







-
Structural Priors Guided Network for the Corneal Endothelial Cell Segmentation
摘要: 角膜内皮显微镜图像中模糊的细胞边界分割具有挑战性,影响临床参数估计的准确性。现有的深度学习方法仅考虑像素分类精度,缺乏对细胞结构知识的利用。因此,模糊的细胞边界分割是不连续的。本文提出了一种结构先验引导网络(SPG-Net)用于角膜内皮细胞分割。我们首先采用混合变压器卷积主干来捕获更多的全局上下文。然后,采用特征增强(FE)模块提高特征的表达能力,采用基于局部亲和的特征融合(LAFF)模块在层次特征之间传播结构信息。最后,我们引入了基于交叉熵和结构相似性指数度量(SSIM)的联合损失来监督像素级和结构级的训练过程。我们在四个角膜内皮数据集上比较了SPG-Net与各种最先进的方法。实验结果表明,SPG-Net能够缓解不连续的细胞边界分割问题,在像素级精度和结构保持性方面达到平衡。我们还评估了地面真实值和SPG-Net预测的参数估计的一致性。统计分析结果显示具有较好的一致性和相关性。

-
DEQ-MPI: A Deep Equilibrium Reconstruction With Learned Consistency for Magnetic Particle Imaging
摘要: 磁粒子成像(MPI)为追踪磁性纳米粒子提供了无与伦比的对比度和分辨率。一个常见的成像程序校准系统矩阵(SM),该系统矩阵用于重建后续扫描的数据。通过同时增强基于SM的数据一致性和基于图像先验的正则化解决病态重建问题。传统的手工先验不能捕获MPI图像的复杂属性,而基于学习先验的MPI方法存在推断时间长或泛化性能受限的问题。本文提出了一种基于学习数据一致性的深度平衡模型(DEQ-MPI)的物理驱动MPI重建方法。DEQ-MPI受深度学习中展开方法的启发,通过将神经网络增强为迭代优化来重建图像。然而,传统的展开方法在计算上受到限制,迭代次数很少,导致解不收敛,而且它们使用手工制作的一致性度量,可能会获得数据分布的次优捕获。DEQ-MPI反而训练了一个隐式映射,以最大限度地提高收敛解决方案的质量,并且它包含了一个学习过的一致性度量,以更好地考虑数据分布。仿真和实验数据表明,DEQ-MPI的图像质量和推断时间均优于最先进的MPI重建方法。

-
Hierarchical Knowledge Guided Learning for Real-World Retinal Disease Recognition
摘要:在现实世界中,医疗数据集往往呈现出长尾数据分布(即少数类别占据大部分数据,而大多数类别只有有限数量的样本),这导致了具有挑战性的长尾学习场景。近年来,眼科人工智能领域的数据集涉及40余种视网膜疾病,异常复杂,发病率多变。然而,超过30种疾病在全球患者队列中罕见。从建模的角度来看,在这些数据集上训练的大多数深度学习模型可能缺乏归纳到罕见疾病的能力,因为只有少数可用样本可供训练。此外,视网膜可能存在多种疾病,导致具有挑战性的标签共现场景,也称为多标签,这可能会在训练期间应用一些重新采样策略时引起问题。为了解决上述两个主要挑战,本文提出了一种新的方法,使深度神经网络能够从长尾眼底数据库学习,用于各种视网膜疾病的识别。首先,我们利用眼科的先验知识,使用层次感知的预训练来改进特征表示。其次,我们采用一种基于实例的类别平衡抽样策略来解决长尾医疗数据集下的标签共现问题。第三,我们引入了一种新的混合知识蒸馏,以训练一个偏倚较小的表示和分类器。我们在四个数据库中进行了广泛的实验,包括两个公共数据集和两个包含超过100万张眼底图像的内部数据库。实验结果表明,我们提出的方法在识别精度上优于最先进的竞争对手,特别是对这些罕见疾病。

