







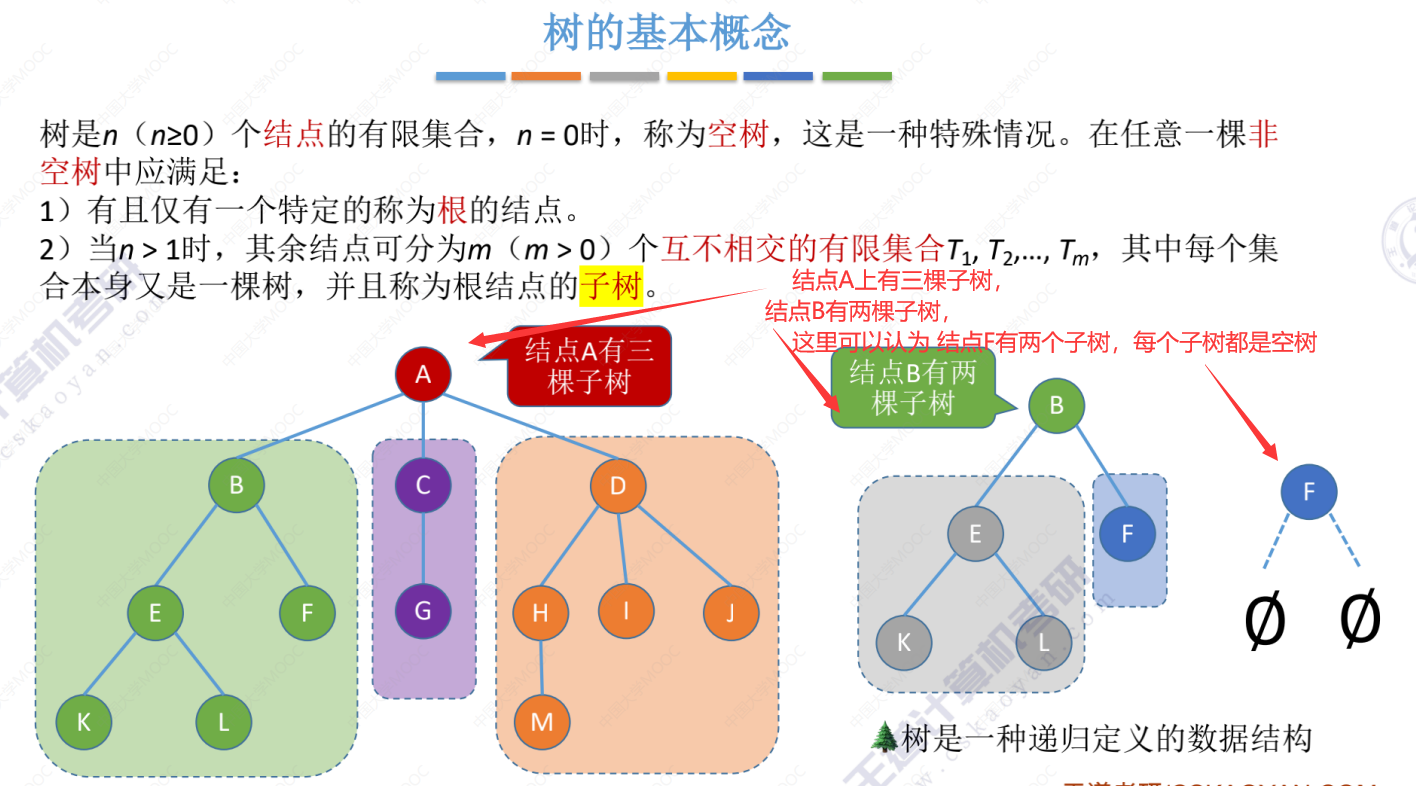
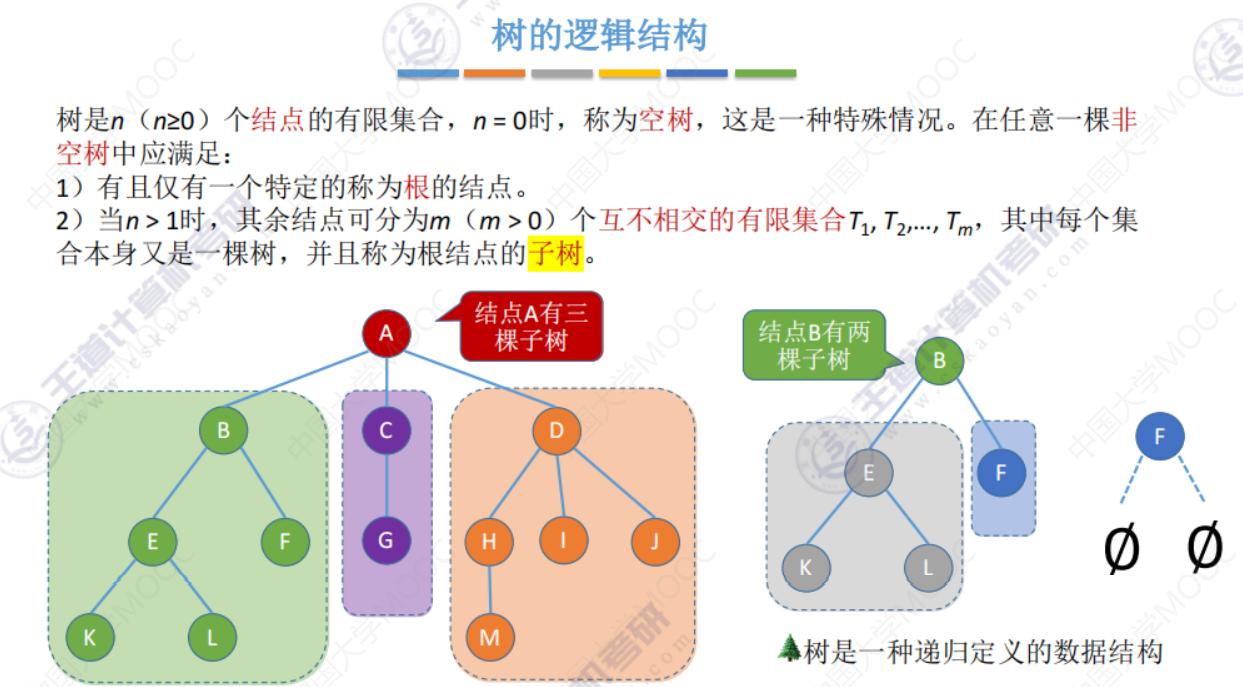
5.1-1 树的定义和基本术语
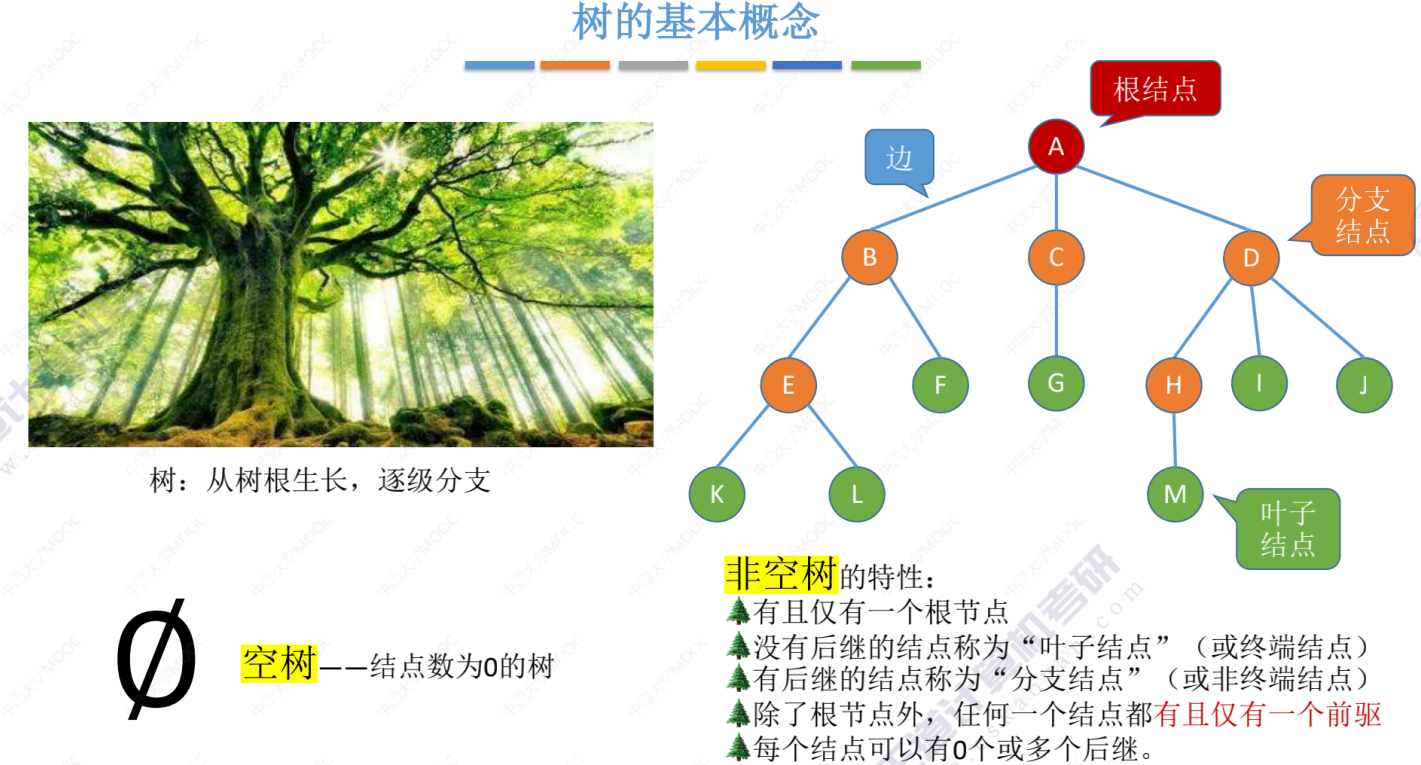
树的基本概念
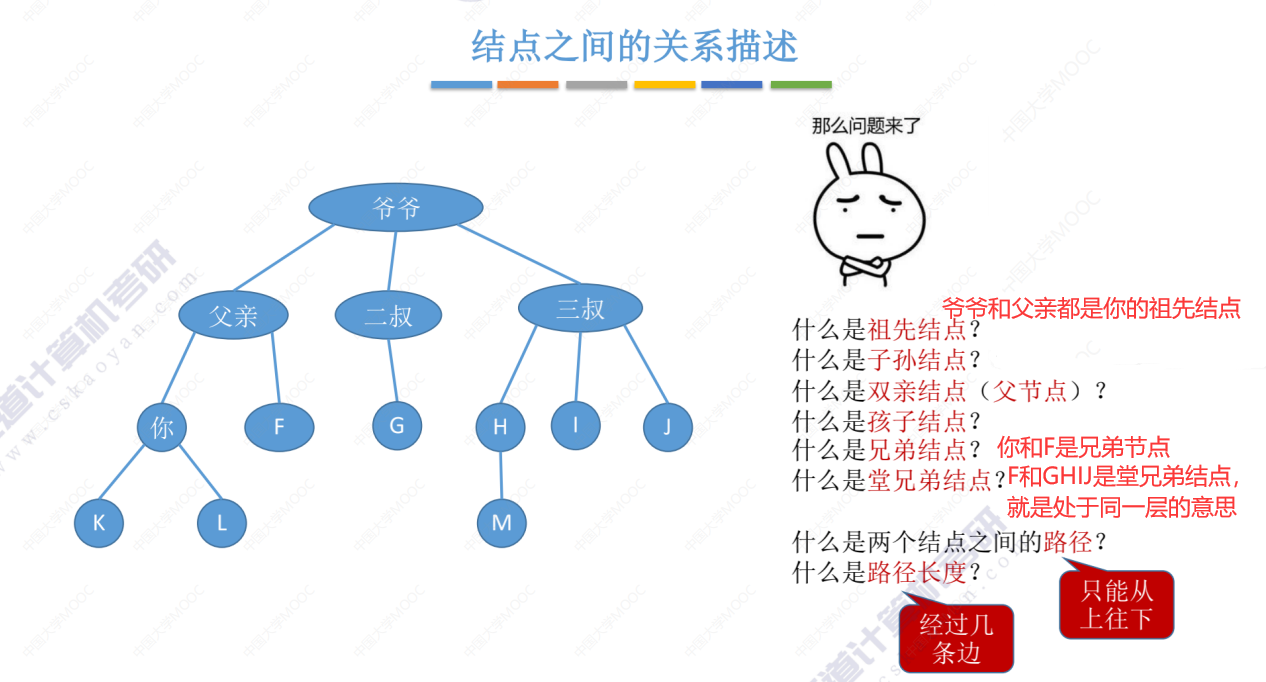
结点之间的关系描述
两个结点之间的路径只能是 从上往下

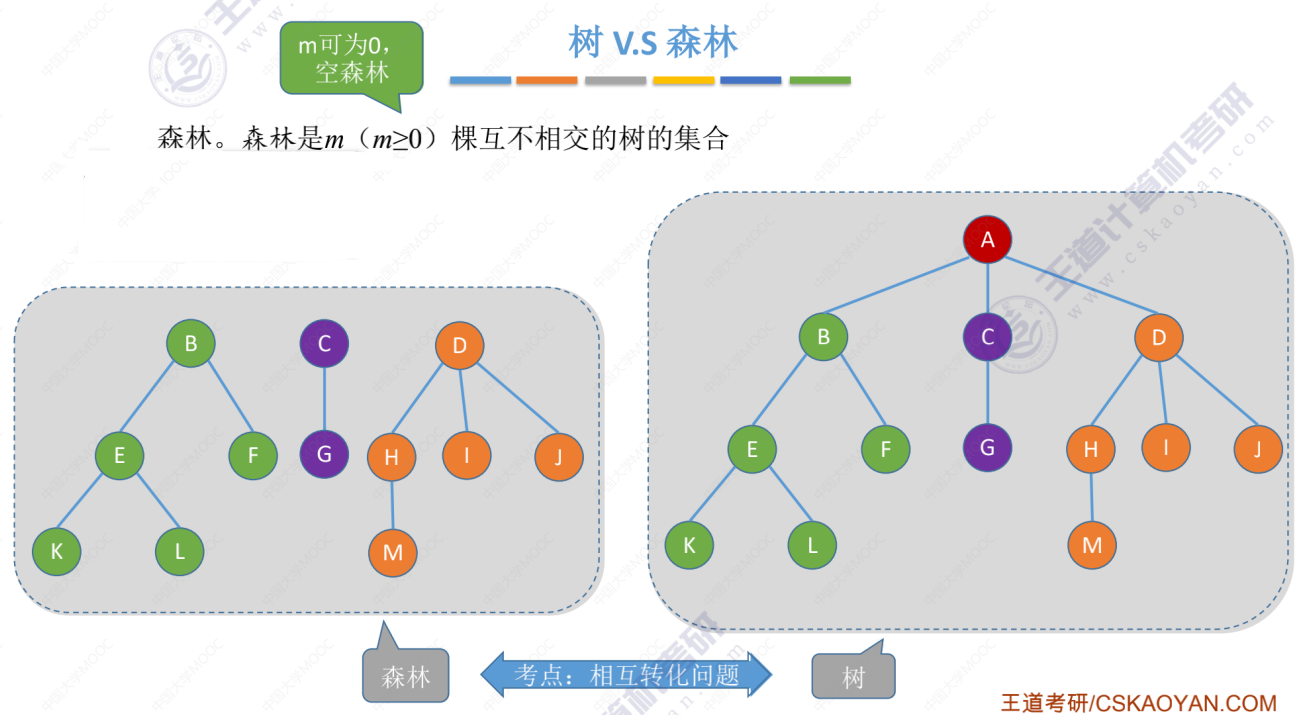
有序树、无序树、森林

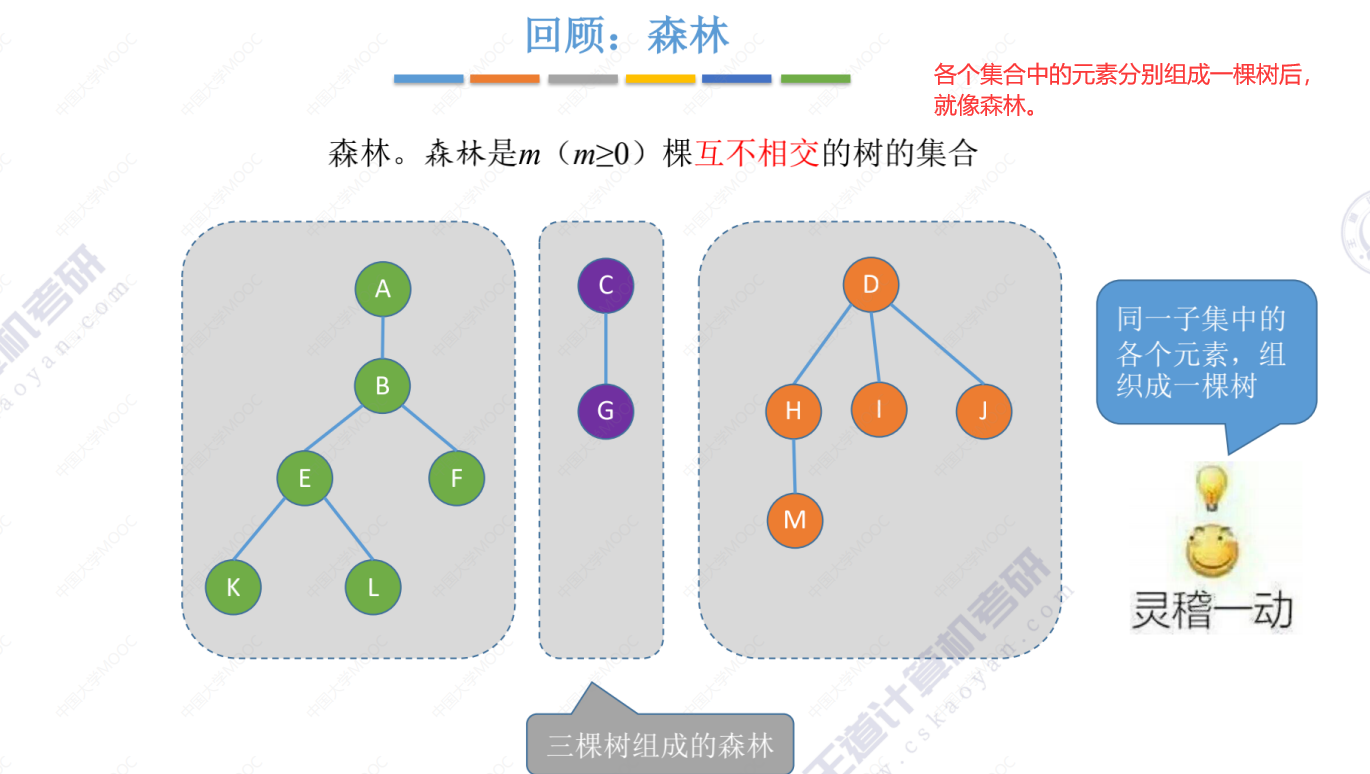
把森林通过结点连起来就是一棵树
5.1-2 树的性质
考点1
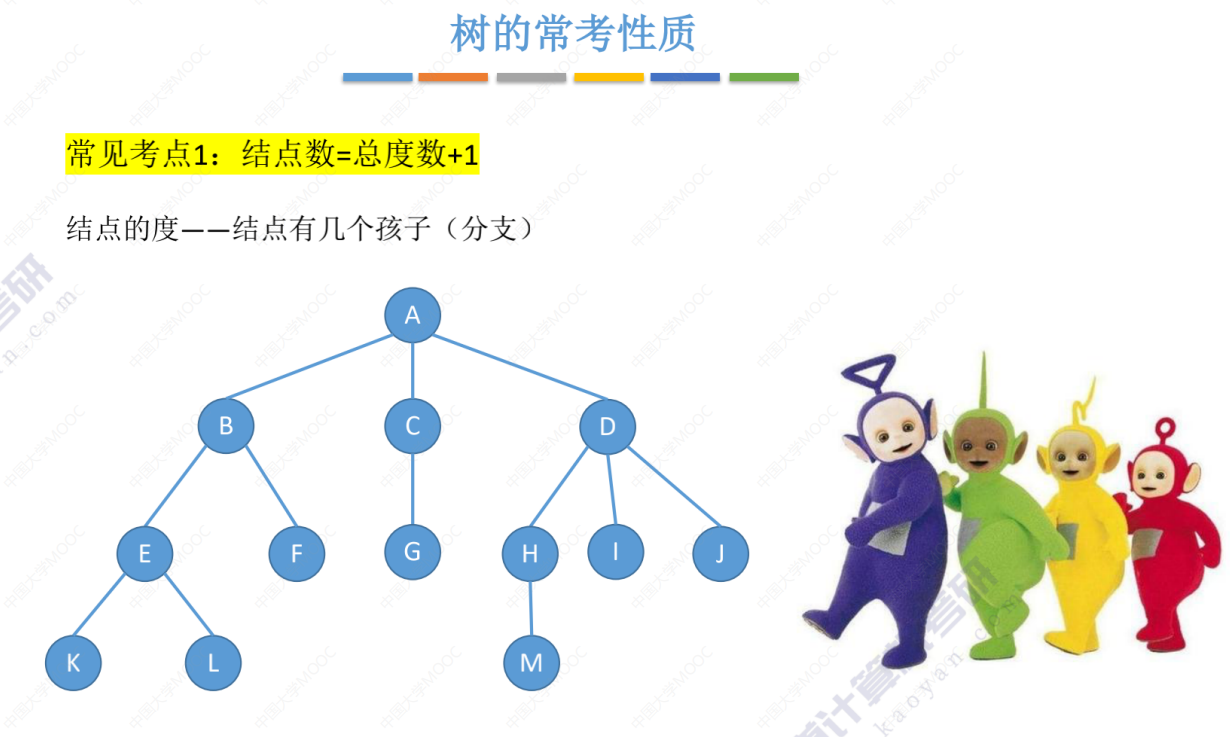
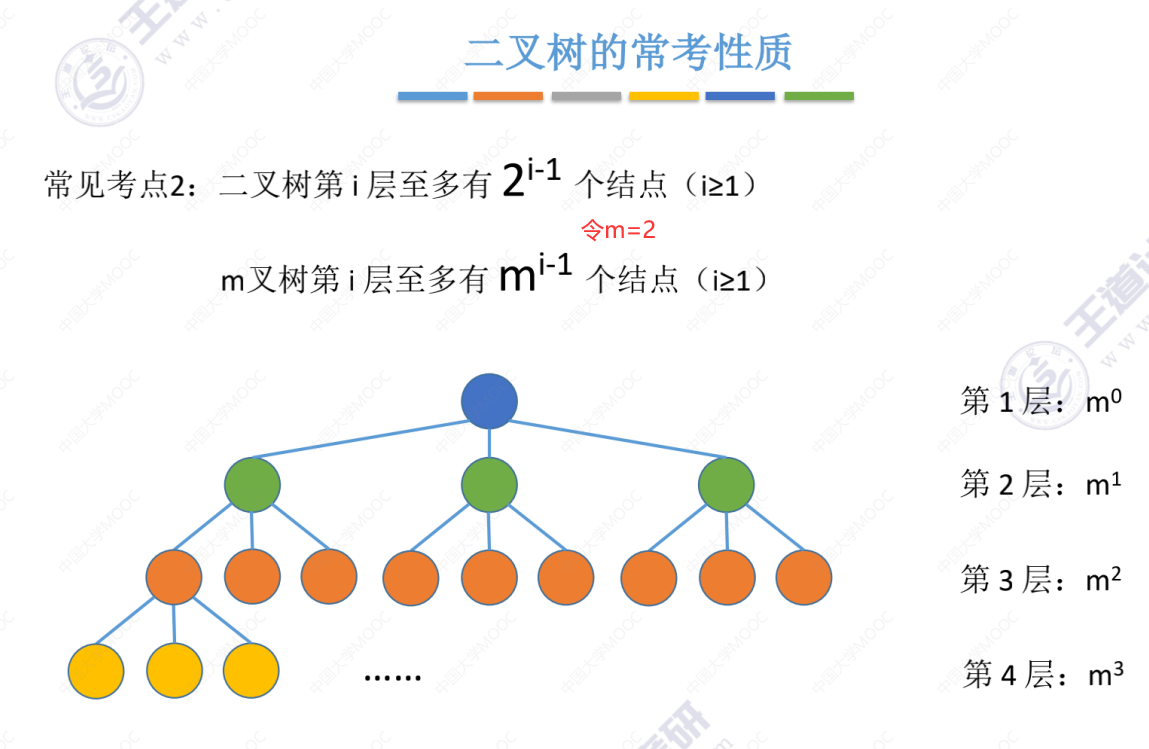
考点2
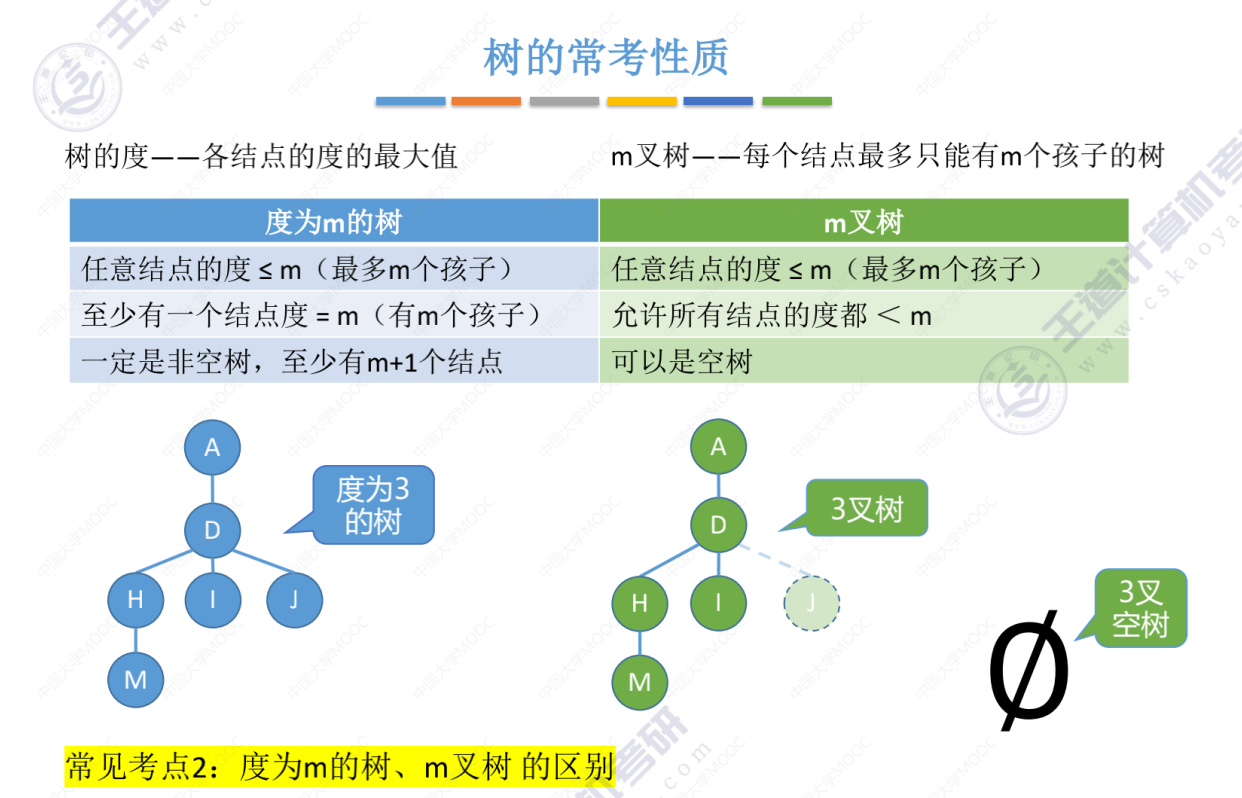
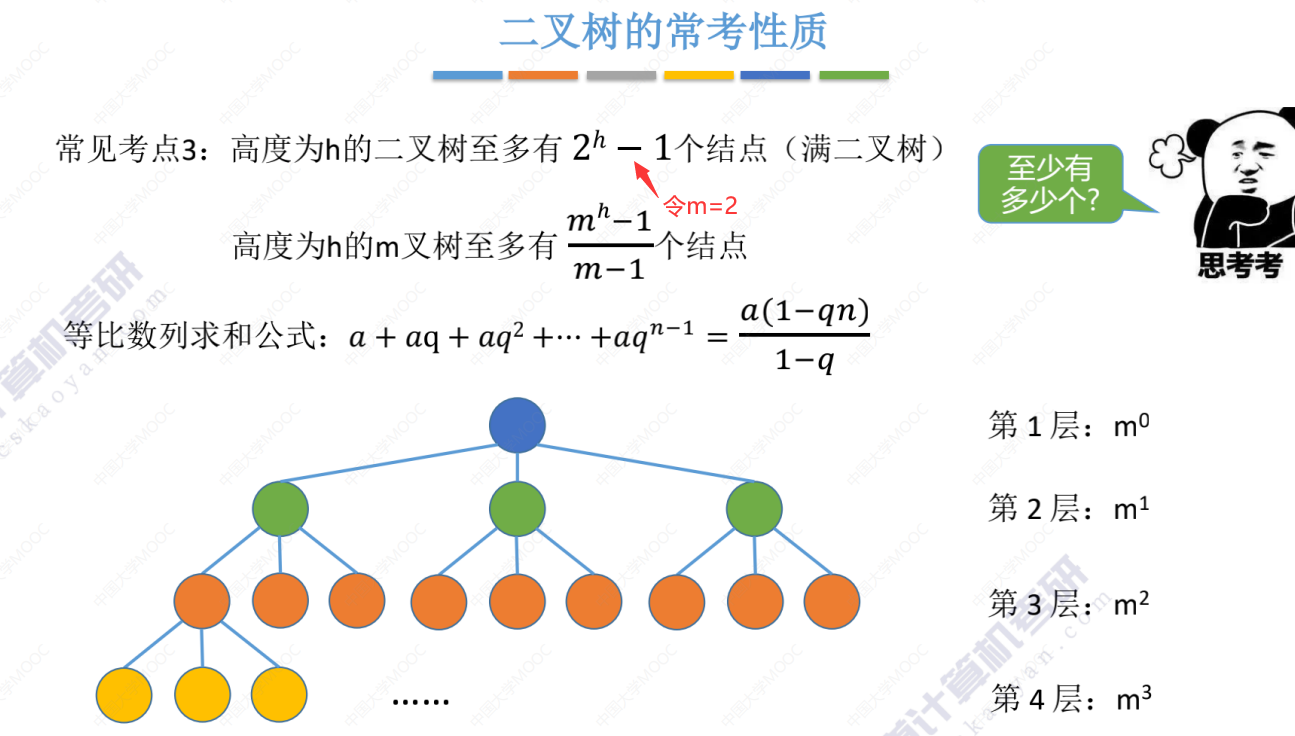
考点3
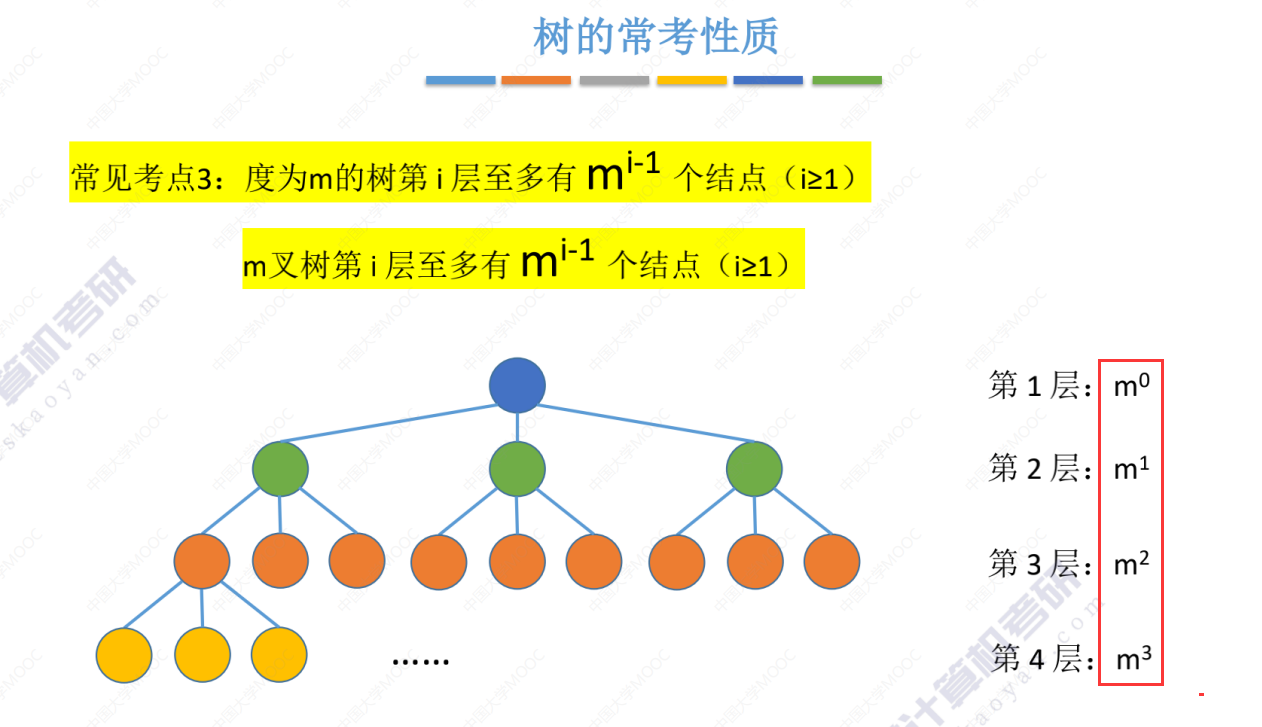
考点4
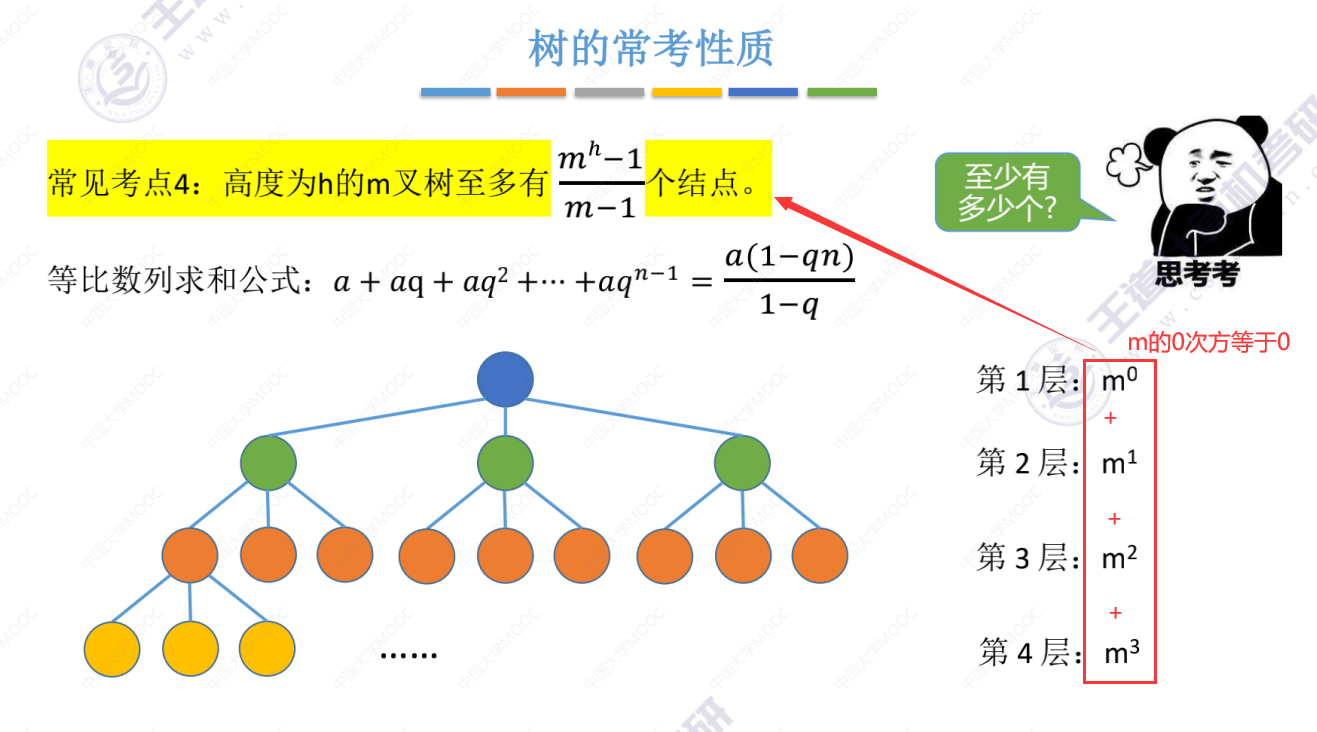
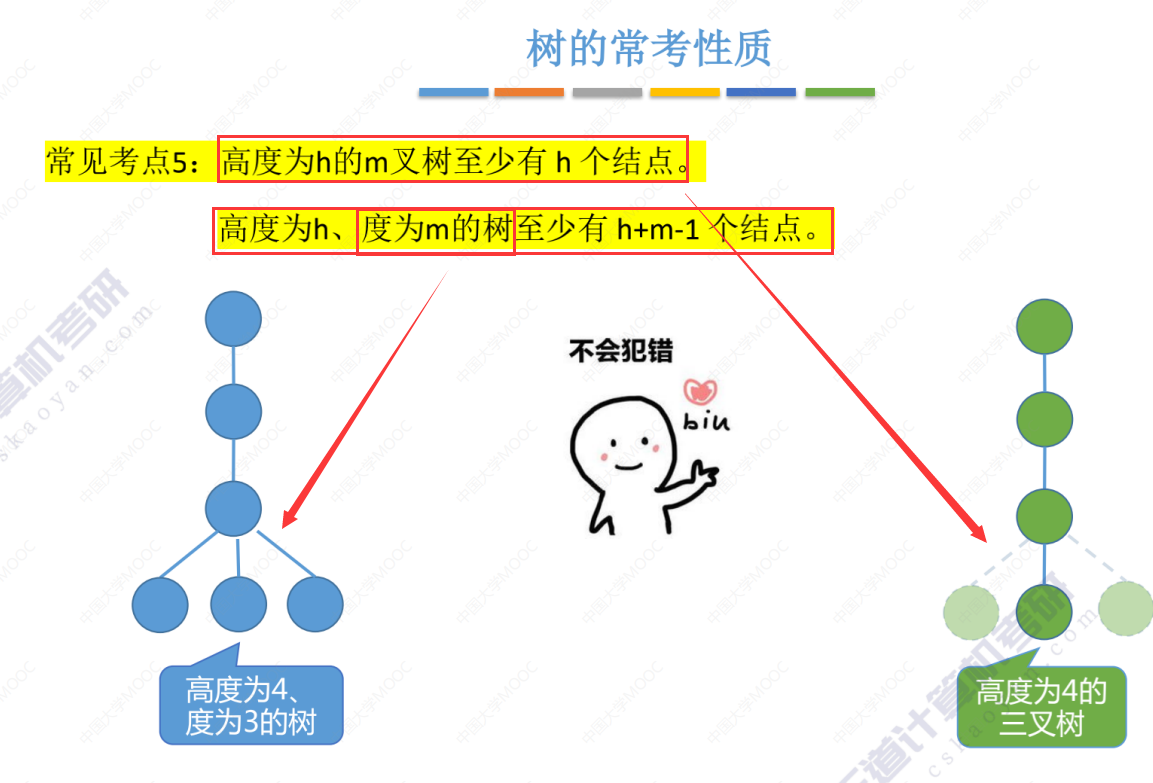
考点5
考点6

