







临时测试学习使用,所以就不搭建集群了,集群搭建配置要弄得比较多。
直接在es官网下载6.4.3这个版本的es,然后下载对应的logstash

直接打开这个bat就可以了
访问localhost:9200 有一堆json,说明成功启动了
然后来做logstash数据同步的配置
现在bin建个jdbcconfig目录,里面写同步相关的一些配置
input {
jdbc {
jdbc_driver_library => "D:\Program Files (x86)\apache-maven-3.6.3\reposi\com\microsoft\sqlserver\mssql-jdbc\6.4.0.jre8\mssql-jdbc-6.4.0.jre8.jar"
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
jdbc_connection_string => "jdbc:sqlserver://192.168.1.10:1433;DatabaseName=数据库名字;"
jdbc_user => "sa"
jdbc_password => "密码"
schedule => "* * * * *"
statement => "SELECT * FROM db_custom WHERE last_track_date >= :sql_last_value"
use_column_value => true
tracking_column_type => "timestamp"
tracking_column => "last_track_date"
last_run_metadata_path => "syncpoint_table"
type => "jdbc"
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => ["localhost:9200"]
# 索引名称 可自定义
index => "user"
# 需要关联的数据库中有有一个id字段,对应类型中的id
document_id => "%{id}"
document_type => "user"
}
stdout {
# JSON格式输出
codec => json_lines
}
}
我这里用的是maven里的SqlServer的驱动包,直接贴了maven仓库的地址
<dependency>
<groupId>com.microsoft.sqlserver</groupId>
<artifactId>mssql-jdbc</artifactId>
<scope>runtime</scope>
</dependency>

上面是SqlServer的配置文件
下面再贴一个mysql的,这个每个配置作用注释也比较全面,自己看吧
input {
jdbc {
# 设置 MySql/MariaDB 数据库url以及数据库名称
jdbc_connection_string => "jdbc:mysql://192.168.1.6:3306/foodie-shop-dev?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "root"
# 数据库驱动所在位置,可以是绝对路径或者相对路径
jdbc_driver_library => "/usr/local/logstash-6.4.3/sync/mysql-connector-java-5.1.41.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 开启分页
jdbc_paging_enabled => "true"
# 分页每页数量,可以自定义
jdbc_page_size => "1000"
# 执行的sql文件路径
statement_filepath => "/usr/local/logstash-6.4.3/sync/foodie-items.sql"
# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务
schedule => "* * * * *"
# 索引类型
type => "_doc"
# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件
use_column_value => true
# 记录上一次追踪的结果值
last_run_metadata_path => "/usr/local/logstash-6.4.3/sync/track_time"
# 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间
tracking_column => "updated_time"
# tracking_column 对应字段的类型
tracking_column_type => "timestamp"
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录
clean_run => false
# 数据库字段名称大写转小写
lowercase_column_names => false
}
}
output {
elasticsearch {
# es地址
hosts => ["192.168.1.187:9200"]
# 同步的索引名
index => "foodie-items"
# 设置_docID和数据相同
document_id => "%{id}"
# document_id => "%{itemId}"
}
# 日志输出
stdout {
codec => json_lines
}
}
配置完之后
在logstash的bin目录输入cmd

然后输入这个命令 启动logstash并带上你写的配置
.\logstash -f .\jdbcconfig\jdbc.conf --path.data=/jdbcconfig/
慢慢等着吧,然后他就会同步了,我这里是每分钟看一次,主要是根据那个时间去判定是不是有更新。
要想看是不是同步到es了,就在谷歌浏览器插件商店搜索elasticsearch,然后有一个叫eshead的,
安装完就打开吧,这个下载,要fanqiang,全局模式fanqiang。

这里可以做一些查询啥的
下面我们和springboot整合一下使用。
先引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<!-- <version>2.1.5.RELEASE</version>-->
<version>2.2.2.RELEASE</version>
</dependency>
然后在你的yml文件,配置一波,那个集群名字,你就打开localhost:9200 那里有 你抄下来就可以了

