







目录
PCA
- 介绍:主成分分析法,在用统计分析方法研究多变量的课题时,变量个数太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,将重复的变量(关系紧密的变量)删去多余,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。
- 过程总结:就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
- 步骤:
- (1) 特征归一化(归一化方式是用每个特征减去列均值,再除以列标准差)
- (2) 计算协方差矩阵(协方差矩阵满足对称正定)
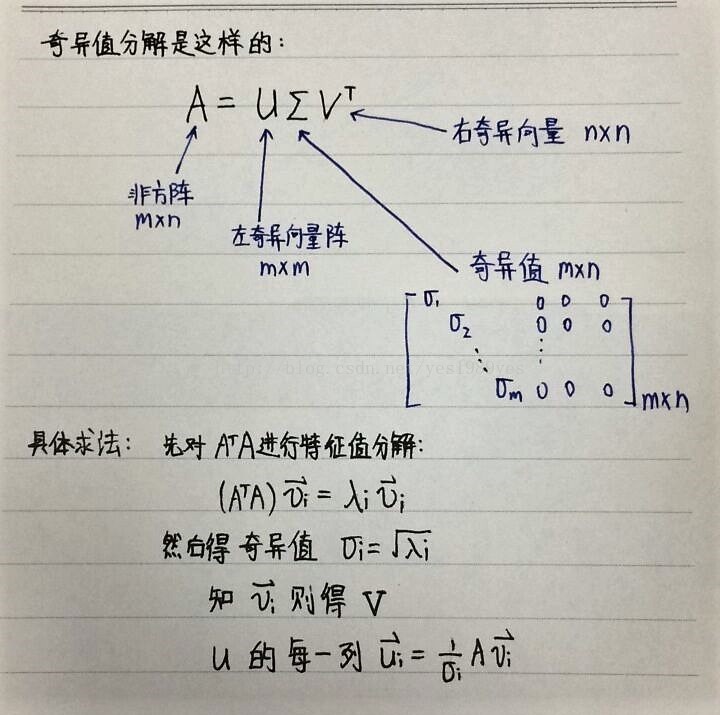
- (3) 对协方差矩阵做奇异值分解,得到U
- (4) 从U中取出前k列(Ur),得到降维后的Z=X*Ur
- 这里提一下特征值与奇异值的区别:并不是所有的矩阵都有特征值,只有方阵才有,而其实更多的矩阵都不是方阵,这里特征值的推广就是奇异值,也可以这么描述一下,特征值只是一个类似数组,它只涉及到矩阵的缩放也就是线性变化,而奇异值是一个矩阵,它设计到矩阵的缩放、旋转、投影。
K-means
- 首先说一下聚类算法:聚类算法是一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。聚类算法与分类算法最大的区别是:聚类算法是无监督的学习算法,而分类算法属于监督的学习算法。在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
- K-means介绍:基本K-Means算法的思想很简单,事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心(即为类中心),重复这样的过程,知道质心不再改变,最终就确定了每个样本所属的类别以及每个类的质心。由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。4
步骤:
- 初始化常数K,随机选取初始点为质心
- 计算样本与每个质心之间的相似度,将样本归类到最相似的类中
- 重新计算质心
- 重复上面两个步骤,知道满足终止条件
- 输出最终的质心以及每个类
Kmeans算法的缺陷
- 聚类中心的个数K 需要事先给定,但在实际中这个 K 值的选定是非常难以估计的,很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适
- Kmeans需要人为地确定初始聚类中心,不同的初始聚类中心可能导致完全不同的聚类结果。
SVM(支持向量机)
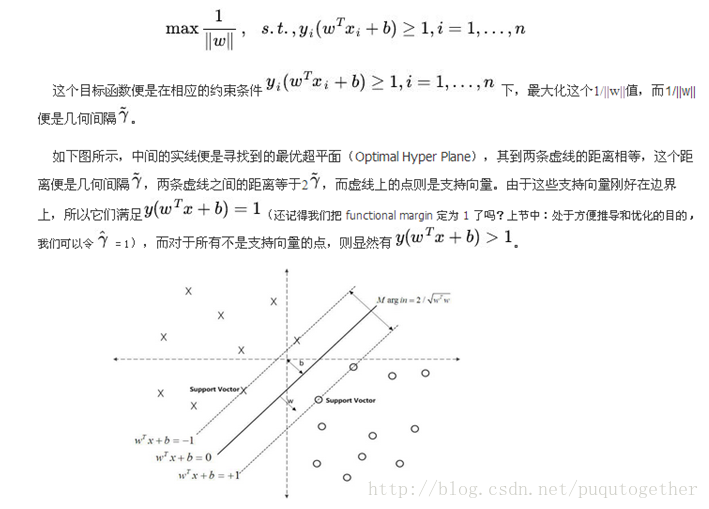
- 首先先大致的了解一下SVM:他的目的是找到一个最优分类面来对数据进行分类,这个分类面可能是线,平面,超平面。所以SVM实际上可以将其转化为一个寻找这个最优面的过程。
具体过程:
可以参考这个链接(算是我看到写的较好的一个)-















 5512
5512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