5.2-1 二叉树的定义和基本术语
二叉树的基本概念
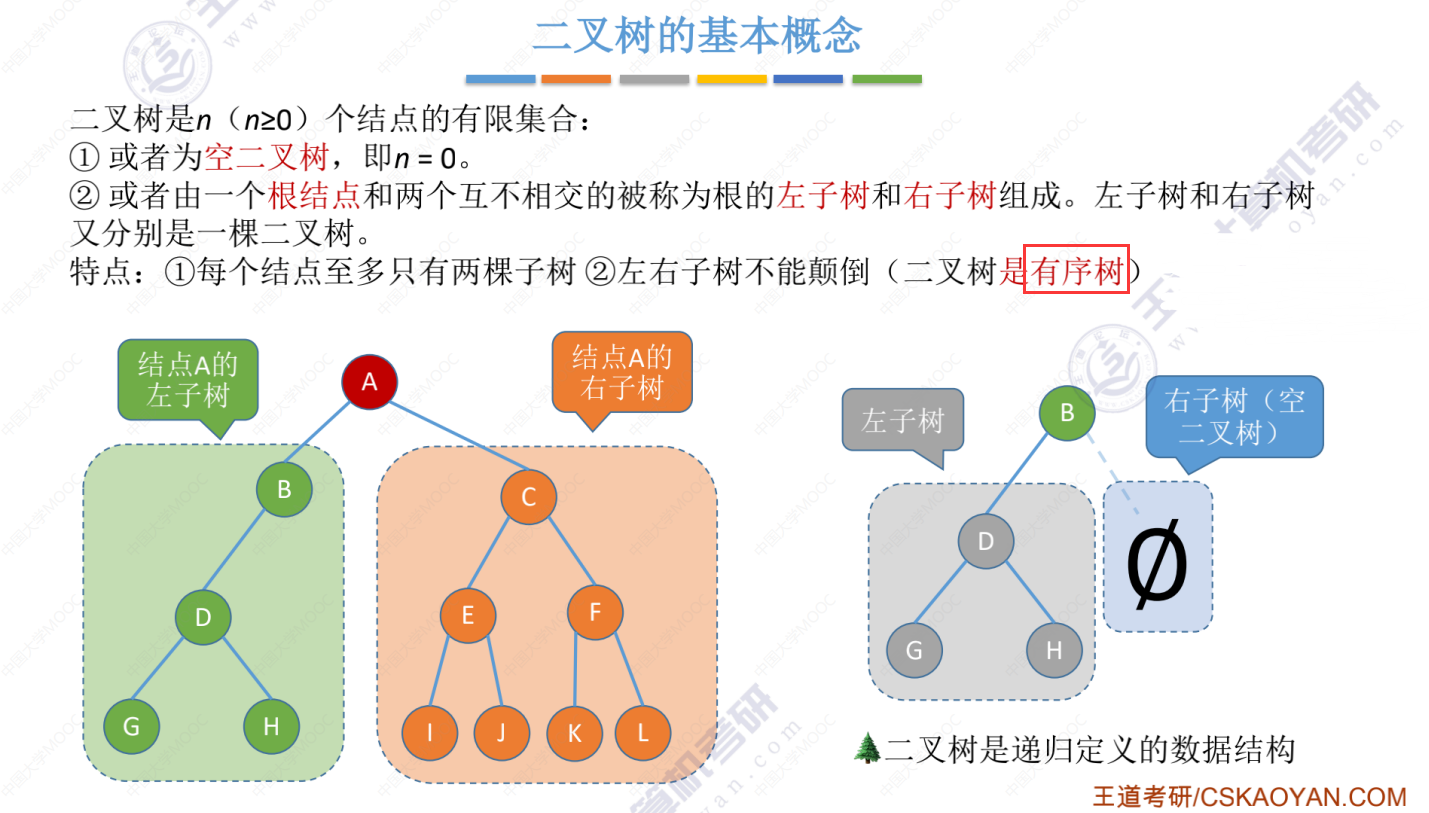
二叉树的五种状态
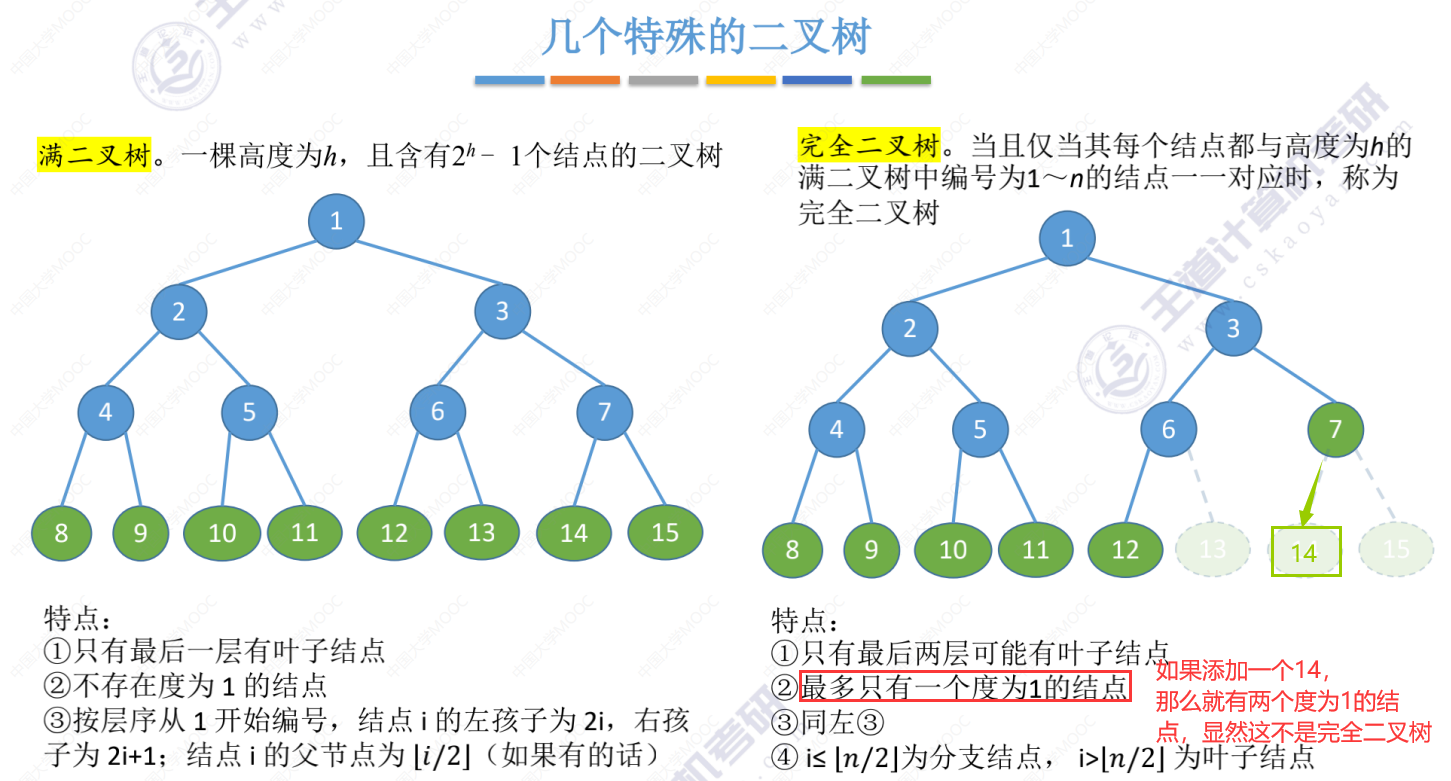
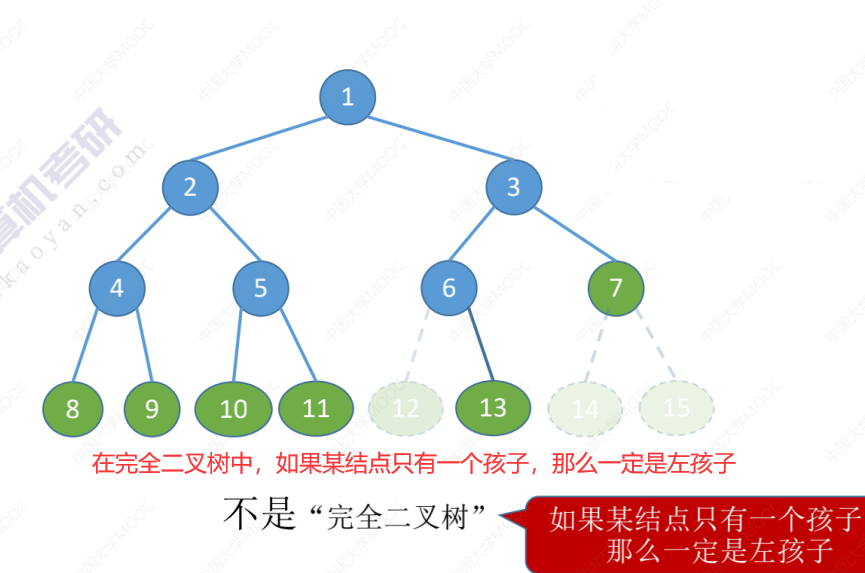
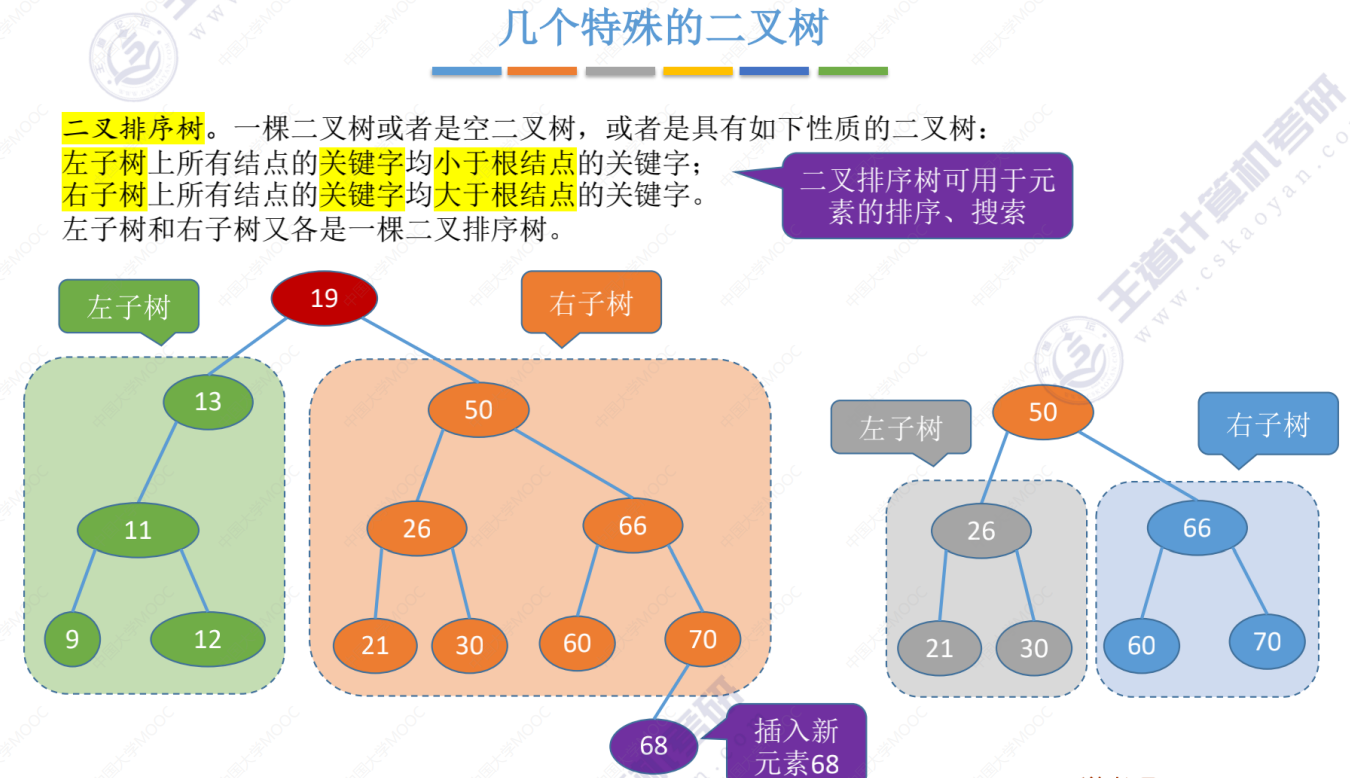
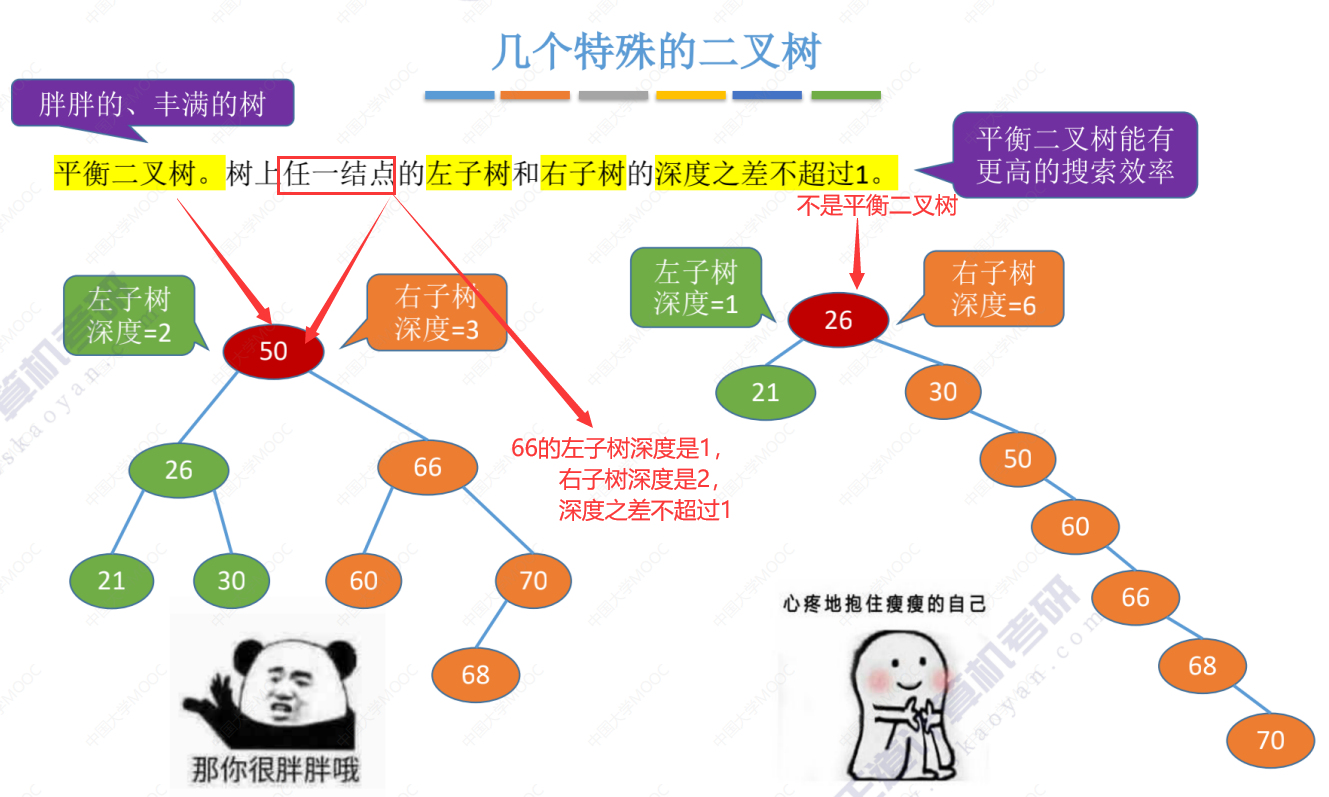
几种特殊的二叉树(满二叉树、完全二叉树、二叉排序树、平衡二叉树)
5.2-2 二叉树的性质
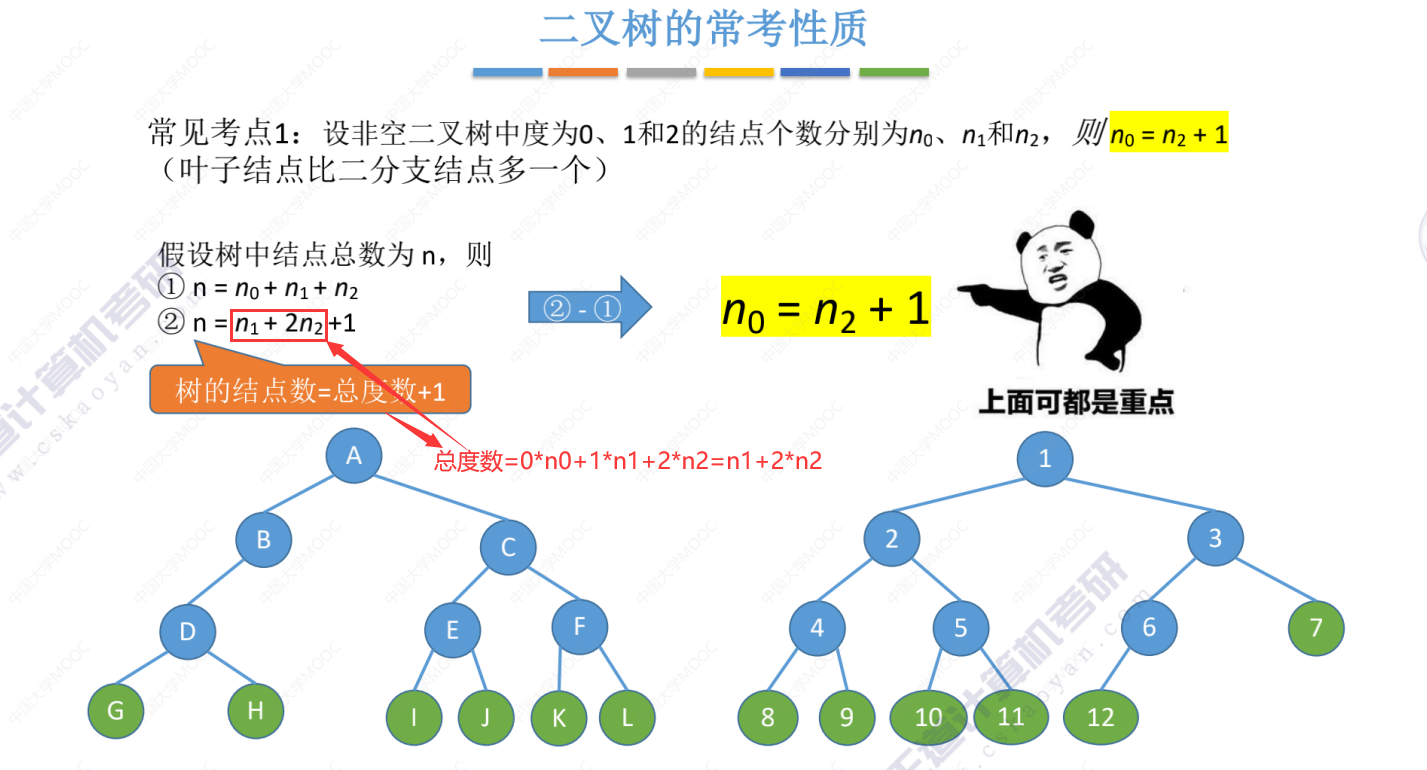
二叉树常考性质
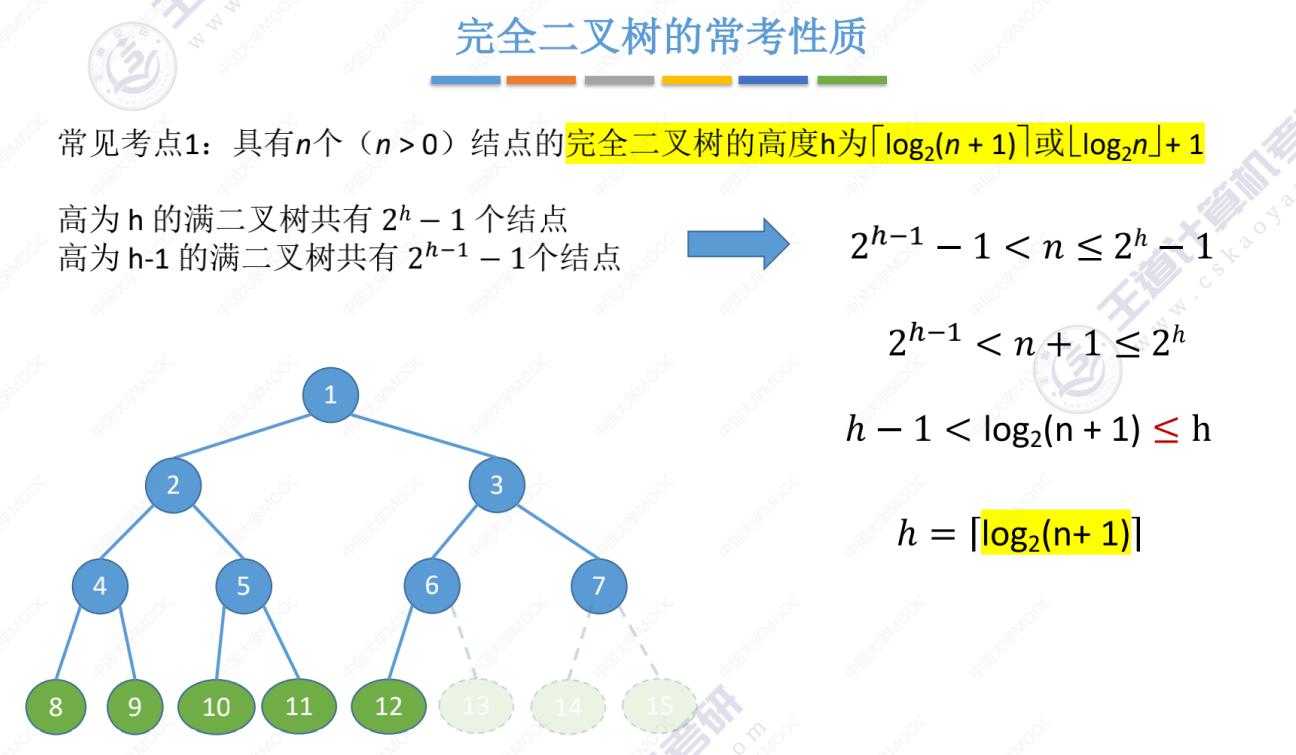
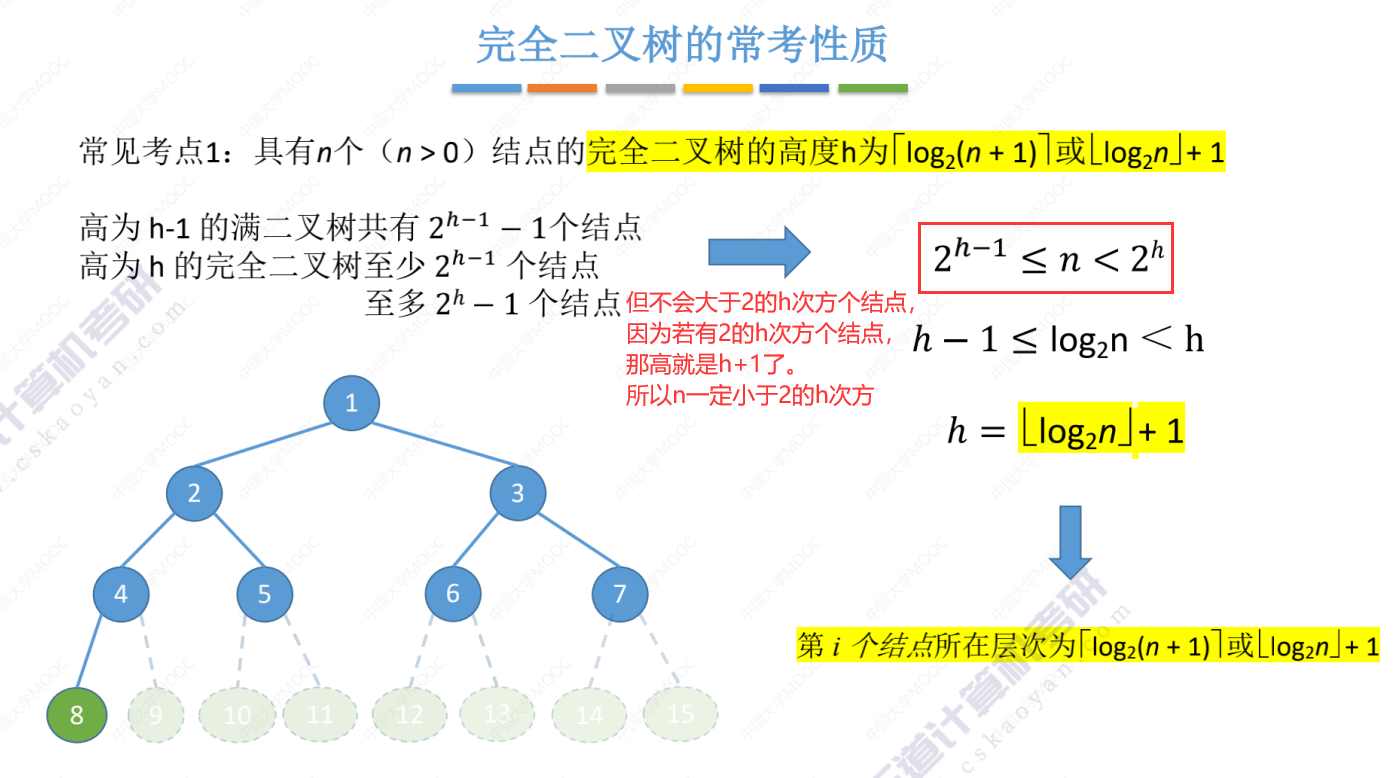
完全二叉树常考性质
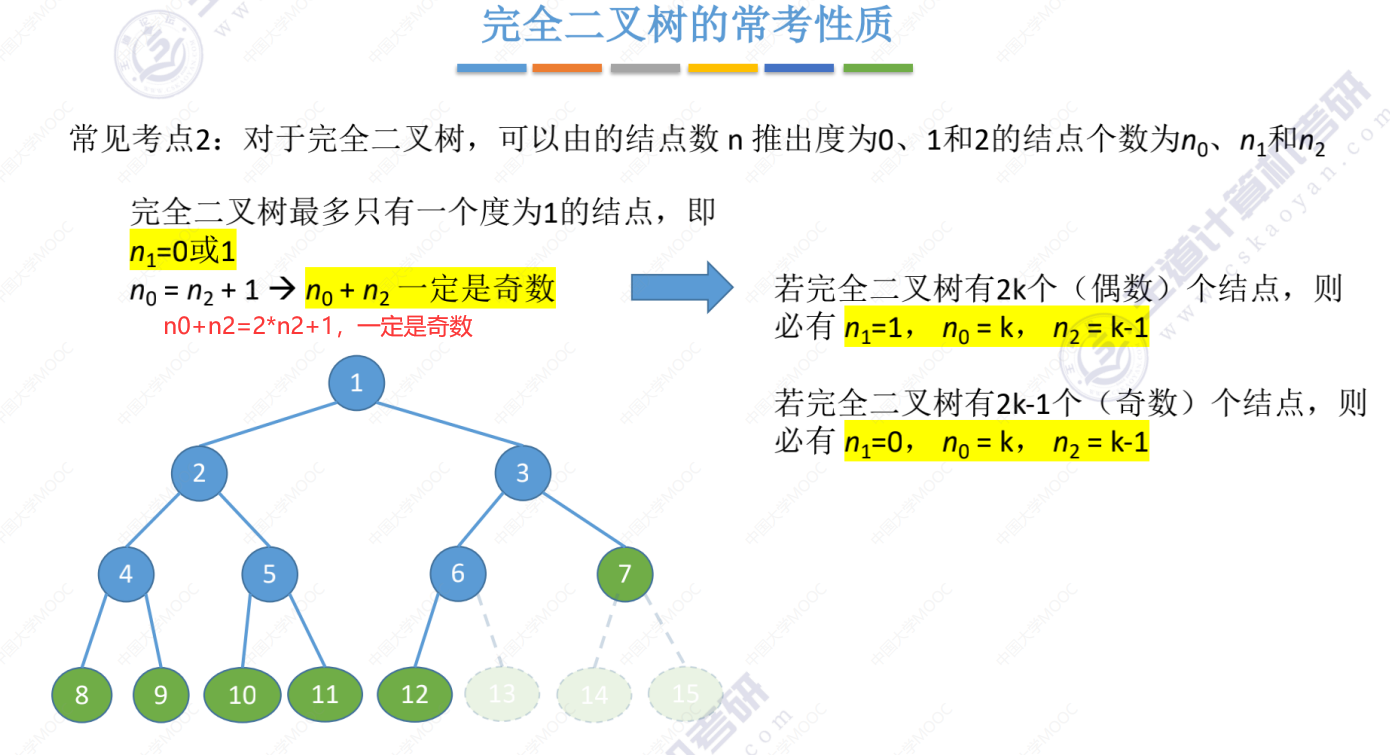
总结

5.2-3 二叉树的存储结构
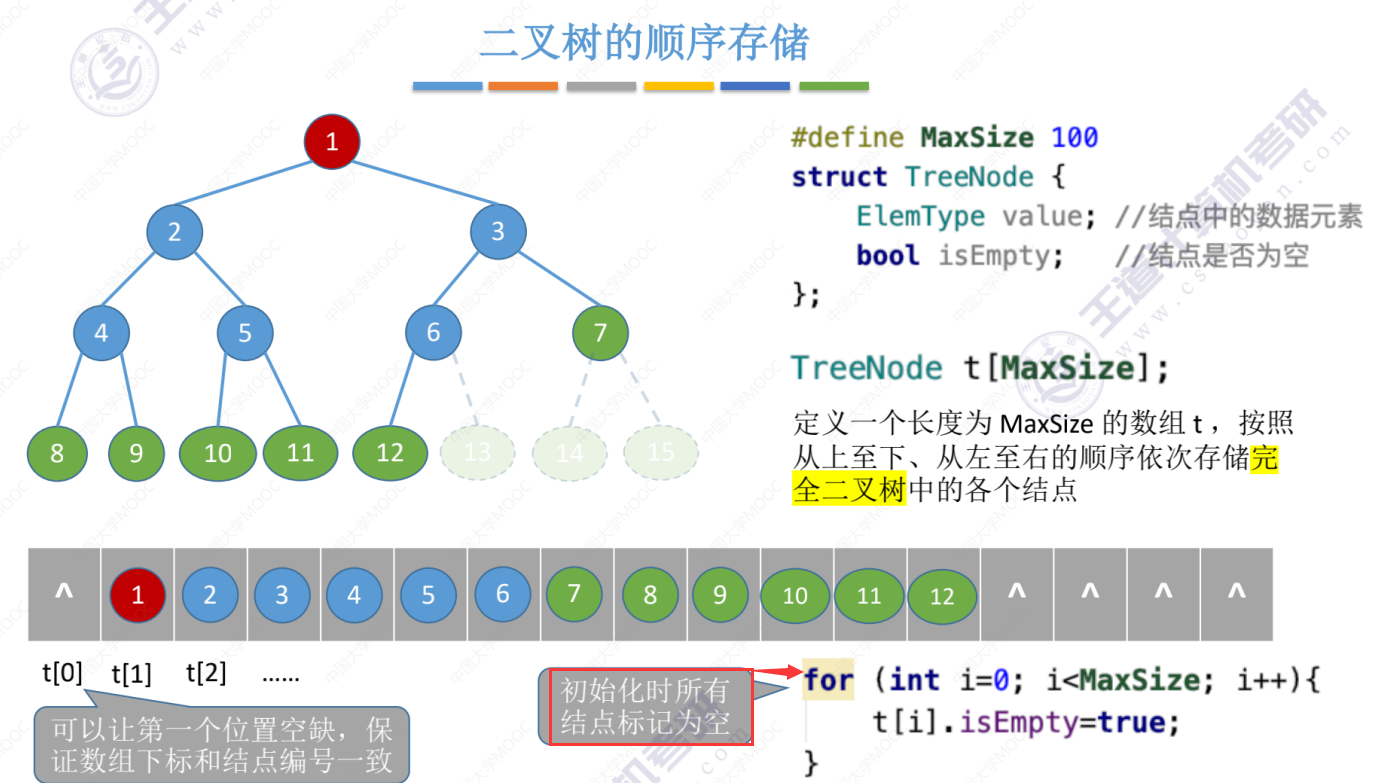
完全二叉树的顺序存储
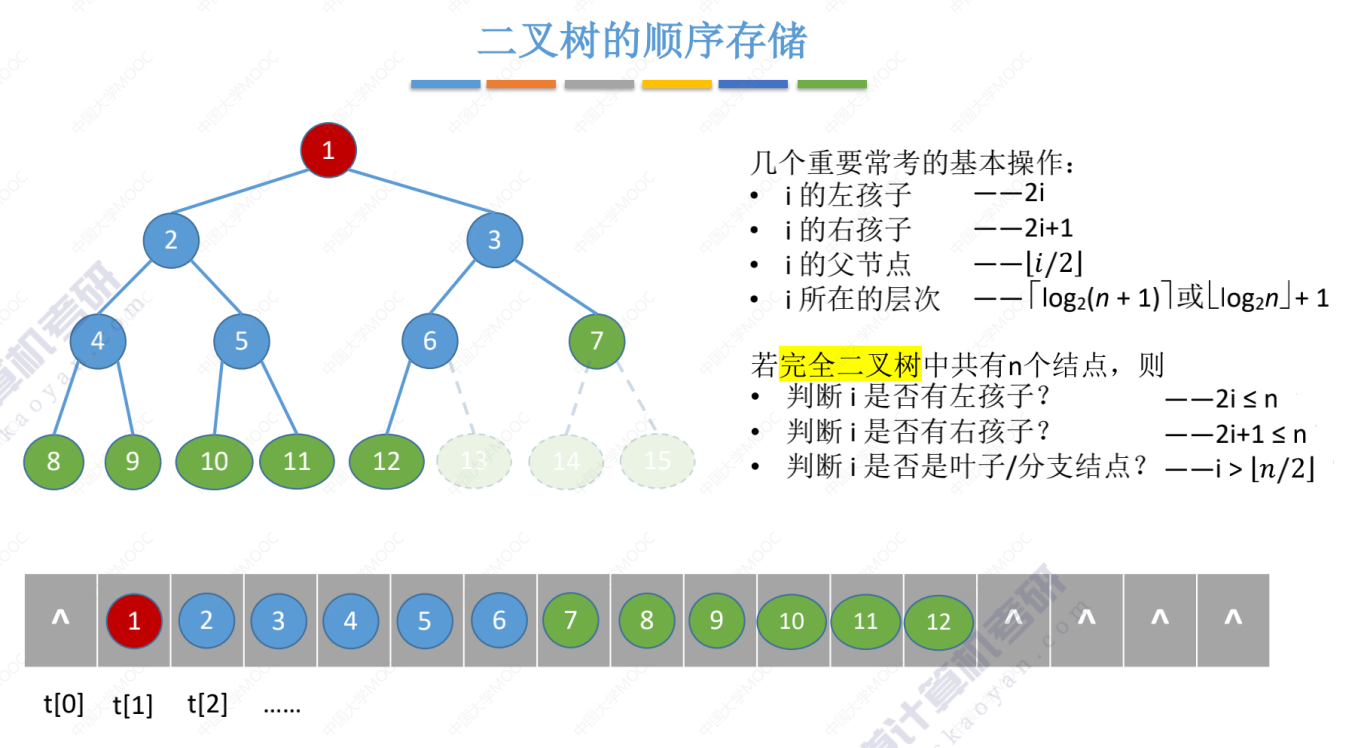
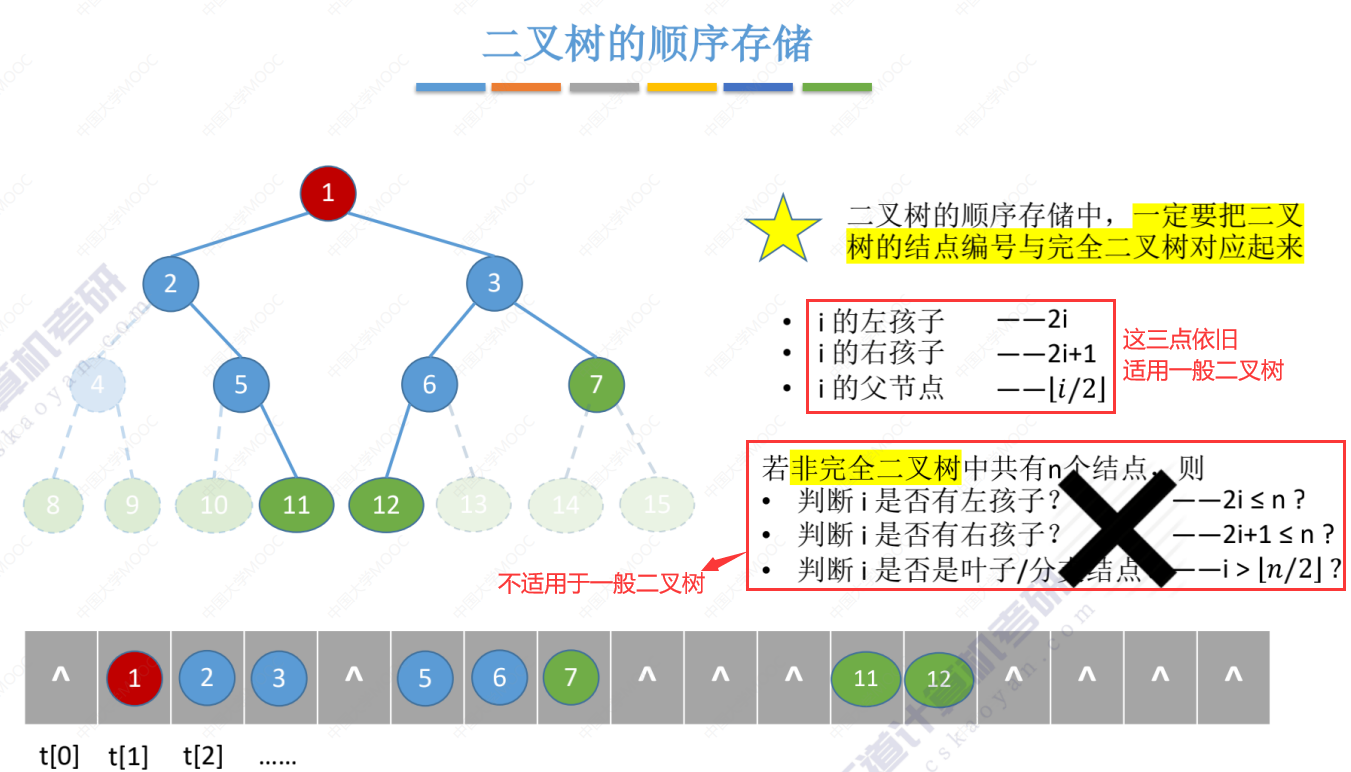
一般二叉树的顺序存储
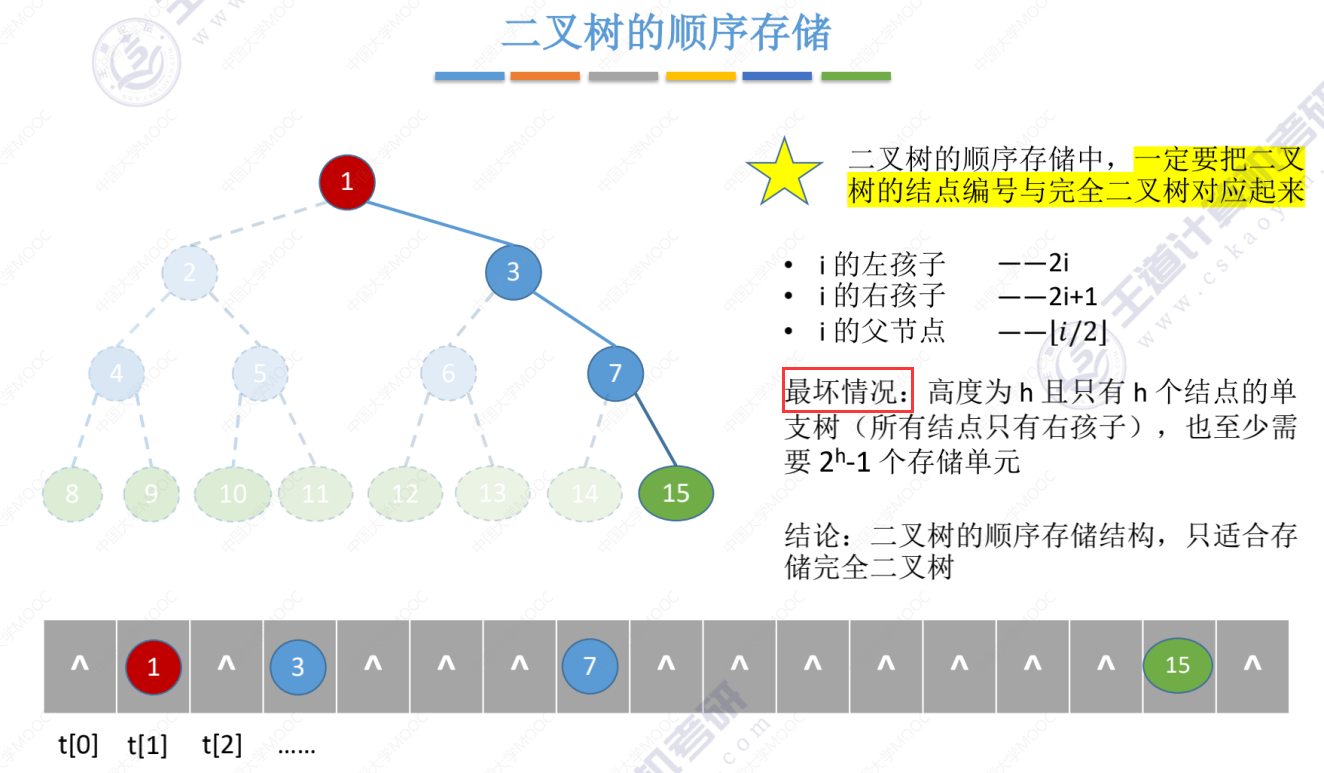
二叉树的链式存储
线索二叉树之后讲解
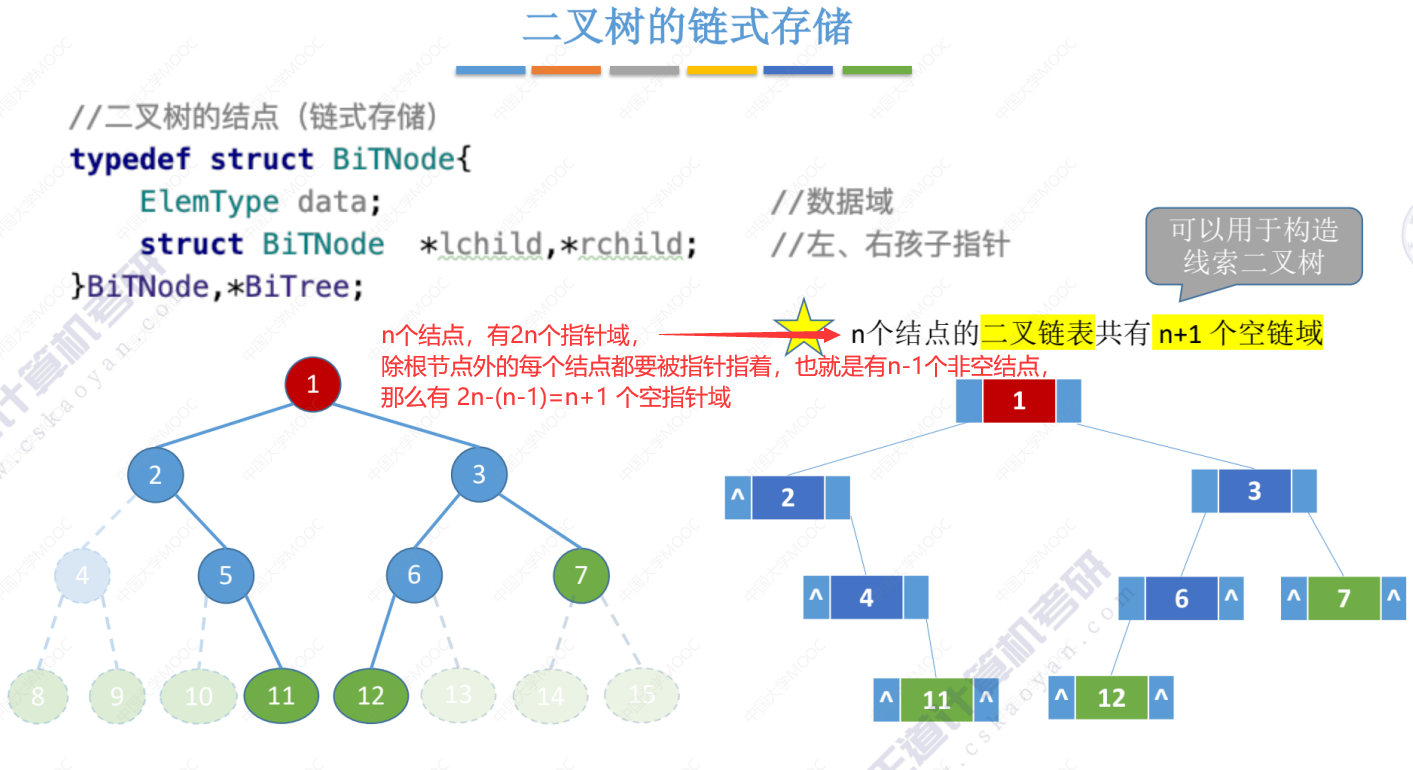
root->data直接赋值了{1},是因为 data是结构体 ElemType类型的,给ElemType类型的赋值{1},相当于给结构体类型的ElemType整体赋值。
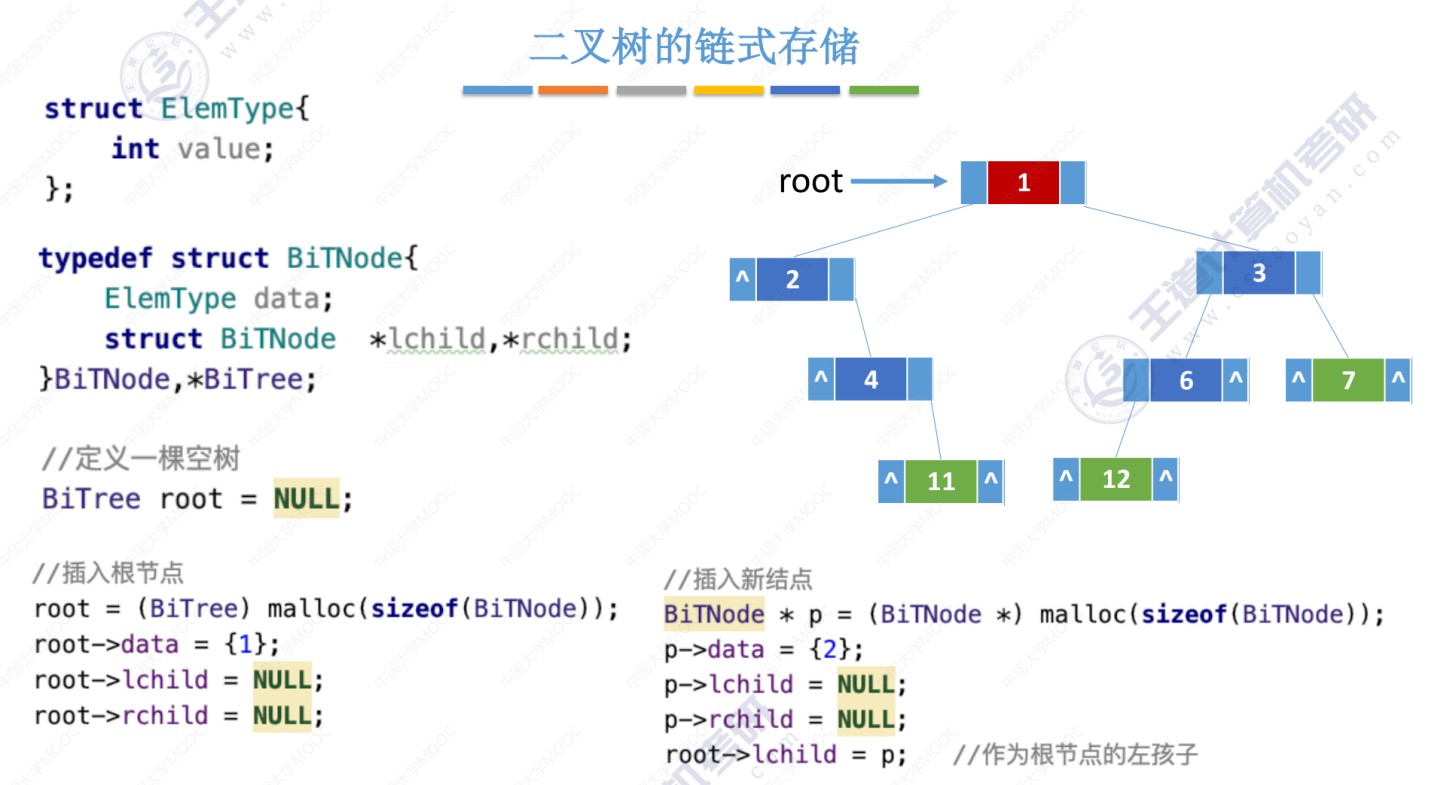
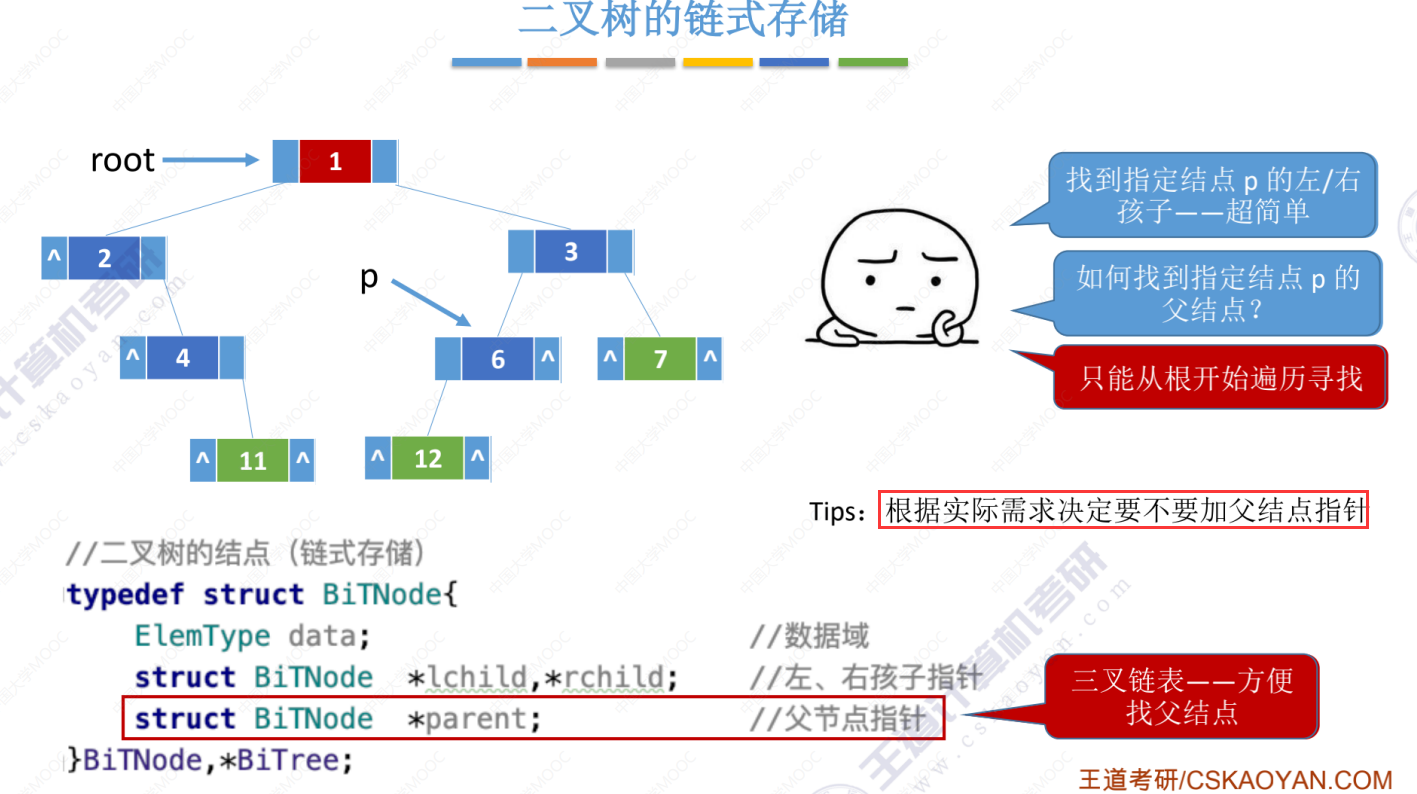
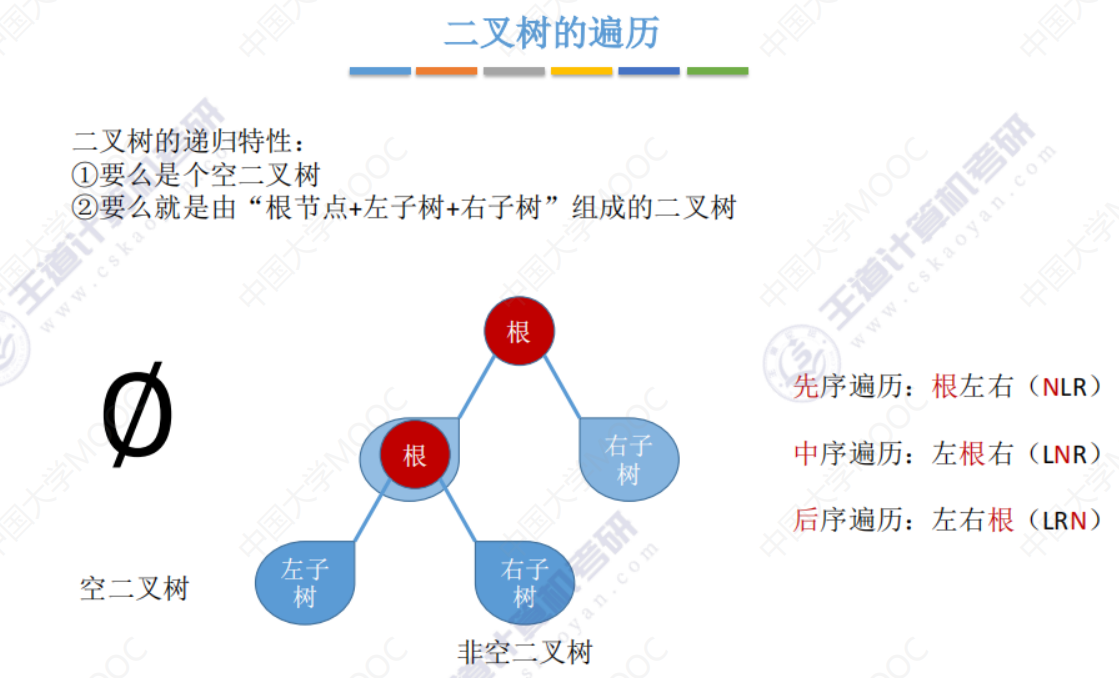
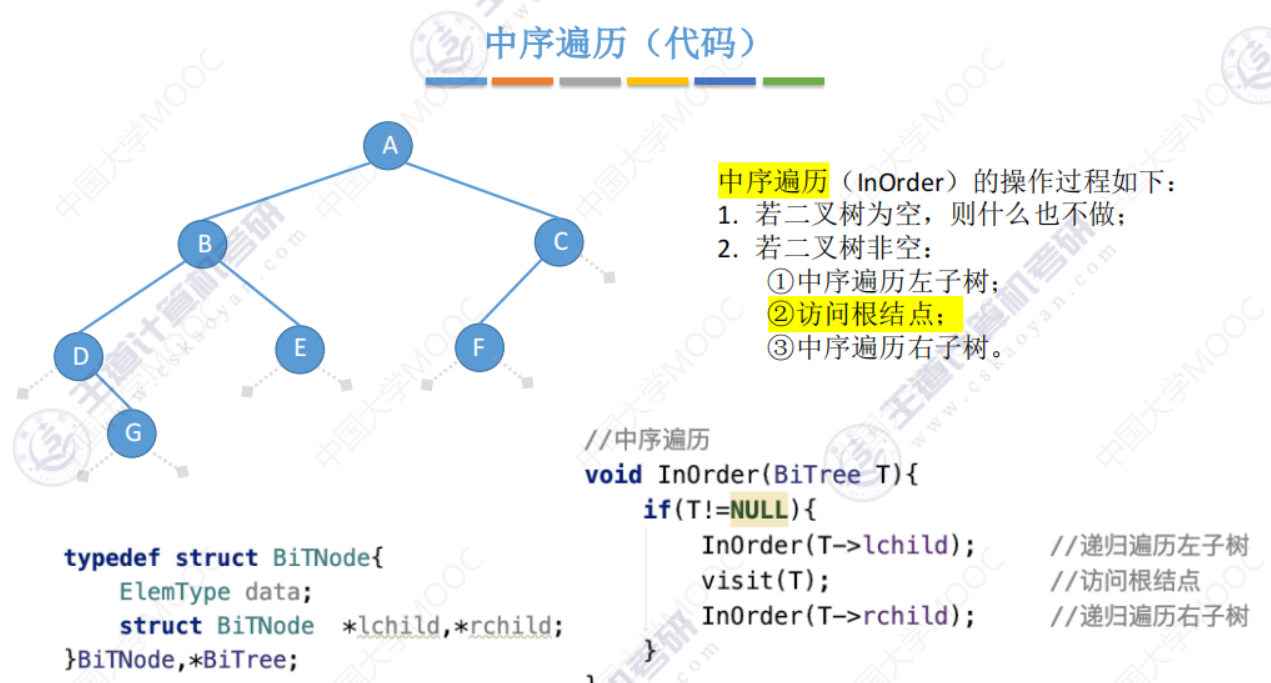
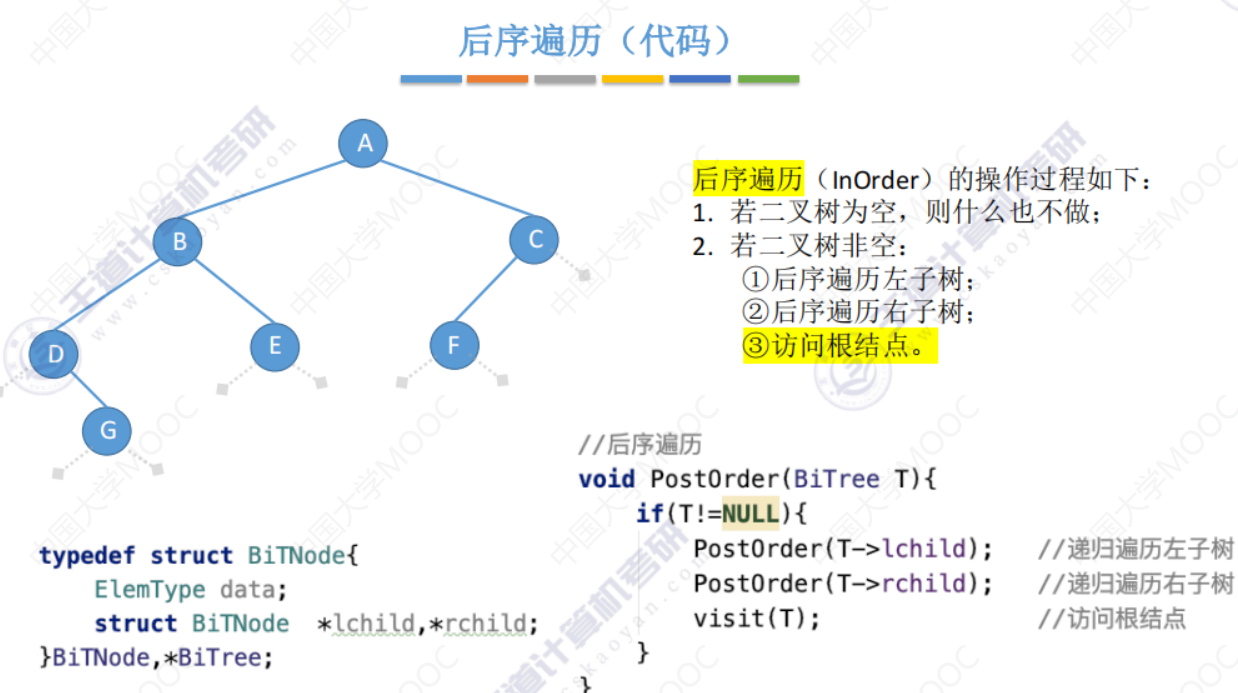
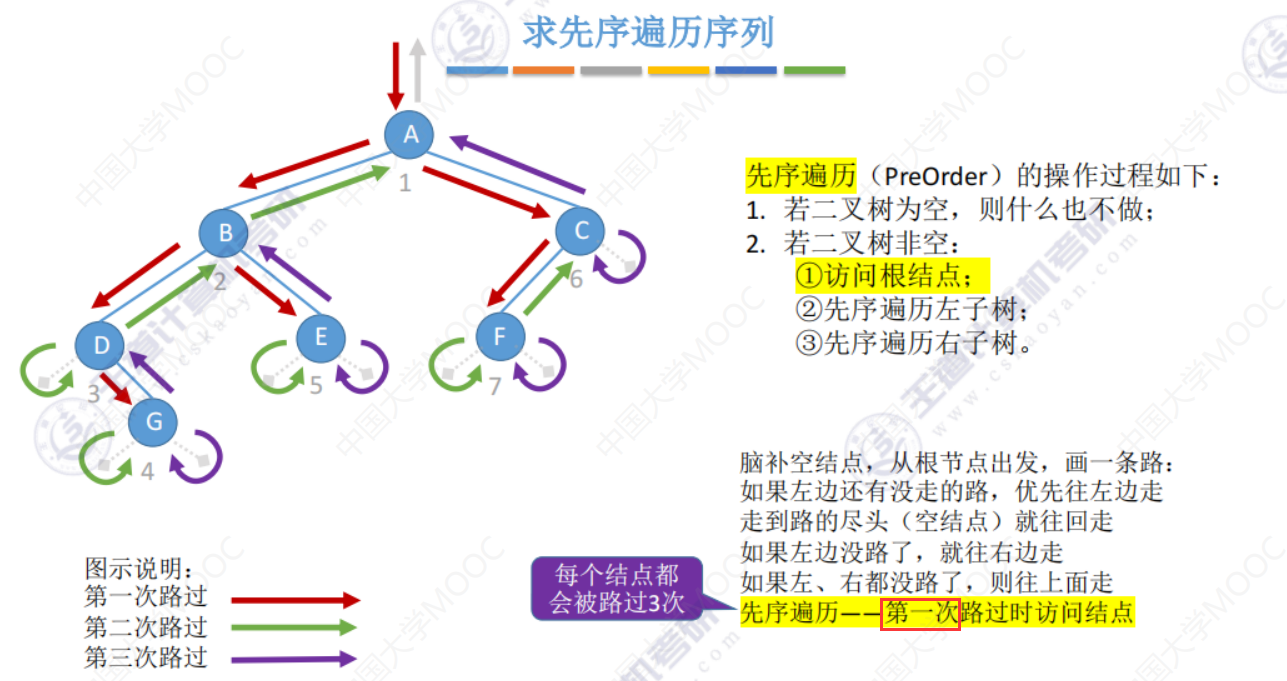
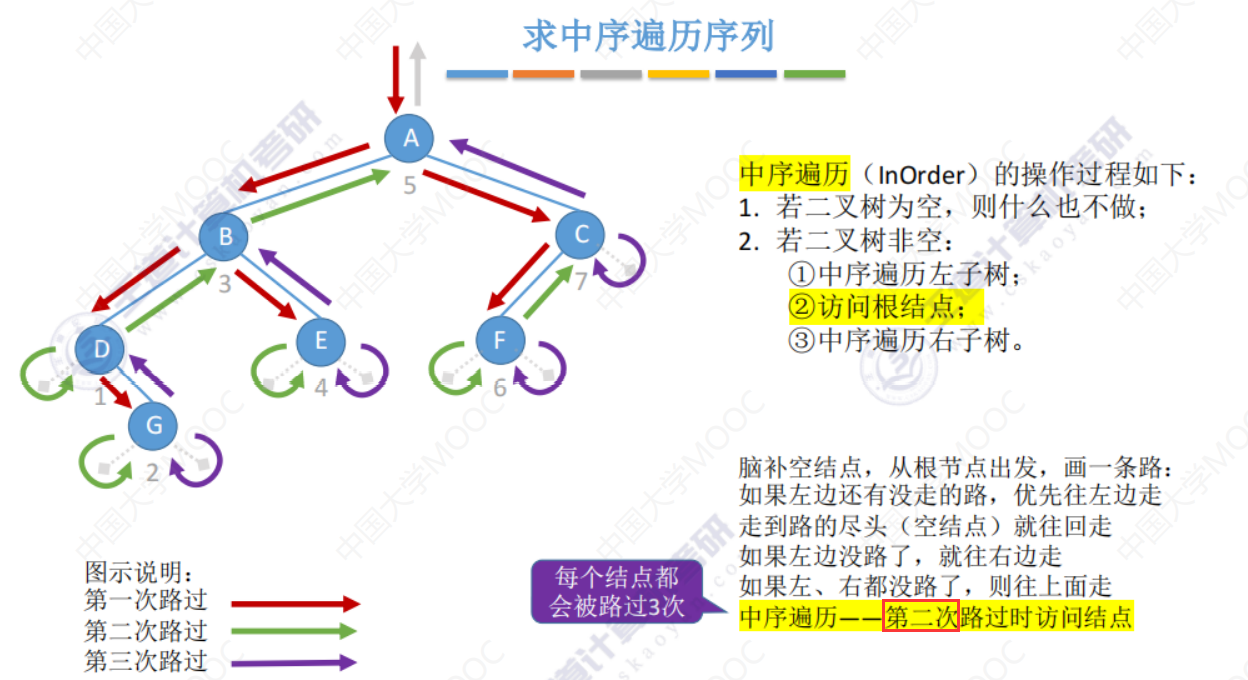
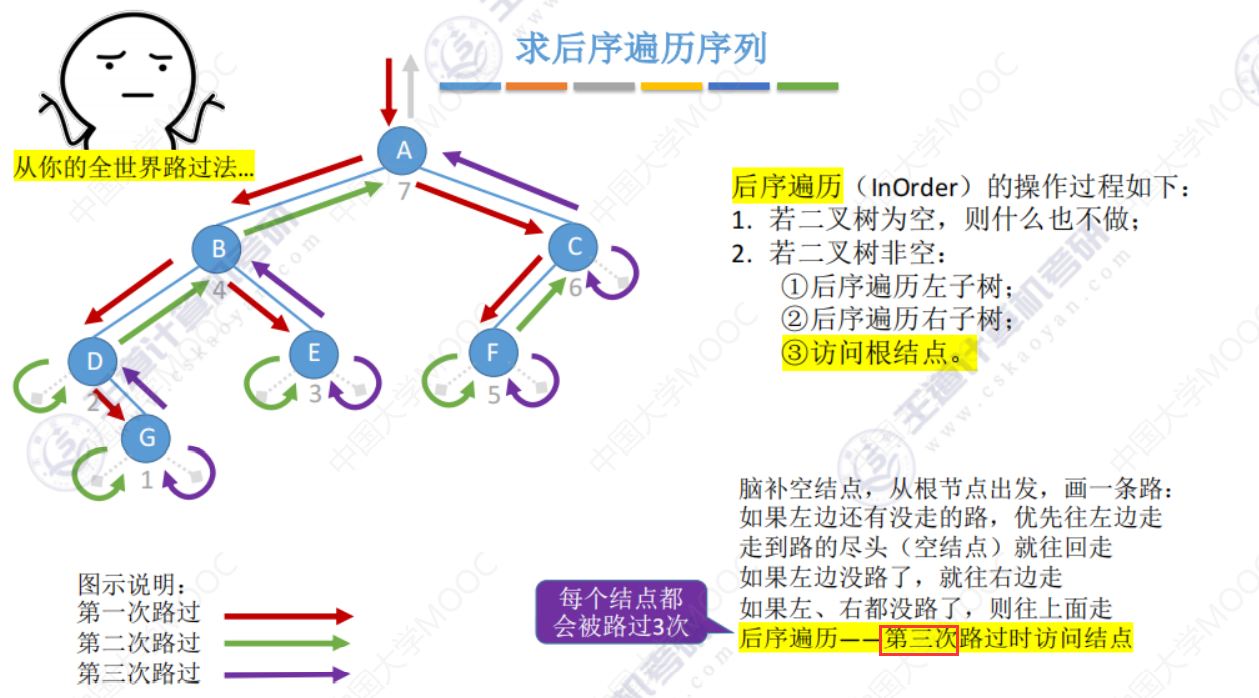
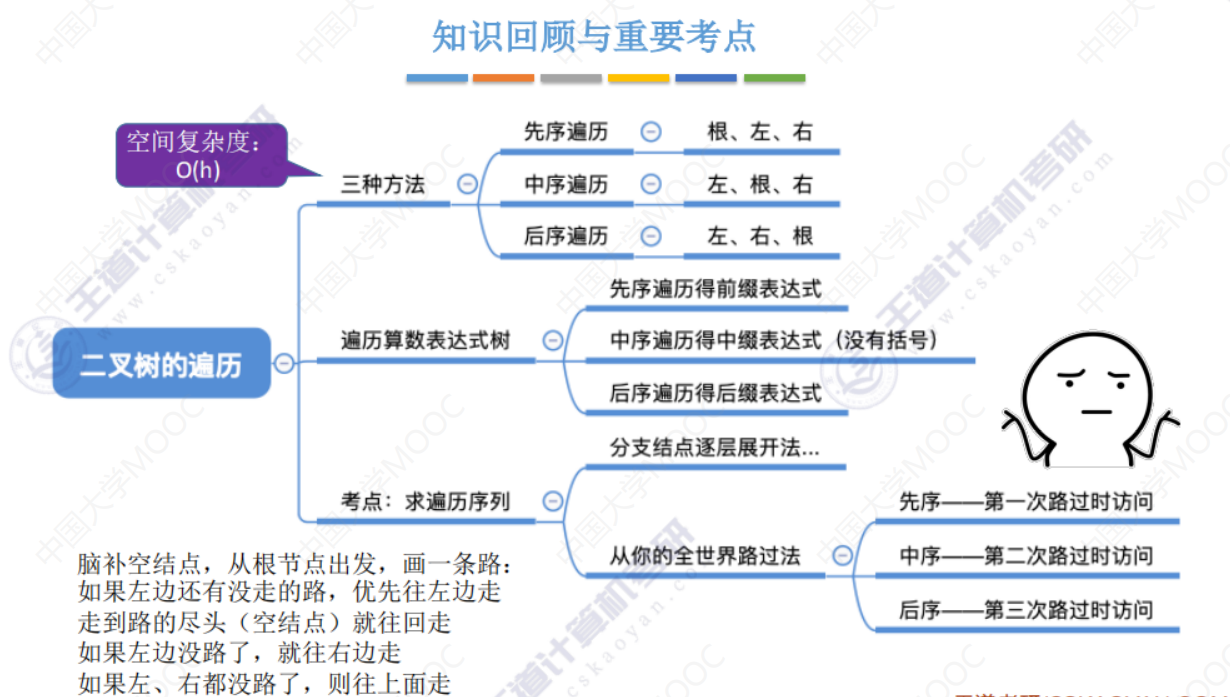
5.3-1 二叉树的先中后序遍历
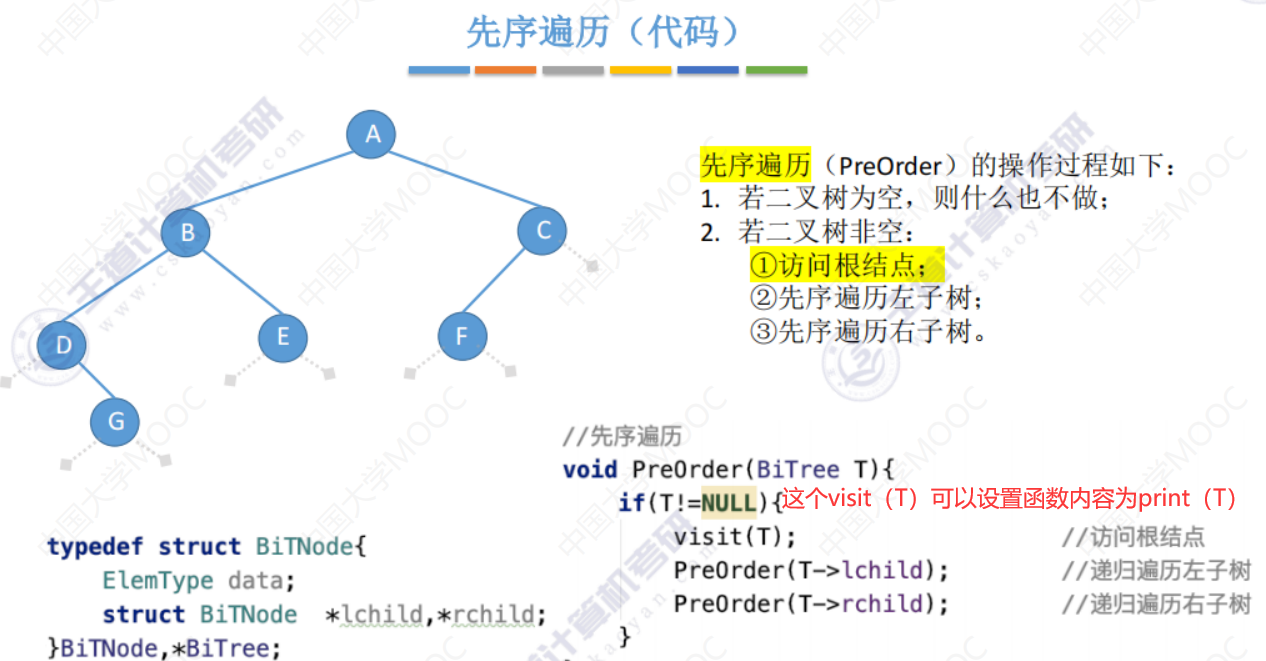
先中后序遍历

