







Flink实际问题以及知识点
- 1 状态原理
- 2.状态是什么东西?有了状态能做什么?
- 3.为什么离线计算中不提状态,实时计算老是提到状态这个概念?状态到底在实时计算中解决了什么问题?
- 4.有了状态、为什么又出现了状态管理的概念?
- 5.怎么学习 Flink 中的状态、状态管理相关的概念呢?
- 6.Flink 中状态的分类?
- 7.Flink 中状态的使用方式?
- 8.Flink 状态后端的分类及使用建议?
- 9.Flink 中状态的能力扩展 - TTL?
- 10.Flink 中状态 TTL 的原理机制?
- 11.Flink Checkpoint 的运行机制?
- 12.Flink Checkpoint 的配置?
- 13.Flink Checkpoint 在 HDFS 的存储格式?
- 14.Flink Checkpoint 的恢复机制?
- 15.Flink SQL 的 State 使用?
- 16.Flink 状态的误用之痛?
- 1.1 状态、状态后端、Checkpoint 三者之间的区别及关系?
- 1.2 把状态后端从 FileSystem 变为 RocksDB 后,Flink 任务状态存储会发生那些变化?
- 1.3 什么样的业务场景你会选择 filesystem,什么样的业务场景你会选 rocksdb 状态后端?
- 1.4 Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是 onReadAndWrite
- 2 时间窗口
- 3 常见优化
- 3.1 为什么 Flink DataStream API 在函数入参或者出参有泛型时,不能使用 lambda 表达式?
- 3.2 Flink 为什么强调 function 实现时,实例化的变量要实现 serializable 接口?
- 3.3 Flink 的并行度可以通过哪几种方式设置,优先级关系是什么?
- 3.4 你是怎么合理的评估 Flink 任务的并行度?
- 3.5 你是怎么合理评估任务最大并行度?
- 3.6 生产环境中,如何快速判断哪个算子存在反压呢?或者说哪个算子出现了性能问题?
- 3.7 反压有哪些危害?
- 3.8 经常碰到哪些问题会任务反压?
- 3.9 怎么缓解、解决任务反压的情况?
- 3.10 实时数据延迟是怎么监控的?报警策略又是怎么制定的?
- 3.11 通过什么样的监控及保障手段来保障实时指标的质量?
- 3.12 operator-state 和 keyed-state 两者的区别?
- 3.13 你认为以后 Flink SQL 的发展趋势是 unbounded 类 SQL 为主还是窗口类 SQL 为主?原因?
- 一、在实时数仓的分层设计中,具体的分层设计方案是怎样的?和离线数仓又有什么区别?你设计的实时数仓是怎么兼顾时效性和通用性的?
- 二、你们公司的实时数仓用到的维表都有哪些类型?分别是通过什么样的方式构建的?
- 三、你碰到过哪些数据倾斜的问题,又是怎么缓解或避免数据倾斜问题的?
- 四、你一般是将实时数据存储到哪里提供对外服务?有没有标准的数据服务方式?
- 五、你们公司在遇到大促时是怎么估算实时任务资源的,有没有成体系的方案可以参考?
- 六、ValueState 和 MapState 各自适合的应用场景?
- 七、Flink 任务 failover 之后,可能会重复写出数据到 Sink 中,你们公司是怎么做到端对端 exactly-once 的?
- 八、OLAP 引擎那么多,是因为 ClickHouse 的哪个特点促使它的性能的突出?
- 九、ClickHouse 不支持高并发,这是真的吗?Redis支持高并发这也是真的吗?
- 十、让你使用用户心跳日志(20s 上报一次)计算同时在线用户、DAU 指标,你怎么设计链路?
- 十一、Flink 配置 State TTL 时都有哪些配置项?每种配置项的作用?
- 十二、Flink State TTL 是怎么做到数据过期的?
1 状态原理
2.状态是什么东西?有了状态能做什么?
大家需要明白:状态不仅仅只限于 Flink 的状态。状态其实是一个普遍存在的东西。
首先来看看状态的一个官方的定义:当前计算流程需要依赖到之前计算的结果,那么之前计算的结果就是状态。
但是大家一定要注意,这里所说的状态不仅仅只限于 Flink 的状态。状态其实是一个普遍存在的东西。举几个例子:
⭐ 生活中的例子:
-
为什么我知道我的面前放着一台电脑?因为眼睛接收到外界的图案,然后我的大脑接收到这个眼睛传输的图案信息后,拿记忆中存储的图案进行对比,匹配得到这是电脑,所以我才识别除了这是一台电脑,其中记忆中存储的图案就是状态;
-
比如日久生情,为什么感情会越来越深,因为今天的感情 = 今天积累的感情 + 以前积累的感情,以前积累的感情就是状态。其实可以看到生活中无处不在都有状态!
⭐ web server 应用中的状态:
- 打开 github 页面,列表展示了我的归属仓库。其流程就是 web client 发给 web server 去查询我的归属仓库,web server 接收到请求之后,然后去存储引擎中进行查询匹配返回。那么存储引擎中存储的内容就是状态。
⭐ Flink 应用中的状态:
-
计算最常见的 DAU 指标,那么必然需要做 id 去重,涉及到去重时,就要存储历史所有来过的的 id。
在去重场景下,我在程序中使用一个 Set存储 id,然后用于去重,算不算状态?
答案:算,只要你的当前数据的处理计算依赖到之前的数据,就算做状态。
3.为什么离线计算中不提状态,实时计算老是提到状态这个概念?状态到底在实时计算中解决了什么问题?
其实在实时计算中的状态的功能:主要体现在任务可以做到失败重启后没有数据质量、时效问题。
我们来对比一下一个离线任务和实时任务的在任务失败重启时候的区别。
⭐ 离线任务失败重启:重新读一遍输入数据,然后重新计算一遍,没有啥大问题,大不了产出慢一些。
⭐ 实时任务失败重启:实时任务一般都是 7x24 小时 long run 的,挂了之后,就会有以下两个问题。首先给一个实际场景:一个消费上游 Kafka,使用 Set去重计算 DAU 的实时任务。
-
数据质量问题:当这个实时任务挂了之后恢复,Set空了,这时候任务再继续从上次失败的 Offset 消费 Kafka 产出数据,则产出的数据就是错误数据了。
这时候可能会提出疑问,计算 DAU 场景的话,这个任务挂了我重新从今天 0 点开始消费 Kafka 不就得了?
这个观点没有错,其实这就是下面即将说的第二个问题。
-
数据时效问题:一定要记得,你是一个实时任务,产出的指标是有时效性(主要是时延)要求的。你可以从今天 0 点开始重新消费,但是你回溯数据也是需要时间的。
举例:中午 12 点挂了,实时任务重新回溯 12 个小时的数据能在 1 分钟之内完成嘛?大多数场景下是不能的!一般都要回溯几个小时,这就是实时场景中的数据时效问题。
那当我们把状态给 “管理” 起来时,上面的两个问题就可以迎刃而解。还是相同的计算任务、相同的业务场景:
当我们把 Set这个数据结构定期(每隔 1min)的给存储到 HDFS 上面时,任务挂了、恢复之后。我们的任务还可以从 HDFS 上面把这个数据给读回来,接着从最新的一个 Kafka Offset 继续计算就可以,这样即没有数据质量问题,也没有数据时效性问题。
所以这就是为什么实时任务中老是提到 状态、状态管理 这些个概念的原因!
⭐ 那么!离线任务真的是没有状态、状态管理这些个概念这个概念嘛?
离线中其实也有,举个例子 Remote Shuffle Service,比如 Spark Remote Shuffle Service。
一个常见的离线任务运行时,通常都由几个 Stage 组成,比如有 1,2,3,4,5 个 Stage 顺序执行,当第 4 个 Stage 运行挂了之后,离线任务就要从第 1 个 Stage 重新开始执行,这样的话,执行效率是非常低的。
那么这个场景下有没有办法做到第 4 个 Stage 挂了,我们只重新运行第 4 个 Stage 呢?
