










目录
前置知识
很多的时候,孤零零的一个线程工作并没有什么太多用处,更多的时候,我们是很多线程一起工作,而且是这些线程间进行通信,或者配合着完成某项工作,这就离不开线程间的通信和协调、协作
课程内容
一、管道输入输出流
我们已经知道,进程间有好几种通信机制,其中包括了管道,其实 Java 的线程里也有类似的管道机制,用于线程之间的数据传输,而传输的媒介为内存
设想这么一个应用场景:通过 Java 应用生成文件,然后需要将文件上传到云端,比如:
- 页面点击导出后,后台触发导出任务,然后将 mysql 中的数据根据导出条件查询出来,生成 Excel 文件,然后将文件上传到 oss,最后发步一个下载文件的链接
- 和银行以及金融机构对接时,从本地某个数据源查询数据后,上报 xml 格式的数据,给到指定的 ftp、或是 oss 的某个目录下也是类似的
我们一般的做法是,先将文件写入到本地磁盘,然后从文件磁盘读出来上传到云盘,但是通过 Java 中的管道输入输出流一步到位,则可以避免写入磁盘这一步。Java 中的管道输入/输出流主要包括了如下 4 种具体实现:PipedOutputStream、PipedInputStream、PipedReader 和 PipedWriter,前两种面向字节,而后两种面向字符
二、Join()方法——线程间的协调和协作
现在有 T1、T2、T3 三个线程,你怎样保证 T2 在 T1 执行完后执行,T3 在 T2执行完后执行?
答:用 Thread#join 方法即可,在 T3 中调用 T2.join,在 T2 中调用 T1.join
- join():把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行。比如在线程 B 中调用了线程 A 的 Join()方法,直到线程 A 执行完毕后,才会继续执行线程 B 剩下的代码
代码示例如下:
public static void main(String[] args) {
Thread t1 = new Thread(()->{
System.out.println("本来我是第一步");
});
Thread t2 = new Thread(()->{
System.out.println("本来我是第二步");
});
Thread t3 = new Thread(()->{
System.out.println("本来我是第三步");
});
t3.start();
t2.start();
t1.start();
}
// 第一次执行输入如下
// 本来我是第二步
// 本来我是第三步
// 本来我是第一步
// 第二次执行输入如下
// 本来我是第一步
// 本来我是第三步
// 本来我是第二步
瞧,输出结果是无序的,每次执行结果可能都不一样。接下来展示一下用join()将他们协调起来:
public static void main(String[] args) {
Thread t1 = new Thread(()->{
System.out.println("本来我是第一步");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread t2 = new Thread(()->{
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("本来我是第二步");
});
Thread t3 = new Thread(()->{
try {
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("本来我是第三步");
});
t3.start();
t2.start();
t1.start();
}
// 第一次执行输入如下
// 本来我是第一步
// 本来我是第二步
// 本来我是第三步
// 第二次执行输入如下
// 本来我是第一步
// 本来我是第二步
// 本来我是第三步
三、synchronized内置锁
线程开始运行,拥有自己的栈空间,就如同一个脚本一样,按照既定的代码一步一步地执行,直到终止。但是,每个运行中的线程,如果仅仅是孤立地运行,那么没有一点儿价值,或者说价值很少,如果多个线程能够相互配合完成工作,包括数据之间的共享,协同处理事情。这将会带来巨大的价值。
Java 支持多个线程同时访问一个对象或者对象的成员变量,但是多个线程同时访问同一个变量,会导致不可预料的结果。给一个示例代码,演示一下:
public class SyncCountTest {
private int count = 0;
public static void main(String[] args) {
SyncCountTest test = new SyncCountTest();
// 线程t1,对count增加了1000次
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
test.increaseCount();
}
System.out.println("t1计数完了,我这里的count=" + test.getCount());
});
// 线程t2,也对count增加了1000次
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
test.increaseCount();
}
System.out.println("t2计数完了,我这里的count=" + test.getCount());
});
t1.start();
t2.start();
}
/**
* 修改count,增加
*/
public void increaseCount() {
count++;
