






abstract
对于神经网络,存在线性层之后会有非线性函数。本片文章主要针对的就是激励函数的设计。本文介绍了一种新的激励函数,它基于每个神经元的核扩张(based on an inexpensive kernel expansion at every neuron),本文针对设计以及初始化这些核函数(KAFs)提出多种变形。结果表明,KAFs能够近似表示任何定义在实线子集上的映射,不管它是凸还是非凸。KAFs能够在整个域上光滑(smooth over their entire domain),linear in their parameters,并且能够使用任何已知的模式来规则化,包括使用 L1 L 1 。
introduction
在NNs中,激励函数一般是一个element-wise,(sub-)differentiable, and fixed 的非线性函数。现在逐渐从收缩映射(sigmoids)激励函数转为使用分段线性函数(piecewise-linear functions)比如ReLUs,在BP error 的计算上更为有效。
在设计方面有两个问题,第一,我们可以使用少量的参数来参数化一个已知的激励函数,这会导致在灵活性以及性能上有少量的提升
preliminaries
对于一个前馈神经网络,第
l−th
l
−
t
h
层,

训练网络的时候,提供输入输出集合
S={Xi.Yi}Ii=1
S
=
{
X
i
.
Y
i
}
i
=
1
I
,损失函数为
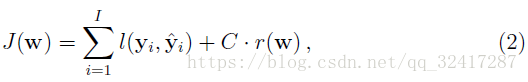
对于激励函数的选择,和 tasks 以及 a proper scaling of the output相关,不能随便选取。对于回归问题使用
g(s)=s
g
(
s
)
=
s
,
s
s
代表的是单个输入。对于二分类问题 ,使用 sigmoid function。
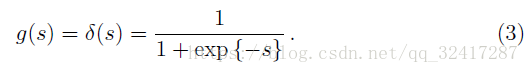
Fixed activation functions
在NNs中最常使用的是一种非减的函数,也就是说
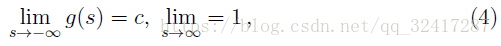
c为0或者1,依赖于约定。
另外一种是双曲正切
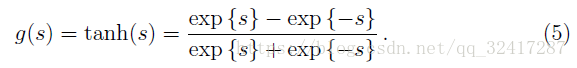
但是在实际的运用中会出现梯度消失和梯度爆炸的问题。
一个突破是ReLU的提出
g(s)=max{0,s}
g
(
s
)
=
m
a
x
{
0
,
s
}
。第一,ReLU的梯度要么是0要么是1,第二,(activations are sparse)激励项是稀疏的。
softplus 是 ReLU的一个smoothed version:
g(s)=log{1+exp{s}}
g
(
s
)
=
l
o
g
{
1
+
e
x
p
{
s
}
}
为了解决‘dying ReLU’,就是说因为初始化或者权重更新问题,激励项变成了0, 因此引入 leaky ReLU
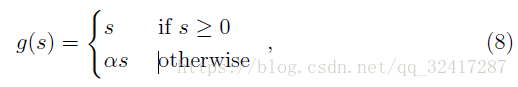
对于仅仅有非负的输出值激励函数,一个问题是他们的平均值是正的(这是什么问题??)Another problem of activation functions having only non-negative output values is that their mean value is always positive by de nition.。受自然梯度natural gradient的启发,提出了exponential linear unit (ELU)
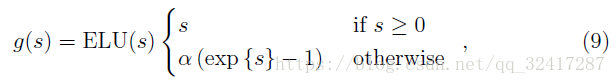
scaled ELU (SELU):
g(s)=SELU(s)=λ∗ELU(s)
g
(
s
)
=
S
E
L
U
(
s
)
=
λ
∗
E
L
U
(
s
)
,其中
λ>1
λ
>
1
Swish inspired by the gating steps in a standard LSTM recurrent cell 提出了
g(s)=s∗δ(s)δ(s)
g
(
s
)
=
s
∗
δ
(
s
)
δ
(
s
)
是一个sigmoid。
Parametric adaptable activation functions
提高NN灵活性的一种快速的方法就是参数化之前介绍的激励函数(activations functions with a xed (small) number of adaptable parameters),只要这些激励函数可以微分,就可以用过数值优化算法(numerical optimization algorithm)进行优化。
因为这些函数的参数数目固定并且缺乏灵活性,所以叫做Parametric adaptable activation functions。
generalized hyperbolic tangent 双曲正切:含有两个正数标量
a,b
a
,
b
,随机初始化,相互独立,a控制输出的范围,b控制曲线的坡度。
g(s)=a(1−exp{−bs})1+exp{−bs}
g
(
s
)
=
a
(
1
−
e
x
p
{
−
b
s
}
)
1
+
e
x
p
{
−
b
s
}
parametric version of the leaky ReLU:
α=0.25
α
=
0.25
, 叫做parametric ReLU (PReLU)
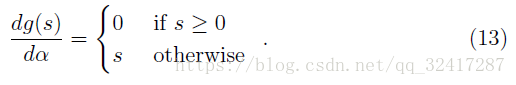
a modi cation of the ELU function in (9) with an additional scalar parameter , called parametric ELU(PELU):
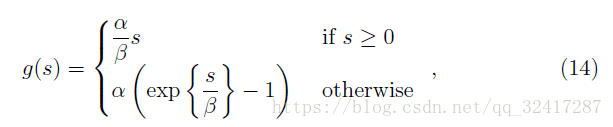
A more flexible proposal is S-shaped ReLU (SReLU)parameterized by four scalar values
tr;ar;tl;al
t
r
;
a
r
;
t
l
;
a
l
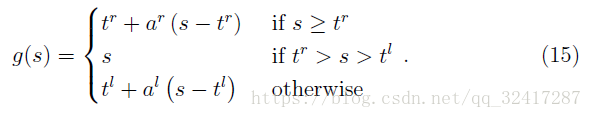
a parametric version of the Swish function is
β−swish:g(s)=s∗δ(βs)
β
−
s
w
i
s
h
:
g
(
s
)
=
s
∗
δ
(
β
s
)
Non-parametric activation functions
参数化的激励函数的灵活性受限,非参数化的激励函数可以给大规模数据建模(allow to model a larger class of shapes),主要是对超参数的引入。
APL functions 分段线性插值函数
generalizes the SReLU function in (15) by summing multiple linear segments,
g(s)=max{0,s}+∑Si=1aimax{0,−s+bi}
g
(
s
)
=
m
a
x
{
0
,
s
}
+
∑
i
=
1
S
a
i
m
a
x
{
0
,
−
s
+
b
i
}

