









论文题目:Fast R-CNN
论文地址:https://arxiv.org/abs/1504.08083
代码地址:https://github.com/Liu-Yicheng/Fast-RCNN
Fast R-CNN主要是解决RCNN重复计算卷积的问题,它的解决方案是,先对整个input图像做卷积,得到feature map,同时,用selective search将候选框选择出来,将候选区域在feature map上选出来,这样避免了对每个候选区域重复计算的问题,大大提高了计算速度。同时ROI pooling可以得到固定大小的输出。

一、对论文的解读
1、网络模型:VGG-16
2、single-stage training
RCNN的分类使用SVM,框回归使用一个线性网络,与RCNN对比,Fast RCNN使用一个网络同时进行分类和回归。
3、RCNN缺点:
(1)multi-stage pipeline:提取特征使用一个CNN,分类使用SVM,框回归使用另一个线性网络
(2)速度慢,因为要对每个候选区域进行卷积运算
4、SPP Net
SPP Net,Spatial pyramid Pooling Convolutional networks,空间金字塔池化卷积网络。与RCNN相比,RCNN喂入CNN的图像必须缩放到一定大小,而SPP Net可以喂入任意大小的图片。
它的原理是,黑色图片代表卷积之后的特征图,接着我们以不同大小的块来提取特征,分别是4*4,2*2,1*1,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial bins),我们从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。SPP Net网络如下:

因此,SPP Net可以将任意大小的图像转换为固定长度向量。
5、SPP Net 缺点
(1)同RCNN一样,multi-stage pipeline
(2)无法更新金字塔结构前的卷积层。SPP-Net中的fine-tuning的样本来自所有图像的所有ROI打散后均匀采样的,这导致SGD的每个batch的样本来自不同的图像,需要同时计算和存储这些图像的feature map,过程变得很expensive,所以不是不能fine-tuning卷积层,而是效率低。
6、Fast RCNN 优势
(1)single-stage 训练,使用multi-task loss
(2)training可以更新所有层
(3)不需要disk存储feature
(4)mAP更高
7、Fast RCNN网络结构图

将原图通过一个CNN网络进行卷积得到特征图,用selective search得到候选区域,在feature map上选择候选区域,输入到ROI pooling层进行最大池化,然后再通过全连接层得到两部分的输出,一部分是分类,另一部分是框回归。
8、Fast RCNN训练过程
(1)将整个image输入到CNN中,得到feature map
(2)用selective search 提取出region proposals
(3)对于每个候选区域,在feature map上提取固定大小的特征向量。(ROI pooling后就是固定大小的特征向量了)
(4)每个特征向量喂入全连接层,有两个输出:分类输出是k类的分类概率,框回归输出是用四个参数表示框的位置。
9、ROI pooling layer
ROI是一个矩形窗口,用4个参数(r,c,h,w)表示,分别是top-left corner(r,c)和它的height,width(h,w),根据输出向量的大小h*w(比如2*2)和候选feature map(即候选区域在feature map上的投影)的大小H*W(比如5*5),将候选feature map划分为(H/h,W/w)(比如(5/2,5/2)=(2,2)注意,此处向下取整),然后使用最大池化,即可获得固定大小的输出。
10、预训练网络
实验中用了3个预训练模型:
(1)“S”:CaffeNet(AlexNet from RCNN)
(2)“M”:VGG_CNN_1024,深度与“S”相同,但宽度更宽
(3)“L”:VGG16
同时,我们对预训练网络做了3个改进:
(1)最后一个最大池化层被ROI pooling代替
(2)一个全连接层换成两个并列的输出层(一个用于分类,一个用于框回归)
(3)有两种输入数据:a list of images,a list of ROIs in those images
11、关于RCNN效率低下的改进
(1)训练过程中,特征共享。也就是度整个图像进行卷积,得到特征图,所有的候选区域都使用同一个特征图,而不需要每个候选区域都通过CNN计算一次。
(2)SGD mini-batch 训练
(3)用一个网络实现分类和框回归
12、multi-task loss
Fast RCNN有两个并行输出,因此损失函数也有两部分组成:分类loss + 回归loss

框回归,回归的其实是预测位置和参考位置的差值,因为相对于漫无目的的回归,这样更高效。
13、mini-batch sampling
(1)每个SGD min-batch 有两个images
(2)输入图像大小为128*128,每个image采样64个ROIs
(3)IOU(交并比)> 0.5 则认为是positive examples
14、ROI pooling是如何向后传播的?