}
/**
* 获取count
*/
public int getCount() {
return count;
}
}
上面的代码很简单,新建了两条线程t1和t2,分别对SyncCountTest对象的成员变量count做1W次【++】操作。理论上,累加完之后count的值是20000才对,那,真的是这样吗?输入结果如下:
// 第一次运行
// t1计数完了,我这里的count=12032
// t2计数完了,我这里的count=12032
// 第二次运行
// t1计数完了,我这里的count=13045
// t2计数完了,我这里的count=13045
// 第三次运行
// t1计数完了,我这里的count=16152
// t2计数完了,我这里的count=16152
// 第一次运行
// t1计数完了,我这里的count=14509
// t2计数完了,我这里的count=15981
看,输出结果,每一次都不尽相同,根本不是我们预想的值20000。这就是多线程同时执行同一个方法的结果,是不可预料的。怎么办?可以使用synchronized关键字。
synchronized介绍
- 关键字 synchronized: 可以修饰方法或者以同步块的形式来进行使用,它主要确保多个线程在同一个时刻,只能有一个线程处于方法或者同步块中,它保证了线程对变量访问的可见性和排他性,使多个线程访问同一个变量的结果正确,它又称为内置锁机制。
下面是用synchronized关键字改造之后的示例:
public class SyncCountTest {
private int count = 0;
public static void main(String[] args) {
SyncCountTest test = new SyncCountTest();
// 线程t1,对count增加了10000次
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
test.increaseCount();
}
System.out.println("t1计数完了,我这里的count=" + test.getCount());
});
// 线程t2,也对count增加了10000次
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
test.increaseCount();
}
System.out.println("t2计数完了,我这里的count=" + test.getCount());
});
t1.start();
t2.start();
}
/**
* 修改count,增加
*/
public synchronized void increaseCount() {
count++;
}
/**
* 获取count
*/
public int getCount() {
return count;
}
/**
* 静态方法
*/
public static void output() {
System.out.println("静态方法,属于整个类");
}
}
// 第一次运行
// t1计数完了,我这里的count=20000
// t2计数完了,我这里的count=20000
// 第二次运行
// t1计数完了,我这里的count=20000
// t2计数完了,我这里的count=20000
// 第三次运行
// t1计数完了,我这里的count=20000
// t2计数完了,我这里的count=20000
很洒洒水,只是在increaseCount方法前面+了一个关键字synchronized就OK了
synchronized用法
synchronized关键字最主要有以下3种使用方式:
- 修饰对象方法(类锁):对当前对象上锁,执行代码需要获得当前对象的锁。锁粒度:对象。上面的示例就是属于这种方式
/**
* 修改count,增加
*/
public synchronized void increaseCount() {
count++;
}
- 修饰静态方法(对象锁):对当前类对象上锁,执行代码需要获得当前类对象的锁。锁粒度:整个类
/**
* 修饰静态方法
*/
public synchronized static void output() {
System.out.println("静态方法,属于整个类");
}
- 修饰代码块(对象锁):指定对象上锁,执行代码需要获得指定对象的锁。锁粒度:局部代码块
/**
* 修饰代码块
*/
public void output() {
int a = 0;
int b = 1;
int c = a + b;
// ...其他业务
// ...其他业务
synchronized (obj) {
System.out.println("这里锁的是obj,只是一小块局部代码");
}
}
synchronized使用注意事项
- 确保锁的对象是同一个
我们知道,类的对象可以是有很多个的,所以,我们在使用锁的时候,一定要确保,我们锁的对象是同一个,不然那将毫无意义。给大家一个经典的【无效锁】代码示例:
package org.tuling.juc;
/**
* @author zhanghuitong
* @Date 2023/7/14 14:54
* @slogan 编码即学习
**/
public class SyncCountTest {
private Integer count = 0;
public static void main(String[] args) {
SyncCountTest test = new SyncCountTest();
// 线程t1,对count增加了10000次
