






1.什么是垃圾对象?
1.引用计数法:
使用引用计数法的会产生循环引用的情况, 但是理论上应该被回收的, 但是有没有对象可以对他进行调用., 引用计数法默认引用还是大于0 的,不会被回收.
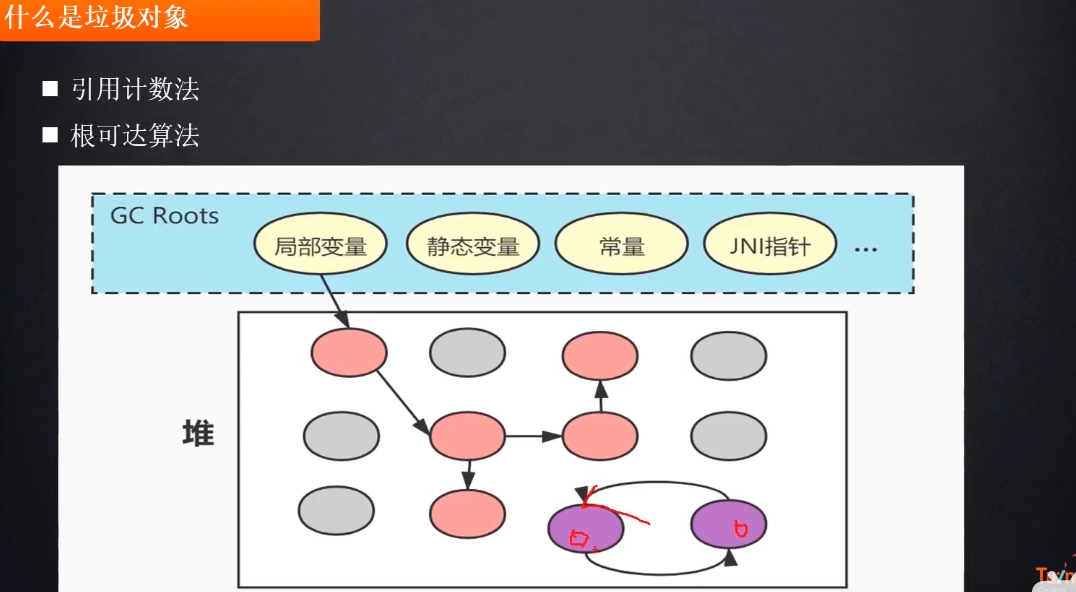
2.根可达算法
gcroots 定义的 局部变量, 静态变量, 常量, jni指针等等 这些都是
然后从这写变量中间找可达性关系. 如图中所示的: 其中箭号可达的就是不能回收的, 他就是一种链路关系图
java中JVM使用的就是根可达算法
2.垃圾回收算法
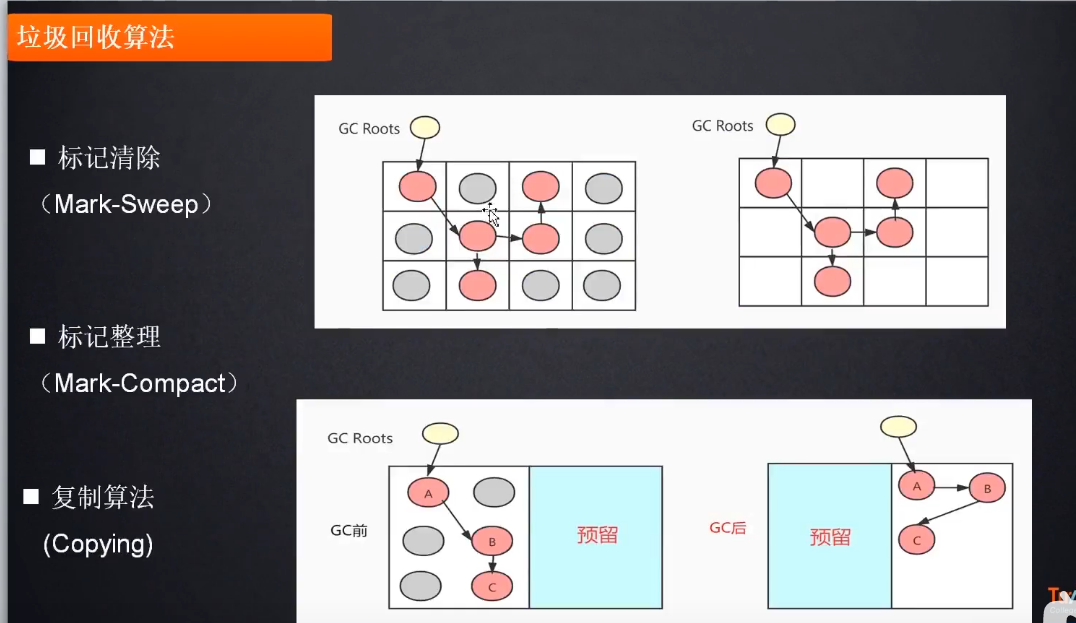
1.标记清除
会产生内存碎片, 造成不连续的现象, 大对象无法进行分配(java中分配大对象需要占据连续的内存空间)
2.标记压缩
在标记和清除的过程中, 同时进行内存的压缩整理(就是将有用的整理到一块儿, 空闲的整理到一块, 行程连续的内存空间), 效率比较低
