






一、 ELK工作栈简介
1. 简介
ELK Stack 是 Elasticsearch、Logstash、Kibana 三个开源软件的组合。在实时数据检索和分析场合,三者通常是配合共用,而且又都先后归于 Elastic.co 公司名下,故有此简称。
ELK Stack 在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,ELK Stack 具有如下几个优点:
处理方式灵活。Elasticsearch 是实时全文索引,不需要像 storm 那样预先编程才能使用;
配置简易上手。Elasticsearch 全部采用 JSON 接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计;
检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到全天数据查询的秒级响应;
集群线性扩展。不管是 Elasticsearch 集群还是 Logstash 集群都是可以线性扩展的;
前端操作炫丽。Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
当然,ELK Stack 也并不是实时数据分析界的灵丹妙药。在不恰当的场景,反而会事倍功半。我自 2014 年初开 QQ 群交流 ELK Stack,发现网友们对 ELK Stack 的原理概念,常有误解误用;对实现的效果,又多有不能理解或者过多期望而失望之处。更令我惊奇的是,网友们广泛分布在传统企业和互联网公司、开发和运维领域、Linux 和 Windows 平台,大家对非专精领域的知识,一般都缺乏了解,这也成为使用 ELK Stack 时的一个障碍。
二、 Logstash数据采集工具安装和使用
1. 官方网站
https://www.elastic.co/products/logstash#
2. 简介
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
3. 安装
下载后直接解压,就可以了。
4. helloword使用
通过命令行,进入到logstash/bin目录,执行下面的命令:
logstash -e ""可以看到提示下面信息(这个命令稍后介绍),输入hello world!
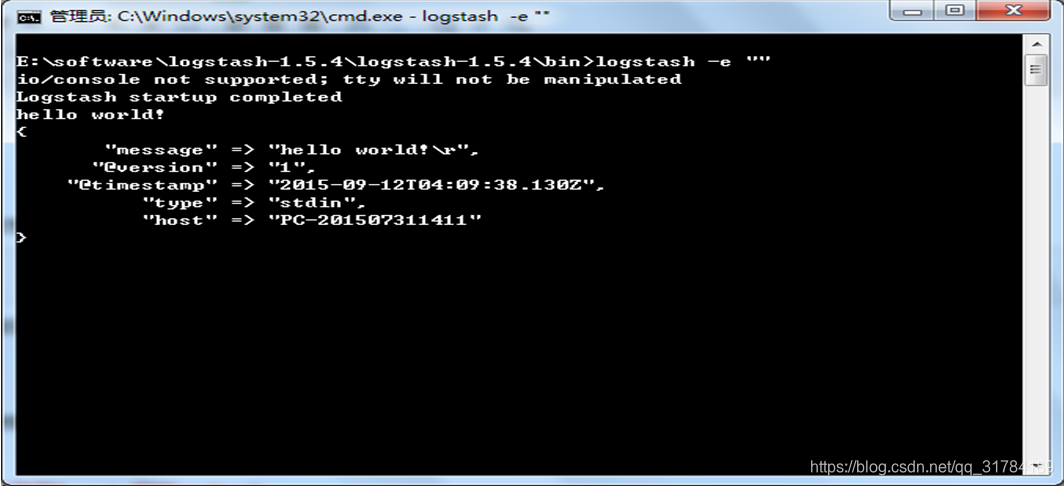
可以看到logstash尾我们自动添加了几个字段,时间戳@timestamp,版本@version,输入的类型type,以及主机名host。
4.1. 简单的工作原理
Logstash使用管道方式进行日志的搜集处理和输出。有点类似*NIX系统的管道命令 xxx | ccc | ddd,xxx执行完了会执行ccc,然后执行ddd。