-
An Efficient Deep Neural Network to Classify Large 3D Images With Small Objects
摘要:三维成像通过提供器官解剖的空间信息,使精确诊断成为可能。然而,使用3D图像来训练AI模型在计算上具有挑战性,因为它们的像素比2D图像多10倍或100倍。为了使用高分辨率的3D图像进行训练,卷积神经网络求助于降采样或将其投影到2D图像。我们提出了一种有效的替代方案,一种能够对全分辨率3D医学图像进行高效分类的神经网络。与现有的卷积神经网络相比,我们的网络,3D全局感知多实例分类器(3D- gmic),减少了77.98%-90.05%的GPU内存和91.23%-96.02%的计算。虽然它只使用图像级标签进行训练,而没有分割标签,但它通过提供像素级显著性地图来解释其预测。在纽约大学朗格尼健康中心收集的85 526例全视野二维乳腺摄影(FFDM)、合成二维乳腺摄影和三维乳腺摄影患者的数据集上,3D- gmic对三维乳腺摄影诊断乳腺恶性病变的AUC为0.831 (95% CI: 0.769 ~ 0.887)。这与GMIC在FFDM (0.816, 95% CI: 0.737 ~ 0.878)和合成2D (0.826, 95% CI: 0.754 ~ 0.884)上的分类性能相当,表明3D-GMIC在专注于更小比例输入的情况下成功分类了大型3D图像。因此,3D- gmic从由数亿像素组成的3D图像中识别和利用极小的感兴趣区域,极大地减少了相关的计算挑战。3D-GMIC对来自美国杜克大学医院的外部数据集BCS-DBT有较好的推广效果,AUC为0.848 (95% CI: 0.798 ~ 0.896)。

-
Transformer-Based Spatio-Temporal Analysis for Classification of Aortic Stenosis Severity From Echocardiography Cine Series
摘要: 主动脉瓣狭窄(AS)以主动脉瓣运动受限和钙化为特征,是最致命的心脏瓣膜病。AS严重程度的评估通常由心脏科专家通过超声心动图对瓣膜血流的多普勒测量来完成。然而,这限制了对AS的评估需要有专家的医院提供全面的超声心动图服务。由于准确的多普勒采集需要大量的临床训练,因此在本文中,我们提出了一种深度学习框架,以确定仅基于二维超声心动图数据的As检测和严重程度分类的可行性。我们证明,我们提出的时空架构有效地结合了主动脉瓣的解剖特征和运动,从而对AS的严重程度进行分级。我们的模型可以处理不同长度的心脏回声电影系列,并且可以在没有明确监督的情况下识别出对AS诊断最有信息的帧。我们提出了一个实证研究,该模型如何在没有任何监督和框架级注释的情况下学习心脏周期的各个阶段。我们的架构在私有和公共数据集上的性能优于最先进的结果,在私有和公共数据集上分别实现了95.2%和91.5%的AS检测,以及78.1%和83.8%的AS严重程度分类。值得注意的是,由于缺少用于AS的大型公共视频数据集,我们对公共数据集的架构做了轻微的调整。此外,我们的方法解决了使用临床超声数据训练深度网络的常见问题,如低信噪比和经常无信息的帧。我们的源代码可以在:https://github.com/neda77aa/FTC.git获得

