WSGI都快,是uWSGI项目自有的协议,主要特征是采用二进制来存储数据,之前的协议都是使用字符串,所以在存储空间和解析速度上,都优于字符串型协议.
uWSGI
-
web服务器,和nginx类似
-
什么是uWSGI: uWSGI是一个全功能的HTTP服务器,实现了WSGI协议、uwsgi协议、http协议等。
-
uWSGI作用: 它要做的就是把HTTP协议转化成语言支持的网络协议,比如把HTTP协议转化成WSGI协议,让Python可以直接使用。
-
uWSGI特点: 轻量级,易部署,性能比nginx差很多
-
uWSGI处理动态请求能力高,但是对于静态请求(静态文件)处理能力就不是很好,就需要结合nginx使用。
-
在生产环境中部署Python Web项目时,uWSGI负责处理Nginx转发的动态请求,并与我们的Python应用程序沟通,同时将应用程序返回的响应数据传递给Nginx。
客户端 <-> Nginx <-> uWSGI <-> Python应用程序(Django, Flask)
Nginx
- Nginx是一个Web服务器,其中的HTTP服务器功能和uWSGI功能很类似
- 但是Nginx还可以用作更多用途,比如最常用的反向代理、负载均衡、拦截攻击等,而且性能极高
区别
nginx和uWSGI区别
- nginx和uWSGI都是web服务器,都可以用来部署django等服务
- nginx: 处理静态资源能力非常强,还可以提供 负载均衡、反向代理、攻击拦截等
- uWSGI: 单点部署,容易部署,性能差一些,可以支持的web协议多
uWSGI 和 uwsgi区别
- uWSGI: 是一个web服务器
- uwsgi: 是一种web协议
WSGI和uwsgi区别
- uwsgi: 也是一种web协议,传输快(二进制存储,其他web协议都是字符串存储)
- WSGI: python专业的web协议
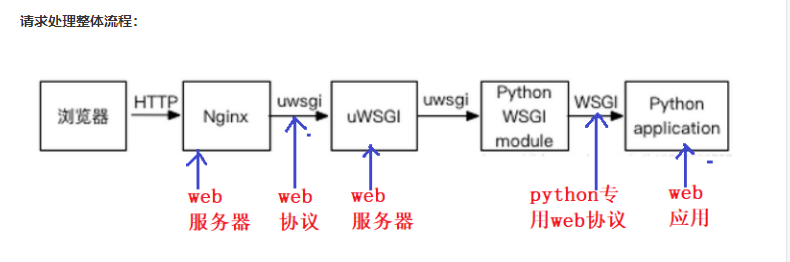
- nginx接收到浏览器发送过来的http请求,将包进行解析,分析url
- 静态文件请求:就直接访问用户给nginx配置的静态文件目录,直接返回用户请求的静态文件
- 动态接口请求:那么nginx就将请求转发给uWSGI,最后到达django处理
模块作用
- nginx: 是对外的服务器,外部浏览器通过url访问nginx,nginx主要处理静态请求
- uWSGI: 是对内的服务器,主要用来处理动态请求
- uwsgi: 是一种web协议,接收到请求之后将包进行处理,处理成wsgi可以接受的格式,并发给wsgi
- wsgi: 是python专用的web协议,根据请求调用应用程序(django)的某个文件,某个文件的某个函数
- django: 是真正干活的,查询数据等资源,把处理的结果再次返回给WSGI, WSGI 将返回值进行打包,打包成uwsgi能够接收的格式
- uWSGI接收WSGI发送的请求,并转发给nginx,nginx最终将返回值返回给浏览器
Django + uwsgi 方案
- 没有nginx而只有uwsgi的服务器,则是Internet请求直接由uwsgi处理,并反馈到web项目中。
- nginx可以实现安全过滤,防DDOS等保护安全的操作,并且如果配置了多台服务器,nginx可以保证服务器的负载相对均衡。
- 而uwsgi则是一个web服务器,实现了WSGI协议(Web Server Gateway Interface),http协议等,它可以接收和处理请求,发出响应等。
- 所以只用uwsgi也是可以的。
DDoS 攻击,全称是 Distributed Denial of Service,翻译成中文就是分布式拒绝服务。一般来说是指攻击者利用“肉鸡”对目标网站在较短的时间内发起大量请求,大规模消耗目标网站的主机资源,让它无法正常服务。在线游戏、互联网金融等领域是 DDoS 攻击的高发行业。
防御DDoS攻击可使用 CDN ( Content Delivery Network ),即内容分发网络。将网站内容分发至全网加速节点,配合智能调度和边缘缓存,使用户可就近获取所需内容,解决网络拥塞问题,提高网站响应速度和可用性,降低源站压力。
nginx和uWSGI特点
nginx的作用
反向代理,可以拦截一些web攻击,保护后端的web服务器
负载均衡,根据轮询算法,分配请求到多节点web服务器
缓存静态资源,加快访问速度,释放web服务器的内存占用,专项专用
uWSGI的作用
单节点服务器的简易部署
轻量级,好部署
nginx和uWSGI 部署顺序缘由
- uWSGI性能比nginx差一些
- nginx还提供反向代理、负载均衡、安全拦截等
Django 服务启动
runserver 启动
- 官方文档解释django自带的server默认是多线程
测试
-
python3 manage.py runserver 0.0.0.0:8000
-
django开两个接口, 第一个接口sleep(20), 另一个接口不做延时处理(大概耗时几毫秒)
先请求第一个接口, 紧接着请求第二个接口, 第二个接口返回数据, 第一个接口20秒之后返回数据
证明django的server是默认多线程
-
关闭多线程
