






锁的作用
首先要明白mysql设计锁的作用是什么?
首先大家都知道MVCC(多版本并发控制),实现的事务,那么事务的隔离性级别是怎么实现的呢。其实就是加锁的粒度的大小。隔离级别越高锁的粒度越大。粒度最小就是行级锁。而且隔离级别Serializable实现了读锁,多事务之间读的时候都会进行加锁。
如果查看锁?
要解决死锁或者其他锁的问题,首先得知道如何查看加锁状态。
- 手动增加表锁
lock table 表名称 read(write),表名称2 read(write);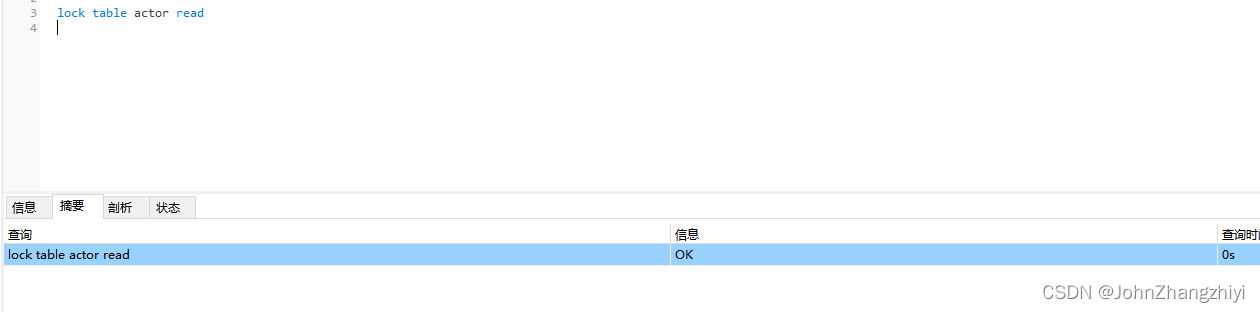
- 查看表上加过的锁
show open tables;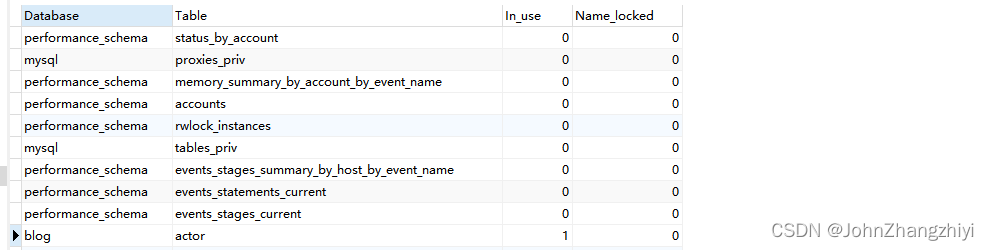
可以看到 in_use 代表 actor这个表正在被使用,其实就是加锁了
- 删除表锁
unlock tables;
可以看到 actor 这个表没有在使用了 其实就是锁删掉了
复现死锁:
看现在还没有锁等待
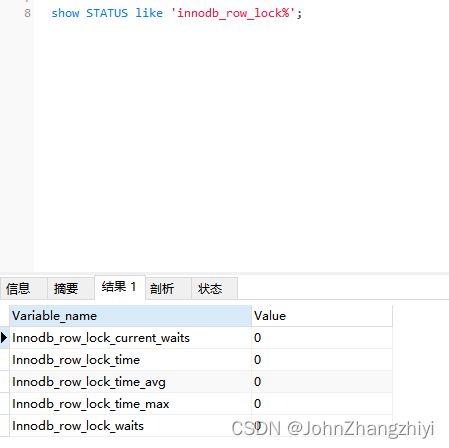
事务1
set tx_isolation='repeatable-read';
BEGIN;
select * from article where id=1 for update;
select * from article where id=2 for update;事务2
set tx_isolation='repeatable-read';
BEGIN;
select * from article where id=2 for update;
select * from article where id=1 for update;
查看锁状态
show STATUS like 'innodb_row_lock%';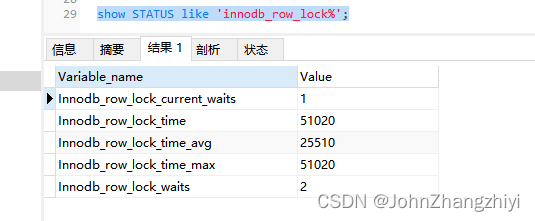
现在出现死锁了,出现有一个锁等待的数量就是说明有死锁存在了
对各个状态量的说明如下:
Innodb_row_lock_current_waits: 当前正在等待锁定的数量
Innodb_row_lock_time: 从系统启动到现在锁定总时间长度
Innodb_row_lock_time_avg: 每次等待所花平均时间
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花时间
Innodb_row_lock_waits: 系统启动后到现在总共等待的次数
-- 查看锁等待
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;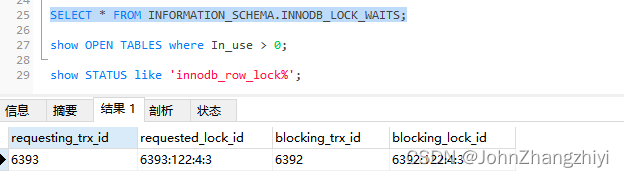
-- 查看锁
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;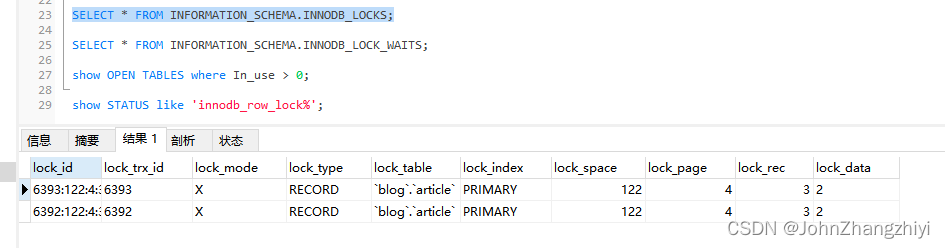
-- 查看事务
select * from INFORMATION_SCHEMA.INNODB_TRX;
解决
1,通过以下语句删掉锁等待的id kill trx_mysql_thread_id(等待的id)
2,等待锁的线程到最大等待时间,就不会继续等待了,然后第一个事务完成提交之后,第二个事务执行就不会发生死锁了
优化
1,尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
2,合理设计索引,尽量缩小锁的范围
3,尽可能减少检索条件范围,避免间隙锁
4,尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql尽量放在事务最后执行
5,尽可能用低的事务隔离级别















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









