







之前因为工作的需要,第一次了使用Python语言第一次写了一个爬虫脚本,可以爬取APP的名称和下载链接,不得不被Python的简洁性和易用性惊叹了。还好之前钻研过PHP,果然代码都是相同的,学会一门之后,学习其他的代码就很容易了,有叹于Python在我现在的工作中时不时的能解放双手,节省人力,于是我决定还是开始系统的学习一下Python吧,之前的那个脚本能成功运行,说实话,5分的PHP代码基础,和5分的运气吧,因为我就当了个裁缝,把各种脚本的代码剪切复制缝补在了一起,没想到竟然可以运行。
我的第一个Python脚本
# -*- coding: utf-8 -*-
import requests
import bs4
import time
import csv
for page in range(1, 91):
url = 'http://www.itmop.com/android/s_212_{}.html'.format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
res = requests.get(url=url,headers=headers)
res.raise_for_status()
res.encoding = res.apparent_encoding
soup=bs4.BeautifulSoup(res.text,'lxml')
elems1 = soup.select('.icon')
elems2 = soup.select('.downBtn')
for i in range(0,len(elems1)):
baseurl = 'http://www.itmop.com'
with open("app23.csv", "a", newline="", encoding="utf-8")as f:
csv_data = csv.DictWriter(f, fieldnames=["appName", "apkUrl"])
appName = elems1[i].get('alt')
apkUrl = baseurl+elems2[i].get('href')
print({"appName": appName, "apkUrl": apkUrl})
csv_data.writerow({"appName": appName, "apkUrl": apkUrl})
time.sleep(1)
言归正传,开始BeautifulSoup学习,我认为在Python爬虫学习中,bs4很重要,因为在我写的第一个爬虫脚本当中,获取网页很简单,复杂的是把你需要的内容,从网页源码中提取出来,刚开始我使用的是正则提取,正则复杂不好写、正则容易出错、正则耗费算力,这个时候,通过度娘我发现bs4库,它可以帮助我们很简单的从网页源码中提取我们想要的信息。
一、Beautiful Soup基础知识
Beautiful Soup 简介
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。由于 BeautifulSoup 是基于 Python,所以相对来说速度会比另一个 Xpath 会慢点,但是其功能也是非常的强大
学习资料中文官网:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
Beautiful Soup 安装
pip install beautifulsoup4
上面安装库最后的4是不能省略的,因为还有另一个库叫作 beautifulsoup,但是这个库已经停止开发了
pip install lxml
因为BS4在解析数据的时候是需要依赖一定的解析器,所以还需要安装解析器,我们安装强大的lxml:
Beautiful Soup 解析原理
实例化一个BeautifulSoup对象,并且将本地或者页面源码数据加载到该对象中
通过调用该对象中相关的属性或者方法进行标签定位和数据提取
如何实例化BeautifulSoup对象
将本地的HTML文档中的数据加载到BS对象中
将网页上获取的页面源码数据加载到BS对象中
二、Beautiful Soup案例学习
 soup.tagName
soup.tagName
soup.tagName获取标签第一次出现的内容