在logstash中,包括了三个阶段:
输入input --> 处理filter(不是必须的) --> 输出output
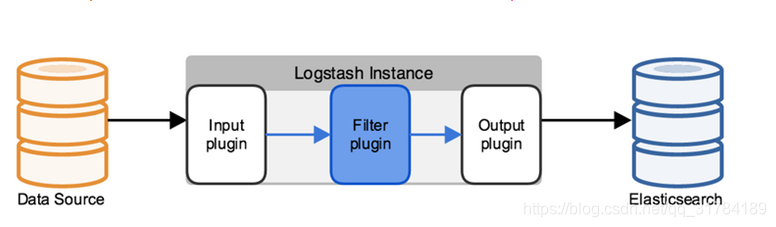
每个阶段都由很多的插件配合工作,比如file、elasticsearch、redis等等。
每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到stdout在控制台打印。
由于这种插件式的组织方式,使得logstash变得易于扩展和定制。
4.2. 命令行中常用的命令
-f:通过这个命令可以指定Logstash的配置文件,根据配置文件配置logstash
-e:后面跟着字符串,该字符串可以被当做logstash的配置(如果是“” 则默认使用stdin作为输入,stdout作为输出)
-l:日志输出的地址(默认就是stdout直接在控制台中输出)
-t:测试配置文件是否正确,然后退出。
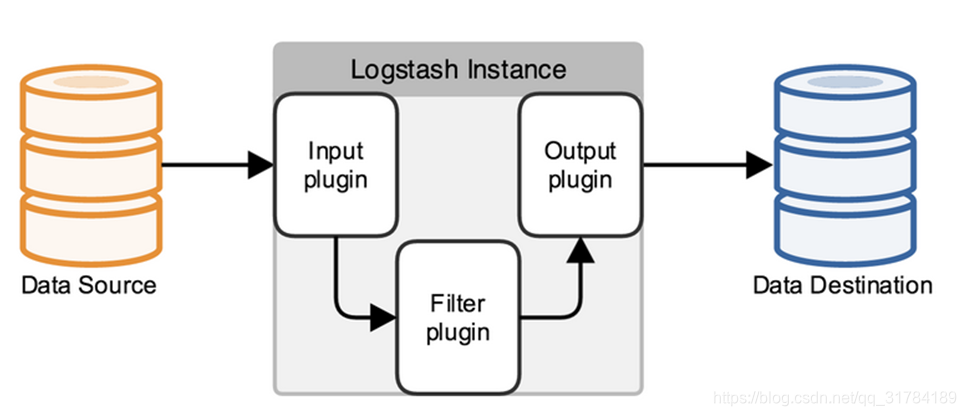
4.3. 配置文件说明
前面介绍过logstash基本上由三部分组成,input、output以及用户需要才添加的filter,因此标准的配置文件格式如下:
input {...}
filter {...}
output {...}
在每个部分中,也可以指定多个访问方式,例如我想要指定两个日志来源文件,则可以这样写:
input {
file { path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
类似的,如果在filter中添加了多种处理规则,则按照它的顺序一一处理,但是有一些插件并不是线程安全的。
比如在filter中指定了两个一样的的插件,这两个任务并不能保证准确的按顺序执行,因此官方也推荐避免在filter中重复使用插件。
说完这些,简单的创建一个配置文件的小例子看看:
input {
file {
#指定监听的文件路径,注意必须是绝对路径
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/test.log"
start_position => beginning
}
}
filter {
}
output {
stdout {}
}
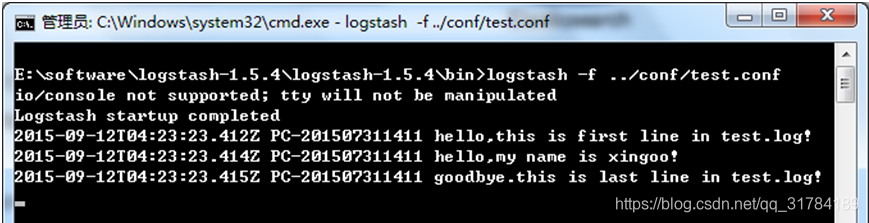
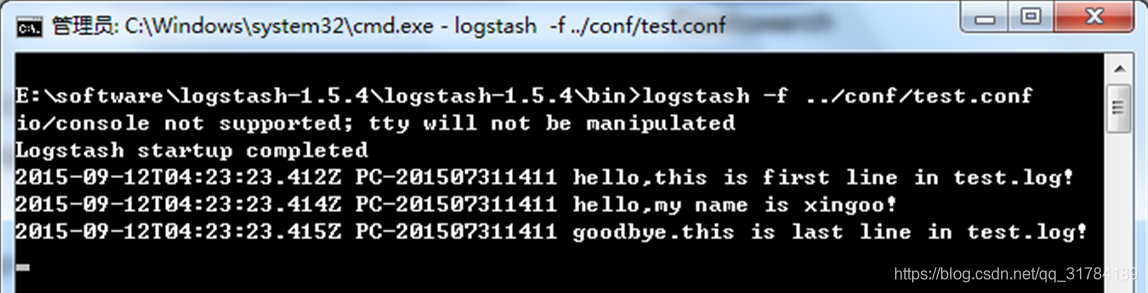
日志大致如下:注意最后有一个空行。
hello,this is first line in test.log!
hello,my name is xingoo!
goodbye.this is last line in test.log!