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
test.increaseCount();
}
System.out.println("t1计数完了,我这里的count=" + test.getCount());
});
// 线程t2,也对count增加了10000次
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
test.increaseCount();
}
System.out.println("t2计数完了,我这里的count=" + test.getCount());
});
t1.start();
t2.start();
}
/**
* 修改count,增加
*/
public void increaseCount() {
synchronized (count) {
count++;
}
// 上面代码:系统输出
// t1计数完了,我这里的count=13920
// t2计数完了,我这里的count=13920
// 如果改为下面的代码:
// synchronized (this) {
// count++;
// }
// 上面代码:系统输出
// t1计数完了,我这里的count=20000
// t2计数完了,我这里的count=20000
}
/**
* 获取count
*/
public int getCount() {
return count;
}
}
为什么会有这样的差别呢???因为我们知道,Integer包装类型,每次做++的时候,其实是会新生成对象的。每次锁的对象不一样,那肯定对不了啊
- 锁类的静态对象 != 锁类对象
上面这个是什么意思呢?我们知道,synchronized修饰静态方法,其实锁的是类对象,即下面的代码是等价的:
/**
* 修饰静态方法
*/
public synchronized static void output() {
System.out.println("静态方法,属于整个类");
}
/**
* 修饰静态方法
*/
public static void output() {
synchronized (SyncCountTest.class) {
System.out.println("静态方法,属于整个类");
}
}
但是,如果他们跟下面这种情况不等价:
static Object obj = new Object();
public static void output() {
synchronized (obj) {
System.out.println("静态方法,属于整个类");
}
}
道理也是很简单,类对象SyncCountTest.class它也是有地址的,指向方法区内的类对象。显然,static Object obj = new Object(); 有自己的地址,锁的不是同一个对象
四、volatile——最轻量的通信/同步机制
volatile 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
不加 volatile 时,子线程无法感知主线程修改了 ready 的值,从而不会退出循环,而加了 volatile 后,子线程可以感知主线程修改了 ready 的值,迅速退出循环。但是 volatile 不能保证数据在多个线程下同时写时的线程安全,volatile 最适用的场景:一个线程写,多个线程读。
下面来一个简单的示例,给大家演示一下什么是可见性:
public class SyncCountTest {
private boolean stop = false;
public static void main(String[] args) {
SyncCountTest test = new SyncCountTest();
// 线程t1,对count增加了10000次
Thread t1 = new Thread(() -> {
while (!test.stop) {
//------------
}
System.out.println("走到这里说明上面的循环跳出来了");
});
t1.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
test.stop = true;
System.out.println("main方法都结束了");
}
}
上面的代码,执行之后如下图,一直都不停止,且不会打印线程里面的内容。明明我都修改了stop的值为true了。这就是所谓的【内存可见性】
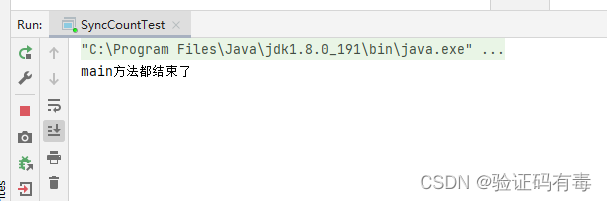
我们使用volatile修饰一下stop值试试看:
private volatile boolean stop = false;
输出结果如下:
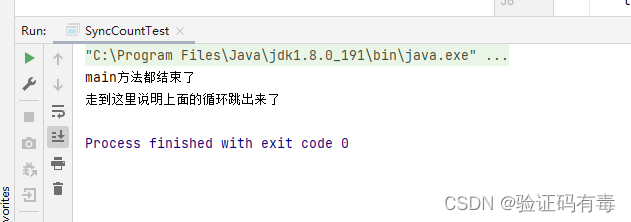
PS:这里都是简单介绍,更多详细的synchronize跟volatile知识会在后面进行更细致的讲解(深入源码,剖析机制)
五、等待/通知机制
线程之间相互配合,完成某项工作,比如:一个线程修改了一个对象的值,而另一个线程感知到了变化,然后进行相应的操作,整个过程开始于一个线程,而最终执行又是另一个线程。前者是生产者,后者就是消费者,这种模式隔离了“做什么”(what)和“怎么做”(How),简单的办法是让消费者线程不断地循环检查变量是否符合预期在 while 循环中设置不满足的条件,如果条件满足则退出 while 循环,从而完成消费者的工作。却存在如下问题:
- 难以确保及时性
- 难以降低开销。如果降低睡眠的时间,比如休眠 1 毫秒,这样消费者能更加迅速地发现条件变化,但是却可能消耗更多的处理器资源,造成了无端的浪费
