









一、问题引入:
相信大部分初学者在开始做算法题的时候,碰到字符串的匹配,一般都会优先使用朴素算法(暴力算法),我也是一个暴力算法的迫害者之一。
例如:现在有一个文本串S=“BBC ABCDAB ABCDABCDABDE”和一个搜索串(模式串)p="ABCDABD",要查找p在s中的位置。(暴力算法的代码就不贴了,此算法的时间复杂度最好为O(n+m)、最坏为O(nm))
这样只能一个一个的去匹配,虽然可以得出想要的结果,但是这样相对来说效率过于低,所以这次我们可以使用KMP算法进行来求解。
二、KMP:
2.1、定义和next的公式
Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
可以这样简单理解,KMP是一种改进的字符串匹配算法,关键在于利用匹配失败后的信息,尽量减少模式串和主串的匹配次数达到快速匹配的目的。他最主要的关键点在于如何求得next()函数,函数本身包含的模式串的局部匹配信息,下面有个公式可以先了解下
公式1:这个公式计算得出next数组,kmp的移动需要根据next数组表的公式进行移动,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值

当然,在不同的地方介绍,也有另外形式的公式,公式2:这个公式计算适用于是根据根据最大长度表得出的next数组,失配时,模式串向右移动的位数 = 已经匹配的字符数 - 失配字符的上一位字符的最大长度值
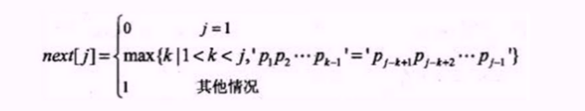
其实,两条公式本质上是一样的,不同点在于“j”的值不同,当然了,计算出来的值也就相差为1。所以,如果在软考中(软考必考题之一),或者是其他算法题目中,有明确给出公式,就必须按照给的公式来做,而不是按照自己的印象来做。
2.2,步骤
先来讲讲KMP是怎么去匹配的。
这里我先按照p="ABCDABD"和公式1给出一个next的匹配值
| j值 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| P值 | A | B | C | D | A | B | D |
| next数组 | -1 | 0 | 0 | 0 | 0 | 1 | 2 |
然后根据《next 数组》,失配时,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值

开始匹配时,i=0;j=0;发现A和B失配,次数配串需要移动的 0-(-1)=1得到下面的图,

依次匹配,直到 i=4 ,此时,j=0,发现s[4]=p[0],即下图

此时,继续往下走,直到发现 s[10]是个空格字符,而p[6]=D,失配。
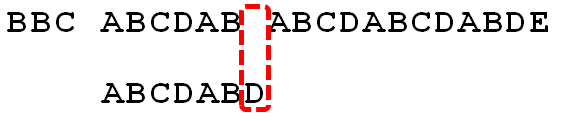
根据《next 数组》,失配时,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值 ,将P串进行移动6-2=4位,如下图

又开始进行匹配,发现,s[10]和p[2]失配。
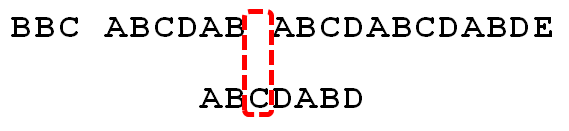
继续根据公式,进行移动2-0=2,得出下图
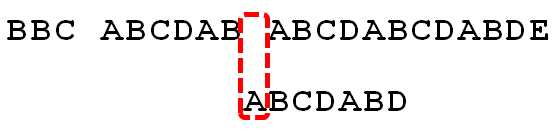
此时s[10]和p[0]再次失配,在继续移动0-(-1)=1位,移动后,s[11]和p[0]相等,j++、i++继续匹配

直到 s[17]和p[6]失配,继续根据《next数组表》的公式,进行移动6-2=4位,得出下图,最终,匹配成功

以上就是kmp的基本的操作过程。
接下来我们来讲讲next是怎么去算的。
2.3、计算next值
了解next值的计算时,我们先需要了解三个关键词语,“前缀”、“后缀”和“最大前缀后缀公共元素长度”。
前缀,是指除了最后一个字符以外,一个字符串的全部头部组合。例如:ABCD,除了D,头部合元素有,A、AB、ABC
后缀,是指除了第一个字符以外,一个字符串的全部尾部组合。例如:ABCD,除了A,尾部组合D、CD、BCD。
这时候有人是不是有疑问,为什么尾部组合不是B、BC和BCD呢,没错,我之前也有这个疑问。后来我思前想后,发现,前面有个关键字眼“头部组合”和“尾部组合”。如果真的可以B、BC和BCD,那么这个不叫尾部组合,而是叫组合。(这里我也是单纯这样理解而已,有更加深刻理解的大佬,欢迎在评论区帮我指正)。
最大前缀后缀公共元素长度,顾名思义,就是前缀和后缀中的元素组合中有想同的最长的元素长度。例如下面这张表

“A”的前缀和后缀都是空集,共有长度为0依次类推下去就是上面的表了。
这个也可以叫做最大长度表,同样也可以用作计算KMP的移动位置,当然了,此时的公式跟next数组的公式不同。