假设:Xi:ROI pooling层第ith激活层的输入;Yrj:第r个ROI的第j-th的输出。
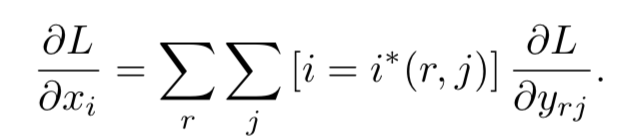
这个公式的含义是,在每个像素点上,有叠加的候选区域的话,那么他的梯度也是叠加的。如下图,它的梯度取决于在这个点上所有的候选框ROI:r,和所有的output:j。

15、SGD超参数设定
(1)利用标准差(standard deviation)分别为0.01和0.001的零均值高斯分布,用于softmax分类和框回归的全连接层初始化。
(2)bias初始化为0
(3)所有层学习率0.001
(4)在VOC 07和VOC 12上训练,先进行30k mini-batch迭代,然后降低学习率为0.0001继续训练10k迭代
(5)momentum:0.9,weight和biases参数衰减率:0.0005
16、尺度不变性
(1)蛮力法,训练前强制图像缩放到一定大小
(2)图像金字塔,图同4
在多尺度训练过程中,随机抽取一个金字塔尺度,每次抽取一幅图像,作为数据增强的形式。
17、Fast RCNN目标检测过程
假设候选框已经计算好,Fast-RCNN网络已经fine-tuning,将一系列图像(也可能是图像金字塔)和一系列候选框(大约2000个)输入到网络中,对于每个ROI r,都会输出一个类别概率p和候选框的位置参数。对每个类别,都采用NMS非极大值抑制。
18、Truncated SVD(截断SVD分解降维)
![]()
截断SVD可以将参数计数从u*v减少到t(u+v),详细内容参见:https://blog.csdn.net/qq_32172681/article/details/99191092
二、代码解读
1、roi pooling
"""
feature_map 特征图
rois shape=[M,5] 5分别为图片索引,框的4个坐标
image_size 图片大小,用于归一化图片 shape=[N,2] N为batch_size
"""
def roi_pooling(feature_map,rois,image_size):
# 处理数据,为了满足tensorflow裁剪数据的要求
roi_indexs = tf.cast(rois[:,0],dtype=tf.int32) # 图片索引集合
roi_boxes = rois[:,1:] # 框坐标集合
normalization = tf.cast(tf.stack([image_size[:, 1], image_size[:, 0], image_size[:, 1], image_size[:, 0]], axis=1),dtype=tf.float32) # 处理框坐标的尺度
roi_boxes = tf.div(roi_boxes, normalization) # 处理框
roi_boxes = tf.stack([roi_boxes[:, 1], roi_boxes[:, 0], roi_boxes[:, 3], roi_boxes[:, 2]], axis=1) # 交换框的坐标(x1, y1, x2, y2)->(y1, x1, y2, x2)
crop_size = tf.constant([640, 1024]) # 初始pool后的图片大小
# 裁剪特征图,将返回使用roi_boxes作用于feature_map后的图片
pooledFeatures = tf.image.crop_and_resize(image=feature_map, boxes=roi_boxes, box_ind=roi_indexs, crop_size=crop_size)
# 最大池化
pooledFeatures = tf.nn.max_pool(pooledFeatures, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
return pooledFeatures
2、selective search
def selective_search(
im_orig, scale=1.0, sigma=0.8, min_size=50):
'''Selective Search
Parameters
----------
im_orig : ndarray
Input image
scale : int
Free parameter. Higher means larger clusters in felzenszwalb segmentation.
sigma : float
Width of Gaussian kernel for felzenszwalb segmentation.
min_size : int
Minimum component size for felzenszwalb segmentation.