让我们举一个更加生动的例子,如下:
背景:在一个生产车间里面,有【两条流水线】和一个做中转的【库存间】
- 流水线1:负责组装产品
- 流水线2:负责包装产品
他们的工作流程是这样的:
- 【流水线1】组装完一批产品后,将组装好的产品放到【库存间】
- 【流水线2】的工人从【库存间】里面把组装好的产品拿来,并且包装
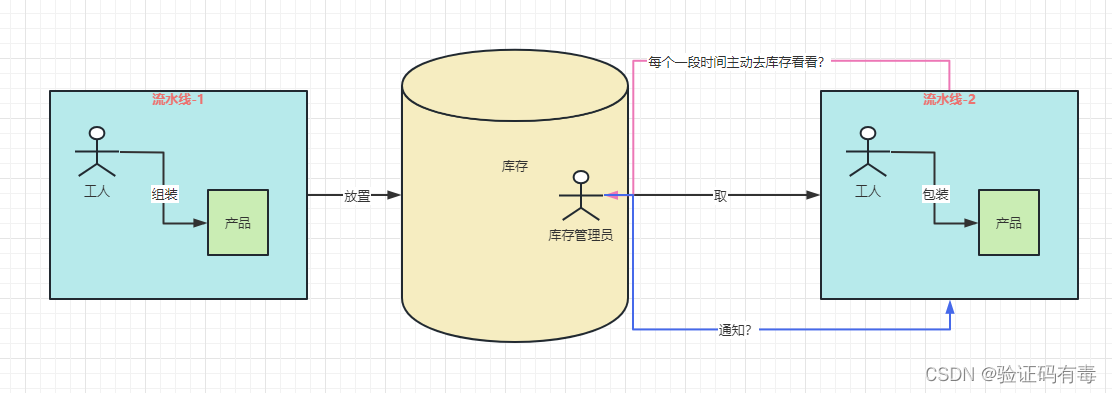
现在有个问题,我【流水线2】的人怎么知道啥时候才去【库存间】里面取呢?基本上的方式有两种:
- 每隔一段时间主动去【库存间】查看是否已经有组装好的产品了。但是有可能空跑
- 仓库管理员通知我去【库存间】取。不会空跑
是你会怎么选?只要不是闲着吃饱没事干都会选择第2种方案吧。第1种方案其实就是上面说的【消费者线程不断地循环检查】,结果【消耗更多的处理器资源,造成了无端的浪费】。而第二种方案就是我们下面说的,【等待通知机制】
等待/通知机制则可以很好的避免【空跑】问题,这种机制对应到Java开发里,是指一个线程 A 调用了对象object的wait()方法进入等待状态,而另一个线程B调用了对象object的notify()或者notifyAll()方法,线程A收到通知后从对象object的 wait()方法返回,进而执行后续操作。上述两个线程通过对象object来完成交互,而对象上的wait()和notify/notifyAll()的关系就如同开关信号一样,用来完成等待方和通知方之间的交互工作
等待和通知的标准范式
标准范式,即无论何种语言,在实现【等待/通知机制】的时候基本上都遵循的原则
等待方遵循的原则如下:
- 获取对象的锁
- 如果条件不满足,那么调用对象的 wait()方法,被通知后仍要检查条件
- 条件满足则执行对应的逻辑

通知方遵循的原则如下:
- 获得对象的锁(这个锁跟等待方拿的是同一个锁)
- 改变条件
- 通知某个、或者所有等待在对象上的线程(这个对象是指:锁对象)

简述一下:在调用wait()、notify()系列方法之前,线程必须要获得该对象的对象级锁,即只能在同步方法或同步块中调用wait()系列、notify()系列方法,进入wait()方法后,当线程释放锁。执行notify()系列方法的线程退出调用了notifyAll的synchronized代码块的时候后,所有等待线程会从wait()调用处返回,接着所有等待线程之间还需要重新竞争以获得锁。如果其中一个线程获得了该对象锁,它就会继续往下执行,在它退出synchronized代码块,释放锁后,其他的已经被唤醒的线程将会继续竞争获取该锁,一直进行下去,直到所有被唤醒的线程都执行完毕
方法精讲
notify()
- 介绍:通知一个在对象上等待的线程,使其从调用wait方法处返回,而返回的前提是该线程获取到了对象的锁,没有获得锁的线程重新进入 WAITING 状态
- 限制:必须在锁内使用
notifyAll()
- 介绍:跟上面的方法一样,只不过该方法通知的是:所有在对象上等待的线程
- 限制:必须在锁内使用
wait()
- 介绍:调用该方法的线程进入 WAITING 状态,只有等待另外线程的通知或被中断才会返回。需要注意,调用 wait()方法后,会释放对象的锁
- 限制:必须在锁内使用
- 特点:会释放持有的锁
wait(long)
- 介绍:调用该方法的线程进入 TIMED_WAITING 状态,只有等待另外线程的通知或被中断才会返回。需要注意,调用 wait()方法后,会释放对象的锁
- 限制:必须在锁内使用
- 特点:会释放持有的锁
那么,notify()和notifyAll()应该用哪个方法呢?通常建议尽可能用 notifyall(),谨慎使用 notify(),因为 notify()只会唤醒一个线程,我们无法确保被唤醒的这个线程一定就是我们需要唤醒的线程。
下面是wait()和notify()的一个使用示例:
public class WaitNotifyTest {
public static Object lockObj = new Object();
public static int stockCount = 0;
private static class Consumer extends Thread {
@Override
public void run() {
synchronized (lockObj) {
System.out.println("消费者线程刚获取到锁");
try {
// 开始检查库存
while (stockCount <= 0) {
System.out.println("没库存,那我先刷一下图灵学院学习视频");
lockObj.wait();
}
System.out.println("来活了来活了, stockCount=" + stockCount);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("消费者线程再次获得锁,并且从wait后面开始调用");
}
}
}
private static class Producer extends Thread {
@Override
public void run() {
synchronized (lockObj) {
System.out.println("生产者线程刚获取到锁,我先睡3秒模拟一下生产东西");
try {
Thread.sleep(3000);
stockCount = 1;
} catch (InterruptedException e) {
e.printStackTrace();
}
lockObj.notifyAll();
}
}
}
public static void main(String[] args) {
