








引用了太多,不知道该怎么标注,就弄个百度百科凑数吧,忘大佬们见谅!
参考博客1:目标检测(九)–YOLO v1,v2,v3
参考博客2:YOLO文章详细解读
参考博客3:目标检测之YOLO系列-V1至V3改进详解
参考博客4:yolo系列之yolo v3【深度解析】(好好看看)
参考博客5:目标检测:YOLOv3: 训练自己的数据
参考博客6:进化历程详解:YOLOv1到YOLOv3
YOLO(开源) 是小有名气的单步(one-stage)目标检测方法(虽然不是最好的),早就想学习了。
目前,基于深度学习算法的一系列目标检测算法大致可以分为两大流派:
1.双步(two-stage)算法:先产生候选区域然后再进行CNN分类
2.单步(one-stage)算法:直接对输入图像应用算法并输出类别和相应的定位
1、YOLOv1
YOLO的检测思想不同于R-CNN系列的思想,它将目标检测作为回归任务来解决。
核心思想
- YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。
- faster RCNN中也直接用整张图作为输入,但是faster-RCNN整体还是采用了RCNN那种proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了,而YOLO则采用直接回归的思路。
实现方法(大致说明)
-
将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。

-
每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息,其值是这样计算的:

其中如果有object落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的groundtruth之间的IoU值。 -
每个bounding box要预测(x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。
注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
检测处理思想
将输入图片划分为SS的格子(逻辑区域),如果物体的中心坐标落在某个格子中,那么这个格子就负责检测这个物体(包括bounding box的坐标和类别概率)。
每个格子预测B个bounding boxes和B个置信度,这个置信度表示这个格子预测的bounding boxes包含物体的可信程度,论文作者将置信度定义为Pr(Object) * IOU,IOU的意义论文中明确提到是预测bounding box和真实bounding box的交集。这里我理解IOU的值为预测bounding box和真实bounding box交集除以它们的并集,因为这样可以将IOU压缩到0到1之间,Pr(Object)的值为0或者1,表示存不存在目标物体。每一个bounding box包括五个元素,x,y,w,h,confidence。
坐标(x,y)表示的是box的中心坐标,并且是相对于格子的边界而言,w和h也是相对于整张图片的宽度和高度而言。置信度预测的值表示预测框和真实框的IOU值。虽然每个格子预测B个bounding box,但是每个格子只预测一组类条件概率,注意这里不是anchor,因为多个bounding box共用了一组class probability。
所以网络架构的最后一层实际预测了B个bouding box和一组类别概率,注意这只是针对于一个格子,所以在不考虑batch size的情况下,实际预测输出长度为SS*(B*5+C),作者在Pascal VOC数据集上训练时S = 7,B=2, C=20。
(发表时的)优点:
1.YOLO执行速度很快(相比于其他检测系统,论文的最大亮点),因为它是一个端对端的网络(pipeline);
2.YOLO在预测中对整张图的全局合理性把握得更好,因为YOLO在训练和测试中使用的是整张图片,这表明它在某种程度上编码了图片的类别和图片内容信息。作者在论文中提到,YOLO比Fast RCNN减少了将近一半的背景错误。这里的background error我理解为出现bounding box,里面没有所谓的前景物体;
3.YOLO能够提取到目标通用的特征,作者用自然图片训练,用艺术图片测试,效果比DPM和R-CNN效果要好很多。
缺点:
1.YOLOv1在精确度上落后于当前最好的检测系统,主要来源于坐标定位的不准确,因为这些坐标预测都是从标签bounding box数据中以一种新的宽高比率统计抽象出来,这个过程很容易出现定位不准确。
2.大的bounding box和小的bounding box对相同的小错误的敏感度相同。这与直觉逻辑不合,因为直觉告诉我们对于相同的小错误,小的bounding box应该更加敏感。虽然作者试图在损失函数中使用平方根来克服这个缺点,但是只能部分解决。
