










前言:
1.基础的环境介绍请移步ShardingSphere应用专题–4.1.1版本–sharding jdbc环境搭建(四)
你可以同时打开两个页面,避免因查找原始配置上下翻动。
2.ShardingSphere官方文档更新不及时,很容易踩坑。贴出的4.x版本文档实际是4.0.1版本的,如果你准备使用该版本可以参考官方文档。本文使用的是此时最新的正式版本4.1.1版本,配置与官方文档配置不同。事实上,源码中有非常详细的版本配置文档,本文也是参考4.1.1 tag的源码配置。
3.ShardingSphere各版本差异很大,甚至核心依赖的包名都不一样,使用时,一定要确认使用哪个版本,目前调研的结果:3.x、4.0.1、4.1.1、5.0.0-alpha都存在很大的配置差异
1.基础概念
(1)逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
(2)真实表
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
(3)数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
(4)绑定表
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。
所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
(5) 广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
2.逻辑引擎
【解析引擎】SQL解析
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
执行器优化
合并和优化分片条件,如OR等。
【路由引擎】SQL路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
【改写引擎】SQL改写
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
【执行引擎】SQL执行
通过多线程执行器异步执行。
【归并引擎】结果归并
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
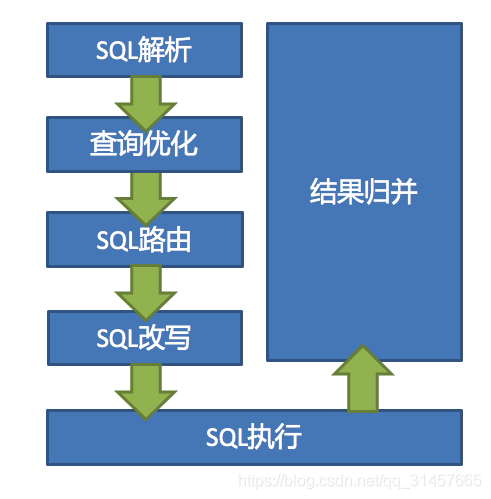
篇幅需要,引入概念,细节请参阅官方文档:内部剖析
3.分布式主键
(1)主键有什么要求
必须保证不能重复。尽量单调,尽量简单,生成成本低。
(2)分布式主键问题怎么产生的
当我们在使用单个数据库的时候,数据库的表提供了在表级别的唯一主键。以mysql为例:
当向表中添加数据时,自增主键会唯一的分配一个自增的id,且不会重复。但是一旦使用分库分表技术,这个范围就脱离了单一表的范畴,表级别的自增主键也就无法使用了。必须使用其他方式生成主键
4.分库分表代码实现
(1)创建分库分表表结构
/*分库分表*/
DROP TABLE IF EXISTS `mydb0`.`bill_0`;
CREATE TABLE `mydb0`.`bill_0`
(
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`bill_name` varchar(255) NOT NULL DEFAULT '' COMMENT '账单名称',
`bill_amount` int unsigned NOT NULL DEFAULT '0' COMMENT '账单金额',
`create_time` datetime(3) NOT NULL COMMENT '创建时间',
`is_delete` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '是否删除 0:未删除 1:已删除',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
