 AFL技术实现深度剖析
AFL技术实现深度剖析




 本文详细分析了AFL(American Fuzzy Lop)的实现原理,涵盖设计思想、代码插装、分支信息记录、输入队列管理等多个方面。AFL通过代码插装收集分支信息,使用随机数标识代码块,记录分支执行次数,实现对程序执行路径的深入理解。此外,AFL使用一系列变异策略,如位翻转、算术运算、字典插入等,逐步探索和优化测试用例,以发现潜在的软件漏洞。在整个模糊测试过程中,AFL通过控制输入队列、剔除语料库和修剪输入文件等手段,优化性能并保持测试用例多样性。
本文详细分析了AFL(American Fuzzy Lop)的实现原理,涵盖设计思想、代码插装、分支信息记录、输入队列管理等多个方面。AFL通过代码插装收集分支信息,使用随机数标识代码块,记录分支执行次数,实现对程序执行路径的深入理解。此外,AFL使用一系列变异策略,如位翻转、算术运算、字典插入等,逐步探索和优化测试用例,以发现潜在的软件漏洞。在整个模糊测试过程中,AFL通过控制输入队列、剔除语料库和修剪输入文件等手段,优化性能并保持测试用例多样性。
AFL技术实现分析
设计说明
American Fuzzy Lop(AFL)设计原理是不把注意力集中在任意单一的操作,也不是对任何的理论进行概念性验证。这是一个在实践测试中进行验证的工具,这个工具非常有效而且运行起来也非常简单。AFL可以做到速度,可靠性和易用性的要求。
代码插装
使用AFL,首先需要通过afl-gcc/afl-clang等工具来编译目标,在这个过程中会对其进行插桩。
我们以afl-gcc为例。如果阅读文件afl-gcc.c便可以发现,其本质上只是一个gcc的wrapper。我们不妨添加一些输出,从而在调用execvp()之前打印全部命令行参数,看看afl-gcc所执行的究竟是什么:
gcc /tmp/hello.c -B /root/src/afl-2.52b -g -O3 -funroll-loops -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1
可以看到afl-gcc最终调用gcc,并定义了一些宏,设置了一些参数。其中最关键的就是-B /root/src/afl-2.52b这条。根据gcc --help可知,-B选项用于设置编译器的搜索路径,这里便是设置成/root/src/afl-2.52b(是我设置的环境变量AFL_PATH的值,即AFL目录,因为我没有make install)。
如果了解编译过程,那么就知道把源代码编译成二进制,主要是经过”源代码”->”汇编代码”->”二进制”这样的过程。而将汇编代码编译成为二进制的工具,即为汇编器assembler。Linux系统下的常用汇编器是as。不过,编译完成AFL后,在其目录下也会存在一个as文件,并作为符号链接指向afl-as。所以,如果通过-B选项为gcc设置了搜索路径,那么afl-as便会作为汇编器,执行实际的汇编操作。
所以,AFL的代码插桩,就是在将源文件编译为汇编代码后,通过afl-as完成。
接下来,我们继续阅读文件afl-as.c。其大致逻辑是处理汇编代码,在分支处插入桩代码,并最终再调用as进行真正的汇编。具体插入代码的部分如下:
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE));
这里通过fprintf()将格式化字符串添加到汇编文件的相应位置。篇幅所限,我们只分析32位的情况,trampoline_fmt_32的具体内容如下:
static const u8* trampoline_fmt_32 =
"\n"
"/* --- AFL TRAMPOLINE (32-BIT) --- */\n"
"\n"
".align 4\n"
"\n"
"leal -16(%%esp), %%esp\n"
"movl %%edi, 0(%%esp)\n"
"movl %%edx, 4(%%esp)\n"
"movl %%ecx, 8(%%esp)\n"
"movl %%eax, 12(%%esp)\n"
"movl $0x%08x, %%ecx\n"
"call __afl_maybe_log\n"
"movl 12(%%esp), %%eax\n"
"movl 8(%%esp), %%ecx\n"
"movl 4(%%esp), %%edx\n"
"movl 0(%%esp), %%edi\n"
"leal 16(%%esp), %%esp\n"
"\n"
"/* --- END --- */\n"
"\n";
这一段汇编代码,主要的操作是:
保存edi等寄存器
将ecx的值设置为fprintf()所要打印的变量内容
调用方法__afl_maybe_log()
恢复寄存器
__afl_maybe_log作为插桩代码所执行的实际内容,会在接下来详细展开,这里我们只分析"movl $0x%08x, %%ecx\n"这条指令。
回到fprintf()命令:
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE));
可知R(MAP_SIZE)即为上述指令将ecx设置的值,即为。根据定义,MAP_SIZE为64K,我们在下文中还会看到他;R(x)的定义是(random() % (x)),所以R(MAP_SIZE)即为0到MAP_SIZE之间的一个随机数。
因此,在处理到某个分支,需要插入桩代码时,afl-as会生成一个随机数,作为运行时保存在ecx中的值。而这个随机数,便是用于标识这个代码块的key。在后面我们会详细介绍这个key是如何被使用的。
分支信息记录
在编译程序中注入的插装捕获了分支(边缘)覆盖,以及粗糙的分支命中计数。在分支点注入的代码本质上相当于:
cur_location = ;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
这里显示的执行的伪代码,我们回到_afl_maybe_log()中,可以看到执行代码为:
"__afl_store:\n"
"\n"
" /* Calculate and store hit for the code location specified in ecx. There\n"
" is a double-XOR way of doing this without tainting another register,\n"
" and we use it on 64-bit systems; but it's slower for 32-bit ones. */\n"
"\n"
#ifndef COVERAGE_ONLY
" movl __afl_prev_loc, %edi\n"
" xorl %ecx, %edi\n"
" shrl $1, %ecx\n"
" movl %ecx, __afl_prev_loc\n"
#else
" movl %ecx, %edi\n"
#endif /* ^!COVERAGE_ONLY */
"\n"
#ifdef SKIP_COUNTS
" orb $1, (%edx, %edi, 1)\n"
#else
" incb (%edx, %edi, 1)\n"
这里对应的便正是文档中的伪代码。具体地,变量__afl_prev_loc保存的是前一次跳转的”位置”,其值与ecx做异或后,保存在edi中,并以edx(共享内存)为基址,对edi下标处进行加一操作。而ecx的值右移1位后,保存在了变量__afl_prev_loc中。
那么,这里的ecx,保存的应该就是伪代码中的cur_location了。回忆之前介绍代码插桩的部分:
static const u8* trampoline_fmt_32 =
...