当然有解法,我们可以将每一个 Stage 的结果保存下来,比如第 3 个 Stage 运行完成之后,将结果保存到远程的服务,当第 4 个 Stage 任务挂了之后,只需要从远程服务将第 3 个 Stage 结果拿来重新执行就行。
而 Remote Shuffle Service 的功能就是将每一个 Stage 的运行结果存储到一个独立的 Service 上面,当第 4 个 Stage fail 之后重新恢复时,可以直接从第 4 个 Stage 开始执行。
那么这里其实也涉及到了状态的概念。对于整个任务来说,这里面的每个 Stage 的结果就是状态,Remote Shuffle Service 就起到了 “管理” 状态 的作用。
⭐ 那么!实时任务真的只能依赖状态、状态管理嘛?
也不一定,举个例子,一个消费 Kafka,计算一个分钟级别的同时在线用户数(TUMBLE 1 min)的实时任务,在任务挂了之后,其实可以完全不依赖状态,直接从前几分钟的 Kafka Offset 去回溯一下数据也可以,能满足时效性的同时,也可以满足数据质量。
4.有了状态、为什么又出现了状态管理的概念?
看完上一小节,相信已经知道了实时计算中提到的状态的概念其实重点不止在于状态本身,更重要的在于强调 “管理” 状态。
一个实时任务光有状态是没用的,我们要把这个状态 “管理” 起来,即上节案例中的把 Set定期的存储到远程 HDFS 上,离线任务将中间结果保存到 Remote Shuffle Service 上。只有这样才能在任务 failover 后将状态恢复,保障数据质量、时效。
而在 Flink 中状态管理的模块就是我们所熟知的 Flink Checkpoint \ Savepoint
5.怎么学习 Flink 中的状态、状态管理相关的概念呢?
在 Flink 中关于状态、状态管理主要是有 3 个概念:
⭐ 状态:指 Flink 程序中的状态数据,也能代指用户在使用 DataStream API 编写程序来操作 State 的接口。
你在 Flink 中见到的 ValueState、MapState 等就是指状态接口。你可以通过 MapState.put(key, value) 去往 MapState 中存储数据,MapState.get(key) 去获取数据。这也是你能直接接触、操作状态的一层。
⭐ 状态后端:做状态数据(持久化,restore)的工具就叫做状态后端。比如你在 Flink 中见到的 RocksDB、FileSystem 的概念就是指状态后端。这些状态后端就是实际存储上面的状态数据的。比如配置了 RocksDB 作为状态后端,MapState 的数据就会存储在 RocksDB 中。
再引申一下,大家也可以理解为:应用中有一份状态数据,把这份状态数据存储到 MySQL 中,这个 MySQL 就能叫做状态后端
⭐ Checkpoint、Savepoint:协调整个任务,将 Flink 任务本地机器中存储在状态后端的状态去同步到远程文件存储系统(比如 HDFS)的过程就叫 Checkpoint、Savepoint。
当我们了解了这 3 个概念之后,继续往下看实际我们怎么使用 Flink 状态。
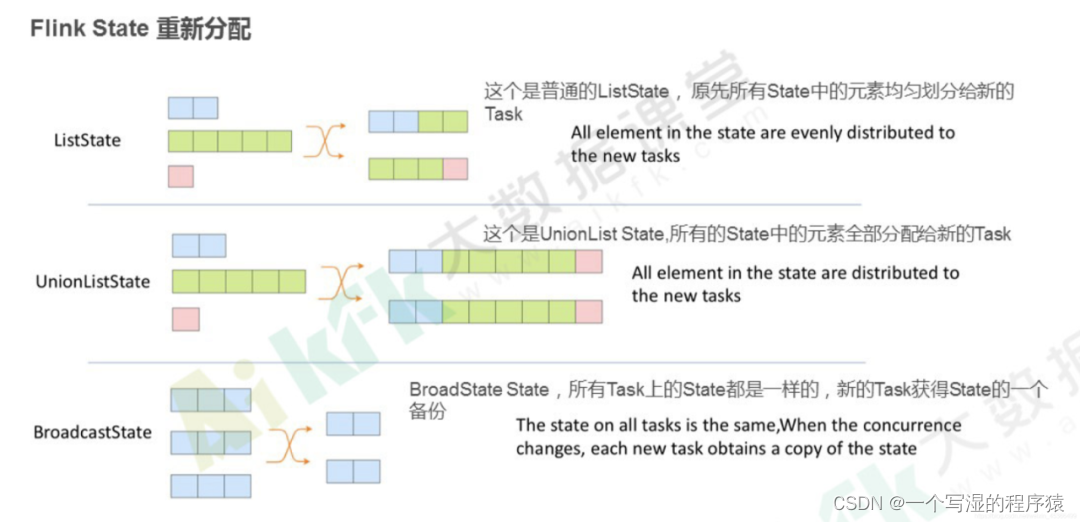
6.Flink 中状态的分类?
Flink 中的状态分类有两大类,我们可以在很多博客文章上面看到:Managed State 和 Raw State。
但是实际上生产开发中基本只会用到 Managed State,不会用到 Raw State。
对 Managed State 细分,它又有两种类型:operator-state 和 keyed-state。这里先对比两种状态,后续将展示具体的使用方法。
⭐ 总结如下:
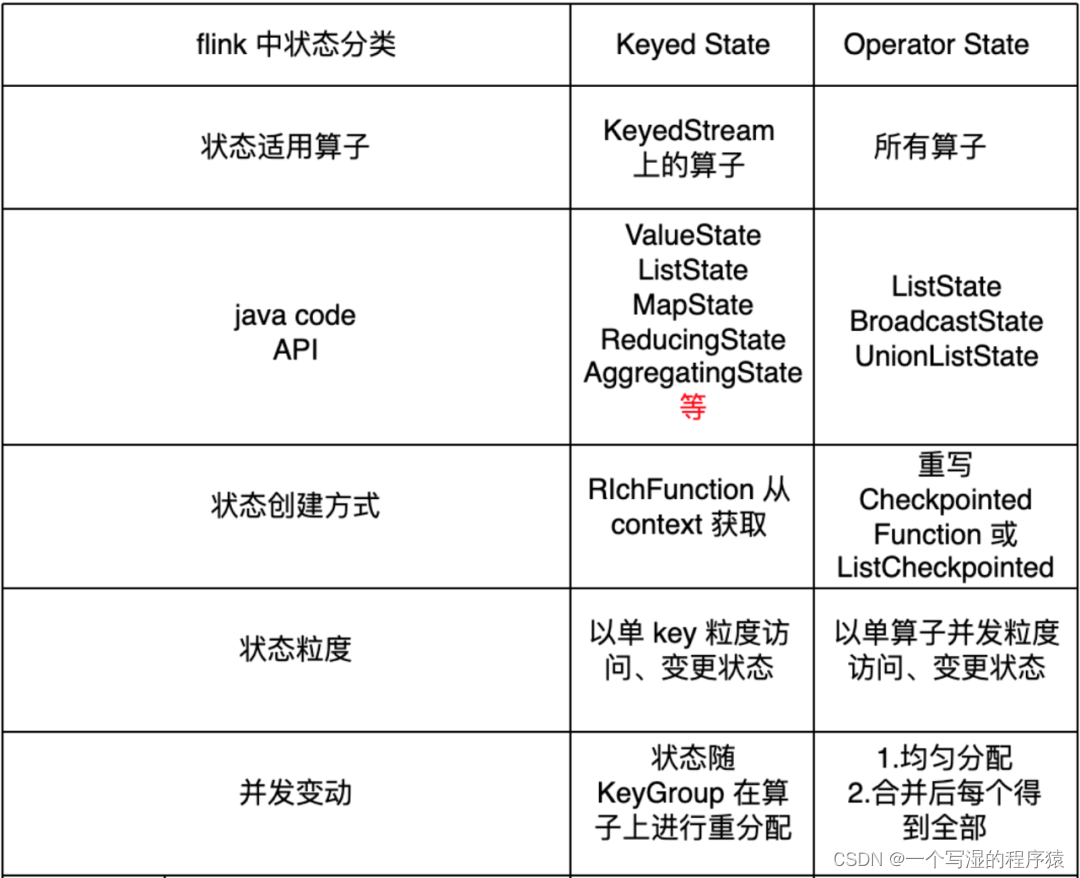
⭐ operator-state:

-
状态适用算子:所有算子都可以使用
operator-state,没有限制。 -
状态的创建方式:如果需要使用 operator-state,需要实现
CheckpointedFunction或ListCheckpointed接口 -
DataStream API 中,operator-state 提供了
ListState、BroadcastState、UnionListState3 种用户接口 -
状态的存储粒度:以单算子单并行度粒度访问、更新状态
-
并行度变化时:
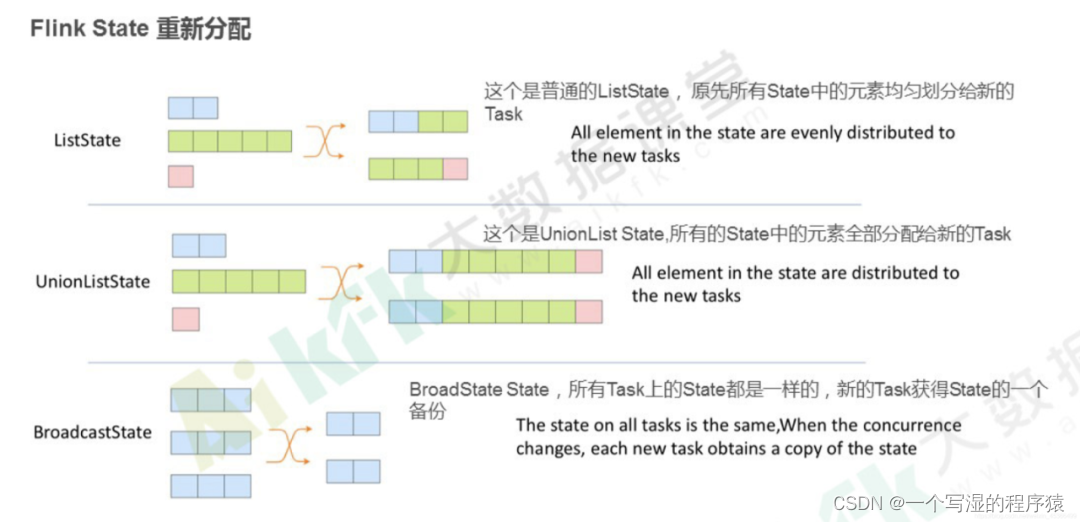
ListState:均匀划分到算子的每个 sub-task 上,比如 Flink Kafka Source 中就使用了 ListState 存储消费 Kafka 的 offset,其 rescale 如下图

