







1 ClickHouse适用场景
当场景满足如下大部分场景时,即可调研尝试使用ck。
01、绝大多数请求都是用于读访问,而且不是单点访问
02、数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
03、数据只是添加到数据库,没有必要修改
04、读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
05、表很“宽”,即表中包含大量的列
06、查询频率相对较低(通常每台服务器每秒查询数百次或更少)
07、对于简单查询,允许大约50毫秒的延迟
08、列的值是比较小的数值和短字符串( 例如,每个URL只有60个字节)
09、在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
10、不需要事务
11、数据一致性要求较低
12、每次查询中只会查询一个大表。除了一个大表,其余都是小表
13、查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
2 经典大厂案例分析
2.1 分组求topn-TopK
创建表:
create table topn_test(a Int32, b Int32, c Int32) ENGINE=Memory;
插入数据:
insert into topn_test( a,b,c) values (1,2,5),(1,2,4),(1,3,8),(1,3,2),(1,4,6),C2,3,3),(2,3,7),(2,3,8),C2,4,9),C2,5,6),(3,3,4),(3,3,7),(3,3,5),(3,4,9),(3,5,6);
查询SQL:
select * from topn_test2 order by a desc;
分组topK:以a分组,取c top3的数据
select a, topK(3)(c) from (select a,c from topn_test2 order by a asc ,c desc ) group by a order by a;
相较于hive的开窗函数,最上层的select不能获取group by 、order by 之外的字段。而且topK是集合。
**注意:**当表是分布式表时这个操作只能获取每台机器上的表的TopK,比较坑,再次验证ck是单机单表性能强悍的数据库。
2.2 窗口分析函数-over partition
Window Functions在clickhouse的需求和呼声很高,早期的版本需要借助array函数,在21.1版本进行了开窗函数的初步支持。
查询版本:
select version();
开启参数:
SET a11ow_experimental_window_functions = 1;
创建表:
create tab1e window_test(id String, score UInt8) engine=MergeTree() order by id;
生成测试数据:
insert into window_test(id,score) values('A',90),('A',80),('A',88),('A',86),('B',91),('B',95),('B',90),('C',88),('C',89),('C', 90);
分组聚合查询表数据:
select id,score, sum(score) over(partition by id order by score) sum from window_test;
select id,score, max(score) over(partition by id order by score) max from window_test;
select id,score, min(score) over(partition by id order by score) min from window_test;
select id,score, avg(score) over(partition by id order by score) avg from window_test;
select id,score, count(score) over(partition by id order by score) count from window_test;
目前已经支持min, max, avg, count, sum等分组函数。
-- 每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数
select
id,
month,
pV,
sum(pv) over(partition by id order by month) sum,
max(pv) over(partition by id order by month) max
from exercise_pv;
2.3 同比环比-neighbor
基础概念:
同比增长率= (本期数-同期数) /同期数 和去年比=》 202105-202005 / 202005