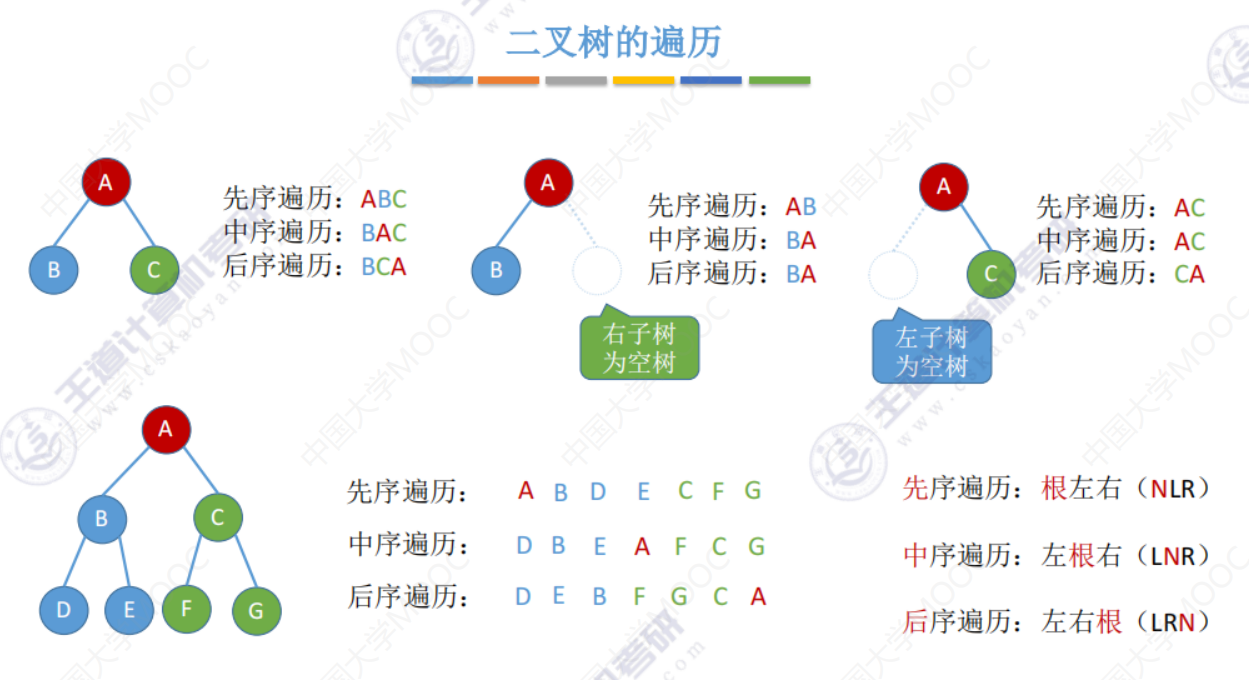
遍历算数表达式树
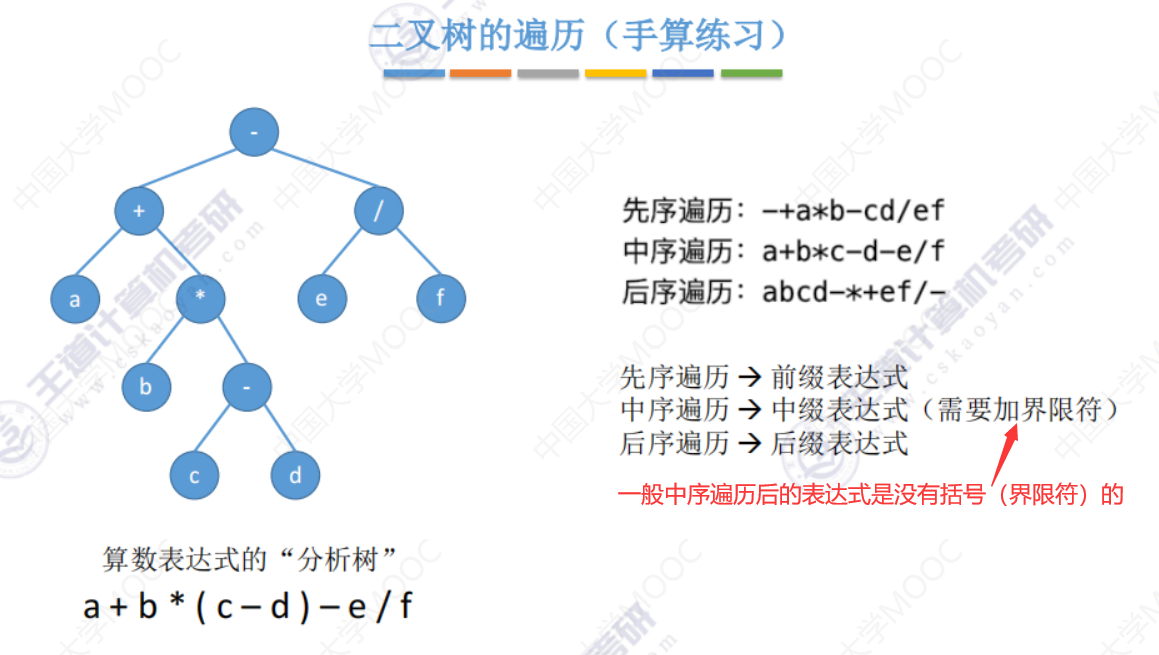
求遍历序列
递归遍历

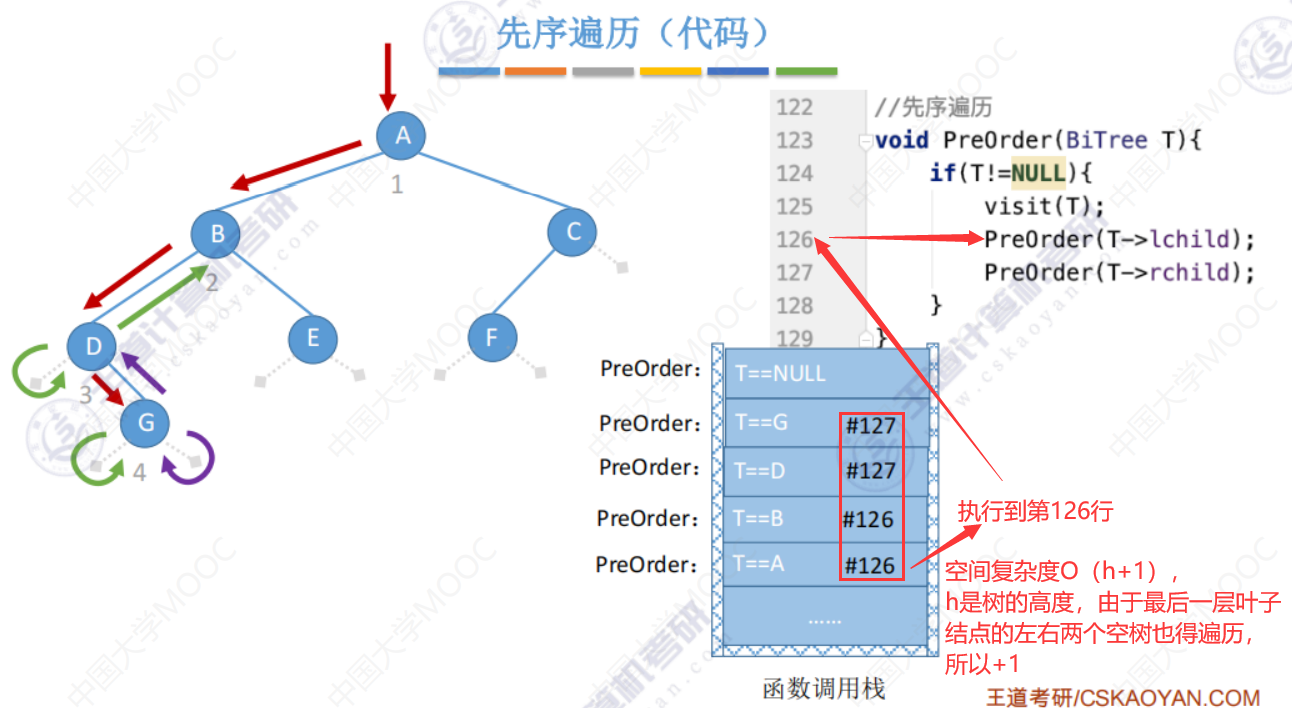
空间复杂度分析
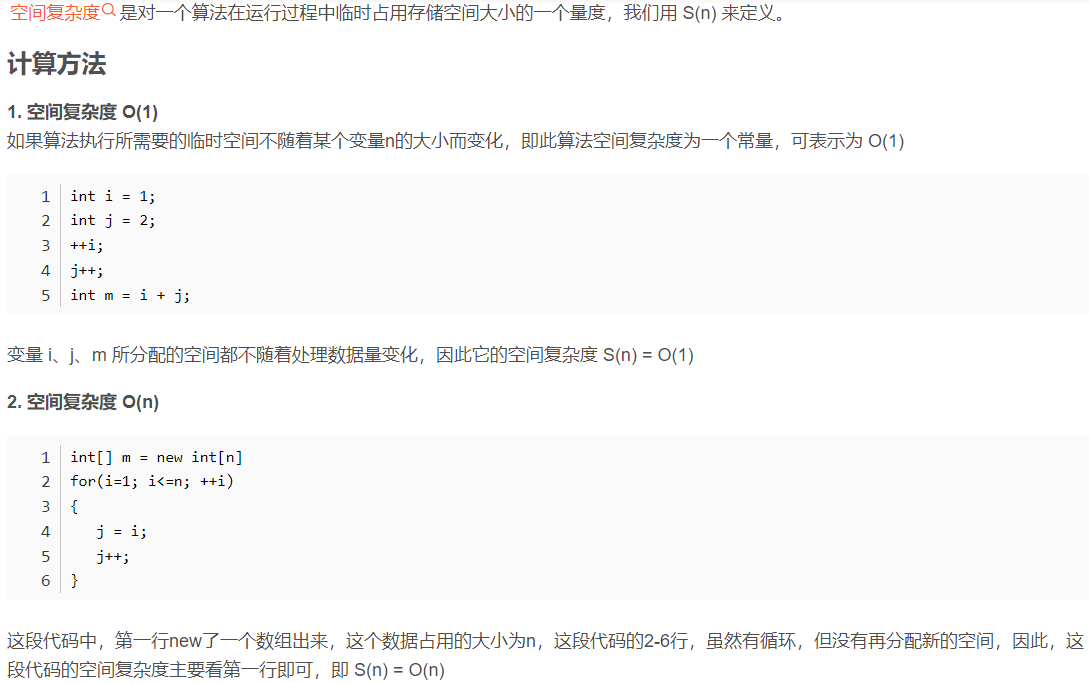
以下占用了函数调用栈的空间,随着深度h的变化,函数调用栈被占用的空间越多。
非递归遍历
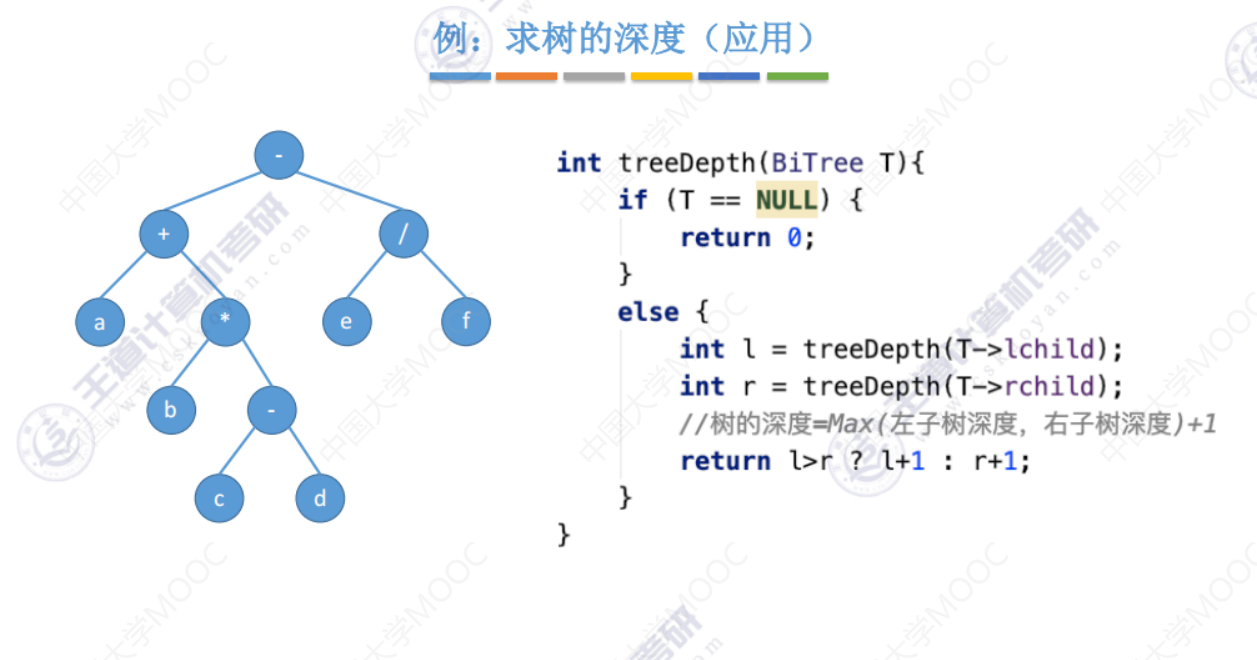
求树的深度
总结
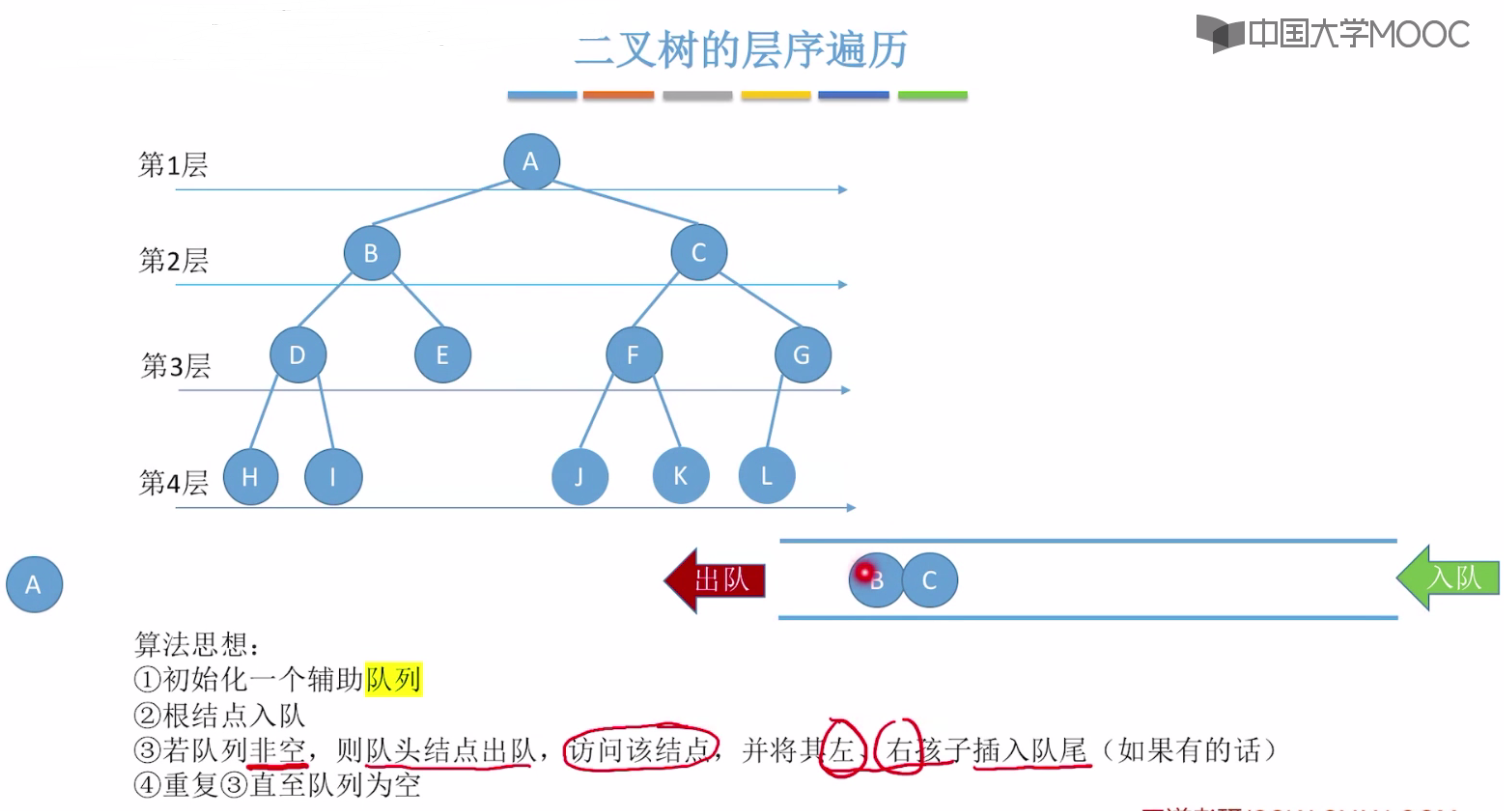
5.3-2 二叉树的层次遍历

5.3-3 由遍历序列构造二叉树
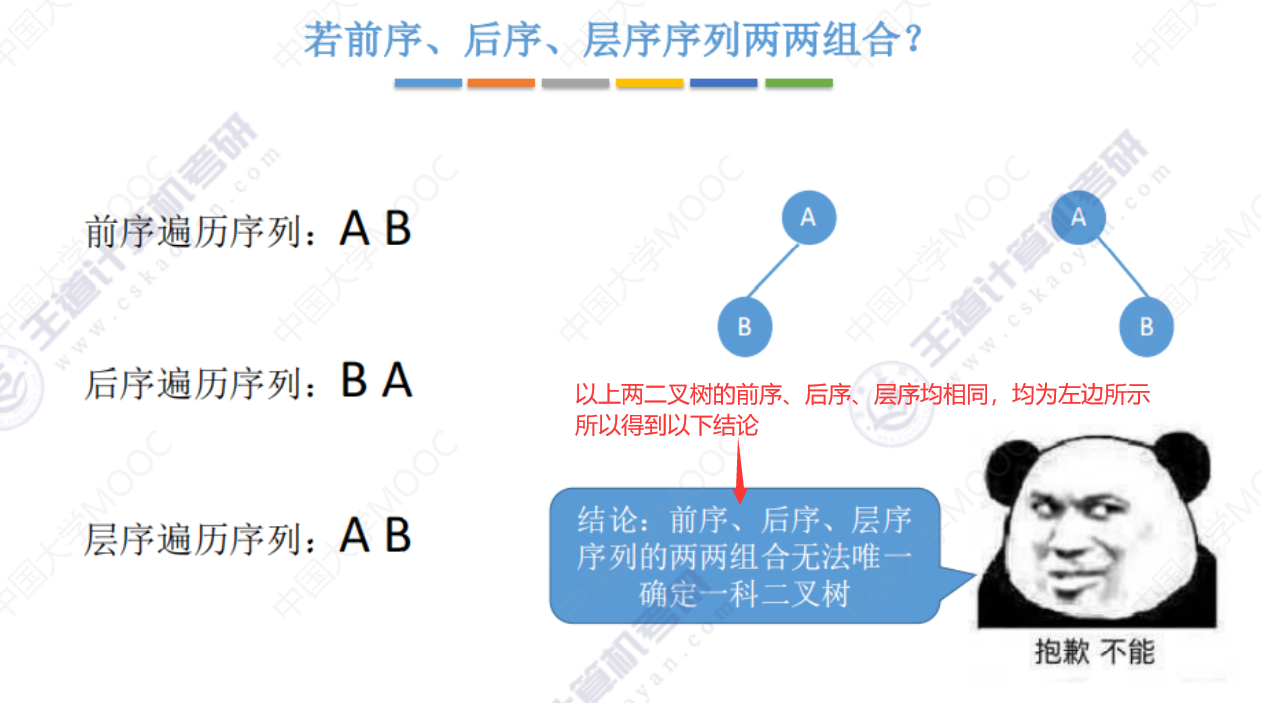
给出单一中序、前序、后序、层序遍历序列 并不能直接还原唯一的二叉树形态。
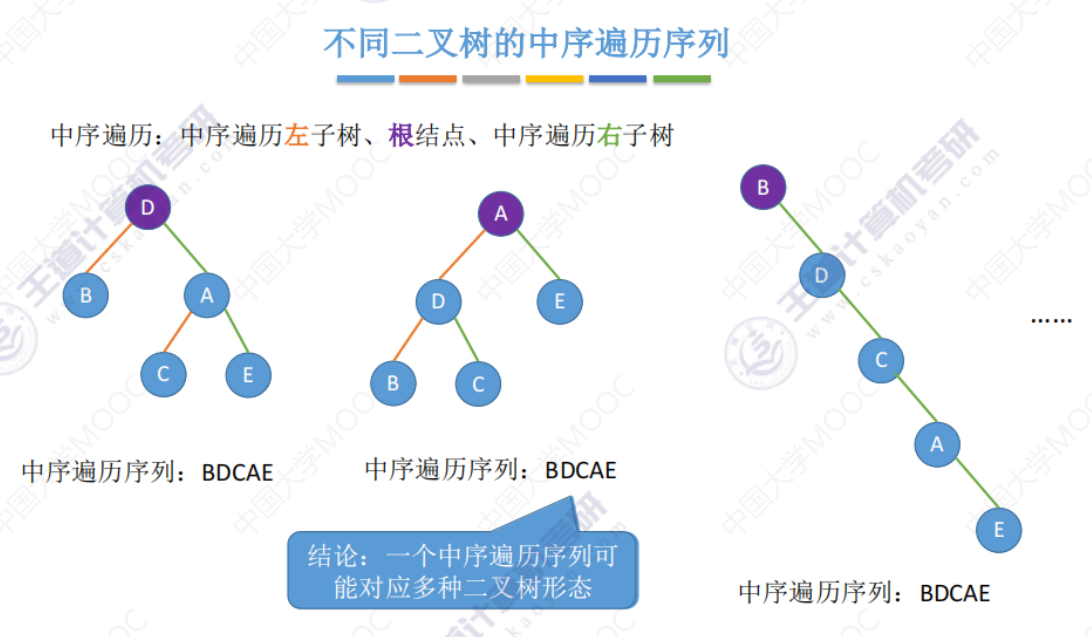
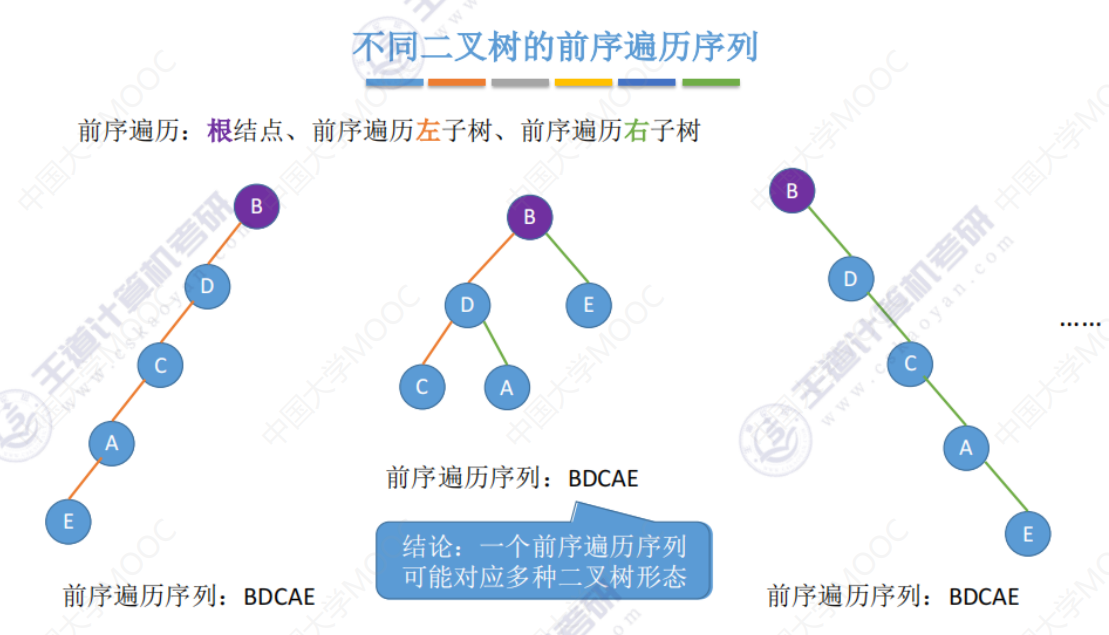
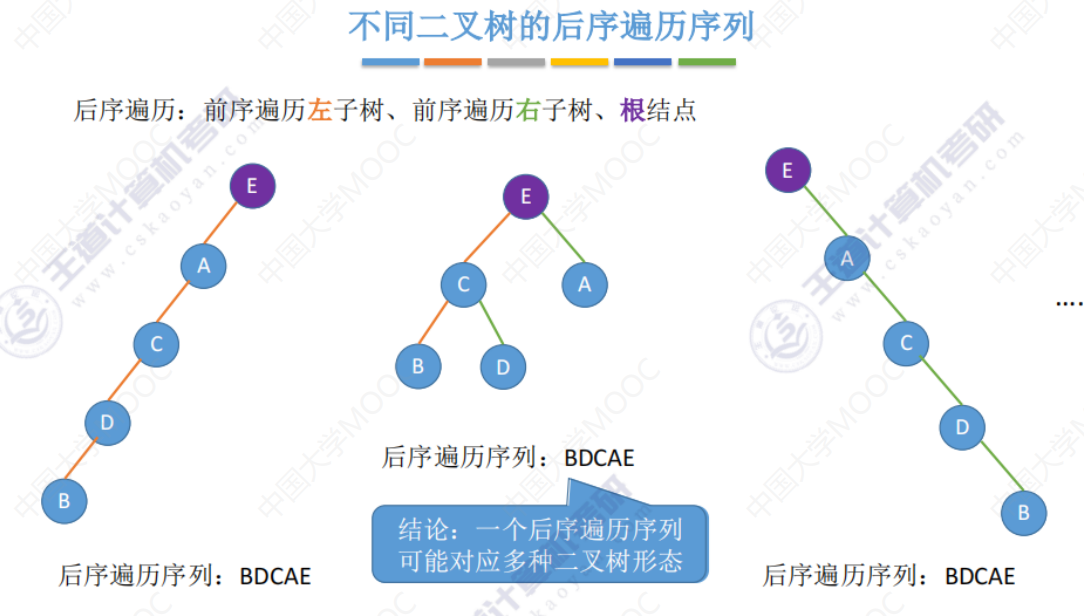
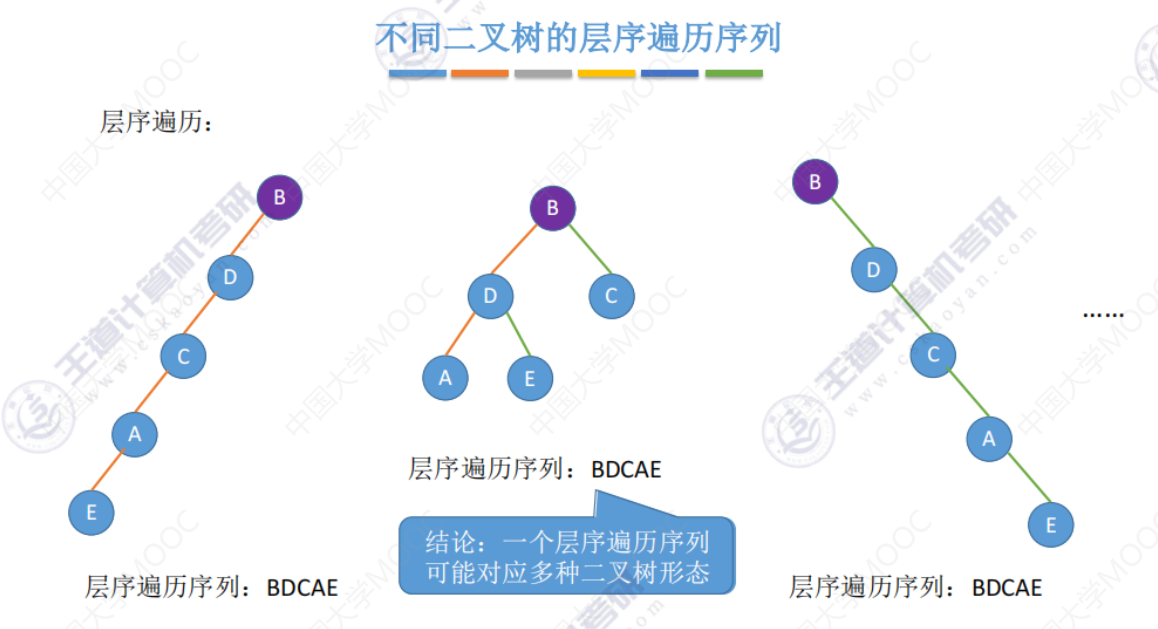
由上面中序、前序、后序、层序可知给出 遍历序列 并不能直接还原唯一的二叉树形态。