BroadcastState:每个 sub-task 的广播状态都一样UnionListState:将原来所有元素合并,合并后的数据每个算子都有一份全量状态数据
⭐ keyed-state:

-
状态适用算子:keyed-stream 后的算子使用。
注意这里很多人会犯一个错误,就是大家会认为 keyby 后面跟的所有算子都使用的是 keyed-state,但这是错误的 ❌,比如有
keyby.process.flatmap,其中 flatmap 中使用状态的话是 operator-state -
状态的创建方式:从 context 接口获取具体的 keyed-state
-
DataStream API 中,keyed-state 提供了 ValueState、MapState、ListState 等用户接口,其中最常用 ValueState、MapState
-
状态的存储粒度:以单 key 粒度访问、更新状态。
举例,当我们使用
keyby.process,在 process 中处理逻辑时,其实每一次 process 的处理 context 都会对应到一个 key,所以在 process 中的处理都是以 key 为粒度的。这里很多人会犯一个错 ❌,比如想在 open 方法中访问、更新 state,这是不行的,因为 open 方法在执行时,还没有到正式的数据处理环节,上下文中是没有 key 的。
-
并行度变化时:keyed-state 的重新划分是随着 key-group 进行的。其中 key-group 的个数就是最大并发度的个数。其中一个 key-group 处理一段区间 key 的数据,不同 key-group 处理的 key 是完全不同的。
当任务并行度变化时,会将 key-group 重新划分到算子不同的 sub-task 上,任务启动后,任务数据在做 keyby 进行数据 shuffle 时,依然能够按照当前数据的 key 发到下游能够处理这个 key 的 key-group 中进行处理,如下图所示。
注意:最大并行度和 key-group 的个数绑定,所以如果想恢复任务 state,最大并行度是不能修改的。大家需要提前预估最大并行度个数。

7.Flink 中状态的使用方式?
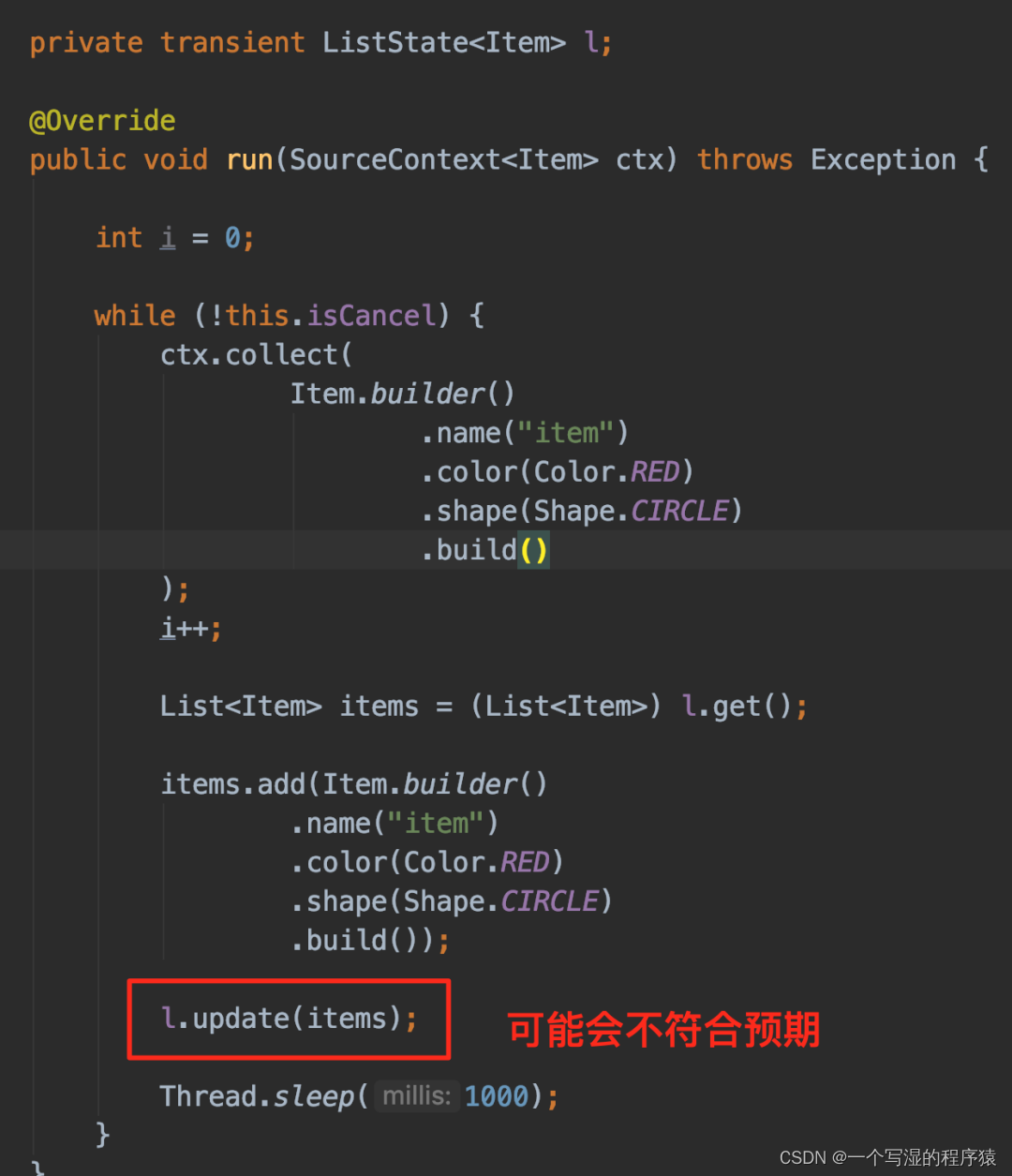
1、⭐ operator-state:实现 CheckpointedFunction
private static class UserDefinedSource extends RichParallelSourceFunction<Item>
implements CheckpointedFunction {
private final ListStateDescriptor<Item> listStateDescriptor =
new ListStateDescriptor<Item>("a", Item.class);
private volatile boolean isCancel = false;
private transient ListState<Item> l;
@Override
public void run(SourceContext<Item> ctx) throws Exception {
int i = 0;
while (!this.isCancel) {
ctx.collect(
Item.builder()
.name("item" + i)
.color(Color.RED)
.shape(Shape.CIRCLE)
.build()
);
i++;
List<Item> items = (List<Item>) l.get();
items.add(Item.builder()
.name("item")
.color(Color.RED)
.shape(Shape.CIRCLE)
.build());
Thread.sleep(1);
}
}
@Override
public void cancel() {
this.isCancel = true;
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
// 做快照逻辑
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
// 获取 operator-state
this.l = context.getOperatorStateStore().getListState(listStateDescriptor);
}
}
这里会问一个问题,initializeState 方法我看懂了是用于恢复 state 的,snapshotState 应该写啥逻辑呢?
