







 本文详细介绍了Linux中使用C语言进行进程操作的基本概念,包括进程的定义,fork()创建子进程,exec()创建新进程(替换进程),exit()退出进程,以及wait()等待子进程。同时讨论了父子进程的判断,子进程执行位置,孤儿进程和僵尸进程,以及exec()和fork()的区别。
本文详细介绍了Linux中使用C语言进行进程操作的基本概念,包括进程的定义,fork()创建子进程,exec()创建新进程(替换进程),exit()退出进程,以及wait()等待子进程。同时讨论了父子进程的判断,子进程执行位置,孤儿进程和僵尸进程,以及exec()和fork()的区别。
目录
0x0 什么是进程
进程是操作系统提供的基本的抽象,我们也可以这样理解:进程就是运行中的程序。也可以说,操作系统为正在运行的程序提供的抽象,就是所谓的进程(process)。程序本身是没有生命周期的,它只是磁盘上面的一些指令或者一些静态数据,是操作系统让这些数据运行起来,让程序发挥作用。下面我们一起看看在Linux中使用C语言进行进程操作的方法,下面所有操作都是在Ubuntu16.04中进行。
0x1 相关函数
fork():创建子进程
#include <unistd.h>
pid_t fork(void);exec():创建新进程,这是一组函数集
#include <unistd.h>
extern char **environ;
int execl(const char *pathname, const char *arg, ...
/*, (char *) NULL */);
int execlp(const char *file, const char *arg, ...
/*, (char *) NULL */);
int execle(const char *pathname, const char *arg, ...
/*, (char *) NULL, char *const envp[] */);
int execv(const char *pathname, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);值得注意的是exec()只是以上函数的简称,其实并没有名为exec()的函数。
exit():退出进程
#include <stdlib.h>
void exit(int status);wait():等待子进程
#include <sys/wait.h>
pid_t wait(int *stat_loc);下面是一个创建子进程和退出进程的实例程序,比较简单,其中使用了getpid()函数和getppid()函数获取进程的pid(进程id)和ppid(父进程id):
/*
* fork()函数示例程序
*/
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
int main(int argc, char *argv[])
{
pid_t pid;
if ((pid = fork()) == 0) {
printf("This is child process, pid = %d, ppid = %d\n",
getpid(), getppid());
exit(EXIT_SUCCESS);
} else {
printf("This is parent process, pid = %d, ppid = %d\n",
getpid(), getppid());
exit(EXIT_SUCCESS);
}
}创建一个子进程,调用fork()的进程称为父进程,产生的新进程成为子进程。子进程可以看作是一个父进程的复制版本,也就是父进程的副本,各种变量数据和父进程调用fork()之前完全一致,但子进程和父进程也有一定的区别:
- 子进程会有自己独立的pid,不继承父进程的pid,执行上面的示例程序可以看出来。
- 子进程的ppid是父进程的pid。
- 子进程不会继承父进程的内存锁(memory locks)。
- 子进程的进程资源利用率(process resource utilizations)和CPU时间计数器(CPU time counters)会被复位为0。
- 子进程的挂起信号集(set of spending signals)初始化为空。
- 子进程不继承父进程的信号量校准(semaphore adjustments)。
- 子进程不继承父进程的记录锁(record locks)。
- 子进程不继承父进程的计时器(timer)。
- 子进程不继承父进程未完成的异步I/O(asynchronous I/O)。
- 更多区别可以访问fork(2) - Linux manual page,更细节的区别这里不一一介绍了。
父子进程判断
在上面的示例程序中也可以看得出我们使用fork()的返回值来判断当前是在父进程中还是在子进程中。当父进程调用fork()的时候,如果调用成功,fork()会返回新的子进程的pid,如果fork()是在子进程中被调用的话将会返回0,我们就可以利用这个特性去实现父进程和子进程的判断,如果失败fork()会返回-1。细心的朋友应该发现了,子进程是不能创建新的子进程的,只有最初的也就是第一个执行fork()的进程才能创建自己的子进程。如果需要创建多个进程,我们可以在父进程中调用多次fork()函数来实现:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#define MAX_PROC 5
int main(int argc, char *argv[])
{
int index;
pid_t pid[MAX_PROC] = { 0 };
for (index = 0; index < MAX_PROC; ++index) {
if ((pid[index] = fork()) == 0) {
printf("child process %d\n", getpid());
exit(EXIT_SUCCESS);
} else if (pid[index] < 0) {
perror("fork()");
exit(EXIT_FAILURE);
}
}
printf("parent process %d\n", getpid());
exit(EXIT_SUCCESS);
}执行结果如下:
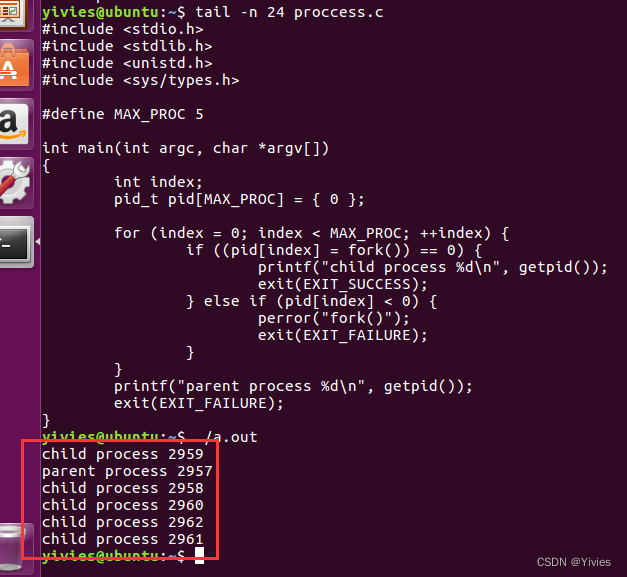
可以看到创建了五个子进程,并且父进程也输出了一条消息。 很多朋友看到父进程的输出和代码中的顺序不同可能会疑惑,这是因为创建进程之后,每一个进程都是独立的进程,这些进程都会进入操作系统调度列表中进行调度,所以每一个进程的先后顺序是不唯一的,具体要看操作系统的进程调度如何去调度进程。当然,这个程序非常不完整,因为父进程没有提供等待子进程的操作,这样很容易造成孤儿进程和僵尸进程。
子进程从哪里开始执行
在父进程创建子进程之后,子进程不是从头开始执行,而是从父进程调用fork()的位置开始执行,当然不是执行在父进程的进程上下文中,而是它自己的进程上下文。可能很多朋友不太了解进程上下文是什么意思,这里给一个简单的解释:一个进程在执行过程中能访问的系统资源就是这个进程的进程上下文,比如进程创建时分配到的指定的内存区域,这是属于这个进程的资源。如果了解汇编语言了解底层了解操作系统原理知识的朋友应该更容易理解进程上下文的概念。很多操作系统原理的教程都解释了上下文。
进程退出
进程的退出使用上面介绍的exit()函数,这个函数需要一个状态参数,也是这个进程的退出时状态,一般0是正常退出,1是非正常退出,这个有助于程序的调试,值得注意的是这个status的范围是0~255,在bash中我们可以使用以下命令查看上一个退出的进程的退出状态:
$ echo $?下面是示例:

