






动态网页即不再是加载后立即下载所有页面内容。这样就会造成许多网页在浏览器中展示的内容不会出现在 HTML 源码中。于是就无法用静态网页的下载方法下载了。
对于这种动态网页的下载,一般有两种方法。
(1)JavaScript 逆向工程
比如一个搜索网页, firebug 显示 HTML 如下
<div class="container">
<header class="mastheader row" id="header">
<section id="main" class="main row">
<div class="span12">
<form>
<div id="results">
<table>
<tbody>
<tr>
<td>
<div>
<a href="/view/Afghanistan">
</div>
</td>
</tr>
</tr>
但是我们用如下的代码下载失败了
import lxml.html
from downloader import Downloader
D = Downloader()
html = D("http://example.webscraping.com/search") # 该搜索页面的地址
tree = lxml.html.fromstring(html)
tree.cssselect("div#results a")检查网页源代码可以帮助我们了解抽取操作为什么失败。在源代码中,可以发现我们准备抓取的 div 元素实际上是空的。
<div id="results">
</div>而以上 firebug 显示给我们的却是网页的当前状态,也就是使用 JavaScript 动态加载完搜索结果之后的网页。这就是静态网页下载方法失败的原因。
我们对 JavaScript 进行逆向工程,在 Firebug 中单击 Console 选项卡,然后执行一次搜索,我们将会看到一个 AJAX 请求,如下图所示:
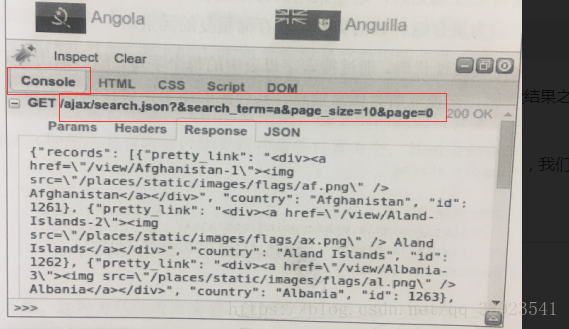
这就是使用 firebug 对 JavaScript 进行的逆向工程,可以看到 AJAX 响应返回的数据是 Json 格式的,因此我们可以用 json 解析。我们在代码中使用该请求的链接和json 数据:
import json
import string
template_url = 'http://example.webscraping.com/ajax/search.josn?&search_term={}&page_size=10&page=0'
for letter in string.lowercase: # 遍历搜索 a-z
html = D(template_url.format(letter))
try:
ajax = json.loads(html)
...
也可以用 "." 来表示全部搜索条件,即搜索全部。
template_url = 'http://example.webscraping.com/ajax/search.josn?&search_term={}&page_size=10&page=0'
html = D(template_url.format("."))
ajax = json.loads(html)
for record in ajax["records"]:
row = [record[field] for field in FIELDS]
writer.writerow(row)
(2)selenium 驱动浏览器运行
2.1 python selenium 安装
安装很简单,一般使用火狐浏览器运行,所以一般先安装火狐浏览器: pip install selenium
但是还要处理一些小细节,否则后面运行报错:
1.下载 geckodriver.exe 地址:https://github.com/mozilla/geckodriver/releases 根据系统版本下载
2.下载后解压将 geckodriver.exe 复制到火狐的安装目录下,并将此目录配置环境变量 Path
3.重启 cmd
Ubuntu 解决方法:
1.下载 geckodriverckod 地址: https://github.com/mozilla/geckodriver/releases
2.解压后将geckodriverckod 存放至 /usr/local/bin/ 路径下即可
2.2 selenium 方法
from selenium import webdriver
driver = webdriver.Firefox() # 火狐驱动,此时会弹出一个空的火狐浏览器窗口
# 想要在选定的浏览器中加载网页,可以调用 get() 方法,执行后会弹出指定的网页窗口
driver.get("http://example.webscraping.com/search") # 这个就是前面示例的动态搜索网页
# 找到搜索文本框后,可以通过 send_keys() 方法输入内容,模拟键盘输入
# search_term 就是前面逆向工程解析的 ajax 请求ID
driver.find_element_by_id("search_term").send_keys(".") # "." 代表全部
# 设置每页显示的数量为 1000
js = "document.getElementById('page_size').options[1].text='1000'"
driver.execute_script(js)
# 模拟点击搜索按钮 点击 search
driver.find_element_by_id("search").click()
# 等待 AJAX 请求加赞完毕,等待 30s
driver.implicitly_wait(30)
# 使用 CSS 选择器获取国家链接
links = driver.find_element_by_css_selector('#results a')
# 抽取链接文本,并创建一个国家列表
countries = [link.text for link in links]
print countries
# 关闭浏览器
driver.close()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