DROP TABLE IF EXISTS `mydb0`.`bill_1`;
CREATE TABLE `mydb0`.`bill_1`
(
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`bill_name` varchar(255) NOT NULL DEFAULT '' COMMENT '账单名称',
`bill_amount` int unsigned NOT NULL DEFAULT '0' COMMENT '账单金额',
`create_time` datetime(3) NOT NULL COMMENT '创建时间',
`is_delete` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '是否删除 0:未删除 1:已删除',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
DROP TABLE IF EXISTS `mydb0`.`bill_item`;
CREATE TABLE `mydb0`.`bill_item`
(
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`bill_id` bigint unsigned NOT NULL DEFAULT 0 COMMENT '账单id',
`bill_item_name` varchar(255) NOT NULL DEFAULT '' COMMENT '子账单名称',
`bill_item_amount` int unsigned NOT NULL DEFAULT '0' COMMENT '账单金额',
`create_time` datetime(3) NOT NULL COMMENT '创建时间',
`is_delete` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '是否删除 0:未删除 1:已删除',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
DROP TABLE IF EXISTS `mydb1`.`bill_0`;
CREATE TABLE `mydb1`.`bill_0`
(
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`bill_name` varchar(255) NOT NULL DEFAULT '' COMMENT '账单名称',
`bill_amount` int unsigned NOT NULL DEFAULT '0' COMMENT '账单金额',
`create_time` datetime(3) NOT NULL COMMENT '创建时间',
`is_delete` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '是否删除 0:未删除 1:已删除',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
DROP TABLE IF EXISTS `mydb1`.`bill_1`;
CREATE TABLE `mydb1`.`bill_1`
(
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`bill_name` varchar(255) NOT NULL DEFAULT '' COMMENT '账单名称',
`bill_amount` int unsigned NOT NULL DEFAULT '0' COMMENT '账单金额',
`create_time` datetime(3) NOT NULL COMMENT '创建时间',