-
Non-Isocentric Geometry for Next-Generation Tomosynthesis With Super-Resolution
摘要: 我们在宾夕法尼亚大学(UPenn)的实验室正在研究数字乳腺断层合成的新设计。我们构建了下一代断层合成系统,该系统具有非等中心的几何形状(探测器的优劣运动)。本文考察了这一设计对图像质量的四个指标的影响。首先,在比检测器像素更小的条件下进行重建,分析混叠现象。混叠通过一个r因子的理论模型来评估,r因子是一个度量,计算在重建正弦对象的傅里叶变换中混叠信号相对于输入信号的幅值。用条形图(表示混叠的空间变化)和360°星形图(表示混叠的方向各向异性)对混叠进行实验评估。其次,对垂直于探测器方向的点扩散函数(PSF)进行建模,以评估面外模糊。第三,在一个由宾夕法尼亚大学开发,计算机成像参考系统(CIRS), Inc. (Norfolk, VA)制造的仿真体模中分析功率谱。最后在CIRS Model 020 BR3D乳腺成像模体中对钙化进行信噪比(SNR)分析;即平均钙化信号相对于背景组织噪声。在非等中心几何图像中,图像质量普遍较好:在理论和实验重建中,用比探测器更小的像素制备的混叠伪影被抑制。大多数位置的PSF宽度也减小。解剖噪声降低。最后,提高了钙化检测的信噪比。(小像素重建的潜在代价是降低信噪比;然而,通过探测器运动采集,信噪比仍然有所提高。)综上所述,非等中心几何结构在几个方面提高了图像质量。 -
An Interpretable and Accurate Deep-Learning Diagnosis Framework Modeled With Fully and Semi-Supervised Reciprocal Learning
摘要: 自动化深度学习分类器在临床实践中的应用有望简化诊断流程,提高诊断准确性,但这些分类器的接受程度取决于其准确性和可解释性。一般来说,准确的深度学习分类器提供的模型可解释性很少,而可解释性模型的分类准确性不具有竞争力。在本文中,我们引入了一种新的深度学习诊断框架,称为InterNRL,其设计目标是高度准确和可解读。InterNRL由一个学生-教师框架组成,其中学生模型是一个可解释的基于原型的分类器(ProtoPNet),而教师是一个准确的全局图像分类器(GlobalNet)。这两个分类器通过一种新颖的互惠学习范式相互优化,其中学生ProtoPNet从教师GlobalNet产生的最优伪标签学习,而GlobalNet从ProtoPNet的分类性能和伪标签学习。这种互惠学习模式使InterNRL在完全监督和半监督学习场景下都能灵活优化,在乳腺癌和视网膜疾病诊断的两种场景中都达到了最先进的分类性能。此外,依靠弱标记的训练图像,InterNRL也取得了优于其他竞争方法的乳腺癌定位和脑肿瘤分割结果。

-
Pattern-Aware Transformer: Hierarchical Pattern Propagation in Sequential Medical Images
摘要: 本文研究了在医学影像任务中,如何有效挖掘序列图像之间的上下文信息并联合建模。不同于现有的通过逐点标记编码来建模序列相关性的方法,本文开发了一种新的层次模式感知标记化策略。它独立地、分层地处理不同的视觉模式,既保证了不同模式表示下注意力聚集的灵活性,又同时保留了局部和全局信息。在此基础上,我们提出了一种基于全局-局部双路径模式感知交叉注意机制的模式感知转换器(pattern-aware Transformer, PATrans),以实现序列图像之间的分层模式匹配和传播。此外,PATrans是即插即用的,可以无缝集成到各种骨干网络中,用于各种下游序列建模任务。我们展示了它在视频对象检测和3D立体语义分割任务中的四个领域和五个基准的一般应用范式。令人印象深刻的是,PATrans在所有这些基准(即CVC-Video(92.3%检测F1)、ASU-Mayo(99.1%定位F1)、肺肿瘤(78.59% DSC)、鼻咽肿瘤(75.50% DSC)和肾肿瘤(87.53% DSC))中设置了最新的技术。代码和模型可在https://github.com/GGaoxiang/PATrans获取。