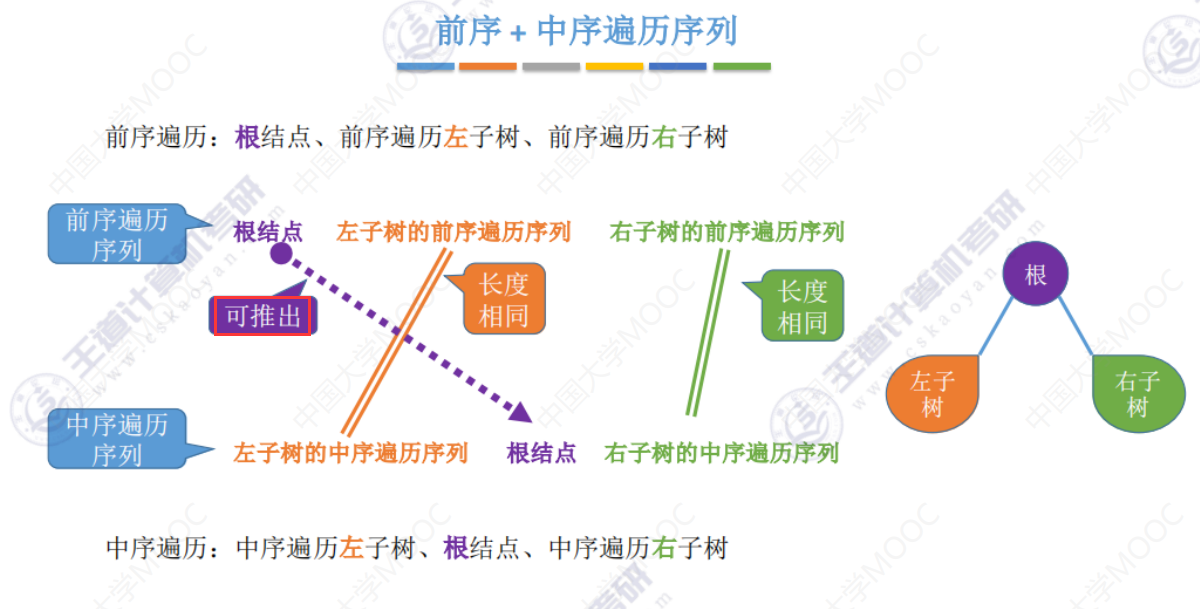
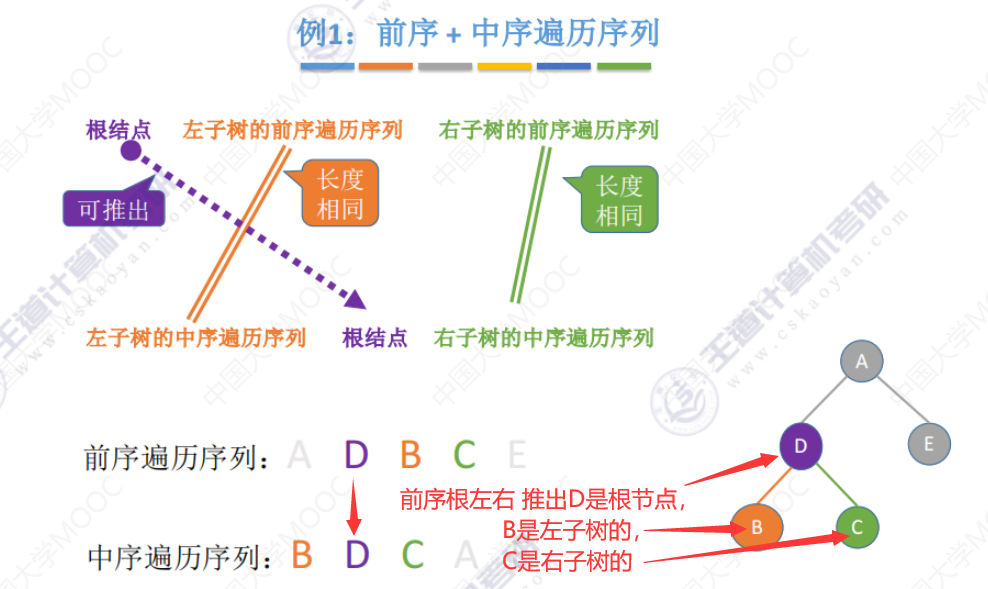
前序+中序遍历序列
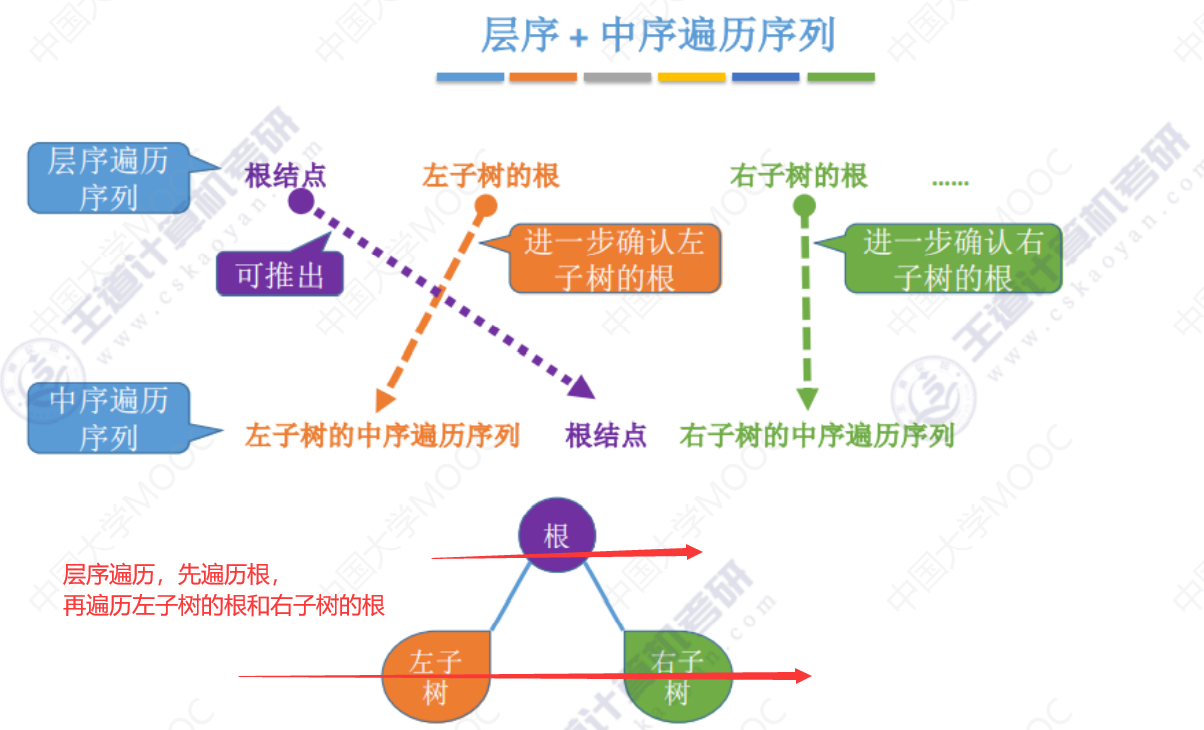
对前+中 、后+中、层+中都适用:找到树的根节点,并根据中序序列划分左右子树,再找到左右子树根节点。
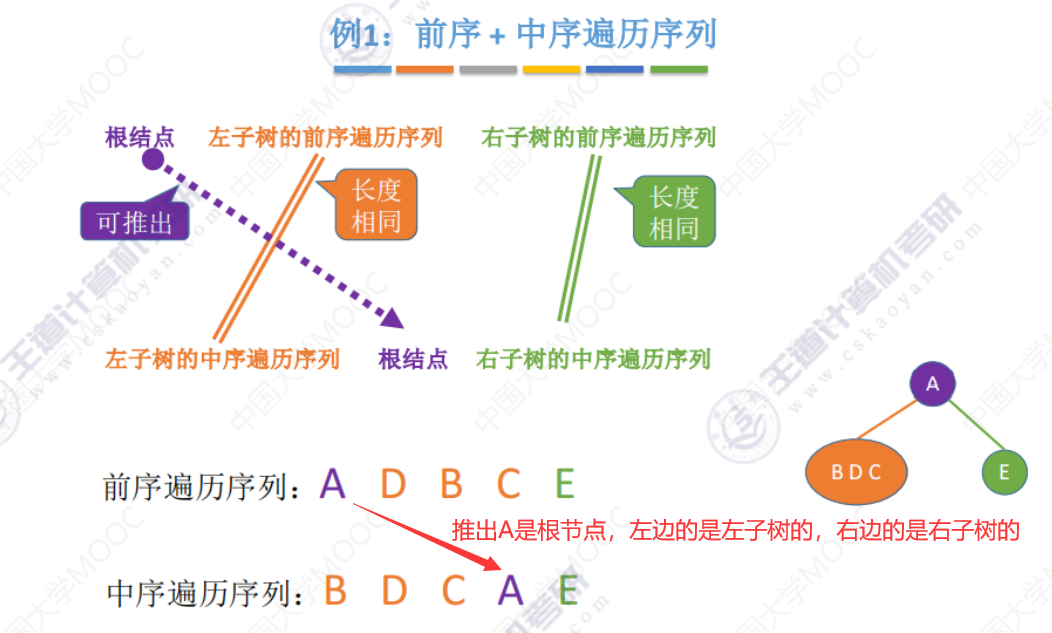
例1(过程解析)
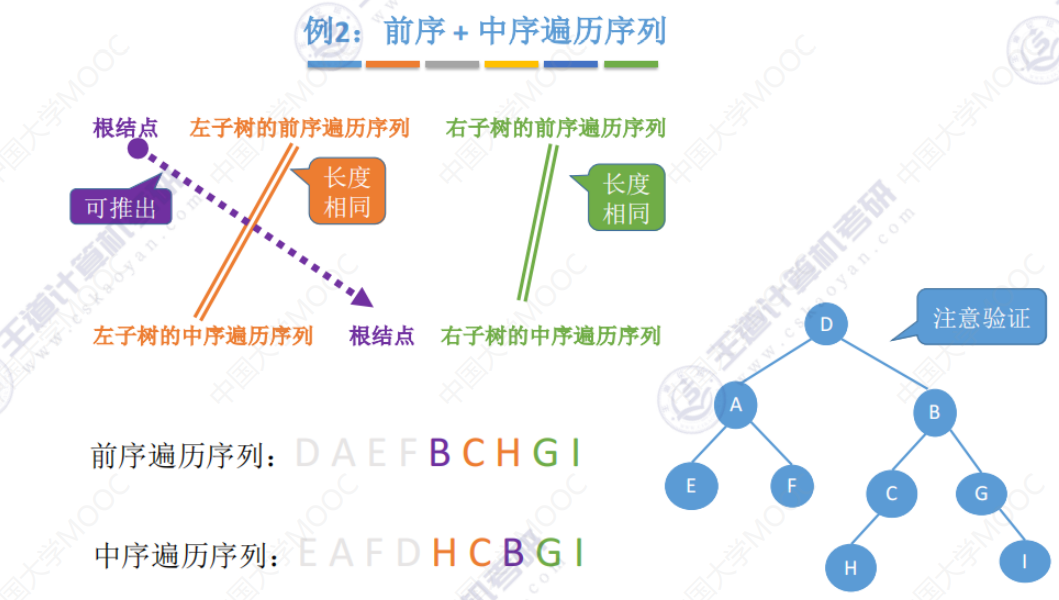
例2(练习自己做)
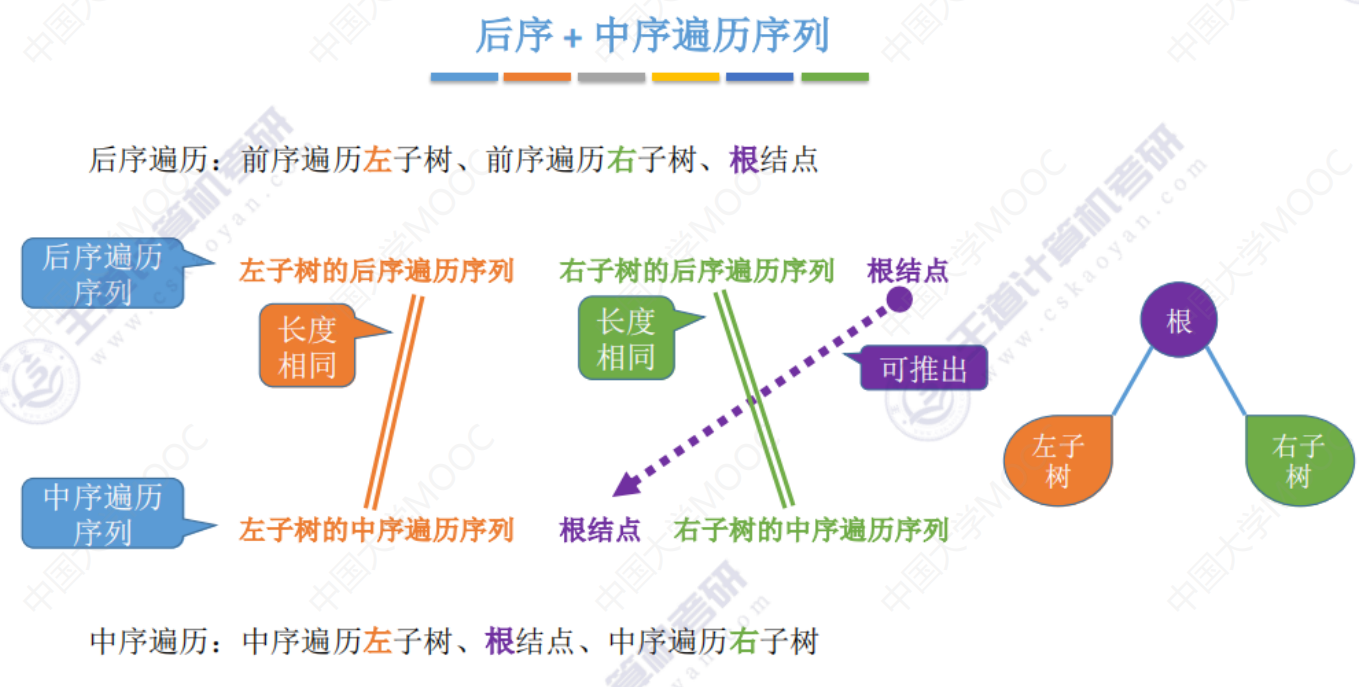
后序+中序遍历序列
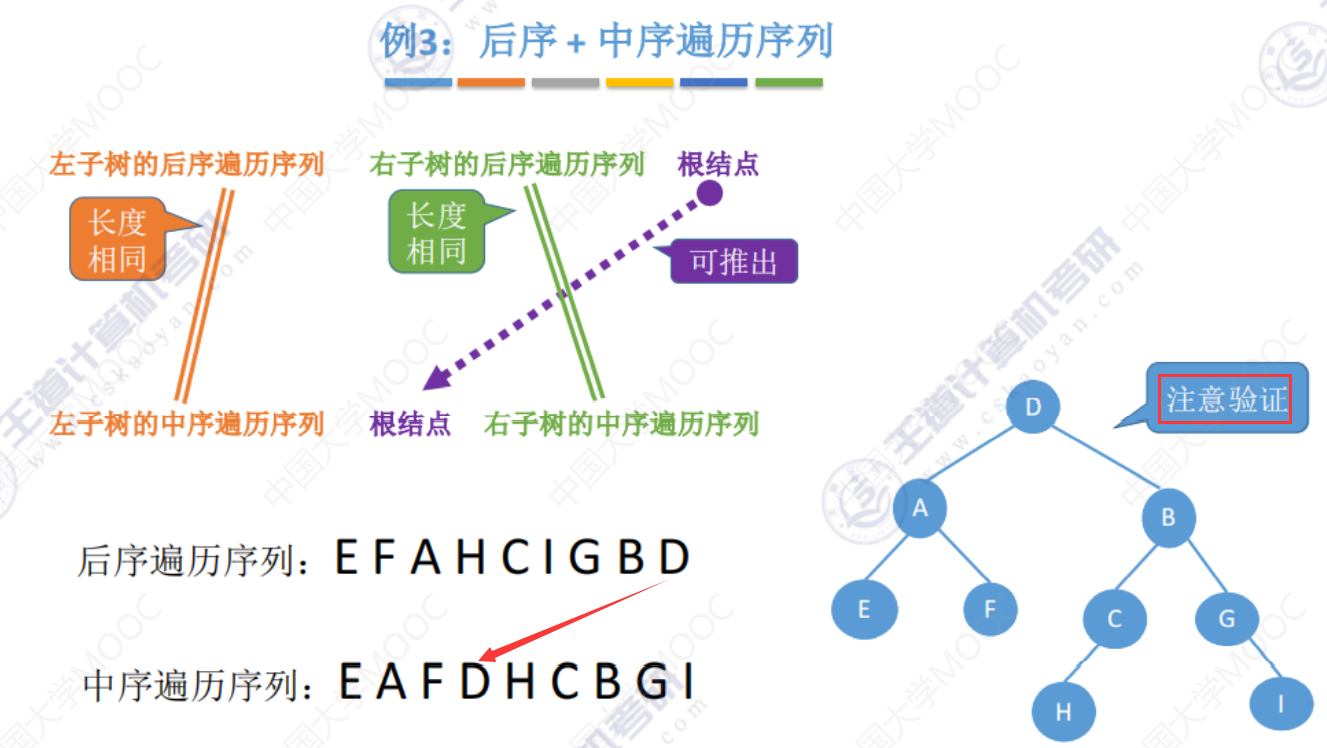
例3(自行练习)
层序+中序遍历序列
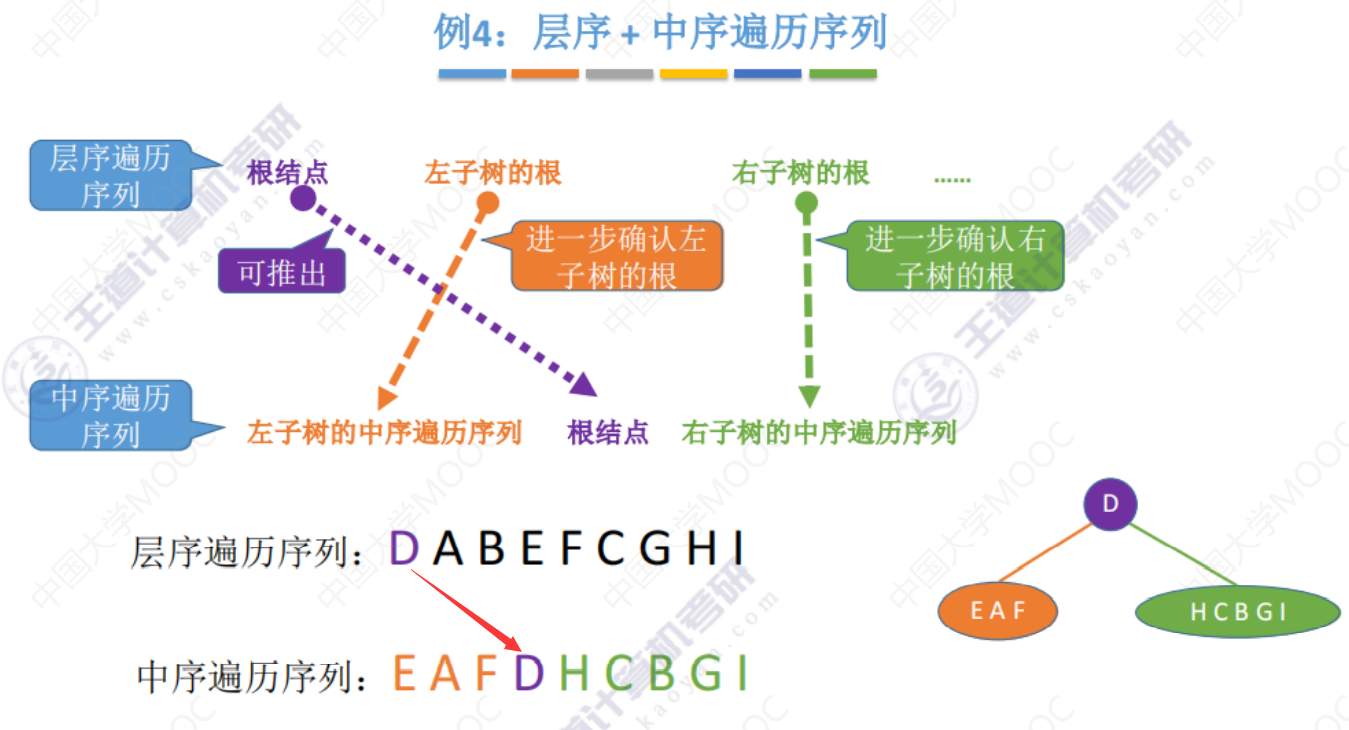
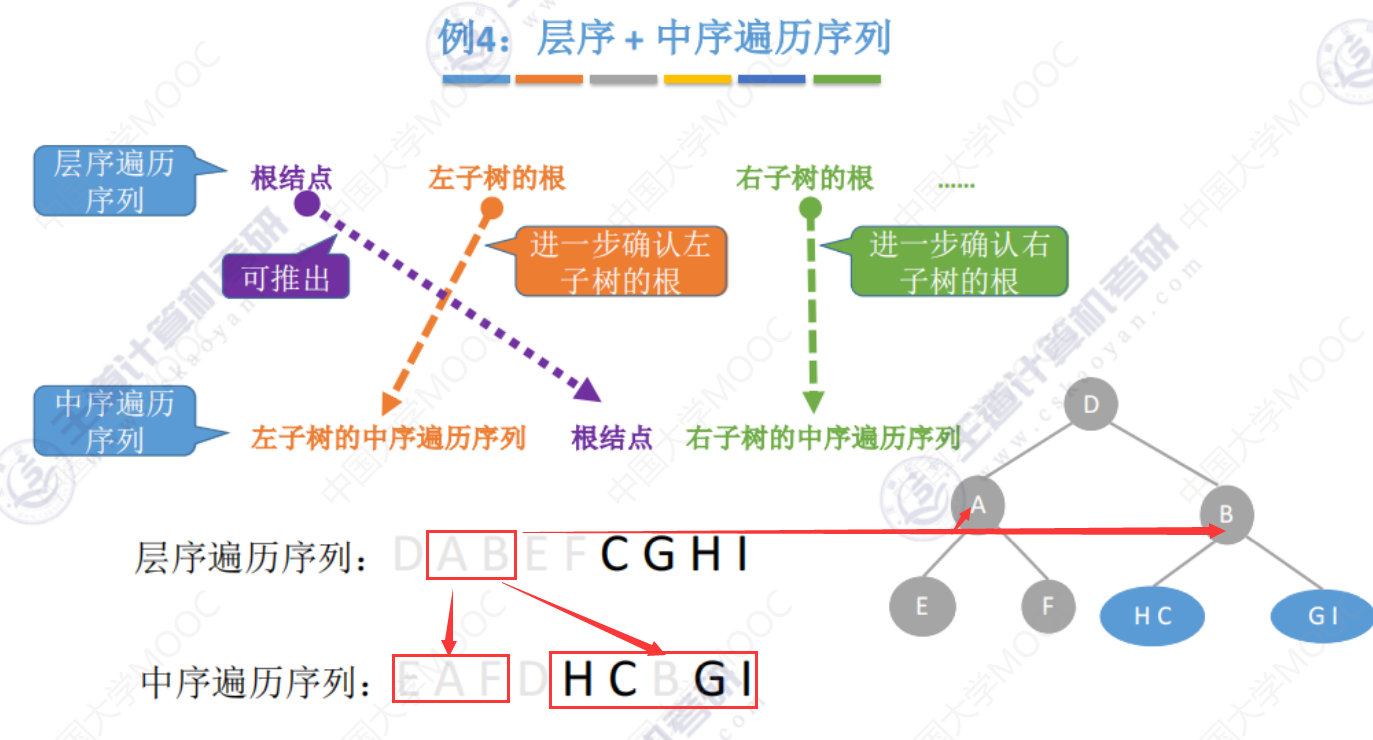
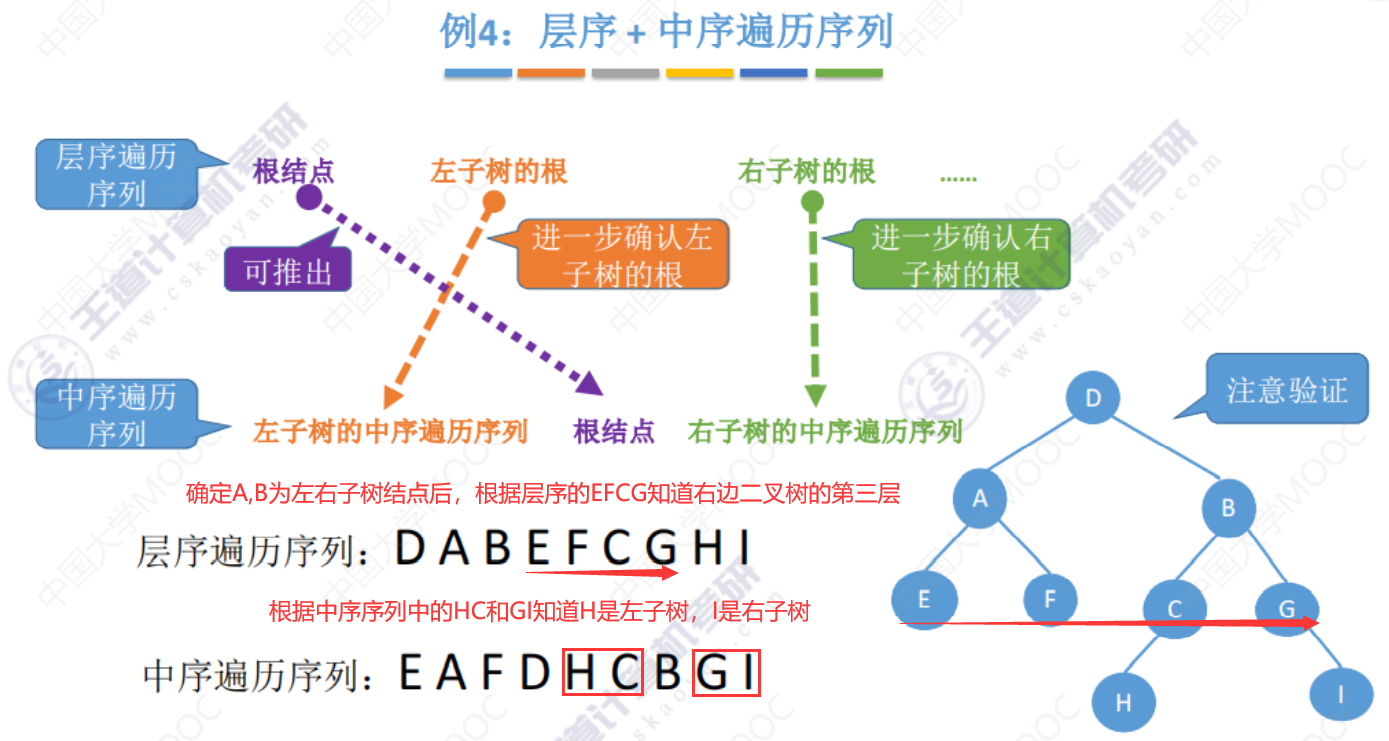
例4(自行练习)
若前序、后序、层序两两组合?
5.3-4 线索二叉树的概念
将二叉树 线索化 后,查找结点的前驱、后继就更方便、容易了。
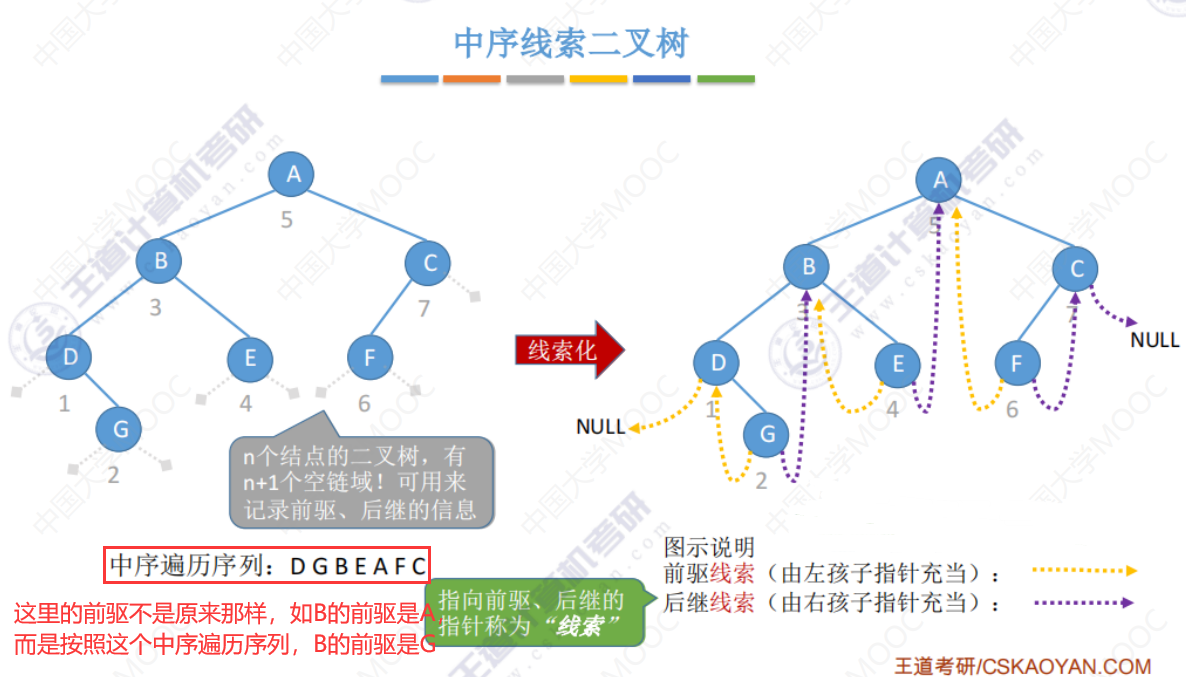
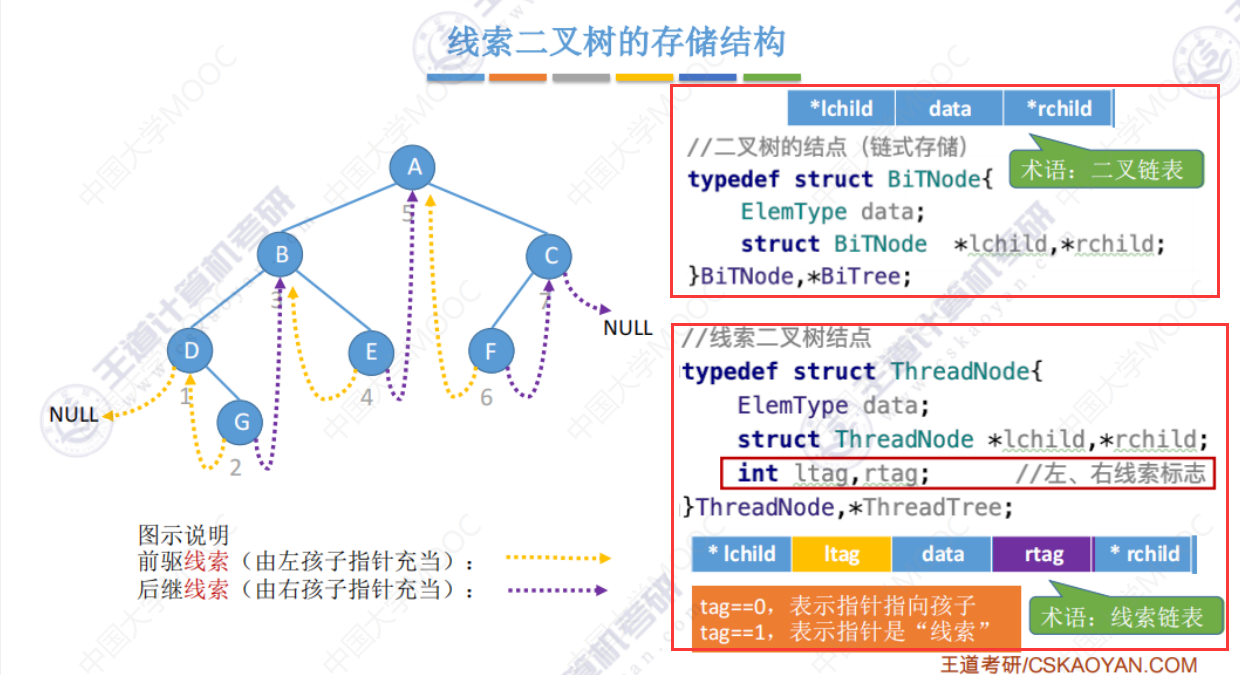
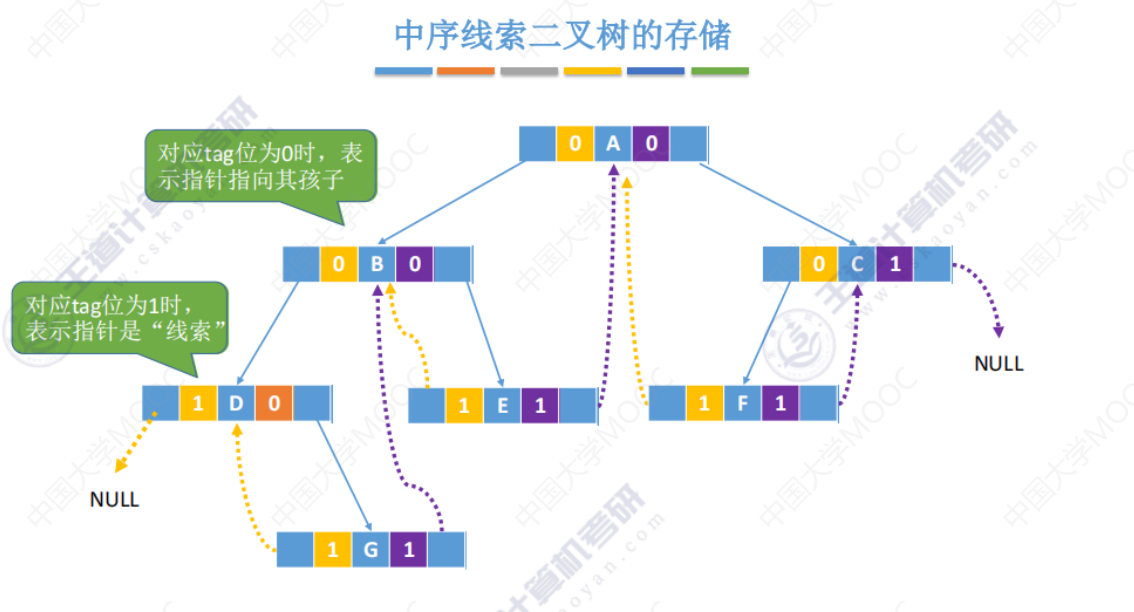
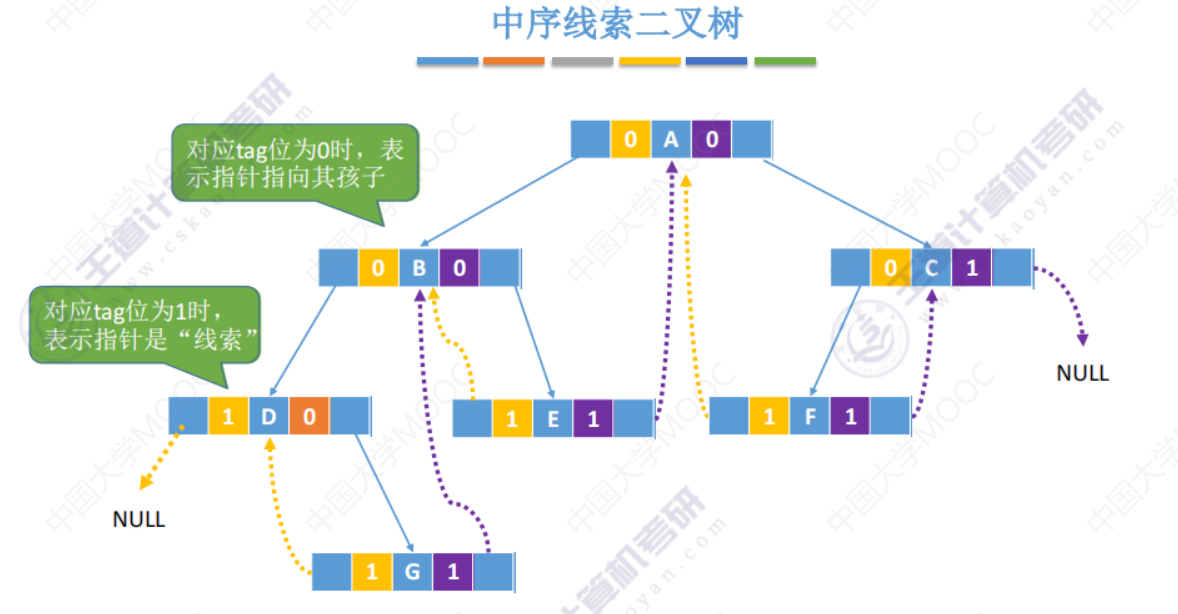
中序线索二叉树
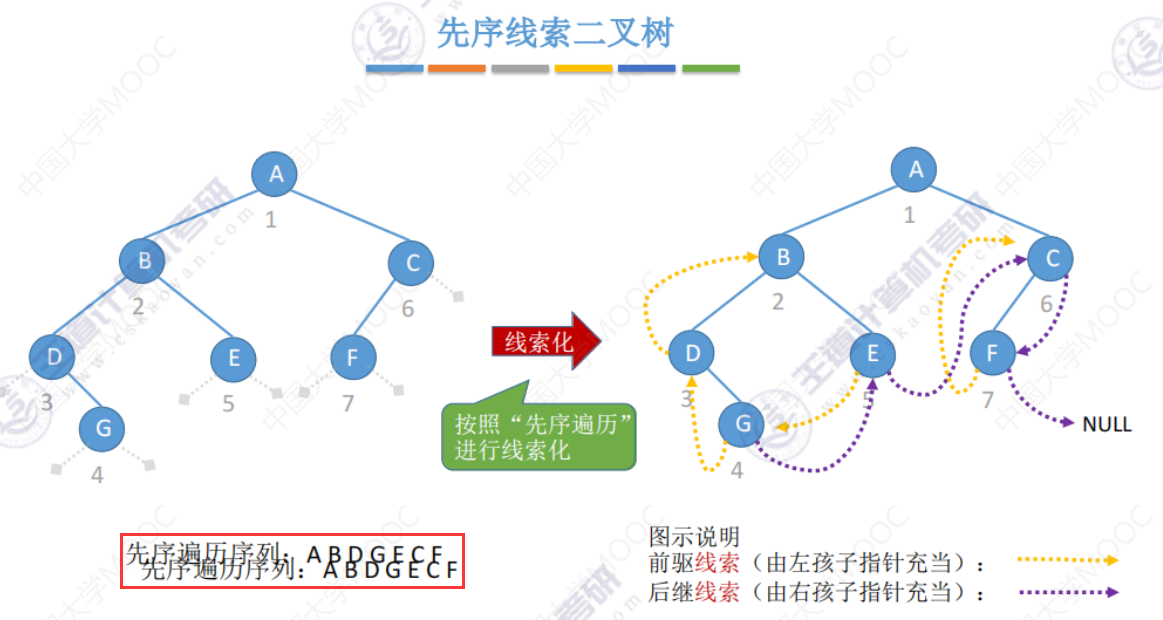
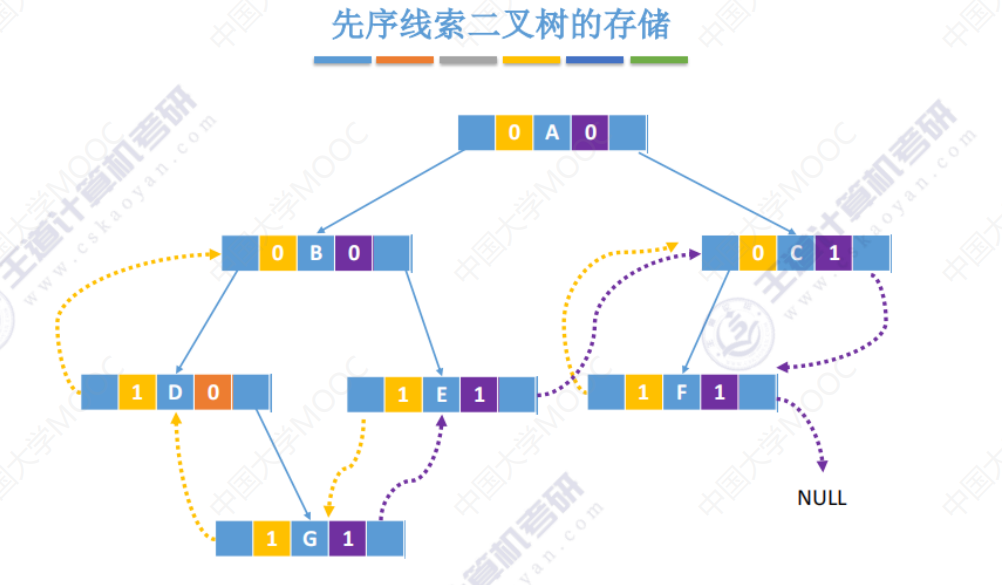
先序线索二叉树
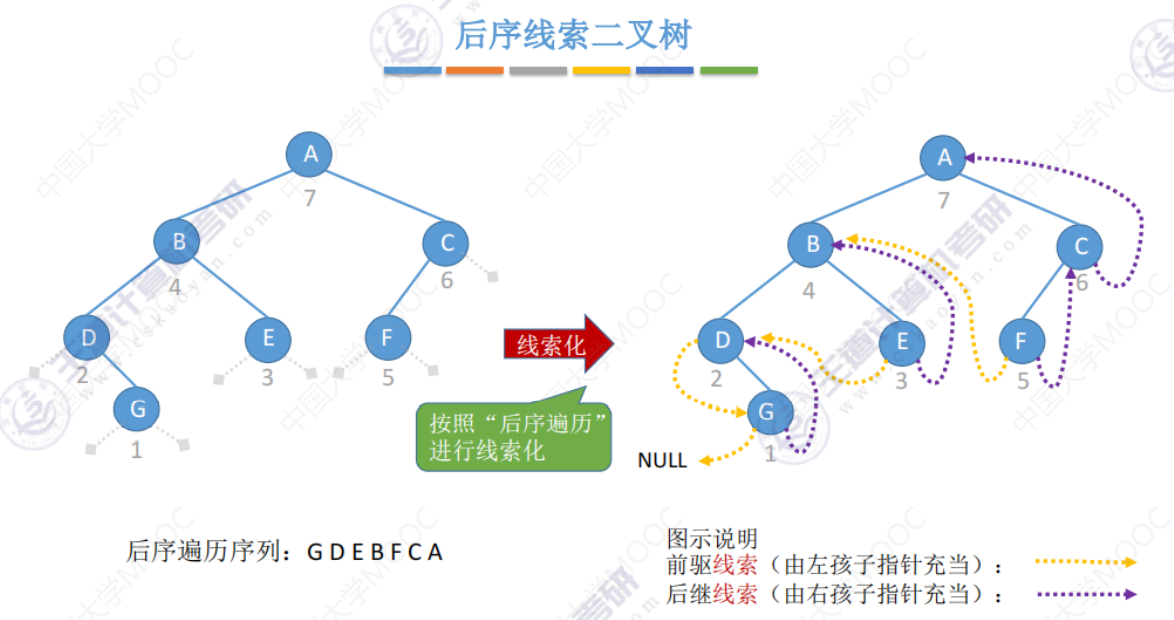
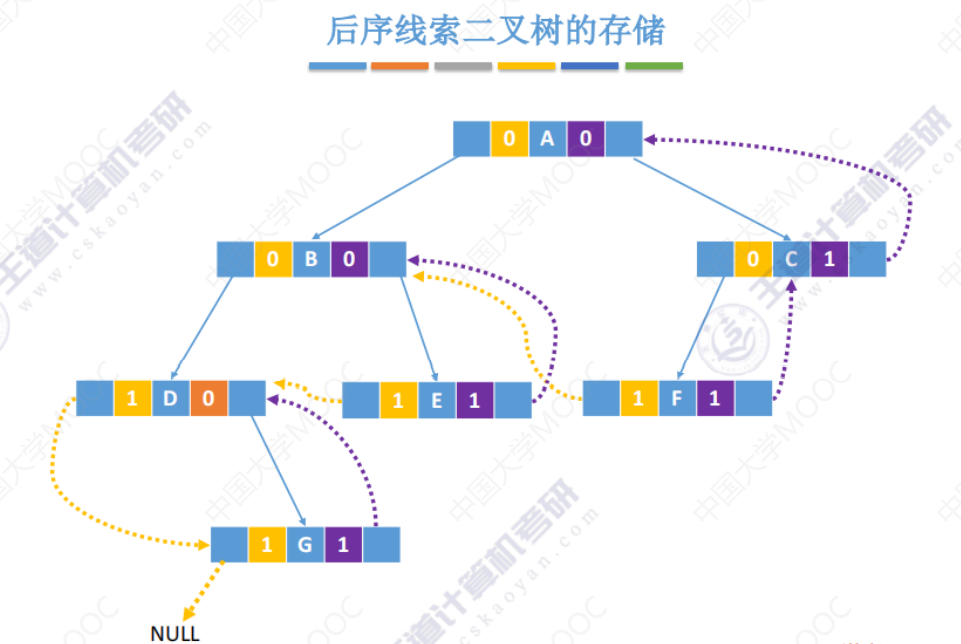
后序线索二叉树
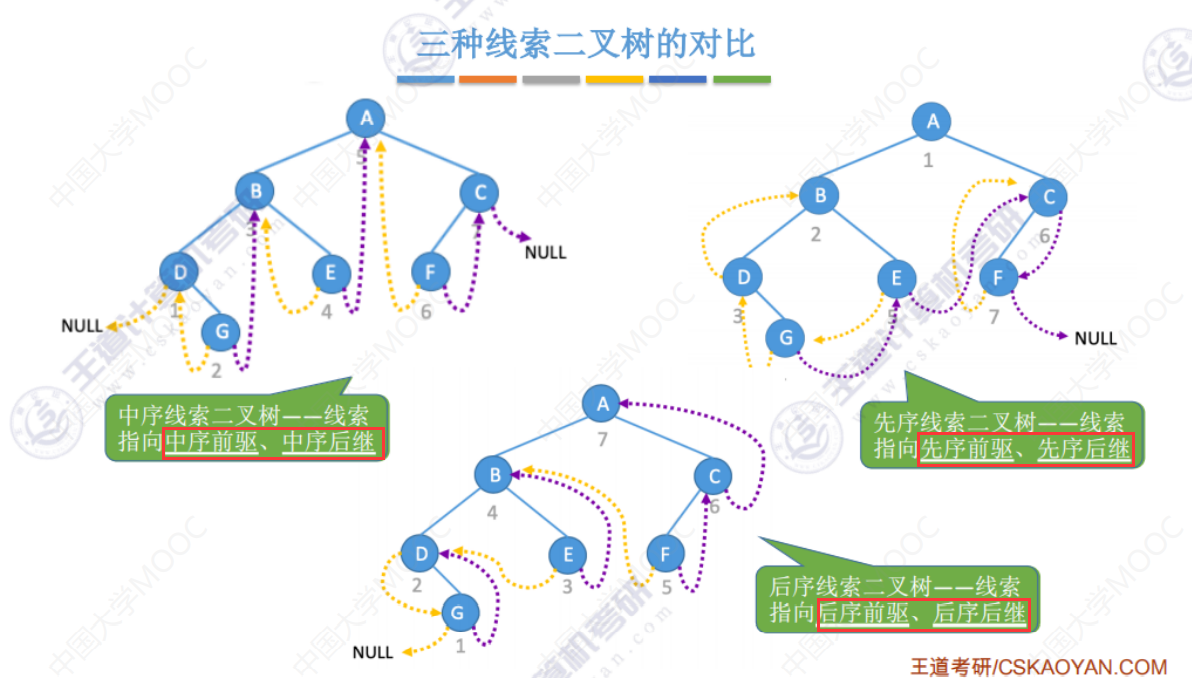
三种线索二叉树的对比
术语不同
如:中序前驱就是,如果按照中序进行遍历,他的前驱是哪个。
总结