执行命令得到如下信息:
5. 最常用的input插件——file。
这个插件可以从指定的目录或者文件读取内容,输入到管道处理,也算是logstash的核心插件了,大多数的使用场景都会用到这个插件,因此这里详细讲述下各个参数的含义与使用。
5.1. 最小化的配置文件
在Logstash中可以在 input{} 里面添加file配置,默认的最小化配置如下:
input {
file {
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*"
}
}
filter {
}
output {
stdout {}
}
当然也可以监听多个目标文件:
input {
file {
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"]
}
}
filter {
}
output {
stdout {}
}
5.2. 其他的配置
另外,处理path这个必须的项外,file还提供了很多其他的属性:
input {
file {
#监听文件的路径
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"]
#排除不想监听的文件
exclude => "1.log"
#添加自定义的字段
add_field => {"test"=>"test"}
#增加标签
tags => "tag1"
#设置新事件的标志
delimiter => "\n"
#设置多长时间扫描目录,发现新文件
discover_interval => 15
#设置多长时间检测文件是否修改
stat_interval => 1
#监听文件的起始位置,默认是end
start_position => beginning
#监听文件读取信息记录的位置
sincedb_path => "E:/software/logstash-1.5.4/logstash-1.5.4/test.txt"
#设置多长时间会写入读取的位置信息
sincedb_write_interval => 15
}
}
filter {
}
output {
stdout {}
}
其中值得注意的是:
1 path
是必须的选项,每一个file配置,都至少有一个path
2 exclude
是不想监听的文件,logstash会自动忽略该文件的监听。配置的规则与path类似,支持字符串或者数组,但是要求必须是绝对路径。
3 start_position
是监听的位置,默认是end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,这个配置也就失去作用了。
4 sincedb_path
这个选项配置了默认的读取文件信息记录在哪个文件中,默认是按照文件的inode等信息自动生成。其中记录了inode、主设备号、次设备号以及读取的位置。因此,如果一个文件仅仅是重命名,那么它的inode以及其他信息就不会改变,因此也不会重新读取文件的任何信息。类似的,如果复制了一个文件,就相当于创建了一个新的inode,如果监听的是一个目录,就会读取该文件的所有信息。
5 其他的关于扫描和检测的时间,按照默认的来就好了,如果频繁创建新的文件,想要快速监听,那么可以考虑缩短检测的时间。
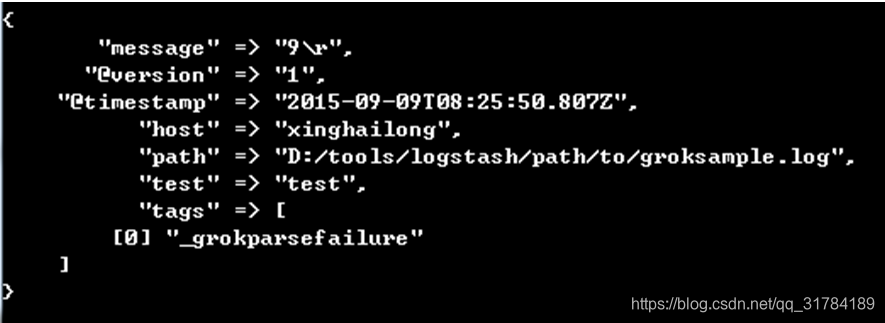
6 add_field
就是增加一个字段,例如:
file {
add_field => {"test"=>"test"}
path => "D:/tools/logstash/path/to/groksample.log"
start_position => beginning
}
6. Kafka与Logstash的数据采集对接
基于Logstash跑通Kafka还是需要注意很多东西,最重要的就是理解Kafka的原理。
6.1. Logstash工作原理
由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送给消费者。而是在中间加入持久化层——broker,生产者把数据存放在broker中,消费者从broker中取数据。这样就带来了几个好处:
1 生产者的负载与消费者的负载解耦
2 消费者按照自己的能力fetch数据
3 消费者可以自定义消费的数量
另外,由于broker采用了主题topic-->分区的思想,使得某个分区内部的顺序可以保证有序性,但是分区间的数据不保证有序性。这样,消费者可以以分区为单位,自定义读取的位置——offset。
Kafka采用zookeeper作为管理,记录了producer到broker的信息,以及consumer与broker中partition的对应关系。因此,生产者可以直接把数据传递给broker,broker通过zookeeper进行leader-->followers的选举管理;消费者通过zookeeper保存读取的位置offset以及读取的topic的partition分区信息。
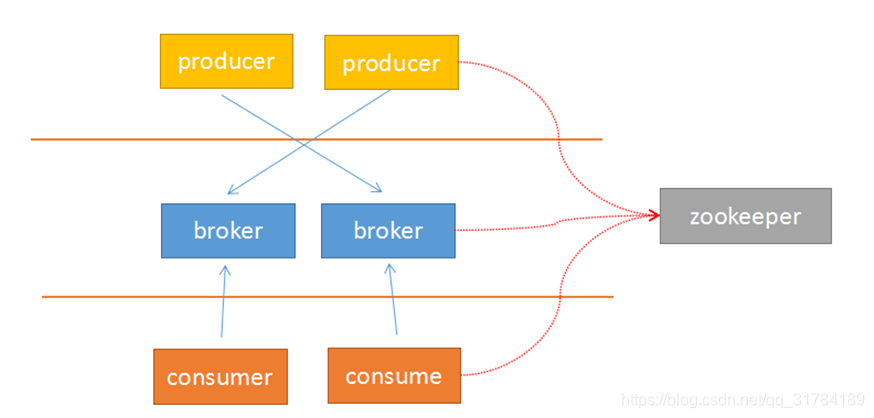
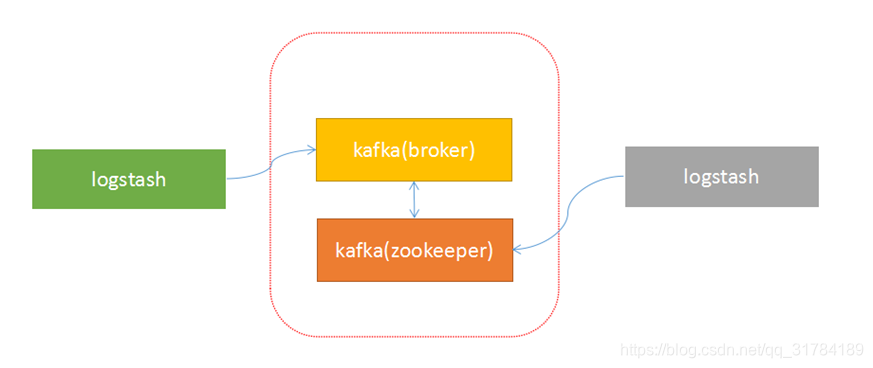
由于上面的架构设计,使得生产者与broker相连;消费者与zookeeper相连。有了这样的对应关系,就容易部署logstash-->kafka-->logstash的方案了。
接下来,按照下面的步骤就可以实现logstash与kafka的对接了。
6.2. 启动kafka
启动zookeeper:
$zookeeper/bin/zkServer.sh start
启动kafka:
$kafka/bin/kafka-server-start.sh $kafka/config/server.properties &
6.3. 创建主题
创建主题:
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic hello --replication-factor 1 --partitions 1