- python3 manage.py runserver 0.0.0.0:8000 --nothreading
uwsgi 启动
-
在django项目目录下 Demo工程名
-
不指定进程线程
uwsgi --http 0.0.0.0:8000 --file Demo/wsgi.py
经过上述的步骤测试, 发现在这种情况下启动django项目, uWSGI也是单线程, 访问接口需要"排队"
不给uWSGI加进程, uWSGI默认是单进程单线程
-
指定进程线程
processes: 进程数 processes 和 workers 一样的效果
threads : 每个进程开的线程数
uwsgi --http 0.0.0.0:8000 --file Demo/wsgi.py --processes 4 --threads 2
经过测试, 接口可以"同时"访问, uWSGI提供多线程
-
Django多线程问题
- Python因为GIL的存在,在一个进程中,只允许一个线程工作,导致单进程多线程无法利用多核
- 多进程的线程之间不存在抢GIL的情况,每个进程有一个自己的线程锁,多进程多GIL
- 单进程多线程的python应用可以实现并发,但是不存在并行
- 多进程的多处理器的python应用可能存在并行,至于并发还是并行,有操作系统决定,如果分配单处理器处理多进程,那就是并发,如果分配给多处理器那就是并行
- Nginx+uWSGI可以实现python高并发
开发生产启动
调试阶段
pyhon manage.py runserver 0.0.0.0:8080
"""
启动django 的配置:
1. settings.py 同级目录下新建 wsgi.py (该配置和manager.py 的配置基本是一样的)
import os
from django.core.wsgi import get_wsgi_application
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "projectName.settings")
application = get_wsgi_application()
2. manager.py 同级目录下创建启动文件 projectName_uwsgi.ini
"""
部署阶段
# 1. 使用uwsgi命令启动django项目
[root@nfs01 django_demo1]# uwsgi --http 0.0.0.0:8080 --file django_demo1/wsgi.py --static-map=/static=static
# 参数详解:
# --http:启动项目的IP地址和端口
# --file:指定Django项目中wsgi文件,一般创建Django项目时自动生成
# --static-map:指定静态资源存放的目录
# 2. 使用uwsgi配置文件启动django项目
[root@nfs01 script]# uwsgi --ini uwsgi.ini
# 查看 uwsgi 启动的 django 服务
[root@nfs01 script]# ps -ef | grep uwsgi | grep -v grep
# 查看监听的 uwsgi ip:端口 状态
[root@nfs01 script]# netstat -tunlp | grep 8080
# 3. 使用uwsgi配置文件管理django项目的其它命令
# 重载django项目
[root@nfs01 script]# uwsgi --reload uwsgi.ini
# 停止django项目
[root@nfs01 script]# uwsgi --stop uwsgi.pid
# 4. 将django服务加入开机自启动
[root@nfs01 script]# echo "uwsgi --ini /data/www/script/uwsgi.ini" >>/etc/rc.local
uwsgi 命令
# 运行 uWSGI 来启动一个会把请求传递给你的 WSGI 应用的 HTTP 服务器/路由器
uwsgi --http localhost:9090 --wsgi-file foobar.py
# 配置并发(uWSGI 默认启动一个单独的进程和一个单独的线程)
"""
通过 --processes 选项或者 --threads (或者两个选项都使用)来增加更多的进程或者线程
这将会产生 4 个进程(每个进程 2 个线程),一个主进程(当你的进程死掉时会重新 spawn 一个新的)以及 HTTP 路由器
"""
uwsgi --http localhost:9090 --wsgi-file foobar.py --master --processes 4 --threads 2
# 监控 stats 子系统允许用 JSON 输出 uWSGI 的内部数据
"""
向你的应用发送几个请求然后 telnet 到 9191 端口,将得到大量的信息
你可能想要使用 “uwsgitop” (使用pipinstall你就能得到它),这是一个类似 top 的工具,用于监控应用实例
"""
