






一、超时问题带来的危害
说起超时控制,我们先来看看它带来的巨大危害:
-
用户体验差:用户在网页、App端使用时会出现响应缓慢,甚至报错问题;同时用户持续反复点击,会加重超时问题,拖垮整个系统。
-
系统吞吐量下降:请求处理时间增加,系统同时处理的请求量减少,吞吐量下降,可用率降低。
-
资源浪费:长时间占用资源未能有效利用,造成资源浪费。
-
系统稳定性降低:超时可能引起连锁反应,导致系统其他部分和外部系统也出现宕机风险。外部依赖时,可将外部线程池打满,从而影响整个链路稳定性。
超时和超时控制不合理往往带来很大的危害,严重影响公司的利益(事故频发)。由此可以看出,面对超时,我们要解决得当,做到可控。
二、超时问题的起因
介绍完超时的危害,接下来说一说为什么会出现超时问题。在应用中,超时问题通常是由于网络请求、硬件性能、线程执行时间过长三方面导致。主要原因包括:
-
网络延迟:当应用尝试连接远程服务器或服务时,如果网络延迟高,响应时间可能超过预设的超时限制。
-
资源争用:多个线程或进程同时访问同一资源(如数据库),可能导致一部分请求等待时间过长。这里可从死循环、死锁等情况研究。
-
服务瓶颈:被调用的服务处理请求的能力有限,当请求量超过其处理阈值时,会导致处理时间延长。这点可从系统负载情况来观测到。
-
代码效率低:程序本身算法效率低下或者存在死循环、慢SQL等问题,导致执行时间过长。
-
硬件问题:硬件本身性能不足,比如使用的不是内存,或者硬盘选择机械硬盘都会导致读取速度慢。
由此可见:超时问题成因很多,但我们需要做可控部分的优化,保证在同等硬件基础上,加快响应速度和保证系统稳定。硬件、网络延迟问题一般由运维处理,我们只需要关注服务瓶颈、代码效率、资源争用三个问题。
三、解决超时问题的策略
解决超时问题的策略分为两方面,第一方面是优化代码,避免出现超时问题,第二方面是优化超时时间控制,避免出现无限期等待,进行适当的降级处理。
1.设置合理的超时时间确保所有的网络请求和资源访问都设置了超时时间,避免无限等待。例如,在使用HttpClient时设置请求超时:
RequestConfig requestConfig =RequestConfig.custom()
.setConnectTimeout(5000)// 连接超时时间
.setSocketTimeout(10000)// 数据传输超时时间
.build();HttpClient client =HttpClientBuilder.create().setDefaultRequestConfig(requestConfig).build();
此外比较常使用的还有RPC调用、数据库连接、缓存连接等,一定要设置超时时间。不要相信任何外部依赖,做好自己的防线。
2.优化代码和算法对业务逻辑和算法进行优化,提高代码执行效率,减少响应时间。常见的方向有:
1)避免重复扫描,多层嵌套遍历。下面给出一个嵌套循环例子,当遍历的数组很大时,这就很低效了!
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
// 假设我们有一个非常大的列表
for (int i = 0; i < 100000; i++) {
numbers.add(i);
}
int targetSum = 99999;
long startTime = System.currentTimeMillis();
// 使用两个嵌套的循环来查找和为targetSum的两个数字
boolean found = false;
for (int i = 0; i < numbers.size() && !found; i++) {
for (int j = i + 1; j < numbers.size() && !found; j++) {
if (numbers.get(i) + numbers.get(j) == targetSum) {
found = true;
System.out.println("Found: " + numbers.get(i) + " + " + numbers.get(j));
}
}
}
if (!found) {
System.out.println("No pair found with the given sum.");
}
long endTime = System.currentTimeMillis();
System.out.println("Time taken: " + (endTime - startTime) + "ms");
}
最常用的手段使用哈希表进行存储数据,取数据时可以做到O(1)时间复杂度,相比较遍历循环高效很多。
2)杜绝死锁问题发生。如线程池的死锁,我们要避免竞争临界资源,同时要注意线程池资源隔离,同一线程池为多个场景提供处理时,任何一个场景出现超时问题,都会拖垮其他场景,同时要避免线程池中的阻塞队列出现死锁问题。
下面给出一个简单的死锁案例,可以进行延伸扩展,自己系统中是否有类似代码
public void method1() {
synchronized (resource1){
System.out.println(Thread.currentThread().getName() + " acquired resource 1");
try {