查看主题:
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe
6.4. 测试环境
执行生产者脚本:
$kafka/bin/kafka-console-producer.sh --broker-list 10.0.67.101:9092 --topic hello
执行消费者脚本,查看是否写入:
$kafka/bin/kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --from-beginning --topic hello
6.5. 向kafka中输出数据
input{
stdin{}
}
output{
kafka{
topic_id => "hello"
bootstrap_servers => "192.168.0.4:9092,172.16.0.12:9092"
# kafka的地址
batch_size => 5
codec => plain {
format => "%{message}"
charset => "UTF-8"
}
}
stdout{
codec => rubydebug
}
}
6.6. 从kafka中读取数据
logstash配置文件:
input{
kafka {
codec => "plain"
group_id => "logstash1"
auto_offset_reset => "smallest"
reset_beginning => true
topic_id => "hello"
zk_connect => "192.168.0.5:2181"
}
}
output{
stdout{
codec => rubydebug
}
}
三、 ElasticSearch索引服务安装和使用
1. 简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些问题和更多的问题。
2. ES概念
cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
river
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
gateway
代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
3. 安装
1、 创建用户
es启动时需要使用非root用户,所以创建一个普通用户
2、 安装jdk(jdk要求1.8.20或1.7.55以上)
3、 上传es安装包
4、 tar -zxvf elasticsearch-2.3.1.tar.gz -C /bigdata/
5、 修改配置
vi /bigdata/elasticsearch-2.3.1/config/elasticsearch.yml
#集群名称,通过组播的方式通信,通过名称判断属于哪个集群
cluster.name: bigdata
#节点名称,要唯一
node.name: es-1
#数据存放位置
path.data: /data/es/data
#日志存放位置
path.logs: /data/es/logs
#es绑定的ip地址
network.host: 172.16.0.14
#初始化时可进行选举的节点
discovery.zen.ping.unicast.hosts: ["node-4.itcast.cn", "node-5.itcast.cn", "node-6.itcast.cn"]
6、 使用scp拷贝到其他节点
scp -r elasticsearch-2.3.1/ node-5.itcast.cn:$PWD
scp -r elasticsearch-2.3.1/ node-6.itcast.cn:$PWD
7、 在其他节点上修改es配置,需要修改的有node.name和network.host
8、 启动es(/bigdata/elasticsearch-2.3.1/bin/elasticsearch -h查看帮助文档)
/bigdata/elasticsearch-2.3.1/bin/elasticsearch –d9、 用浏览器访问es所在机器的9200端口
http://172.16.0.14:9200/
{
"name" : "es-1",
"cluster_name" : "bigdata",
"version" : {
"number" : "2.3.1",
"build_hash" : "bd980929010aef404e7cb0843e61d0665269fc39",
"build_timestamp" : "2016-04-04T12:25:05Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
kill `ps -ef | grep Elasticsearch | grep -v grep | awk '{print $2}'`
4. es安装插件下载es插件
/bigdata/elasticsearch-2.3.1/bin/plugin install mobz/elasticsearch-head
#本地方式安装head插件
./plugin install file:///home/bigdata/elasticsearch-head-master.zip
#访问head管理页面
http://172.16.0.14:9200/_plugin/head
5. es的RESTful接口操作
RESTful接口URL的格式:
http://localhost:9200/<index>/<type>/[<id>]
其中index、type是必须提供的。
id是可选的,不提供es会自动生成。
index、type将信息进行分层,利于管理。
index可以理解为数据库;type理解为数据表;id相当于数据库表中记录的主键,是唯一的。
#向store索引中添加一些书籍
curl -XPUT 'http://172.16.0.14:9200/store/books/1' -d '{