下面放个测试用例,更多用法探索就自己百度了
package com.test;
import com.imooc.Application;
import com.imooc.es.pojo.Stu;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.FieldSortBuilder;
import org.elasticsearch.search.sort.SortBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.SearchResultMapper;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.aggregation.impl.AggregatedPageImpl;
import org.springframework.data.elasticsearch.core.query.*;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class ESTest {
@Autowired
private ElasticsearchTemplate esTemplate;
/**
* 不建议使用 ElasticsearchTemplate 对索引进行管理(创建索引,更新映射,删除索引)
* 索引就像是数据库或者数据库中的表,我们平时是不会是通过java代码频繁的去创建修改删除数据库或者表的
* 我们只会针对数据做CRUD的操作
* 在es中也是同理,我们尽量使用 ElasticsearchTemplate 对文档数据做CRUD的操作
* 1. 属性(FieldType)类型不灵活
* 2. 主分片与副本分片数无法设置
*/
@Test
public void createIndexStu() {
Stu stu = new Stu();
stu.setStuId(1005L);
stu.setName("iron man");
stu.setAge(54);
stu.setMoney(1999.8f);
stu.setSign("I am iron man");
stu.setDescription("I have a iron army");
IndexQuery indexQuery = new IndexQueryBuilder().withObject(stu).build();
esTemplate.index(indexQuery);
}
@Test
public void deleteIndexStu() {
esTemplate.deleteIndex(Stu.class);
}
// ------------------------- 我是分割线 --------------------------------
@Test
public void updateStuDoc() {
Map<String, Object> sourceMap = new HashMap<>();
// sourceMap.put("sign", "I am not super man");
sourceMap.put("money", 99.8f);
// sourceMap.put("age", 33);
IndexRequest indexRequest = new IndexRequest();
indexRequest.source(sourceMap);
UpdateQuery updateQuery = new UpdateQueryBuilder()
.withClass(Stu.class)
.withId("1004")
.withIndexRequest(indexRequest)
.build();
// update stu set sign='abc',age=33,money=88.6 where docId='1002'
esTemplate.update(updateQuery);
}
@Test
public void getStuDoc() {
GetQuery query = new GetQuery();
query.setId("1002");
Stu stu = esTemplate.queryForObject(query, Stu.class);
System.out.println(stu);
}
@Test
public void deleteStuDoc() {
esTemplate.delete(Stu.class, "1002");
}
// ------------------------- 我是分割线 --------------------------------
@Test
public void searchStuDoc() {
Pageable pageable = PageRequest.of(0, 2);
SearchQuery query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("description", "save man"))
.withPageable(pageable)
.build();
AggregatedPage<Stu> pagedStu = esTemplate.queryForPage(query, Stu.class);
System.out.println("检索后的总分页数目为:" + pagedStu.getTotalPages());
List<Stu> stuList = pagedStu.getContent();
for (Stu s : stuList) {
System.out.println(s);
}
}
@Test
public void highlightStuDoc() {
String preTag = "<font color='red'>";
String postTag = "</font>";
Pageable pageable = PageRequest.of(0, 10);
SortBuilder sortBuilder = new FieldSortBuilder("money")
.order(SortOrder.DESC);
SortBuilder sortBuilderAge = new FieldSortBuilder("age")
.order(SortOrder.ASC);
SearchQuery query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("description", "save man"))
.withHighlightFields(new HighlightBuilder.Field("description")
.preTags(preTag)
.postTags(postTag))
.withSort(sortBuilder)
.withSort(sortBuilderAge)
.withPageable(pageable)
.build();
AggregatedPage<Stu> pagedStu = esTemplate.queryForPage(query, Stu.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) {
List<Stu> stuListHighlight = new ArrayList<>();
SearchHits hits = response.getHits();
for (SearchHit h : hits) {
HighlightField highlightField = h.getHighlightFields().get("description");
String description = highlightField.getFragments()[0].toString();
Object stuId = (Object)h.getSourceAsMap().get("stuId");
String name = (String)h.getSourceAsMap().get("name");
Integer age = (Integer)h.getSourceAsMap().get("age");
String sign = (String)h.getSourceAsMap().get("sign");
Object money = (Object)h.getSourceAsMap().get("money");
Stu stuHL = new Stu();
stuHL.setDescription(description);
stuHL.setStuId(Long.valueOf(stuId.toString()));
stuHL.setName(name);
stuHL.setAge(age);
stuHL.setSign(sign);
stuHL.setMoney(Float.valueOf(money.toString()));
stuListHighlight.add(stuHL);
}
if (stuListHighlight.size() > 0) {
return new AggregatedPageImpl<>((List<T>)stuListHighlight);
}
return null;
}
});
System.out.println("检索后的总分页数目为:" + pagedStu.getTotalPages());
List<Stu> stuList = pagedStu.getContent();
for (Stu s : stuList) {
System.out.println(s);
}
}
}

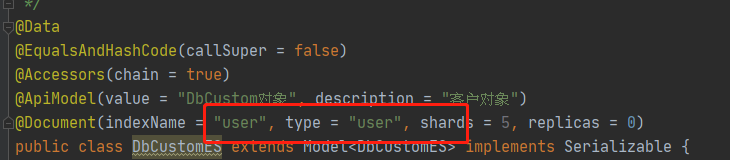
这个实体,你要看eshead那里有显示

改一下就行了
















 764
764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