3.复制算法
没有碎片, 浪费空间
复制就需要开辟两个一模一样的大小的空间, 将标记的东西整理到另一个区域, 剩下的就滚吧, 相对来说比较占用内存
3.垃圾回收模型
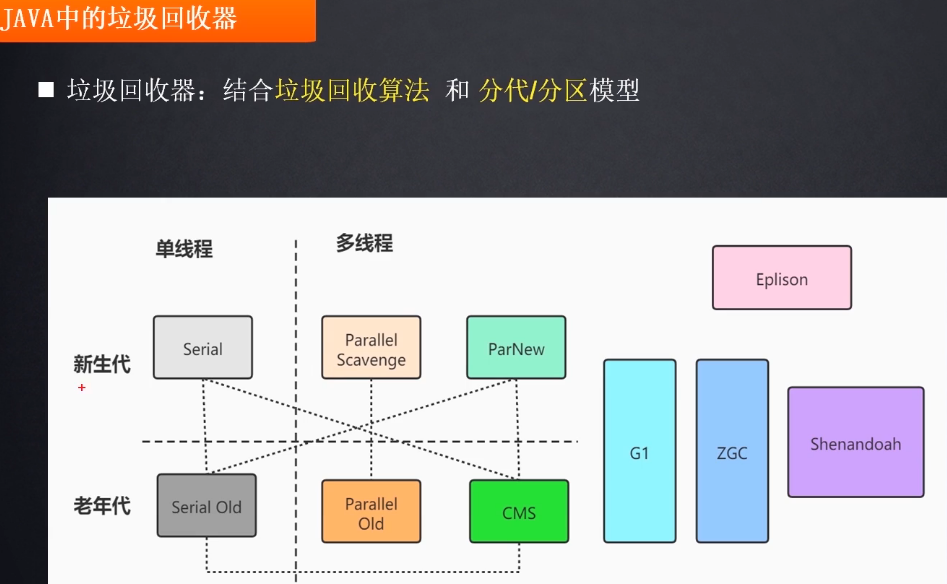
java当中的垃圾回收器如下, Serial, Serial Old, ParallelScavenge,ParallelOld, ParNew和CMS, G1等等, 其中前面六个是数据分代模型,后面的都属于分区模型垃圾回收器.
1.分代模型
分代模型: 新生代:复制算法,老年代:标记整理,标记清除算法,

我们主要回收的空间主要是堆, 分代模型的几乎所有的对象都是在堆中进行分配, 对是java中非常占据内存的空间, 当我们使用某个对象的时候, 我们会先new出来, 或者spring自动帮我们new出来的, 然后就不管了, 而当我们不使用的时候, 他就没有引用占用这个对象了, 这个时候就需要垃圾回收器来进行自动回收,.