`is_delete` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '是否删除 0:未删除 1:已删除',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
DROP TABLE IF EXISTS `mydb1`.`bill_item`;
CREATE TABLE `mydb1`.`bill_item`
(
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`bill_id` bigint unsigned NOT NULL DEFAULT 0 COMMENT '账单id',
`bill_item_name` varchar(255) NOT NULL DEFAULT '' COMMENT '子账单名称',
`bill_item_amount` int unsigned NOT NULL DEFAULT '0' COMMENT '账单金额',
`create_time` datetime(3) NOT NULL COMMENT '创建时间',
`is_delete` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '是否删除 0:未删除 1:已删除',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
(2)pom添加ShardingSphere依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
(3)添加分库分表环境配置application-sharding-sub-tb.properties
#打印sql
spring.shardingsphere.props.sql.show=true
#设置单次请求可适用的最大线程数,以决定是线程限制还是内存限制。增大该参数可提高数据库元数据加载速度(默认为1)
spring.shardingsphere.props.max.connections.size.per.query=3
#当使用inline分表策略时,是否允许范围查询,默认值: false
spring.shardingsphere.props.allow.range.query.with.inline.sharding=true
spring.shardingsphere.datasource.names=db0,db1
spring.shardingsphere.datasource.db0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.jdbc-url=jdbc:mysql://localhost:4406/mydb0?characterEncoding=utf-8
spring.shardingsphere.datasource.db0.username=root
spring.shardingsphere.datasource.db0.password=111
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.jdbc-url=jdbc:mysql://localhost:4406/mydb1?characterEncoding=utf-8
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=111
#2.设置为广播表,每个数据库都存在一份相同的数据,插入的时候每个库都插入,相对于1中的方式,插入的时候涉及分布式事务,执行逻辑复杂,但是毕竟rw比是很高的,这部分问题不大,另外一个好处是,运维层面简单。支持join(不跨库)
spring.shardingsphere.sharding.broadcast-tables=bill_item
#根据amount分库
spring.shardingsphere.sharding.tables.bill.database-strategy.inline.sharding-column= bill_amount