uwsgi --http localhost:9090 --wsgi-file foobar.py --master --processes 4 --threads 2 --stats 127.0.0.1:9191
结论
-
使用 execute_from_command_line 方式启动django应用时, 会先加载urls, 从而会加载我们写的业务代码(views中的代码); 然后再加载中间件代码
在应用启动完成时, 所有相关代码都已经被加载入内存
-
使用 get_wsgi_application 方式启动django应用时, 会先加载中间件代码, 这与1中的是完全相反的。 此时, 我们的业务代码仍然没有被加载
直到第一个请求过来。 如果我们在代码中, 使用了未加载的代码中的全局变量, 就会出现莫名其妙的bug
配置 uwsgi.ini
# 在/data/www/目录中创建script目录用于存放uwsgi的配置文件及相关启动文件
[root@nfs01 django_demo1]# cd /data/www/
[root@nfs01 www]# mkdir -p script
[root@nfs01 www]# cd script/
[root@nfs01 script]# cat uwsgi.ini
----------------------------------------------------------------------
[uwsgi]
# 指定django项目的目录
chdir=/data/www/django_demo1
# 指定django项目的应用程序 /data/www/django_demo1/django_demo1/wsgi.py
module=django_demo1.wsgi:application
# 指定django项目的socket文件路径,用于和其它程序进行通信
socket=/data/www/script/uwsgi.sock
# 指定django项目的进程个数,根据cpu的核数来指定
workers=1
# 指定django项目的后台进程pid文件路径,用于标识当前django项目所处的状态
pidfile=/data/www/script/uwsgi.pid
# 指定django项目的ip地址和端口号
http=0.0.0.0:8080
# 指定django项目的静态文件目录
static-map=/static=/data/www/django_demo1/static
# 指定启动django项目的用户名和用户组
uid=root
gid=root
# django项目启用主进程
master=true
# 当django项目服务停止的时候自动移除相应的 socket 文件和 pid 文件
vacuum=true
# django项目序列化接受的内容
thunder-lock=true
# django项目启用线程
enable-threads=true
# django项目自动中断时间,单位是秒(s)
harakiri=30
# django项目设置的缓冲
post-buffering=4096
# django项目的日志文件路径
daemonize=/data/www/script/uwsgi.log
----------------------------------------------------------------------
生产环境部署
centos 7安装python3环境
# 1、yum更新yum源
yum update
# 2、安装Python 3.7所需的依赖否则安装后没有pip3包
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel gcc make
# 3、在官网下载所需版本,这里用的是3.7.0版本
wget https://www.python.org/ftp/3.7.0/Python-3.7.0.tgz
# 4、解压
tar -xvf Python-3.7.0.tgz
# 5、配置编译
cd Python-3.7.0
./configure --prefix=/usr/local/python3 # 配置编译的的路径(这里--prefix是指定编译安装的文件夹)
./configure --enable-optimizations # 执行该代码后,会编译安装到 /usr/local/bin/ 下,且不用添加软连接或环境变量
make && make install
ln -s /usr/local/python3/bin/python3 /usr/bin/python3 # 添加软连接
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
# 6、将/usr/local/python3/bin加入PATH
[root@linux-node1 testProj]# vim /etc/profile
#然后在文件末尾添加
export PATH=$PATH:/usr/local/python3/bin
[root@linux-node1 testProj]# source /etc/profile # 修改完后,还需要让这个环境变量在配置信息中生效,执行命令
初始化Django项目