环比增长率= (本期数-上期数) /上期数 和上个月比=》 202105-202104 / 202104
使用neighbor定位一定行数据的字段值:
WITH toDate( ' 2020-01-01') AS start_ _date
SELECT
toStartofMonth(start_ _date + (number *t 31)) AS month_ start,
(number + 20) tt 100 AS amount,
neighbor (amount, -12) AS prev_ year_ _amount ,
neighbor (amount, -1) AS prev_ month_ _amount
FROM numbers (24);
同比、环比计算:
WITH toDate(' 2020-01-01') AS start_ _date
SEL ECT
toStartofMonth(start_ date + (number *t 31)) AS month_ start,
(number + 20) *t 100 AS amount,
neighbor (amount, -12) AS prev_ _year_ _amount,
neighbor (amount, -1) AS prev_ month_ amount ,
if(prev_ _year_ _amount = 0, -999, amount - prev_ _year_ _amount) as year_ inc,
if(prev_ year_ _amount = 0, -999, round( (amount - prev_ year_ _amount) / prev_ _year_ _amount, 4)) AS year_ over_ _year,if (prev_ _year_ _amount = 0, -999, amount - prev_ _month_ _amount) as month_ _inc,
if (prev_ month_ _amount = 0, -999, round( (amount - prev_ _month_ _amount) / prev_ month_ _amount, 4)) AS month_ _over_ _mFROM numbers (24);
neighbor函数可以说是lag()与lead()的合体,它可以根据指定的offset,向前或者向后获取到相应字段的值,其完整定义为:neighbor(column, offset[, default_ _value])
2.4 漏斗分析-WindowFunnel
漏斗模型主要涉及到转化,用于分析生命周期每个环节的转化率,然后根据分析结果优化低转化率的流程。漏斗模型是每个电商平台比不可少的运营分析模型,如下某个商品从广告曝光到最终交易成功的漏斗分析:
1、广告曝光 1000万
2、用户点击 20万
3、用户浏览详情页 19万
4、加入购物车 2万
5、下单 1万
6、支付 8000
7、支付成功 7500
8、收获成功、结束订单 6000
通过分析某个关键步骤的转化,我们可以针对性的进行优化,如1到2转化率过低,我们可以建立用户的人物画像,根据任务画像进行精准广告推销,若6到7转化率低我们可以增加支付方式支付宝、微信、银行卡等以及订单15分钟内可支付设置。
创建表:
CREATE TABLE พindow_funne1_test (uid String, eventid String, eventTime UInt64) ENGINE = Memory;
插入数据:
insert into พindow_funne1_test (uid,eventid, eventTime) values('A' ,'login',20200101) ,
('A','view' ,20200102) ,
('A', 'buy', 20200103) ,
('B','login',2020011 ,
('B', 'view' ,20200102) ,
('c', 'login' ,20200101) ,
('c', 'buy' ,20200102) ,
('D','login',202011) ,
('D','view', 20200103),
('D', 'buy' ,20200102);
漏斗分析:
-- 先按eventTime时间顺序,再按login、view、buy顺序统计出合法的每个用户执行到的步骤信息。
SELECT
uid,
windowFunne1(2) (eventTime, eventid = 'login', eventid = 'view', eventid = 'buy') AS resFROM window_funnel_test
GROUP BY uid
-- 然后根据根据上面的结果就可以很容易分析每个步骤的用户人数了,
2.4 去重统计
针对不同的场景需求,ck提供不同的去重函数,主要分为精确去重和非精确去重,前者用于统计成交总额等极度准确的数据、后者用于统计如uv这中趋势结果数据,后者的函数计算速度远远大于前者。