它会返回这个标签内的所有内容,直到这个标签结束。比如:<a></a>、<script></script>
数据中多次出现a标签,但是只会返回第一次出现的内容
soup.find('tagName')
find()主要是有两个方法:
-
返回某个标签第一次出现的内容,等同于上面的soup.tagName
-
属性定位:用于查找某个有特定性质的标签
1、返回标签第一次出现的内容:
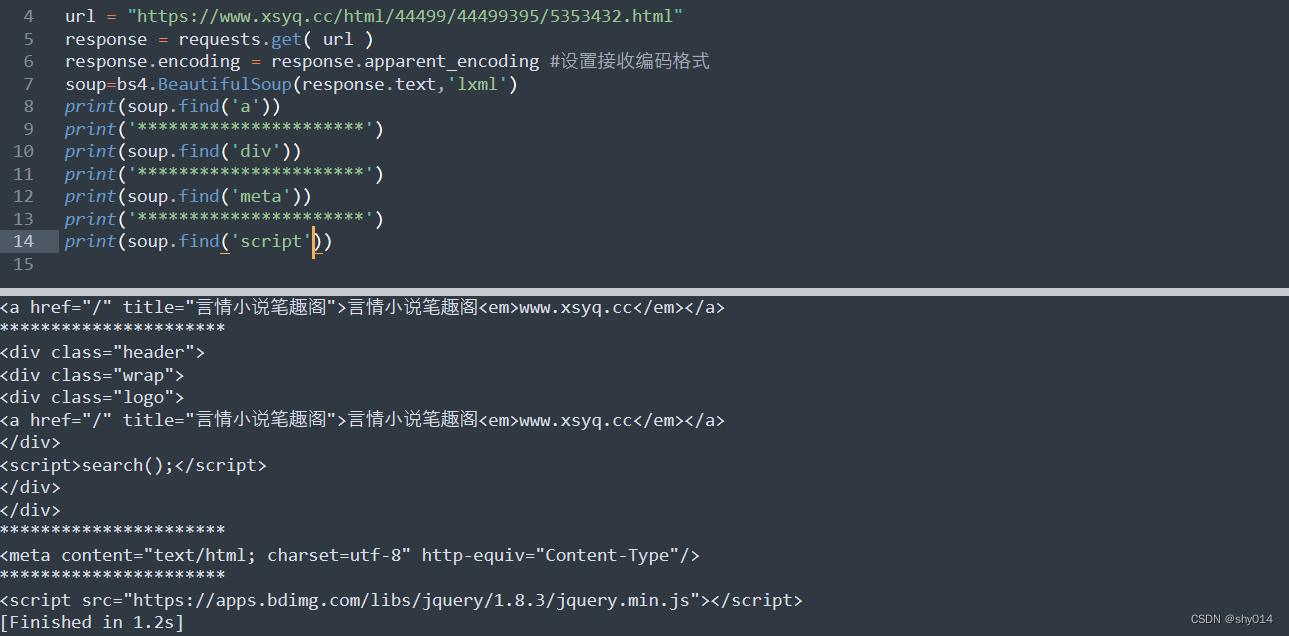
修改为soup.find('tagName')之后,可以看到和soup.tagName返回的内容一样,都是返回标签第一次出现的内容
2、属性定位
这个a标签中有个rel属于,它的值为nofollow,这样我们就可以使用soup.fing('a',rel='nofollw')将这条a标签的内容提取出来。


BS4中规定,如果遇到要查询class情况,需要使用class_来代替:

但是如果我们使用attrs参数,则是不需要使用下划线的:

soup.find_all()
以列表的形式返回所有你指定的标签
1、返回所有的a标签

因为它以列表的方式返回,我们可以通过下表获取你想要的内容

也可以写个循环,返回列表中所有的值

2、传入多个标签(列表形式)
需要主要返回内容的表达形式,每个标签的内容是单独显示的

 3、传入正则表达式
3、传入正则表达式
查看以m标签开头的全部内容:
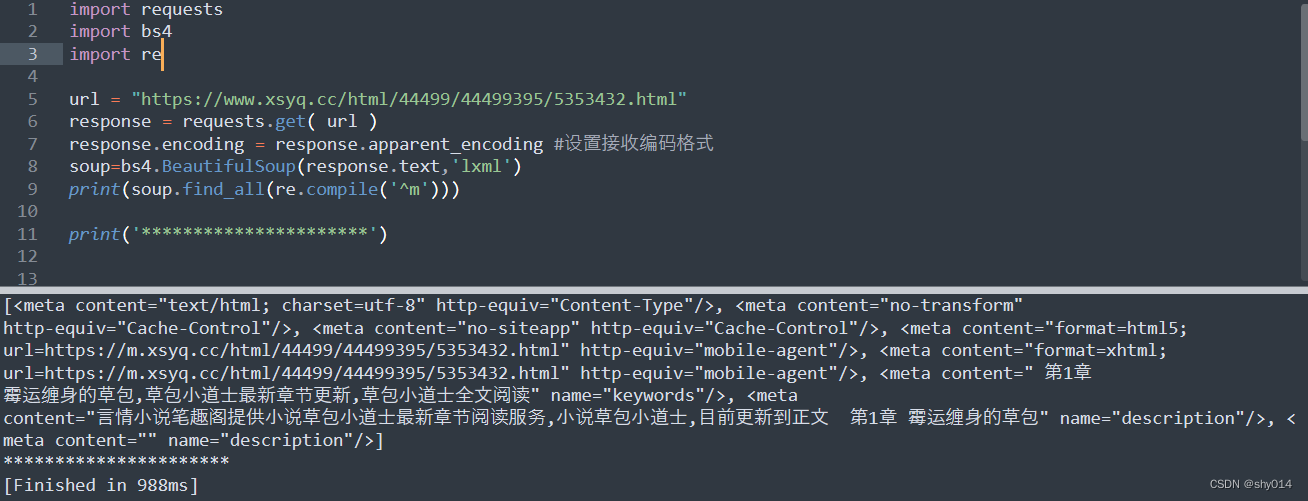
选择器soup.select()
主要是有3种选择器,返回的内容都是列表形式
-
class类选择器:点
-
id选择器:#
-
标签选择器:直接指定标签名
1、class类选择器
所有使用CSS class属性名为logod的元素