[root@linux-node1 /]# pip3 install django==2.0.4
[root@linux-node1 /]# mkdir /code/
[root@linux-node1 /]# cd /code/
[root@linux-node1 testProj]# django-admin startproject mmcsite
[root@linux-node1 testProj]# cd /code/mmcsite
[root@linux-node1 testProj]# python3 manage.py runserver 0.0.0.0:8000
# 页面中访问:http://192.168.56.11:8000/
安装uwsgi并用uWSGI启动服务
# 1. 安装uwsgi
[root@linux-node1 /]# pip3 install uwsgi
[root@linux-node1 /]# ln -s /usr/local/python3/bin/uwsgi /usr/bin/uwsgi
# 2. 配置uwsgi.ini启动文件
[root@linux-node1 /]# vim uwsgi.ini
----------------------------------------------------------------------
[uwsgi]
socket = 0.0.0.0:3031 # 指定socket监听的地址和端口
chdir = /code/mmcsite # 项目路径
wsgi-file = /code/mmcsite/wsgi.py # django的wsgi文件路径
processes = 5 # 启动五个进程
threads = 30 # 每个进程启动30个线程
master = true
daemonize = /code/mmcsite/uwsgi.log # 日志存放路径
module=mmcsite.wsgi # 使用mmcsite.wsgi模块
pidfile = /code/mmcsite/uwsgi.pid # uwsgi启动进程id存放路径
chmod-socket=666 # socket权限
enable-threads = true # 允许用内嵌的语言启动线程,这将允许你在app程序中产生一个子线程
----------------------------------------------------------------------
[root@linux-node2 demo2]# vim /code/mmcsite/uwsgi.ini
----------------------------------------------------------------------
[uwsgi]
socket = 0.0.0.0:3031
chdir = /code/mmcsite
wsgi-file = /code/mmcsite/wsgi.py
processes = 5
threads = 30
master = true
daemonize = /code/mmcsite/uwsgi.log
module=mmcsite.wsgi
pidfile = /code/mmcsite/uwsgi.pid
chmod-socket=666
enable-threads = true
----------------------------------------------------------------------
# 3. 使用uwsgi启动django:一定要在这个项目目录中
"""
# 使用uwsgi命令行启动Django项目,端口8000
$ uwsgi --http :8000 --module myproject.wsgi
"""
[root@linux-node1 /]# uwsgi --http 192.168.56.11:80 --file mmcsite/wsgi.py --static-map=/static=static
# 4. 访问项目
http://192.168.56.11
安装Nginx
'''配置nginx YUM源'''
[root@linux-node1 /] vim /etc/yum.repos.d/nginx.repo
----------------------------------------------------------------------
[nginx]
name=nginx repo
# 下面这行centos根据你自己的操作系统修改比如:OS/rehel
# 7是你Linux系统的版本,可以通过URL查看路径是否正确
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
enabled=1
----------------------------------------------------------------------
'''2. 安装nginx'''
[root@linux-node1 /] yum -y install nginx
配置Nginx
'''配置Nginx'''