为了提高垃圾回收的效率, 它会把整个堆空间一分为二, 前一段是新生代, 后一段是老年代, new出来的都会在新生代, 但是很快啊, 就会满了 , 满了之后会进行垃圾回收, 同时他的年龄也会加1, 回收不动的时候就会抛给from区 或者to区, 再次进行来及回收, 第二次, 第三次, 直到年龄够了, 最终还没有回收的会进入老年代, 那老年代也满了的时候, 就会进行一次Full GC,
新生代进入老年代的年龄一般是: 15,CMS是6,具体的需要看对象头.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Dwbb2xU-1634976311728)(https://cdn.jsdelivr.net/gh/hx1098/Algorithm@master/img/jvm/20211017135906.png)]
2.分区模型

4.不同类型收破烂的
1.serial + serial old
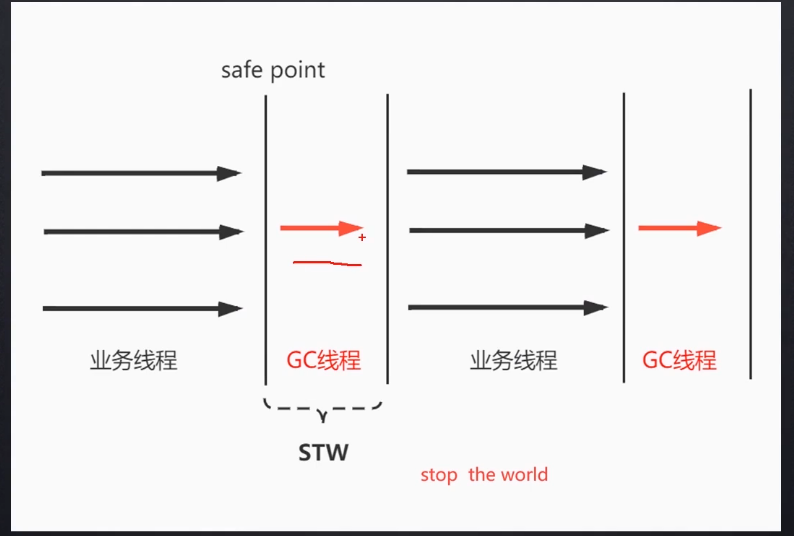
这些是单线程垃圾回收器, 所以内存满了的话, 业务线程就会产生停顿(STW), 让GC线程开始工作, 清扫完之后然后再进行业务的操作.
举个栗子: 这就好比一家公司里面有好多人在进行工作, 保洁的阿姨来清理时候, 所有的人都要停下所有的手头的工作, 跑到外面来配合保洁阿姨的工作, 等到保洁阿姨工作完了, 我们才可以进行下面的业务工作, 是不是有点烦(阿姨也没办法的, 工作需要)
所以现在的 serial 的可以说是废弃的状态.
2.PS+PO垃圾回收器(吞吐量优先)
举个栗子, 单线程的垃圾回收器好比你是一个人住, 买了个小房子(前提是你得有钱, 不过租的也行, 没毛病), 自己一个人打扫, 然后慢慢的有有了女朋友, 有了孩子, 把父母也接过来住了, 这个时候不够住了呀, 房子太小了多尴尬呀, 就直接换了一个大的房子住, 但是你自己清扫的时候就清扫不过来了呀, 你就呼朋唤友, 叫上你的家人一起清理, 这就是并发清理了.
但是可以看到, 业务线程和GC线程任然是不在一起执行的, 只是会减少STW的时间,原来10秒, 现在可能变秒nan了, 反正就是快嘛, 但是也会有缺点, 你需要跟你的服务器cpu相匹配才行, 不然线程开的太多, 增加了cpu的上下文切换还是会变慢的.
所以并发并不能解决STW的时间, 只能不断的优化stw的时间.