2、id选择器
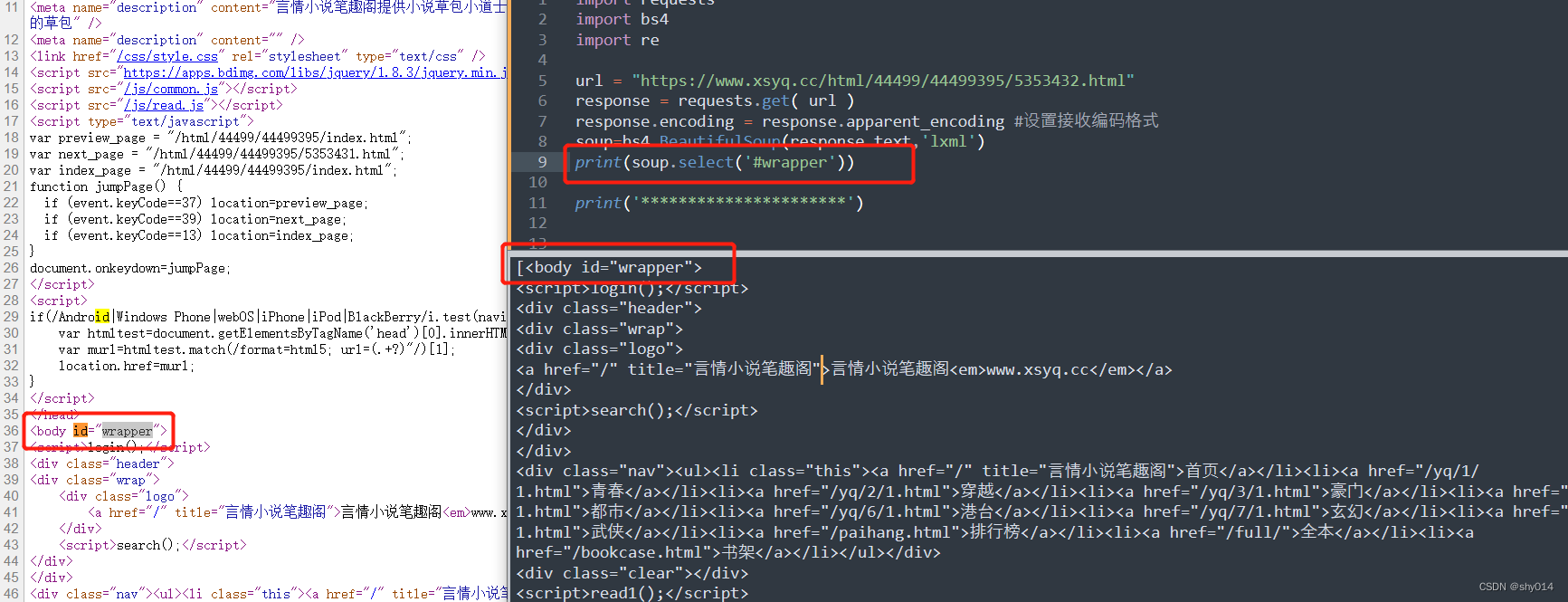
3、标签选择器
直接指定li标签

4、选择器和find_all()可以达到相同的效果:

层级选择器使用
在soup.select()方法中是可以使用层级选择器的,选择器可以是类、id、标签等,使用规则:
-
单层:>
-
多层:空格

1、单层使用


2、多层使用
使用空格跨国li标签
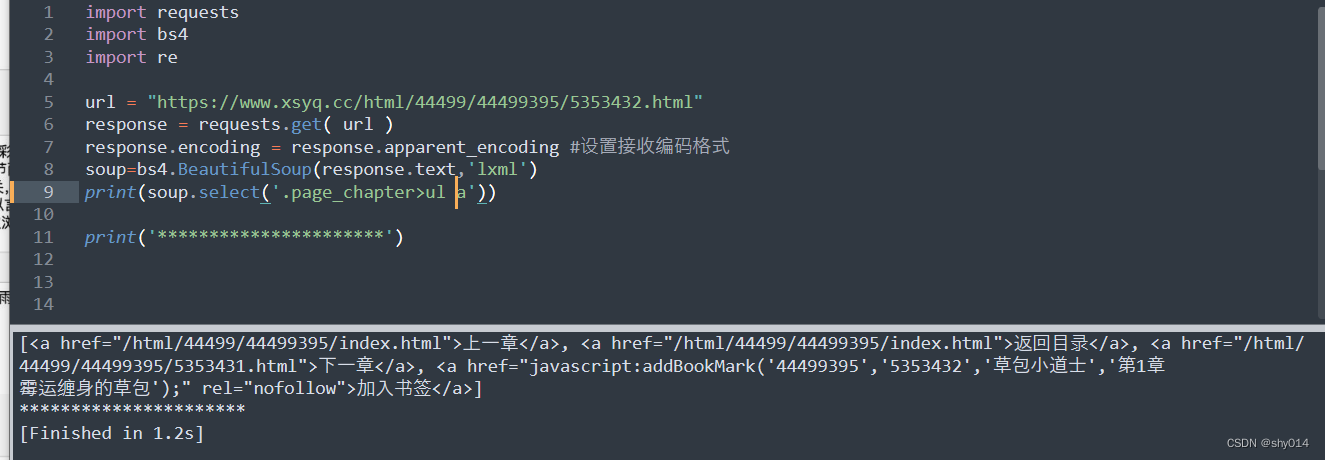
获取标签文本内容
获取某个标签中对应文本内容主要是两个属性+一个方法:
-
text
-
string
-
get_text()
1、text
 2、string
2、string
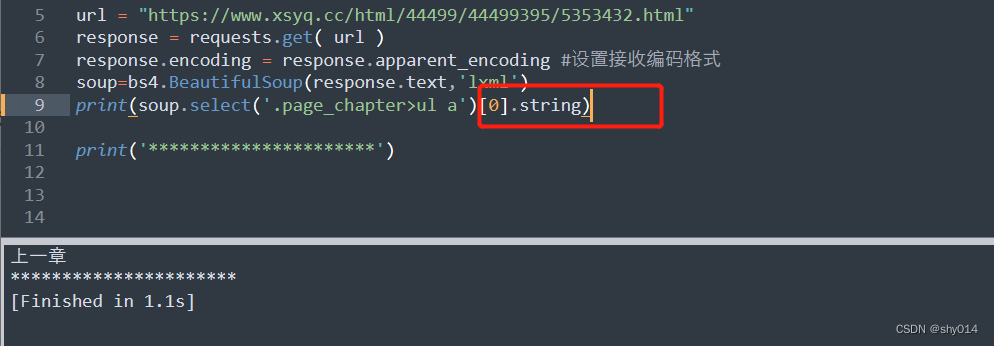
3、get_text()