-
Hierarchical-Instance Contrastive Learning for Minority Detection on Imbalanced Medical Datasets
摘要:深度学习方法常受到数据不平衡、数据饥渴等问题的阻碍。在医学影像学中,恶性或罕见疾病常属于数据集中的少数类,具有分布多样化的特点。此外,标签的不足和看不到的案例也给少数民族班的培训带来了难题。针对上述问题,我们提出了一种新的层次实例对比学习(HCLe)方法,通过在训练阶段只涉及大多数类的数据来检测少数类。为了解决大多数类别的类内分布不一致的问题,我们的方法引入了两个分支,其中第一个分支使用了一个带有三个约束函数的自编码器网络来有效地提取图像级特征,第二个分支考虑了大多数类别的分层样本之间的特征一致性,设计了一个新的对比学习网络。提出的方法进一步完善了一个多样化的小批量策略,使少数类的识别在多种条件下。在三个不同疾病和模式的数据集上进行了大量的实验以评估所提出的方法。实验结果表明,该方法的性能优于现有方法。
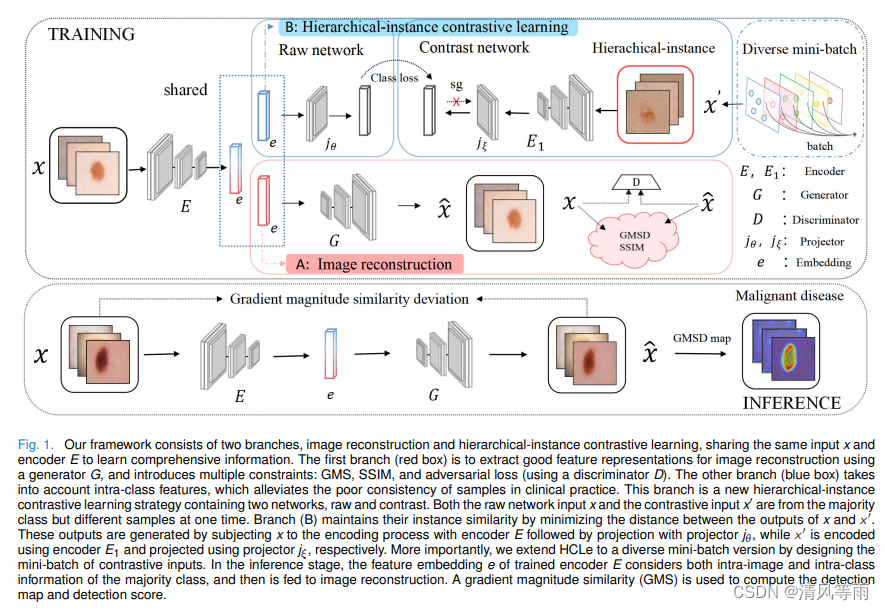
-
Developing Explainable Deep Model for Discovering Novel Control Mechanism of Neuro-Dynamics
摘要:人脑是一个由许多相互作用的成分组成的复杂系统。一个设计良好的计算模型,通常以偏微分方程(PDEs)的形式,对于理解可以解释动态和自组织行为的工作机制至关重要。然而,模型的制定和参数往往是基于预定义的领域特定知识进行经验调整,这落后于从前所未有的大量时空数据中发现新机制的新兴范式。为了解决这一局限性,我们试图将深度神经网络的力量与复杂系统的物理原理联系起来,从而使我们能够设计可解释的深度模型,以揭示人类大脑(最复杂的复杂系统)在与外部刺激交互时如何保持可控功能的机制作用。本着最优控制的精神,我们提出了一个统一的框架来设计一个可解释的深度模型,描述潜在的神经生物学过程的动态行为,使我们能够在系统水平上理解潜在的控制机制。我们揭示了阿尔茨海默病的病理生理机制,并达到了疾病进展可控的程度。与传统的黑箱深度模型相比,深入的系统层面的理解能够提高对疾病进展的预测准确性和对疾病病因的解释能力。

-
Omnidirectional Monolithic Marker for Intra-Operative MR-Based Positional Sensing in Closed MRI
摘要:我们设计了一种用于基于磁共振(MR)的位置跟踪的电感耦合射频(ICRF)标记物,能够在二次激发闭合磁共振成像(MRI)中稳健地增加所有扫描方向的跟踪信号。该标记采用了三个弯曲的谐振电路,完全覆盖了一个圆柱形的表面,包围了信号源。每个谐振电路都是在柔性印刷电路板(FPC)上整块制作的平面螺旋电感并联平板电容器,并通过弯曲实现曲面结构。所构建的标记的大小为Ø3-mm ×5 -mm,质量因子>在1.5 T MRI上验证其追踪性能。因此,在3轴360°旋转下,标记仍然是一个高正对比点。在距等中心56 mm的位移下,标记点可以精确定位,最大误差为0.56 mm,固有标准差为0.1 mm。由于图像对比度高,所呈现的标记能够在3D中自动和实时跟踪,而不依赖于其与MRI扫描仪接收线圈的方向。结合其小的形状因子,提出的标记将有助于稳健的和无线的基于mr的跟踪干预和临床诊断。这种方法针对的应用程序可能涉及所有轴(X-Y-Z)的旋转变化。