spring.shardingsphere.sharding.tables.bill.database-strategy.inline.algorithm-expression=db$->{bill_amount % 2}
#根据id分表
spring.shardingsphere.sharding.tables.bill.actual-data-nodes=db$->{0..1}.bill_$->{0..1}
spring.shardingsphere.sharding.tables.bill.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.bill.table-strategy.inline.algorithm-expression=bill_$->{id % 2}
spring.shardingsphere.sharding.tables.bill.key-generator.column=id
spring.shardingsphere.sharding.tables.bill.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.bill.key-generator.props.worker.id=123
(4)配置说明
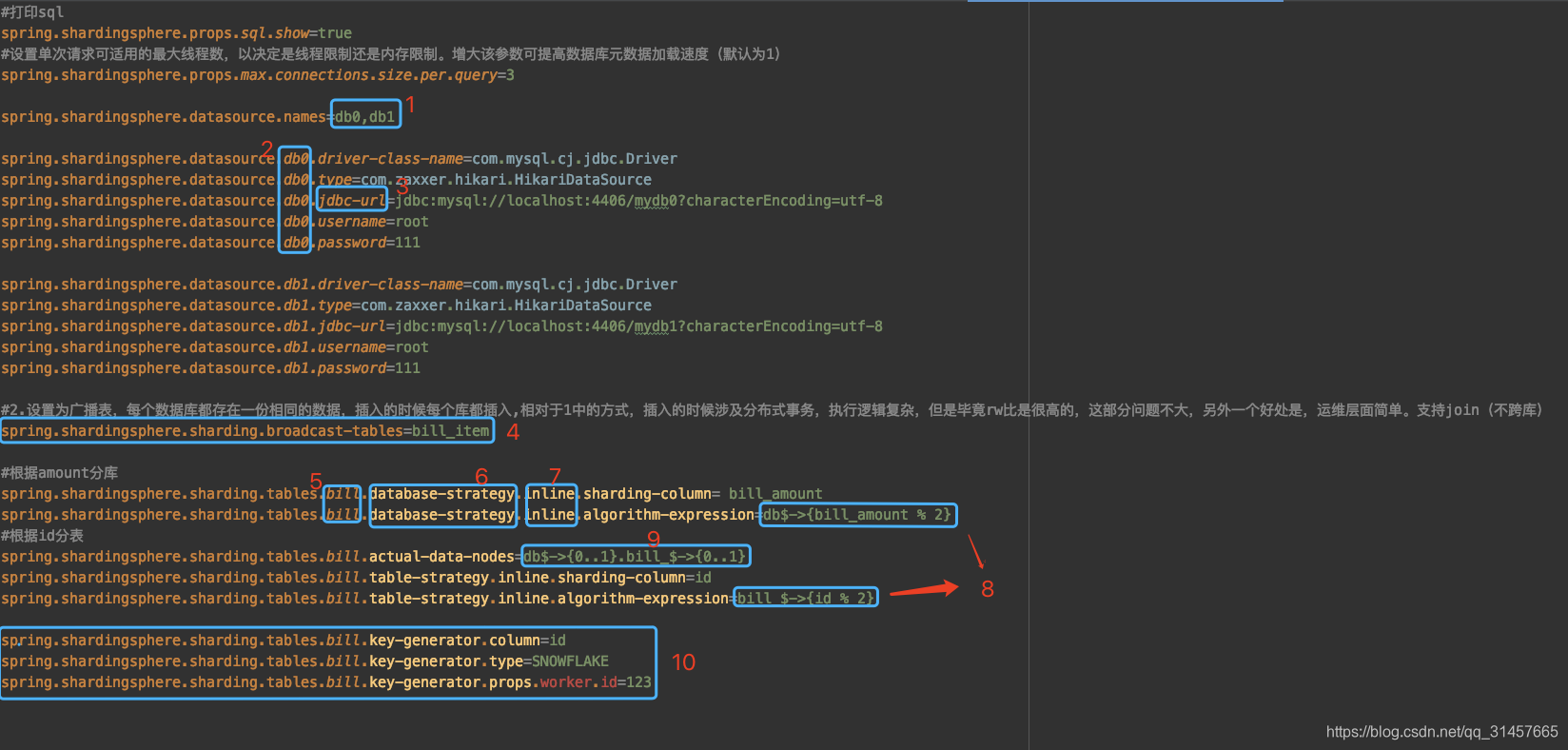
1.spring.shardingsphere.datasource.names 这里的数据源名称是自定义的
2.在配置数据源的基本属性时,标注的位置必须是1中定义的
3.本文选的连接池是HikariDataSource,如果使用的是druid,这里的配置就不是jdbc-url,而是url。且不同数据库连接池,对应的starter的兼容度可能不一样,需要自己调试。springboot官方推荐使用Hikari
4.配置了bill_item为广播表,则每个数据库中都有一个bill_item
5.【逻辑表】的名称
6.定义了分表策略还是分库策略
7.inline表明使用的分片策略为【行表达式】,其他可选分片策略,standard,complex,hint。分片策略不同,对应的配置也存在差异,具体内容见详细示例
8.分片算法行表达式,其中参与计算的为真实的列的名称
9.行表达式定义的数据节点,这里的数据节点即:db0,.bill_0、db0,.bill_1、db1.bill_0、db1.bill_1四个个表节点,。行表达式标识符可以使用${...}或$->{...},但前者与Spring本身的属性文件占位符冲突,因此在Spring环境中使用行表达式标识符建议使用$->{...}。
10.分布式主键策略。主键字段为id,主键类型使用雪花算法,props针对不同的算法需要的参数不同,进行自定义配置,具体见分布式主键部分,内置的还可以选择UUID作为主键生成策略
4.代码测试
按照以上的配置,按照bill_amount进行分库,双数进入db0、单数进入db1
按照id进行分库,双数进入bill_0、单数进入bill_1
(1)插入
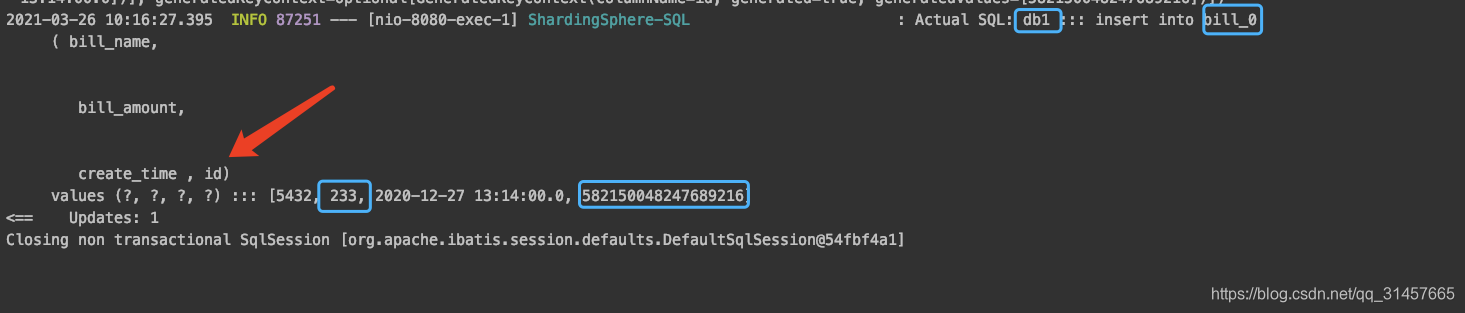
插入的sql是没有指定id的
<insert id="insertSelective" keyColumn="id" keyProperty="id" parameterType="com.example.sharding.entry.BillModel" useGeneratedKeys="true">
<!--@mbg.generated-->
insert into bill
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="billName != null and billName != ''">
bill_name,
</if>
<if test="billAmount != null">
bill_amount,
</if>
<if test="createTime != null">
