






一、并发
1、同时执行多个CUDA操作的能力(超越多线程并行)
CUDA Kernel <<<>>>
cudaMemcpyAsync(HostToDevice)
cudaMemcpyAsync(DeviceToHost)
CPU上的操作
2、Fermi 体系结构可以同时支持(计算能力2.0+)
GPU上最多16个CUDA内核
2个cudaMemcpyAsyncs(必须在不同方向)
CPU上的计算
二、流
1、流
在GPU上按发布顺序执行的一系列操作
2、用于影响并发的编程模型
不同流中的CUDA操作可以同时运行
来自不同流的CUDA操作可以交织
三、并发示例
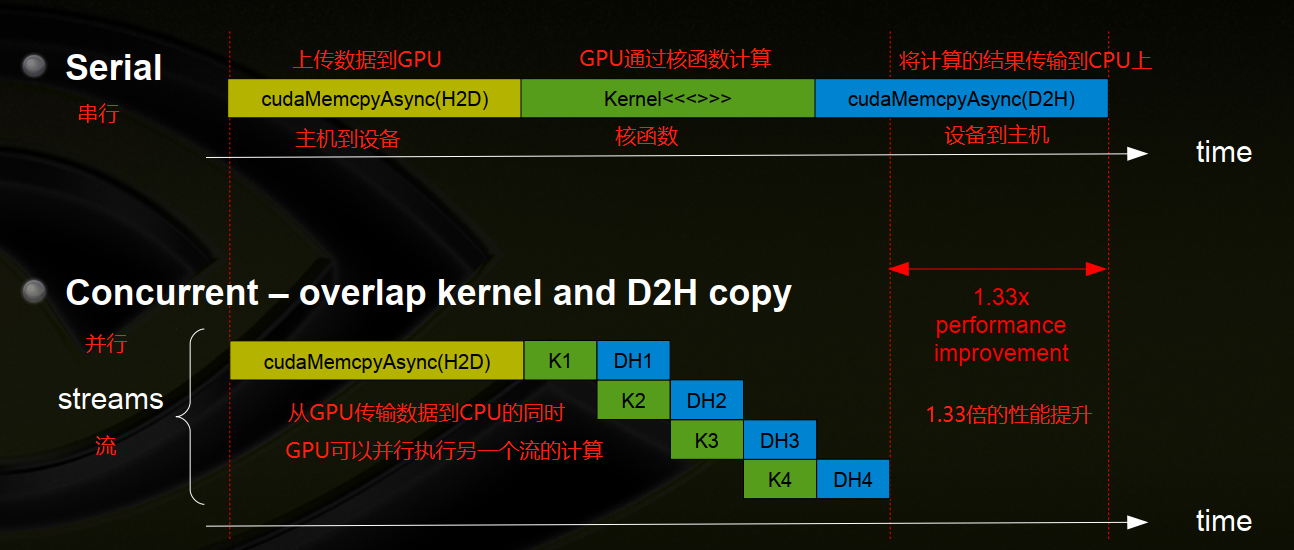
1、串行:将数据从CPU传输到GPU,GPU核函数执行计算操作,将计算结果从GPU传输到CPU上。
2、并行:重叠内核和设备到主机的内存拷贝,即内核执行的同时,可以将GPU上的数据拷贝到CPU上。
四、并发量

1、串行:1倍的性能
2、2路并发:最多2倍的性能提升
3、3路并发:最多3倍的性能提升
4、4路并发:最多3倍多性能提升
5、多路并发
五、举例 - Tiled DGEMM
1、CPU(4 core Westmere x5670 @2.93GHZ,MKL)
43 Gflops
2、GPU(C2070)
串行:125 Gflops(2.9x)
2-路并行:177 Gflops(4.1x)
3-路并行:262 Gflops(6.1x)
3、GPU + CPU
4-路并行:282 Gflops (6.6x)
对于更高级的显卡,最大可以达到 330 Gflops
4、通过利用并发性获得最大性能
5、所有通信隐藏 - 有效地消除设备内存大小限制

六、默认的流(流 ‘0’ )
1、未指定流时使用默认的流。
2、完全同步的w.r.t.主机和设备:好像在每次CUDA操作前后都插入了cudaDeviceSynchronize()
3、异常:异步w.r.t.主机
(1)内核在默认流中启动
(2)cudaMemcpy*Async
(3)cudaMemset*Async
(4)同一设备中使用cudaMemcpy
(5)小于或等于64KB的H2D(主机到设备) cudaMemcpy
七、并发性要求
1、CUDA操作必须位于不同的非0流中
2、来自“固定”内存的主机与cudaMemcpyAsync
分页锁定的内存
使用cudaMallocHost()或cudaHostAlloc()分配内存
3、必须有足够的资源
在不同的方向使用cudaMemcpyAsyncs
设备资源(SMEM,registers,blocks,etc.)
