







阅读文本大概需要 5 分钟。
我们先来看看 MRV1 版本的时候,资源是如何调度管理的?
MRV1 如下图,大型的 Hadoop 集群出了由单个 JobTracker 导致的可伸缩性瓶颈。由于此限制,必须创建和维护更小的、功能更差的集群。
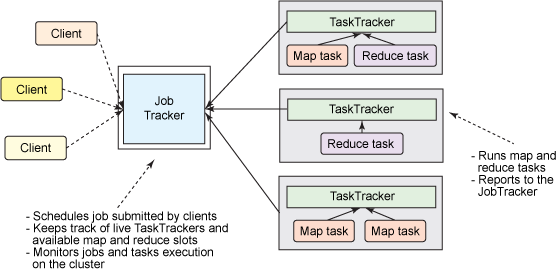
如上图,可以看出 JobTracker 具有两种不同的职责:
管理集群中的计算资源,这涉及到维护活动节点列表、可用和占用的 map 和 reduce slots 列表,以及依据所选的调度策略将可用 slots 分配给合适的作业和任务
协调在集群上运行的所有任务,这涉及到指导 TaskTracker 启动 map 和 reduce 任务,监视任务的执行,重新启动失败的任务,推测性地运行缓慢的任务,计算作业计数器值的总和,等等
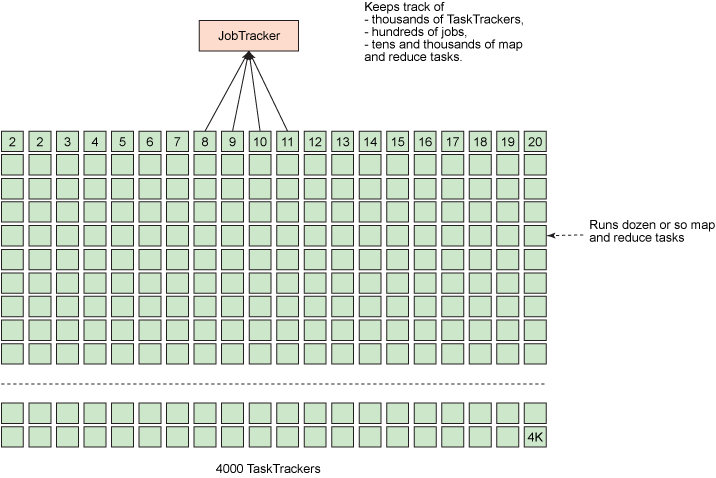
为单个进程安排大量职责会导致重大的可伸缩性问题,尤其是在较大的集群上,JobTracker 必须不断跟踪数千 TaskTracker、数百个作业,以及数万个 map 和 reduce 任务。下图演示了这一问题。相反,TaskTracker 通常近运行十来个任务,这些任务由勤勉的 JobTracker 分配给它们。
接下来,Yarn 要登场了。
于是,Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的;将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。
ResourceManager:负责整个集群的资源管理和调度。
ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等。
它就是 Yarn。
Yarn 的基本思想是将资源管理和作业调度/监视功能拆分为单独的守护进程。其想法是拥有一个全局资源管理器(RM)和每个应用程序应用程序主控器(AM)。应用程序可以是单个作业,也可以是一个DAG作业。
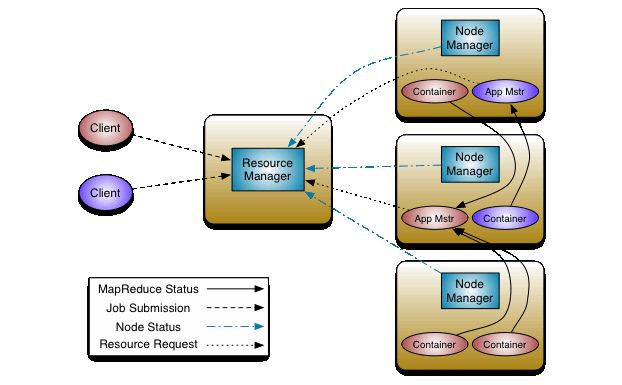
分工更加明细了,注意这里出现了 RM, AM, NM 他们分别发挥着什么作用呢?