Thread.sleep(100); // 暂停一下,模拟做了一些工作
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (resource2) {
System.out.println(Thread.currentThread().getName() + " acquired resource 2");
}
}
}
public void method2() {
synchronized (resource2) {
System.out.println(Thread.currentThread().getName() + " acquired resource 2");
try {
Thread.sleep(100); // 暂停一下,模拟做了一些工作
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (resource1) {
System.out.println(Thread.currentThread().getName() + " acquired resource 1");
}
}
}
扩展到微服务场景下,会出现多个服务竞争同一把分布式锁场景,获取分布式锁时一定设置合理的超时时间,一般100ms足够了,获取不到锁走失败策略。
3)避免发生慢SQL。如果某一接口出现了慢SQL,毫无例外,这个接口都会出现超时问题,如果这个接口的访问非常频繁,会进而导致tomcat线程池被占满,整个系统进入瘫痪状态。
之前发生过一个事故案例,在MQ消费中,进行了数据库查询操作,碰巧这是个慢Sql,导致MQ消费极其缓慢,本来MQ的量级不大,但叠加了一个bug,导致消费失败,需要消费的MQ就出现了源源不断的现象,应用暂且抗住了,但由于应用与数据库之间的连接久久不能断开,链接池被打满,出现了无法创建连接的问题,应用所有功能也均不可用,重启恢复,不一会继续出现一样的问题,查询日志发现慢SQL,修复后不再出现。
另一种是没有慢SQL时,应用进行SQL操作缓慢,可以查看下当前应用与数据库的连接池大小,对比数据库当前连接数,若数据库的最大连接数尚有余量,未达到80%-90%,可考虑增加数据库连接池大小。
3. 资源和服务的扩容
1)对于经常出现超时的服务,观察系统的内存、cpu是否已经达到非常高的数值,这时候可以考虑增加资源。
2)如果未出现慢SQL问题,数据处理速度慢,可考虑增加数据库连接池大小,扩展服务器的计算能力等。同样可以扩展其他使用到的线程池大小。要注意观察整个系统的线程数,不一定线程数越多越快,警惕线程池被打满!
3)查看其他中间件的响应速度,比如Redis、RPC、ES等,若Redis的响应速度超过了100ms,考虑其他存储方式进行替代,这时并没有发挥出Redis的力量,本地缓存也不失为一种很好的解决方式,尤其在热点数据场景中。
4)考虑对存储组件Redis、Mysql进行扩容,分片处理,提高存储组件的响应速度。
5)服务自身的扩容
4. 异步处理
将一些耗时操作异步处理,如使用消息队列来缓冲和分配任务。这里不做过多阐述,主要注意异步均依靠线程池资源,需要合理设置线程数。
5. 使用缓存
对于重复请求相同资源的操作,使用缓存可以减少对后端服务的压力,降低响应时间。如Redis、本地缓存等。通过Redis实现布隆过滤器提前进行一层校验,也可以提高的数据处理能力,拒绝垃圾请求,保护系统
6. 超时重试机制
对于偶尔的网络抖动导致的超时,可以通过设置重试机制来解决。例如,使用开源库如Apache HttpClient的重试处理器:
HttpRequestRetryHandler retryHandler =newDefaultHttpRequestRetryHandler(3,true);HttpClient client =HttpClientBuilder.create().setRetryHandler(retryHandler).build();
7. 监控和报警实施监控机制
对超时频率和超时请求进行监控,设置报警系统,在出现问题时能够及时发现并处理。
8.超时控制
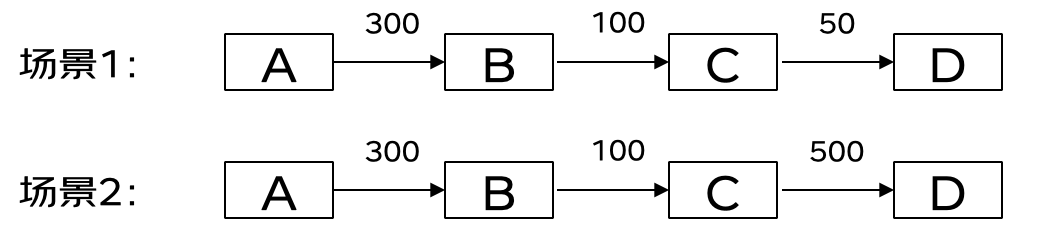
上述方法目的为降低响应时间,提高响应速度,接下来给出如何控制超时时间,降低对系统的影响。大多数组件都会强制要求设置超时时间,防止拖垮整个系统,但是这个时间设置多久,如何设置呢?
上面给出两个场景,第一个场景的超时时间呈现漏斗状,越向底层,超时时间越短,第二个场景在C请求D时超时时间很大。
第二个场景中,当C请求D时间达到了400ms时,首先在100ms时,B就中断了对C的响应,即使这时D返回了C结果,C也无法再返回给B结果了,超时时间毫无用处,但是一直在占用C和D的线程,最糟糕的问题就是上游系统还健在,下游都崩了。
综上分析,第一个场景是最为合理的,超时时间的设置呈现漏斗状,随着层级的深入,依次递减,当下游时间超时时,上游请求依然保持连接,整个链路的响应时间在300ms,处于可控范围内。
三、总结
面对超时,我们要降低发生的概率,同时做好强有力的防护,不相信任何三方组件和接口,绝对保证自己及上游系统的稳定性!

















 489
489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