八、简单的例子:同步
完全的同步操作
cudaMalloc(&dev1,size); // 给GPU分配空间
double* host1 = (double*)malloc(&host1,size); // 给CPU分配空间
...
cudaMemcpy(dev1,host1,size,H2D); // 从CPU上拷数据到GPU
kernel2 <<< grid,block,0 >>>(...,dev2,...); // GPU上做计算操作
kernel3 <<< grid,block,0 >>>(...,dev3,...); // GPU上做计算操作
cudaMemcpy(host4,dev4,size,D2H); // 将计算结果从GPU上拷贝到CPU上
...默认流中的所有CUDA操作都是同步的。
九、简单的例子:异步,不使用流
默认情况下,GPU内核与主机异步。
cudaMalloc(&dev1,size); // 给GPU分配空间
double* host1 = (double*)malloc(&host1,size); // 给CPU分配空间
...
cudaMemcpy(dev1,host1,size,H2D); // 从CPU上拷数据到GPU
kernel2 <<< grid,block,0 >>>(...,dev2,...); // GPU上做计算操作
some_CPU_method(); // 这一行与上一行存在潜在的并行
kernel3 <<< grid,block,0 >>>(...,dev3,...); // GPU上做计算操作
cudaMemcpy(host4,dev4,size,D2H); // 将计算结果从GPU上拷贝到CPU上
...十、简单的例子:异步,使用流
完全异步/并发
并发操作使用的数据应该是独立的
cudaStream_t stream1,stream2,stream3,stream4;
cudaStreamCreate(&stream1);
...
cudaMalloc(&dev1,size); // 给GPU分配空间
cudaMallocHost(&host1,size);
...
cudaMemcpyAsunc(dev1,host1,size,H2D,stream1); // 从CPU上拷数据到GPU
kernel2 <<< grid,block,0,stream2 >>>(...,dev2,...); // GPU上做计算操作
kernel3 <<< grid,block,0,stream3 >>>(...,dev3,...); // GPU上做计算操作