3.YOLOv1对密集物体,重叠面积大的物体不好预测,作者在论文中提到,每个格子负责预测一个物体,但是如果一个格子内有两个或者多个物体,就必然会丢失物体。
2、YOLOv2
摘要
-
提出YOLOv2:代表着目前业界最先进物体检测的水平,它的速度要快过其他检测系统(FasterR-CNN,ResNet,SSD),使用者可以在它的速度与精确度之间进行权衡。
-
提出YOLO9000:这一网络结构可以实时地检测超过9000种物体分类,这归功于它使用了WordTree,通过WordTree来混合检测数据集与识别数据集之中的数据。
-
提出了一种新的联合训练算法( Joint Training Algorithm ),使用这种联合训练技术同时在ImageNet和COCO数据集上进行训练。YOLO9000进一步缩小了监测数据集与识别数据集之间的代沟。
更好(Better):
更好主要指相对于YOLOv1,YOLOv2提高了召回率,减少了定位错误,同时提高了分类精度。YOLOv2想要既做到高精度也要高速度,仅仅是增加网络的复杂性不可能提高检测速度。所以作者简化网络结构,并且做了一系列处理让特征容易被提取出来。这些操作包括:
-
1.Batch Normalization(提高损失收敛速度,同时mAP提高了2个百分点)batch normalization一般加在神经网络激活函数的前面,他能够提高梯度在网络中的流动,Normalization的能够使特征全部缩放到[0,1],这样在反向传播的过程中,梯度都是1左右,避免了梯度消失,提升了学习率,更快达到收敛,减少模型训练对初始化的依赖。
-
2.High Resolution Classifier:从AlexNet开始,绝大多数的分类器的输入图片的大小小于256256,[YOLOv1预训练的input image size是224224,正式训练的input image size是448448]。在YOLOv2中,用size为448448的ImageNet数据集微调分类网络10个epoches【既然是微调,和YOLOv1一样,低分辨率的ImageNet图片进行预训练分类网络,高分辨图片训练检测网络,只是在这两个过程加了一个适应性微调】,这样做的目的是使网络能够有足够的时间适应高分辨率图片的输入。然后继续用高分辨图片微调这个网络进行检测任务,作者在论文中提到这样做能够提高mAP将近4个百分点。
-
3.Convolutional With Anchor Boxes:作者去掉了YOLOv1的全连接层,使用anchor boxes来预测bounding boxes,同时也去掉了最后池化层使得最后feature maps的分辨率大一些。为了得到奇数形状的feature maps,作者调整输入图片的分辨率为416416,使得最后的卷积层输出的feature maps的分辨率大小为1313。与YOLOv1不同的是,YOLOv2为每一个bounding box预测一个类条件概率【YOLOv1中B个bounding box共用一个类条件概率】。在YOLOv1中bounding boxes数目为:SS(5B+C),而在YOLOv2中bounding box数目为SSB(5+C)。使用anchor box没有使精度提升,提高了召回率。在YOLOv1中每一幅图片值预测98个bounding boxes,在YOLOv2预测了1313*9个bounding boxes,召回率肯定提高呀,所以anchor box在YOLOv2中其实没有太大的作用【个人感觉】。
-
4.Dimension Clusters,前面使用B=9是根据Faster R-CNN来设定的,但是9是不是最合适的,还有待检验,于是作者采用维度聚类的方法对数据集的真实标签的bounding box进行聚类分析从而确定B的取值。如果用欧式距离来衡量K-means的距离,会使得大的bounding box比小的bounding box产生更大的误差,于是作者调整距离计算公式为:
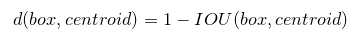
如下图,作者在论文中提到最终选择B=5(聚类中心有5个,意味着每一个格子的anchor box有5个)来平衡模型的复杂性和召回率,并且发现这些作为聚类中心的box比手工挑选的box要偏窄,偏高。对于聚类分析的过程作者在论文中没有详细说明。对此有一个疑惑,IOU(box,centroid)是用直接用像素点计算还是相对于最后的feature map计算。我觉得是相对于feature map计算,因为这样做可以保持与预测网络输出的bouding box的环境一样。具体的做法是:先按比例缩小真实的bouding box(原始图片的大小肯定不是416,输入的图片会按一定的比例缩放到416)再除以32(416/13),然后再计算IOU值。