5.3-5 二叉树的线索化
中序线索化
中序线索化代码引入
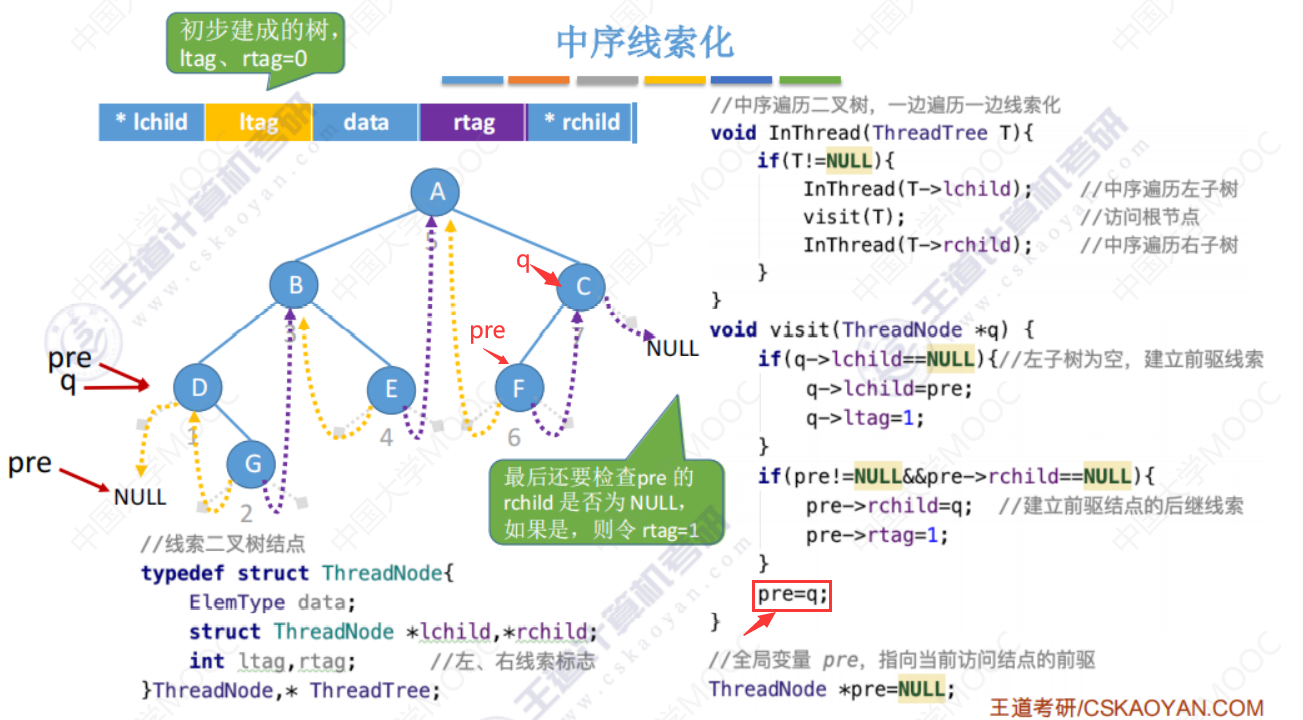
如图位置后,q指向C,q->lchild != null,不执行下面红框1 的程序,
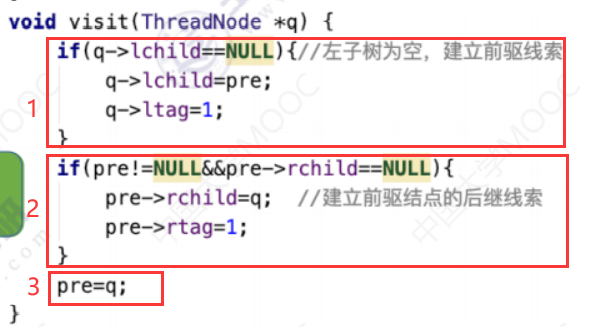
pre指向F,pre!=null && pre->rchild=null,所以建立F右边那条紫色的连接。执行红框2的程序。
之后执行红框3 pre=q。
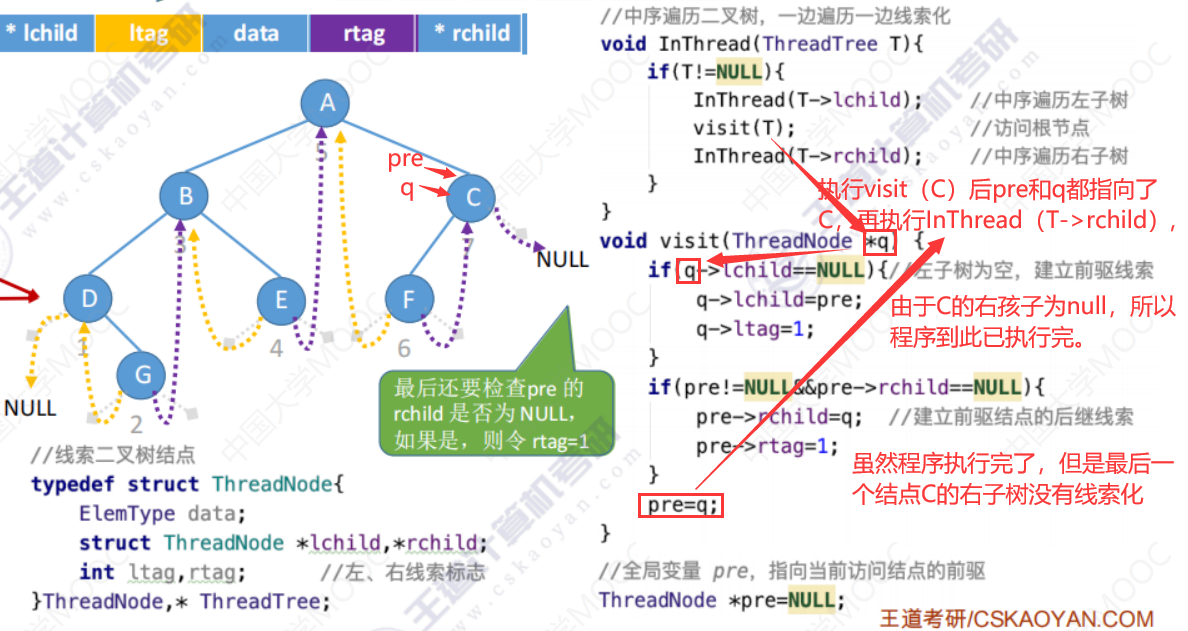
进行中序线索化的全部代码

中序线索化的二叉树应是什么样的
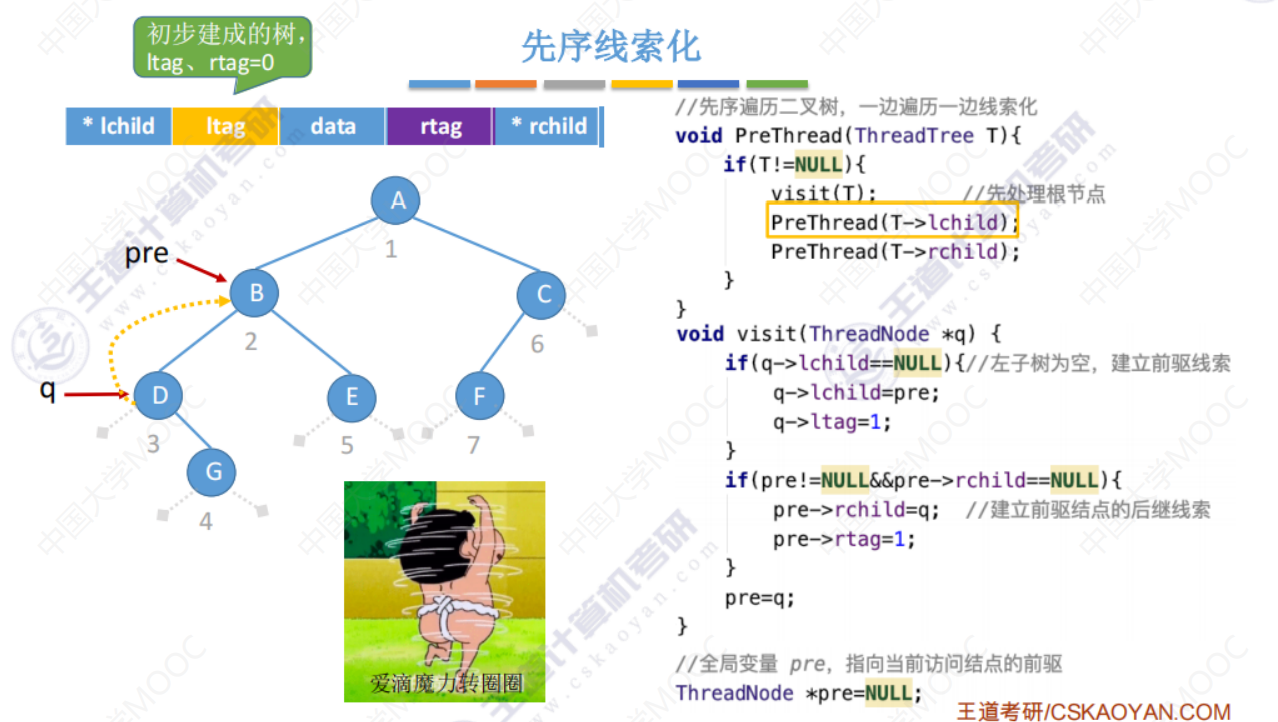
先序线索化(原理类似)
先序线索化代码引入
如图,q指向D,q->lchild=null,q->lchild=pre,q->ltag=1后,本来q的左孩子是空,但是当执行PreThread(T->lchild)时,T->lchild由于刚才线索化了,此时等于之前的 pre指向的B,T->lchild等于B 不等于null,所以又回去执行visit(B)了,这是不好的。
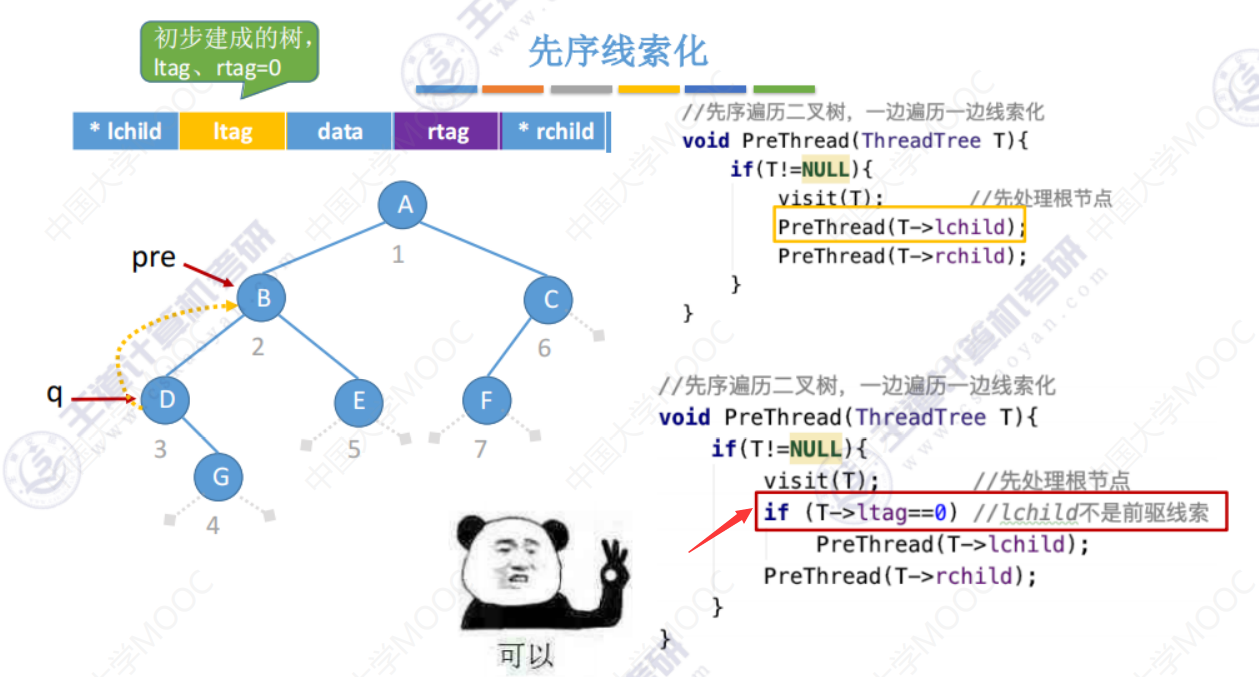
为解决上面问题,在下图中添加箭头指的一句代码 if(T->ltag==0)来判断他有无 真正的左子树,而不是线索。
进行先序线索化的全部代码

后序线索化
后序线索化中不会出现先序线索化中转圈的问题。因为是后序先访问左子树,右子树,最后访问根,所以当我们访问一个结点q的时候,这个结点他左孩子那条路已经处理完了,右孩子那条路也处理完了,所以我们访问完这个结点后,不会回头去重新访问左孩子所指向的那棵子树和右孩子所指向的那棵子树了,所以也就不会出现转圈的问题了。
进行后序线索化的全部代码

5.3-6 在线索二叉树中找前驱后继
中序线索二叉树
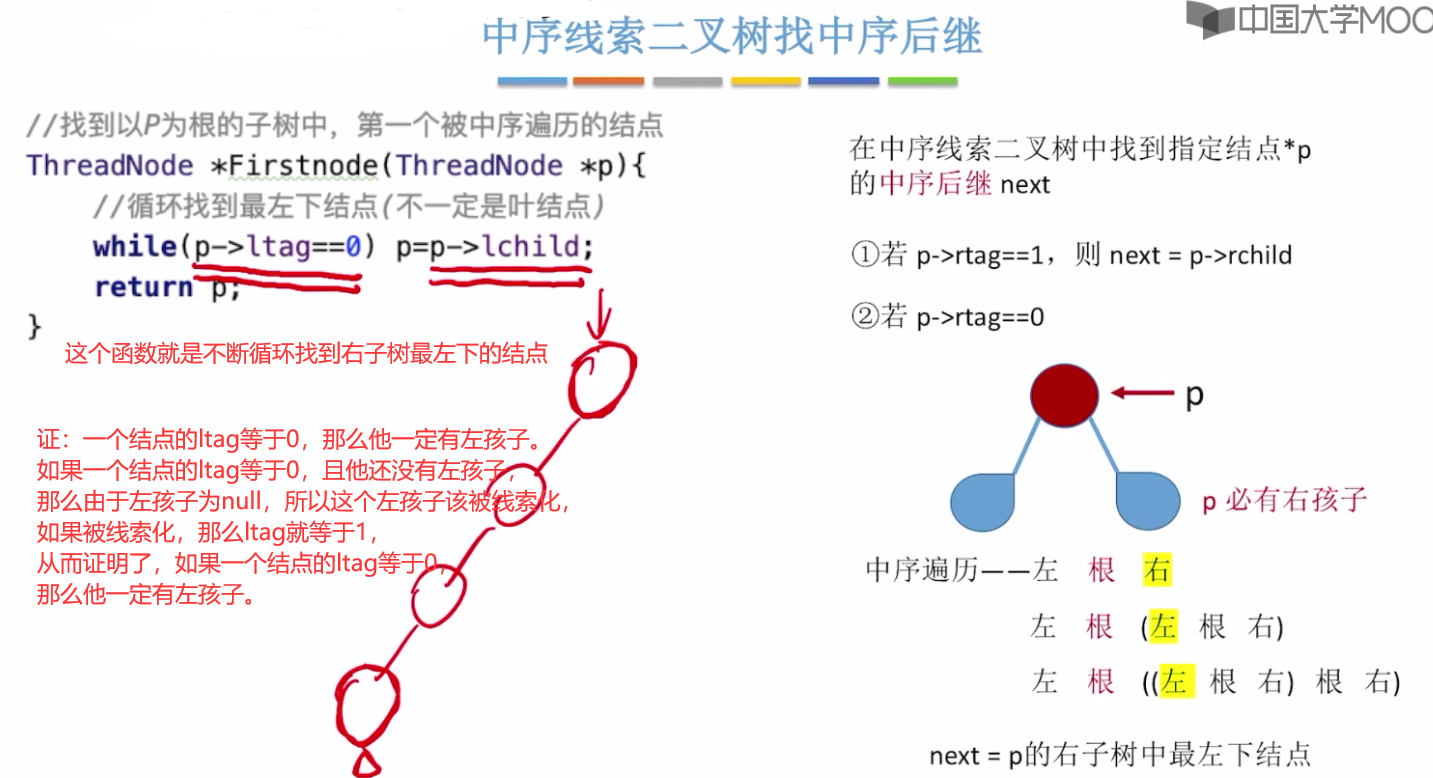
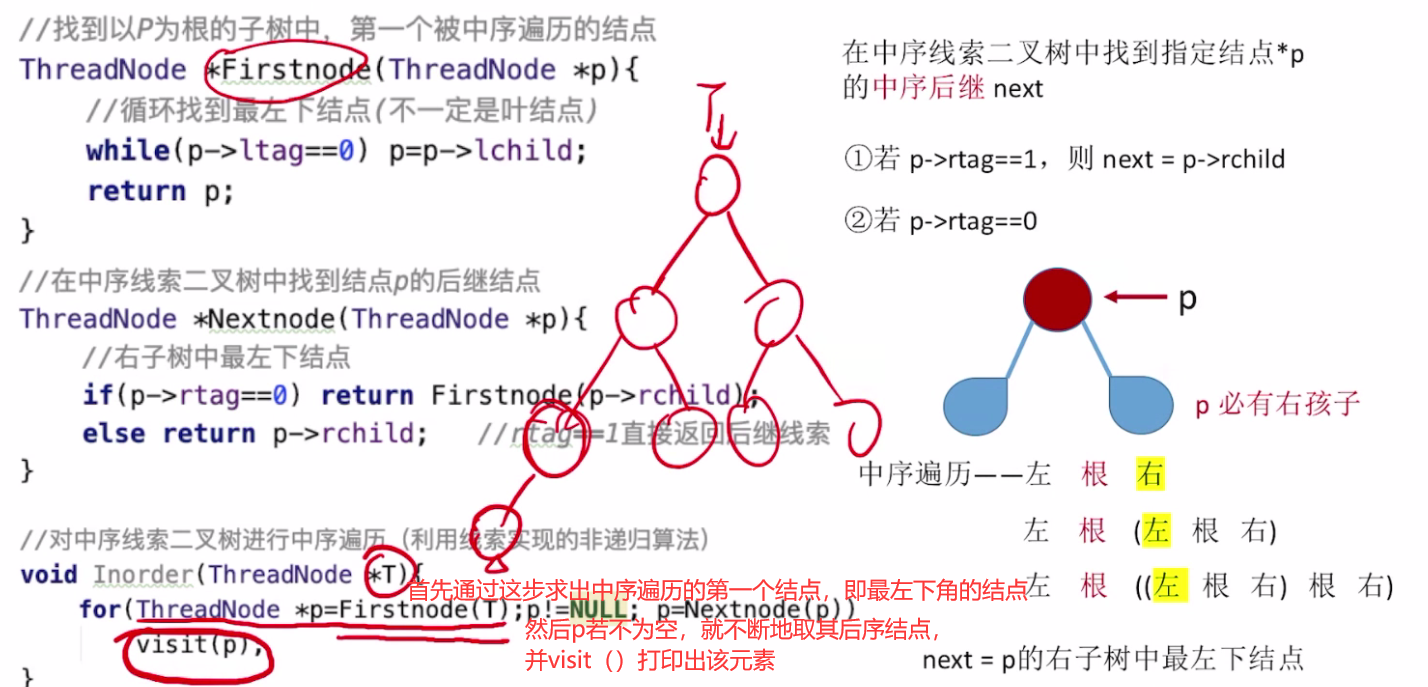
中序线索二叉树找中序后继
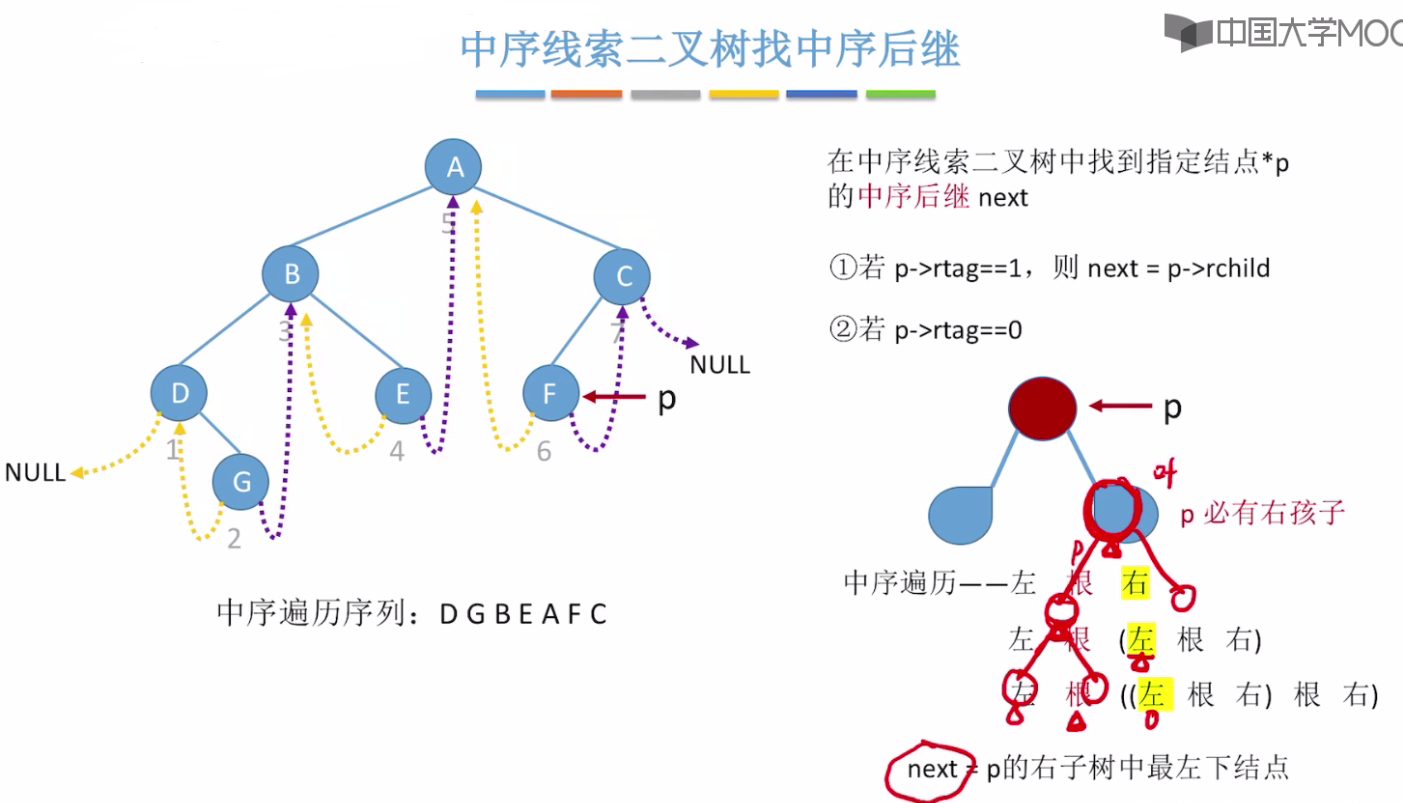

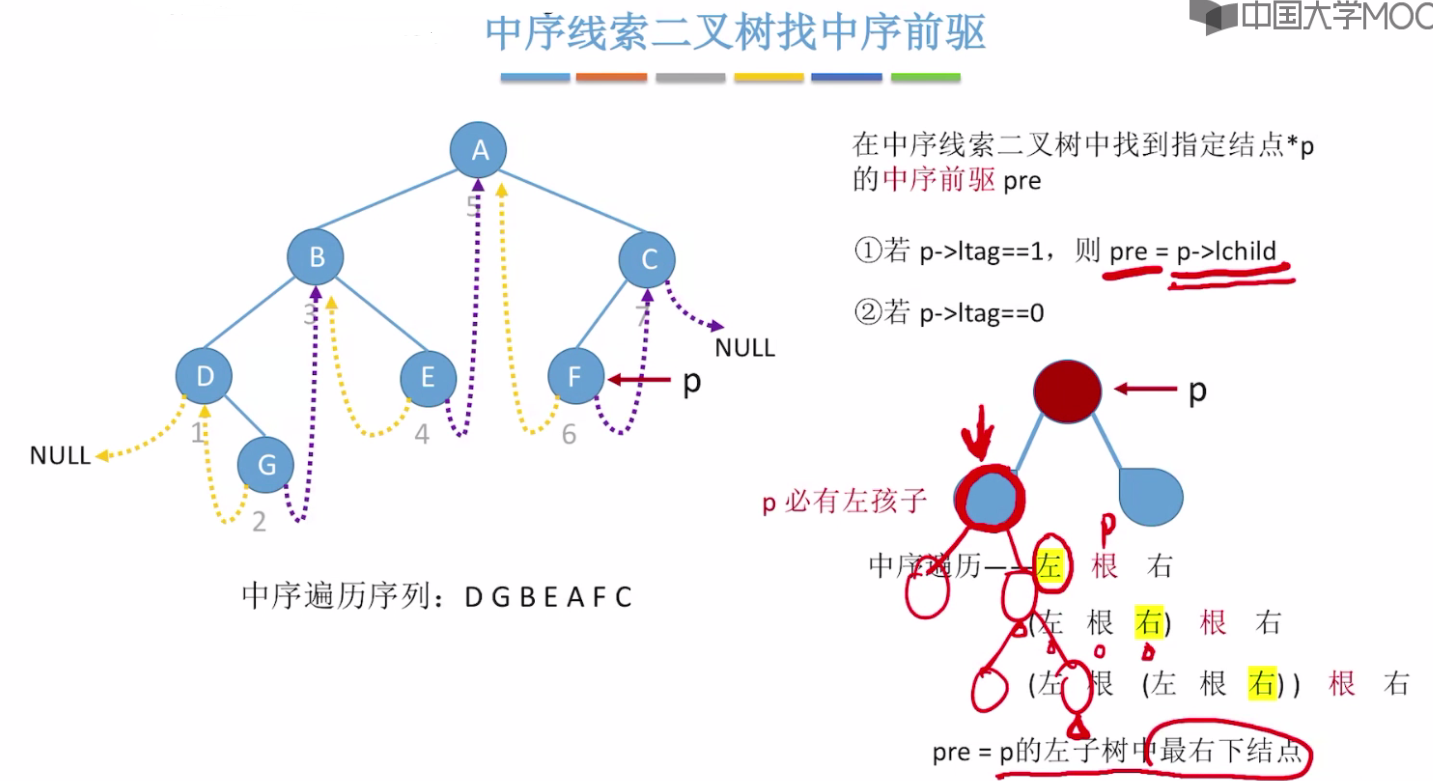
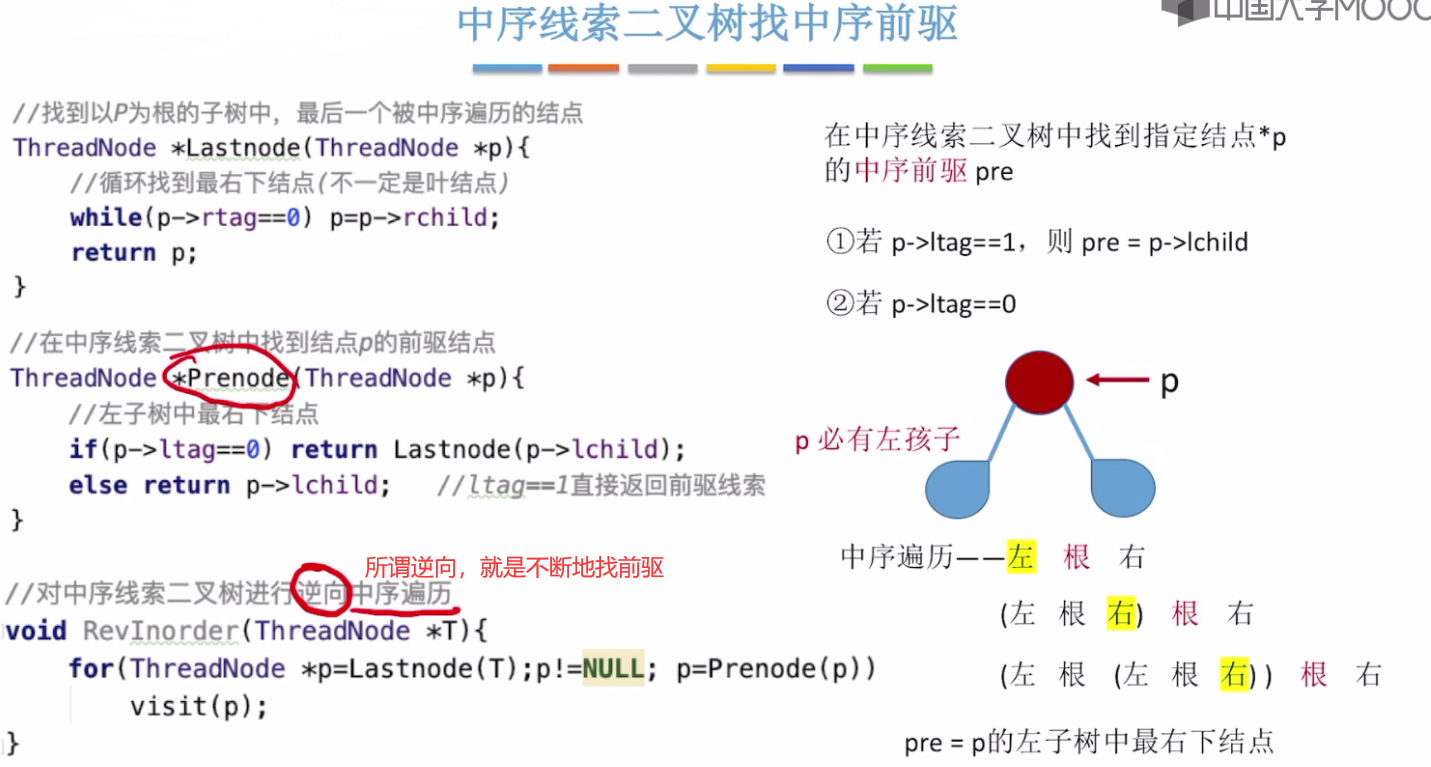
中序线索二叉树找中序前驱
根节点p的前驱 应该是左子树中按照中序遍历最后一个结点。即左子树中最右下的结点

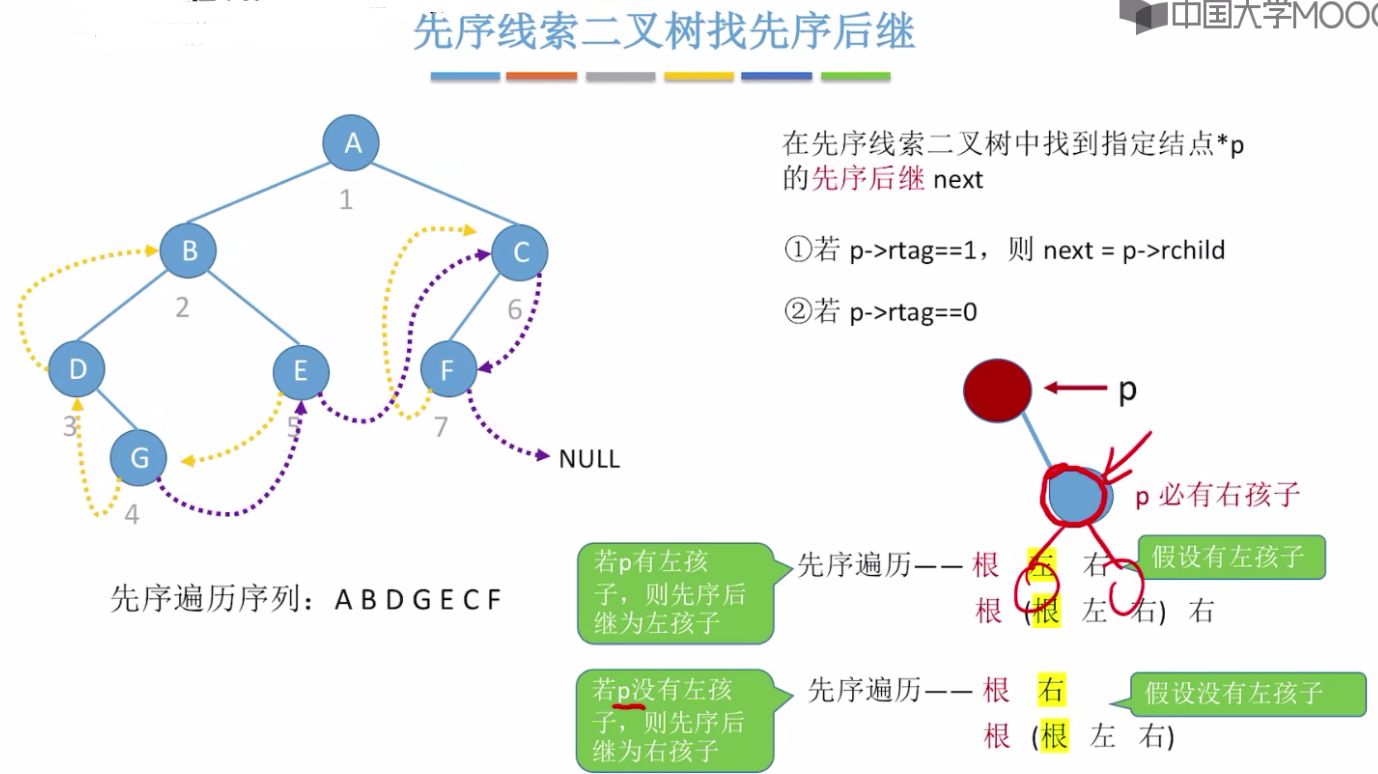
先序线索二叉树
先序线索二叉树找后继
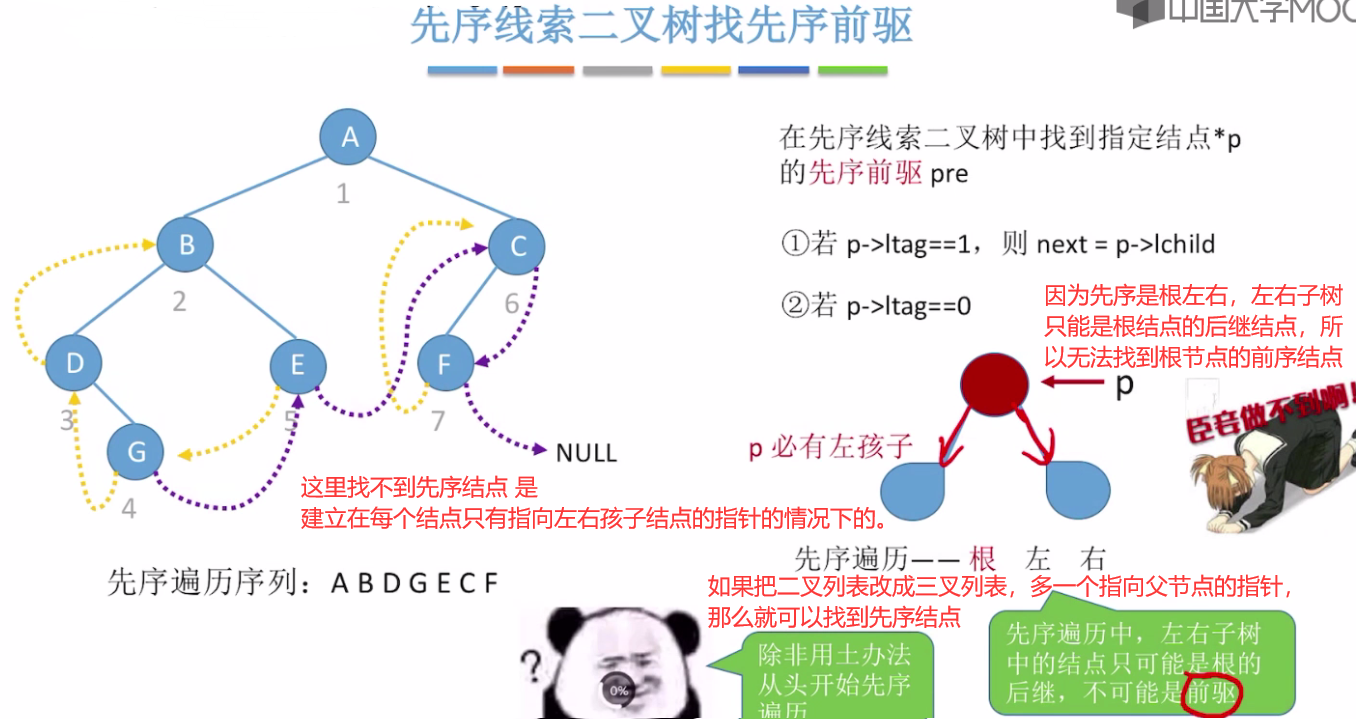
先序线索二叉树找前驱
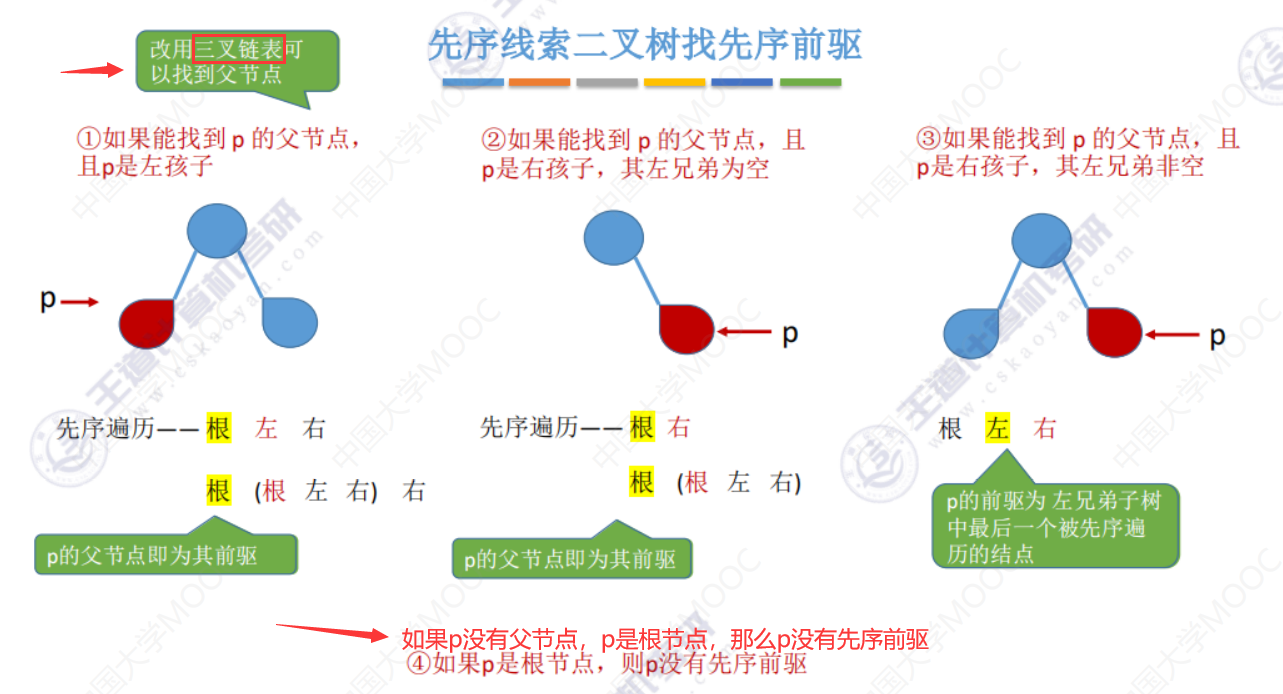
下面改为在三叉列表的情况下,多一个指向父结点的指针。
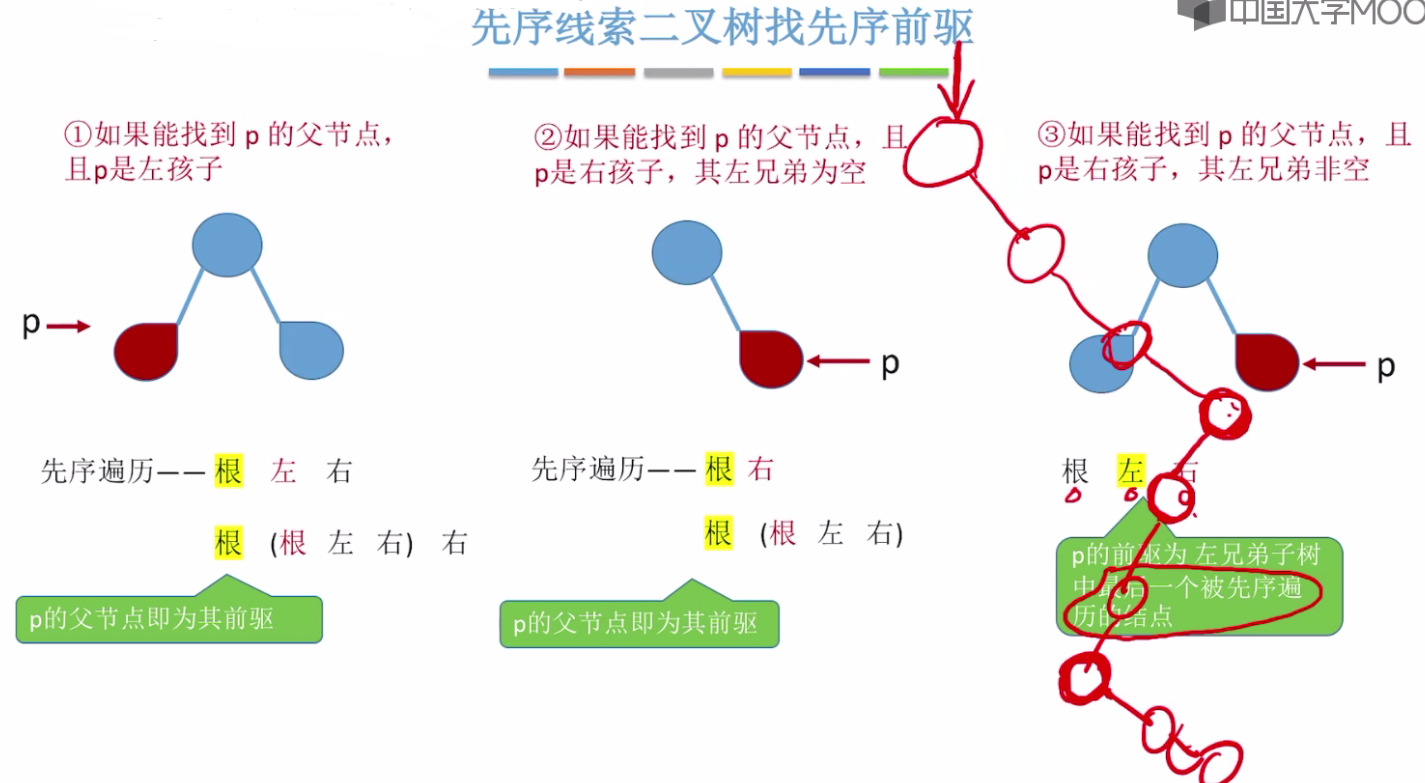
最右边图示的解释:
根左右,
左子树的最右下边,
如果最右下那个结点有左子树,那么在取该左子树,
如果该左子树有右子树,那么该取最右下边右子树,
总之就是沿着最右边往下走,遇到左边沿着最左边往下走,遇到右边沿着最右边往下走。。。。。。
后序线索二叉树
后序线索二叉树找前驱
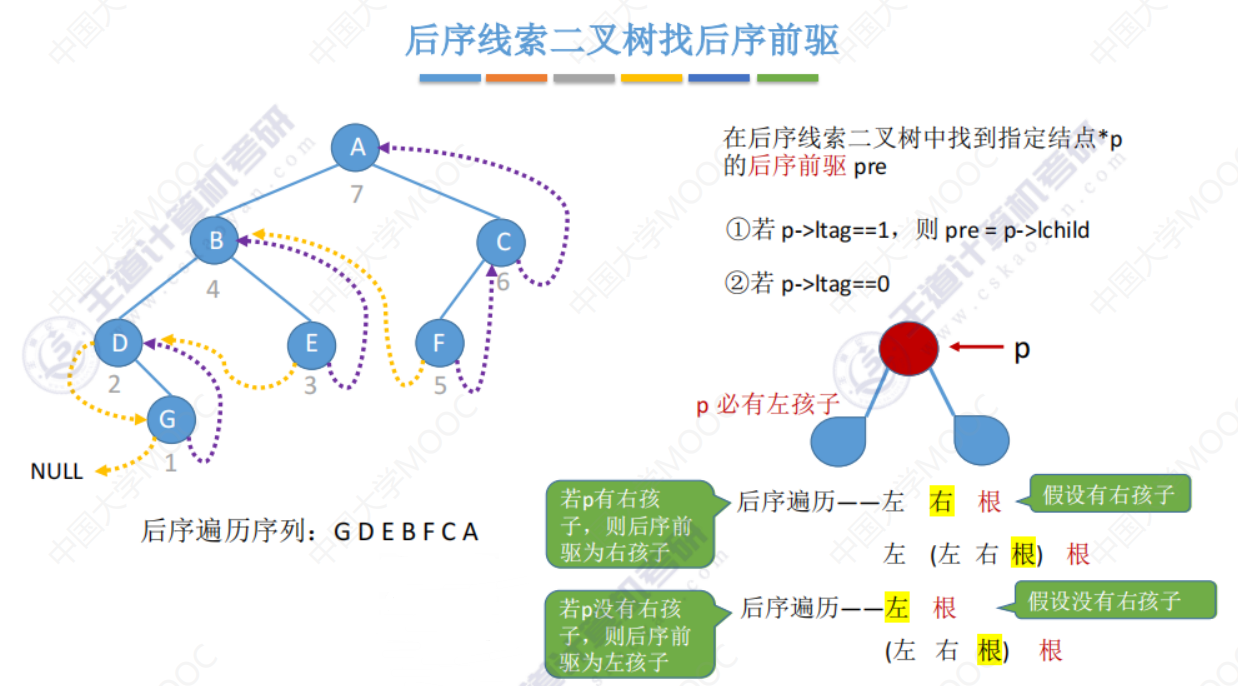
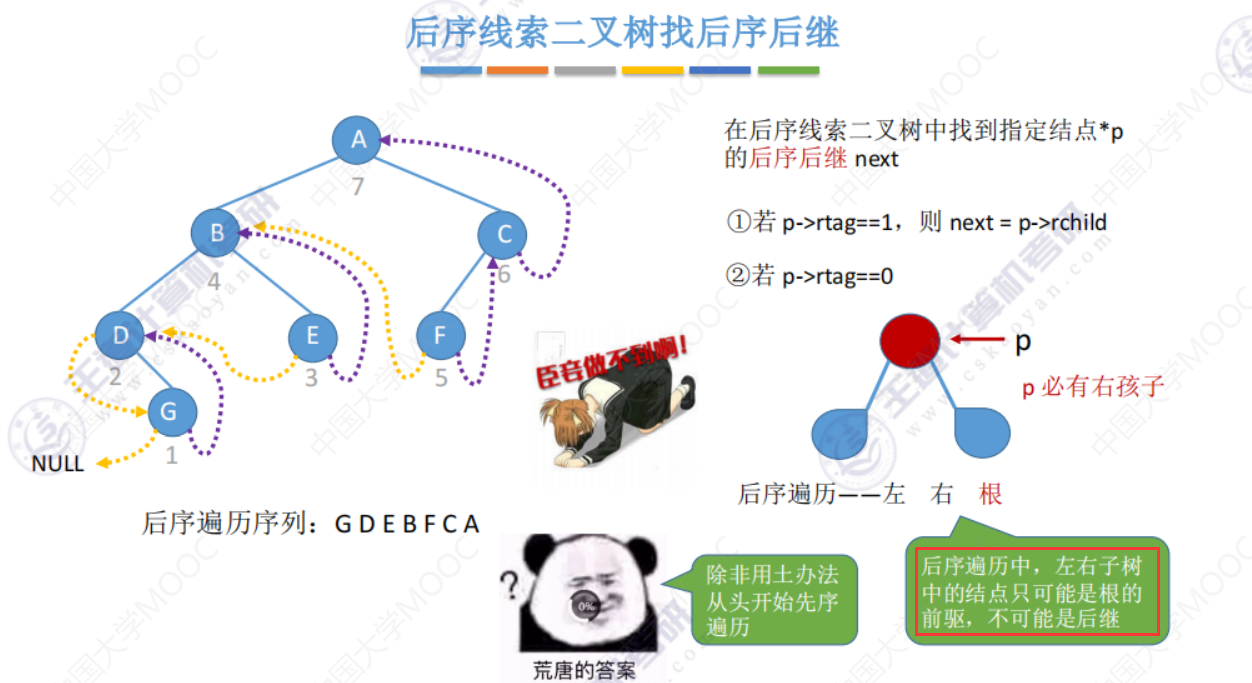
后序线索二叉树找后继
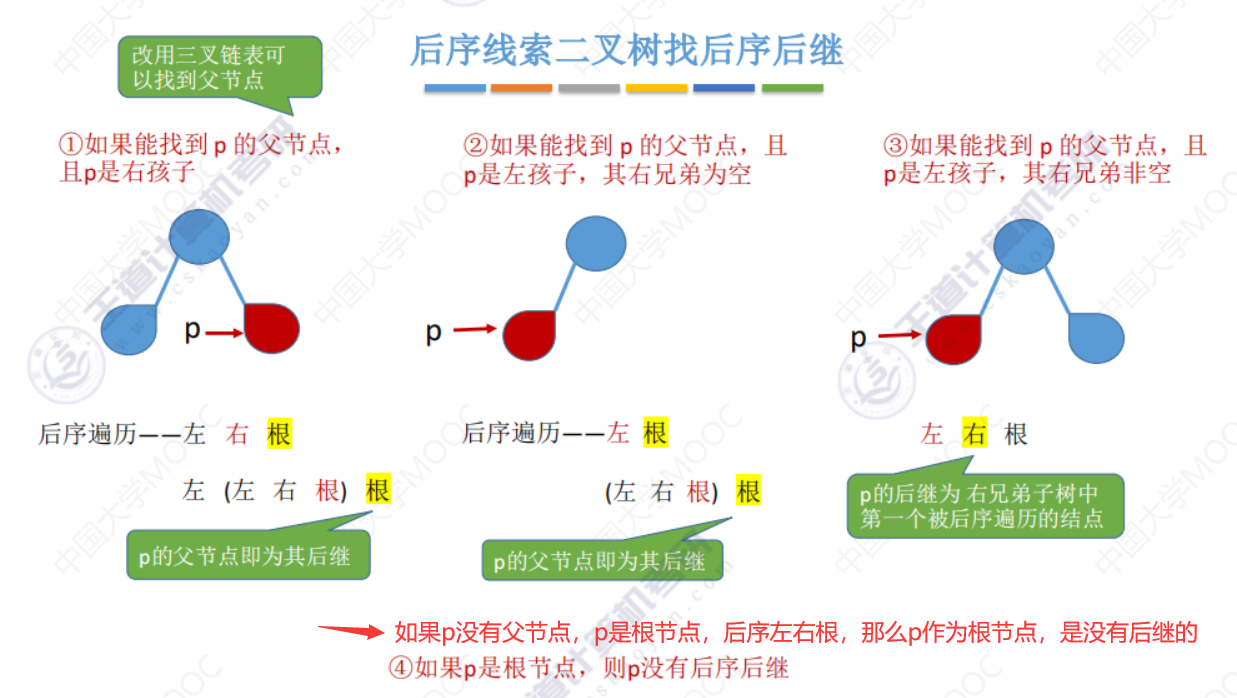
下面改为在三叉列表的情况下,多一个指向父结点的指针。