"movl $0x%08x, %%ecx\n"
"call __afl_maybe_log\n"
在每个插桩处,afl-as会添加相应指令,将ecx的值设为0到MAP_SIZE之间的某个随机数,从而实现了伪代码中的cur_location = <COMPILE_TIME_RANDOM>;。
因此,AFL为每个代码块生成一个随机数,作为其“位置”的记录;随后,对分支处的”源位置“和”目标位置“进行异或,并将异或的结果作为该分支的key,保存每个分支的执行次数。这个 cur_location的值随机产生来简化对于复杂程序的链接过程而且还要保持XOR输出的均匀分布。
AFL会用一片大小为64KB的共享内存来存储二进制程序的信息。在输出的map中的每一个Byte字节用来保存被插装程序中的 (branch_src, branch_dst)命中信息。
因为保存执行次数的实际是一张哈希表所以会存在碰撞问题。我们选择MAP_SIZE=64K,这其中可以保存大约 2k 到 10k程序分支点。对于不是很复杂的程序程序的碰撞还是可以接受的:
Branch cnt | Colliding tuples | Example targets
------------+------------------+-----------------
1,000 | 0.75% | giflib, lzo
2,000 | 1.5% | zlib, tar, xz
5,000 | 3.5% | libpng, libwebp
10,000 | 7% | libxml
20,000 | 14% | sqlite
50,000 | 30% | -
如果一个目标过于复杂,那么AFL状态面板中的map_density信息就会有相应的提示:
┬─ map coverage ─┴───────────────────────┤
│ map density : 3.61% / 14.13% │
│ count coverage : 6.35 bits/tuple │
┼─ findings in depth ────────────────────┤
这里的map density,就是这张哈希表的密度。可以看到,上面示例中,该次执行的哈希表密度仅为3.61%,即整个哈希表差不多有95%的地方还是空的,所以碰撞的概率很小。不过,如果目标很复杂,map density很大,那么就需要考虑到碰撞的影响了.
与此同时它的大小足够小,可以让map被分析。在接收端的几微秒内,并且毫不费力地适应在L2高速缓存。
这种形式的覆盖提供了比简单的块覆盖更深入地了解程序的执行路径。特别地,它将以下执行跟踪区分开来:
A -> B -> C -> D -> E (tuples: AB, BC, CD, DE)
A -> B -> D -> C -> E (tuples: AB, BD, DC, CE)
这有助于在底层代码中发现微妙的错误条件,因为安全漏洞通常与意外或不正确的状态转换相关联,而不仅仅是到达一个新的基本块。
移位操作的原因在伪代码的最后一行显示在本节的方向性保护tuples,假设target中存在A->A和B->B这样两个跳转,如果不右移,那么这两个分支对应的异或后的key都是0,从而无法区分;另一个例子是A->B和B->A,如果不右移,这两个分支对应的异或后的key也是相同的。
## 分支信息分析
fuzzer维护了在以前的执行中看到的tuples的全局map;这些数据可以与单独的跟踪进行快速的比较,并在几个dword或qword的指令周期和一个简单的循环中进行更新。
当一个突变的输入产生一个包含新的tuples的执行trace时,相应的输入文件将被保留并路由到稍后进行额外的处理。在执行跟踪中不触发新的局部规模状态转换的输入(例如不产生新的元组)将被丢弃,即使他们的总体控制流程是独一无二的。
这种方法允许对程序状态进行非常细粒度和长期的探索,而不必执行计算密集型复杂的执行跟踪和脆弱的全局比较,同时避免了路径爆炸的灾难。
为了说明该算法的属性,下面所示的第二个跟踪将被认为是全新的,因为存在新的tuples(CA,AE):
#1: A -> B -> C -> D -> E
#2: A -> B -> C -> A -> E
同时,因为#2的出现下面的路径将不会被认为是一条独特的路径,尽管有一个明显不同的总体执行路径:
#3: A -> B -> C -> A -> B -> C -> A -> B -> C -> D -> E
除了检测新的元组之外,模糊者还考虑了粗元组计数。这些被分成几个部分:
1, 2, 3, 4-7, 8-15, 16-31, 32-127, 128+