-
The CathEye: A Forward-Looking Ultrasound Catheter for Image-Guided Cardiovascular Procedures
摘要:以导管为基础的手术通常由x线引导,其缺点是软组织对比度低,只能提供三维体积的二维投影图像。血管内超声(IVUS)可作为一种补充影像学技术。前视导管可用于观察沿导管路径的阻塞。CathEye系统机械地操纵单元件换能器,从不规则间隔的二维扫描模式生成前视表面重建。该可导向导管利用带有电缆的可伸缩框架来独立于血管弯曲度操纵远端。通过测量电缆位移估计尖端位置,并使用单元件传感器创建成像工作空间的表面重构。通过琼脂模体和体外慢性完全闭塞(CTO)样本,在导管局限于各种弯曲路径时,测试了CathEye的成像能力。无论路径是否弯曲,CathEye均能保持相似的扫描模式,并能够再现成像靶点的主要特征,如孔洞和挤压。本研究证明了使用CathEye进行前瞻性IVUS的可行性。CathEye机制可应用于视野(FOV)受限的其他成像模式,并代表了与图像引导完全集成的介入设备的基础。 -
Nucleus-Aware Self-Supervised Pretraining Using Unpaired Image-to-Image Translation for Histopathology Images
摘要:自我监督预训练试图通过从未标记数据中获取有效特征来提高模型性能,并在组织病理学图像领域证明了其有效性。尽管它取得了成功,但很少有研究专注于提取对病理分析至关重要的核水平信息。在这项工作中,我们提出了一种新的基于核感知的自我监督的组织病理学图像预训练框架。该框架旨在通过组织病理学图像和伪掩膜图像之间的非配对图像-图像转换获取细胞核的形态和分布信息。生成过程通过条件和随机两种风格的表示进行调制,确保生成的组织病理学图像的真实性和多样性,用于预训练。此外,利用实例分割引导策略来获取实例级信息。在7个数据集上的实验表明,本文提出的预训练方法在Kather分类、多实例学习和5个基于迁移学习协议的密集预测任务上优于监督方法,在8个半监督任务上优于其他自我监督方法。我们的项目在https://github.com/zhiyuns/UNITPathSSL上公开。

-
A Multi-Scale Fusion and Transformer Based Registration Guided Speckle Noise Reduction for OCT Images
摘要:光学相干断层扫描(Optical coherence tomography, OCT)由于基于低相干干涉,图像不可避免地会受到散斑噪声的影响。多帧平均法是降低散斑噪声的有效方法之一。在平均之前,图像之间的错位必须校正。本文提出了一种基于多尺度融合和互感器(MsFTMorph)的形变视网膜OCT图像配准方法,以减少采集过程中引起的图像间的不匹配。该方法利用卷积视觉转换器获取全局连通性和局域性,并采用多分辨率融合策略学习全局仿射变换。与其他最新的配准方法的对比实验表明,本文方法取得了较高的配准精度。在配准的指导下,后续的多帧平均算法对斑点噪声的抑制效果更好。噪声被抑制,而边缘可以被保留。此外,我们提出的方法具有较强的跨域泛化性,可以直接应用于不同模式的不同扫描器获取的图像。