create_time,
</if>
<if test="isDelete != null">
is_delete,
</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="billName != null and billName != ''">
#{billName,jdbcType=VARCHAR},
</if>
<if test="billAmount != null">
#{billAmount,jdbcType=INTEGER},
</if>
<if test="createTime != null">
#{createTime,jdbcType=TIMESTAMP},
</if>
<if test="isDelete != null">
#{isDelete,jdbcType=TINYINT},
</if>
</trim>
</insert>
-
Log中的id是ShardingSphere的【改写引擎】加入的,在执行INSERT的SQL语句时,如果使用数据库自增主键,是无需写入主键字段的。 但数据库的自增主键是无法满足分布式场景下的主键唯一的,因此ShardingSphere提供了分布式自增主键的生成策略,并且通过补列,让使用方无需改动现有代码,即可将分布式自增主键透明的替换数据库现有的自增主键
-
id为双数,bill_amount为单数,最终进入db1.bill_0
(2)查询
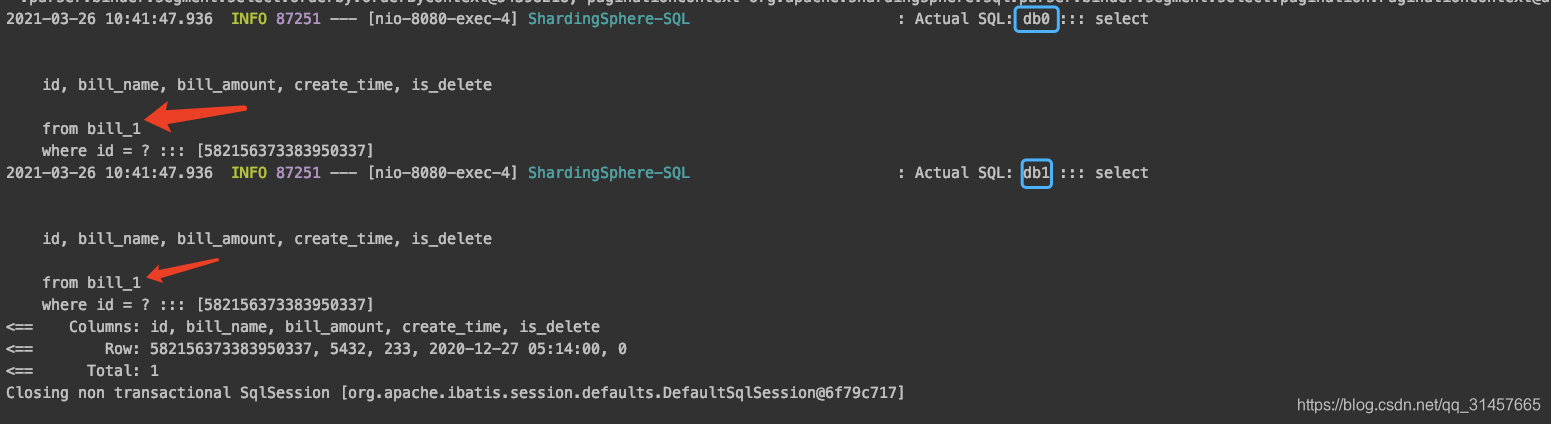
当使用了id作为查询条件时。Sharding-JDBC的【路由引擎】识别到当前的查询条件包含分片键(id和bill_amount都是分片键)。就会按照分片规则直接确定路由的表和库,这里给的查询条件是id,且id是单数,所以可以确定数据一定在bill_1中,由于没有给bill_amount,无法确定在那个库中,所以两个库都查了一遍。最后由【归并引擎】将结果归并。同理如果使用bill_amount查询则路由节点dbx.bill_0,dbx.bill_1
(3) 聚合查询

- 由于查询条件只有limit,这里【路由引擎】会选择【全库全表路由】,业务许可的情况,查询条件使用分片键,性能将得到提升(网络io及线程开销方面)
【归并引擎】聚合函数归并原理:
- 比较类型的聚合函数是指MAX和MIN。它们需要对每一个同组的结果集数据进行比较,并且直接返回其最大或最小值即可
- 累加类型的聚合函数是指SUM和COUNT。它们需要将每一个同组的结果集数据进行累加
- 求平均值的聚合函数只有AVG。它必须通过SQL改写的SUM和COUNT进行计算
(4) 批量插入
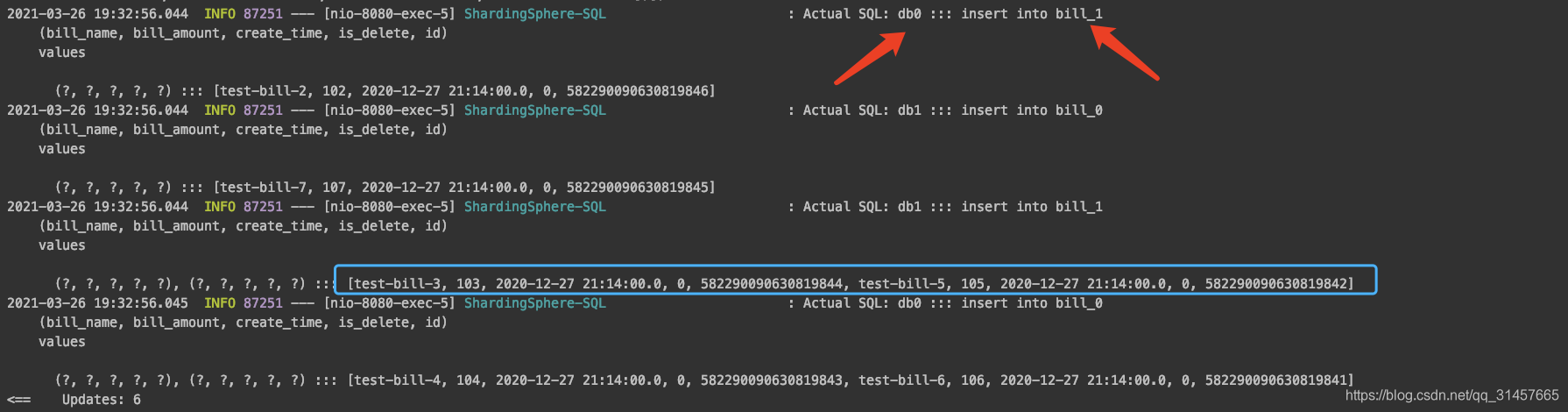
- 插入的数据存在分片键id及bill_amout,【路由引擎】会选择【标准路由】,将对应的数据确定进入具体的那个【数据节点】
- 【改写引擎】将使用【批量拆分】方式,将不同路由的sql拆分。改写成与精准的【数据节点】对应的sql
- 【改写引擎】中的【批量拆分】同样作用在使用in语句的sql,与批量inser不同的是,即使不精准对应【数据节点】,也不会出现逻辑错误,目前Sharding-JDBC对于in语句的sql精准匹配的策略暂未实现
补:很明显,上面的路由规程错误了,这是4.1.1的bug,具体bug详情参考:ShardingSphere应用专题–4.1.1版本–Sharding-JDBC应用注意点(八)—批量插入的bug源码分析
SELECT * FROM bill WHERE id IN (1, 2, 3);
(5) 分页查询
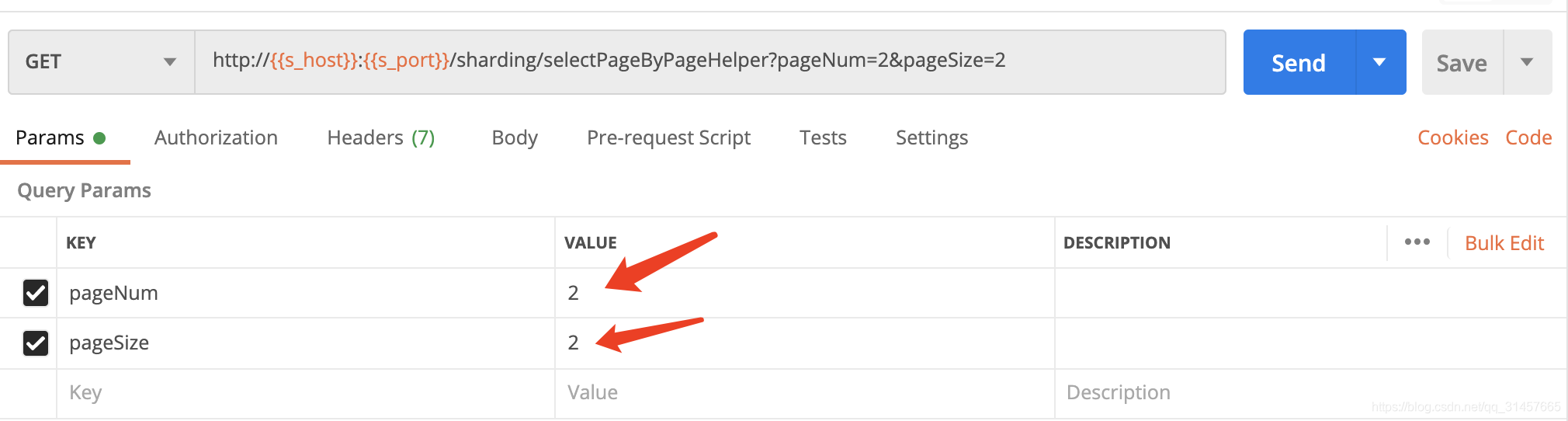
count查询

数据查询
-
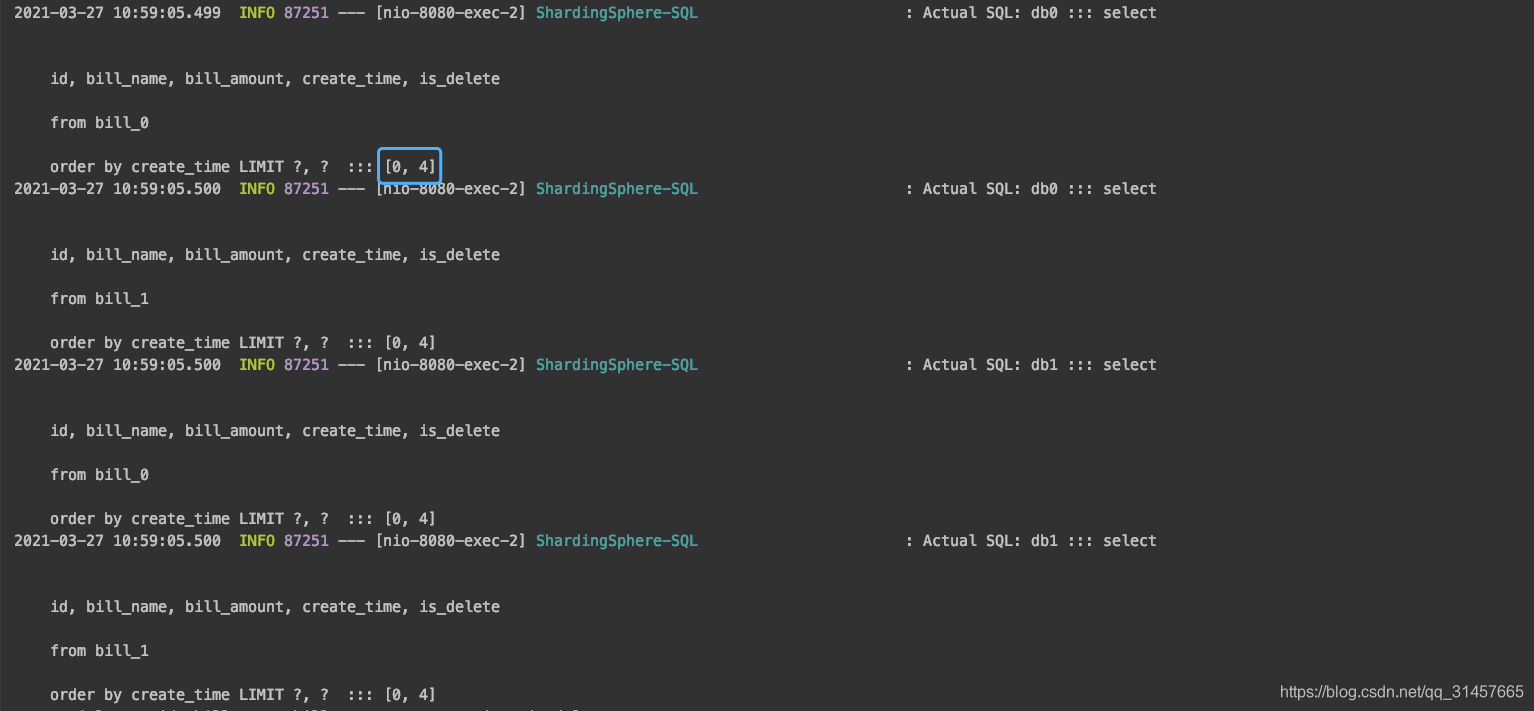
这里没有使用任何的查询条件,【路由引擎】会选择【全库全表路由】,将会从所有的【数据节点】中取数据,当前场景就是4个
-