cudaMemcpyAsync(host4,dev4,size,D2H,stream4); // 将计算结果从GPU上拷贝到CPU上
some_CPU_method();
...十一、显式同步
1、同步一切
cudaDeviceSunchronize()
阻止主机,直到所有发出的CUDA调用完成。
2、同步w.r.t. 特定的流
cudaStreamSynchronize(streamid)
阻止主机,直到streamid中的所有CUDA调用完成
3、使用事件同步
在流中创建特定的“事件”以用于同步
cudaEventRecord(event,streamid)
cudaEventSynchronize(event)
cudaStreamWiatEvent(stream,event)
cudaEventQuery(event)
4、显示同步示例
使用事件解决
{
cudaEvent_t event;
cudaEventCreate(&event);
cudaMemcpyAsync(d_in,in,size,H2D,stream1);
cudaEventRecord(event,stream1);
cudaMemcpyAsync(out,d_out,size,D2H,stream2);
cudaStreamWaitEvent(stream2,event);
kernel<<<,,,stream2>>>(d_in,d_out);
asynchronousCPUmethod(...);
}十二、隐式同步
1、这些操作隐式同步所有其他CUDA操作
(1)分页锁定的内存分配
cudaMallocHost
cudaHostAlloc
(2)设备内存分配
cudaMalloc
(3)非异步版本的内存操作
cudaMemcpy* (no Async suffix)
cudaMemset* (no Async suffix)
(4)更改为L1 /shared 内存配置
cudaDeviceSetCacheConfig
十三、流调度
1、Fermi硬件有三个队列
(1)1个计算引擎队列
(2)2个复制引擎队列–一个用于H2D,一个用于D2H
2、CUDA操作按其发出的顺序分派给硬件
(1)放在相关队列中
(2)引擎队列之间的流依赖关系得到维护,但在引擎队列中丢失
3、在以下情况下,将从引擎队列中调度CUDA操作:
(1)同一流中的先前调用已完成
(2)已调度同一队列中的先前调用,并且
(3)资源可用
4、如果CUDA内核位于不同的流中,则可以同时执行