答案:其实这个问题的核心点在于大家认为 Flink 不是自己持久化 State 吗?为啥要我去实现 snapshotState 逻辑,其实就算我们不写 snapshotState 方法也可以,Flink 会自动把上面的 ListState<Item> l 持久化,snapshotState 是给小伙伴们实现特殊逻辑使用的,举例:在做 cp 时,可以从 ListState<Item> l 删除一些不要的数据,添加一些特殊的数据。
2、⭐ keyed-state:context 接口获取
new KeyedProcessFunction<Integer, Item, String>() {
private final MapStateDescriptor<String, List<Item>> mapStateDesc =
new MapStateDescriptor<>(
"itemsMap",
BasicTypeInfo.STRING_TYPE_INFO,
new ListTypeInfo<>(Item.class));
private final ListStateDescriptor<Item> listStateDesc =
new ListStateDescriptor<>(
"itemsList",
Item.class);
private final ValueStateDescriptor<Item> valueStateDesc =
new ValueStateDescriptor<>(
"itemsValue"
, Item.class);
private final ReducingStateDescriptor<String> reducingStateDesc =
new ReducingStateDescriptor<>(
"itemsReducing"
, new ReduceFunction<String>() {
@Override
public String reduce(String value1, String value2) throws Exception {
return value1 + value2;
}
}, String.class);
private final AggregatingStateDescriptor<Item, String, String> aggregatingStateDesc =
new AggregatingStateDescriptor<Item, String, String>("itemsAgg",
new AggregateFunction<Item, String, String>() {
@Override
public String createAccumulator() {
return "";
}
@Override
public String add(Item value, String accumulator) {
return accumulator + value.name;
}
@Override
public String getResult(String accumulator) {
return accumulator;
}
@Override
public String merge(String a, String b) {
return null;
}
}, String.class);
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
mapStateDesc.enableTimeToLive(StateTtlConfig
.newBuilder(Time.milliseconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupInRocksdbCompactFilter(10)
.build());
}
@Override
public void processElement(Item value, Context ctx, Collector<String> out) throws Exception {
MapState<String, List<Item>> mapState = getRuntimeContext().getMapState(mapStateDesc);
List<Item> l = mapState.get(value.name);
if (null == l) {
l = new LinkedList<>();
}
l.add(value);
mapState.put(value.name, l);
ListState<Item> listState = getRuntimeContext().getListState(listStateDesc);
listState.add(value);
Object o = listState.get();
ValueState<Item> valueState = getRuntimeContext().getState(valueStateDesc);
valueState.update(value);
Item i = valueState.value();
AggregatingState<Item, String> aggregatingState = getRuntimeContext().getAggregatingState(aggregatingStateDesc);
aggregatingState.add(value);
String aggResult = aggregatingState.get();
ReducingState<String> reducingState = getRuntimeContext().getReducingState(reducingStateDesc);
reducingState.add(value.name);
String reducingResult = reducingState.get();
System.out.println(1);
}
}
ValueState[T]、 MapState[K, V]、 ListState[T]、 ReducingState[T]、AggregatingState[IN, OUT]
注意:大多数情况下,常用的 State 也就是 keyed-state 中的 ValueState、MapState,其他 State 接口其实非常少用(包括 operator-state 也很少用)。
8.Flink 状态后端的分类及使用建议?