在 YARN 架构中,一个全局 ResourceManager 以主要后台进程的形式运行,它通常在专用机器上运行,在各种竞争的应用程序之间仲裁可用的集群资源。ResourceManager 会追踪集群中有多少可用的活动节点和资源,协调用户提交的哪些应用程序应该在何时获取这些资源。ResourceManager 是惟一拥有此信息的进程,所以它可通过某种共享的、安全的、多租户的方式制定分配(或者调度)决策(例如,依据应用程序优先级、队列容量、ACLs、数据位置等)。
在用户提交一个应用程序时,一个称为 ApplicationMaster 的轻量型进程实例会启动来协调应用程序内的所有任务的执行。这包括监视任务,重新启动失败的任务,推测性地运行缓慢的任务,以及计算应用程序计数器值的总和。这些职责以前分配给所有作业的单个 JobTracker。ApplicationMaster 和属于它的应用程序的任务,在受 NodeManager 控制的资源容器中运行。
NodeManager 是 TaskTracker 的一种更加普通和高效的版本。没有固定数量的 map 和 reduce slots,NodeManager 拥有许多动态创建的资源容器。容器的大小取决于它所包含的资源量,比如内存、CPU、磁盘和网络 IO。
接下来,分析一个任务提交的流程,加深我们队 Yarn 资源调度框架的理解。
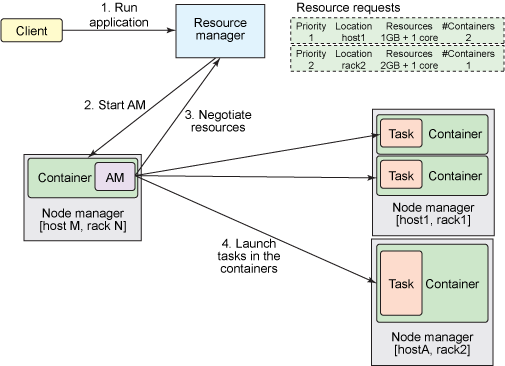
Client 将应用程序提交到 ResourceManager。ResourceManager 维护着集群上运行的应用程序列表,以及每个活动的 NodeManager 上的可用资源列表。ResourceManager 需要确定哪个应用程序接下来应该获得一部分集群资源。该决策受到许多限制,比如队列容量、ACL 和公平性。
ResourceManager 使用一个可插拔的 Scheduler。Scheduler 仅执行调度;它管理谁在何时获取集群资源(以容器的形式),但不会对应用程序内的任务执行任何监视,所以它不会尝试重新启动失败的任务。
在 ResourceManager 接受一个新应用程序提交时,Scheduler 制定的第一个决策是选择将用来运行 ApplicationMaster 的容器。在 ApplicationMaster 启动后,它将负责此应用程序的整个生命周期。首先也是最重要的是,它将资源请求发送到 ResourceManager,请求运行应用程序的任务所需的容器。资源请求是对一些容器的请求,用以满足一些资源需求,比如:一定量的资源,目前使用 MB 内存和 CPU 份额来表示,一个首选的位置,由主机名、机架名称指定,或者使用 * 来表示没有偏好,此应用程序中的一个优先级,而不是跨多个应用程序。
如果可能的话,RM 会分配一个满足 ApplicationMaster 在资源请求中所请求的需求的容器(表达为容器 ID 和主机名)。该容器允许应用程序使用特定主机上给定的资源量。分配一个容器后,ApplicationMaster 会要求 NodeManager(管理分配容器的主机)使用这些资源来启动一个特定于应用程序的任务。此任务可以是在任何框架中编写的任何进程(比如一个 MapReduce 任务)。
NodeManager 不会监视任务;它仅监视容器中的资源使用情况,举例而言,如果一个容器消耗的内存比最初分配的更多,它会结束该容器。
ApplicationMaster 会竭尽全力协调容器,启动所有需要的任务来完成它的应用程序。它还监视应用程序及其任务的进度,在新请求的容器中重新启动失败的任务,以及向提交应用程序的客户端报告进度。应用程序完成后,ApplicationMaster 会关闭自己并释放自己的容器。
尽管 ResourceManager 不会对应用程序内的任务执行任何监视,但它会检查 ApplicationMaster 的健康状况。如果 ApplicationMaster 失败,ResourceManager 可在一个新容器中重新启动它。您可以认为 ResourceManager 负责管理 ApplicationMaster,而 ApplicationMasters 负责管理任务。
不知道你们注意到没有?图中的 ResourceManager 都是单节点的。在实际中并不是单节点存在的,但是同一时刻只有一个节点在服务,另一个是 HA,作为主 RM 的备灾。
理解它的 HA 配置原理不难。
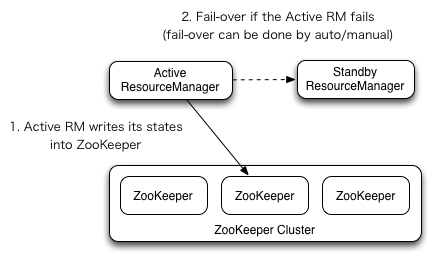
ResourceManager HA是通过/standby体系结构实现的-在任何时间点,其中一个RMS处于活动状态,并且一个或多个RMS处于待机模式,等待在active的RM发生任何故障时接管。
正常情况下,发生故障是,会进行自动切换,如果需要手动切换的时候,可以使用命令 yarn rmadmin 把现在的 active 状态的 RM 切换成待命状态,然后在其他一台 standby 状态的机器上,执行 yarn rmadmin 来唤醒到 active 状态。
自动切换的原理和NameNode HA 故障转移的原理一致。大家可以看这篇文章复习一下:Hadoop HA 深度解剖
在这里也简单说一下,RM 可以选择嵌入基于ZooKeeper的ActiveStatandByElector来决定哪个RM应该是活动的。当活动停止或无响应时,会自动选择另一个RM作为活动RM,然后由该RM接管。注意,没有必要像hdfs那样运行单独的zkfc守护进程,因为嵌入在rms中的activestandbyelector充当故障检测器和引导选择器,而不是单独的zkfc守护进程。
下面是 Ha 的配置示例,yarn-site.xml
<property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>cluster1</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>master1</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>master2</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>master1:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>master2:8088</value></property><property><name>yarn.resourcemanager.zk-address</name><value>zk1:2181,zk2:2181,zk3:2181</value></property>
(完)
本文分享自微信公众号 - 大数据每日哔哔(bb-bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。














 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