5.4-1 树的存储结构(一般的树,不止二叉树)
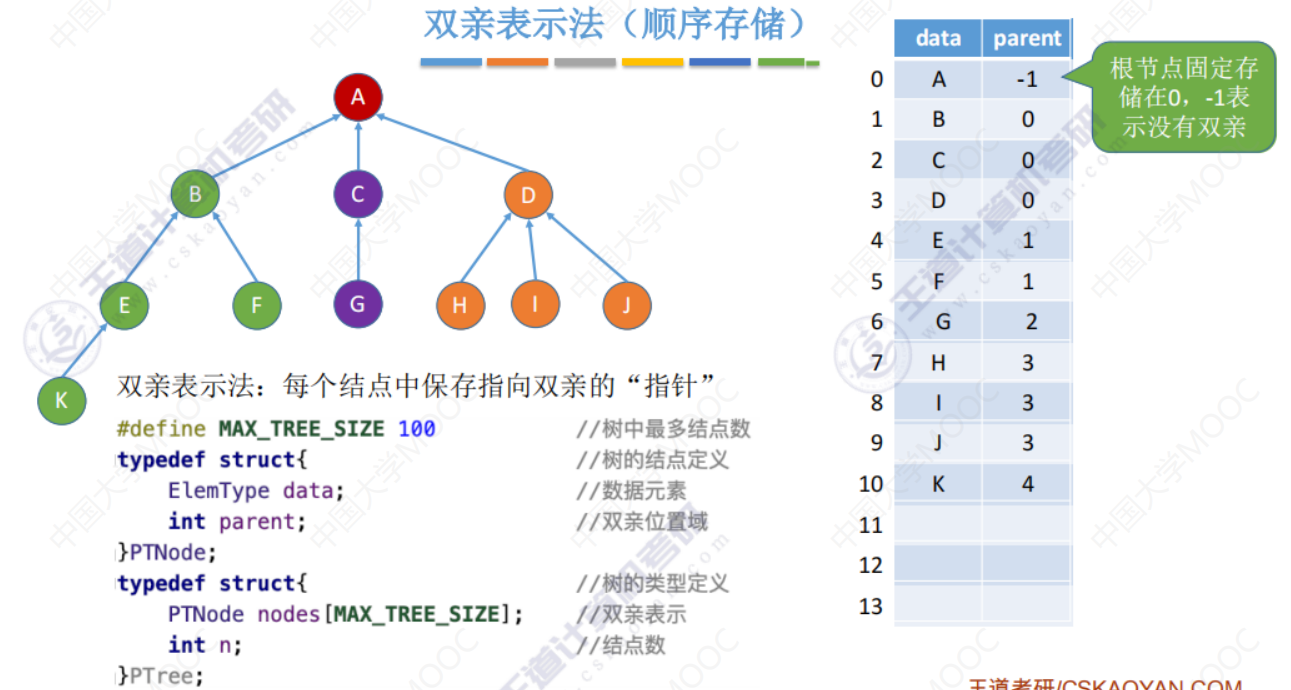
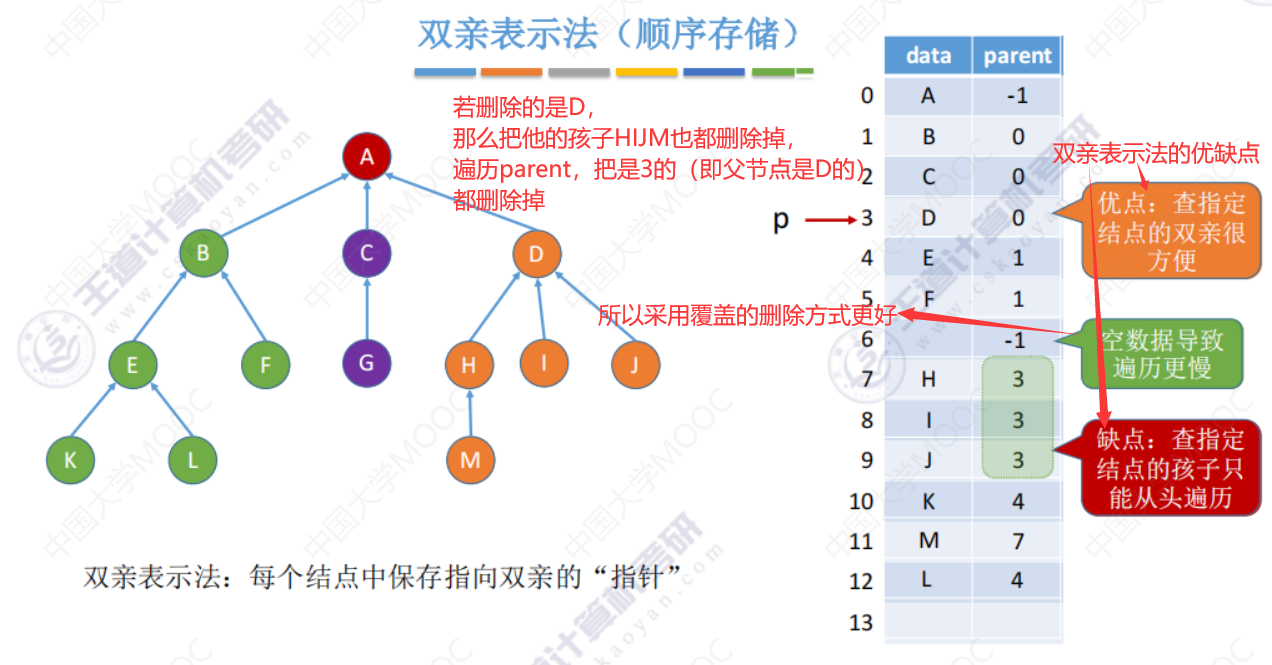
双亲表示法
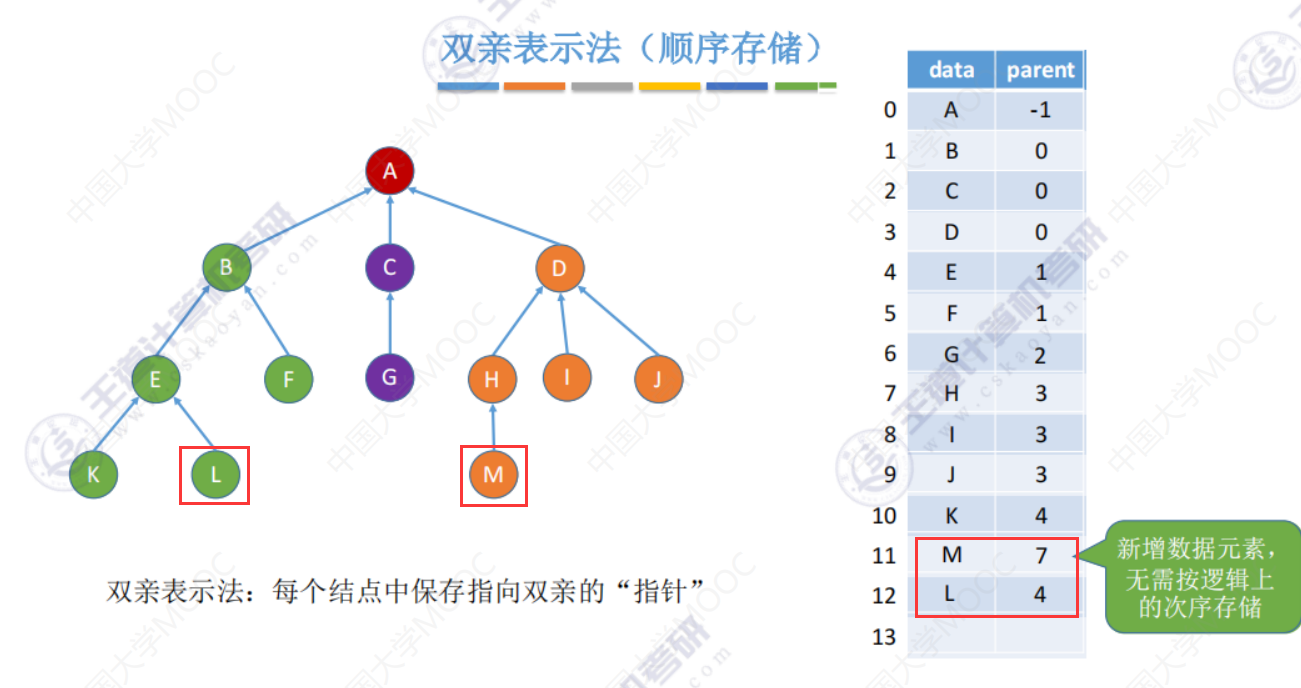
增
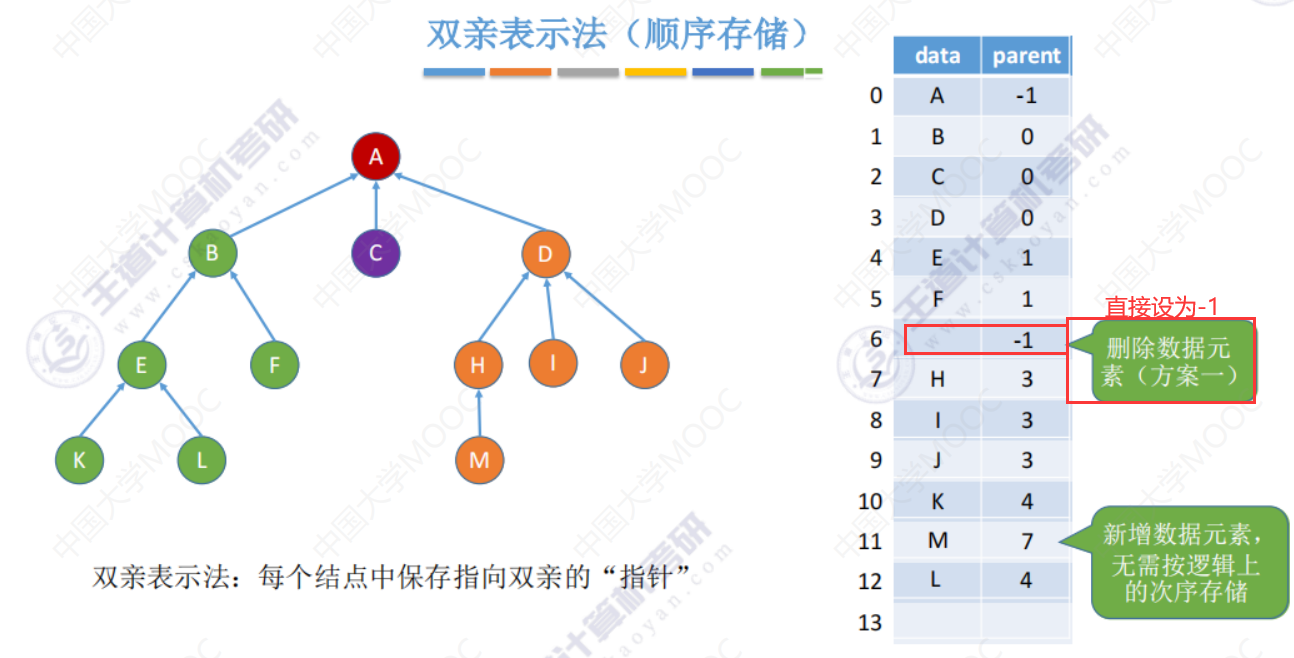
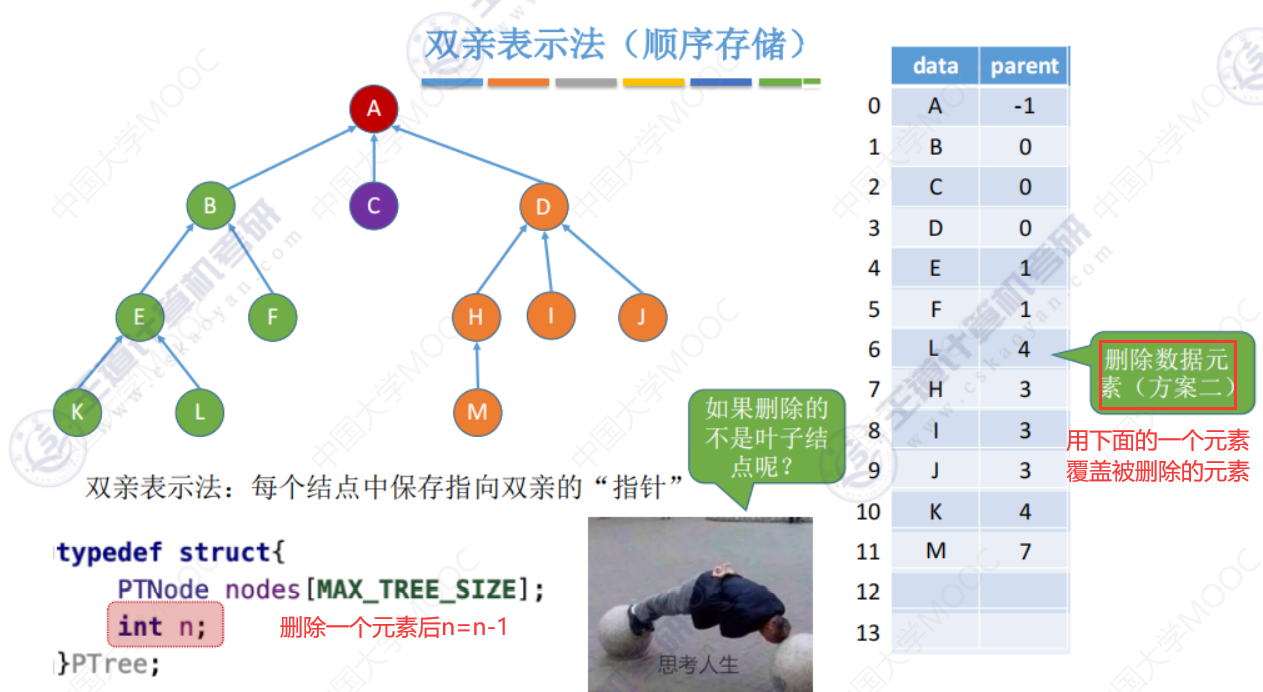
删
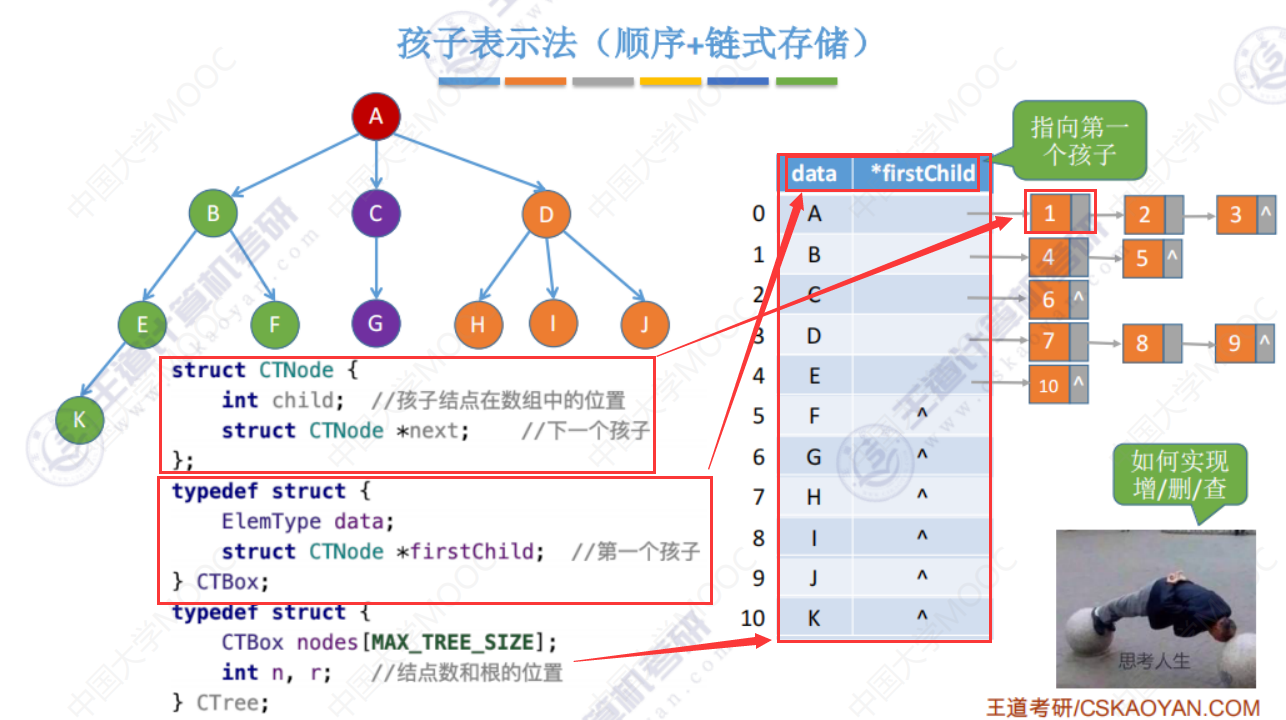
孩子表示法
找孩子很方便,找双亲不方便
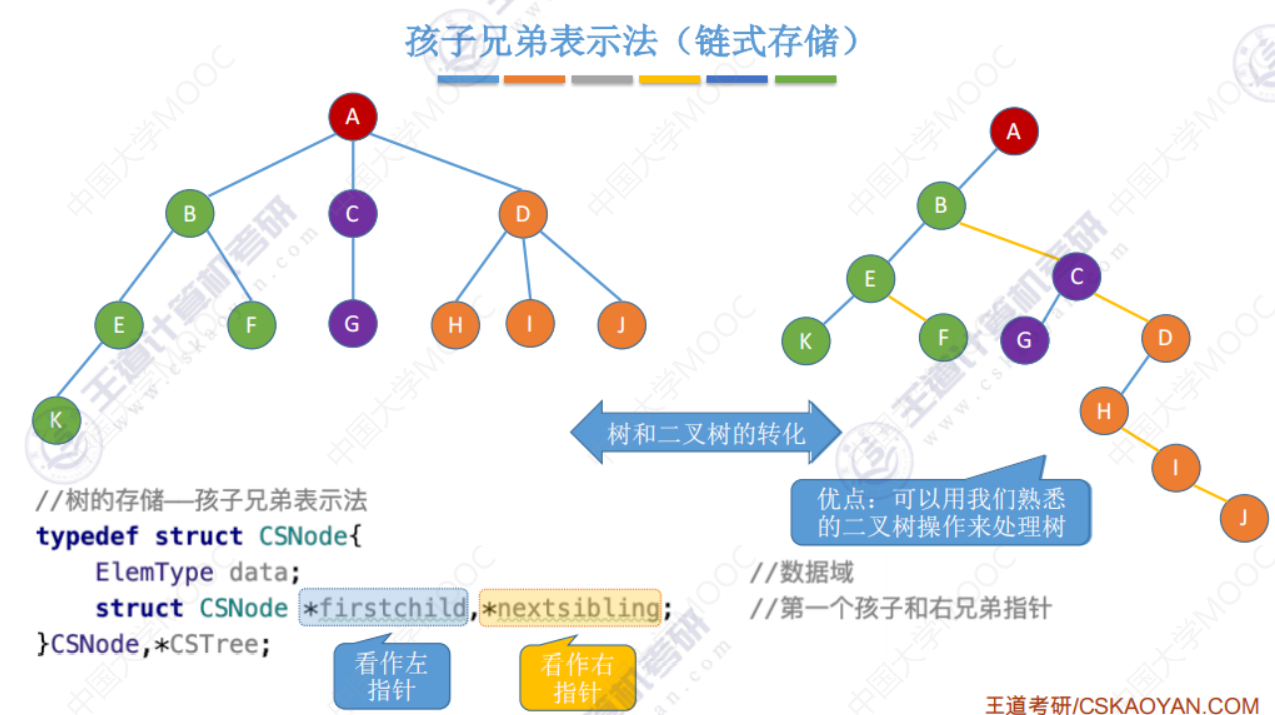
孩子兄弟表示法
用孩子兄弟表示法存储的树 在物理上 呈现出“二叉树”的样子。
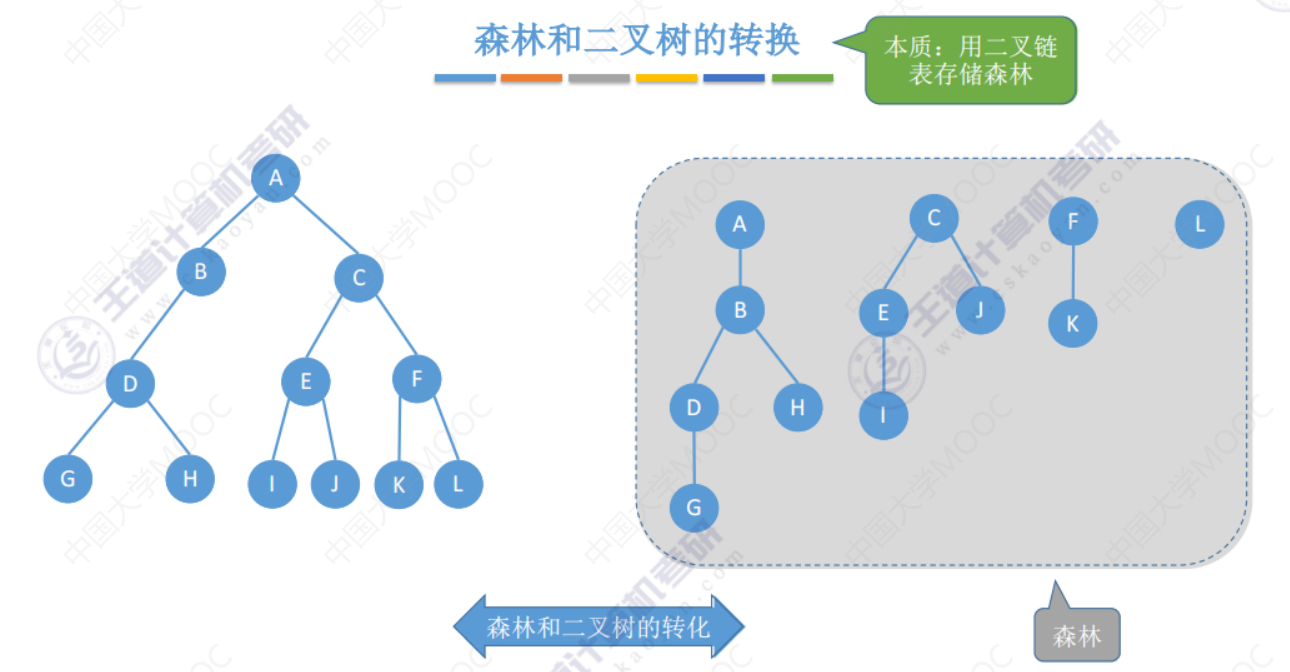
森林和二叉树的转换
森林转换为二叉树
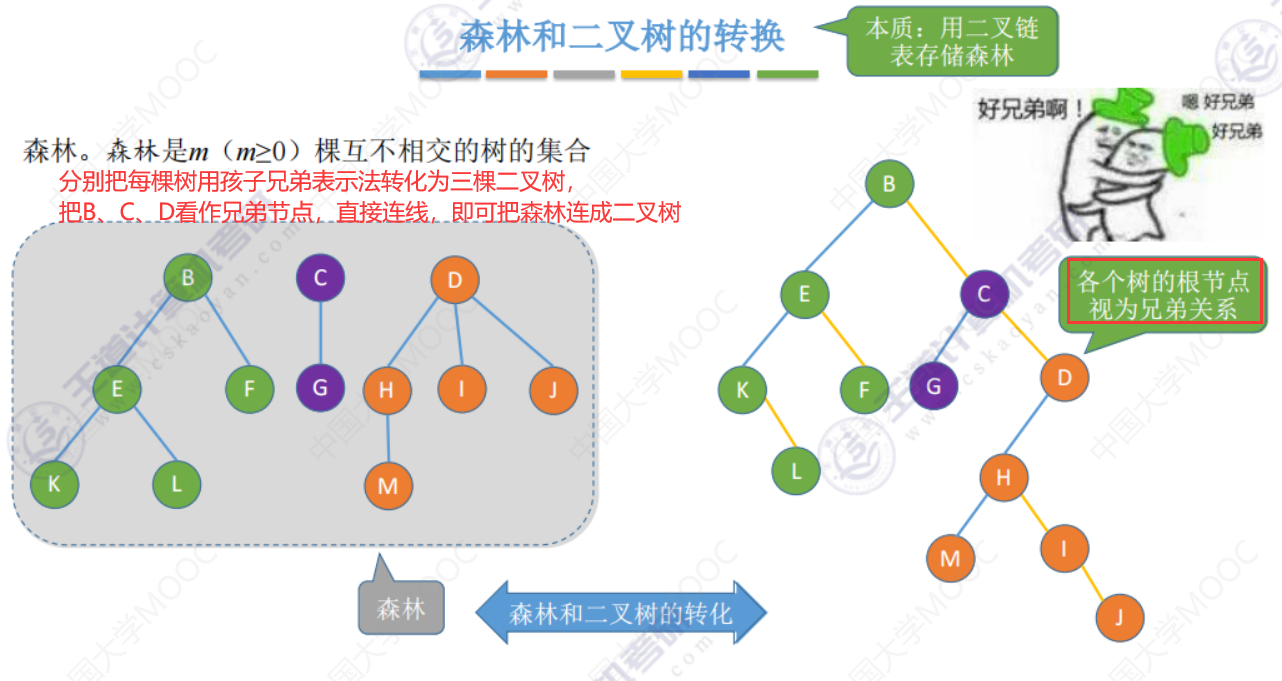
二叉树转换为森林
5.4-2 树和森林的遍历
树的遍历
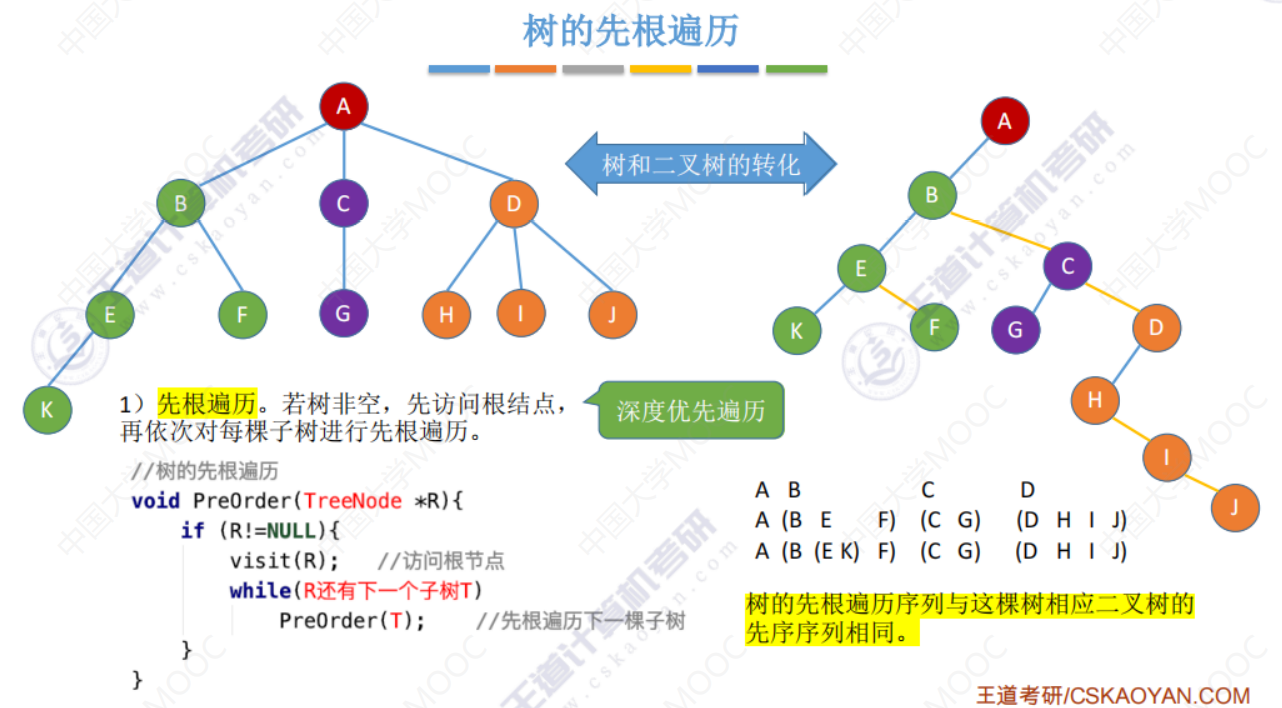
树的先根遍历
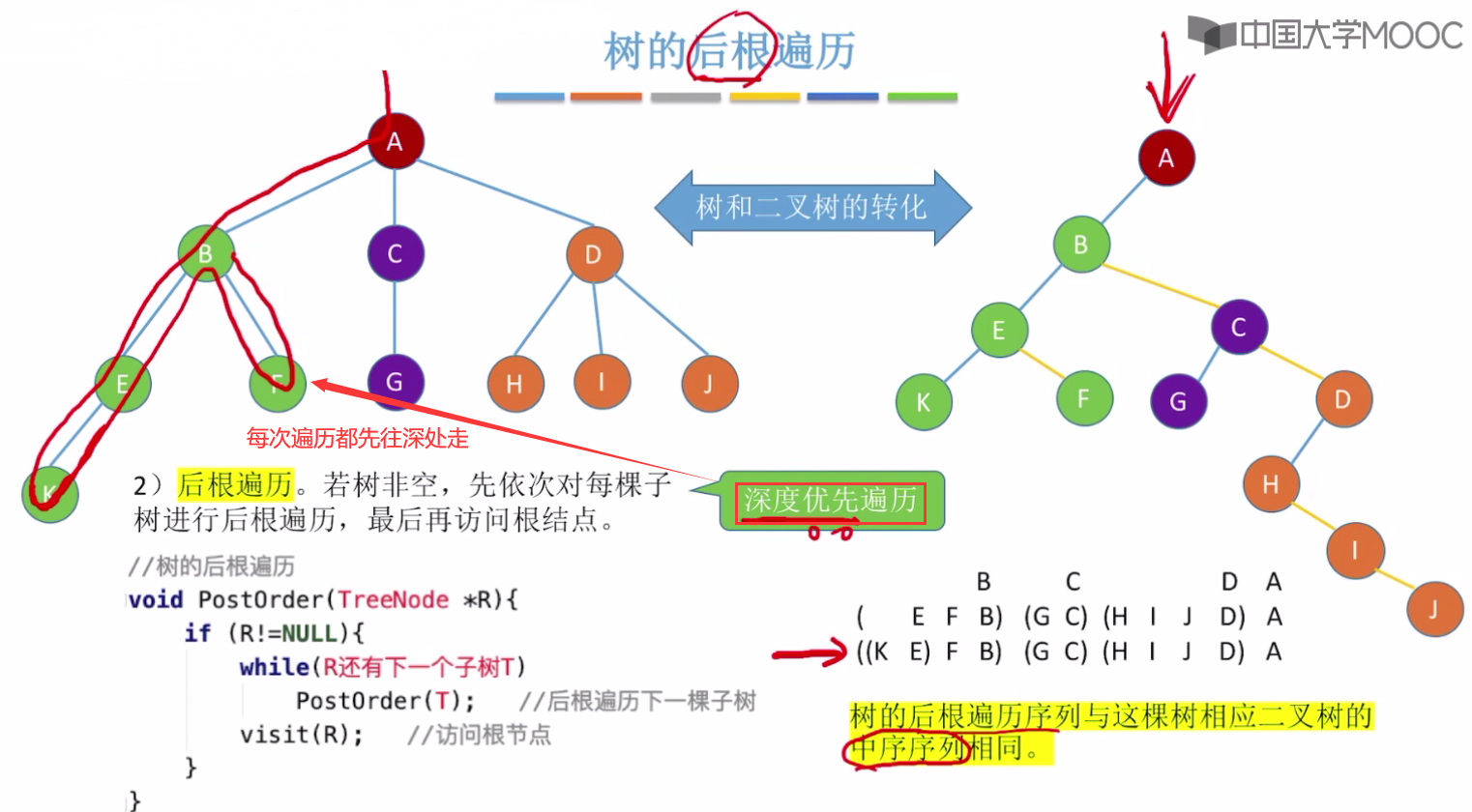
树的后根遍历
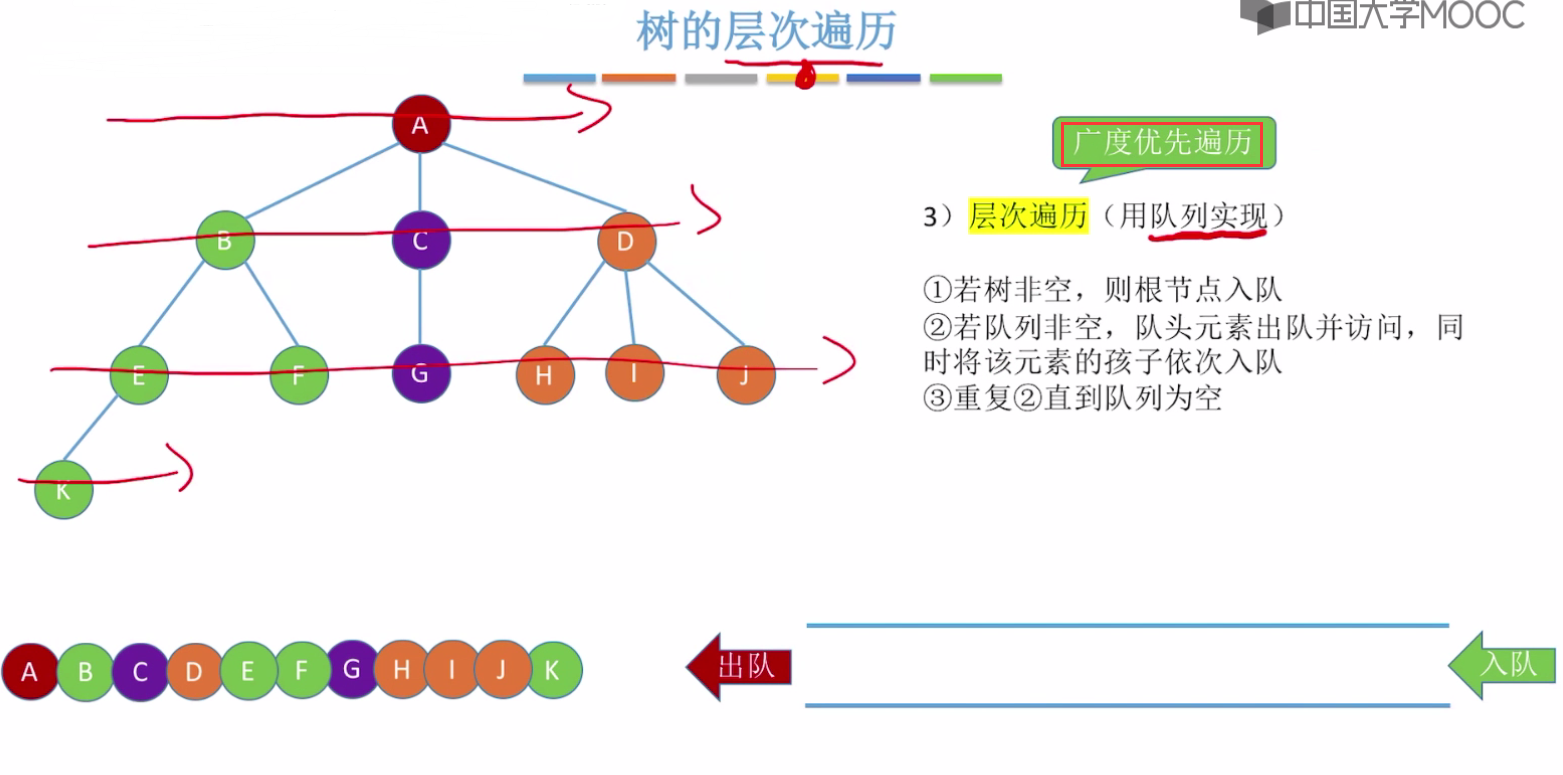
树的层次遍历
森林的遍历
森林的先序遍历
第一种方法
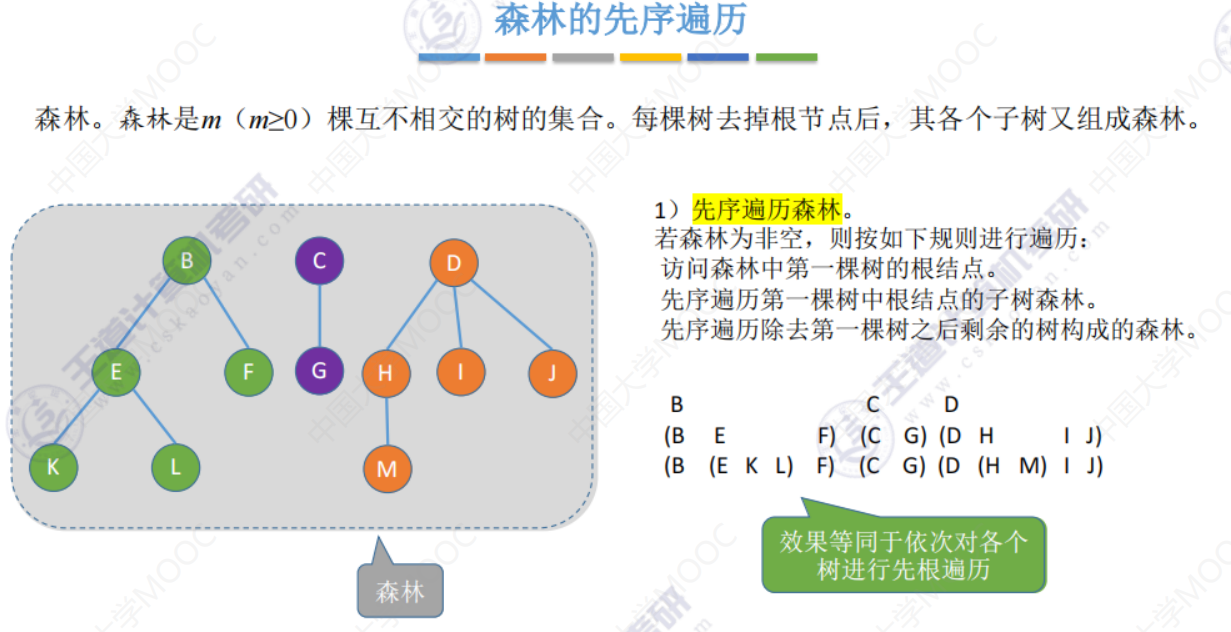
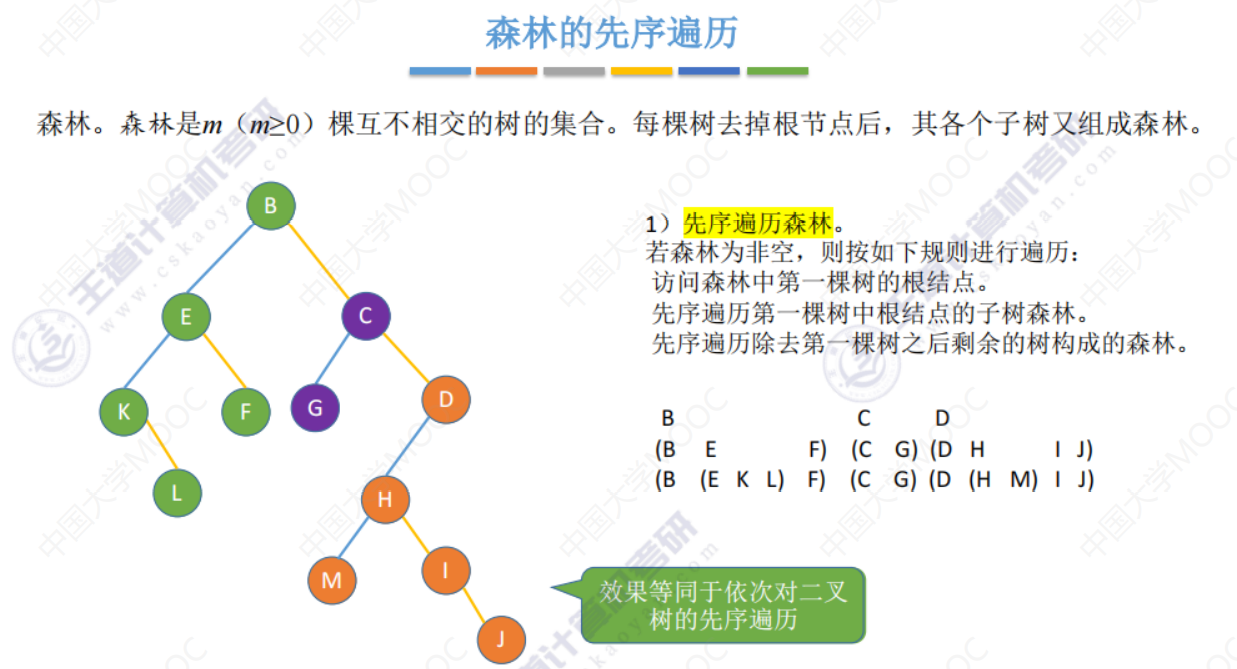
第二种方法
通过孩子兄弟表示法 转化为二叉树(左孩子右兄弟)
森林的中序遍历
第一种方法
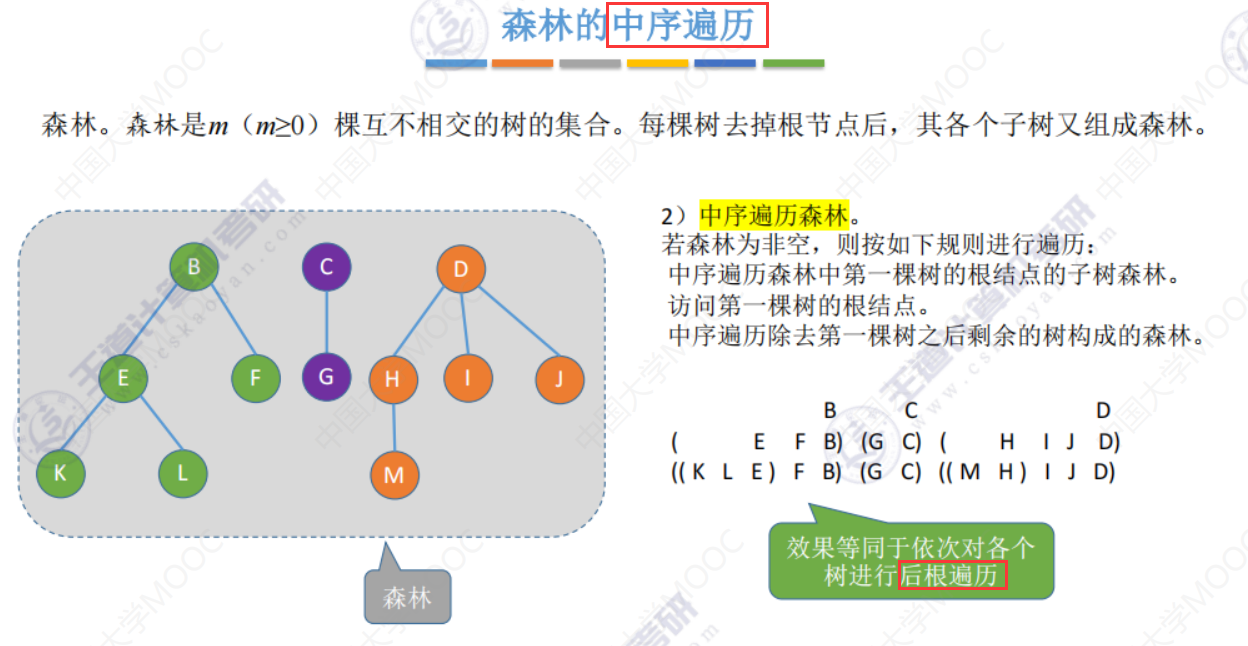
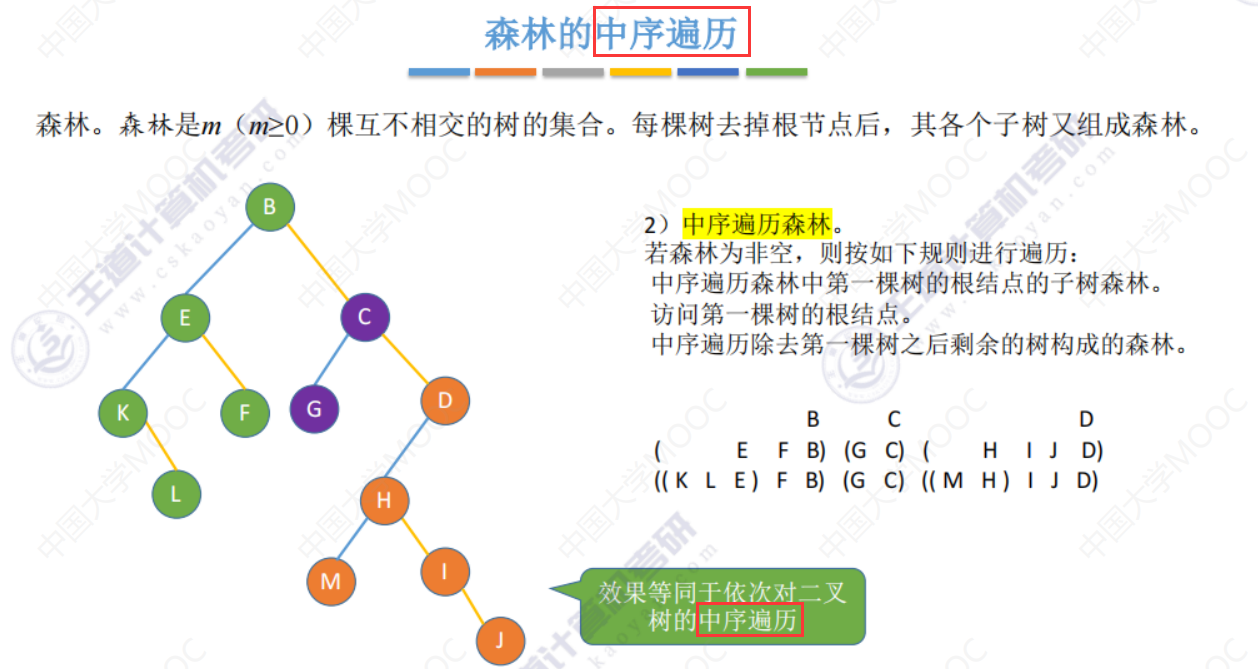
第二种方法
通过孩子兄弟表示法 转化为二叉树(左孩子右兄弟)
总结
森林转化为树后,森林的中序遍历转化为树的后根遍历;
森林转化为二叉树后,森林的中序遍历转化为二叉树的中序遍历。