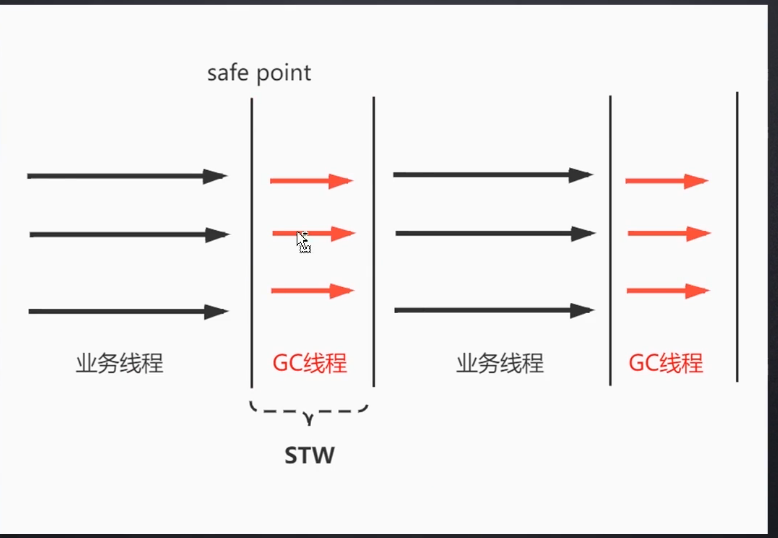
3.CMS(Concurrent Mark Sweep)
1.cms的描述
随着业务的不断增加, cpu和内存的技术革新, 原来内存也不是太大, 也没啥问题, 但是一旦内存在8G, 10G以上的时候, 他的停顿时间是没有保障的, 就催生出了一个新的垃圾回收器.
并发标记清理垃圾, 一般来说CMS(回收老年代)和ParNew(新生代并发)组合使用, 但是通过下面的例子可以看到, 这家伙也是没有解决STW的停顿现象(貌似还没有垃圾回收器能做到吧, 多多少少都有停顿时间), 在初始标记阶段和重新标记阶段, 他还是会自己玩的, 只是一定程度上减少了STW的这种现象.
有小伙伴问了, 问啥需要重新标记呢? 因为前面已经有业务线程和GC线程在跑了, 后面清理的难点在于: 再初始标记之后你不知道又产生了多少个垃圾, 产生了多少个引用的变化, 这些引用还有没有用, 需不需要进行回收. 这就好比你家狗子就是那个业务线程, 早上你把家里收拾的好好的, 整整齐齐, 干干净净的, 但是你下班之后你不知道你还能不能认得出来是不是你家一样, 狗子在家可能还是会产生垃圾, 有可能是沙发掏了个洞, 也有可能是卫生纸碎片铺满了一地, 这都是垃圾的不确定性.
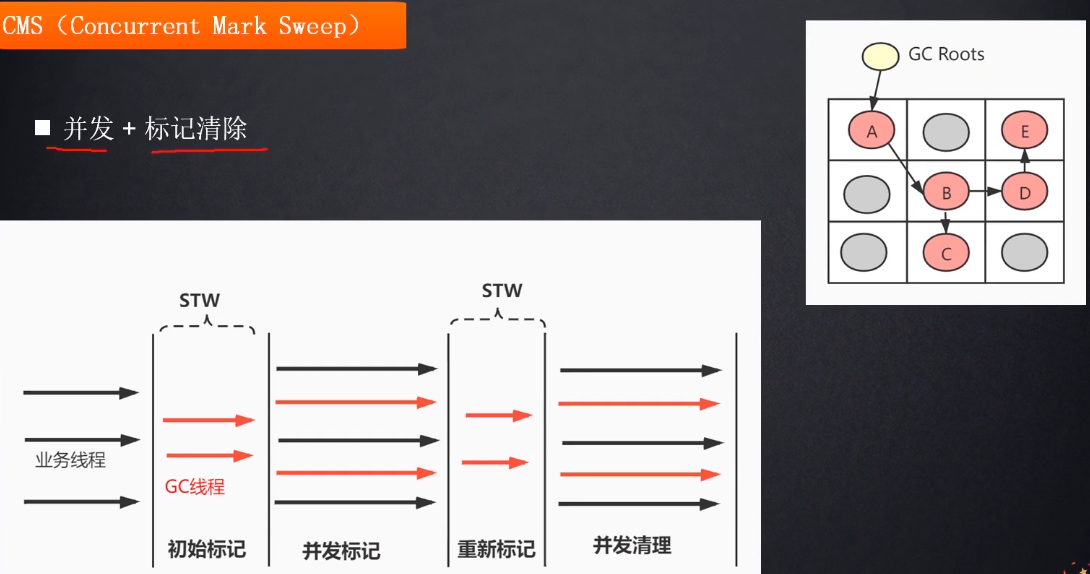
所以为了实现并发的垃圾回收, 这里采用的是三色标记(Tri-color marking),
2.三色标记:
概述:
https://blog.csdn.net/u013490280/article/details/107495053