Consumer consumer = new Consumer();
Producer producer = new Producer();
consumer.start();
// 这里睡眠是为了确保consume先wait
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
producer.start();
}
}
// 输出结果如下:
// 消费者线程刚获取到锁
// 没库存,那我先刷一下图灵学院学习视频
// 生产者线程刚获取到锁,我先睡3秒模拟一下生产东西
// 来活了来活了, stockCount=1
// 消费者线程再次获得锁,并且从wait后面开始调用
上面的代码很简单,就是简单的新建了一个生产者和消费者线程,消费者等待生产者通知,再接着运行。不知道大家有没有留意到,我的代码有如下细节:
- 使用了等待/通知的范式,即:while循环等待条件
- 我使用了notifyAll()方法,原因前面讲过
- wait()跟notifyAll()都是在synchronized代码块里面的,前面说了要这么干,但是没说原因
那么,为什么wait()跟notify()方法要在synchronized代码块里面调用呢?
首先,从代码层面来说,是JavaApi强制我们这么干的,不这么做是会报错的。从技术角度来看,是因为要防止:Lost wake up,丢失唤醒。什么是丢失唤醒?为什么会丢失唤醒?举个例子:(就算没有并发意识,这个例子应该也看得懂吧)
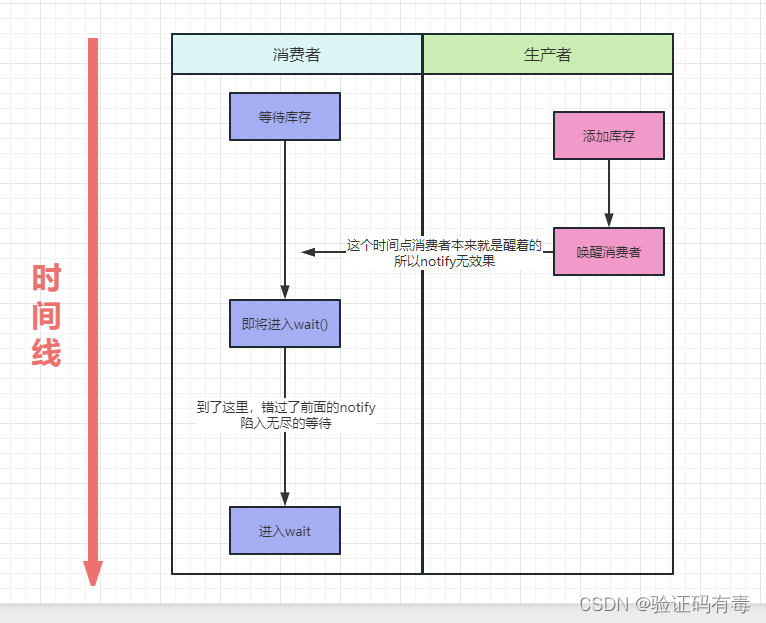
所以你知道了吧,在多线程并发情况下会发生这个问题,所以需要synchronized同步代码
还有一个问题,为什么要在循环中检查等待的条件?为了安全。
处于等待状态的线程可能会收到错误警报和伪唤醒,如果不在循环中检查等待条件,程序就会在没有满足结束条件的情况下退出。因此,当一个等待线程醒来时,不能认为它原来的等待状态仍然是有效的,在notify()方法调用之后和等待线程醒来之前这段时间它可能会改变。这就是在循环中使用wait()方法效果更好的原因
六、CompletableFuture
Java 的 1.5 版本引入了 Future,可以把它简单的理解为运算结果的占位符,它提供了两个方法来获取运算结果。
get():调用该方法线程将会无限期等待运算结果
get(long timeout, TimeUnit unit):调用该方法线程将仅在指定时间timeout内等待结果,如果等待超时就会抛出 TimeoutException 异常
Future 可以使用 Runnable 或 Callable 实例来完成提交的任务,它存在如下几个问题:
- 阻塞:调用 get() 方法会一直阻塞,直到计算完成,它没有提供任何方法可以在完成时通知,同时也不具有附加回调函数的功能
- 链式调用和结果聚合处理:在很多时候我们想链接多个 Future 来完成耗时较长的计算,此时需要合并结果并将结果发送到另一个任务中,该接口很难完成这种处理
- 异常处理:Future 没有提供任何异常处理的方式
JDK1.8 才新加入的一个实现类 CompletableFuture,很好的解决了这些问题,CompletableFuture 实现了 Future, CompletionStage两个接口。实现了Future 接口,意味着可以像以前一样通过阻塞或者轮询的方式获得结果。
同时CompletableFuture实现了对任务编排的能力。借助这项能力,可以轻松地组织不同任务的运行顺序、规则以及方式。从某种程度上说,这项能力是它的核心能力。而在以往,虽然通过CountDownLatch等工具类也可以实现任务的编排,但需要复杂的逻辑处理,不仅耗费精力且难以维护
方法精讲
创建
除了直接 new 出一个 CompletableFuture 的实例,还可以通过工厂方法创建CompletableFuture 的实例(静态工厂)

Asynsc 表示异步,而 supplyAsync 与 runAsync 不同在于,supplyAsync 异步返回一个结果,runAsync 是 void。第二个函数第二个参数表示是用我们自己创建的线程池,否则采用默认的 ForkJoinPool.commonPool()作为它的线程池。
示例代码如下:(这里不演示new的创建了,通常我们也很少使用这种方式创建。毕竟CompletableFutrue的4个静态工厂方法,已经提供了很好的支撑,除了默认的ForkJoin,还支持我们自己定义的外部线程池)
// 这里就不演示外部线程池了
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<String> asyncWithReturn = CompletableFuture.supplyAsync(() -> {
System.out.println("这里一般写耗时操作");
return "success";
});
CompletableFuture<Void> asyncNoReturn = CompletableFuture.runAsync(() -> {
System.out.println("这里一般写耗时操作");
});
System.out.println("有返回值的future=" + asyncWithReturn.get());
System.out.println("没有返回值的future=" + asyncNoReturn.get());
}
获得结果
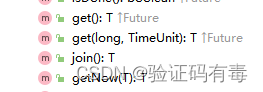
getNow 有点特殊,如果结果已经计算完则返回结果或者抛出异常,否则返回给定的 valueIfAbsent 值