具体地,target是将每个分支的执行次数用1个byte来储存,而fuzzer则进一步把这个执行次数归入以下的buckets中:
static const u8 count_class_lookup8[256] = {
[0] = 0,
[1] = 1,
[2] = 2,
[3] = 4,
[4 ... 7] = 8,
[8 ... 15] = 16,
[16 ... 31] = 32,
[32 ... 127] = 64,
[128 ... 255] = 128
};
举个例子,如果某分支执行了1次,那么落入第2个bucket,其计数byte仍为1;如果某分支执行了4次,那么落入第5个bucket,其计数byte将变为8,等等。这样处理之后,对分支执行次数就会有一个简单的归类。例如,如果对某个测试用例处理时,分支A执行了32次;对另外一个测试用例,分支A执行了33次,那么AFL就会认为这两次的代码覆盖是相同的。当然,这样的简单分类肯定不能区分所有的情况,不过在某种程度上,处理了一些因为循环次数的微小区别,而误判为不同执行结果的情况。
通过内存和执行时间限制,执行的执行相当严格;默认情况下,超时设置为5倍于初始校准的执行速度,四舍五入为20ms。这种积极的超时是为了防止急剧的模糊性能下降,通过降入tarpits。比如,为了提高覆盖率1%,同时降低时间100倍;我们务实地拒绝它们,希望模糊者能够找到一种更便宜的方法来达到相同的代码。实证检验有力地表明,更慷慨的时间限制是不值得花费的。
不断变化的输入队列
在程序中产生新的状态转换的突变测试用例被添加到输入队列中,并作为未来几轮fuzzing的起点。它们补充,但不能自动替换现有的发现。
与更贪婪的遗传算法相比,这种方法允许工具逐步探索底层数据格式的各种分离和可能相互不兼容的特性,如下图所示 :
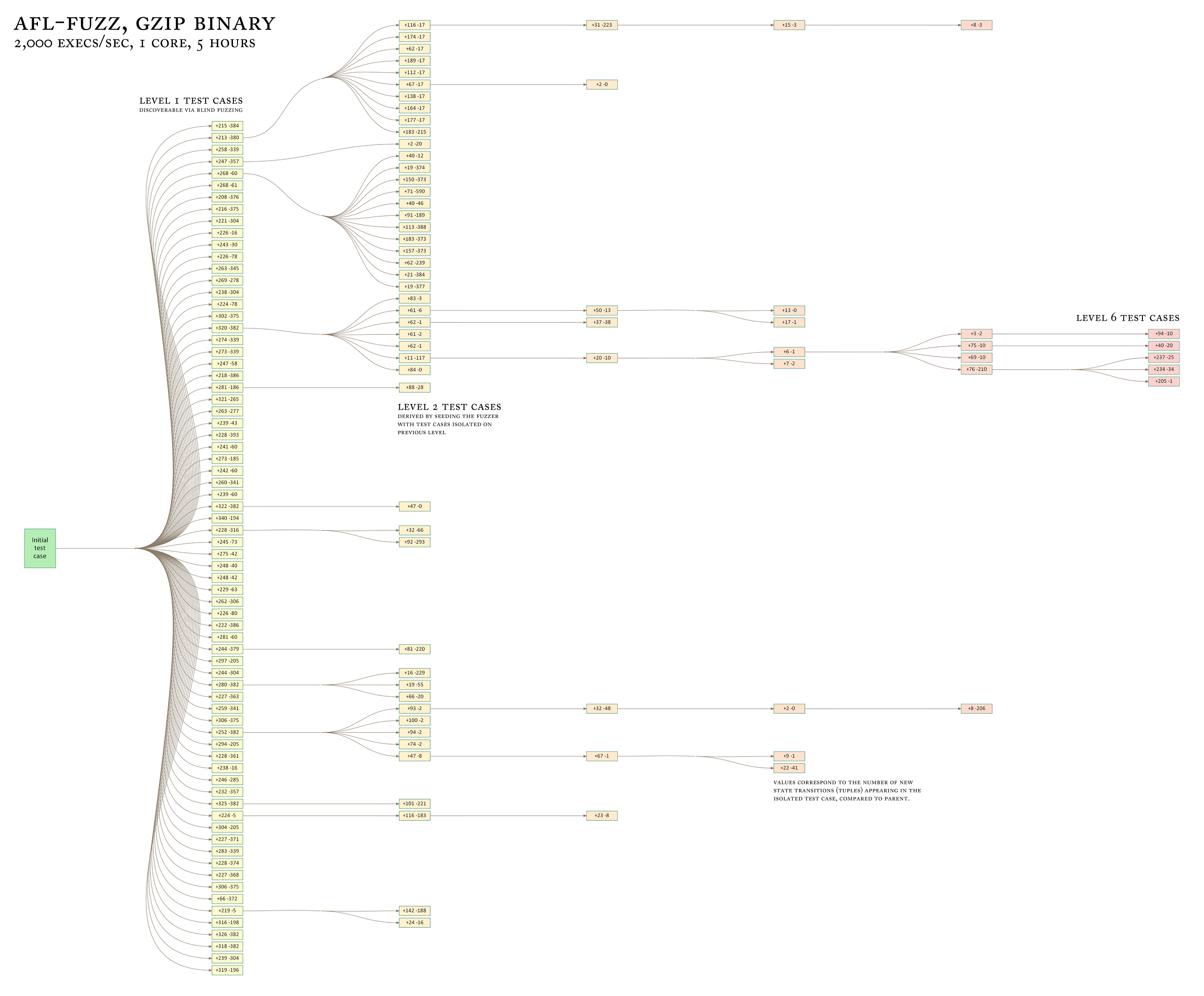
总的来讲,AFL维护了一个队列(queue),每次从这个队列中取出一个文件,对其进行大量变异,并检查运行后是否会引起目标崩溃、发现新路径等结果。变异的主要类型如下:
* bitflip,按位翻转,1变为0,0变为1
* arithmetic,整数加/减算术运算
* interest,把一些特殊内容替换到原文件中
* dictionary,把自动生成或用户提供的token替换/插入到原文件中
* havoc,中文意思是“大破坏”,此阶段会对原文件进行大量变异,具体见下文
* splice,中文意思是“绞接”,此阶段会将两个文件拼接起来得到一个新的文件
其中,前四项bitflip, arithmetic, interest, dictionary是非dumb mode(-d)和主fuzzer(-M)会进行的操作,由于其变异方式没有随机性,所以也称为deterministic fuzzing;havoc和splice则存在随机性,是所有状况的fuzzer(是否dumb mode、主从fuzzer)都会执行的变异。
bitflip
拿到一个原始文件,打头阵的就是bitflip,而且还会根据翻转量/步长进行多种不同的翻转,按照顺序依次为:
* bitflip 1/1,每次翻转1个bit,按照每1个bit的步长从头开始
* bitflip 2/1,每次翻转相邻的2个bit,按照每1个bit的步长从头开始
* bitflip 4/1,每次翻转相邻的4个bit,按照每1个bit的步长从头开始
* bitflip 8/8,每次翻转相邻的8个bit,按照每8个bit的步长从头开始,即依次对每个byte做翻转
* bitflip 16/8,每次翻转相邻的16个bit,按照每8个bit的步长从头开始,即依次对每个word做翻转
* bitflip 32/8,每次翻转相邻的32个bit,按照每8个bit的步长从头开始,即依次对每个dword做翻转
作为精妙构思的fuzzer,AFL不会放过每一个获取文件信息的机会。这一点在bitflip过程中就体现的淋漓尽致。具体地,在上述过程中,AFL巧妙地嵌入了一些对文件格式的启发式判断。
自动检测token
在进行bitflip 1/1变异时,对于每个byte的最低位(least significant bit)翻转还进行了额外的处理:如果连续多个bytes的最低位被翻转后,程序的执行路径都未变化,而且与原始执行路径不一致(检测程序执行路径的方式可见文章中“分支信息的分析”一节),那么就把这一段连续的bytes判断是一条token。
例如,PNG文件中用IHDR作为起始块的标识,那么就会存在类似于以下的内容:
........IHDR........