spline functions 样条插值 (SAF)
多项式插值(polynomial activation function PAF)
g(s)=∑Pi=0aisi
g
(
s
)
=
∑
i
=
0
P
a
i
s
i
P
P
是超参数,有个系数
{ai}Pi=0
{
a
i
}
i
=
0
P
drawbacks: 每一个
ai
a
i
有全局的影响。

maxout networks

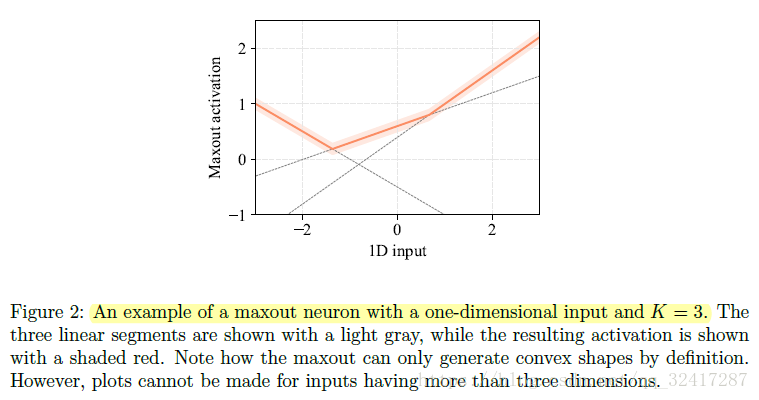
为了解决 smoothness problem,引入两种变种
soft-maxout:
lp−maxout
l
p
−
m
a
x
o
u
t
与 lp−maxout l p − m a x o u t 相关的是 Lpunit L p u n i t
Proposed kernel-based activation functions
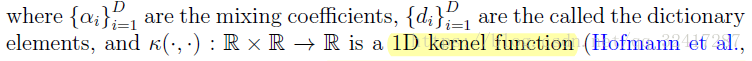
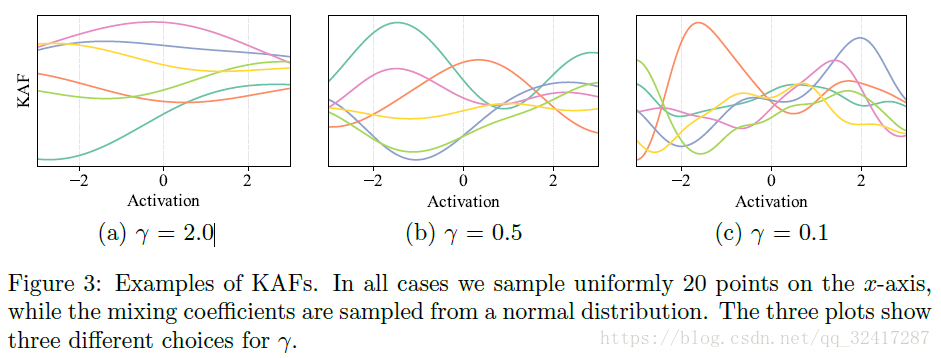
For our experiments, we use the 1D Gaussian kernel de ned as
γ γ called the kernel bandwidth
simple derivatives for back-propagation:
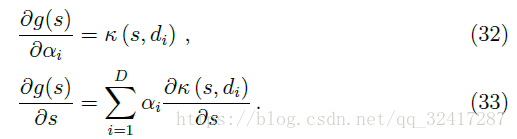
On the selection of the kernel bandwidth γ γ
Selecting
γ
γ
is crucial for the well-behavedness of the method
many methods have been proposed to select the bandwidth parameter for performing kernel density estimation,但是对于核密度估计(kernel density estimation)的问题,(the abscissa corresponds to a given dataset with an arbitrary distribution.)所以,KAF中,abscissa 通过一个网格grid选取