-
OSCNet: Orientation-Shared Convolutional Network for CT Metal Artifact Learning
摘要:x线计算机体层摄影术(computed tomography, CT)已广泛应用于临床,用于疾病诊断和影像引导介入治疗。然而,患者体内的金属会对恢复后的CT图像造成不利的伪影。尽管对于减少金属伪影(MAR)任务,现有的大多数基于深度学习的方法都有一些局限性。关键问题是,这些方法中的大多数没有充分利用这一特定的MAR任务的重要先验知识。因此,在本文中,我们仔细研究了呈现旋转对称条纹图案的金属伪影的固有特性。然后,我们专门提出了一种方向共享的卷积表示机制,以适应这种物理先验结构,并利用基于傅里叶级数展开的滤波器参数化对伪影进行建模,可以将金属伪影从人体组织中精细地分离出来。采用经典的近端梯度算法求解模型,然后利用深度展开技术,可以轻松地构建相应的方向共享卷积网络,称为OSCNet。此外,考虑到不同大小和类型的金属会导致不同的伪影模式(如伪影强度),为了更好地提高伪影学习的灵活性,并充分利用迭代阶段的重建结果进行信息传播,我们设计了一个简单而有效的伪影动态卷积表示子网络。通过简单地将子网络集成到提出的OSCNet框架中,我们进一步构建了一个更灵活的网络结构,称为OSCNet+,提高了泛化性能。通过在合成数据集和临床数据集上进行的大量实验,我们全面证实了我们提出的方法的有效性。代码将在https://github.com/hongwang01/OSCNet上发布。

-
Adversarially Trained Persistent Homology Based Graph Convolutional Network for Disease Identification Using Brain Connectivity
摘要:脑疾病的传播与大脑结构和功能连接网络的特征性改变有关。图卷积网络(GCNs)因其强大的图嵌入能力来表征脑网络的非欧氏结构而被用于识别疾病特异性网络表示。然而,现有的GCNs通常专注于学习区分感兴趣区域(ROI)的特征,往往忽略了能够集成大脑活动连接组模式的重要拓扑信息。此外,大多数方法未能考虑GCNs对脑网络属性扰动的脆弱性,这大大降低了诊断结果的可靠性。在这项研究中,我们提出了一种对抗训练的基于持续同源的图卷积网络(ATPGCN)来捕获疾病特异性的脑连接组模式,并对脑疾病进行分类。首先,使用不同的神经影像模式构建大脑的功能/结构连接。然后,我们开发了一种新的策略,将来自脑代数拓扑分析的持久同源特征与GCN模型的全局池化层的读出特征连接起来,以协同学习个体层面的表示。最后,我们通过针对来自临床的风险roi来模拟对抗扰动,并将其纳入训练循环,以评估模型的鲁棒性。在三个独立数据集上的实验结果表明,ATPGCN在疾病识别方面优于现有的分类方法,并且对网络结构中的微小扰动具有鲁棒性。我们的代码可以在https://github.com/CYB08/ATPGCN获取。
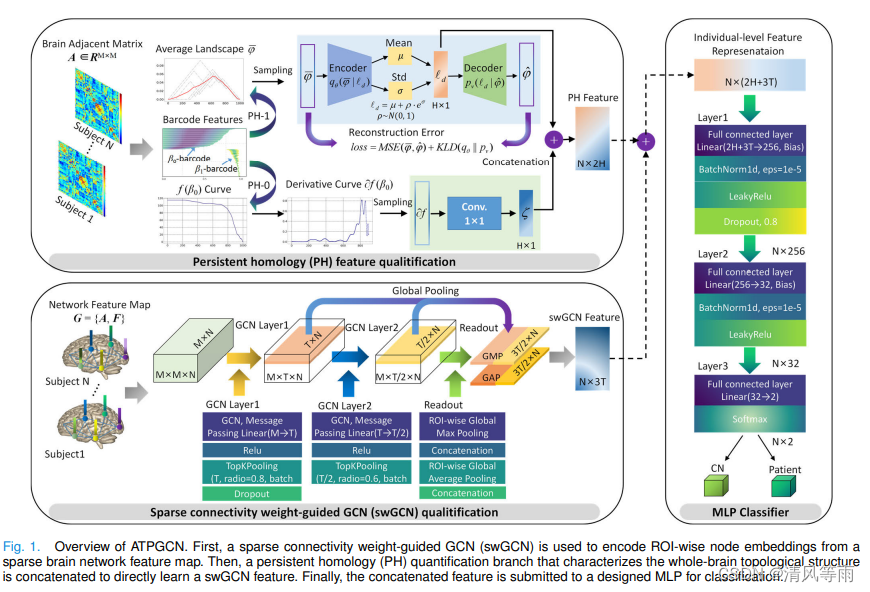
-
DTR-Net: Dual-Space 3D Tooth Model Reconstruction From Panoramic X-Ray Images
摘要:在数字化口腔医学中,锥形束ct (CBCT)可以提供完整的三维牙体模型,但长期以来存在辐射剂量过大和费用较高的问题。因此,基于二维全景x线图像的三维牙模型重建更具成本效益,在临床应用中引起了极大的兴趣。在本文中,我们提出了一种新的双空间框架,即DTR-Net,从二维全景x射线图像在图像和几何空间中重建三维牙齿模型。具体而言,在图像空间中,我们在任务导向的牙齿分割网络的引导下,以协同训练的方式,应用二维到三维生成模型来恢复CBCT图像的强度。同时,在几何空间中,我们受益于连续空间中的隐函数网络,学习使用点来获取具有几何性质的复杂牙齿形状。实验结果表明,我们提出的DTR-Net在三维牙模型重建中无论从定量还是定性上都达到了最先进的性能,表明了其在口腔实践中的潜在应用。