当翻转到字符I的最高位时,因为IHDR被破坏,此时程序的执行路径肯定与处理正常文件的路径是不同的;随后,在翻转接下来3个字符的最高位时,IHDR标识同样被破坏,程序应该会采取同样的执行路径。由此,AFL就判断得到一个可能的token:IHDR,并将其记录下来为后面的变异提供备选。
AFL采取的这种方式是非常巧妙的:就本质而言,这实际上是对每个byte进行修改并检查执行路径;但集成到bitflip后,就不需要再浪费额外的执行资源了。此外,为了控制这样自动生成的token的大小和数量,AFL还在config.h中通过宏定义了限制:
/* Length limits for auto-detected dictionary tokens: */
#define MIN_AUTO_EXTRA 3 #define MAX_AUTO_EXTRA 32
/* Maximum number of auto-extracted dictionary tokens to actually use in fuzzing (first value), and to keep in memory as candidates. The latter should be much higher than the former. */
#define USE_AUTO_EXTRAS 10
#define MAX_AUTO_EXTRAS (USE_AUTO_EXTRAS * 10)
对于一些文件来说,我们已知其格式中出现的token长度不会超过4,那么我们就可以修改MAX_AUTO_EXTRA为4并重新编译AFL,以排除一些明显不会是token的情况。遗憾的是,这些设置是通过宏定义来实现,所以不能做到运行时指定,每次修改后必须重新编译AFL。
生成effector map
在进行bitflip 8/8变异时,AFL还生成了一个非常重要的信息:effector map。这个effector map几乎贯穿了整个deterministic fuzzing的始终。
具体地,在对每个byte进行翻转时,如果其造成执行路径与原始路径不一致,就将该byte在effector map中标记为1,即“有效”的,否则标记为0,即“无效”的。
这样做的逻辑是:如果一个byte完全翻转,都无法带来执行路径的变化,那么这个byte很有可能是属于”data”,而非”metadata”(例如size, flag等),对整个fuzzing的意义不大。所以,在随后的一些变异中,会参考effector map,跳过那些“无效”的byte,从而节省了执行资源。
由此,通过极小的开销(没有增加额外的执行次数),AFL又一次对文件格式进行了启发式的判断。看到这里,不得不叹服于AFL实现上的精妙。
不过,在某些情况下并不会检测有效字符。第一种情况就是dumb mode或者从fuzzer,此时文件所有的字符都有可能被变异。第二、第三种情况与文件本身有关:
/* Minimum input file length at which the effector logic kicks in: */
#define EFF_MIN_LEN 128
/* Maximum effector density past which everything is just fuzzed unconditionally (%): */
#define EFF_MAX_PERC 90
即默认情况下,如果文件小于128 bytes,那么所有字符都是“有效”的;同样地,如果AFL发现一个文件有超过90%的bytes都是“有效”的,那么也不差那10%了,大笔一挥,干脆把所有字符都划归为“有效”。
arithmetic
在bitflip变异全部进行完成后,便进入下一个阶段:arithmetic。与bitflip类似的是,arithmetic根据目标大小的不同,也分为了多个子阶段:
- arith 8/8,每次对8个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个byte进行整数加减变异
- arith 16/8,每次对16个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个word进行整数加减变异
- arith 32/8,每次对32个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个dword进行整数加减变异
加减变异的上限,在config.h中的宏ARITH_MAX定义,默认为35。所以,对目标整数会进行+1, +2, …, +35, -1, -2, …, -35的变异。特别地,由于整数存在大端序和小端序两种表示方式,AFL会贴心地对这两种整数表示方式都进行变异。
此外,AFL还会智能地跳过某些arithmetic变异。第一种情况就是前面提到的effector map:如果一个整数的所有bytes都被判断为“无效”,那么就跳过对整数的变异。第二种情况是之前bitflip已经生成过的变异:如果加/减某个数后,其效果与之前的某种bitflip相同,那么这次变异肯定在上一个阶段已经执行过了,此次便不会再执行。
interest
下一个阶段是interest,具体可分为:
- interest 8/8,每次对8个bit进替换,按照每8个bit的步长从头开始,即对文件的每个byte进行替换
- interest 16/8,每次对16个bit进替换,按照每8个bit的步长从头开始,即对文件的每个word进行替换
- interest 32/8,每次对32个bit进替换,按照每8个bit的步长从头开始,即对文件的每个dword进行替换
而用于替换的”interesting values”,是AFL预设的一些比较特殊的数:
static s8 interesting_8[] = { INTERESTING_8 };
static s16 interesting_16[] = { INTERESTING_8, INTERESTING_16 };
static s32 interesting_32[] = { INTERESTING_8, INTERESTING_16, INTERESTING_32 };
这些数的定义在config.h文件中:
/* List of interesting values to use in fuzzing. */
#define INTERESTING_8 \ -128, /* Overflow signed 8-bit when decremented */ \ -1, /* */ \ 0, /* */ \ 1, /* */ \ 16, /* One-off with common buffer size */ \ 32, /* One-off with common buffer size */ \ 64, /* One-off with common buffer size */ \ 100, /* One-off with common buffer size */ \ 127 /* Overflow signed 8-bit when incremented */
