







一开始接触到Linux page cache时,就有一些疑问。Linux page cache很大,一般的文件读写是怎么通过虚拟内存访问的,一开始便想到的是通过mmap的机制,将文件映射到用户层的虚拟内存区间,然后通过触发page fault来从文件中读取,后来发现并不是这样,我们先来看下linux 的page cache的存储方式。
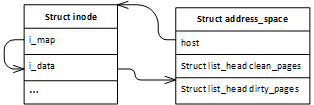
page cache是存放在struct inode中的,通过struct address_space(i_data)中的iru链表,串联起了该文件所有的page cache,所以这个page cache是一个全局性质的资源。
那么每个进程通过一般的文件的写过程进入内核态的时候,又是如何通过操作page cache的呢?我们之前提到过,每个进程拥有独立的4GB的虚拟内存区间(32位操作系统),其中低3GB是用户空间,高1GB是内核空间,在父进程在创建子进程时会将高1GB内核空间的页表拷贝,这样每个进程在内核空间中的映射都是一样的,可以说内核空间是所有进程的全局段。
既然page cache是全局属性。那么把page cache在内核空间申请行不行呢,答案是不行。内核空间内存太小,又存储这许多重要的资源,将page cache这么大的资源存储进来显然是不合适的。那么使用用户空间合不合适呢?那占用用户空间的虚拟内存显然是更不合适的。所以,内核访问page cache的方式实际上是通过高端内存访问。
关于高端内存的讲解,这里不说明,有兴趣的同学可以去了解下。
高端内存有一个问题,就是内核映射的高端内存是非常少的,内核在高端内存处建立的映射不能一直存在。我们看下处理page cache时,是怎么做的。
我们以Linux 2.4.0代码为例:(我看了下3.10.0的代码处理方式都一样)
文件的读写是通过sys_write系统调用实现的,这里我们省略大部分的流程:
|-sys_write()
|--generic_file_write()
|--while() //循环处理每一个page cache
|--__grab_cache_page() //寻找page cache,找不到分配一个
|--block_prepare_write() //将数据读入page cache ,并和buffer head建立映射
|--generic_commit_write() //往page cache中写入数据//sys_write->generic_file_write->block_prepare_write
static int __block_prepare_write(struct inode *inode, struct page *page, //做准备就是使有关记录块缓冲区的
unsigned from, unsigned to, get_block_t *get_block) //内容与设备上相关记录块的内容相一致
{
unsigned block_start, block_end;
unsigned long block;
int err = 0;
unsigned blocksize, bbits;
struct buffer_head *bh, *head, *wait[2], **wait_bh=wait;
char *kaddr = kmap(page); //开始了高端内存的映射
blocksize = inode->i_sb->s_blocksize;
if (!page->buffers)
create_empty_buffers(page, inode->i_dev, blocksize); //创建并初始化buffer_head
head = page->buffers;
bbits = inode->i_sb->s_blocksize_bits; //数据块大小, 一般为10 ,1024
block = page->index << (PAGE_CACHE_SHIFT - bbits); //对于i386 为12-10 = 2, block为逻辑记录块号
for(bh = head, block_start = 0; bh != head || !block_start; //
block++, block_start=block_end, bh = bh->b_this_page) {
if (!bh) //
BUG();
block_end = block_start+blocksize;
if (block_end <= from)
continue;
if (block_start >= to)
break;
if (!buffer_mapped(bh)) { //如果没有建立起映射
err = get_block(inode, block, bh, 1); //ext2_get_block
if (err)
goto out;
if (buffer_new(bh)) {
unmap_underlying_metadata(bh);
if (Page_Uptodate(page)) {
set_bit(BH_Uptodate, &bh->b_state);
continue;
}
if (block_end > to)
memset(kaddr+to, 0, block_end-to);
if (block_start < from)
memset(kaddr+block_start, 0, from-block_start);
if (block_end > to || block_start < from)
flush_dcache_page(page);
continue;
}
}
if (Page_Uptodate(page)) {
set_bit(BH_Uptodate, &bh->b_state);
continue;
}
if (!buffer_uptodate(bh) && //对于已经建立起映射,检查记录块是否一致, 不一致就通过ll_rw_block从磁盘读取
(block_start < from || block_end > to)) {
ll_rw_block(READ, 1, &bh);
*wait_bh++=bh;
}
}
/*
* If we issued read requests - let them complete.
*/
while(wait_bh > wait) {
wait_on_buffer(*--wait_bh);
err = -EIO;
if (!buffer_uptodate(*wait_bh))
goto out;
}
return 0;
out:
return err;
} block_prepare_write是为文件的写入,准备好已经从磁盘读入数据的page cache,在创建好了page cache后,通过kmap建立高端内存的映射,那么该映射是如何解除的呢
我们来看下面的函数
//sys_write->generic_file_write->generic_commit_write
int generic_commit_write(struct file *file, struct page *page,
unsigned from, unsigned to)
{
struct inode *inode = page->mapping->host;
loff_t pos = ((loff_t)page->index << PAGE_CACHE_SHIFT) + to;
__block_commit_write(inode,page,from,to);
kunmap(page); //解除高端内存映射
if (pos > inode->i_size) {
inode->i_size = pos;
mark_inode_dirty(inode);
}
return 0;
} 在实际写入page cache后,便解除了高端内存映射
也就是说处理一个page cache,就要建立一次高端内存映射,处理完成后,就解除对高端内存的映射
以上是自己的个人理解,如果有不对的地方,望指出,谢谢^ ^















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