简单单表场景下limit a,b ,在分库分表场景下,如果不更改这个范围,无论怎么处理得出的结果都不可能正确
使用官方的例子,比如有sql
SELECT score FROM t_score ORDER BY score DESC LIMIT 1, 2;
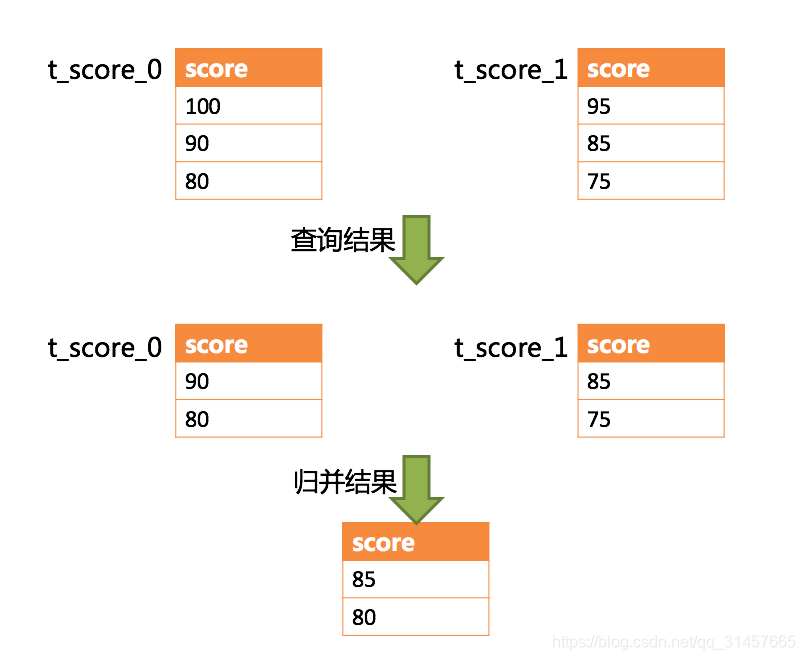
事实上:对于limit a,b ,在分库分表场景中,使用极值法,很容知道查询的数据覆盖范围是limit 0,a+b
本次a=2,b=2,所以【改写引擎】将路由的每个sql的修改成了 limit 0,4
-
将 LIMIT 10000000, 10 改写为 LIMIT 0, 10000010,才能保证其数据的正确性。 用户非常容易产生 ShardingSphere 会将大量无意义的数据加载至内存中,造成内存溢出风险的错觉。 事实上:ShardingSphere 会通过结果集的 next 方法将无需取出的数据全部跳过,并不会将其存入内存,这种在多个流上进行归并的操作称为【流式归并】,由【执行引擎】决定,并由【归并引擎】做具体数据归并操作。【流式归并】对应的策略为【内存归并】。归并策略的选择依赖maxConnectionSizePerQuery的配置,当单个库的线程数>=该库中执行的执行的条数,则优先使用【流式归并】
-
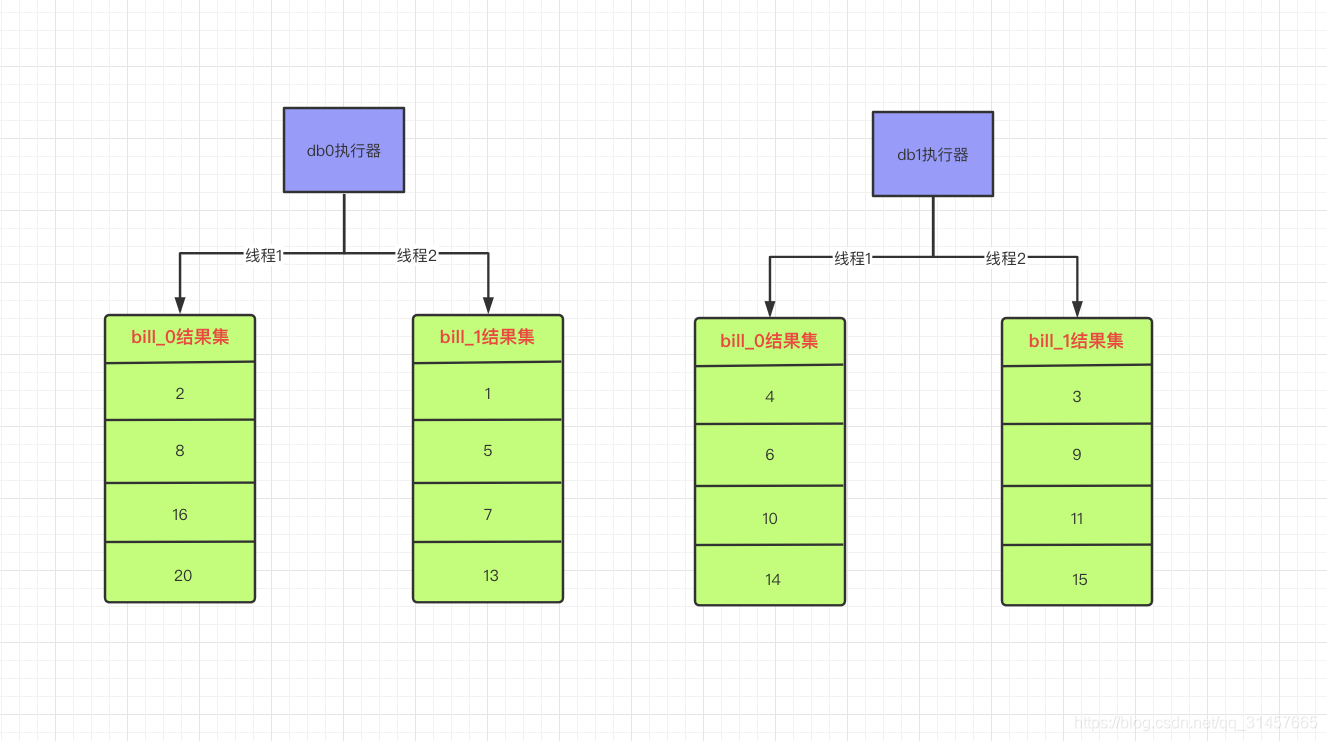
以本次分页查询为例,【执行引擎】图示:
-
【流式归并】图示
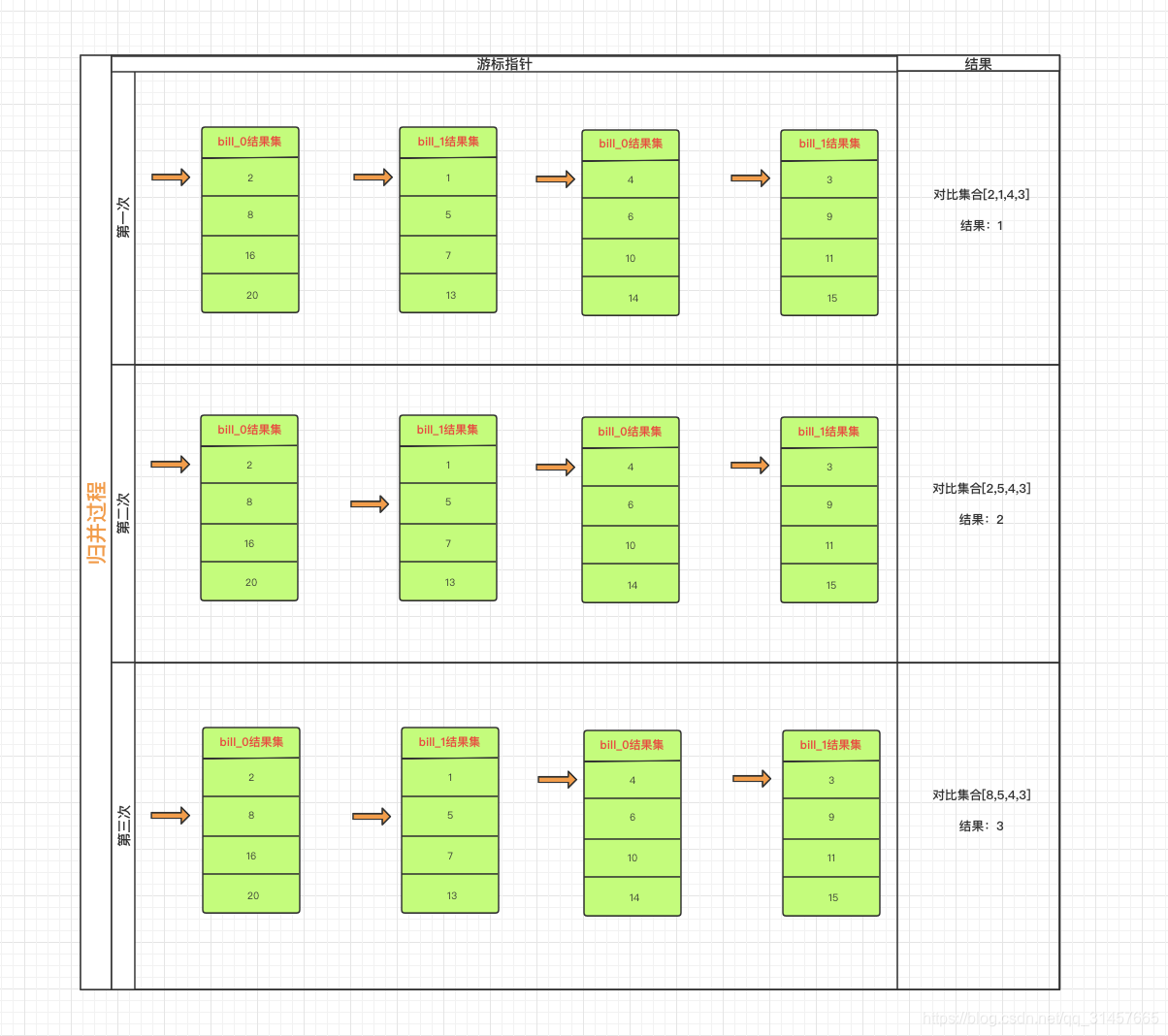
【归并引擎】只持有结果集的流,并不会直接将结果集数据加载到内存,通过移动游标的方式,按照id asc排序规则,取出MIN(id)(如果是id desc 则取出MAX(id)),当集合数量为N,每次仅对比N个数据。产生的结果就是合集数据的有序排列。当limit N,M时,只要对比N次,即到达需要的数据区间了,取接下来的M个数据即为分页需要的集合了 -
由于排序的需要,大量的数据仍然需要占用带宽。采用 LIMIT a,b这种方式分页,本身mysql层面就存在性能问题,并非最佳实践。 至于最佳实践可以参考业界难题-“跨库分页”的四种方案,这里就不展开说了。
(6) 分组查询
-
分页流程已经阐述了归并引擎的底层逻辑,分组相关逻辑底层同样使用了【流式归并】,这里就不自己写例子了,具体参考官方文档:归并引擎-分组归并
-
流式分组归并和内存分组归并。 流式分组归并要求SQL的排序项与分组项的字段以及排序类型(ASC或DESC)必须保持一致,否则只能通过内存归并才能保证其数据的正确性。好在分组后的数据基本不会太多。
-
当SQL中只包含分组语句时,根据不同数据库的实现,其排序的顺序不一定与分组顺序一致。 但由于排序语句的缺失,则表示此SQL并不在意排序顺序。 因此,ShardingSphere通过SQL优化的改写,自动增加与分组项一致的排序项,使其能够从消耗内存的内存分组归并方式转化为流式分组归并方案。
-
官方不支持having子句
(7) OR及Range语句测试
select * from bill where id < 30 or bill_amount > 40
执行测试:
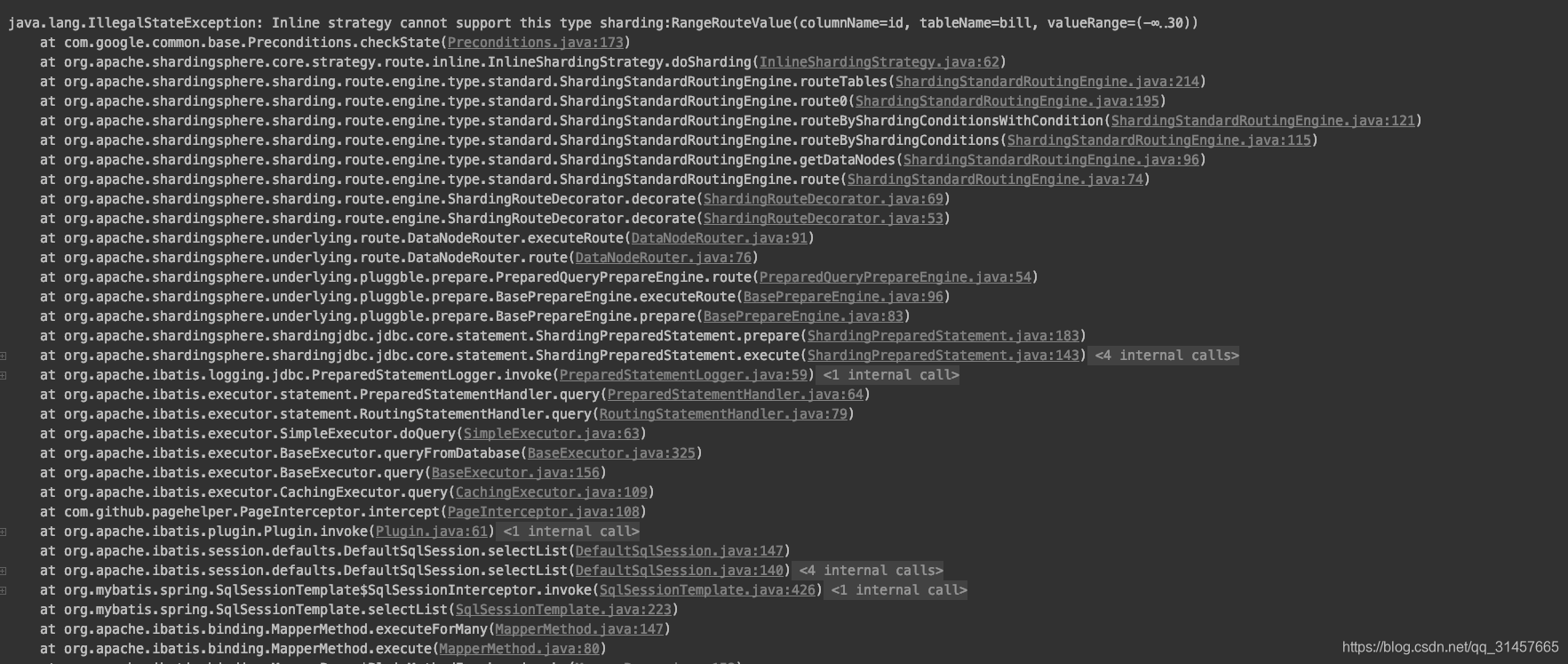
java.lang.IllegalStateException: Inline strategy cannot support this type sharding:RangeRouteValue
解决这个问题需要添加配置:
spring.shardingsphere.props.allow.range.query.with.inline.sharding=true
再次启动并执行代码:

- 即使包含分片键,此时已经无法按照模糊的分片键精准路由到对应的数据节点,很明显使用的是【全库全表路由】
- 官方给出了优化了OR语句,本以为是把Or语句拆分了,用来支持UNION(ALL),看来并不是这样
5. 广播表
当前bill_item作为广播表配置的