#define INTERESTING_16 \ -32768, /* Overflow signed 16-bit when decremented */ \ -129, /* Overflow signed 8-bit */ \ 128, /* Overflow signed 8-bit */ \ 255, /* Overflow unsig 8-bit when incremented */ \ 256, /* Overflow unsig 8-bit */ \ 512, /* One-off with common buffer size */ \ 1000, /* One-off with common buffer size */ \ 1024, /* One-off with common buffer size */ \ 4096, /* One-off with common buffer size */ \ 32767 /* Overflow signed 16-bit when incremented */
#define INTERESTING_32 \ -2147483648LL, /* Overflow signed 32-bit when decremented */ \ -100663046, /* Large negative number (endian-agnostic) */ \ -32769, /* Overflow signed 16-bit */ \ 32768, /* Overflow signed 16-bit */ \ 65535, /* Overflow unsig 16-bit when incremented */ \ 65536, /* Overflow unsig 16 bit */ \ 100663045, /* Large positive number (endian-agnostic) */ \ 2147483647 /* Overflow signed 32-bit when incremented */
可以看到,用于替换的基本都是可能会造成溢出的数。
与之前类似,effector map仍然会用于判断是否需要变异;此外,如果某个interesting value,是可以通过bitflip或者arithmetic变异达到,那么这样的重复性变异也是会跳过的。
dictionary
进入到这个阶段,就接近deterministic fuzzing的尾声了。具体有以下子阶段:
- user extras (over),从头开始,将用户提供的tokens依次替换到原文件中
- user extras (insert),从头开始,将用户提供的tokens依次插入到原文件中
- auto extras (over),从头开始,将自动检测的tokens依次替换到原文件中
其中,用户提供的tokens,是在词典文件中设置并通过-x选项指定的,如果没有则跳过相应的子阶段。
user extras (over)
对于用户提供的tokens,AFL先按照长度从小到大进行排序。这样做的好处是,只要按照顺序使用排序后的tokens,那么后面的token不会比之前的短,从而每次覆盖替换后不需要再恢复到原状。
随后,AFL会检查tokens的数量,如果数量大于预设的MAX_DET_EXTRAS(默认值为200),那么对每个token会根据概率来决定是否进行替换:
for (j = 0; j < extras_cnt; j++) {
/* Skip extras probabilistically if extras_cnt > MAX_DET_EXTRAS. Also skip them if there's no room to insert the payload, if the token is redundant, or if its entire span has no bytes set in the effector map. */
if ((extras_cnt > MAX_DET_EXTRAS && UR(extras_cnt) >= MAX_DET_EXTRAS) ||
extras[j].len > len - i ||
!memcmp(extras[j].data, out_buf + i, extras[j].len) ||
!memchr(eff_map + EFF_APOS(i), 1, EFF_SPAN_ALEN(i, extras[j].len))) {
stage_max--;
continue;
}
这里的UR(extras_cnt)是运行时生成的一个0到extras_cnt之间的随机数。所以,如果用户词典中一共有400个tokens,那么每个token就有200/400=50%的概率执行替换变异。我们可以修改MAX_DET_EXTRAS的大小来调整这一概率。
由上述代码也可以看到,effector map在这里同样被使用了:如果要替换的目标bytes全部是“无效”的,那么就跳过这一段,对下一段目标执行替换。
user extras (insert)
这一子阶段是对用户提供的tokens执行插入变异。不过与上一个子阶段不同的是,此时并没有对tokens数量的限制,所以全部tokens都会从原文件的第1个byte开始,依次向后插入;此外,由于原文件并未发生替换,所以effector map不会被使用。
这一子阶段最特别的地方,就是变异不能简单地恢复。之前每次变异完,在变异位置处简单取逆即可,例如bitflip后,再进行一次同样的bitflip就恢复为原文件。正因为如此,之前的变异总体运算量并不大。
但是,对于插入这种变异方式,恢复起来则复杂的多,所以AFL采取的方式是:将原文件分割为插入前和插入后的部分,再加上插入的内容,将这3部分依次复制到目标缓冲区中(当然这里还有一些小的优化,具体可阅读代码)。而对每个token的每处插入,都需要进行上述过程。所以,如果用户提供了大量tokens,或者原文件很大,那么这一阶段的运算量就会非常的多。直观表现上,就是AFL的执行状态栏中,”user extras (insert)”的总执行量很大,执行时间很长。如果出现了这种情况,那么就可以考虑适当删减一些tokens。
auto extras (over)
这一项与”user extras (over)”很类似,区别在于,这里的tokens是最开始bitflip阶段自动生成的。另外,自动生成的tokens总量会由USE_AUTO_EXTRAS限制(默认为10)。
havoc
对于非dumb mode的主fuzzer来说,完成了上述deterministic fuzzing后,便进入了充满随机性的这一阶段;对于dumb mode或者从fuzzer来说,则是直接从这一阶段开始。
havoc,顾名思义,是充满了各种随机生成的变异,是对原文件的“大破坏”。具体来说,havoc包含了对原文件的多轮变异,每一轮都是将多种方式组合(stacked)而成:
- 随机选取某个bit进行翻转
- 随机选取某个byte,将其设置为随机的interesting value
- 随机选取某个word,并随机选取大、小端序,将其设置为随机的interesting value
- 随机选取某个dword,并随机选取大、小端序,将其设置为随机的interesting value
- 随机选取某个byte,对其减去一个随机数
- 随机选取某个byte,对其加上一个随机数
- 随机选取某个word,并随机选取大、小端序,对其减去一个随机数
- 随机选取某个word,并随机选取大、小端序,对其加上一个随机数
- 随机选取某个dword,并随机选取大、小端序,对其减去一个随机数