如果前面内核的所有线程块都已调度,并且仍有可用的SM资源,则会调度给定内核的线程块
5、请注意,被阻止的操作会阻止队列中的所有其他操作,即使在其他流中也是如此
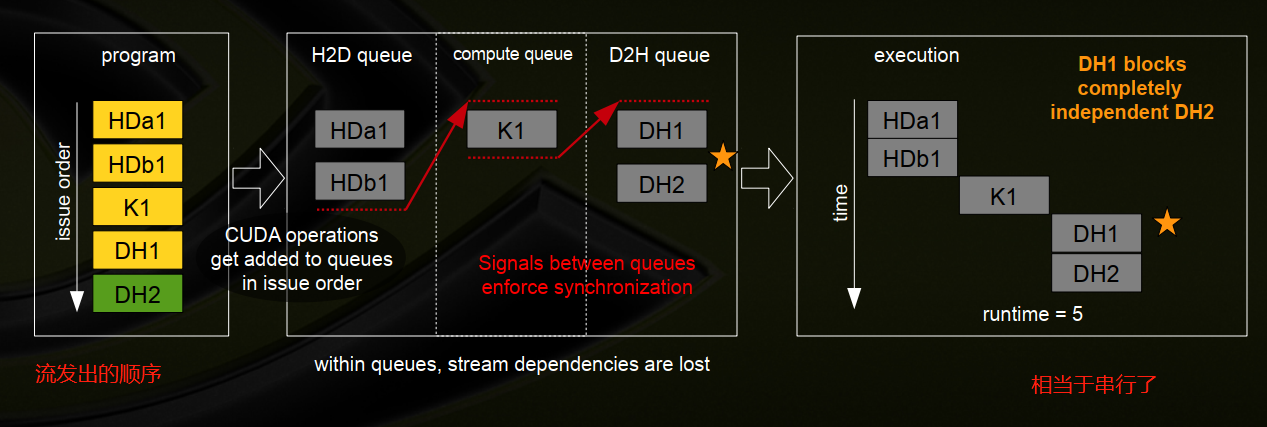
十四、示例–阻塞队列
1、两个流,流1首先发布
(1)Stream 1::HDa1,HDb1,K1,DH1(首先发出)
(2)Stream 2:DH2(完全独立于流1)
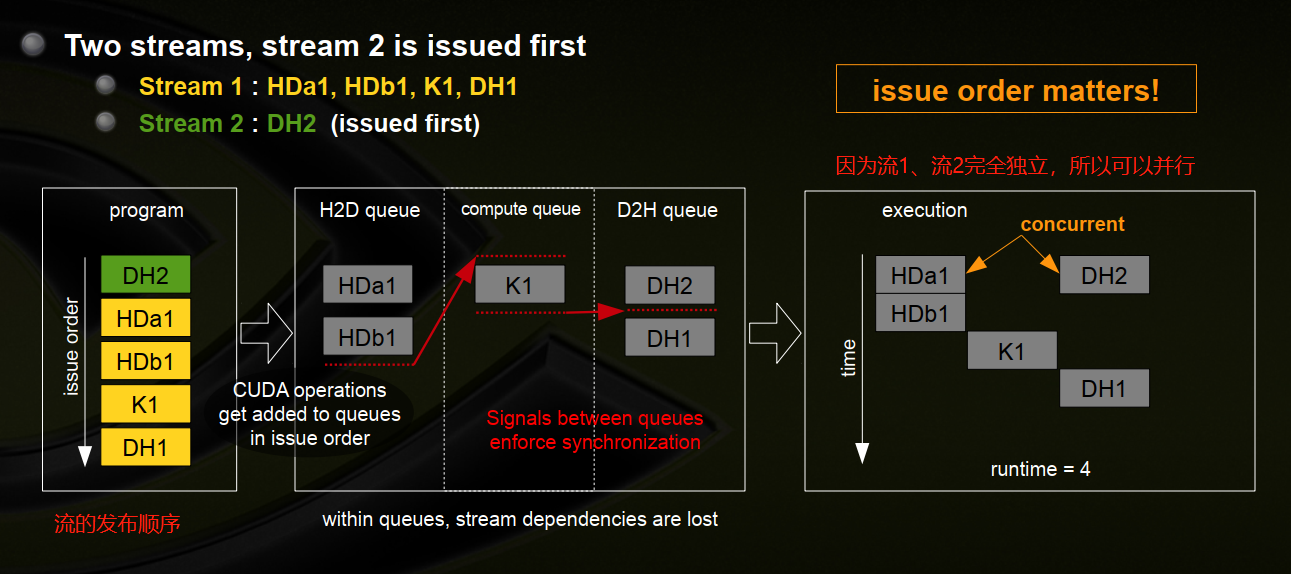
2、两个流,流2首先发布- issue order matters
(1)Stream 1:HDa1,HDb1,K1,DH1
(2)Stream 2:DH2(issued first)
十五、示例-阻塞内核 - issue order matters
1、两个流–仅发布CUDA内核
(1)Stream 1:Ka1,Kb1
(2)Stream 2:Ka2,Kb2
(3)内核大小一样,占SM资源的½
2、发行深度优先
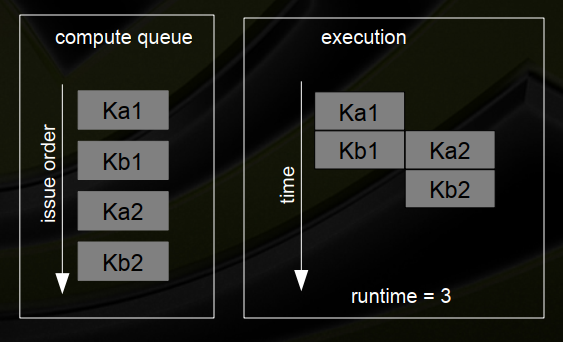
3、发行广度优先
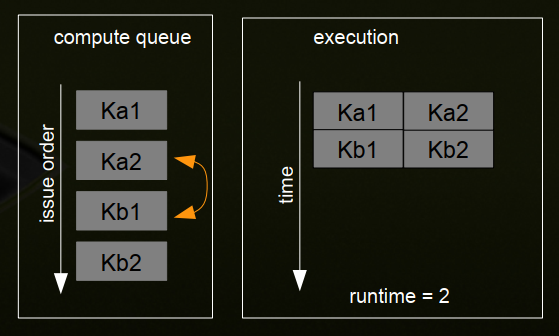
十六、示例-最佳并发性取决于内核执行时间
1、两个流-仅发布CUDA内核-但是内核的“大小”不同
issue order matters! execution time matters!
(1)Stream 1 : Ka1 {2}, Kb1 {1}
(2)Stream 2 : Kc2 {1}, Kd2 {2}
(3)内核占SM资源的一半
2、深度优先
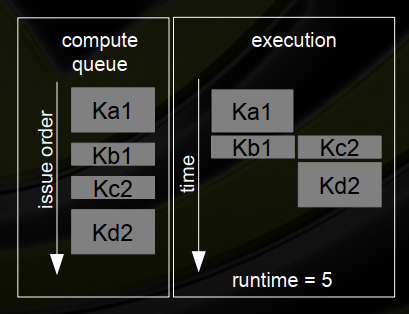
3、广度优先
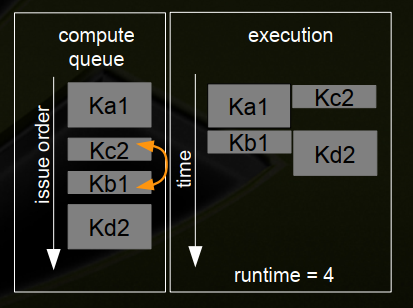
4、自定义

十七、并发内核调度
1、并发内核调度是一种特殊的调度方法
2、通常,在操作之后,将信号插入队列,以在同一流中启动下一个操作
3、对于计算引擎队列,要启用并发内核,当按顺序发布计算内核时,该信号将延迟到最后一个按顺序计算内核之后
4、在某些情况下,这种信号延迟会阻塞其他队列
十八、示例–并发内核和阻塞
1、三个流,分别为(HD,K,DH)
2、广度优先,顺序发出的内核延迟信号并阻塞cudaMemcpy(D2H)
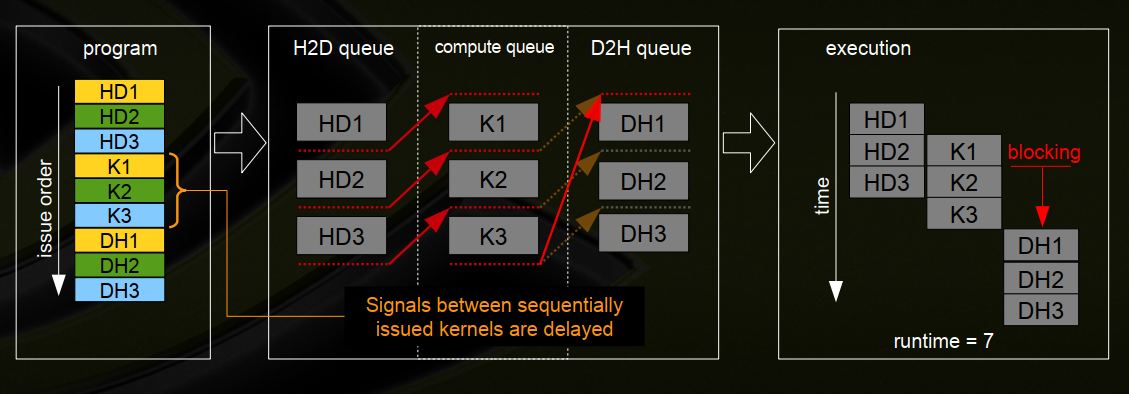
3、深度优先,“通常”最适合Fermi体系架构,即执行GPU的过程中,同时可以将GPU中计算的结果传输到CPU上