我们上面的示例程序的EXIT_SUCCESS和EXIT_FAILURE是两个宏,它们的值如下:
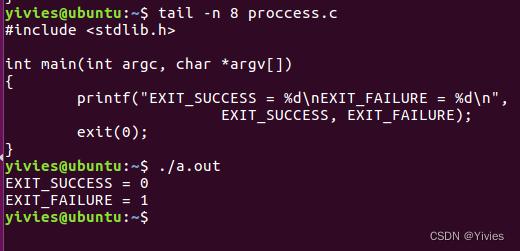
孤儿进程和僵尸进程
如果父进程已经执行完毕并退出,子进程还在执行,但是子进程没有退出机制,那么这个子进程将会变成一个孤儿进程。如果子进程先退出,但是父进程并没有做任何检测子进程退出的操作,那这个子进程将会变成一个僵尸进程。为了防止这种状况发生,我们在父进程中应该使用wait()函数去等待子进程的退出:
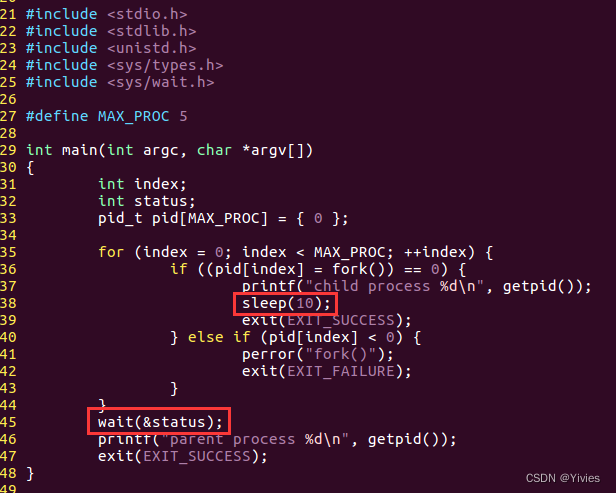
这样之后,只有当所有进程都结束执行之后父进程才会退出,这样父进程永远都是最后一个退出的进程:
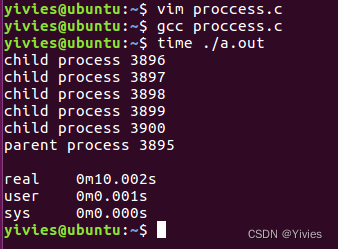
虽然以上代码也是一个简单的不安全的代码,但是按照这个思路去开发,就可以避免孤儿进程和僵尸进程。值得注意的是我在上面代码中添加了sleep()函数,让每一个子进程睡眠10秒再执行,之后使用time命令计算进程时间,我们发现这个进程执行了10秒多一点的时间,可以体现出,父进程必须等待所有子进程都结束之后父进程的wait()函数才会返回。
用exec()创建新进程
注意这里是创建新进程,而不是子进程,使用exec()创建进程,其实不是创建进程,更准确来说应该是加载可执行文件,完全从零开始的去加载执行一个exec()函数中指定的新的可执行文件,具体代码如下:

这里使用execv()函数调用了ls命令去检索 / 目录的内容。exec()和fork()的不同之处是exec()是加载执行一个完全的新的可执行程序,并不从调用exec()的进程继承任何东西,执行的程序是全新的进程,而fork()是在自己的基础上创建出子进程,子进程继承了父进程的大部分内容。
0x2 最后
以上就是在Linux中使用C语言去进行进程创建的大致内容了,个人拙见,欢迎指正。















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