Flink 提供了 3 种状态后端用于管理和存储状态数据,我们来看看每种状态后端的适用场景:
⭐ MemoryStateBackend
原理:运行时所需的 State 数据全部保存在 TaskManager JVM 堆上内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到 JobManager 进程 的内存中。执行 Savepoint 时,可以把 State 存储到文件系统中。
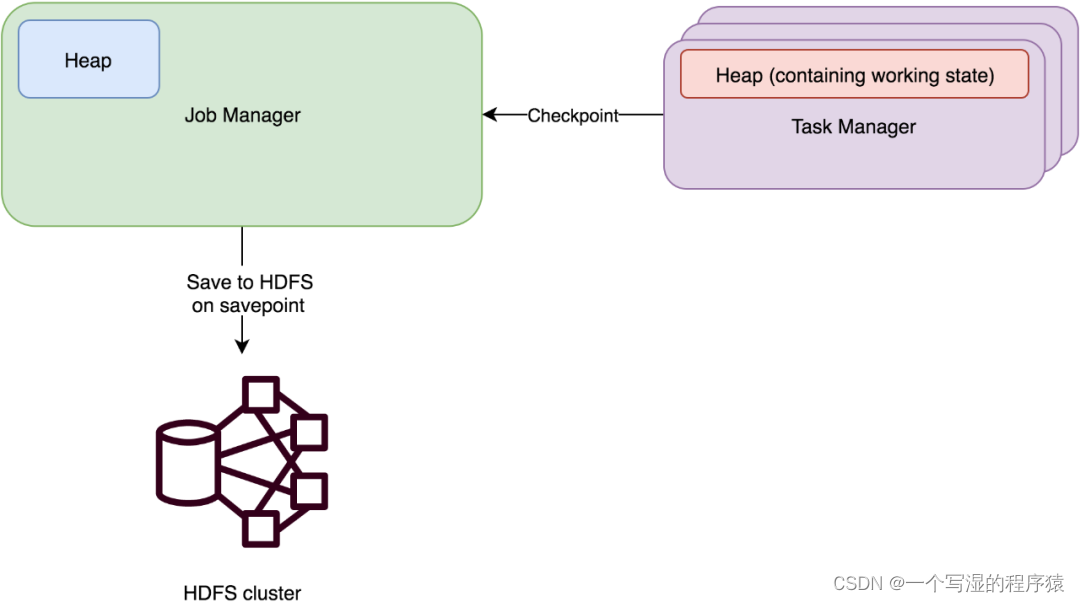
适用场景:
-
a.基于内存的 StateBackend 在生产环境下不建议使用,因为 State 大小超过 JobManager 内存就 OOM 了,此种状态后端适合在本地开发调试测试,生产环境基本不用。
-
b.State 存储在 JobManager 的内存中。受限于 JobManager 的内存大小。
-
c.每个 State 默认 5MB,可通过 MemoryStateBackend 构造函数调整。
-
d.每个 Stale 不能超过 Akka Frame 大小。
⭐ FSStateBackend
原理:运行时所需的 State 数据全部保存在 TaskManager 的内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到配置的文件系统中。TM 是异步将 State 数据写入外部存储。
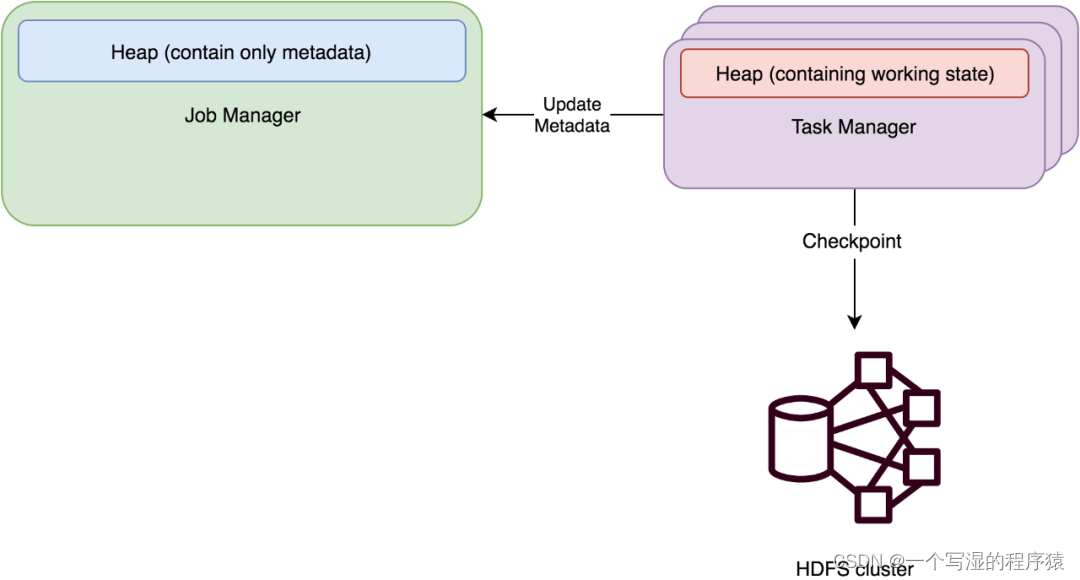
适用场景:
-
a.适用于处理小状态、短窗口、或者小键值状态的有状态处理任务,不建议在大状态的任务下使用 FSStateBackend。适用的场景比如明细层 ETL 任务,小时间间隔的 TUMBLE 窗口
-
b.State 大小不能超过 TM 内存。
⭐ RocksDBStateBackend
原理:使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中。在执行 Checkpoint 的时候,会将整个 RocksDB 中保存的 State 数据全量或者增量持久化到配置的文件系统中。
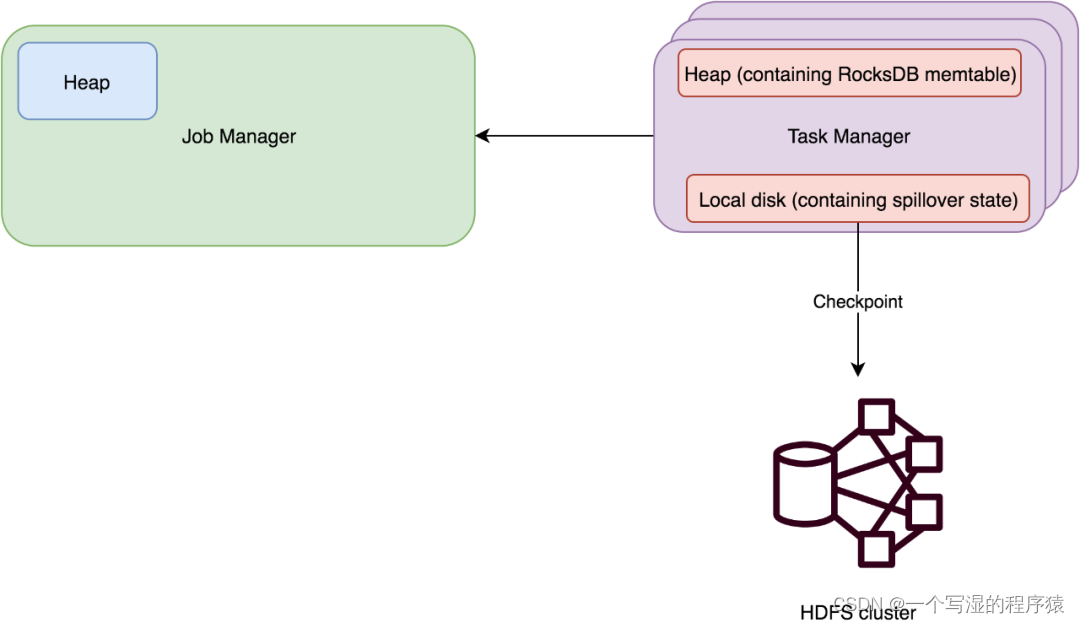
适用场景:
-
a.最适合用于处理大状态、长窗口,或大键值状态的有状态处理任务。
-
b.RocksDBStateBackend 是目前唯一支持增量检查点的后端。
-
c.增量检查点非常适用于超大状态的场景。比如计算 DAU 这种大数据量去重,大状态的任务都建议直接使用 RocksDB 状态后端。
到生产环境中:
⭐ 如果状态特别大,使用 Rocksdb;如果状态差不多大,使用 Filesystem。
⭐ Rocksdb 使用磁盘存储 State,所以会涉及到访问 State 磁盘序列化、反序列化,性能会受到影响,而 Filesystem 直接访问内存,单纯从访问状态的性能来说 Filesystem 远远好于 Rocksdb。生产环境中实测,相同任务使用 Filesystem 性能为 Rocksdb 的 n 倍,因此需要根据具体场景评估选择。
9.Flink 中状态的能力扩展 - TTL?