"title": "Elasticsearch: The Definitive Guide",
"name" : {
"first" : "Zachary",
"last" : "Tong"
},
"publish_date":"2015-02-06",
"price":"49.99"
}'
#通过浏览器查询
http://172.16.0.14:9200/store/books/1
#在linux中通过curl的方式查询
curl -XGET 'http://172.16.0.14:9200/store/books/1'
#在添加一个书的信息
curl -XPUT 'http://172.16.0.14:9200/store/books/2' -d '{
"title": "Elasticsearch Blueprints",
"name" : {
"first" : "Vineeth",
"last" : "Mohan"
},
"publish_date":"2015-06-06",
"price":"35.99"
}'
# 通过ID获得文档信息
curl -XGET 'http://172.16.0.14:9200/bookstore/books/1'
#在浏览器中查看
http://172.16.0.14:9200/bookstore/books/1
# 通过_source获取指定的字段
curl -XGET 'http://172.16.0.14:9200/store/books/1?_source=title'
curl -XGET 'http://172.16.0.14:9200/store/books/1?_source=title,price'
curl -XGET 'http://172.16.0.14:9200/store/books/1?_source'
#可以通过覆盖的方式更新
curl -XPUT 'http://172.16.0.14:9200/store/books/1' -d '{
"title": "Elasticsearch: The Definitive Guide",
"name" : {
"first" : "Zachary",
"last" : "Tong"
},
"publish_date":"2016-02-06",
"price":"99.99"
}'
# 或者通过 _update API的方式单独更新你想要更新的
curl -XPOST 'http://172.16.0.14:9200/store/books/1/_update' -d '{
"doc": {
"price" : 88.88
}
}'
curl -XGET 'http://172.16.0.14:9200/store/books/1'
#删除一个文档
curl -XDELETE 'http://172.16.0.14:9200/store/books/1'
# 最简单filter查询
# SELECT * FROM books WHERE price = 35.99
# filtered 查询价格是35.99的
curl -XGET 'http://172.16.0.14:9200/store/books/_search' -d '{
"query" : {
"filtered" : {
"query" : {
"match_all" : {}
},
"filter" : {
"term" : {
"price" : 35.99
}
}
}
}
}'
#指定多个值
curl -XGET 'http://172.16.0.14:9200/store/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"terms" : {
"price" : [35.99, 88.88]
}
}
}
}
}'
# SELECT * FROM books WHERE publish_date = "2015-02-06"
curl -XGET 'http://172.16.0.14:9200/store/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"term" : {
"publish_date" : "2015-02-06"
}
}
}
}
}'
# bool过滤查询,可以做组合过滤查询
# SELECT * FROM books WHERE (price = 35.99 OR price = 99.99) AND (publish_date != "2016-02-06")
# 类似的,Elasticsearch也有 and, or, not这样的组合条件的查询方式
# 格式如下:
# {
# "bool" : {
# "must" : [],
# "should" : [],
# "must_not" : [],
# }
# }
#
# must: 条件必须满足,相当于 and
# should: 条件可以满足也可以不满足,相当于 or
# must_not: 条件不需要满足,相当于 not
curl -XGET 'http://172.16.0.14:9200/bookstore/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 35.99}},
{ "term" : {"price" : 99.99}}
],
"must_not" : {
"term" : {"publish_date" : "2016-02-06"}
}
}
}
}
}
}'
# 嵌套查询
# SELECT * FROM books WHERE price = 35.99 OR ( publish_date = "2016-02-06" AND price = 99.99 )
curl -XGET 'http://172.16.0.14:9200/bookstore/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 35.99}},