Returns
-------
img : ndarray
image with region label
region label is stored in the 4th value of each pixel [r,g,b,(region)]
regions : array of dict
[
{
'rect': (left, top, right, bottom),
'labels': [...]
},
...
]
'''
assert im_orig.shape[2] == 3, "3ch image is expected"
# load image and get smallest regions
# region label is stored in the 4th value of each pixel [r,g,b,(region)]
img = _generate_segments(im_orig, scale, sigma, min_size)
if img is None:
return None, {}
imsize = img.shape[0] * img.shape[1]
R = _extract_regions(img)
# extract neighbouring information
neighbours = _extract_neighbours(R)
# calculate initial similarities
S = {}
for (ai, ar), (bi, br) in neighbours:
S[(ai, bi)] = _calc_sim(ar, br, imsize)
# hierarchal search
while S != {}:
# get highest similarity
# i, j = sorted(S.items(), cmp=lambda a, b: cmp(a[1], b[1]))[-1][0]
i, j = sorted(list(S.items()), key = lambda a: a[1])[-1][0]
# merge corresponding regions
t = max(R.keys()) + 1.0
R[t] = _merge_regions(R[i], R[j])
# mark similarities for regions to be removed
key_to_delete = []
for k, v in S.items():
if (i in k) or (j in k):
key_to_delete.append(k)
# remove old similarities of related regions
for k in key_to_delete:
del S[k]
# calculate similarity set with the new region
for k in filter(lambda a: a != (i, j), key_to_delete):
n = k[1] if k[0] in (i, j) else k[0]
S[(t, n)] = _calc_sim(R[t], R[n], imsize)
regions = []
for k, r in R.items():
regions.append({
'rect': (
r['min_x'], r['min_y'],
r['max_x'] - r['min_x'], r['max_y'] - r['min_y']),
'size': r['size'],
'labels': r['labels']
})
return img, regions
3、以AlexNet构建网络基本模型,前五个卷积层FCN用来做特征提取,将最后一个池化层用roi pooling代替,将最后一个全连接层用两个输出的全连接层代替,分别输出分类和框回归,分类用softmax作为激活函数,输出个数为class_num,框回归输出个数class_num*4,这意味这对于每个候选区域,要输出每个类别框回归的4个位置参数。
def build_network(self, images, class_num, is_training=True, keep_prob=0.5, scope='Fast-RCNN'):
self.conv1 = self.convLayer(images, 11, 11, 4, 4, 96, "conv1", "VALID")
lrn1 = self.LRN(self.conv1, 2, 2e-05, 0.75, "norm1")
self.pool1 = self.maxPoolLayer(lrn1, 3, 3, 2, 2, "pool1", "VALID")
self.conv2 = self.convLayer(self.pool1, 5, 5, 1, 1, 256, "conv2", groups=2)
lrn2 = self.LRN(self.conv2, 2, 2e-05, 0.75, "lrn2")
self.pool2 = self.maxPoolLayer(lrn2, 3, 3, 2, 2, "pool2", "VALID")
self.conv3 = self.convLayer(self.pool2, 3, 3, 1, 1, 384, "conv3")
self.conv4 = self.convLayer(self.conv3, 3, 3, 1, 1, 384, "conv4", groups=2)
self.conv5 = self.convLayer(self.conv4, 3, 3, 1, 1, 256, "conv5", groups=2)
self.roi_pool6 = roi_pooling(self.conv5, self.rois, pool_height=6, pool_width=6)
with slim.arg_scope([slim.fully_connected, slim.conv2d],
activation_fn=nn_ops.relu,
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
flatten = slim.flatten(self.roi_pool6, scope='flat_32')
self.fc1 = slim.fully_connected(flatten, 4096, scope='fc_6')
drop6 = slim.dropout(self.fc1, keep_prob=keep_prob, is_training=is_training, scope='dropout6',)
self.fc2 = slim.fully_connected(drop6, 4096, scope='fc_7')
