







WordCount程序
首先看来一个快速入门案例,单词计数
这个需求就是类似于我们在学习MapReduce的时候写的案例
需求这样的:读取文件中的所有内容,计算每个单词出现的次数
这个需求就没什么好分析的了,咱们之前在学习MapReduce的已经分析过了,接下来就来看一下使用 Spark需要如何实现。
Scala代码开发
这里先使用Scala开发,sdk版本为:scala-2.11.12
以下为配置scala sdk与scala开发目录的步骤:
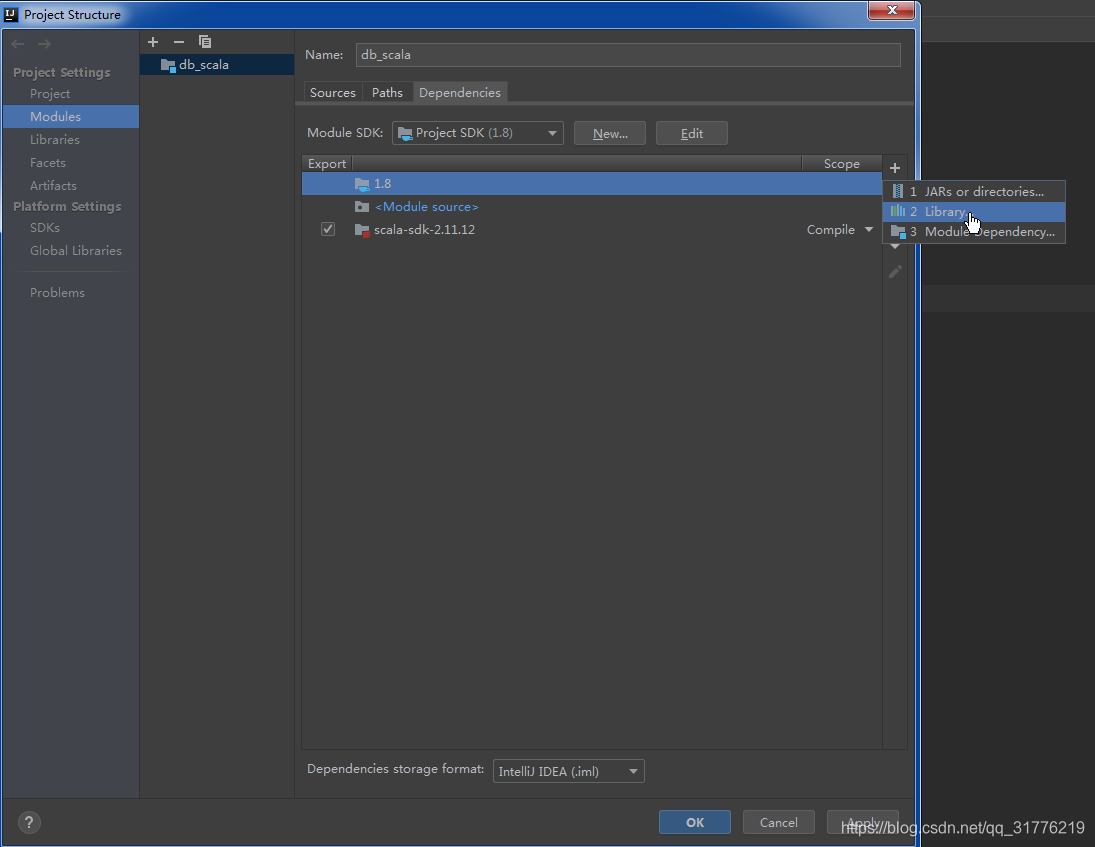
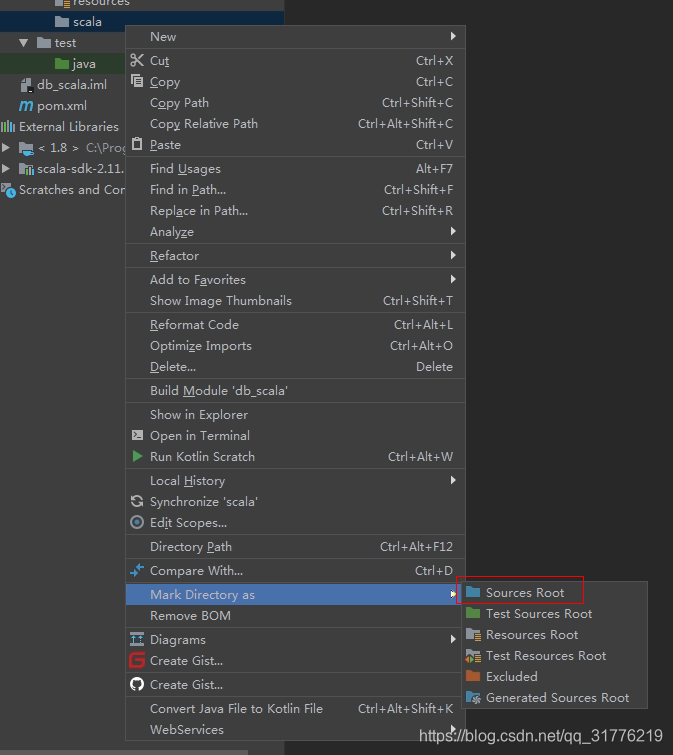
开发环境配置完毕
最后需要添加Spark的maven依赖
注意:由于目前我们下载的spark的安装包中使用的scala是2.11的,所以在这里要选择对应的scala 2.11版本的依赖。
spark这个版本也有对应scala2.12版本的安装包,不过那个安装包里面没有包含hadoop的依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
<scope>provided</scope>
</dependency>
import org.apache.spark.{SparkConf, SparkContext}
object WordCountScala {
def main(args: Array[String]): Unit = {
//第一步:创建SparkContext
val conf = new SparkConf()
conf.setAppName("WordCountScala")//设置任务名称
.setMaster("local")//local表示在本地执行
val sc = new SparkContext(conf)
//第二步:加载数据
var path = "E:\\1yyyyyyywz\\git-master\\bigdata_course_materials\\spark\\上\\hello.txt"
if(args.length==1){
path = args(0)
}
val linesRDD = sc.textFile(path)
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
val wordsRDD = linesRDD.flatMap(_.split(" "))
//第四步:迭代words,将每个word转换为(word,1)这种形式
val pairRDD = wordsRDD.map((_,1))
//第五步:根据key(其实就是word)进行分组聚合统计
val wordCountRDD = pairRDD.reduceByKey(_ + _)
//第六步:将结果打印到控制台
//注意:只有当任务执行到这一行代码的时候,任务才会真正开始执行计算
//如果任务中没有这一行代码,前面的所有算子是不会执行的
wordCountRDD.foreach(wordCount=>println(wordCount._1+"--"+wordCount._2))
//第七步:停止SparkContext
sc.stop()
}
}
注意:由于此时我们在代码中设置的Master为local,表示会在本地创建一个临时的spark集群运行这个代码,这样有利于代码调试
我们再来总结一下代码中这几个RDD中的数据结构
val linesRDD = sc.textFile("D:\\hello.txt")
linesRDD中的数据是这样的:
hello you
hello me
val wordsRDD = linesRDD.flatMap(_.split(" "))
wordsRDD中的数据是这样的:
hello
you
hello
me
val pairRDD = wordsRDD.map((_,1))
pairRDD 中的数据是这样的
(hello,1)
(you,1)
(hello,1)
(me,1)
val wordCountRDD = pairRDD.reduceByKey(_ + _)