-
5.Direct location prediction直接预测坐标会导致模型不稳定,特别是在迭代早期。YOLOv2,没有采用RPN(region proposal network)的坐标预测方法,而是继续使用YOLOv1的坐标预测方法,预测相对于格子的偏移,使用logistic activation(sigmoid)函数将偏移值限定在0到1之间。具体计算示意图如下图:

tx和ty为预测的偏移值,sigma函数为sigmoid激活函数,pw和ph为聚类维度中的先验bounding box宽度和高度。cx和cy为格子坐标。如果要恢复为最终的显示bounding box,只需要将bx,by,bw,bh分别乘以(416/13)然后乘以缩放比例即可。这样做后,增加了5个百分点的精度。 -
6.Fine-Grained Feature,1313的feature map可以提供足够信息预测较大的物体,但是对于小物体而言提供的信息仍然不够,所以作者提供了一个passthrough层,利用2626的feature map来预测小物体(可能是受SSD的启发,不同大小的特征图检测不同大小的物体)。和Resnet相似,将前面高分辨率的feature maps连接到后面低分辨率的feature map上,例如2626512的feature maps则可以转化为低分比率的feature maps 13132048,作者在论文中提到这样做提高准确率1个百分点。具体的passthrough层处理方式为:分别对高度和宽度进行倍数提取像素点组成低分辨率feature maps。
-
7.Mutil-Scale Training,YOLOv2的网络只有卷积层和池化层,所以就可以在训练进行的过程改变feature maps的shape。 为了使得YOLOv2更具鲁棒性,我们让模型能够对不同大小的图片进行训练。在训练过程中,每10个batch就换一组新尺度的图片(这里的新图片指大小不同,图片的其他属性是一样的)。由于下采样因子是32,作者将尺度设置为{320,352,…,608},不同尺度的图片最终输出的feature map是不同的,如何修改最后的检测处理,论文没有说明。
(当时)总结
YOLO v2 代表着目前最先进物体检测的水平,在多种监测数据集中都要快过其他检测系统,并可以在速度与精确度上进行权衡。
YOLO 9000 的网络结构允许实时地检测超过9000种物体分类,这归功于它能同时优化检测与分类功能。使用WordTree来混合来自不同的资源的训练数据,并使用联合优化技术同时在ImageNet和COCO数据集上进行训练,YOLO9000进一步缩小了监测数据集与识别数据集之间的大小代沟。
文章还提出了WordTree,数据集混合训练,多尺寸训练等全新的训练方法。
3、YOLOv3
YOLO v3的模型比之前的模型复杂了不少,可以通过改变模型结构的大小来权衡速度与精度。
简而言之,YOLOv3 的先验检测(Prior detection)系统将分类器或定位器重新用于执行检测任务。他们将模型应用于图像的多个位置和尺度。而那些评分较高的区域就可以视为检测结果。此外,相对于其它目标检测方法,我们使用了完全不同的方法。我们将一个单神经网络应用于整张图像,该网络将图像划分为不同的区域,因而预测每一块区域的边界框和概率,这些边界框会通过预测的概率加权。我们的模型相比于基于分类器的系统有一些优势。它在测试时会查看整个图像,所以它的预测利用了图像中的全局信息。与需要数千张单一目标图像的 R-CNN 不同,它通过单一网络评估进行预测。这令 YOLOv3 非常快,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
改进之处:
-
1.多尺度预测 (类FPN)
-
2.更好的基础分类网络(类ResNet)和分类器 darknet-53,见下图。
-
3.分类器-类别预测:
YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个:
a.Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。
b.Softmax可被独立的多个logistic分类器替代,且准确率不会下降。分类损失采用binary cross-entropy loss.
多尺度预测
每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3中尺度.
- 尺度1: 在基础网络之后添加一些卷积层再输出box信息.
- 尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍.
- 尺度3: 与尺度2类似,使用了32x32大小的特征图.
(当时)优点
-
快速,pipline简单.
-
背景误检率低。
-
通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
















 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