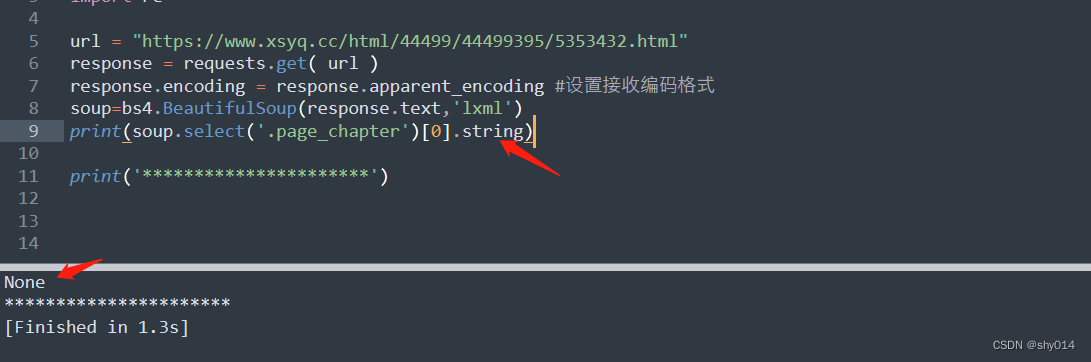
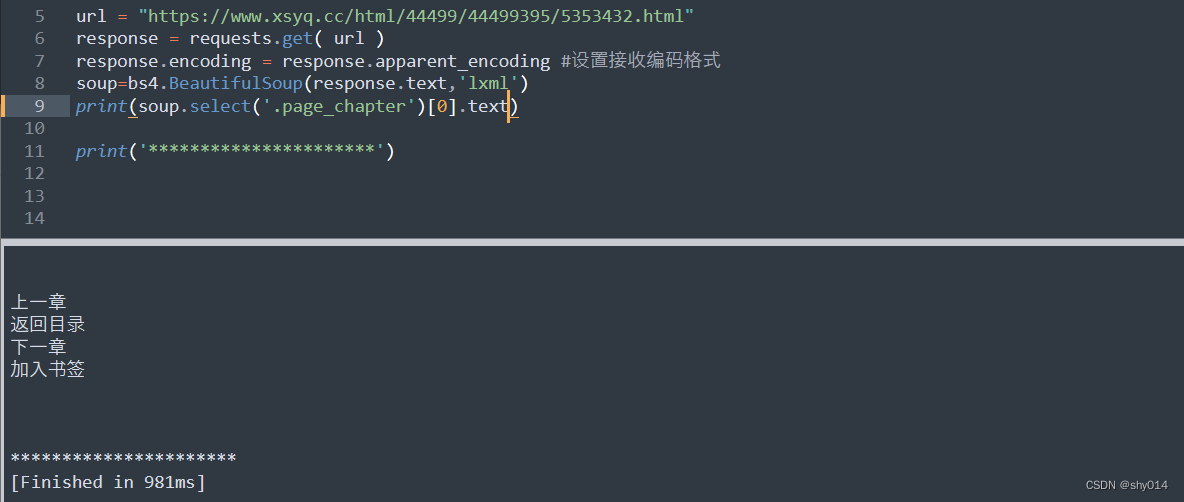
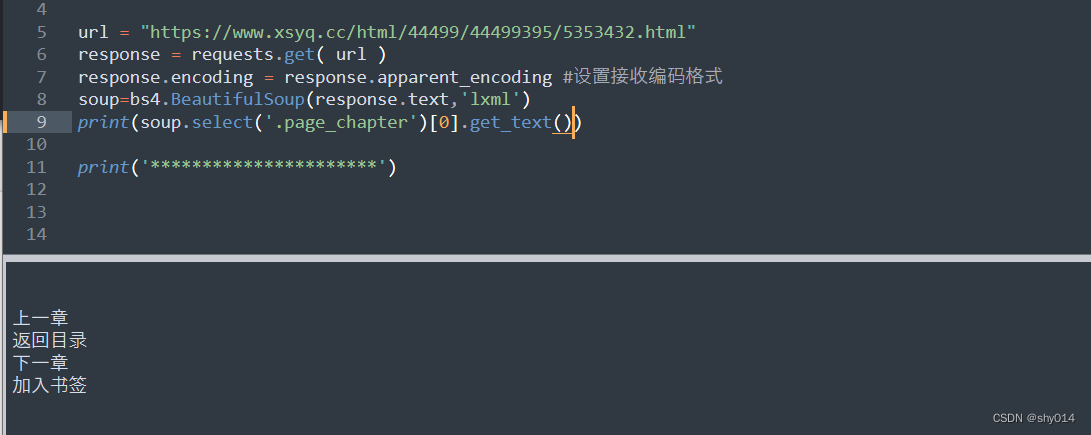
3者之间的区别
# text和get_text():获取标签下面的全部文本内容