- 随机选取某个dword,并随机选取大、小端序,对其加上一个随机数
- 随机选取某个byte,将其设置为随机数
- 随机删除一段bytes
- 随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入一段随机选取的数
- 随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是替换成一段随机选取的数
- 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)替换
- 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)插入
怎么样,看完上面这么多的“随机”,有没有觉得晕?还没完,AFL会生成一个随机数,作为变异组合的数量,并根据这个数量,每次从上面那些方式中随机选取一个(可以参考高中数学的有放回摸球),依次作用到文件上。如此这般丧心病狂的变异,原文件就大概率面目全非了,而这么多的随机性,也就成了fuzzing过程中的不可控因素,即所谓的“看天吃饭”了。
### splice
历经了如此多的考验,文件的变异也进入到了最后的阶段:splice。如其意思所说,splice是将两个seed文件拼接得到新的文件,并对这个新文件继续执行havoc变异。
具体地,AFL在seed文件队列中随机选取一个,与当前的seed文件做对比。如果两者差别不大,就再重新随机选一个;如果两者相差比较明显,那么就随机选取一个位置,将两者都分割为头部和尾部。最后,将当前文件的头部与随机文件的尾部拼接起来,就得到了新的文件。在这里,AFL还会过滤掉拼接文件未发生变化的情况。
cycle
于是乎,一个seed文件,在上述的全部变异都执行完成后,就…抱歉,还没结束。
上面的变异完成后,AFL会对文件队列的下一个进行变异处理。当队列中的全部文件都变异测试后,就完成了一个”cycle”,这个就是AFL状态栏右上角的”cycles done”。而正如cycle的意思所说,整个队列又会从第一个文件开始,再次进行变异,不过与第一次变异不同的是,这一次就不需要再进行deterministic fuzzing了。
当然,如果用户不停止AFL,那么seed文件将会一遍遍的变异下去。
这里有几个该算法的实例:
实例一
实例二
这个过程产生的合成文集本质上是一个紧凑的集合,“嗯,这做了一些新的东西!”输入文件,并且可以用来在生产线上进行任何其他的测试过程(例如手动压力测试资源密集型的桌面应用程序)。
通过这种方法,大多数目标的队列都在1k到10k之间;大约10%-30%的原因是新元组的发现,其余的则与命中数的变化有关。
下表比较了发现文件语法的相对能力,并在使用几种不同的方法来引导fuzzing时,可以探索程序状态。被插装的target是用-O3编译的GNU补丁2.7.3,并使用一个虚拟文本文件作为种子文件;会话由一个带有afl-fuzz的输入队列的单一传递组成:
Fuzzer guidance | Blocks | Edges | Edge hit | Highest-coverage
strategy used | reached | reached | cnt var | test case generated
------------------+---------+---------+----------+---------------------------
(Initial file) | 156 | 163 | 1.00 | (none)
| | | |
Blind fuzzing S | 182 | 205 | 2.23 | First 2 B of RCS diff
Blind fuzzing L | 228 | 265 | 2.23 | First 4 B of -c mode diff
Block coverage | 855 | 1,130 | 1.57 | Almost-valid RCS diff
Edge coverage | 1,452 | 2,070 | 2.18 | One-chunk -c mode diff
AFL model | 1,765 | 2,597 | 4.99 | Four-chunk -c mode diff
盲目的模糊(“S”)的第一个条目对应于执行一个单独的测试;第二组数据(“L”)显示了在循环中运行的fuzzing,它的执行周期与插装的运行周期相当,这需要更多的时间来完全处理不断增长的队列。
在一个单独的实验中,我们得到了大致相似的结果,在这个实验中,fuzzer被修改了,为了编译出所有的随机的fuzzing阶段,只留下一系列基本的、连续的操作,比如连续的比特翻转。因为这种模式无法改变输入文件的大小,所以会话被植入一个有效的统一格式:
Queue extension | Blocks | Edges | Edge hit | Number of unique
strategy used | reached | reached | cnt var | crashes found
------------------+---------+---------+----------+------------------
(Initial file) | 624 | 717 | 1.00 | -
| | | |
Blind fuzzing | 1,101 | 1,409 | 1.60 | 0
Block coverage | 1,255 | 1,649 | 1.48 | 0
Edge coverage | 1,259 | 1,734 | 1.72 | 0
AFL model | 1,452 | 2,040 | 3.16 | 1
在早些时候的研究中,先前关于基因模糊的研究依赖于维持一个单一的测试用例,并将其发展为最大限度的覆盖。至少在上面描述的测试中,这种“贪婪”的方法似乎没有给盲目的fuzzing策略带来实质性的好处。
剔除语料库
上面概述的启发式状态探索方法意味着稍后在运行中合成的一些测试用例可能具有边缘覆盖,这是对其祖先提供的覆盖范围的严格超集。
为了优化模糊工作,AFL使用快速算法定期重新评估队列,该算法选择一个较小的测试用例子集,该子集仍覆盖到目前为止所看到的每个元组,并且其特征使它们对Fuzzing特别有利。
该算法通过为每个队列条目分配与其执行延迟和文件大小成正比的分数来工作;然后为每个tuples选择最低得分候选者。
/* Faster-executing or smaller test cases are favored. */
if (fav_factor > top_rated[i]->exec_us * top_rated[i]->len) continue;
然后使用简单的工作流程按顺序处理tuples:
1.找到尚未在临时工作集中的下一个tuples;
2.找到这个tuples的获胜队列条目;
3.在工作集中注册该队列trace中存在的所tuples,
4.返回 1 看看是否还有遗漏的tuples没有发现。
所生成的“favored”条目通常比起始数据集小5到10倍, Non-favored的条目不会被丢弃,但是当遇到队列时,它们会被以不同的概率跳过:
* 如果存在新的尚未被fuzzed过tuples的favored的队列,那么有99%的概率跳过non-favored的输入,AFL会去选择favored的队列.
