







爬虫学习+数据分析的产物,练习、自娱的同时也想了解不同行业对于数据挖掘的需求。
一.确定爬虫范围
数据挖掘,数据最重要,翻了资料后,从这篇博客中确定了自己需要从哪里爬取数据:http://blog.sina.com.cn/s/blog_48fbe4a10100ezsm.html
以下引用原文:
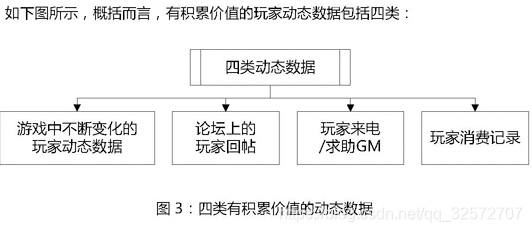

对于玩家动态数据的存储:
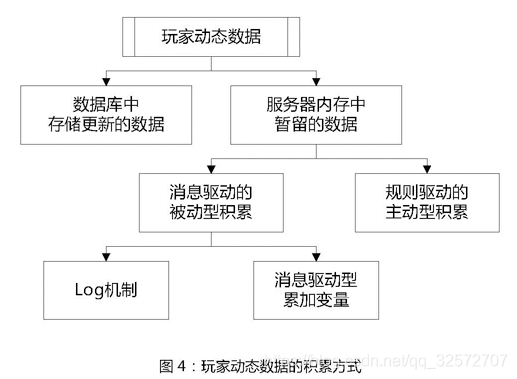
看到四类动态数据,我去游戏官网查看了一下:我发现除了论坛上的回帖,其他的除了黑了服务器,否则我根本拿不到。那就只能去爬回帖,微博评论,游戏视频的弹幕和评论。
看视频找数据的时候,发现了这个小框框,然后结合上面的四类动态数据中的的玩家消费记录,我突然悟了,游戏的人气也可以从这些打赏的情况来看。当然,这个点我还要研究一下是否可用,先放着。
二.微博爬虫获取评论
通过评论数据集可以进一步做中文分词、命名实体识别、关键词提取、句法分析、文本向量化、情感分析、舆情分析等进一步的数据处理和应用。
下面的微博爬虫的代码。这里看了一位博主的详细讲解,选用的是手机端的微博地址:https://weibo.cn/,这个地址的微博是最容易爬的,因为结构简单。
import requests
import re
import time
def get_one_page(url):#请求函数:获取某一网页上的所有内容
headers = {
'User-agent' : '自己的',
'Host' : 'weibo.cn',
'Accept' : 'application/json, text/plain, */*',
'Accept-Language' : 'zh-CN,zh;q=0.9',
'Accept-Encoding' : 'gzip, deflate, br',
'Cookie' : '自己的',
'DNT' : '1',
'Connection' : 'keep-alive'
}#请求头的书写,包括User-agent,Cookie等
response = requests.get(url,headers = headers,verify=False)#利用requests.get命令获取网页html
if response.status_code == 200:#状态为200即为爬取成功
return response.text#返回值为html文档,传入到解析函数当中
return None
def parse_one_page(html):#解析html并存入到文档result.txt中
pattern = re.compile('<span class="ctt">.*?</span>', re.S)
items = re.findall(pattern,str(html))
result = str(items)
with open('test1.txt','a',encoding='utf-8') as fp:
fp.write(result)
for i in range(677):
url = "https://weibo.cn/comment/HBLUDfXFb?uid=6140485374&rl=0&page="+str(i)
html = get_one_page(url)
print(html)
print('正在爬取第 %d 页评论' % (i+1))
parse_one_page(html)
time.sleep(3)读取到的数据未经处理,不能使用。

下面对他进行处理:
# -*- coding: utf-8 -*
import re
f = open('test1.txt','r',encoding='utf-8')
content = f.read()
rawResults = re.findall(">.*?<",content,re.S)
firstStepResults = []
for result in rawResults:
#print(result)
if ">\'][\'<" in result:
continue
if ">:<" in result:
continue
if ">回复<" in result:
continue
if "><" in result:
continue
if ">\', \'<" in result:
continue
if "@" in result:
continue
if "> <" in result:
continue
else:
firstStepResults.append(result)
subTextHead = re.compile(">")
subTextFoot = re.compile("<")
i = 0
for lastResult in firstStepResults:
resultExcel1 = re.sub(subTextHead, '', lastResult)
resultExcel = re.sub(subTextFoot, '', resultExcel1)
print(i,resultExcel)
with open('F:/日常··练习/Spider/weiboComment/test.txt', 'a', encoding='utf-8') as f1:
f1.write('\n')
f1.writelines(resultExcel)
f1.write('\n\n')
i+=1
获得的结果如下:

通过引入jieba、wordcloud模块
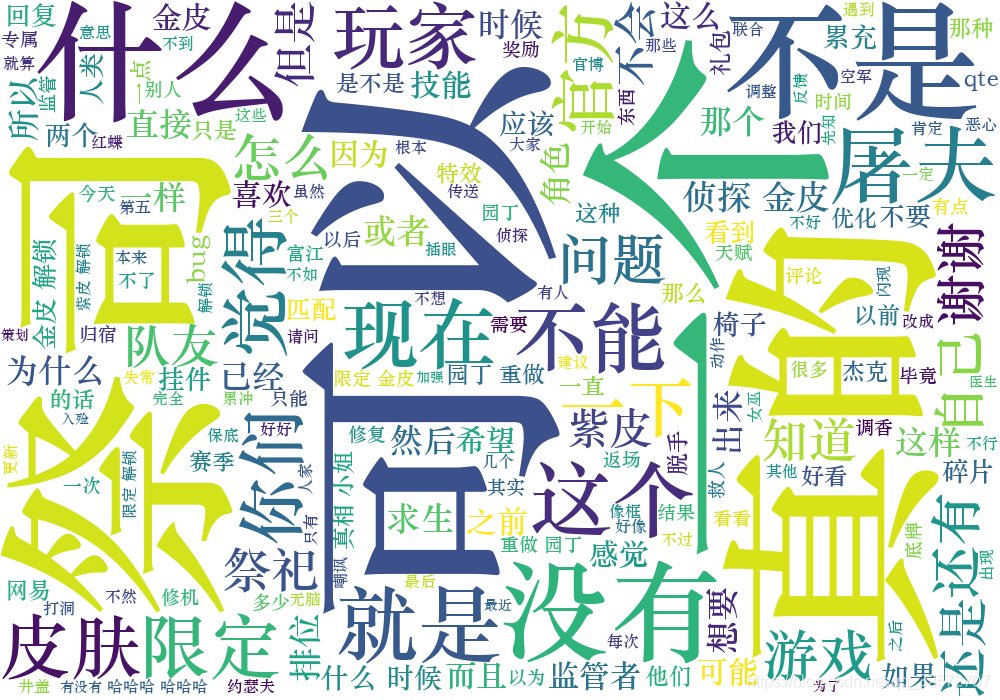
从这个词云可以看出,在这条微博下,大部分评论都是围绕着祭祀,一部分围绕着屠夫。
既然玩家们对祭祀的提出频率最高,那么单独选出有关祭祀的所有评论,分析这些评论。
通过正则表达式筛选出包含‘祭祀’字符的评论,然后我大致看了一下,一段时间没玩,祭祀竟然改技能了!!!心痛。

看评论,感觉伤了好多本命祭祀玩家的心啊,还有监管者幸灾乐祸的。
粗略的看了一下,选择五个关键词来筛选对祭祀改动失望的评论:
其中涉及祭祀的评论共有113条,含有(‘削’,‘弱’,‘改’,‘骂’,‘废’)的词的评论共有45条,比例为0.39823008849557523,并没有我想象中的影响大,通过分析评论中的关键词,可以看出来,技能改变影响了一部分玩游戏消遣为主的玩家,分析显示,玩的好的玩家依旧遛监管者溜得飞起。
不过就我自己的游戏经验而言,第五人格有策略性游戏影子,4VS1的模式,如果四人都是单排,那么在配合不默契或者说根本没配合的情况下(没有语音啊),其实很容易团灭。而日常消遣的玩家很多都是单排,这就使一个角色的削弱在他们眼中变得很严重,影响了他们的游戏体验。对于中上层玩家,经常四人排位,真的是配合默契,监管者经常被虐啊(我就是,会被遛的很惨),所以说,有利有弊。但为了留住玩家,还是应该用新的游戏机制,适应不同的群体。偶尔输输是乐趣,太多了真的玩不下去啊。
附上分析代码。因为数据不是很多,没有进行更深入的分析。有时间会在加上其他特征,看看别的信息。
import wordcloud
import jieba
import re
def wordCloud_show():
f = open('test.txt', 'r', encoding='utf-8')
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = ' '.join(ls)
w = wordcloud.WordCloud(font_path='c:\windows\Fonts\STZHONGS.TTF', width=1000, height=700, background_color='white')
w.generate(txt)
w.to_file('testWordcloud.png')
def choose_jisi():
num = 0
for lines in open('test.txt', 'r',encoding='utf-8'):
line = lines[:-1]
#reg = re.compile(r'(?:祭祀)\d+')
match = re.search('祭祀',line)
if match != None:
with open('jisi.txt', 'a', encoding='utf-8') as f:
f.write('\n')
f.writelines(lines)
f.write('\n\n')
num += 1
return num
def choose_xiaoruo():
num = 0
for lines in open('jisi.txt', 'r',encoding='utf-8'):
line = lines[:-1]
#reg = re.compile(r'(?:祭祀)\d+')
match1 = re.search('削',line)
match2 = re.search('弱', line)
match3 = re.search('改', line)
match4 = re.search('骂', line)
match5 = re.search('废', line)
if match1 != None or match2 != None or match3 != None or match4 != None or match5 != None:
with open('xiaoruo.txt', 'a', encoding='utf-8') as f:
f.write('\n')
f.writelines(lines)
f.write('\n\n')
num += 1
return num
if __name__ == '__main__':
#d = wordCloud_show()
num_jisi = choose_jisi()
num_xiao = choose_xiaoruo()
print(num_jisi)
print(num_xiao)
print(num_xiao/num_jisi)

















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