# string:只能获取到标签下的直系文本内容
因为没有直系的文本内容,所以输出None
获取标签属性值
1、通过选择器来获取
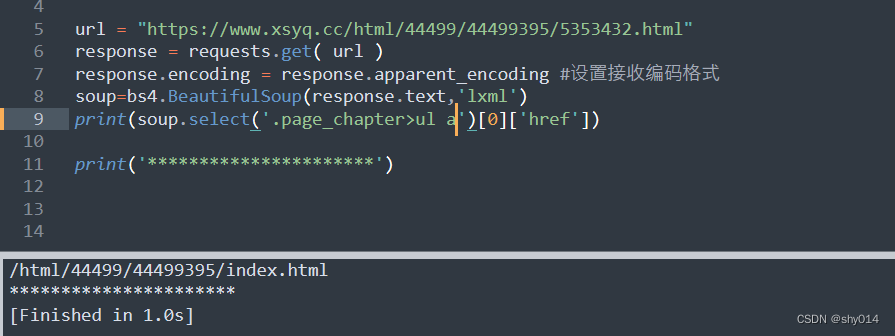
2、通过find_all方法来获取
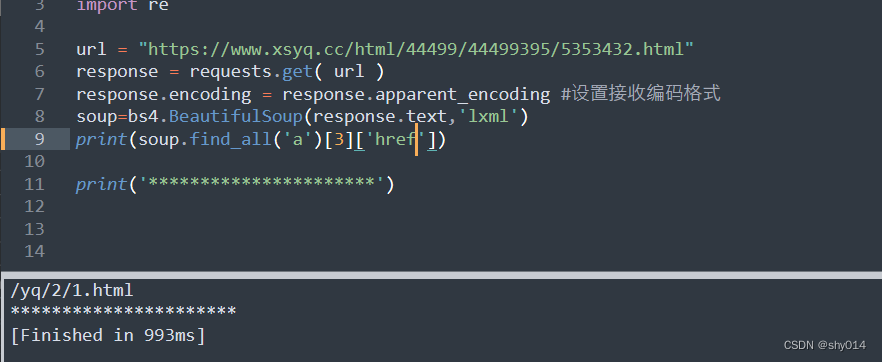