{ "bool" : {
"must" : [
{"term" : {"publish_date" : "2016-02-06"}},
{"term" : {"price" : 99.99}}
]
}}
]
}
}
}
}
}'
# range范围过滤
# SELECT * FROM books WHERE price >= 20 AND price < 100
# gt : > 大于
# lt : < 小于
# gte : >= 大于等于
# lte : <= 小于等于
curl -XGET 'http://172.16.0.14:9200/store/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"range" : {
"price" : {
"gt" : 20.0,
"lt" : 100
}
}
}
}
}
}'
# 另外一种 and, or, not查询
# 没有bool, 直接使用and , or , not
# 注意: 不带bool的这种查询不能利用缓存
# 查询价格既是35.99,publish_date又为"2015-02-06"的结果
curl -XGET 'http://172.16.0.14:9200/bookstore/books/_search' -d '{
"query": {
"filtered": {
"filter": {
"and": [
{
"term": {
"price":59.99
}
},
{
"term": {
"publish_date":"2015-02-06"
}
}
]
},
"query": {
"match_all": {}
}
}
}
}'
6. Logstash读取file写入es
input {
file {
path => "/var/nginx_logs/*.log"
codec => "json"
discover_interval => 5
start_position => "beginning"
}
}
output {
elasticsearch {
index => "flow-%{+YYYY.MM.dd}"
hosts => ["172.16.0.14:9200", "172.16.0.15:9200", "172.16.0.16:9200"]
}
}
7. Logstash+kafka+es
input {
kafka {
type => "accesslogs"
codec => "plain"
auto_offset_reset => "smallest"
group_id => "elas1"
topic_id => "accesslogs"
zk_connect => "172.16.0.11:2181,172.16.0.12:2181,172.16.0.13:2181"
}
kafka {
type => "gamelogs"
auto_offset_reset => "smallest"
codec => "plain"
group_id => "elas2"
topic_id => "gamelogs"
zk_connect => "172.16.0.11:2181,172.16.0.12:2181,172.16.0.13:2181"
}
}
filter {
if [type] == "accesslogs" {
json {
source => "message"
remove_field => [ "message" ]
target => "access"
}
}
if [type] == "gamelogs" {
mutate {
split => { "message" => " " }
add_field => {
"event_type" => "%{message[3]}"
"current_map" => "%{message[4]}"
"current_X" => "%{message[5]}"
"current_y" => "%{message[6]}"
"user" => "%{message[7]}"
"item" => "%{message[8]}"
"item_id" => "%{message[9]}"
"current_time" => "%{message[12]}"
}
remove_field => [ "message" ]
}
}
}
output {
if [type] == "accesslogs" {
elasticsearch {
index => "accesslogs"
codec => "json"
hosts => ["172.16.0.14:9200", "172.16.0.15:9200", "172.16.0.16:9200"]
}
}
if [type] == "gamelogs" {
elasticsearch {
index => "gamelogs"
codec => plain {
charset => "UTF-16BE"
}
hosts => ["172.16.0.14:9200", "172.16.0.15:9200", "172.16.0.16:9200"]
}
}
}
6、数据分析代码
package game
/**
* 事件类型枚举
* 0 管理员登陆
* 1 首次登陆
* 2 上线
* 3 下线
* 4 升级
* 5 预留
* 6 装备回收元宝
* 7 元宝兑换RMB
* 8 PK
* 9 成长任务
* 10 领取奖励
* 11 神力护身
* 12 购买物品
*/
object EventType {
val REGISTER = "1"
val LOGIN = "2"
val LOGOUT = "3"
val UPGRADE = "4"
}
package game
import org.apache.commons.lang3.time.FastDateFormat
/**
* Created by root on 2016/7/10.