join 返回计算的结果或者抛出一个 unchecked 异常(CompletionException),它和 get 对抛出的异常的处理有些细微的区别。
getNow()示例代码如下:
// 演示getNow
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<String> asyncWithReturn = CompletableFuture.supplyAsync(() -> {
System.out.println("这里一般写耗时操作");
return "success";
});
Thread.sleep(1000);
System.out.println("有返回值的future=" + asyncWithReturn.getNow("failure"));
}
// 输出如下内容:
// 这里一般写耗时操作
// 有返回值的future=success
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<String> asyncWithReturn = CompletableFuture.supplyAsync(() -> {
System.out.println("这里一般写耗时操作");
return "success";
});
System.out.println("有返回值的future=" + asyncWithReturn.getNow("failure"));
}
// 输出如下内容:
// 有返回值的future=failure
// 这里一般写耗时操作
注意没有Thread.sleep(1000)之间的区别。为什么会这样?因为没有的话,当我执行getNow()的时候,或许我的CompletableFuture还没有开始执行我的任务呢
辅助方法
public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs)
public static CompletableFuture<Object> anyOf(CompletableFuture<?>... cfs)
allOf 方法是当所有的 CompletableFuture 都执行完后执行计算
anyOf 方法是当任意一个 CompletableFuture 执行完后就会执行计算,计算的结果相同
代码示例如下:(事实上我们线上不会使用的这么简单)
// 演示allOf
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> calculation1 = CompletableFuture.supplyAsync(() -> {
System.out.println("这里经过了一些列复杂的计算,得到了结果");
return 1;
});
CompletableFuture<Integer> calculation2 = CompletableFuture.supplyAsync(() -> {
System.out.println("这里经过了一些列复杂的计算,得到了结果");
return 2;
});
CompletableFuture<Void> voidCompletableFuture = CompletableFuture.allOf(calculation1, calculation2);
System.out.println("测试一下allOf 之后的结果是咋回事voidCompletableFuture=" + voidCompletableFuture.get());
}
// 输出如下内容:
// 这里经过了一些列复杂的计算,得到了结果
// 这里经过了一些列复杂的计算,得到了结果
// 测试一下合并之后的结果是咋回事voidCompletableFuture=null
// 演示anyOf
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> calculation2 = CompletableFuture.supplyAsync(() -> {
System.out.println("这里经过了一些列复杂的计算,得到了结果--2");
return 2;
});
CompletableFuture<Integer> calculation1 = CompletableFuture.supplyAsync(() -> {
System.out.println("这里经过了一些列复杂的计算,得到了结果--1");
return 1;
});
CompletableFuture<Object> objectCompletableFuture = CompletableFuture.anyOf(calculation1, calculation2);
System.out.println("测试一下any之后的结果是咋回事voidCompletableFuture=" + objectCompletableFuture.get());
}
// 输出如下内容:
// 这里经过了一些列复杂的计算,得到了结果--2
// 这里经过了一些列复杂的计算,得到了结果--1
// 测试一下any之后的结果是咋回事voidCompletableFuture=1
CompletionStage讲解
CompletionStage 是一个接口,从命名上看得知是一个完成的阶段,它代表了一个特定的计算的阶段,可以同步或者异步的被完成。你可以把它看成一个计算流水线上的一个单元,并最终会产生一个最终结果,这意味着几个CompletionStage 可以串联起来,一个完成的阶段可以触发下一阶段的执行,接着触发下一次,再接着触发下一次,……….