# 清理注释的配置
[root@nfs01 application]# sed -ri.bak "/#|^$/d" nginx/conf/nginx.conf
# 创建nginx的配置文件目录
[root@nfs01 application]# mkdir nginx/conf/conf.d/ -p
# 修改配置文件
# 1. 主配置文件
[root@nfs01 application]# vim nginx/conf/nginx.conf
----------------------------------------------------------------------
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
include conf.d/*.conf;
}
----------------------------------------------------------------------
# 2. 包含配置文件
[root@nfs01 application]# cat nginx/conf/conf.d/uwsgi.conf
----------------------------------------------------------------------
server{
listen 80; # 监听那个端口
server_name www.cnblogs.com/0.0.0.0; # 访问的路径前面的url名称/ip地址
pid /var/run/nginx.pid; # 进程文件
access_log logs/uwsgi_access.log; # Nginx日志配置
error_log logs/uwsgi_error.log; # 错误日志定义等级,[ debug | info | notice | warn | error | crit ]
charset utf-8; # Nginx编码
gzip on; # 开启支持压缩
gzip_types text/plain application/x-javascript text/css text/javascript application/x-httpd-php application/json text/json image/jpeg image/gif image/png application/octet-stream; # 支持压缩的类型
# 项目路径 (location 类似 Django 的url(r'^admin/', admin.site.urls) )
location / {
include uwsgi_params; # 导入一个uwsgi模块,它是用来和uwsgi进行通讯的
uwsgi_connect_timeout 30; # 设置连接uWSGI超时时间
uwsgi_pass unix:/data/www/script/uwsgi.sock; # uwsgi的socket文件所在路径,客户端所有的动态请求都会直接传给它
"uwsgi_pass 0.0.0.0:3031; # 必须和uwsgi中的设置一致"
uwsgi_param UWSGI_SCRIPT demosite.wsgi; # 入口文件,即wsgi.py相对于项目根目录的位置,“.”相当于一层目录
uwsgi_param UWSGI_CHDIR /demosite; # 项目根目录
}
# 静态文件路径
location /static/ {
alias /data/www/django_demo1/static/;
# 注意这里的静态文件目录后面必须要加左斜杠,否则会找不到静态资源。
index index.html index.htm;
}
# 错误页面配置
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
----------------------------------------------------------------------
Nginx 命令
# 启动Nginx服务器命令
cd /usr/local/nginx/sbin
./nginx
# 查看Nginx 版本号命令
nginx -v # 显示版本信息并退出
nginx -V # 显示版本和配置选项信息,然后退出
# 查看Nginx进程命令
ps aux|grep nginx
# 检测配置文件是否有语法错误,然后退出
./nginx -t
# 检测配置文件是否有语法错误,转储并退出
./nginx -T
# 在检测配置文件期间屏蔽非错误信息
./nginx -q
#设置前缀路径 (默认是:/usr/share/nginx/)
./nginx -p prefix
# 指定检测特定Nginx配置文件:-c表示configuration,指定配置文件
./nginx -t -c /usr/local/nginx/conf/nginx.conf
# Nginx服务器指定启动配置文件命令
./nginx -c /usr/local/nginx/conf/nginx.conf
# 设置配置文件外的全局指令
./nginx -g directives