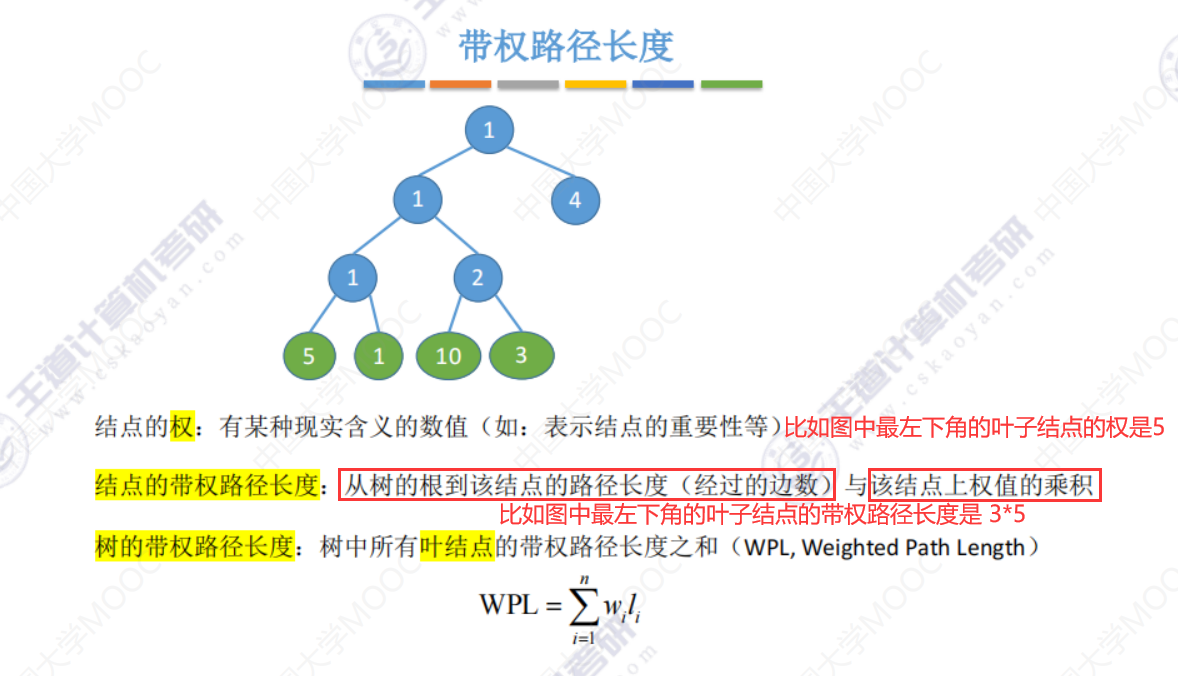
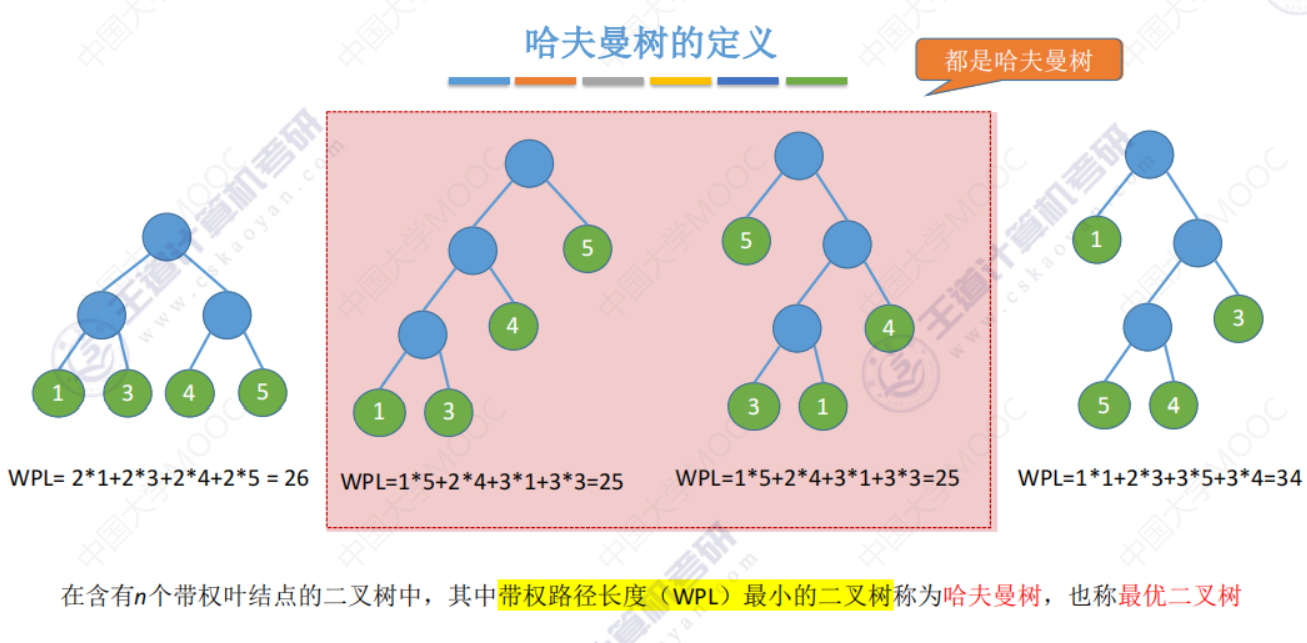
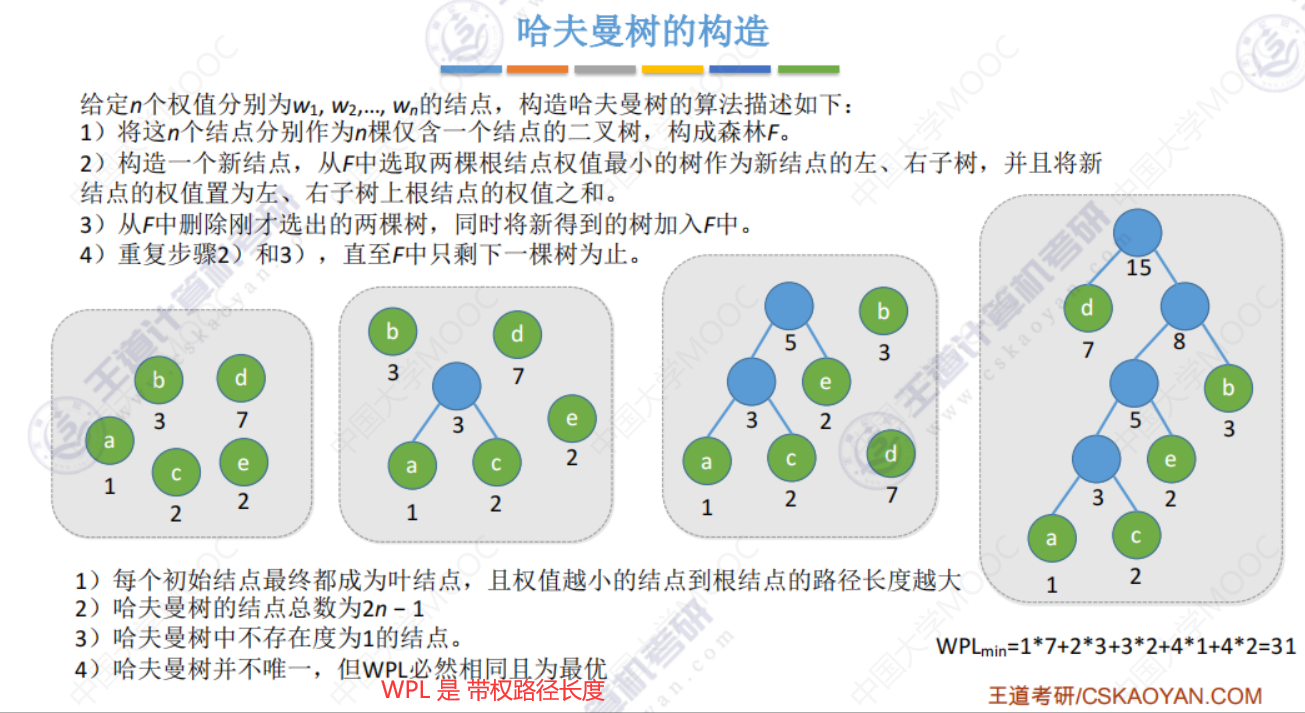
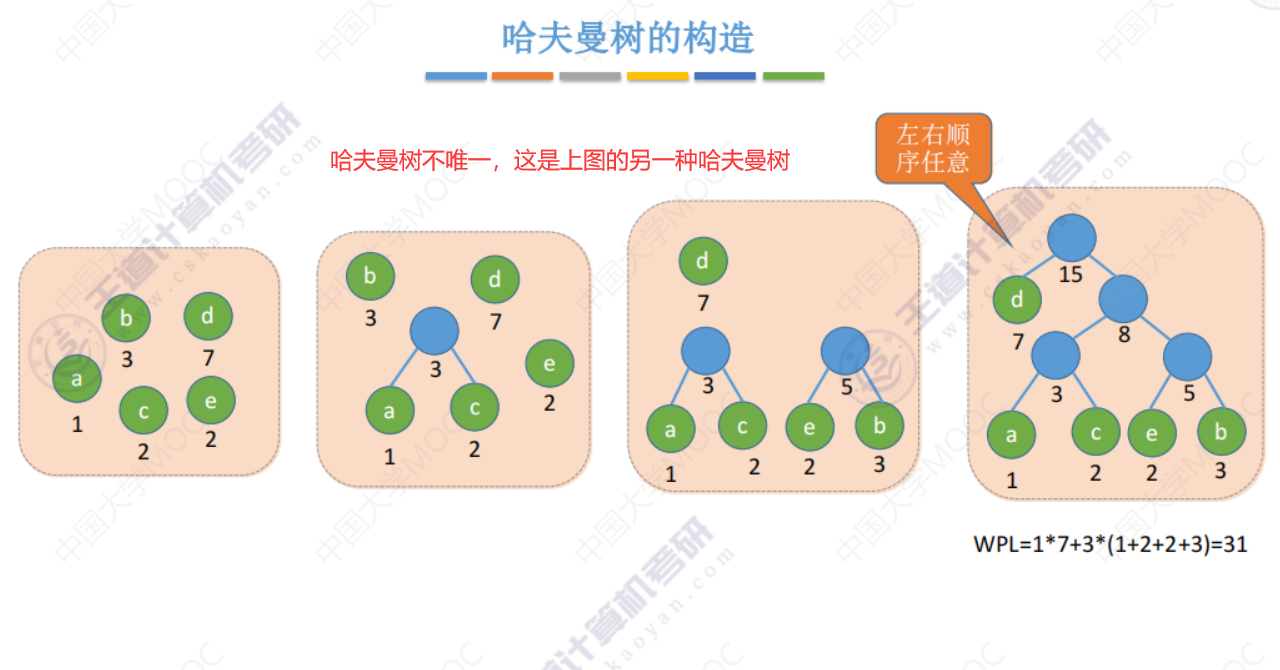
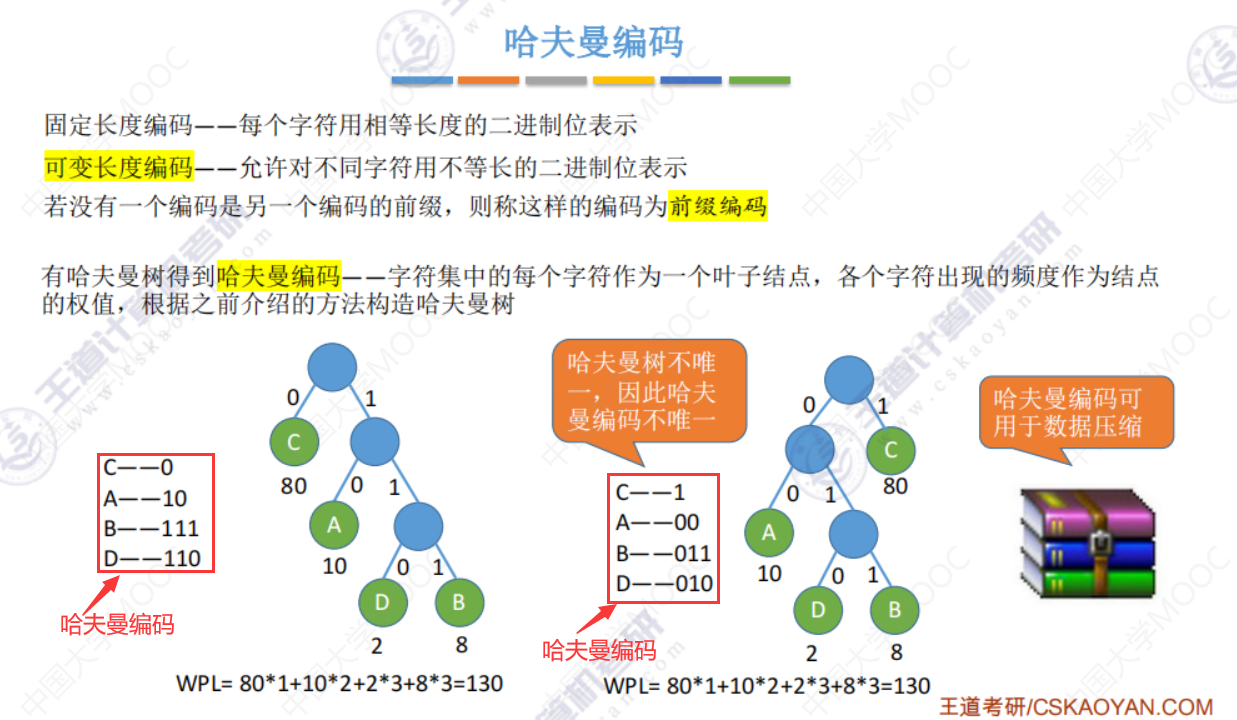
5.5-1 哈夫曼树
哈夫曼树
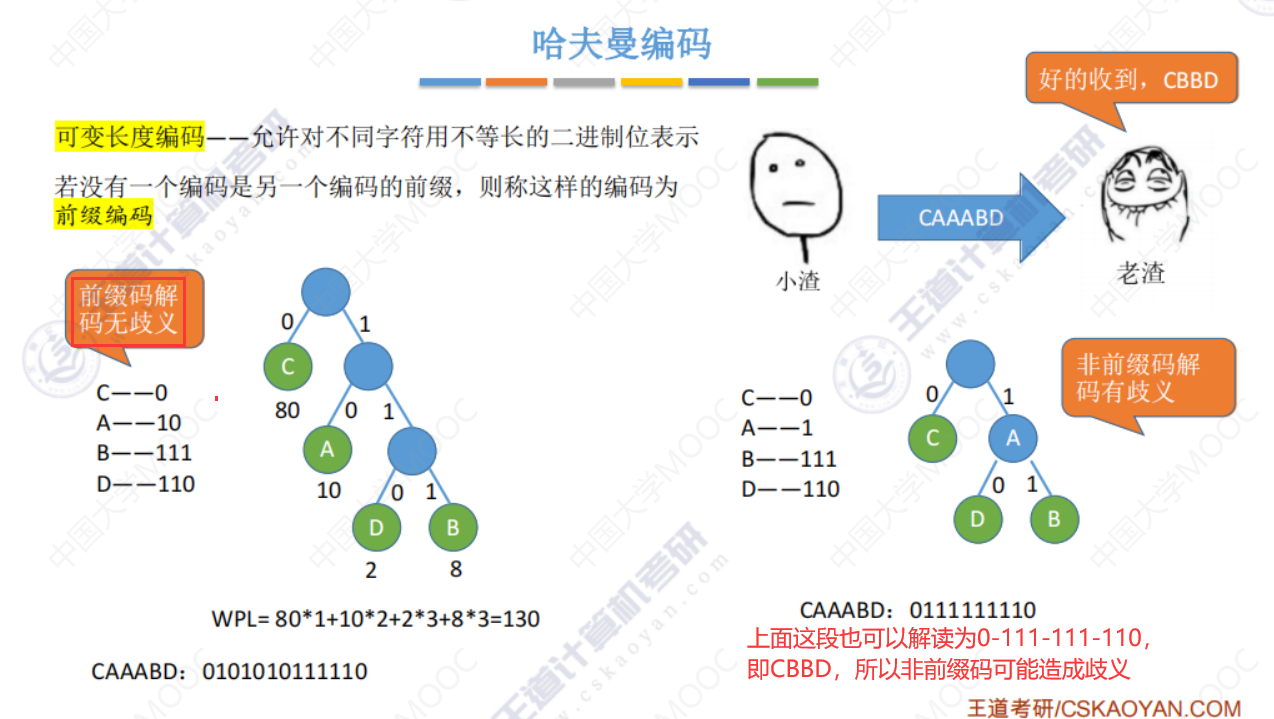
哈夫曼编码
利用 可变长度编码 可以压缩数据,用更少的比特表示同样多的数据
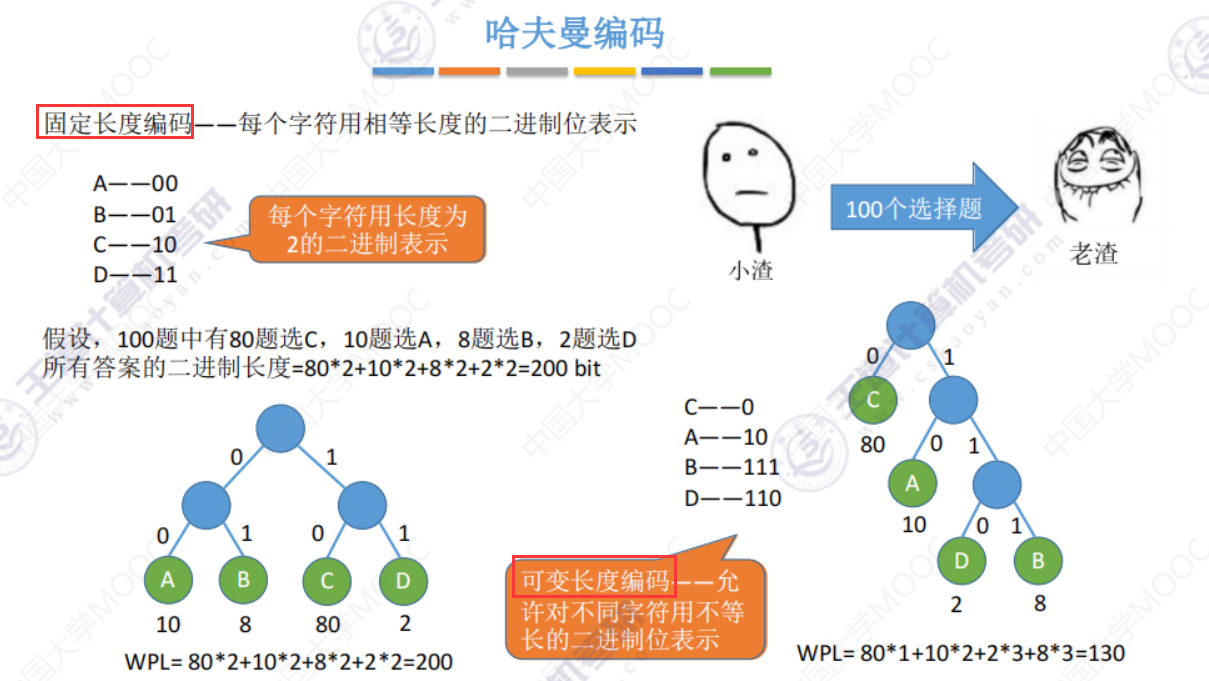
如果A不用10来编码,用1来编码,那么A就不是叶子节点了,会造成解码的误解。如下图右边所示,
比如111不知道是3个A还是1个B了。
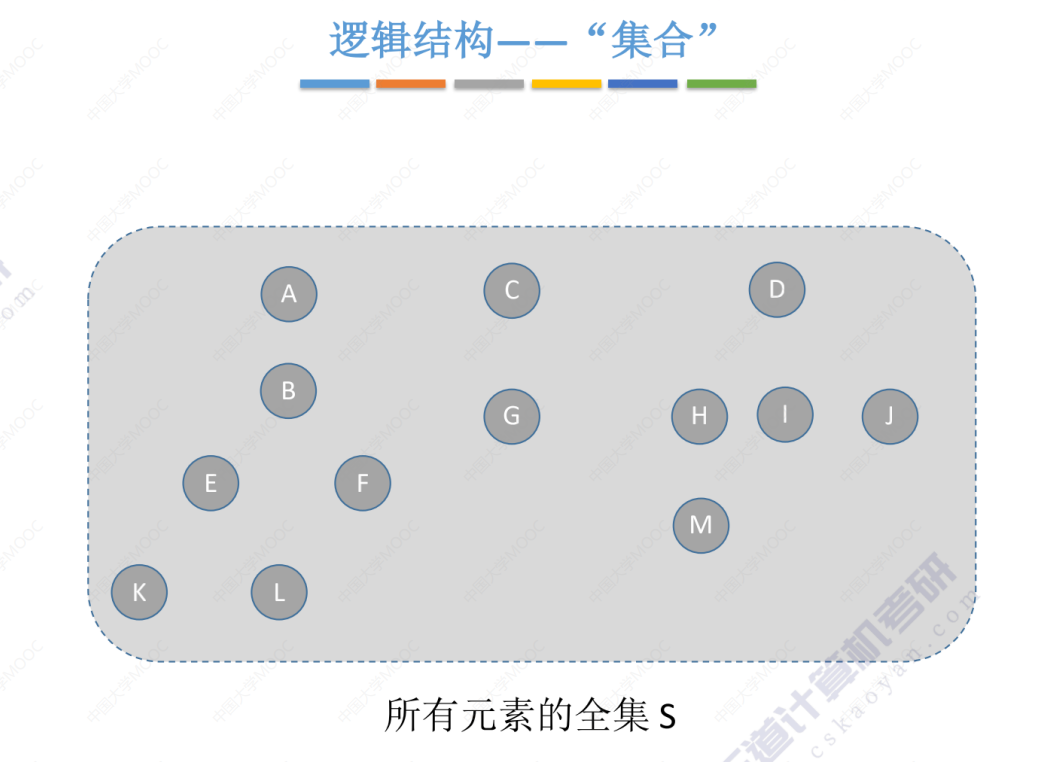
5.5-2 并查集
并查集的逻辑结构(本质是一种表示集合的逻辑关系)
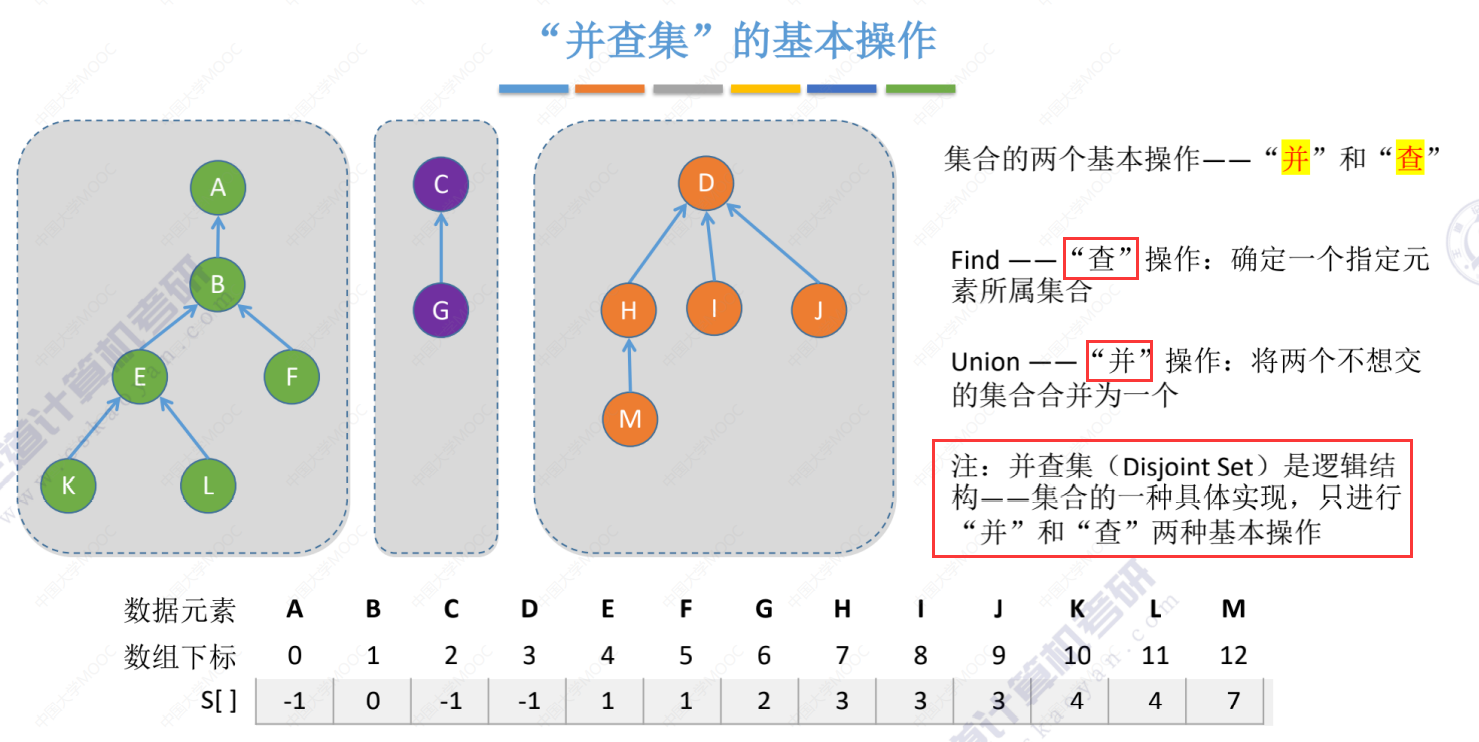
并查集本质上是表示一种集合的逻辑关系,而这个集合要实现的基本操作是并和查。
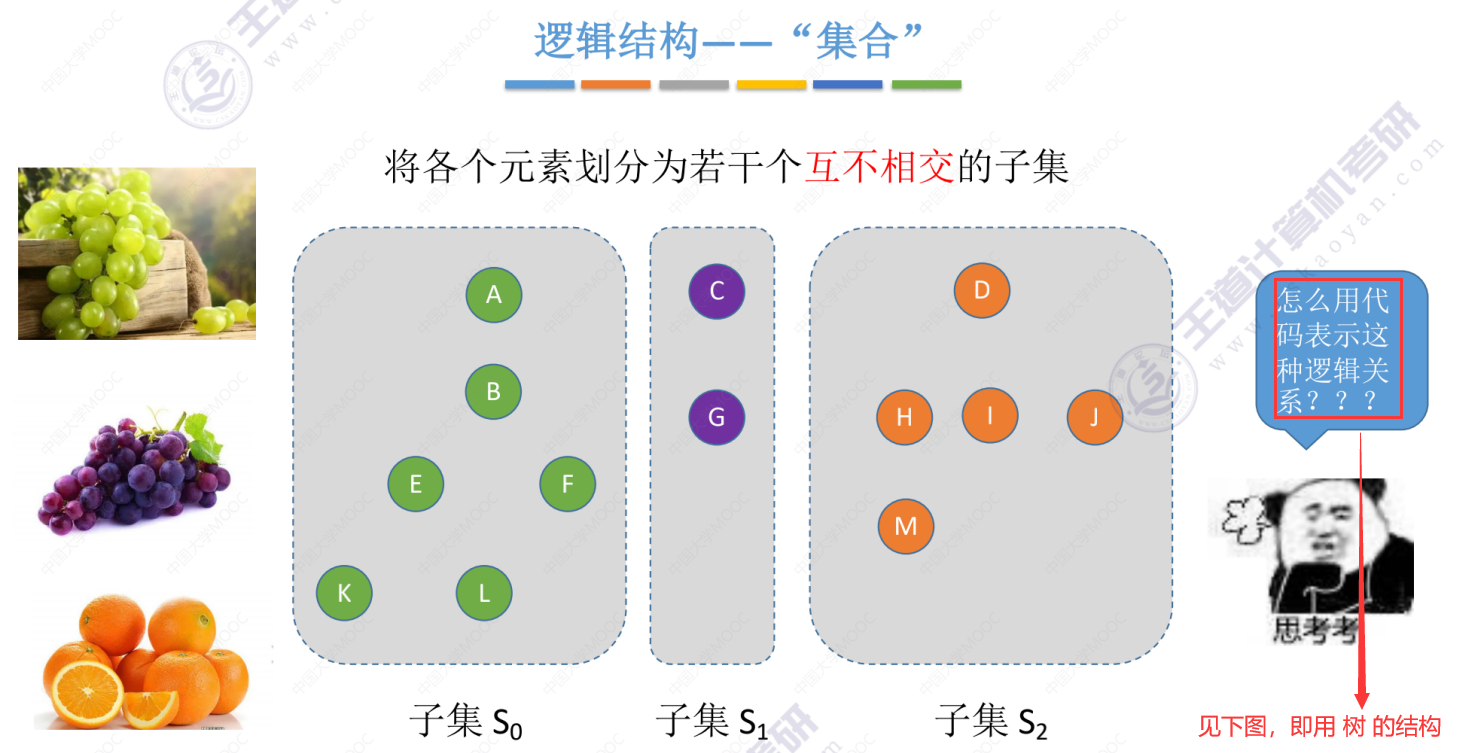
查
并
双亲表示法更有效:
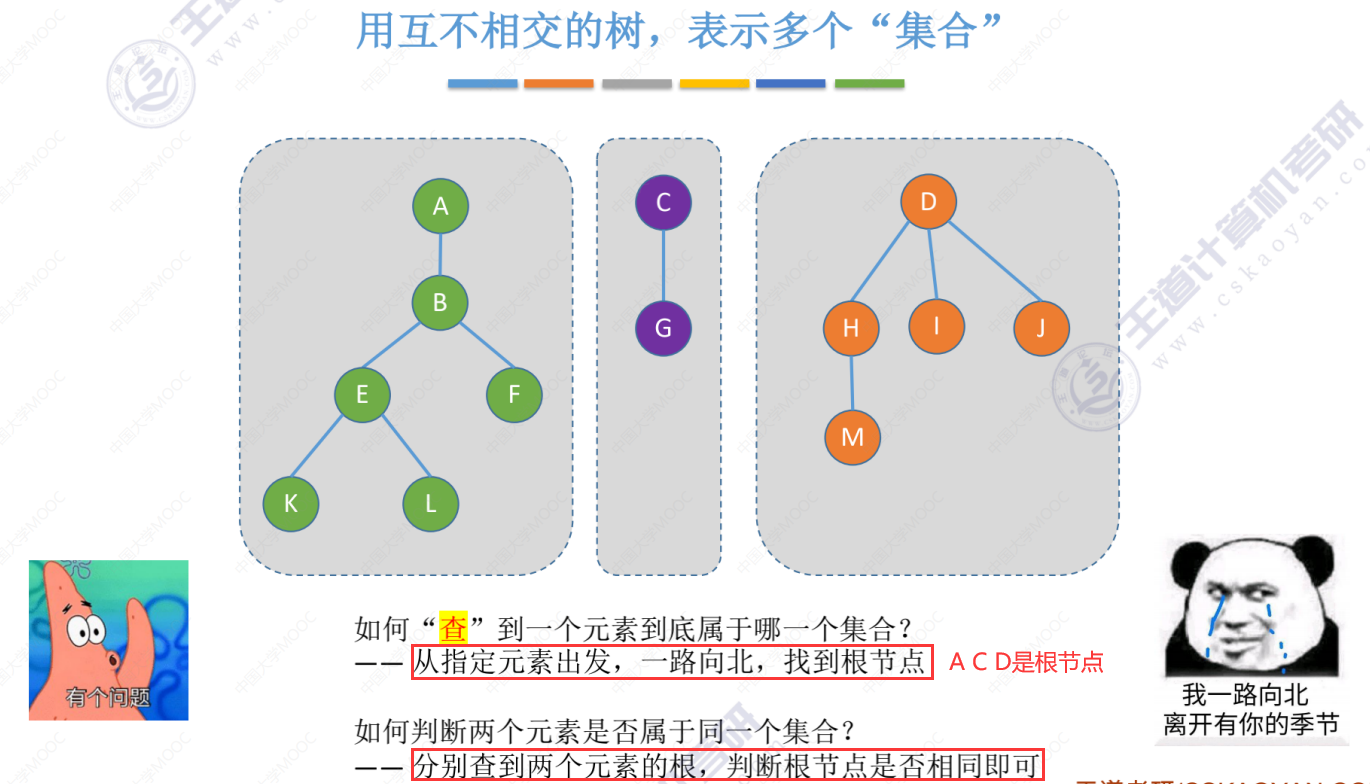
查就是一路向上找到根节点,可以通过比较根节点是否相同来判断是否是同一个集合。
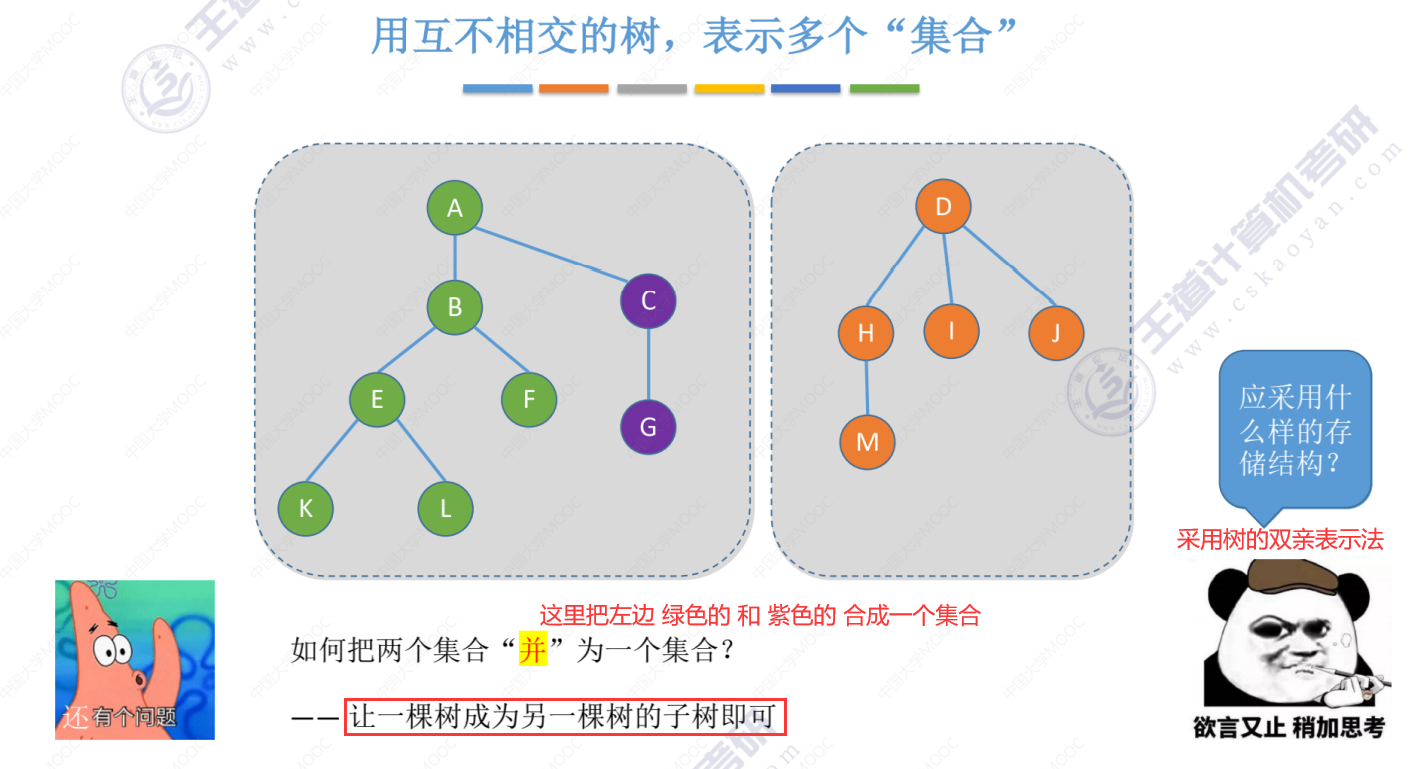
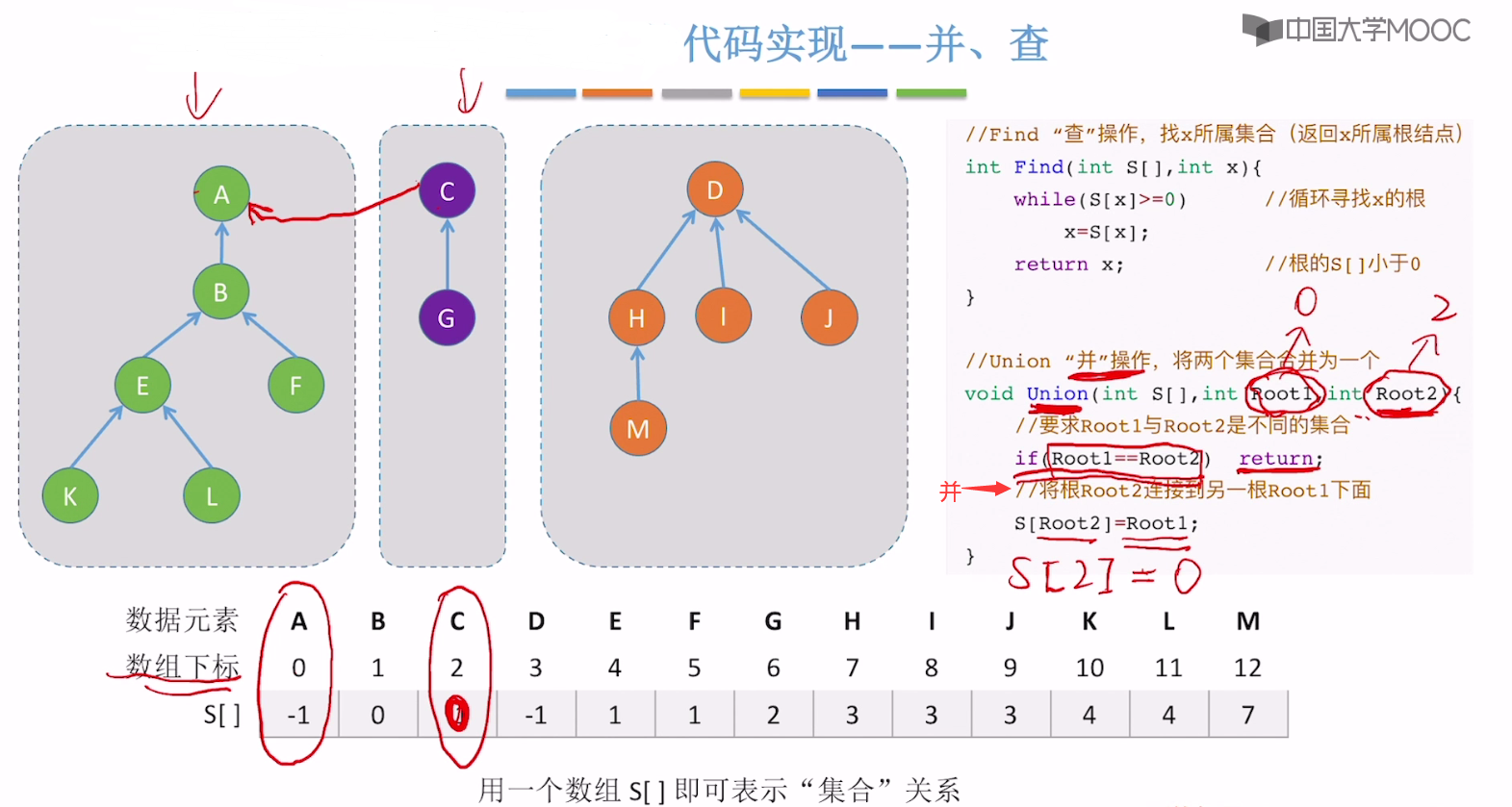
并就是将其中一棵树的根节点指向另一棵树的根节点。
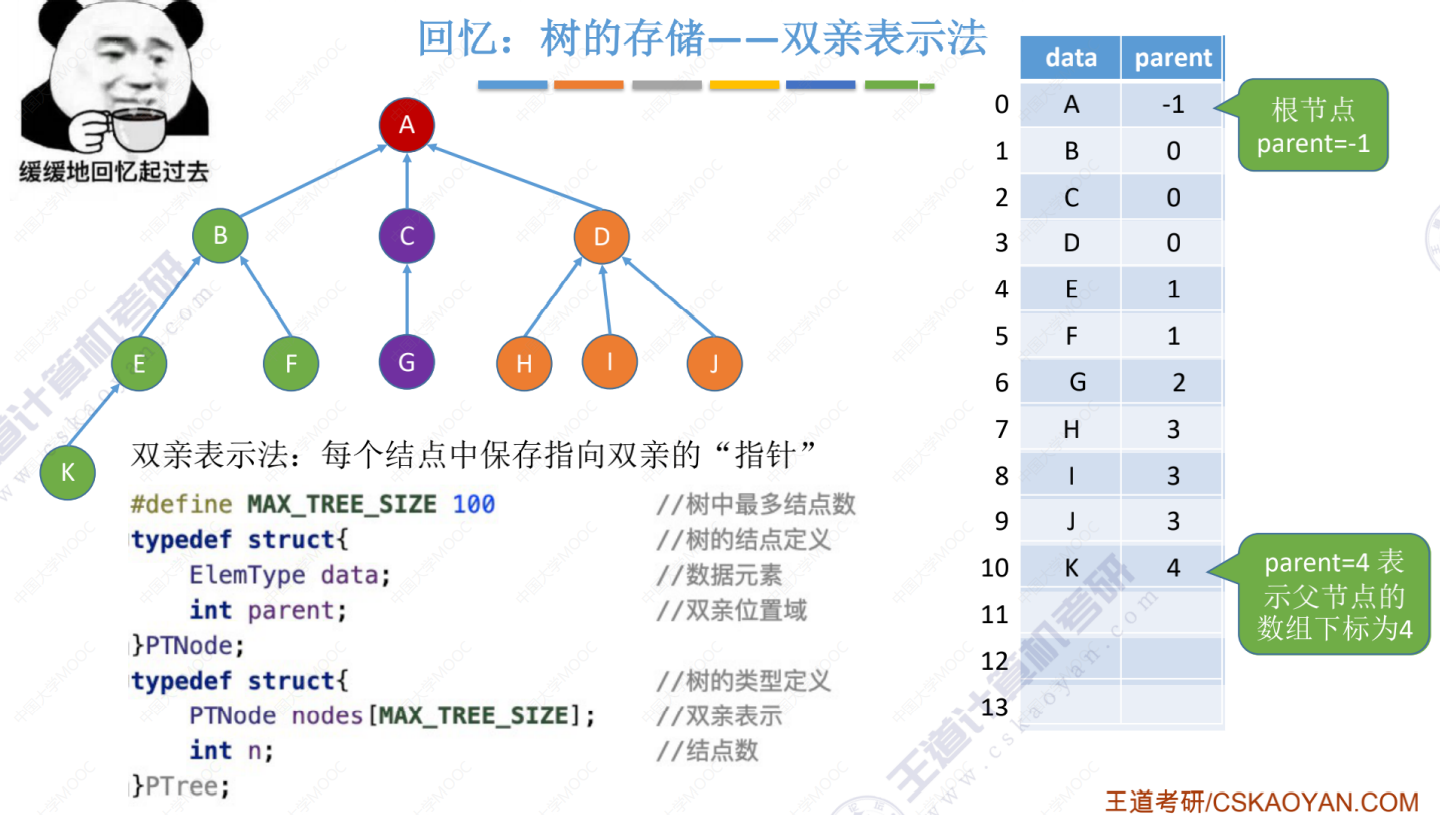
并查集的存储结构(类似双亲表示法,S[]数组中也是存储的其父节点数组下标)