-
Clinically-Inspired Multi-Agent Transformers for Disease Trajectory Forecasting From Multimodal Data
摘要:深度神经网络常应用于医学图像,实现医学诊断问题的自动化。然而,医师通常面临的一个更具有临床意义的问题是如何预测疾病的未来发展轨迹。目前的预后或疾病轨迹预测方法往往需要领域知识,且应用较为复杂。在本文中,我们将预后预测问题表述为一对多预测问题。受两名代理人(一名放射科医师和一名全科医师)的临床决策过程的启发,我们通过两个相互共享信息的基于变压器的组件来预测预后。该框架中的第一个变压器旨在分析影像数据,第二个变压器利用其内部状态作为输入,并将其与辅助临床数据融合。问题的时间性质是在变压器状态内建模的,允许我们将预测问题作为一个多任务分类,为此我们提出了一个新的损失。我们证明了我们的方法在预测结构性膝骨关节炎的发展和直接从原始多模态数据预测阿尔茨海默病临床状态方面的有效性。所提出的方法在性能和校准方面优于多种最先进的基线,这两者都是真实世界的应用所需要的。我们方法的开源实现在https://github.com/Oulu-IMEDS/CLIMATv2上公开。

-
AIROGS: Artificial Intelligence for Robust Glaucoma Screening Challenge
摘要:青光眼的早期发现对预防视力损害至关重要。人工智能(AI)可用于分析彩色眼底照片(CFPs),以一种具有成本效益的方式,使青光眼筛查更容易获得。虽然人工智能青光眼筛查模型在实验室环境中显示出了有前景的结果,但由于存在分布外和低质量的图像,它们在真实世界场景中的性能显著下降。为了解决这一问题,我们提出了人工智能稳健青光眼筛查(AIROGS)挑战。这一挑战包括来自约60,000例患者和500个不同筛查中心的约113,000张图像的大型数据集,这鼓励我们开发出对不可分级和意外输入数据稳健的算法。我们在本文中评估了14个团队的解决方案,发现最好的团队与20名眼科专家和视光师的表现相似。在动态检测不可分级图像时,得分最高的团队获得了0.99 (95% CI: 0.98 ~ 0.99)的受试者工作特征曲线下面积。此外,在其他三个公开的数据集上测试时,许多算法表现出了稳健的性能。这些结果证明了稳健的人工智能青光眼筛查的可行性。