类型:
- 非精确去重函数: uniq、 uniqHLL12、uniqCombined、uniqCombi ned642、
- 精确去重函数: uniqExact、 groupBitmap
区别:
- 整形值精确去重场景,groupBitmap比uniqExact快很多
- groupBitmap仅支持整形值去重,uniqExact支持任意类型(Tup1e、 Array、Date、DateTime、 String和数字类型) 去重。
- 非精确去重场景,uniq在精准度上有优势。
- uniq是近似去重,千万级用户,精确度能达到99%以上,uniqExact是精确去重,和mysq1 的count distinct功能相同,比如统计uv。
比如,腾讯在进行去重方案选择的时候,其实对比了很多方案:
1、基于TDW临时表的方案,在pysq1 中循环对每个活动执行对应的hiveSQL 来完成T+1时效的计算
2、基于实时计算+文件增量去重的方案,虽然可在storm 中进行HLL近似去重,但是内存资源有限,无法给出精确的结果和最终的号码包文件,而且导致每日新增几十万小文件
3、基于实时计算+Leve1DB增量去重方案,Leve1DB 是KV存储,key存文件名,value存储文件内容,可执行毫秒级去重,可在10s内导出千万量级的数据。但是扩展性较差,数据回溯困难。
4、基于CLickHouse的解决方案,灵活,扩展性强,轻量级。
最终选择了ClickHouse,去重服务就变成了SQL查询,例如下面这条SQL就是查询LOL官网某个页面在9月6日这1天的UV:
select uni qExact(uvid) from tbUv where date= ' 2020-09-06' and ur1=' http://1o1. qq. com/main. shtm1';
2.6 ck整合BitMap
该方案可用于解决大表join的问题。
**位图计算原理:**每个bit位表示一个数子id,即第N个bit位表示数子id N。0、1表示否与是。这样大大降低了我们在内存中存储数据量。如一个对于40亿用户今天是否上线描述,只需要40亿bit位,约477m大小=(4*10^9/8/1024/1024)即可标记。如下图:
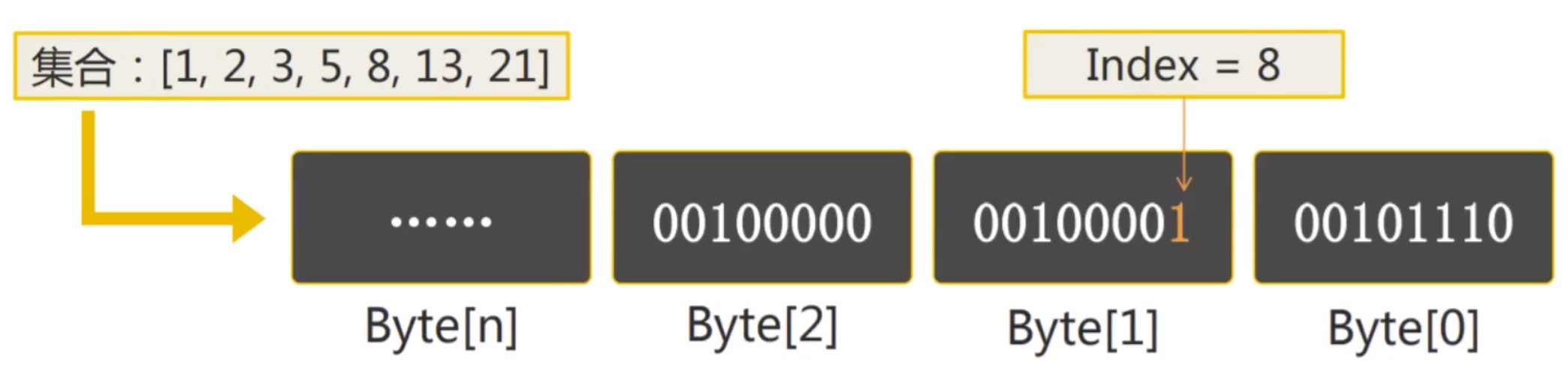
程序底层逻辑与或非都是的位运算,当我们将信息转化为位信息后通过位运算即可快速完成数据的分析。
通过单个bitmap可以完成精确去重操作,通过多个bitmap的and、or、xor、andor等位操作即可完成留存分析、漏斗分析、用户画像等场景的计算。ck支持丰富的位图计算函数
需求案例一:电信用户每个月的话费统计,当一天有流量或者有电话产生时就收费1元钱。
0100110101000101010100101010101 这串数字一共31位的,每一位代表某个月某一天, 如电信的号码某一天有通话记录就置成1,没有为0
1101010101010101010100101010100 这串数字一共31位的, 每一位代表某个月某一 天, 如电信的号码某一天有流量记录就置成1, 没有为0
1101110101010101. . #位运算求或,获取改用户需要收费的天集合
需求案例二:统计微信过去连续7天都发朋友圈的用户。
每天的朋友圈信息,构建成一张表(110) 经过bitmap的构建,每天的15E用户是否发朋友圈的信息,就被构建成了一个长度为15E的二进制序列
1号用户发了3条朋友圈,就是3条信息
2号用户发了2条朋友圈,就是2条信息
3号用户没有发朋友圈
7张表做join链接
table1 1号所有用户发朋友圈的信息的表= bitmap = 101010101010110101010101011010101
table2 2号所有用户发朋友圈的信息的表= bitmap = 101010101010110101010101011010101
table3 2号所有用户发朋友圈的信息的表= bitmap = 101010101010110101010101011010101
....
最后位运算求与即可求的连续七天都发朋友圈的用户集合,确只需要耗费大约1.5G内存。
扩展1:生产中hive的一些join优化也是可以转成bitmap操作,作为一个大数据的开发人员不知道bitmap技术就是伪程序猿。
扩展2: **ck的优势是适用于大数量级的非实时的单张大宽表的聚合查询分析,其它场景使用需要慎重。**最佳场景方案是在spark等计算引擎中将数据扩展为大宽表,然后离线落地ck,使用ck进行各种聚合分析。
扩展3: ck生产中是需要搭建集群,使用副本的,ck集群的稳定性相较于doris更好
扩展4: ck并不擅长做join,但是doris的join性能就好的多了,但是它的稳定性远远低于ck
扩展5: ck等这种偏向于分析的引擎,对与事物一致性保障比较差,他们是用于做OLAP,非TP型处理















 6455
6455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