本文没有把
γ
γ
看作一个超参数,而是从经验上设定
γ=16Δ2
γ
=
1
6
Δ
2
其中
Δ
Δ
是网格点(grid points)之间的距离
对于KAF,初始化的不同,会有性能的差异,所以可以通过对参数进行初始化来得到想要激励函数。如图:
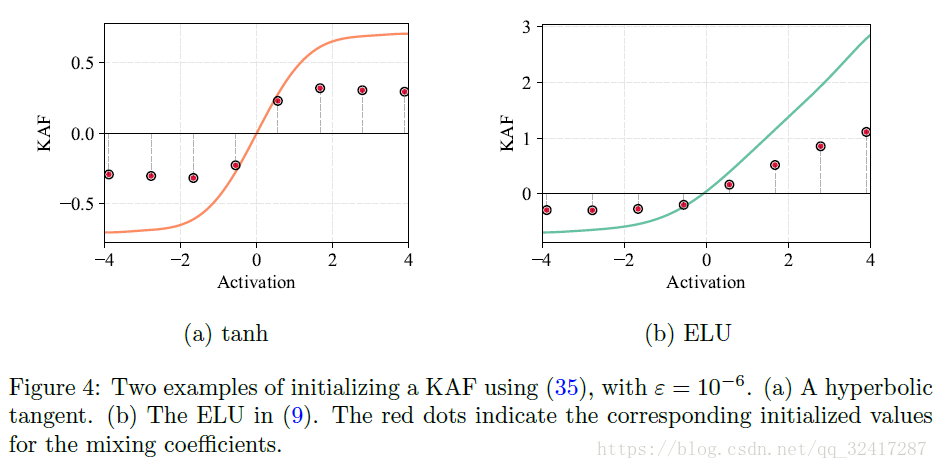
On the initialization of the mixing coefficients
使用kernel ridge regression 来初始化 the mixing coefficients
α=(K+εI)−1t
α
=
(
K
+
ε
I
)
−
1
t
其中
t=[t1,t2,...,tD]T
t
=
[
t
1
,
t
2
,
.
.
.
,
t
D
]
T
表示希望的得到的KAF的初始值,与字典元素相对应
d=[d1,d2,...,dD]T
d
=
[
d
1
,
d
2
,
.
.
.
,
d
D
]
T
,
K
K
是通过得到的核矩阵。
Multi-dimensional kernel activation functions
对于2D-KAF,作用于pair of 激励函数上,而不是单个的,最终学习一个两维度的函数。
for each possible pair of activations
s=[sk,sk+1]T
s
=
[
s
k
,
s
k
+
1
]
T
,可得到:
di d i 表示字典的第i个元素。
对于2D Gaussian kernel:
k(s,di)=exp{−γ∥s−di∥}22 k ( s , d i ) = e x p { − γ ‖ s − d i ‖ } 2 2
KAF: they are smooth over their entire domain, and their operations
can be implemented easily with a high degree of vectorization














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