# 强制停止Nginx服务器命令
./nginx -s stop
# 优雅停止Nginx服务器命令(即处理完所有请求后再停止服务)
./nginx -s quit
# 重新加载Nginx配置文件,然后以优雅的方式重启Nginx
./nginx -s reload
# Nginx重新生成新的空的日志文件
"""
1. 当nginx正在运行期间,如果我们改了日志文件的名字或路径,日志照样会写到该文件。原因在于linux系统中,内核是根据文件描述符来找文件的
2. nginx -s reopen的作用:
当nginx默认的日志文件没有的时候(如1,被人挪走或改了名字),该命令会重新创建一个默认的nginx日志文件,后续日志会写的刚创建的默认日志路径中。
因此当nginx默认的日志文件存在的时候,该命令没有起做用
正确备份日志的步骤
步骤1:备份日志文件 mv access.log access.log-时间戳
步骤2:nginx -s reopen #重新生成新的空的日志文件
步骤3:删除超出保留时间的旧日志
"""
nginx -s reopen
# 显示Nginx帮助信息
./nginx -?,-h
# Nginx通过master发送信号的相关命令
"""
若在 nginx.conf 配置了 pid 文件存放路径则该文件存放的就是 Nginx 主进程号,如果没指定则放在 Nginx 的 logs 目录下
有 pid 文件,不用先查询Nginx的主进程号,直接向Nginx发送信号
"""
kill -信号类型 '/usr/nginx/logs/nginx.pid'
# 杀死所有nginx进程
killall nginx
# 从容停止Nginx服务器命令: kill -QUIT 主进程号
# 快速停止Nginx服务器命令: kill -TERM 主进程号
# 强制停止Nginx服务器命令: pkill -9 nginx
Nginx设置systemctl
# 创建nginx.service服务
"""
1. 在/usr/lib/systemd/system目录下创建nginx.service文件(服务文件)
2. 停止原来的Nginx,使用systemctl命令对其进行管理
"""
[root@web01 ~]# vim /usr/lib/systemd/system/nginx.service
[Unit]
Description=nginx
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
ExecReload=/usr/local/nginx/sbin/nginx -s reload
ExecStop=/usr/local/nginx/sbin/nginx -s quit
PrivateTmp=true
[Install]
WantedBy=multi-user.target
"""
注:
[Unit] : 服务的说明
Description: 描述服务
After : 描述服务类别
[Service] : 服务运行参数的设置
Type=forking 是后台运行的形式
ExecStart 为服务的具体运行命令
ExecReload 为重启命令
ExecStop 为停止命令第三步:停止原来的Nginx,使用systemctl命令对其进行管理
PrivateTmp=True 表示给服务分配独立的临时空间
注意:
[Service]的启动、重启、停止命令全部要求使用绝对路径
[Install]运行级别下服务安装的相关设置,可设置为多用户,即系统运行级别为3
"""
[root@web01 ~]# /usr/local/nginx/sbin/nginx -s stop => 一定不要使用systemctl停止Nginx,失效
[root@web01 ~]# systemctl start|reload|stop nginx 启动 | 重载 | 停止 nginx
[root@web01 ~]# systemctl enable|disable nginx 开机启动 | 不启动 nginx
验证Nginx配置文件
[root@nfs01 application]# nginx/sbin/nginx -t
# 重启nginx服务
[root@nfs01 application]# nginx/sbin/nginx -s reload
# 将nginx服务加入到开机自启动
[root@nfs01 application]# echo "/application/nginx/sbin/nginx" >>/etc/rc.local
启动项目
# 1. 正常启动nginx
[root@nfs01 nginx-1.16.0]# cd /application/
[root@nfs01 application]# nginx/sbin/nginx
[root@nfs01 application]# netstat -tunlp | grep 80
# 2. 配置 systemctl 启动 nginx
[root@linux-node1 demo2]# systemctl restart nginx
# 启动uwsgi的django项目
[root@linux-node1 demo2]# uwsgi --ini uwsgi.ini