Flink 对状态做了能力扩展,即 TTL。它的能力其实和 redis 的过期策略类似,举例:
-
支持 TTL 更新类型:更新 TTL 的时机
-
访问到已过期数据的时的数据可见性
-
过期时间语义:目前只支持处理时间
-
具体过期实现:lazy,后台线程
那么首先我们看下什么场景需要用到 TTL 机制呢?举例:
比如计算 DAU 使用 Flink MapState 进行去重,到第二天的时候,第一天的 MapState 就可以删除了,就可以用 Flink State TTL 进行自动删除(当然你也可以通过代码逻辑进行手动删除)。
其实在 Flink DataStream API 中,TTL 功能还是比较少用的。Flink State TTL 在 Flink SQL 中是被大规模应用的,几乎除了窗口类、ETL(DWD 明细处理任务)类的任务之外,SQL 任务基本都会用到 State TTL。
那么我们在要怎么开启 TTL 呢?这里分 DataStream API 和 SQL API:
⭐ DataStream API:
private final MapStateDescriptor<String, List<Item>> mapStateDesc =
new MapStateDescriptor<>(
"itemsMap",
BasicTypeInfo.STRING_TYPE_INFO,
new ListTypeInfo<>(Item.class));
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 使用 StateTtlConfig 开启 State TTL
mapStateDesc.enableTimeToLive(StateTtlConfig
.newBuilder(Time.milliseconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupInRocksdbCompactFilter(10)
.build());
}
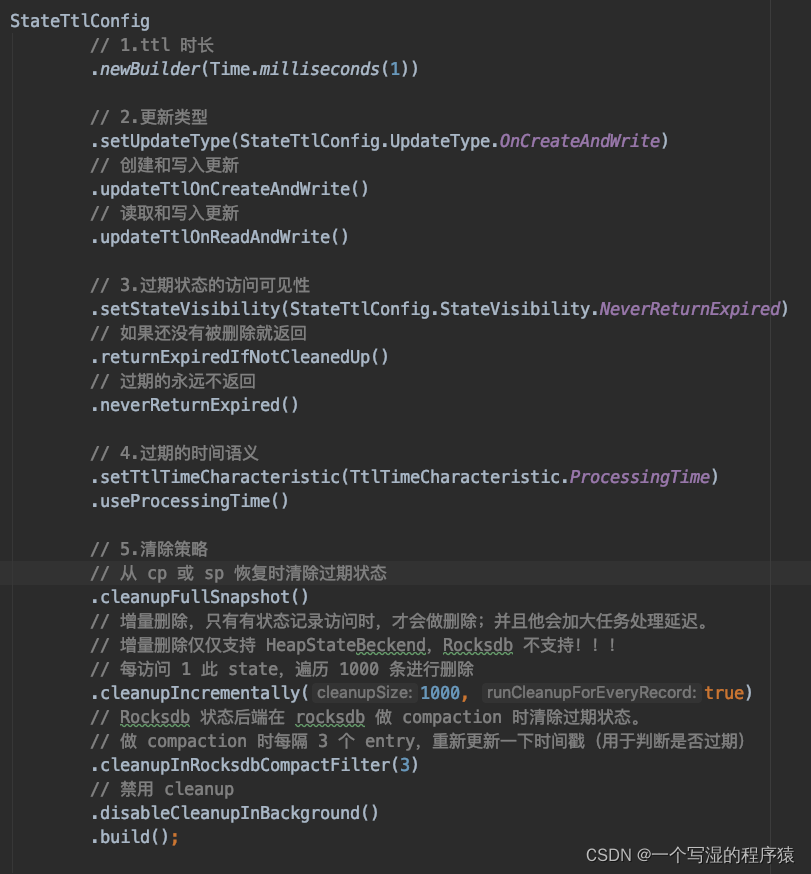
关于 StateTtlConfig 的每个配置项的功能如下图所示:
⭐ SQL API:
StreamTableEnvironment
.getConfig()
.getConfiguration()
.setString("table.exec.state.ttl", "180 s");
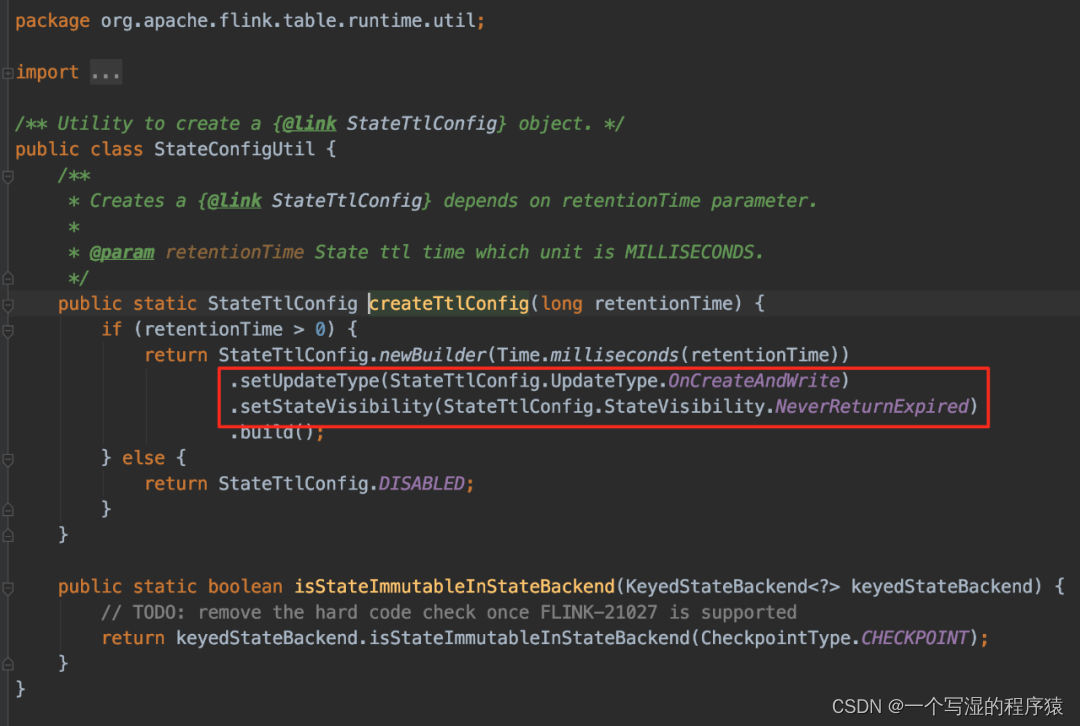
注意:SQL 中 TTL 的策略不如 DataStream 那么多,SQL 中 TTL 只支持下图所示策略:
10.Flink 中状态 TTL 的原理机制?
首先我们来想想,要做到 TTL 的话,要具备什么条件呢?
想想 Redis 的 TTL 设置,如果我们要设置 TTL 则必然需要给一条数据给一个时间戳,只有这样才能判断这条数据是否过期了。
在 Flink 中设置 State TTL,就会有这样一个时间戳,具体实现时,Flink 会把时间戳字段和具体数据字段存储作为同级存储到 State 中。
举个例子,我要将一个 String 存储到 State 中时:
-
没有设置
State TTL时,则直接将 String 存储在 State 中 -
如果设置
State TTL时,则 Flink 会将 <String, Long> 存储在 State 中,其中 Long 为时间戳,用于判断是否过期。
接下来以 FileSystem 状态后端下的 MapState 作为案例来说:
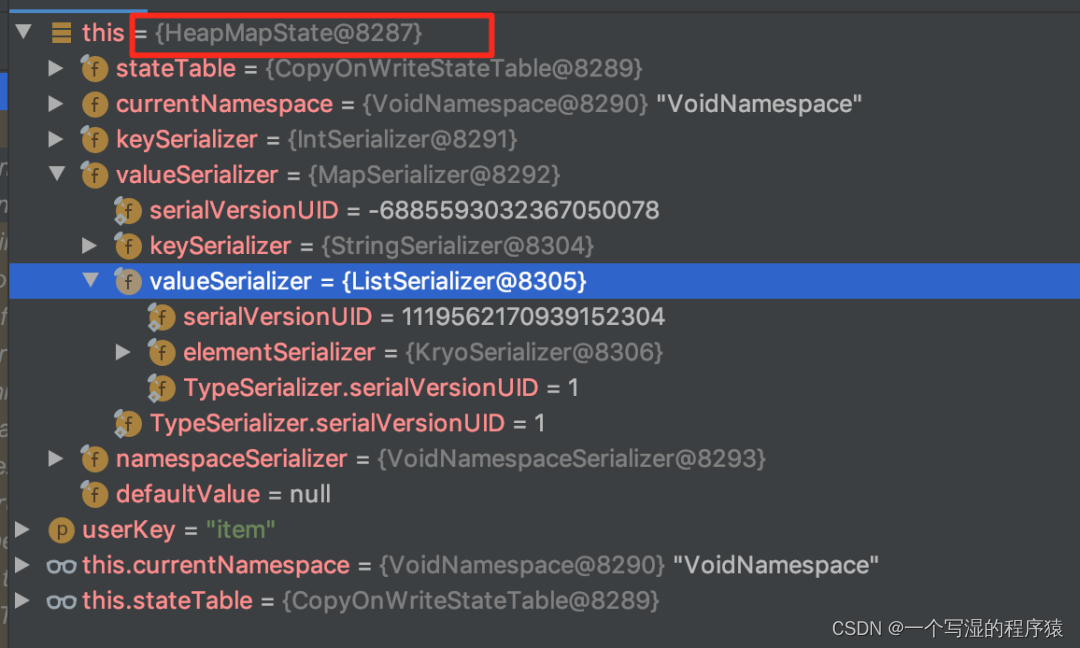
- 如果没有设置 State TTL,则生产的 MapState 的字段类型如下(可以看到生成的就是 HeapMapState 实例):
- 如果设置了 State TTL,则生成的 MapState 的字段类型如下(可以看到使用到了装饰器的设计模式生成是 TtlMapState):
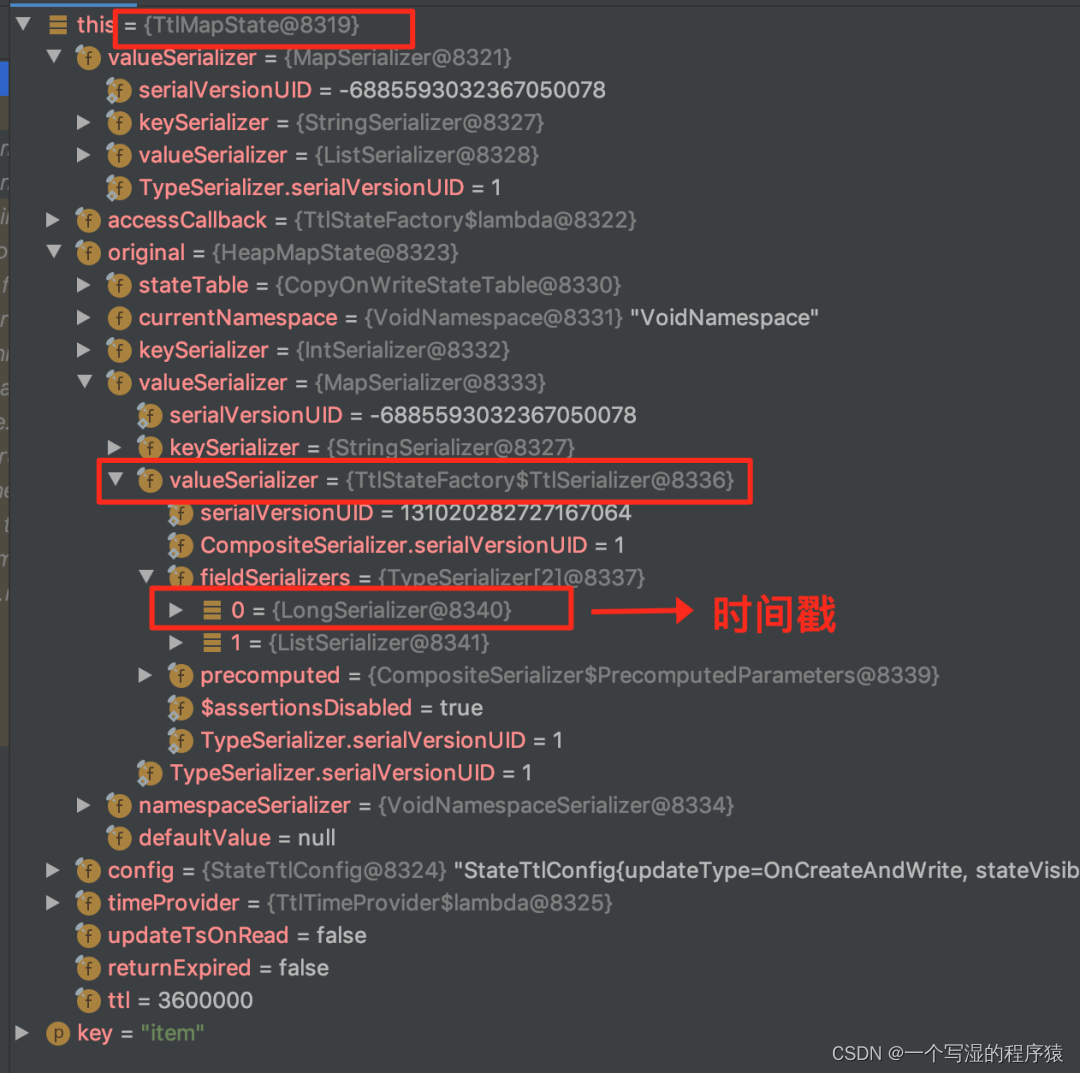
注意:
任务设置了 State TTL 和不设置 State TTL 的状态是不兼容的。这里大家在使用时一定要注意。防止出现任务从 Checkpoint 恢复不了的情况。但是你可以去修改 TTL 时长,因为修改时长并不会改变 State 存储结构。
了解了基础数据结构之后,我们再来看看 Flink 提供的 State 过期的 4 种删除策略:
-