总结 CompletableFuture 几个关键点:
- 计算可以由 Future ,Consumer 或者 Runnable 接口中的 apply,accept 或者 run 等方法表示
- 计算的执行主要有以下
(1)默认执行
(2)使用默认的 CompletionStage 的异步执行提供者异步执行。这些方法名使用 someActionAsync 这种格式表示
(3)使用 Executor 提供者异步执行。这些方法同样也是 someActionAsync 这种格式,但是会增加一个 Executor 参数
CompletableFuture 里大约有五十种方法,但是可以进行归类。但是有一些细则想提前说下,可以帮助大家加深理解:
- 下面的带Async后缀的都是异步方法,这不用解释太多。优秀源码一般都是极具规范的,所以后面所有出现了Async后缀的都是异步的意思
- thenApply()方法跟thenAccept()方法区别:方法中的Apply跟Accpet后缀,其实分别取自于Function跟Consumer两个函数式接口。Function的业务方法为
R apply(T t);是有返回值的;Consumer的业务方法为void accept(T t);是没有返回值的
变换类 thenApply:
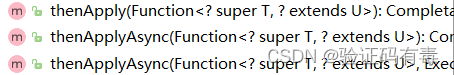
这里的关键入参是函数式接口Function。它的入参是上一个阶段计算后的结果,返回值是经过转化后结果。
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> calculation = CompletableFuture.supplyAsync(() -> {
System.out.println("这里经过了一些列复杂的计算,得到了结果--1");
return 1;
});
CompletableFuture<Integer> thenApply = calculation.thenApply(lastResult -> {
System.out.println("打印一下这个结果是不是上面返回的1, lastResult=" + lastResult);
int result = lastResult.intValue() * 10;
return result;
});
System.out.println("测试一下使用thenApply效果, result=" + thenApply.get());
}
// 输出如下内容:
// 这里经过了一些列复杂的计算,得到了结果--1
// 打印一下这个结果是不是上面返回的1, lastResult=1
// 测试一下使用thenApply效果, result=10
消费类 thenAccept:
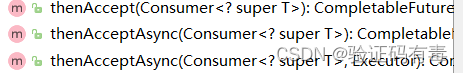
关键入参是函数式接口Consumer。它的入参是上一个阶段计算后的结果, 没有返回值。
跟上面的thenApply一样,只是没有返回值而已,这里就不演示了
执行操作类 thenRun:

对上一步的计算结果不关心,执行下一个操作,入参是一个Runnable的实例,表示上一步完成后执行的操作。
示例代码如下:(这个也是洒洒水,强调的是不同任务之间的协调调度顺序而已)
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> calculation = CompletableFuture.supplyAsync(() -> {
System.out.println("这里经过了一些列复杂的计算,得到了结果--1");
return 1;
});
calculation.thenRun(()->{
try {
System.out.println("测试一下使用thenRun效果, result=" + calculation.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
}
// 输出如下内容:
// 这里经过了一些列复杂的计算,得到了结果--1
// 测试一下使用thenRun效果, result=1
结合转化类:

thenCombine会在两个任务都执行完成后,把两个任务的结果合并成一个新的CompletableFuture,两个任务是相互独立的,并且没有先后顺序。需要上一步的处理返回值,并且other代表的CompletionStage 有返回值之后,利用这两个返回值,进行转换后返回指定类型的值。
两个CompletionStage是并行执行的,它们之间并没有先后依赖顺序,other并不会等待先前的CompletableFuture执行完毕后再执行。
示例代码如下:
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Integer> calculation1 = CompletableFuture.supplyAsync(() -> {
System.out.println("这里经过了一些列复杂的计算,得到了结果--1");
return 1;
});