https://en.wikipedia.org/wiki/Tracing_garbage_collection#TRI-COLOR
感谢这位老哥的维基百科出来的好东西.其实还是不够通俗易懂的, 图中A对象的引用指向了B对象, 同时B对象里的有一个引用指向了C对象, 现在找到一个与A对象有关联的 ROOT:
- A对象是黑色: 黑色说明A自身已经被扫描了, 以及他的下一个孩子也被扫描了
- B对象是灰色: 灰色说明B已经被扫了, 但是孩子对象还没被扫描
- C对象是白色: 没有被扫描的对象

问题1:浮动垃圾
情况: 如下图: 如果A到B到C的过程中都已经标记完成黑色了, 但是业务线程此时已经执行完成了, C已经没有引用的时候, 此时C还是黑色的状态,但是在三色标记当中当中, 我认为黑色的对象是可达的, 是存活对象不是乐色(垃圾), 此时C的状态就是浮动垃圾
解决方案: 在CMS当中是等待下一次被标记的时候才会进行垃圾回收, 同时也会设置出发GC的条件, 比如90%, 预留10%的空间用来存储的就是浮动垃圾, 举个栗子: 你在外面作为一个为了老板能开上宝马的打工人, 有一天朋友出差, 他的房子到期了, 把他的衣服家居啥的一股脑的全部搬你家里来了, 这些东西他也有用, 但对于你来说也没有用. 到了下一次垃圾回收的时候才知道有用没用.

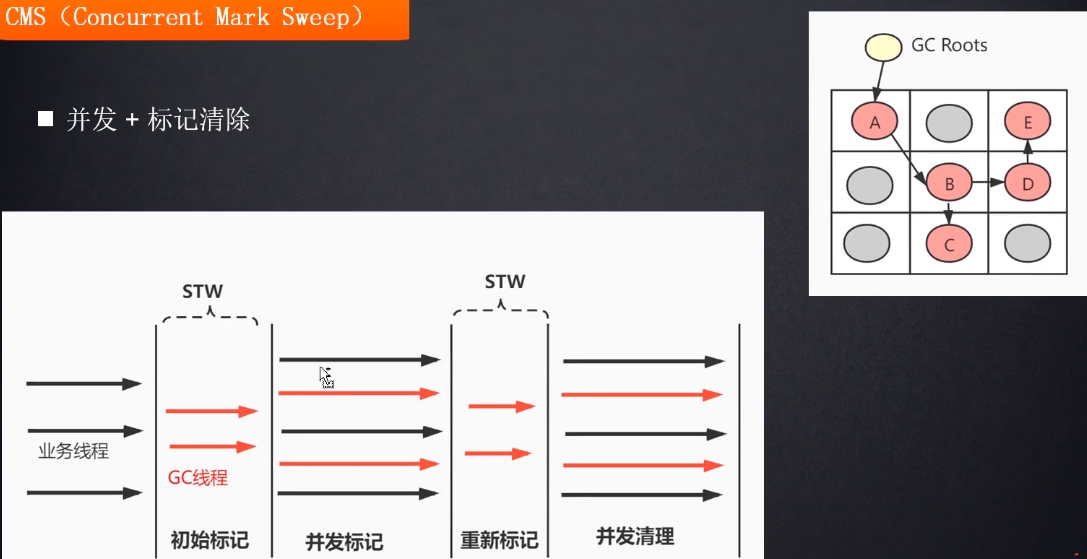
问题2: 漏标问题
漏标的解决方案有两种, 一种是增量更新, 另一种是SATB堆栈快照的方式, 具体的请往下看G1垃圾回收器的详细描述.