drop7 = slim.dropout(self.fc2, keep_prob=keep_prob, is_training=is_training, scope='dropout7')
cls = slim.fully_connected(drop7, class_num,activation_fn=nn_ops.softmax ,scope='fc_8')
bbox = slim.fully_connected(drop7, (self.class_num-1)*4,
weights_initializer=tf.truncated_normal_initializer(0.0, 0.001),
activation_fn=None ,scope='fc_9')
return cls,bbox
4、非极大值抑制
def NMS_IOU(self, vertice1, vertice2): # verticle:[pro,xin,ymin,xmax,ymax]
lu = np.maximum(vertice1[1:3], vertice2[1:3])
rd = np.minimum(vertice1[3:], vertice2[3:])
intersection = np.maximum(0.0, rd - lu)
inter_square = intersection[0] * intersection[1]
square1 = (vertice1[3] - vertice1[1]) * (vertice1[4] - vertice1[2])
square2 = (vertice2[3] - vertice2[1]) * (vertice2[4] - vertice2[2])
union_square = np.maximum(square1 + square2 - inter_square, 1e-10)
return np.clip(inter_square / union_square, 0.0, 1.0)
def NMS(self, result_dic):
final_result = []
for cls_ind, cls_collect in result_dic.items():
cls_collect = sorted(cls_collect, reverse=True)
for i in range(len(cls_collect) - 1):
for j in range(len(cls_collect) - 1, i, -1):
if self.NMS_IOU(cls_collect[i], cls_collect[j]) > cfg.NMS_threshold:
del cls_collect[j]
for each_result in cls_collect:
final_result.append(
[each_result[1], each_result[2], each_result[3] - each_result[1], each_result[4] - each_result[2],
cls_ind, each_result[0]])
return final_result
def NMS_average(self, result_dic):
final_result = []
for cls_ind, cls_collect in result_dic.items():
cls_collect = sorted(cls_collect, reverse=True)
for i in range(len(cls_collect) - 1):
for j in range(len(cls_collect) - 1, i, -1):
if self.NMS_IOU(cls_collect[i], cls_collect[j]) > cfg.NMS_threshold:
cls_collect[i] = [(x + y) / 2.0 for (x, y) in zip(cls_collect[i], cls_collect[j])]
del cls_collect[j]
for each_result in cls_collect:
final_result.append(
[each_result[1], each_result[2], each_result[3] - each_result[1], each_result[4] - each_result[2],
cls_ind, each_result[0]])
return final_result
5、定义损失,分类采用交叉熵损失函数,框回归采用均方差损失函数
def loss_layer(self, y_pred, y_true, box_pred):
cls_pred = y_pred
cls_true = y_true[:, :self.class_num]
bbox_pred = box_pred
bbox_ture = y_true[:, self.class_num:]
cls_pred /= tf.reduce_sum(cls_pred,
reduction_indices=len(cls_pred.get_shape()) - 1,
keep_dims=True)
cls_pred = tf.clip_by_value(cls_pred, tf.cast(1e-10, dtype=tf.float32), tf.cast(1. - 1e-10, dtype=tf.float32))
cross_entropy = -tf.reduce_sum(cls_true * tf.log(cls_pred), reduction_indices=len(cls_pred.get_shape()) - 1)
cls_loss = tf.reduce_mean(cross_entropy)
tf.losses.add_loss(cls_loss)
tf.summary.scalar('class-loss', cls_loss)
mask = tf.tile(tf.reshape(cls_true[:, 1], [-1, 1]), [1, 4])
for cls_idx in range(2, self.class_num):
mask =tf.concat([mask, tf.tile(tf.reshape(cls_true[:, int(cls_idx)], [-1, 1]), [1, 4])], 1)
bbox_sub = tf.square(mask * (bbox_pred - bbox_ture))
bbox_loss = tf.reduce_mean(tf.reduce_sum(bbox_sub, 1))
tf.losses.add_loss(bbox_loss)
tf.summary.scalar('bbox-loss', bbox_loss)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