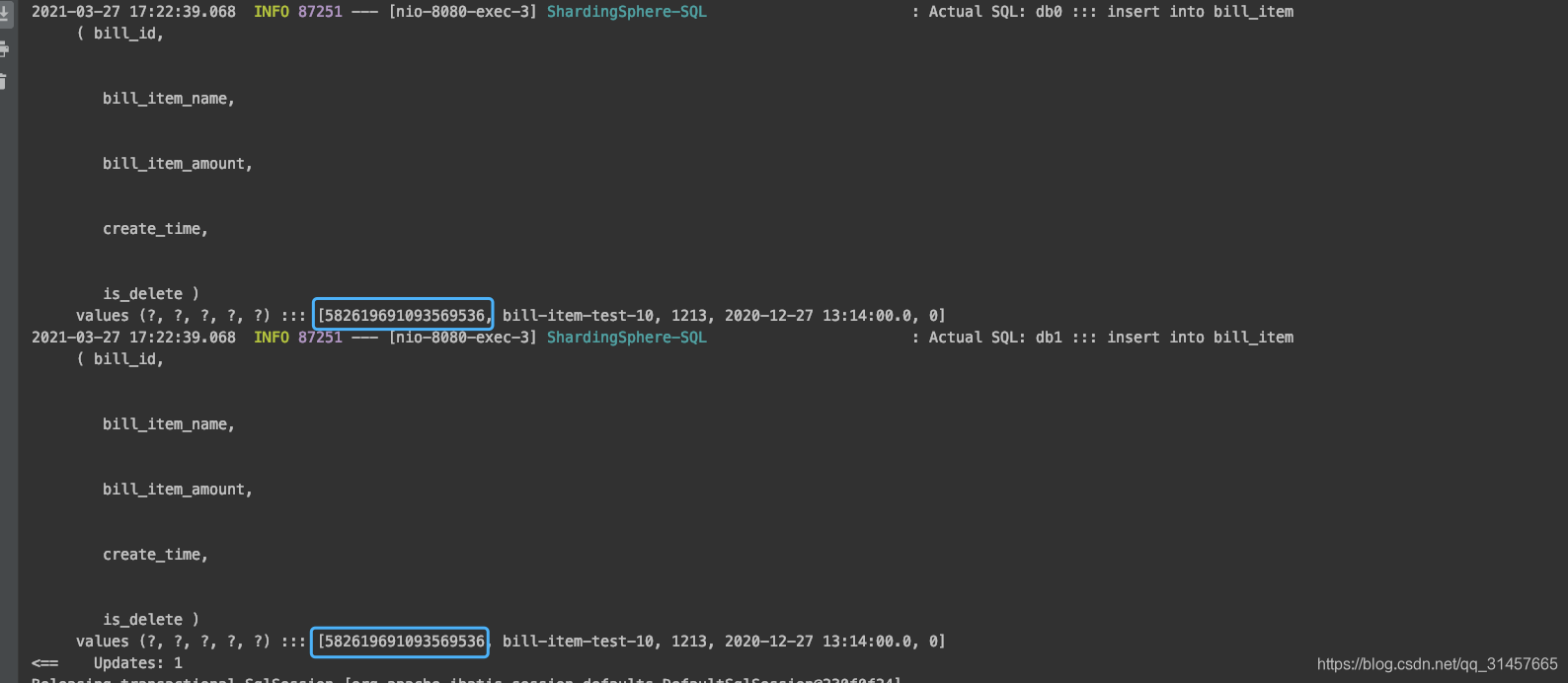
(1)插入
-
广播表概念只存在有分库的情况,如果只是分表或主从,不涉及这个概念,配置了也没啥意义。以下论述均依据存在分库的情况
-
绑定表在每个数据库都有一个,且数据一样,适合字典表场景,数据量少。
-
当插入一条数据时,所有库的bill_item表都会插入一条一模一样数据(可能出现分布式事务问题)
(2)查询


多次查询billItemId为3的,路由到的库是随机的。即【路由引擎】中【广播路由】中的【单播路由】
6. 绑定表
参考官方文档-绑定表
7.详细配置示例
spring.shardingsphere.datasource.names= #数据源名称,多数据源以逗号分隔
spring.shardingsphere.datasource.<data-source-name>.type= #数据库连接池类名称
spring.shardingsphere.datasource.<data-source-name>.driver-class-name= #数据库驱动类名
spring.shardingsphere.datasource.<data-source-name>.url= #数据库url连接
spring.shardingsphere.datasource.<data-source-name>.username= #数据库用户名
spring.shardingsphere.datasource.<data-source-name>.password= #数据库密码
spring.shardingsphere.datasource.<data-source-name>.xxx= #数据库连接池的其它属性
spring.shardingsphere.sharding.tables.<logic-table-name>.actual-data-nodes= #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
#分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
#用于单分片键的标准分片场景
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.sharding-column= #分片列名称
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.precise-algorithm-class-name= #精确分片算法类名称,用于=和IN。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.range-algorithm-class-name= #范围分片算法类名称,用于BETWEEN,可选。该类需实现RangeShardingAlgorithm接口并提供无参数的构造器
#用于多分片键的复合分片场景
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.sharding-columns= #分片列名称,多个列以逗号分隔
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.algorithm-class-name= #复合分片算法类名称。该类需实现ComplexKeysShardingAlgorithm接口并提供无参数的构造器
#行表达式分片策略
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.sharding-column= #分片列名称
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.algorithm-expression= #分片算法行表达式,需符合groovy语法
#Hint分片策略