wordCountRDD 中的数据是这样的 (hello,2)
(you,1)
(me,1)
这是Scala代码的实现,接下来我们用java代码实现一下
Java代码开发
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class WordCountJava {
public static void main(String[] args) {
//第一步:创建JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("WordCountJava");
//.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
//第二步:加载数据
String path = "D:\\hello.txt";
if(args.length==1){
path = args[0];
}
JavaRDD<String> linesRDD = sc.textFile(path);
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
//注意:FlatMapFunction的泛型,第一个参数表示输入数据类型,第二个表示是输出数据类型
JavaRDD<String> wordsRDD = linesRDD.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
//第四步:迭代words,将每个word转换为(word,1)这种形式
//注意:PairFunction的泛型,第一个参数是输入数据类型
//第二个是输出tuple中的第一个参数类型,第三个是输出tuple中的第二个参数类型
//注意:如果后面需要使用到....ByKey,前面都需要使用mapToPair去处理
JavaPairRDD<String, Integer> pairRDD = wordsRDD.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
//第五步:根据key(其实就是word)进行分组聚合统计
JavaPairRDD<String, Integer> wordCountRDD = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
//第六步:将结果打印到控制台
wordCountRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
public void call(Tuple2<String, Integer> tup) throws Exception {
System.out.println(tup._1+"--"+tup._2);
}
});
//第七步:停止SparkContext
sc.stop();
}
}
任务提交
针对任务的提交有这么几种形式
使用idea
直接在idea中执行,方便在本地环境调试代码 咱们刚才使用的就是这种方式
使用spark-submit
使用spark-submit提交到集群执行,实际工作中会使用这种方式 那接下来我们需要把我们的代码提交到集群中去执行
这个时候就需要对代码打包了
首先在项目的pom文件中添加build 配置,和dependencies 标签平级
<build>
<plugins>
<!-- java编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- scala编译插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.6</version>
<configuration>
<scalaCompatVersion>2.11</scalaCompatVersion>
<scalaVersion>2.11.12</scalaVersion>
</configuration>
<executions>
<execution>
<id>compile-scala</id>