*
* 我们定义的单例对象,每个Executor进程中只有一个FilterUtils实例
* 但是Executor进程中的Task是多线程的
*/
object FilterUtils {
//为什么不用SimpleDateFormat,因为SimpleDateFormat不是线程安全的
val dateFormat = FastDateFormat.getInstance("yyyy年MM月dd日,E,HH:mm:ss")
def filterByTime(fields: Array[String], startTime: Long, endTime: Long): Boolean = {
val time = fields(1)
val logTime = dateFormat.parse(time).getTime
logTime >= startTime && logTime < endTime
}
def filterByType(fields: Array[String], eventType: String) = {
val _type = fields(0)
_type == eventType
}
def filterByTypeAndTime(fields: Array[String], eventType: String, beginTime: Long, endTime: Long) = {
val _type = fields(0)
val time = fields(1)
val timeLong = dateFormat.parse(time).getTime
_type == eventType && timeLong >= beginTime && timeLong < endTime
}
def filterByTypes(fields: Array[String], eventTypes: String*): Boolean = {
val _type = fields(0)
for(et <- eventTypes){
if(_type == et)
return true
}
false
}
}
package game
import java.text.SimpleDateFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by root on 2016/7/10.
*/
object GameKPI {
def main(args: Array[String]) {
val queryTime = "2016-02-01 00:00:00"
val beginTime = TimeUtils(queryTime)
val endTime = TimeUtils.getCertainDayTime(+1)
//t1 02-02
val t1 = TimeUtils.getCertainDayTime(+1)
//t2 02-03
val t2 = TimeUtils.getCertainDayTime(+2)
val conf = new SparkConf().setAppName("GameKPI").setMaster("local")
//非常重要的一个对象SparkContext
val sc = new SparkContext(conf)
val splitedLog: RDD[Array[String]] = sc.textFile("c://GameLog.txt").map(_.split("\\|"))
//新增用户
class FilterUtils
// splitedLog.filter(_(0) == "1").filter(x => {
// val time = x(1)
// //不好,每filter一次就会new一个SimpleDateFormat实例,会浪费资源
// val sdf = new SimpleDateFormat("yyyy年MM月dd日,E,HH:mm:ss")
// val timeLong = sdf.parse(time).getTime
// })
//过滤后并缓冲
val filteredLogs = splitedLog.filter(fields => FilterUtils.filterByTime(fields, beginTime, endTime))
.cache()
//日新增用户数,Daily New Users 缩写 DNU
val dnu: RDD[Array[String]] = filteredLogs.filter(arr => FilterUtils.filterByType(arr, EventType.REGISTER))
println(dnu.count())
//日活跃用户数 DAU (Daily Active Users)
val dau = filteredLogs.filter(arr => FilterUtils.filterByTypes(arr, EventType.REGISTER, EventType.LOGIN))
.map(_(3)).distinct()
println(dau.count())
//(次日留存)用户留存
val dnuMap: RDD[(String, Int)] = dnu.map(arr =>(arr(3), 1))
val d2Login: RDD[Array[String]] = splitedLog.filter(arr => FilterUtils.filterByTypeAndTime(arr, EventType.LOGIN, t1, t2))
val d2UnameMap: RDD[(String, Int)] = d2Login.map(_(3)).distinct().map((_, 1))
// 留存率:某段时间的新增用户数记为A,经过一段时间后,仍然使用的用户占新增用户A的比例即为留存率
// // 次日留存率(Day 1 Retention Ratio) Retention [rɪ'tenʃ(ə)n] Ratio ['reɪʃɪəʊ]
// // 日新增用户在+1日登陆的用户占新增用户的比例
val d1rr: RDD[(String, (Int, Int))] = dnuMap.join(d2UnameMap)
val rdda = sc.parallelize(Array("a", "b", "c"))
val rddb = sc.parallelize(Array("a", "d", "e", "f"))
val r = rdda.subtract(rddb).collect().toBuffer
println(r)
// println(d1rr.collect().toBuffer)
//
//println(d1rr.count())
//
// println("dnu" + dnu.count())
//
// println("dau" + dau.count())
sc.stop()
}
}
package game
import org.apache.spark.{SparkConf, SparkContext}
import org.elasticsearch.spark._
object ElasticSpark {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("ElasticSpark").setMaster("local")
conf.set("es.nodes", "172.16.0.14,172.16.0.15,172.16.0.16")
conf.set("es.port", "9200")
conf.set("es.index.auto.create", "true")
val sc = new SparkContext(conf)
//val query: String = "{\"query\":{\"match_all\":{}}}"
val start = 1472290002
val end = 1472290047
// val query: String =
// s"""{
// "query": {"match_all": {}},
// "filter": {
// "bool": {
// "must": {
// "range": {
// "access.time": {
// "gte": "$start",
// "lte": "$end"
// }
// }
// }
// }
// }
// }"""
val tp = 1
val query: String =
s"""{
"query": {"match_all": {}},
"filter" : {
"bool": {
"must": [
{"term" : {"access.type" : $tp}},
{
"range": {
"access.time": {
"gte": "$start",
"lte": "$end"
}
}
}
]
}
}
}"""
val rdd1 = sc.esRDD("accesslog", query)
println(rdd1.collect().toBuffer)
println(rdd1.collect().size)
}
}
package game
import redis.clients.jedis.{Jedis, JedisPool, JedisPoolConfig}
/**
* Created by root on 2016/5/24.