* 如果没有没有新的favorites:
* 如果当前non-favored输入之前已经fuzzed,则会在95%的时间内被跳过。
* 如果它还没有经过任何fuzzing轮次,跳过的几率会下降到75%。
基于经验测试,这提供了队列循环速度与测试案例多样性之间的合理平衡。
使用afl-cmin可以在输入或输出语料库上执行稍微复杂但较慢的剔除操作。该工具会永久丢弃多余的条目,并生成适用于afl-fuzz或插件的较小的语料库。
修剪输入文件
文件大小对模糊性能有很大影响,这是因为大文件使目标二进制文件变得更慢,并且因为它们减少了突变将触及重要的格式控制结构而不是冗余数据块的可能性。这在perf_tips.txt中有更详细的讨论。
用户可能会提供低质量的起始语料库,某些类型的突变可能会产生迭代地增加生成文件的大小的效果,因此应对这一趋势是很重要的。
幸运的是,插装反馈提供了一种简单的方法来自动删除输入文件,同时确保对文件的更改不会对执行路径产生影响。
在afl-fuzz中内置的修边器试图按可变长度和stepover顺序删除数据块;任何不影响跟踪映射校验和的删除都被提交到磁盘。修剪器的设计并不是特别彻底;相反,它试图在精度和在进程上花费的execve()调用的数量之间取得平衡,选择块大小和stepover来匹配。每个文件的平均增益大约在5%到20%之间。
独立的afl-tmin工具使用了更详尽的迭代算法,并尝试在修剪过的文件上执行字母标准化。afl-tmin的操作如下。
首先,工具自动选择操作模式。如果初始输入崩溃了目标二进制文件,afl-tmin将以非插装模式运行,只需保留任何能产生更简单文件但仍然会使目标崩溃的调整。如果目标是非崩溃的,那么这个工具使用一个插装的模式,并且只保留那些产生完全相同的执行路径的微调。
实际的最小化算法是:
1.尝试将大块数据与大量的步骤归零。从经验上看,这可以通过在以后的时间内抢先进行更细粒度的工作来减少执行的次数。
2.执行块删除过程,减少块大小和stepovers,二进制搜索式(binary-search-style)。
3.通过计算唯一字符并尝试用零值批量替换每个字符来执行字母表规范化。
4.作为最后的结果,对非零字节执行逐字节标准化。
afl-tmin用ASCII数字“0”代替0x00字节。这样做是因为这样的修改不太可能干扰文本解析,因此更有可能成功地将文本文件最小化。
这里使用的算法与学术工作中提出的一些其他测试用例最小化方法相比所涉及的内容较少,而且需要的执行次数少得多,并且倾向于在大多数实际应用程序中产生可比较的结果。
Fuzzing 策略
插装提供的反馈信息可以很容易地理解各种fuzzing策略的价值,并优化其参数,以使它们在各种文件类型中均能很好地工作。afl-fuzz使用的策略通常是格式不可知的,并在此处进行更详细的讨论:
Binary fuzzing strategies: what works, what doesn’t 点这里
有点值得注意的是,特别是早期,afl-fuzz完成的大部分工作实际上都是高度确定性的,并且只能在后期阶段进行随机堆叠修改和测试用例拼接。确定性策略包括:
* 顺序的以不同的长度和stepover进行位翻转;
* 对小整数的顺序加和减;
* 顺序插入已知的有趣整数(0,1,INT_MAX,等等)
以确定性步骤运行的目的与它们倾向于生成紧凑的测试用例以及区分非崩溃和崩溃输入之间的小差异有关。
在确定性fuzzing之后,非确定性步骤包括多层位翻转,插入,删除,算术运算和拼接不同的测试用例。
所有这些策略的相对收益率和execve()成本已经被调查,并在上述博客中进行了讨论。
由于historical_notes.txt中讨论的原因(主要是性能,简单性和可靠性),AFL通常不会试图推断特定突变与程序状态之间的关系;fuzzing的步骤名义上是盲目的,并且仅由输入队列的演化设计引导。
也就是说,这个规则有一个(不重要的)例外:当一个新的队列条目经历了初始的确定性模糊步骤集合,并且观察到文件中某些区域的调整对执行路径的校验和没有影响 ,他们可能会被排除在确定性模糊的其余阶段 - 而模糊器可能会直接进行随机调整。 特别是对于冗长的,人类可读的数据格式,这可以将执行的数量减少10-40%左右,而不会导致覆盖率的明显下降。在极端情况下,例如通常为块对齐的tar档案,收益可高达90%。
由于底层的"effector maps"是每个队列条目的本地化,并且只有在不改变底层文件大小或总体布局的确定性阶段才会保持有效,这种机制似乎非常可靠,并且被证明是很容易实现的。
Dictionaries
插装提供的反馈可以很容易地在某些类型的输入文件中自动识别语法标记,并检测到预定义或自动检测的字典术语的某些组合构成了测试解析器的有效语法。
关于如何在afl-fuzz中实现这些功能的讨论可以在这里找到:
afl-fuzz: making up grammar with a dictionary in hand
通常容易获得的语法标记以纯粹随机的方式组合在一起时,插装和队列的进化设计一起提供了反馈机制来区分无意义的突变和触发被插装代码中的新行为的突变-并在此发现之上逐步构建更复杂的语法。
这些字典已经被证明可以使fuzzer快速地重建高度冗长和复杂的语言的语法,如JavaScript、SQL或XML;在上面提到的博客中给出了几个生成SQL语句的例子。