-
Joint Cross-Attention Network With Deep Modality Prior for Fast MRI Reconstruction
摘要:目前基于深度学习的加速多线圈磁共振成像(MRI)重建模型主要是基于卷积神经网络(CNN)的单模态下采样k空间数据。虽然MRI快速重建常采用双域信息和数据一致性约束,但现有模型的性能仍然受到3个因素的限制:线圈灵敏度估计不准确、结构先验利用不足和CNN的诱导偏倚。为了解决这些挑战,我们提出了一种基于展开的联合交叉注意网络(jCAN),利用已获得的受试者内部数据的深度引导。特别是,为了提高线圈灵敏度估计的性能,我们同时优化了潜在磁共振图像和灵敏度图(SM)。此外,我们在SM估计中引入了门控层和高斯层,以缓解“离焦”和“过耦合”的影响,进一步改善SM估计。为了增强模型的表达能力,我们在图像和k空间域分别部署了视觉转换器(ViT)和CNN。此外,我们利用预获得的受试者内扫描作为参考模式,通过自我和交叉注意方案来指导下采样目标模式的重建。在公共膝关节和内部大脑数据集上的实验结果表明,在不同的加速度因子和采样面罩下,所提出的jCAN在SSIM和PSNR方面大大优于最先进的方法。我们的代码可以在https://github.com/sunkg/jCAN上公开。

-
RibSeg v2: A Large-Scale Benchmark for Rib Labeling and Anatomical Centerline Extraction
摘要:肋骨自动标记和解剖中线提取是各种临床应用的共同前提。以前的研究要么使用社区无法获得的内部数据集,要么关注肋骨分割,忽视了肋骨标记的临床意义。为了解决这些问题,我们扩展了我们之前关于二元肋骨分割任务的数据集(RibSeg)到一个综合的基准,命名为RibSeg v2,使用660个CT扫描(总共15,466个肋骨)和由专家手工检查的肋骨标记和解剖中心线提取的注释。基于RibSeg v2,我们开发了包括基于深度学习的肋骨标记方法和基于骨架化的中心线提取方法的流程。为了提高计算效率,我们提出了一种CT扫描的稀疏点云表示方法,并与标准密集体素网格进行了比较。此外,我们设计并分析了评估指标,以解决每个任务的关键挑战。我们的数据集、代码和模型可以在线获取,以便于在https://github.com/M3DV/RibSeg上进行公开研究。

-
ReconFormer: Accelerated MRI Reconstruction Using Recurrent Transformer
摘要:磁共振成像(MRI)的加速重建过程是一个具有挑战性的病态逆问题,由于在k空间中存在过多的欠采样操作。在本文中,我们提出了一种用于MRI重建的递归Transformer模型,即ReconFormer,它可以从高度欠采样的k空间数据中迭代重建高保真的磁共振图像(例如,高达8×加速度)。特别是,提出的体系结构是建立在循环金字塔变压器层(rptl)上的。该方法的核心设计是递归尺度关注(Recurrent Scale-wise Attention, RSA),它联合利用每个架构单元内在的多尺度信息以及深度特征相关性通过递归状态的依赖性。此外,受益于其反复出现的特性,ReconFormer与其他基线相比是轻量级的,并且只包含1.1 M可训练参数。我们在不同磁共振序列的多个数据集上验证了ReconFormer的有效性,结果表明它在参数效率更高的情况下比目前最先进的方法取得了显著的改进。实现代码和预先训练的权重可在https://github.com/guopengf/ReconFormer获得。

-
Self-Supervised Multi-Scale Cropping and Simple Masked Attentive Predicting for Lung CT-Scan Anomaly Detection
摘要:基于正态数据的非分布检测器在医学图像异常检测中得到了广泛的应用。然而,在不知晓异常类型的情况下检测局部和细微的异常给肺部ct扫描图像异常检测带来了挑战。在本文中,我们提出了一个自我监督框架,通过多尺度裁剪和简单的掩蔽注意预测来学习肺部ct扫描图像的表示,该框架能够构建一个强大的分布外检测器。首先,我们提出了CropMixPaste,这是一种自我监督的增强任务,用于生成密度阴影样的异常,鼓励模型检测肺部ct扫描图像的局部不规则。然后,我们提出了一种自我监督重建块,命名为简单掩蔽注意预测块(SMAPB),通过预测掩蔽上下文信息来更好地细化局部特征。最后,利用自监督任务学习到的表示,构建出一个分布外检测器。在真实肺CT扫描数据集上的结果表明,与现有方法相比,我们提出的方法是有效和优越的。


















04-10
 572
572
572
03-11
1721
1721
02-23
906
906
03-24
2074
2074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