*/
object JedisConnectionPool{
val config = new JedisPoolConfig()
//最大连接数,
config.setMaxTotal(10)
//最大空闲连接数,
config.setMaxIdle(5)
//当调用borrow Object方法时,是否进行有效性检查 -->
config.setTestOnBorrow(true)
val pool = new JedisPool(config, "172.16.0.101", 6379)
def getConnection(): Jedis = {
pool.getResource
}
def main(args: Array[String]) {
val conn = JedisConnectionPool.getConnection()
val r = conn.keys("*")
println(r)
}
}
package game
import kafka.serializer.StringDecoder
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Milliseconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by root on 2016/5/24.
*/
object ScannPlugins {
def main(args: Array[String]) {
val Array(zkQuorum, group, topics, numThreads) = Array("node-1.itcast.cn:2181,node-2.itcast.cn:2181,node-3.itcast.cn:2181", "g0", "gamelog", "1")
val dateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
val conf = new SparkConf().setAppName("ScannPlugins").setMaster("local[4]")
val sc = new SparkContext(conf)
//C产生数据批次的时间间隔10s
val ssc = new StreamingContext(sc, Milliseconds(10000))
//如果想要在集群中运行该程序,CheckpointDir设置一个共享存储的目录:HDFS
sc.setCheckpointDir("c://ck0710")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val kafkaParams = Map[String, String](
"zookeeper.connect" -> zkQuorum,
"group.id" -> group,
"auto.offset.reset" -> "smallest"
)
val dstream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicMap, StorageLevel.MEMORY_AND_DISK_SER)
//取出kafka的内容
val lines = dstream.map(_._2)
//用制表符切分数据
val splitedLines = lines.map(_.split("\t"))
val filteredLines = splitedLines.filter(f => {
val et = f(3)
val item = f(8)
et == "11" && item == "强效太阳水"
})
val userAndTime: DStream[(String, Long)] = filteredLines.map(f => (f(7), dateFormat.parse(f(12)).getTime))
//安装时间窗口进行分组
val grouedWindow: DStream[(String, Iterable[Long])] = userAndTime.groupByKeyAndWindow(Milliseconds(30000), Milliseconds(20000))
val filtered: DStream[(String, Iterable[Long])] = grouedWindow.filter(_._2.size >= 5)
val itemAvgTime = filtered.mapValues(it => {
val list = it.toList.sorted
val size = list.size
val first = list(0)
val last = list(size - 1)
val cha: Double = last - first
cha / size
})
val badUser: DStream[(String, Double)] = itemAvgTime.filter(_._2 < 10000)
badUser.foreachRDD(rdd => {
rdd.foreachPartition(it => {
// val connection = JedisConnectionPool.getConnection()
// it.foreach(t => {
// val user = t._1
// val avgTime = t._2
// val currentTime = System.currentTimeMillis()
// connection.set(user + "_" + currentTime, avgTime.toString)
// })
// connection.close()
it.foreach(t => {
println(t._1)
})
})
})
//filteredLines.print()
ssc.start()
ssc.awaitTermination()
}
}
package game
import java.text.SimpleDateFormat
import java.util.Calendar
/**
* Created by root on 2016/5/23.
*/
object TimeUtils {
val simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val calendar = Calendar.getInstance()
def apply(time: String) = {
calendar.setTime(simpleDateFormat.parse(time))
calendar.getTimeInMillis
}
def getCertainDayTime(amount: Int): Long ={
calendar.add(Calendar.DATE, amount)
val time = calendar.getTimeInMillis
calendar.add(Calendar.DATE, -amount)
time
}
}

















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