CompletableFuture<Long> calculation2 = CompletableFuture.supplyAsync(() -> {
System.out.println("这里经过了一些列复杂的计算,得到了结果--2");
return 2L;
});
CompletableFuture<String> thenCombine = calculation1.thenCombine(calculation2, (mine, other) -> {
int i = mine.intValue();
long i2 = other.longValue();
System.out.println("这里打印一下i=" + i);
System.out.println("这里打印一下i2=" + i2);
long result = i + i2;
return String.valueOf(result);
});
System.out.println("测试一下thenCombine的效果,thenCombine=" + thenCombine.get());
}
// 输出如下内容:
// 这里经过了一些列复杂的计算,得到了结果--1
// 这里经过了一些列复杂的计算,得到了结果--2
// 这里打印一下i=1
// 这里打印一下i2=2
// 测试一下thenCombine的效果,thenCombine=3
结合转化类

thenCompose 可以用于组合多个CompletableFuture,将前一个任务的返回结果作为下一个任务的参数,它们之间存在着业务逻辑上的先后顺序。对于Compose可以连接两个CompletableFuture,其内部处理逻辑是当第一个CompletableFuture处理没有完成时会合并成一个CompletableFuture。如果处理完成,第二个future会紧接上一个CompletableFuture进行处理。
第一个CompletableFuture 的处理结果是第二个future需要的输入参数。
示例代码如下:
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<String> calculation1 = CompletableFuture.supplyAsync(() -> {
System.out.println("这里经过了一些列复杂的计算,得到了结果--1");
return "牛";
});
CompletableFuture<String> thenCompose = calculation1.thenCompose(lastResult -> CompletableFuture.supplyAsync(() -> lastResult + "逼"));
System.out.println("测试一下thenCompose的效果,thenCompose=" + thenCompose.get());
}
// 输出如下内容:
// 这里经过了一些列复杂的计算,得到了结果--1
// 测试一下thenCompose的效果,thenCompose=牛逼
结合消费类:

需要上一步的处理返回值,并且other代表的CompletionStage 有返回值之后,利用这两个返回值,进行消费
运行后执行类:

不关心这两个CompletionStage的结果,只关心这两个CompletionStage都执行完毕,之后再进行操作(Runnable)。
取最快转换类:

两个CompletionStage,谁计算的快,我就用那个CompletionStage的结果进行下一步的转化操作。现实开发场景中,总会碰到有两种渠道完成同一个事情,所以就可以调用这个方法,找一个最快的结果进行处理。
取最快消费类:
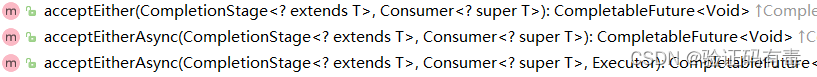
两个CompletionStage,谁计算的快,我就用那个CompletionStage的结果进行下一步的消费操作。
取最快运行后执行类:

两个CompletionStage,任何一个完成了都会执行下一步的操作(Runnable)。
异常补偿类:

当运行时出现了异常,可以通过exceptionally进行补偿。
运行后记录结果类:
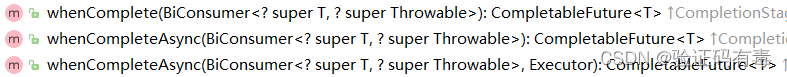
action执行完毕后它的结果返回原始的CompletableFuture的计算结果或者返回异常。所以不会对结果产生任何的作用。
运行后处理结果类:
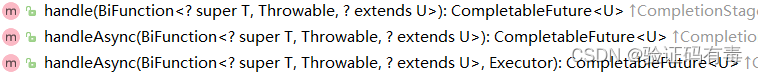
运行完成时,对结果的处理。这里的完成时有两种情况,一种是正常执行,返回值。另外一种是遇到异常抛出造成程序的中断。
学习总结
1.学习了join()方法
2.重温synchronized关键字和volatile关键字的基本用法
3.学习了object的wait()和notify()系列方法,以及通知等待机制的范式
4.拓展了CompletableFuture方法
















 2510
2510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