上面是最大长度表的计算,下面开始next的计算,我们按照之前给的next公式和上面的表格来看
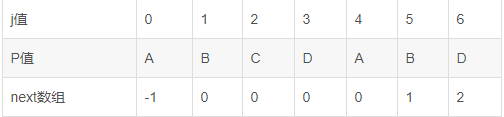
当j=0时,next[0]=-1;
当j=1时,就公式来看,k必然整数,那么不符合0<k<1,就是第三中情况,next[1]=0;
当j=2时,符合0<k<2,所以k=1,所以p0=P(2-1)=p1,此时,我们发现,p0=A而p1=B,明显不相等,所以此时公式不成立,属于第三种情况,所以next[2]=0;
当j=3时,k的取值有1和2,我们先取k=2代入,有p0p1=AB,p(3-2)p(3-1)=p1p2=BC ,式子不相等,k=2不成立,取k=1代入,p0=A,p(3-1)=p2=C,式子不相等,那么就是第三种情况了。所以next[3]=0;
当j=4时,k的取值有1、2、3,先取k=3代入,有p0p1p2=ABC, p1p2p3=BCD 式子不相等,k=3不成立;取k=2代入,有p0p1=AB ,p2p3=CD ,式子不相等,k=2不成立;取k=1代入,有p0=A ,p3=D,式子不相等,k=1不成立,那么就是第三种情况了。所以next[4]=0;
当j=5时,k的取值有1、2、3,4,先取k=4代入,有p0p1p2p3=ABCD ,p1p2p3p4=BCDA,式子不相等,k=4不成立,取k=3代入,有p0p1p2=ABC,p2p3p4=CDA,式子不相等,k=3不成立;取k=2代入,有p0p1=AB,p3p4=DA,式子不相等,k=2不成立;取k=1代入,有p0=A ,p4=A,此时,p0=p4,所以next[5]=1;
当j=6时,k的取值有1、2、3、4、5,先取k=5代入,有p0p1p2p3p4=ABCDA,(依次类推吧,写累了,直到k=2),当k=2时,有p0p1=AB,p4p5=AB ,式子相等,所以next[6]=2
所以可以得去这样的表格

以上,就是next的计算方式。
(如果觉得下面会混乱你之前的思维的话,那么就不建议了解了)
如果你按照的是下面的这个公式计算的话,那么J的起始值是等于1,相当与跟上面算出来的值全部都加1而已,

| j值 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| P值 | A | B | C | D | A | B | D |
| next数组 | 0 | 1 | 1 | 1 | 1 | 2 | 3 |
最终,我们拿到这个next值,根据根据《next 数组》,失配时,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值
当然也有另外的一个公式是根据《最大长度表》,进行计算,失配时,模式串向右移动的位数 = 已经匹配的字符数 - 失配字符的上一位字符的最大长度值
| j值 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| P值 | A | B | C | D | A | B | D |
| 最大长度表 | 0 | 0 | 0 | 0 | 1 | 2 | 0 |
这个什么意思呢,做个例子,就是ABCDABD,已经匹配了前面6位,即ABCDAB,发现第七位的D失配了,此时的跳跃位置就是要6-2=4,移动四位。
到此,我个人对KMP和next的理解就介绍完了,我们回归第一个点,问题引入,根据KMP算法,写一下代码
package KMP;
/**
* @date 2021-04-21
*/
import java.util.Arrays;
public class KMP {
public static void main(String[] args) {
String str1 = "BBC ABCDAB ABCDABCDABDE";
String str2 = "ABCDABD";
int[] next = kmpNext("ABCDABD");
System.out.println("next数组" + Arrays.toString(next));
int index = kmpSearch(str1, str2, next);
System.out.println("index:" + index);
//利用java里面的indexOf函数帮我们验证答案
System.out.println("index:" + str1.indexOf(str2));
}
public static int kmpSearch(String str1, String str2, int[] next) {
for (int i = 0, j = 0; i < str1.length(); i++) {
//需要处理 str1.charAt(i) != str2.charAt(j), 去调整 j 的大小
while (j > 0 && str1.charAt(i) != str2.charAt(j)) {
j = next[j - 1];
}
if (str1.charAt(i) == str2.charAt(j)) {
j++;
}
if (j == str2.length()) {
return i - j + 1;
}
}
return -1;
}
/*
这是计算最大长度表,并非直接计算next值
*/
public static int[] kmpNext(String str) {
int[] next = new int[str.length()];
next[0] = 0;
for (int i = 1, j = 0; i < str.length(); i++) {
while (j > 0 && str.charAt(i) != str.charAt(j)) {
j = next[j - 1];
}
if (str.charAt(i) == str.charAt(j)) {
j++;
}
next[i] = j;
}
return next;
}
}

三、参考资料
从头到尾彻底理解KMP(2014年8月22日版) https://blog.csdn.net/v_july_v/article/details/7041827 (这一篇讲得非常棒,建议大家可以去看下)
(算法)通俗易懂的字符串匹配KMP算法及求next值算法 https://blog.csdn.net/qq_37969433/article/details/82947411(这一篇也不错,有动图,也是讲得很好)















 9022
9022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