BeautifulSoup问题总结:
这里用来记录我在使用bs4的时候出现的各种问题,持续更新。
1、两种去数据的方式
这两种方式都能取到数据是一样的

2、嵌套取数据
第一次取出来的数据是这样的
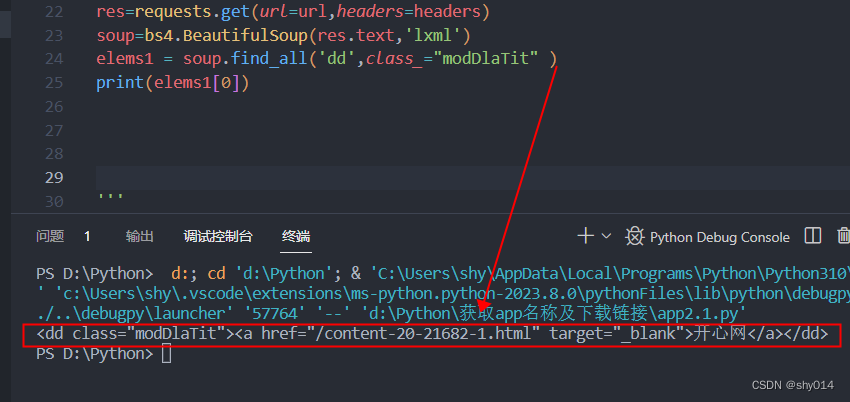
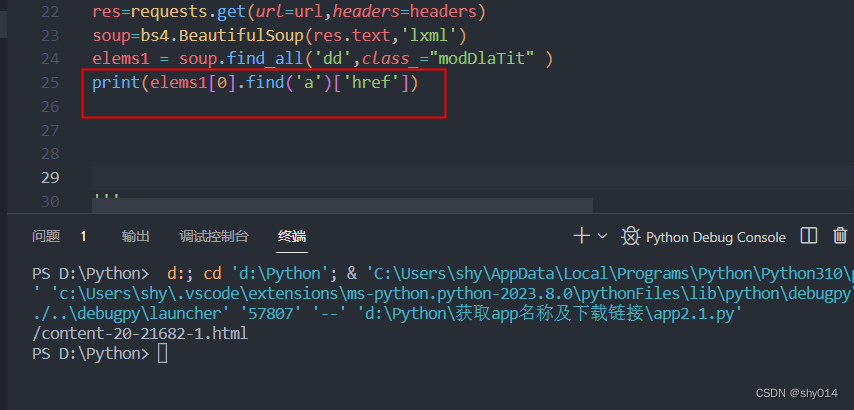
这个时候使用print(elems1[0].['href'])取href的值报错,无法直接取出
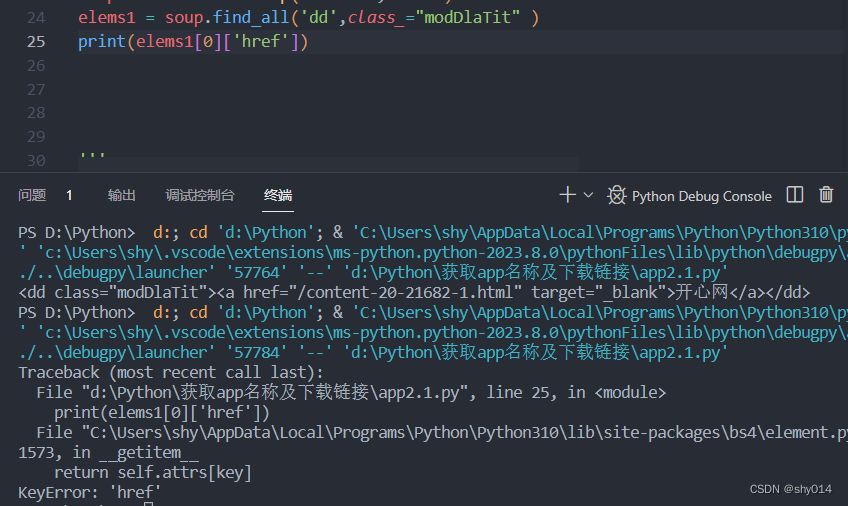
这个时候可以嵌套一个find()方法,取a标签的,然后再从中取href的值就可以了。
print(elems1[0].find('a')['href'])
BeautifulSoup实战
我为什么一直拿这个网站做测试了,因为我想看这本小说,但是网上却没有下载链接,于是乎我就打算学习完成后直接爬取。
import requests
import bs4
import time
import io
import sys
import urllib.request
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
for page in range(5353432, 5268488,-1):
url = "https://w/{}.html".format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
res = requests.get(url=url,headers=headers)
res.raise_for_status()
res.encoding = res.apparent_encoding
soup=bs4.BeautifulSoup(res.text,'lxml')
#print(soup.h1.text)
#print(soup.find('div',id='content').text)
with open('caobao4.txt','a',encoding="utf-8") as f:
f.write(soup.h1.text+'\n')
f.write(soup.find('div',id='content').text+'\n')
time.sleep(1)
import requests
import bs4
import time
for page in range(5353432, 5268488,-1):
url = "https://*/{}.html".format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
res = requests.get(url=url,headers=headers)
res.raise_for_status()
res.encoding = res.apparent_encoding
soup=bs4.BeautifulSoup(res.text,'lxml')
#print(soup.h1.text)
#print(soup.find('div',id='content').text)
file = open("caobaoxiaodaoshi2.txt",'a',encoding='utf-8')
file.write(soup.h1.text+'\n')
file.write(soup.find('div',id='content').text)
time.sleep(3)
print(url)















 7900
7900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