情况:
时刻1 : 是一个正常的标记过程,A–>B–>C, A是黑色, B是灰色, C是白色, 仅仅标记到了B节点
时刻2 : 也挺正常的, 只不过标记到了B的时候发现B没有孩子了, 那就算标记完成了, 直接就将B标记为黑色了, 而A又将引用指向了原来的C, C原来就是白色, 而此时的A已经是黑色标记完成了, 那我默认A这一串都是被标记完成的, 但真实的情况是C还没有被标记, 这就是三色标记的漏标问题.

解决方案:
这里是CMS清理垃圾的过程, 初始标记只标记了跟"ROOT"直接相关的对象(A), 而并发标记阶段标记的是BCDE的节点, BCDE中使用了三色标记, 中间可能产生漏标的问题, 所以我就需要再次产生一次"重新标记"的过程, 这次重新标记处理的就是漏标问题.
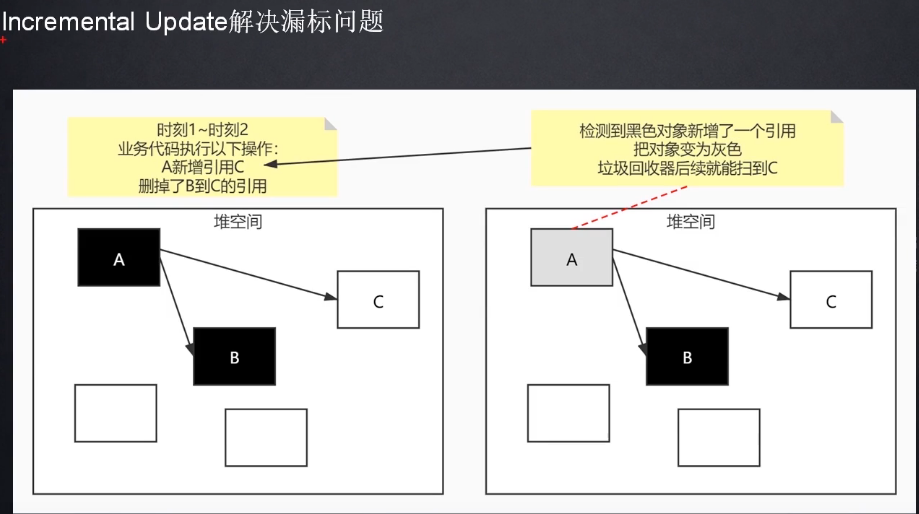
Incremental Update
但是但是但是CMS仍然不能彻底解决漏标问题, 就用到了下面的技术: Incremental Update(增量更新), 在时刻一到时刻二的过程中, 如果检测到黑色对象A增加了一个引用, 那就将A置为灰色, 而灰色代表还没有扫描完成, 就会去扫描C这个白色的对象, 扫完之后A就又变回了黑色的状态, 那么缺点也比较明显:
- 无法处理浮动垃圾, 三色标记的增量更新实际到最后变成了多标, 变成浮动垃圾, 只能下次回收
- 回收时间长, 业务线程和回收线程是同时进行的
- 会产生大量的空间碎片,标记清除的特点
(这里还有个有趣的问题: 增量更新到底有没有彻底解决漏标的问题, 我在bilibili大学里看的一个视频, 说的是如果在多线程的情况下,有两个垃圾回收线程, 1和2, 线程1: A新增了C, 此时A会变成灰色,C为白色, 这个时候线程2并不感知,线程2继续扫描完成变成黑色, 认为我只有一个孩子, 将A变成黑色, 此时两个线程都扫描完成, C仍然为白色, 还是漏标了, 所以只能重新扫描, 会造成效率不稳定, 但是我查了很多资料, 都是找不到有关增量更新的漏标问题, 如果有朋友看到的话, 麻烦回复我一下, 让我开一下眼)
4.G1垃圾回收器
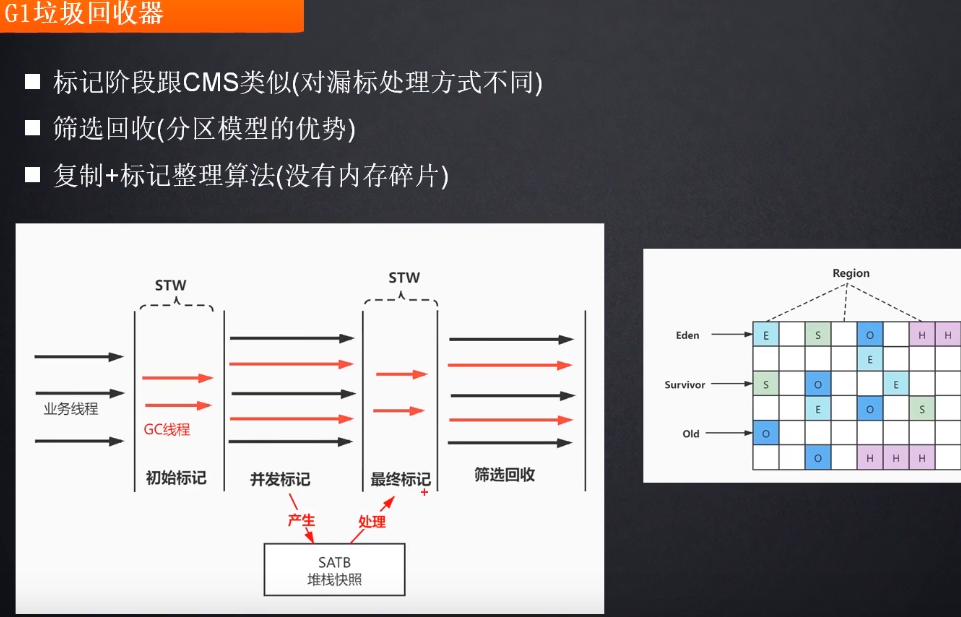