lazy 删除策略:就是在访问 State 的时候根据时间戳判断是否过期,如果过期则主动删除 State 数据 -
full snapshot cleanup 删除策略:从状态恢复(checkpoint、savepoint)的时候采取做过期删除,但是不支持 rocksdb 增量 ck -
incremental cleanup 删除策略:访问 state 的时候,主动去遍历一些 state 数据判断是否过期,如果过期则主动删除 State 数据 -
rocksdb compaction cleanup 删除策略:rockdb 做 compaction 的时候遍历进行删除。仅仅支持 rocksdb
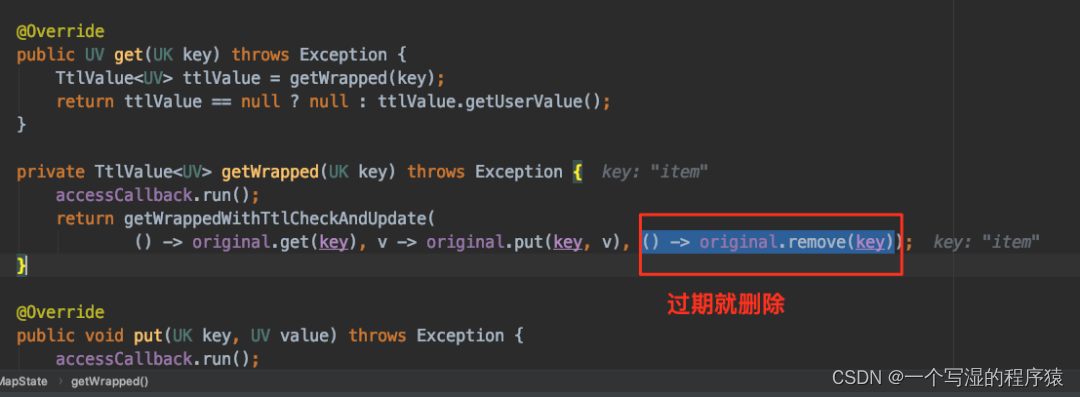
10.1.lazy 删除策略
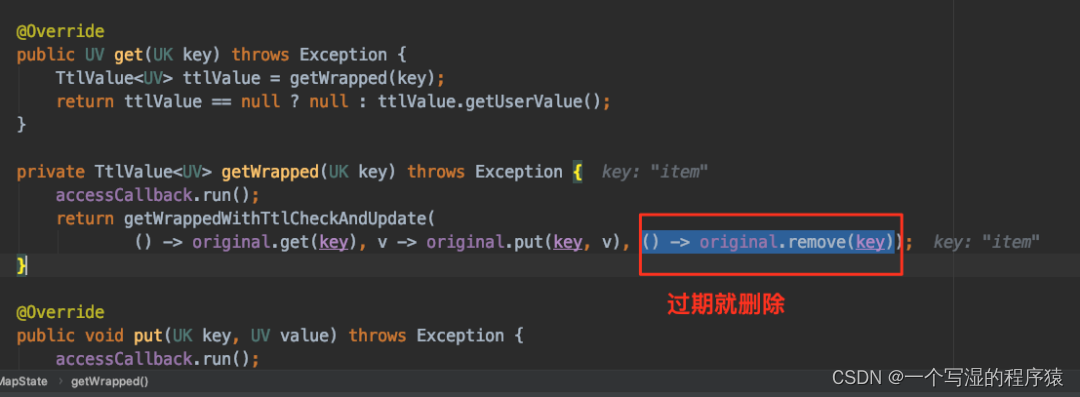
访问 State 的时候根据时间戳判断是否过期,如果过期则主动删除 State 数据。以 MapState 为例,如下图所示,在 MapState.get(key) 时会进行判断是否过期:
这个删除策略是不需要用户进行配置的,只要你打开了 State TTL 功能,就会默认执行
10.2.full snapshot cleanup 删除策略
从状态恢复(checkpoint、savepoint)的时候采取做过期删除,但是不支持 rocksdb 增量 checkpoint。
StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build()
10.3.incremental cleanup 删除策略
访问 state 的时候,主动去遍历一些 state 数据判断是否过期,如果过期则主动删除 State 数据。
StateTtlConfig
.newBuilder(Time.seconds(1))
// 每访问 1 此 state,遍历 1000 条进行删除
.cleanupIncrementally(1000, true)
.build()
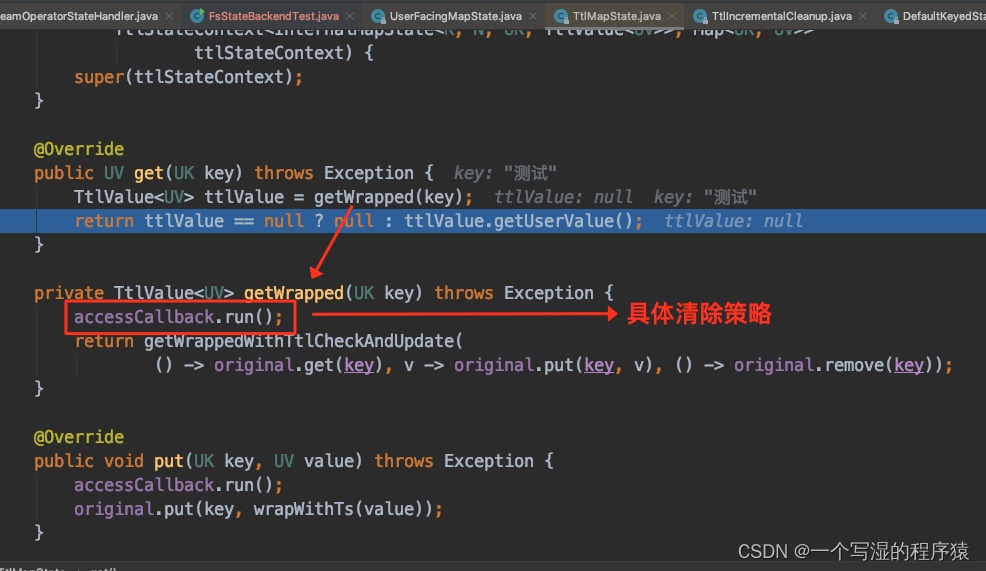
注意:
-
如果没有 state 访问,也没有处理数据,则不会清理过期数据。
-
增量清理会增加数据处理的耗时。
-
现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。
-
因为是遍历删除 State 机制,并且每次遍历的条目数是固定的,所以可能会出现部分过期的 State 很长时间都过期不掉导致 Flink 任务 OOM。
10.4.rocksdb compaction cleanup 删除策略
仅仅支持 rocksdb。在 rockdb 做 compaction 的时候遍历进行删除。
StateTtlConfig
.newBuilder(Time.seconds(1))
// 做 compaction 时每隔 3 个 entry,重新更新一下时间戳(这个时间戳是 Flink 用于和数据中的时间戳来比较判断是否过期)
.cleanupInRocksdbCompactFilter(3)
.build()
注意:
rocksdb compaction 时调用 TTL 过滤器会降低 compaction 速度。因为 TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。对于集合型状态类型(比如 ListState 和 MapState),会对集合中每个元素进行检查。
11.Flink Checkpoint 的运行机制?
通过上面的部分,我们已经知道了状态、状态后端,最后来看看 Flink Checkpoint 机制。
Checkpoint 整个流程如下:
-
JM 定时调度 Checkpoint 的触发:JM CheckpointCoorinator 定时触发,CheckpointCoordinator 会去通过 RPC 接口调用 Source 算子的 TM 的 StreamTask 告诉 TM 可以开始执行 Checkpoint 了。 -
Source 算子:接受到 JM 做 Checkpoint 的请求后,开始做本地 Checkpoint,本地执行完成之后,发 barrier 给下游算子。barrier 发送策略是随着 partition 策略走,将 barrier 发往连接到的所有下游算子(举例:keyby 就是广播,forward 就是直接送)。 -
