









本文概述:
1、大数据特征
2、大数据带来的革命性变革
3、Google大数据
4、分布式文件系统
5、HDFS优缺点
6、HDFS分布式文件的设计思想
7、组成结构
8、HDFS架构
9、HDFS读写数据流程
10、HDFS快照
11、HDFS日志收集实战案例
12、HDFS Java Idea操作
大数据特征:
1)大量化(Volume):存储量大,增量大
2)快速化(Velocity):告诉数据I/O
3)多样化(Variety):
来源多:搜索引擎,社交网络,通话记录,传感器
格式多:(非)结构化数据
4)价值密度低(Value):
大数据带来的革命性变革:
1)成本降低
2)软件容错,硬件故障视为常态
3)简化分布式并行计算
Google大数据
mapreduce:分布式计算框架 (mr、计算)
bigTable:大数据数据库 (存储、hbase(hbase不用sql--用hive可以去解释sql语句在hbase里头使用))
GFS:分布式集群管理分布式文件系统 (存储、hdfs)
HDFS:
Hadoop Distributed FIle System是分布式文件系统,是GFS的克隆版
分布式文件系统:
1)dataset 量达到一定规模时,那么单机就没办法进行处理
2)把数据分布到各个独立的机器上(多台机器共同协作)
3)网络
HDFS优缺点:
HDFS优点:
1)硬件错误
2)流式数据访问
3)大规模数据集
4)简单的一致性模型
5)移动计算比移动数据更划算
6)异构软硬件平台间的可移植性
HDFS缺点:
1)不适合低延迟数据访问
2)不适合小文件存储
HDFS分布式文件的设计思想:
1)将一个文件拆分成多个Block(128MB通常)
2)每个block以多副本的方式存储在各个节点
3)保存元数据映射关系
4)负载均衡
5 ) 分布式并行计算
普通分布式文件的设计思想:
1)一个文件存储在一个节点上
2)每个文件多副本方式存储
3)负载难以均衡
组成结构
nn、dn:
block:块
fsimage:文件镜像
edits:账单
client:编写的客户端
HDFS架构:
1)Master(NameNode/NN) 带 N个Slaves(DataNode/DN)大数据场景经常常用的
后面所涉及的HDFS、YARN、HBase都是这种场景
2)1个文件会被拆分成多个Block
blocksize:128M
130M ==> 2个Block: 128M 和 2M
NN:
1)负责客户端请求的响应
2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DN:
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
NameNode + N个DataNode
建议:NN和DN是部署在不同的节点上
replication factor:副本系数、副本因子(我理解的其实就是DN的个数),存放在NN
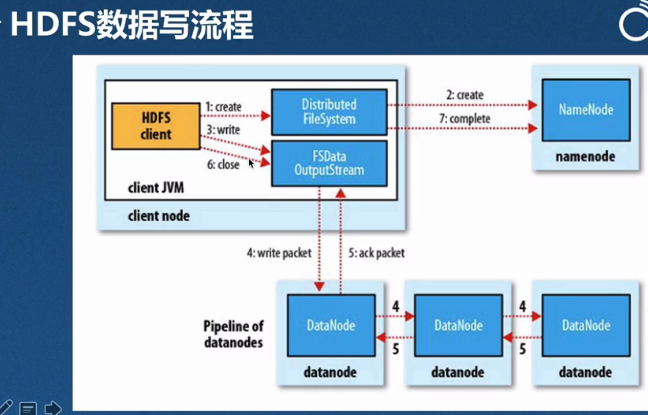
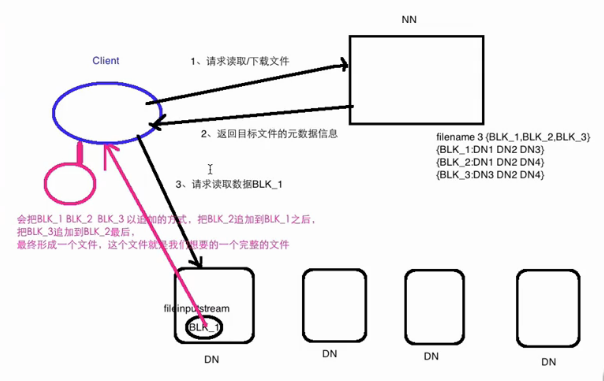
HDFS读写数据流程
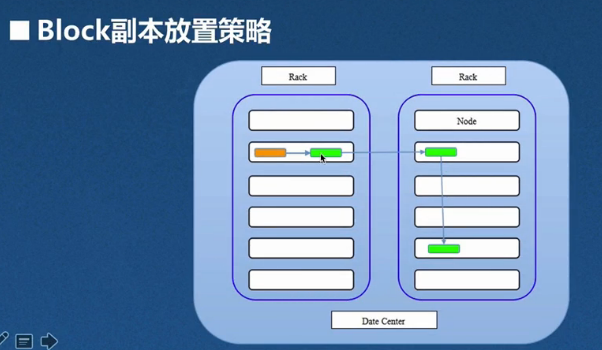
block副本存放策略:
1)在客户端相同的节点上存放第一个副本
如何客户端不在集群内呢?就随机挑选一个节点
2)第二个副本:存放在与第一个不同的随机选择的机架上
3)第三个副本:存放在与第二个副本相同机架但是不同的节点上
4)大于三的副本:被放置在集群中的随机节点上
HDFS快照
使用场景
1)备份
2)防止用户的误操作
3)容灾
注意:如果你想创建快照,第一步必须要通过hdfs dfsadmin -allowSnapshot path之后,才能创建快照
允许快照:hdfs dfsadmin -allowSnapshot /user/hadoop
创建快照:hdfs dfs -createSnapshot /user/hadoop s0(快照名称)
表示创建成功:Created snapshot /user/hadoop/.snapshot/s0
查找快照:hadoop fs -ls /user/hadoop/.snapshot
创建文件夹:hadoop fs -touchz /user/hadoop/f{1,2,3}
再次创建快照:hdfs dfs -createSnapshot /user/hadoop s1(此时的快照包含新建的文件)
删除文件:hadoop fs -rm /user/hadoop/f3
查找误操作快照:hadoop fs -ls -R /user/hadoop/.snapshot
拷贝误操作:hdfs dfs -cp -ptopax /user/hadoop/.snapshot/s1/f3 /user/hadoop/
重命名:hdfs dfs -renameSnapshot /user/hadoop/ oldname newname
查询快照目录:hdfs lsSnapshottableDir
比较快照差异:hdfs snapshotDiff /user/hadoop/ num1 num2
删除快照:hdfs dfs -deleteSnapshot /user/hadoop/ s_init
禁用快照:hdfs dfsadmin -disallowSnapshot /user/hadoop/
HDFS日志收集实战案例
需求:将业务系统产生的日志(用户行为日志、业务系统日志)通过我们开发应用程序,将其日志收集到HDFS