G1垃圾回收器之前, 垃圾收集的目标范围要么是整个新生代(MinorGC), 要么是真个老年代(MajorGC), 再要摸就是整个java堆(FullGC),而G1很是另类, 他开创了基于region的堆内存布局, 图中的region, 每一个不是固定的, 都会根据需要扮演新生代的Eden空间, Survivor空间,或者老年代空间, 收集器能够对不同角色的region使用不同的策略进行去处理, 无论是新生对象, 还是存活了一段时间的对象, 都能获得很好的收集效果.
其中region中还有一个Humongous区域, 专门用来存储大对象, 一般来说如果超过了Region容量一半, 就算是大对象了, region的大小可通过参数进行设置(1~32M), 这里不过多赘述, 对于那些超过整个region的大对象, 会被存在连续的Humongous Region中, G1大多数行为会将其看为老年代.
G1保留了老年代新生代的概念, 在回收时候, 会优先回收价值收益最大的那些region(价值即回收能获得的大小和回收所需时间的经验值大小), 谁回收的时间短, 回收的还多, 我就去那家(region)去收垃圾, 这样我回收的空间就多, stw的停顿就可以进行预测.

接下来看看G1垃圾回收器是如何处理漏标问题的, G1垃圾回收器使用的是 STAB(snapshot at the beginning), 接下来开始进行操作了, 坐好了, 时刻1到时刻2业务代码进行了一下操作, A新增了引用C, 删除了B到C的引用, 这个时候, 把这个引用推到了GC的堆栈, 到了时刻2之后, GC线程在堆栈找到C, 知道C被漏掉了, 我再看看有没有对象指向你呢, 原来还有一个A的引用指向了C, 所以这个C就不会被漏掉了. 可以看到, 这个过程最主要关注的是"引用的消失", 而不是引用的增加.
感谢:
https://my.oschina.net/u/3471412/blog/4740055
https://www.cnblogs.com/hongdada/p/14578950.html
https://blog.csdn.net/qq_39685066/article/details/107294318















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









