







 本文介绍了聚类算法的基本原理,如K-means的计算流程,以及如何通过SSE、肘方法和轮廓系数评估聚类效果。通过分析customers.csv数据集,确定了K-means的最佳聚类类别数为5。
本文介绍了聚类算法的基本原理,如K-means的计算流程,以及如何通过SSE、肘方法和轮廓系数评估聚类效果。通过分析customers.csv数据集,确定了K-means的最佳聚类类别数为5。
聚类算法是无监督学习算法,它根据样本之间的相似性,将样本划分到不同的类别中;不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧氏距离法。聚类算法的目的是在没有先验知识的情况下,自动发现数据集中的内在结构和模式。
聚类算法的分类:
-
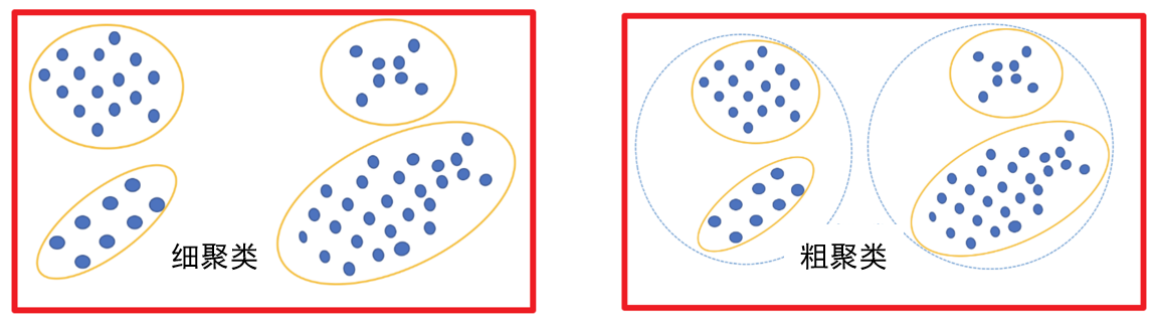
按照聚类细粒度分类:细聚类和粗聚类
-
-
根据实现方法分类:
-
K-means:按照质心分类,主要介绍K-means,通用、普遍
-
层次聚类:对数据进行逐层划分,直到达到聚类的类别个数
-
DBSCAN聚类:基于密度的聚类算法
-
谱聚类:基于图论的聚类算法
-
KMeans基本思路
通过计算相似度(默认欧氏距离),将相似度大的样本聚集到同一个类别,K表示聚成K个类别,means表示每个类别的聚类中心点是通过簇中所有样本点的均值得到。
KMeans算法流程:
-
事先确定常数K,K是最终的聚类类别数
-
随机选择K个样本点作为初始的聚类中心
-
计算每个样本点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