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.hint.algorithm-class-name= #Hint分片算法类名称。该类需实现HintShardingAlgorithm接口并提供无参数的构造器
#分表策略,同分库策略
spring.shardingsphere.sharding.tables.<logic-table-name>.table-strategy.xxx= #省略
spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.column= #自增列名称,缺省表示不使用自增主键生成器
spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.type= #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.props.<property-name>= #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性
spring.shardingsphere.sharding.binding-tables[0]= #绑定表规则列表
spring.shardingsphere.sharding.binding-tables[1]= #绑定表规则列表
spring.shardingsphere.sharding.binding-tables[x]= #绑定表规则列表
spring.shardingsphere.sharding.broadcast-tables[0]= #广播表规则列表
spring.shardingsphere.sharding.broadcast-tables[1]= #广播表规则列表
spring.shardingsphere.sharding.broadcast-tables[x]= #广播表规则列表
spring.shardingsphere.sharding.default-data-source-name= #未配置分片规则的表将通过默认数据源定位
spring.shardingsphere.sharding.default-database-strategy.xxx= #默认数据库分片策略,同分库策略
spring.shardingsphere.sharding.default-table-strategy.xxx= #默认表分片策略,同分表策略
spring.shardingsphere.sharding.default-key-generator.type= #默认自增列值生成器类型,缺省将使用org.apache.shardingsphere.core.keygen.generator.impl.SnowflakeKeyGenerator。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
spring.shardingsphere.sharding.default-key-generator.props.<property-name>= #自增列值生成器属性配置, 比如SNOWFLAKE算法的worker.id与max.tolerate.time.difference.milliseconds
spring.shardingsphere.props.sql.show= #是否开启SQL显示,默认值: false
spring.shardingsphere.props.allow.range.query.with.inline.sharding= #当使用inline分表策略时,是否允许范围查询,默认值: false
spring.shardingsphere.props.executor.size= #工作线程数量,默认值: CPU核数
- 不同的分片策略对应的配置项不同,配置时需要注意

















 7969
7969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