<phase>compile</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile-scala</id>
<phase>test-compile</phase>
<goals>
<goal>add-source</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打包插件 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
注意:这里面的scala版本信息要使用2.11,因为spark安装包中依赖的scala是2.11的。
然后把spark-core依赖的作用域设置为provided
<scope>provided</scope>
修改代码中的输入文件路径信息,因为这个时候无法读取windows中的数据了,把代码修改成动态接收 输入文件路径,还需要将setMaster(“local”)注释掉,后面我们会在提交任务的时候动态指定master信息
在cmd命令行下执行打包命令
mvn clean package -DskipTests
把生成的jar包上传到bigdata04机器的/data/soft/sparkjars目录下 先创建这个目录
[root@bigdata04 ~]# mkdir -p /data/soft/sparkjars
上传jar包:db_spark-1.0-SNAPSHOT-jar-with-dependencies.jar
由于spark-submit命令后面的参数有点多,所以在这我们最好是写一个脚本去提交任务
[root@bigdata04 sparkjars]# vi wordCountJob.sh
spark-submit \
--class com.imooc.scala.WordCountScala \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 1 \
db_spark-1.0-SNAPSHOT-jar-with-dependencies.jar \
hdfs://bigdata01:9000/test/hello.txt
注意:为了能够方便使用spark-submit脚本,需要在/etc/profile中配置SPARK_HOME环境变量
[root@bigdata04 sparkjars]# vi /etc/profile
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export HIVE_HOME=/data/soft/apache-hive-3.1.2-bin
export SPARK_HOME=/data/soft/spark-2.4.3-bin-hadoop2.7
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin: [root@bigdata04 sparkjars]# source /etc/profile
在提交任务之前还需要先把hadoop集群启动了,以及对应的historyserver进程
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
[root@bigdata01 hadoop-3.2.0]#bin/mapred --daemon start historyserver
[root@bigdata02 hadoop-3.2.0]#bin/mapred --daemon start historyserver
[root@bigdata03 hadoop-3.2.0]#bin/mapred --daemon start historyserver
[root@bigdata04 sparkjars]# sh -x wordCountJob.sh
此时任务会被提交到YARN集群中,可以看到任务执行成功了















 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