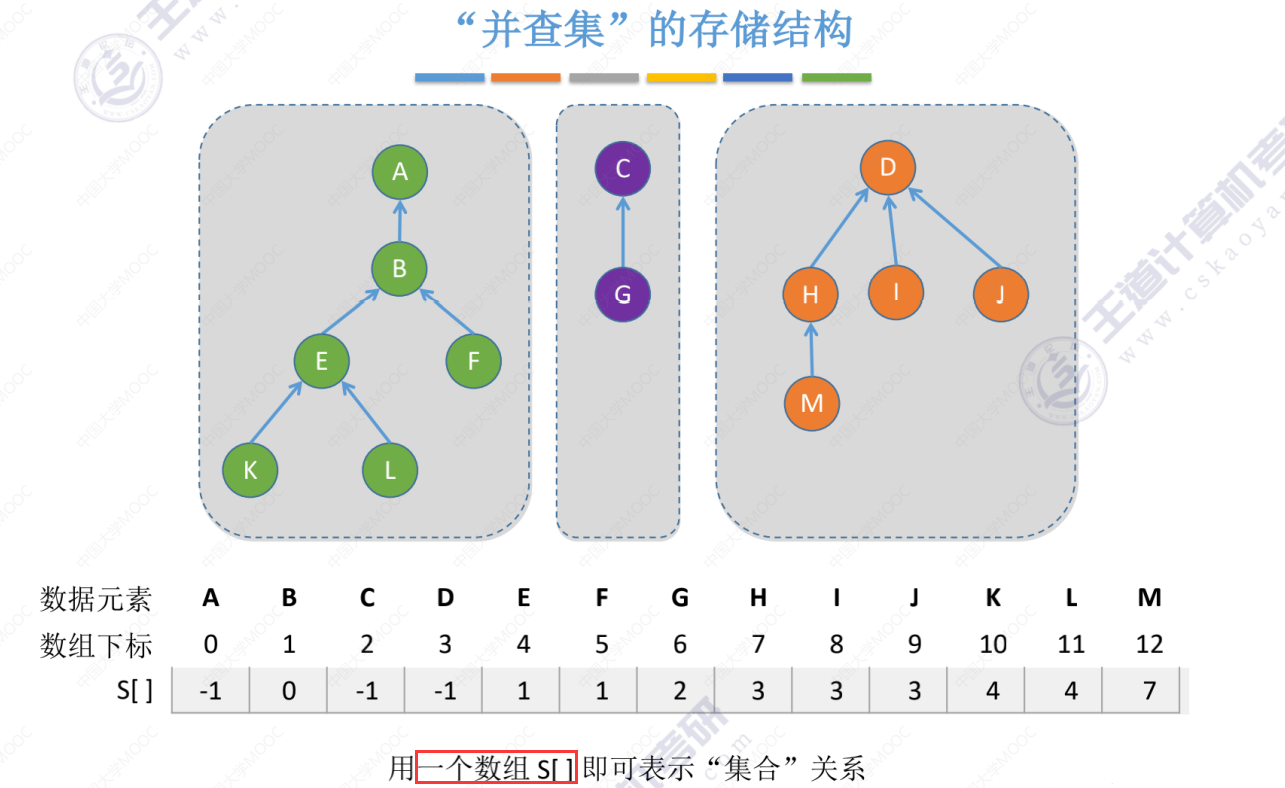
并查集的基本操作(并、查)
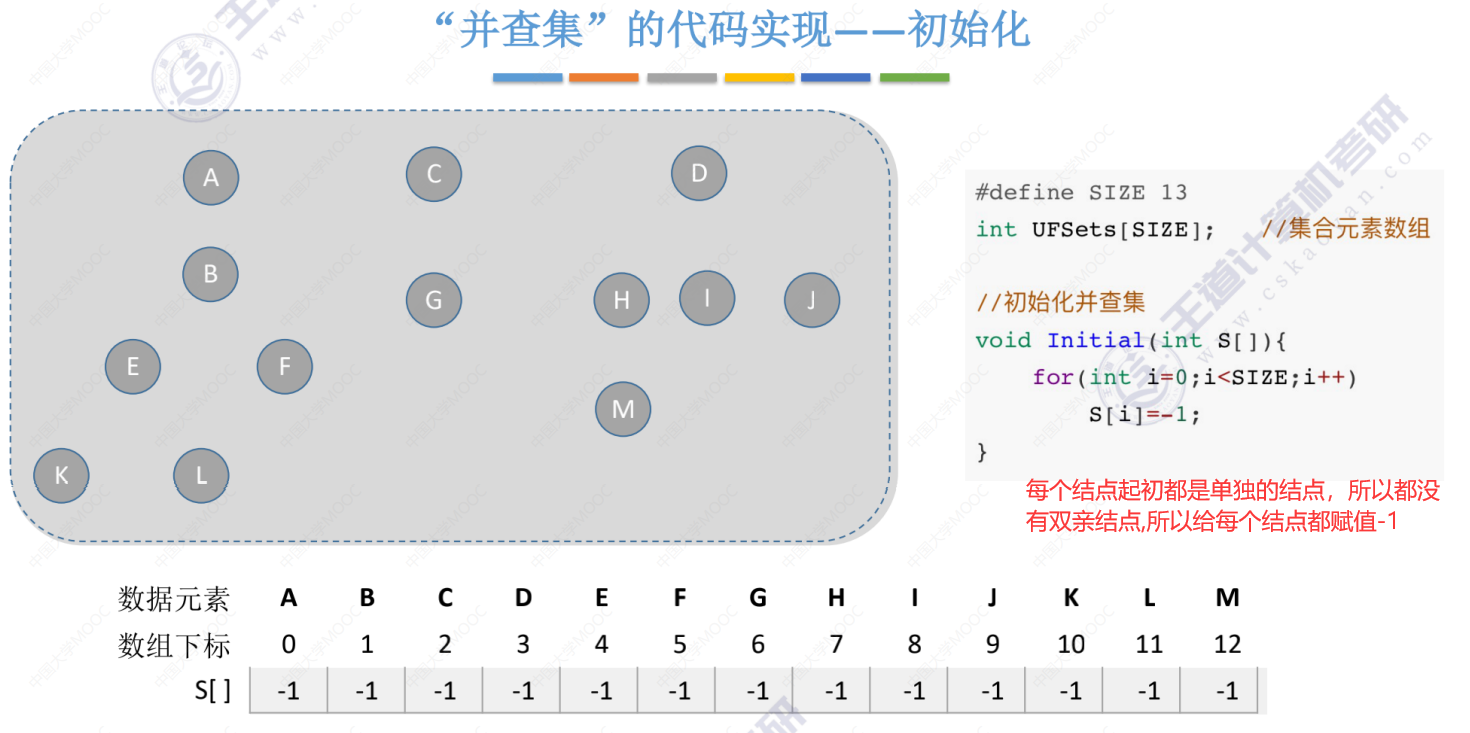
并查集代码的初始化
并查集的 查和并 的代码
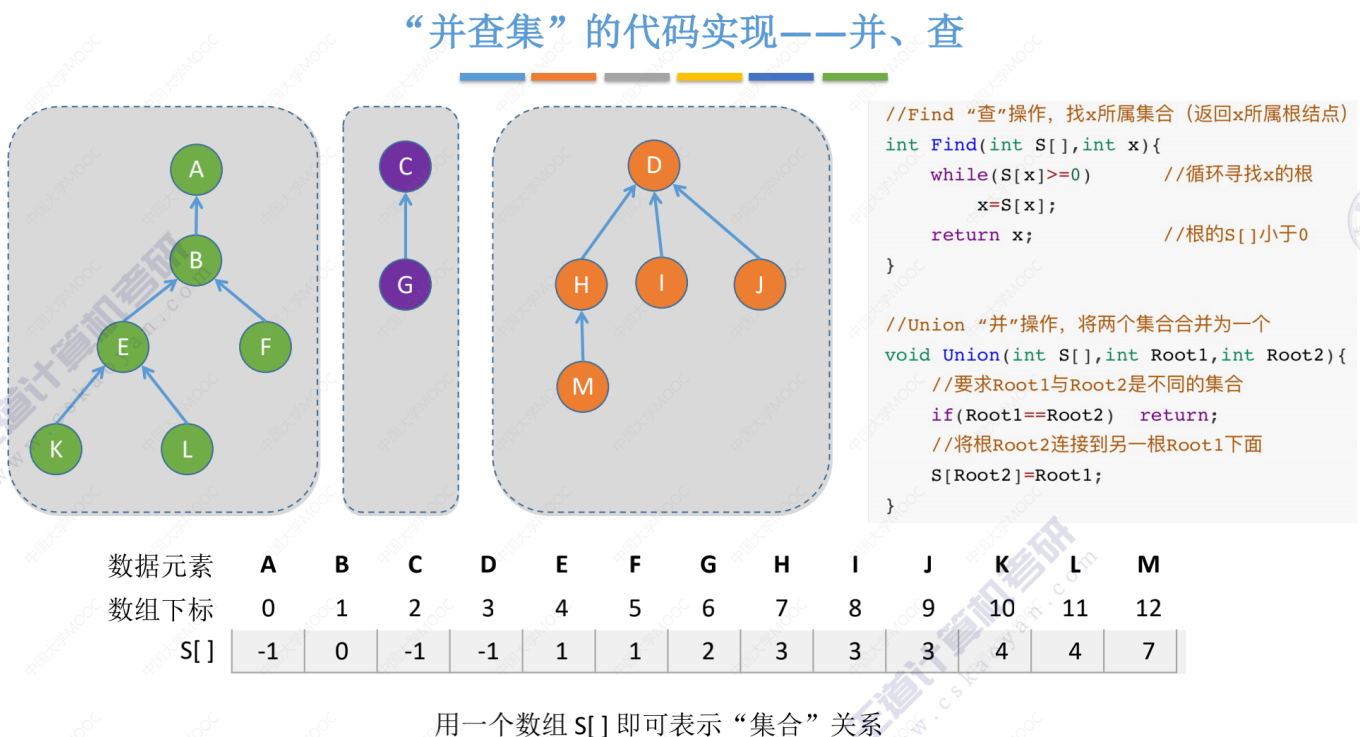
并查集的查的举例演示
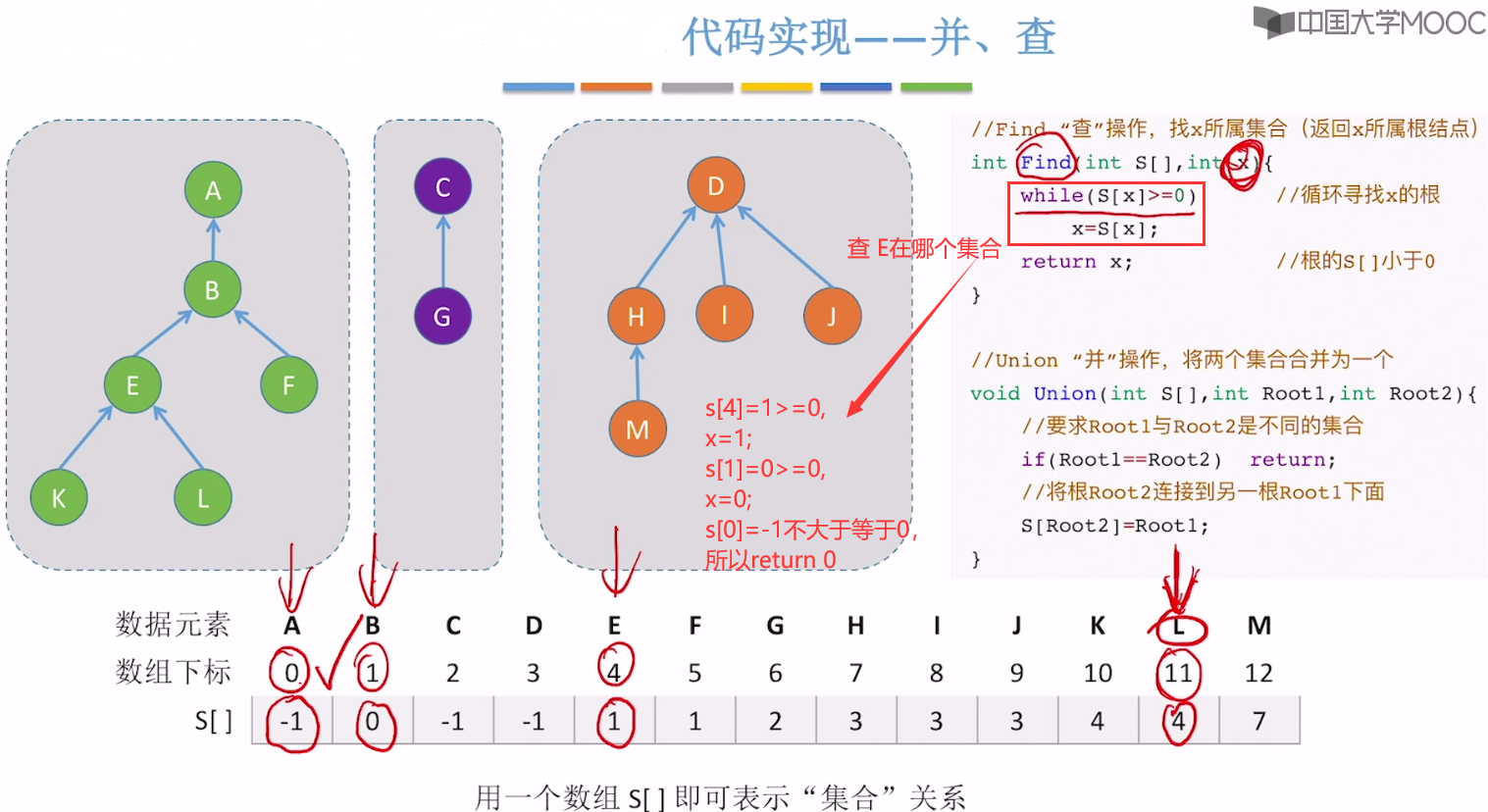
并查集的并的举例演示
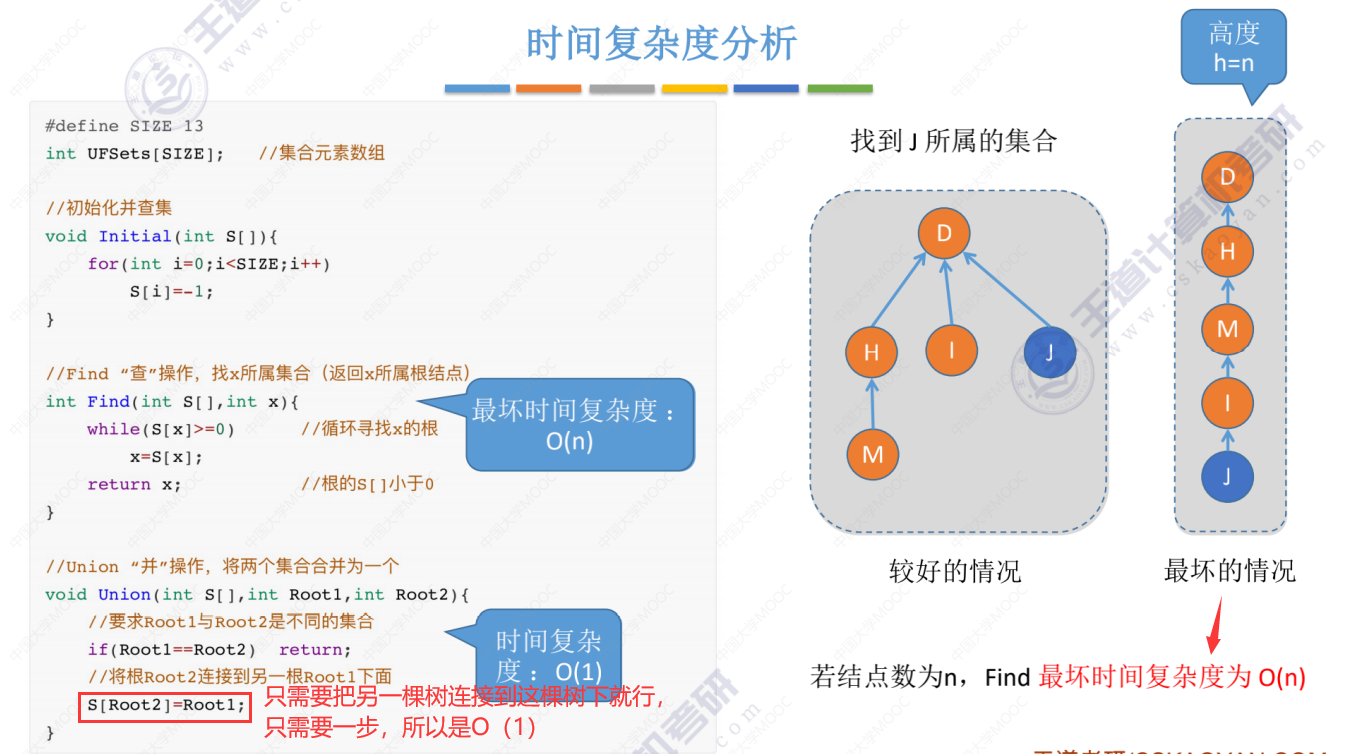
代码的时间复杂度分析
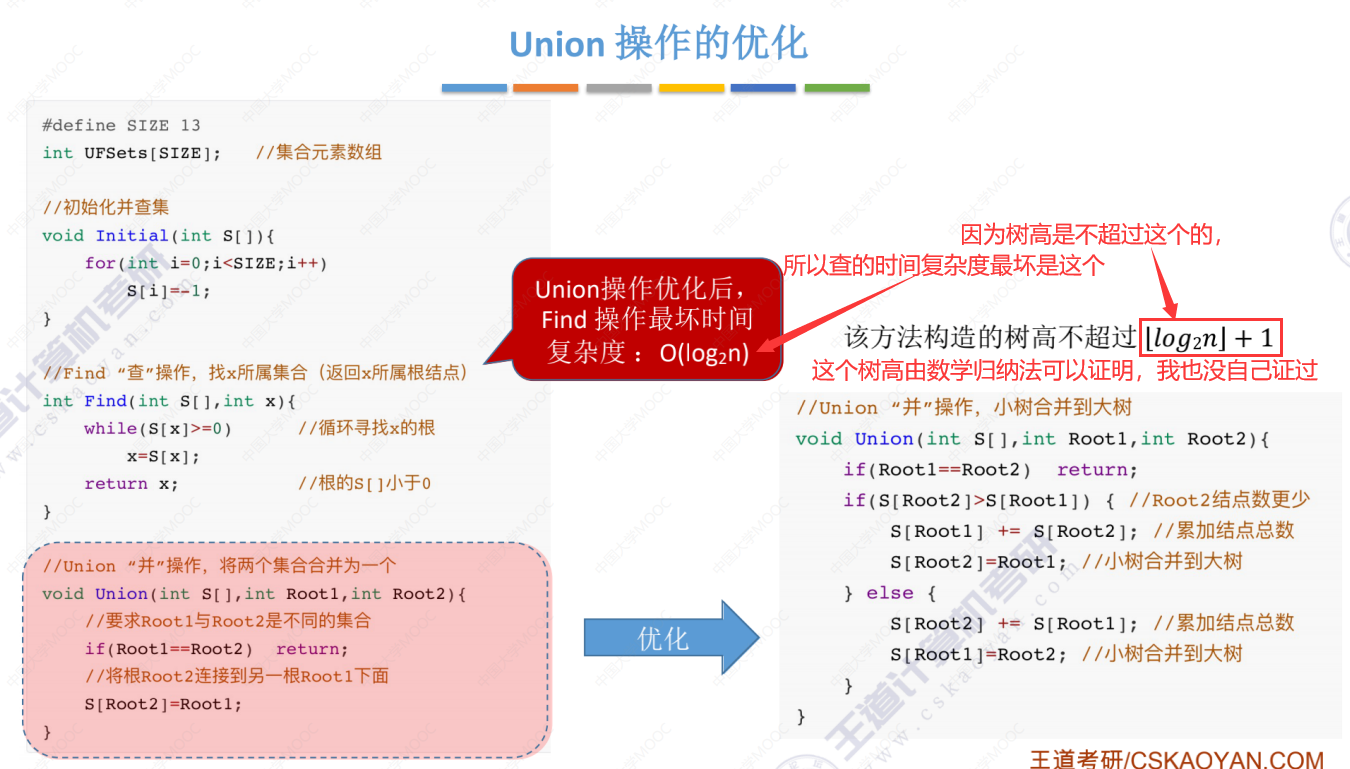
降低时间复杂度的优化思路
上图说明要想时间复杂度低,树就不能太高太长,
优化思路:在每次Union操作构建树的时候,尽可能让树不长高高
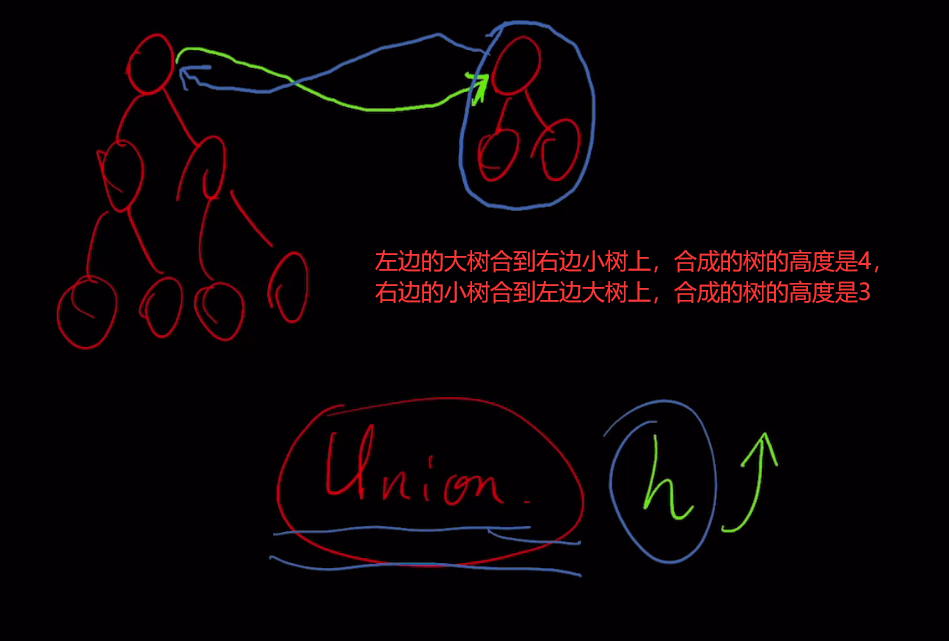
优化过程
三棵树
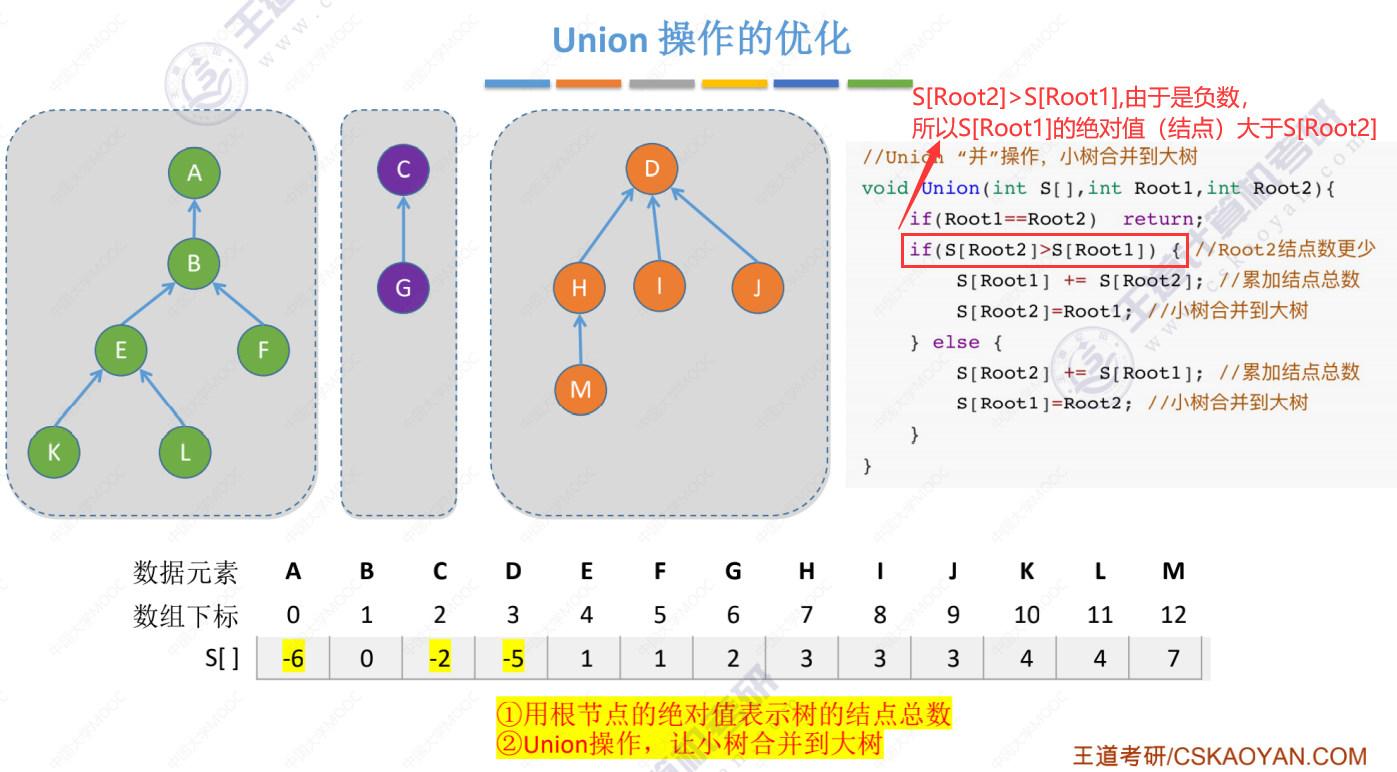
前两棵树合并
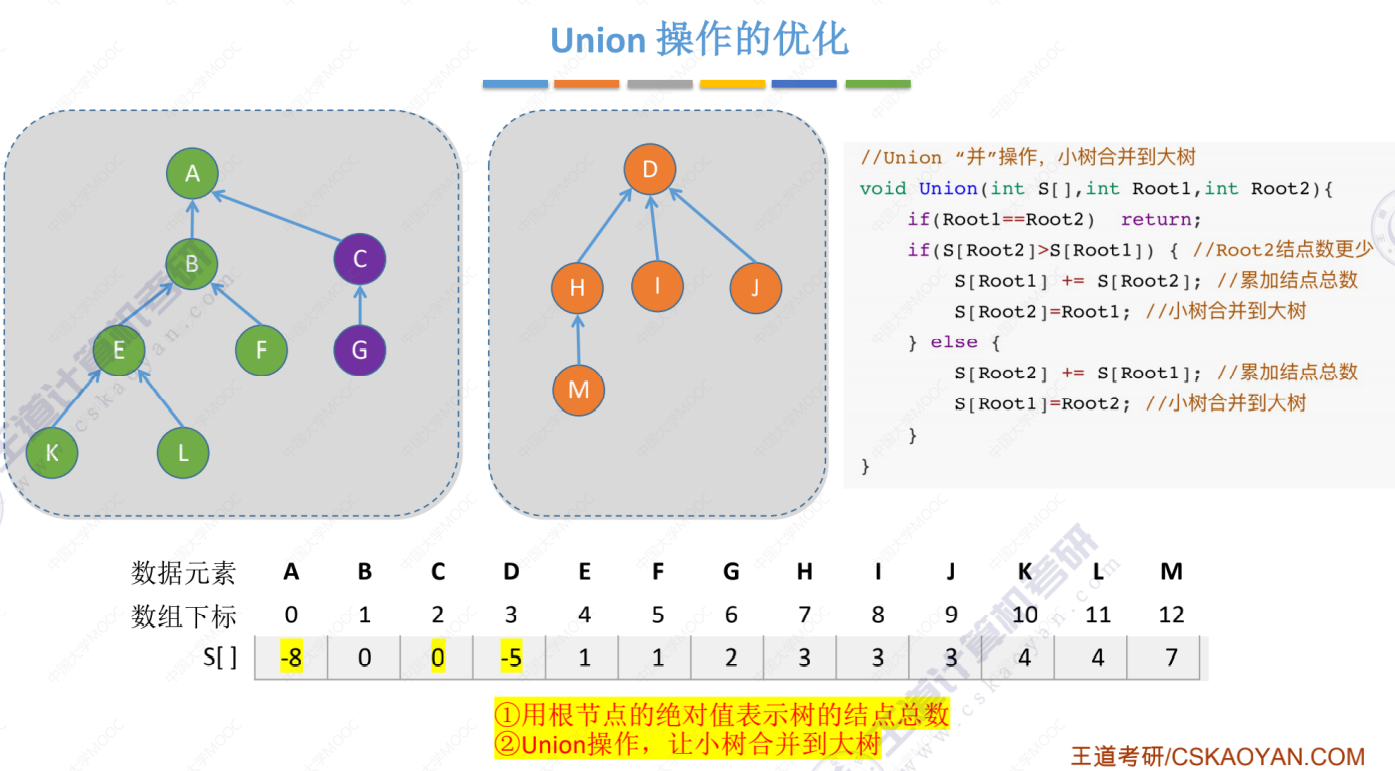
三棵树全部合并
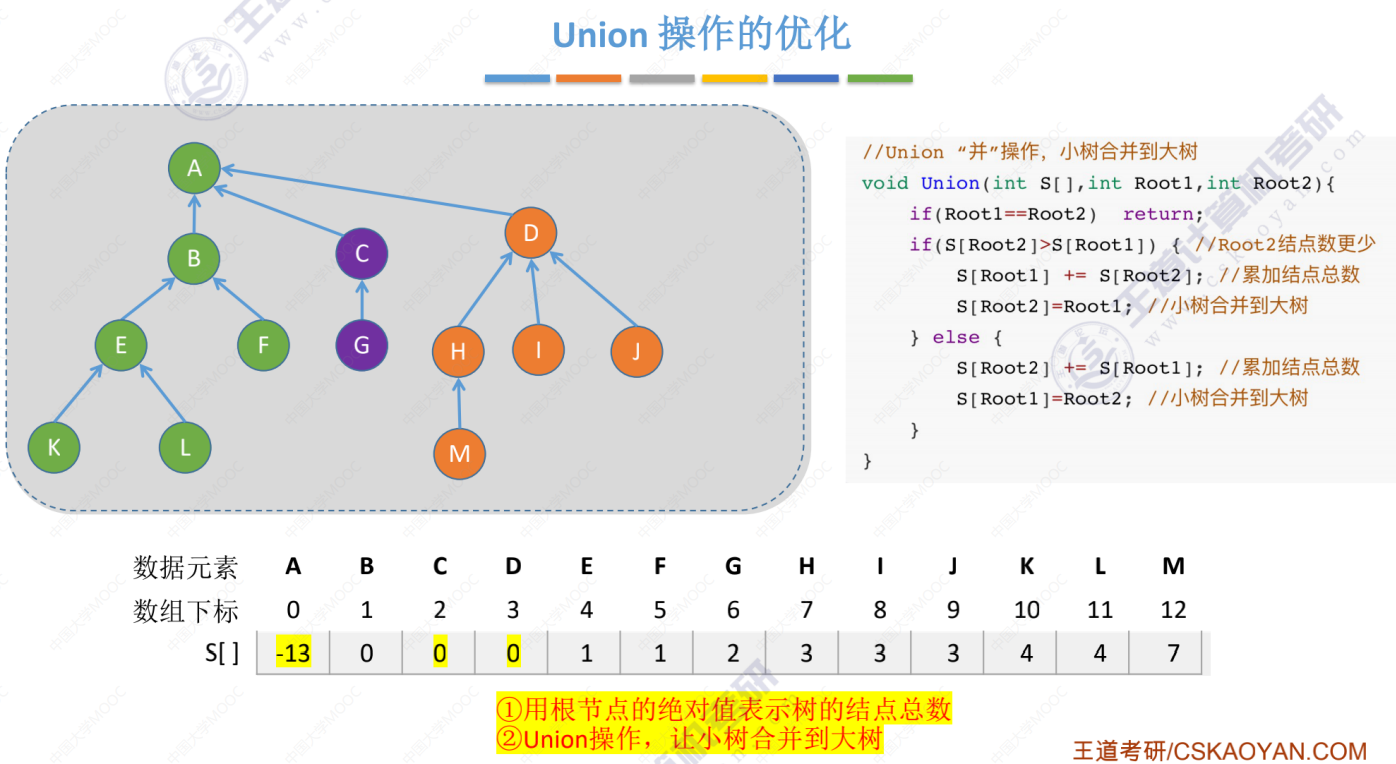
优化后的时间复杂度
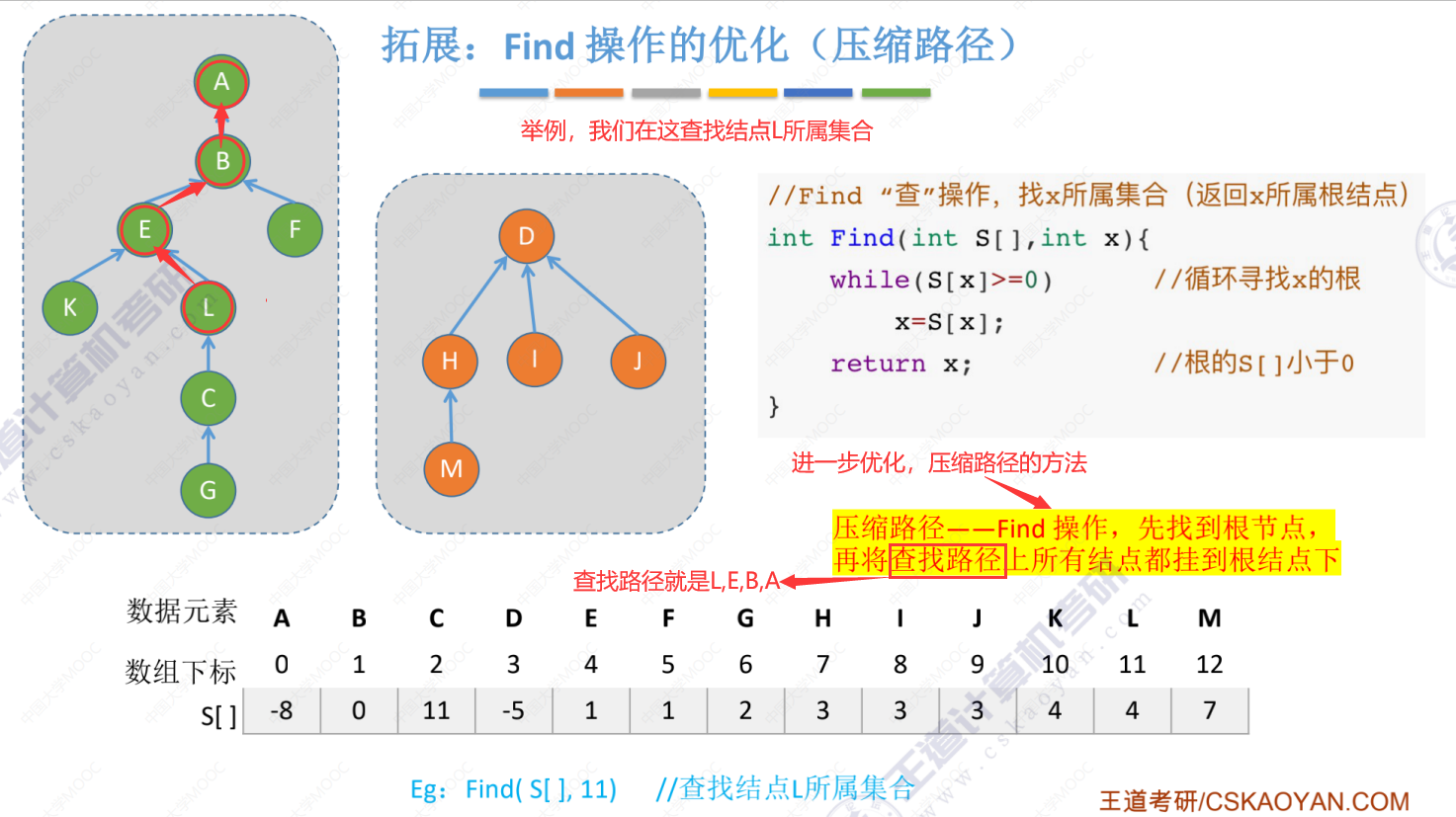
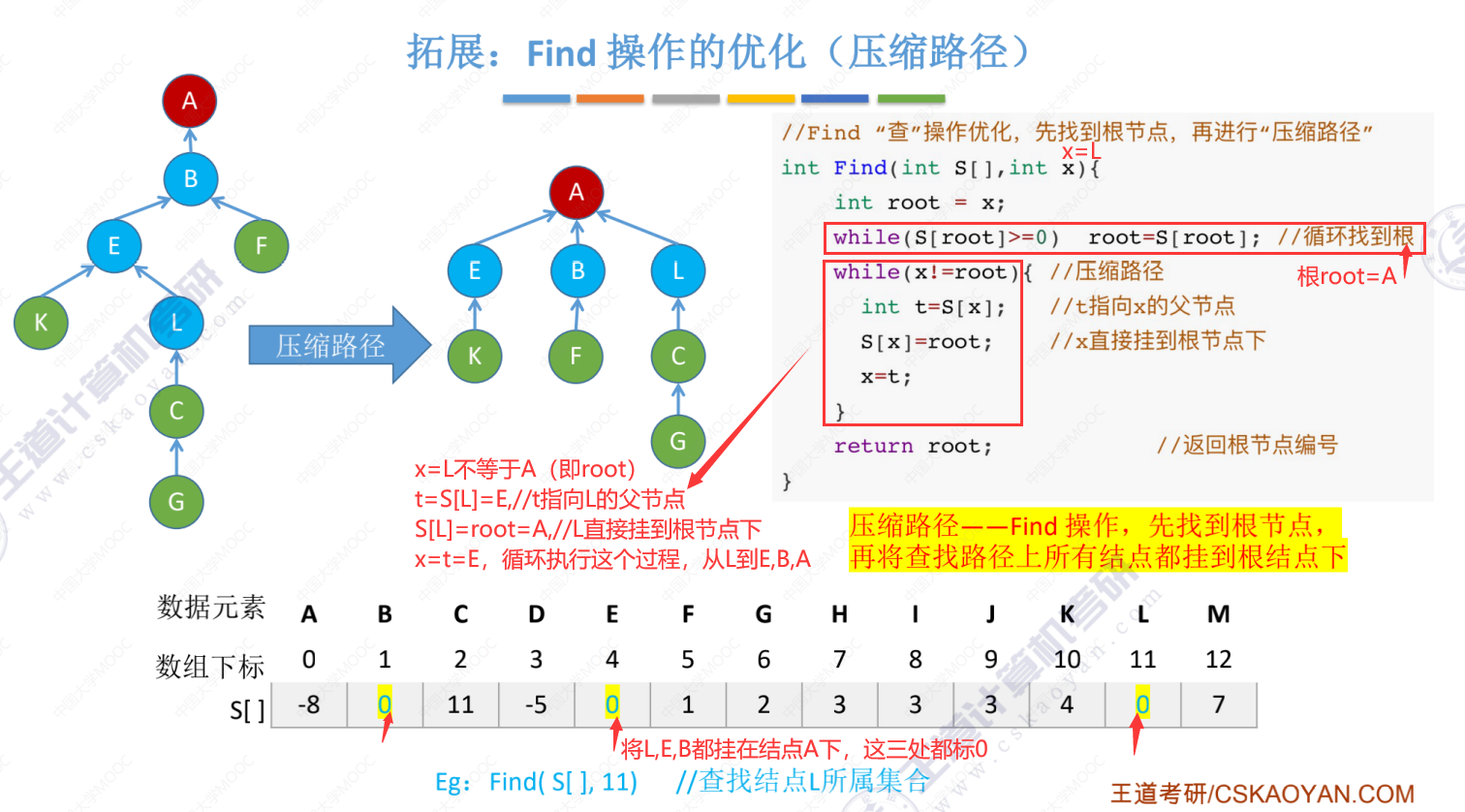
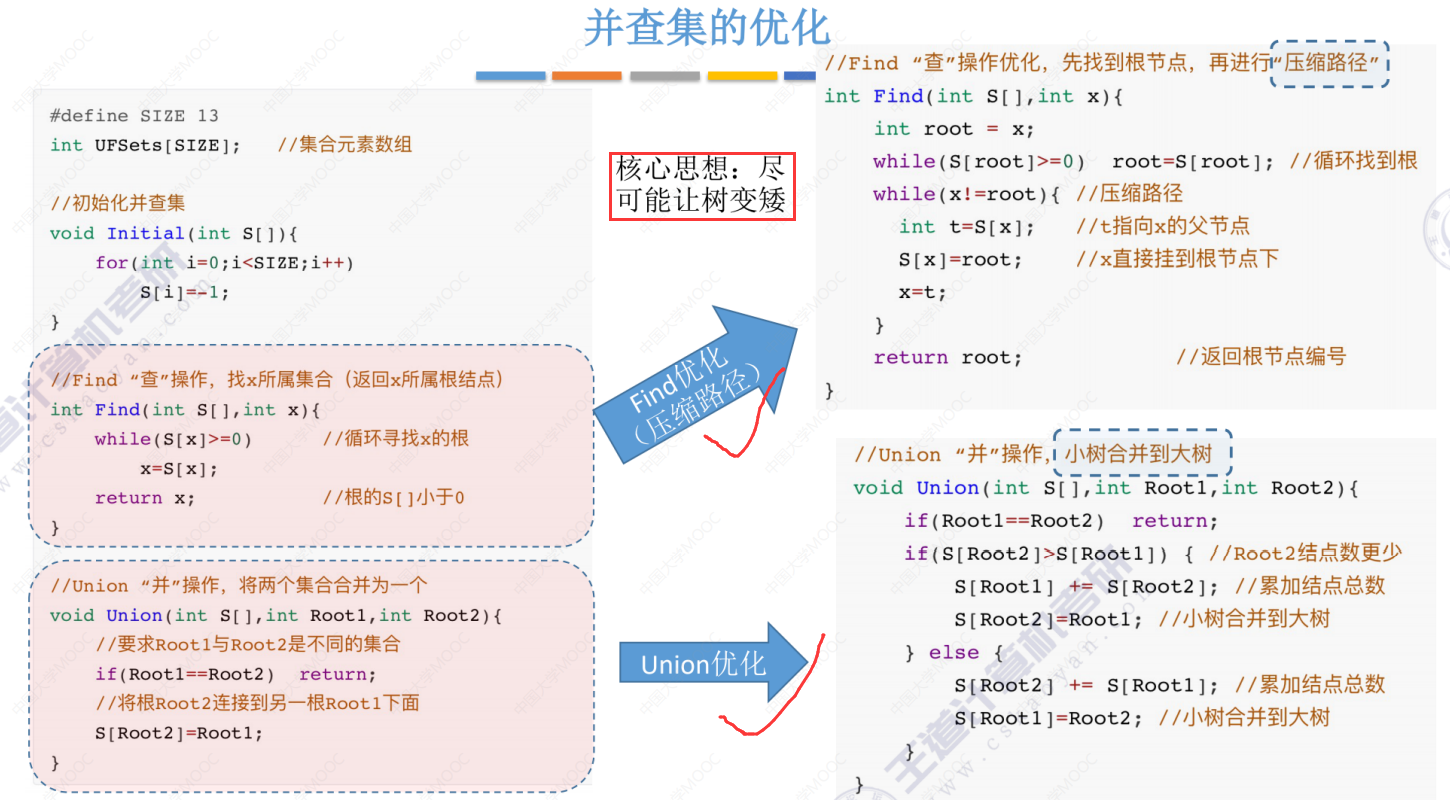
5.5-3 并查集的进一步优化(Find操作的优化(压缩路径))
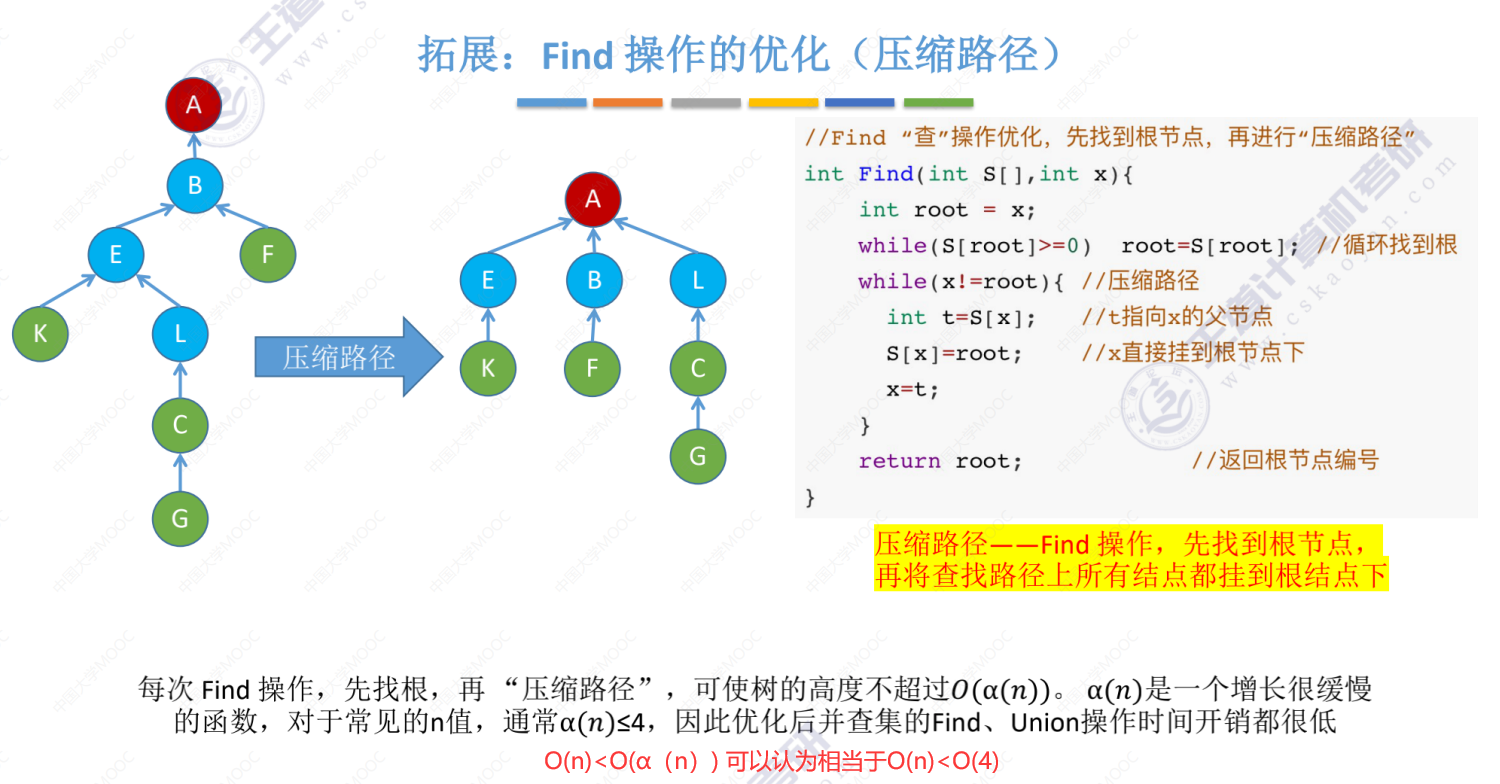
并查集的优化总结















 3338
3338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