# 访问项目
# http://192.168.56.11:8888/
# 关闭uwsgi
[root@linux-node1 demo2]# uwsgi --stop uwsgi.pid
uwsgi.ini 启动服务
在生产环境中我们通常不会使用命令行启动Python Web项目,而是通常编辑好uWSGI配置文件uwsgi.ini, 然后使用如下命令启动Python Web项目。
# 使用uwsgi.ini配置文件启动Django应用程序
$ uwsgi --ini uwsgi.ini
# 重启uWSGI服务器
$ sudo service uwsgi restart
# 查看所有uWSGI进程
$ ps aux | grep uwsgi
# 停止所有uWSGI进程
$ sudo pkill -f uwsgi -9
uwsgi常用配置
uwsgi 常用配置选项如下所示,稍加修改(项目名,项目根目录)即可部署大部分Python Web项目。
[uwsgi]
uid=www-data # Ubuntu系统下默认用户名
gid=www-data # Ubuntu系统下默认用户组
project=mysite1 # 项目名
base = /home/user1 # 项目根目录
home = %(base)/Env/%(project) # 设置项目虚拟环境,Docker部署时不需要
chdir=%(base)/%(project) # 设置工作目录
module=%(project).wsgi:application # wsgi文件位置
master=True # 主进程
processes=2 # 同时进行的进程数,一般
# 以下uwsgi与nginx通信手段3选一即可
# 选项1, 使用unix socket与nginx通信,仅限于uwsgi和nginx在同一主机上情形
# Nginx配置中uwsgi_pass应指向同一socket文件
socket=/run/uwsgi/%(project).sock
# 选项2,使用TCP socket与nginx通信
# Nginx配置中uwsgi_pass应指向uWSGI服务器IP和端口
# socket=0.0.0.0:8000 或则 socket=:8000
# 选项3,使用http协议与nginx通信
# Nginx配置中proxy_pass应指向uWSGI服务器一IP和端口
# http=0.0.0.0:8000
# socket权限设置
chown-socket=%(uid):www-data
chmod-socket=664
# 进程文件
pidfile=/tmp/%(project)-master.pid
# 以后台守护进程运行,并将log日志存于temp文件夹。
daemonize=/var/log/uwsgi/%(project).log
# 服务停止时,自动移除unix socket和pid文件
vacuum=True
# 为每个工作进程设置请求数的上限。当处理的请求总数超过这个量,进程回收重启。
max-requests=5000
# 当一个请求花费的时间超过这个时间,那么这个请求都会被丢弃。
harakiri=60
#当一个请求被harakiri杀掉会输出一条日志
harakiri-verbose=true
# uWsgi默认的buffersize为4096,如果请求数据超过这个量会报错。这里设置为64k
buffer-size=65536
# 如果http请求体的大小超过指定的限制,打开http body缓冲,这里为64k
post-buffering=65536
#开启内存使用情况报告
memory-report=true
#设置平滑的重启(直到处理完接收到的请求)的长等待时间(秒)
reload-mercy=10
#设置工作进程使用虚拟内存超过多少MB就回收重启
reload-on-as=1024
注意:uWSGI和Nginx之间有3种通信方式, unix socket,TCP socket和http。Nginx的配置必须与uwsgi配置保持一致。
# 选项1, 使用unix socket与nginx通信
# 仅限于uwsgi和nginx在同一主机上情形
# Nginx配置中uwsgi_pass应指向同一socket文件地址
socket=/run/uwsgi/%(project).sock
# 选项2,使用TCP socket与nginx通信
# Nginx配置中uwsgi_pass应指向uWSGI服务器IP和端口
socket==0.0.0.0:8000 或则 socket=:8000
# 选项3,使用http协议与nginx通信
# Nginx配置中proxy_pass应指向uWSGI服务器IP和端口
http==0.0.0.0:8000
如果你的nginx与uwsgi在同一台服务器上,优先使用本地机器的unix socket进行通信,这样速度更快。此时nginx的配置文件如下所示:
location / {
include /etc/nginx/uwsgi_p


















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