有趣的是,AFL仪器还允许模糊器自动隔离已存在于输入文件中的语法标记。它可以通过查找运行的字节来实现,该字节在翻转时会对程序的执行路径产生一致的变化; 这暗示了一个 underlying atomic与代码中预定义值的比较。fuzzer依靠这个信号来构建紧凑的“自动字典”,然后与其他fuzzing策略一起使用。
De-duping crashes
对于任何有效的fuzzing工具来说,重复崩溃是更重要的问题之一。许多解决办法都不好,特别是如果故障发生在公共库函数中(比如strcmp,strcpy),那么只关注错误地址可能会导致完全不相关的问题聚集在一起(这个我也不太懂,后面再补充);如果错误可以通过许多不同的,可能是递归的代码路径达到,那么校验和检查调用堆栈回溯跟踪会导致极端的崩溃计数膨胀。
如果满足以下两个条件中的任何一个,afl-fuzz中实现的解决方案将认为崩溃是唯一的:
* crash trace中包含一个在以前的崩溃中没有看到的tuples;
* crash trace中缺少一个在早期错误中总是存在的tuples。
这种方法很容易受到早期一些路径计数膨胀的影响,但是它具有很强的自限性作用,类似于执行路径分析逻辑,这是afl-fuzz的基石。
崩溃调查 (Investigating crashes)
许多类型崩溃的可利用性可能不明确;afl-fuzz试图通过提供crash exploration模式来解决这个问题,其中已知错误的测试用例fuzzed的方式与fuzzer的正常操作非常相似,但有一个限制会导致任何非碰撞突变被丢弃。
在这里可以找到关于这种方法的价值的详细讨论:
afl-fuzz: crash exploration mode
该方法使用插装反馈来探索崩溃程序的状态,以克服模糊的故障状态,然后将新发现的输入隔离起来供人们审阅。
关于崩溃的问题,值得注意的是,与正常的队列条目相比,崩溃的输入没有被修剪;它们被精确地保存在一起,以便更容易地将它们与队列中的父类、非碰撞条目进行比较。也就是说,afl-tmin可以用来随意收缩它们。
并行化
并行化机制依赖于定期检查由其他CPU内核或远程机器上的独立运行实例产生的队列,然后有选择地引入测试用例,这些测试用例在本地尝试时会产生现有的fuzzer尚未看到的行为。
这允许在fuzzing设置中具有极大的灵活性,包括针对通用数据格式的不同解析器同步运行实例,通常具有协同作用。
想要了解AFL关于并行化的设计,可以去查阅 parallel_fuzzing.txt。
Binary-only instrumentation(只有二进制程序的插装)
在“用户模拟”模式下,使用单独构建的QEMU版本可以完二进制程序的黑盒插装。这也允许执行跨体系结构的代码 - 比如x86上的ARM二进制代码。
QEMU使用基本块作为翻译单元;插装在此基础上实现,并使用一个与编译时hooks类似的模型:
if (block_address > elf_text_start && block_address < elf_text_end) {
cur_location = (block_address >> 4) ^ (block_address << 8);
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
}
第二行中加入的移位和异或指令是为了消减指令对齐的影响。
像QEMU、DynamoRIO和PIN这样的二进制翻译的启动是相当缓慢的;为了解决这个问题,QEMU模式利用了一个类似于编译时插装的fork服务器,在开始时暂停然后有效地生成已经初始化的进程的副本。
新基本块的首次翻译也会带来大量的延迟。为了消除这个问题,AFL fork服务器通过在运行模拟器和父进程之间提供通道来扩展。这个通道用于通知父节点关于任何新遇到的块的地址,并将它们添加到转换缓存中,以便将来的子进程复制。
通过这两个优化的方法,QEMU模式的开销大约为2-5倍,而PIN为100x +。
关于这部分以后会有更加详细的分析。
afl-analyse 工具
文件格式分析器是前面讨论的最小化算法的一个简单扩展;该工具没有试图试图删除无操作块,而是执行一系列的字节翻转的步骤,然后在输入文件中注释掉字节的运行。
它使用以下分类方案:
* “无操作块”——在这些片段中,位翻转不会对控制流产生明显的变化。常见的例子可能是注释部分、位图文件中的像素数据等等。
* “表面的内容”——有些部分,但不是全部,都产生了一些控制流的变化。示例可能包括大量文档中的都有的字符串(例如,XML、RTF)。
* “临界流” ——— 一系列字节,其中所有位翻转以不同但相关的方式改变控制流。 这可能是压缩数据,非原子比较关键字或魔术值等。
* “可疑长度字段” - 小的原子整数,当以任何方式触及时,会导致程序控制流程的一致更改,这表明长度检查失败。
* “可疑的cksum或magic int” - 一个整数,其行为与长度字段相似,但有一个数值,使长度解释不太可能。 这暗示了校验和或其他“魔术”整数。
* “可疑的校验和块” - 一段长串的数据,其中任何变化总是触发相同的新执行路径。 在进行任何后续解析之前,可能由于未通过校验和或类似的完整性检查而导致。
* “魔法值部分”——一个通用的标记,其中的变化会导致前面列出的二进制行为的类型,但是它不符合任何其他标准。可能是一个基本的关键字。

















 5052
5052






 到【灌水乐园】发言
到【灌水乐园】发言