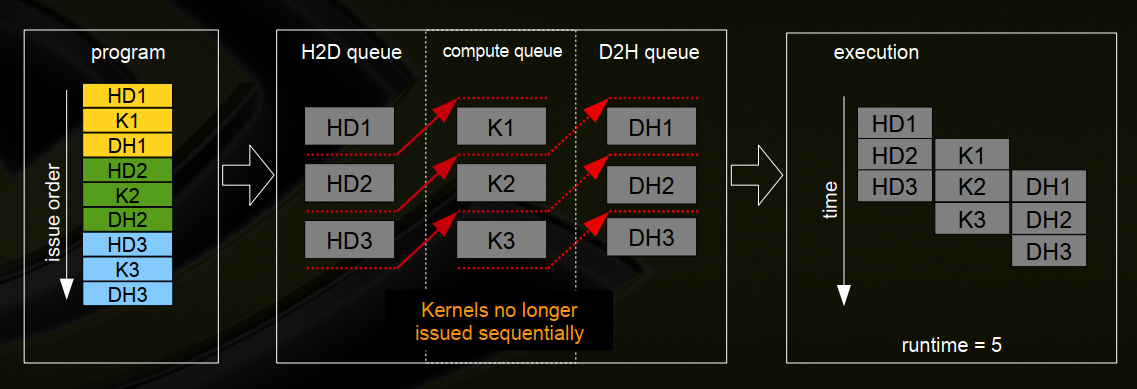
十九、以前的架构
1、计算能力1.0+
支持GPU / CPU并发
2、计算能力1.1+(即C1060)
增加了对异步内存复制的支持(单引擎),(某些异常–使用asyncEngineCount设备属性检查)
3、计算能力2.0+(即C2050)
添加对并发GPU内核的支持,(某些异常–使用concurrentKernels设备属性检查)
添加第二个复制引擎以支持双向存储,(某些异常–使用asyncEngineCount设备属性检查
二十、额外细节
1、很难同时运行四个以上的内核
2、可以使用环境变量禁用并发:CUDA_LAUNCH_BLOCKING
3、cudaStreamQuery可用于分离顺序内核并防止延迟信号
4、使用8个以上纹理的内核不能同时运行
5、切换 L1 / Shared 配置将破坏并发性
6、要同时运行,CUDA操作必须具有不超过62个中间CUDA操作,也就是说,按照“发出顺序”,它们之间不能相隔超过62个其他问题;进一步的操作被序列化。
7、cudaEvent_t is useful for timing, but for performance use
cudaEventCreateWithFlags ( &event, cudaEventDisableTiming )
二十一、并发准则
1、代码到编程模型–流
未来的设备将不断改善流模型的硬件表示
2、注意发布顺序
可能会有所不同
3、注意可能破坏并发性的资源和操作
(1)默认流中的所有内容
(2)事件和同步
(3)流查询
(4)L1 /Shared 配置更改
(5)8种以上的纹理
4、使用工具(Visual Profiler,Parallel Ensight)可视化并发,但这些当前不显示并发内核。
二十二、问题
1、验证Stream-0中的cudaMemcpyAsync()后跟Kernel <<< >>>,该memcpy将阻止内核,但都不会阻止主机。
2、下列操作(或类似操作)是否对 64 'out-ofissue-order' 限制有所贡献?
cudaStreamQuery
cudaWaitEvent
3、我知道'query'操作cudaStreamQuery()可以放在引擎或复制队列中,任何查询实际进入的队列都很难确定,并且这可能导致某些阻塞。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