HDFS Java API 操作
1、创建maven项目,pom.xml文件中下载hadoop jar包
<
dependencies
>
<
dependency
>
<
groupId
>
org.apache.hadoop
</
groupId
>
<
artifactId
>
hadoop-client
</
artifactId
>
<
version
>
2.7.3
</
version
>
</
dependency
>
</
dependencies
>
2、创建文件夹
Configuration cfg =
new
Configuration();
FileSystem files = FileSystem.
get
(cfg);
files.mkdirs(
new
Path(
"file1"
));
3、上传文件
String path =
"填写你上传文件路径
"
;
InputStream in =
new
FileInputStream(path);
byte
[] buffer =
new byte
[
1024
];
FSDataOutputStream out = files.create(
new
Path(
"file1/a.java"
));
int
n =
0
;
while
(
true
){
n=in.read(buffer);
if
(n==-
1
){
break
;
}
out.write(buffer,
0
,n);
out.flush();
}
in.close();
out.close();
3、下载文件
String dowloadpath =
"填写你下载文件的存储位置
"
;
OutputStream out =
new
FileOutputStream(
new
File(dowloadpath,
"b.java"
));
FSDataInputStream in = files.open(
new
Path(
"file1/a.java"
));
byte
[] buffer =
new byte
[
1024
];
int
n =
0
;
while
(
true
) {
n = in.read(buffer);
if
(n == -
1
) {
break
;
}
out.write(buffer,
0
, n);
out.flush();
}
4、日志收集
Logger log = LogManager.
getLogger
(
"类名"
);
int
i =
0
;
while
(
true
){
log.info(
"......."
+
new
Date().toString()+
".............."
);
i++;
Thread.
sleep
(
500
);
if
(i>
10000
){
break
;
}
}
resources/log4j.properties:
log4j.rootLogger
=
INFO,log
log4j.appender.log
=
org.apache.log4j.RollingFileAppender
log4j.appender.log.layout
=
org.apache.log4j.PatternLayout
log4j.appender.log.layout.ConversionPattern
=
[%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.log.Threshold
=
INFO
log4j.appender.log.ImmediateFlush
=
TRUE
log4j.appender.log.Append
=
TRUE
#log4j.appender.log.File =
这块可以写
hadoop
集群下面
#下面的路径是日志存放文件
log4j.appender.log.File
=
D:/Program Files/BigData/IDeaProject/logs/access.log
log4j.appender.log.MaxFileSize
=
10KB
log4j.appender.log.MaxBackupIndex
=
20















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