剩余的算子:接收到上游所有 barrier 之后进行触发 Checkpoint。当一个算子接收到上游一个 channel 的 barrier 之后,就停止处理这个 input channel 来的数据(本质上就是不会再去影响状态了)
注意:
实际代码中,慎用 Thread.sleep(),有可能导致任务执行线程卡住,barrier 发不下去,从而导致 Checkpoint 失败。
12.Flink Checkpoint 的配置?
来看看 Flink 为 Checkpoint 都提供了哪些配置及功能来帮助我们控制 Checkpoint 执行时的行为:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 30 秒触发一次 checkpoint,checkpoint 时间应该远小于(该值 + MinPauseBetweenCheckpoints),否则程序会一直做 checkpoint,影响数据处理速度
env.enableCheckpointing(30000);
// Flink 框架内保证 EXACTLY_ONCE
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 两个 checkpoints 之间最少有 30s 间隔(上一个 checkpoint 完成到下一个 checkpoint 开始,默认为 0,这里建议设置为非 0 值)
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000);
// checkpoint 超时时间(默认 600 s)
env.getCheckpointConfig().setCheckpointTimeout(600000);
// 同时只有一个checkpoint运行(默认)
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 取消作业时是否保留 checkpoint (默认不保留,非常建议配置为保留)
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// checkpoint 失败时 task 是否失败(默认 true, checkpoint 失败时,task 会失败)
env.getCheckpointConfig().setFailOnCheckpointingErrors(true);
// 对 FsStateBackend 刷出去的文件进行文件压缩,减小 checkpoint 体积
env.getConfig().setUseSnapshotCompression(true);
参考了很多云厂商后,建议大家的 Checkpoint 配置如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 120 秒触发一次 checkpoint,不会特别频繁
env.enableCheckpointing(120000);
// Flink 框架内保证 EXACTLY_ONCE
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 两个 checkpoints 之间最少有 120s 间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(120000);
// checkpoint 超时时间 600s
env.getCheckpointConfig().setCheckpointTimeout(600000);
// 同时只有一个 checkpoint 运行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 取消作业时保留 checkpoint,因为有时候任务 savepoint 可能不可用,这时我们就可以直接从 checkpoint 重启任务
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// checkpoint 失败时 task 不失败,因为可能会有偶尔的写入 HDFS 失败,但是这并不会影响我们任务的运行
// 偶尔的由于网络抖动 checkpoint 失败可以接受,但是如果经常失败就要定位具体的问题!
env.getCheckpointConfig().setFailOnCheckpointingErrors(false);
13.Flink Checkpoint 在 HDFS 的存储格式?
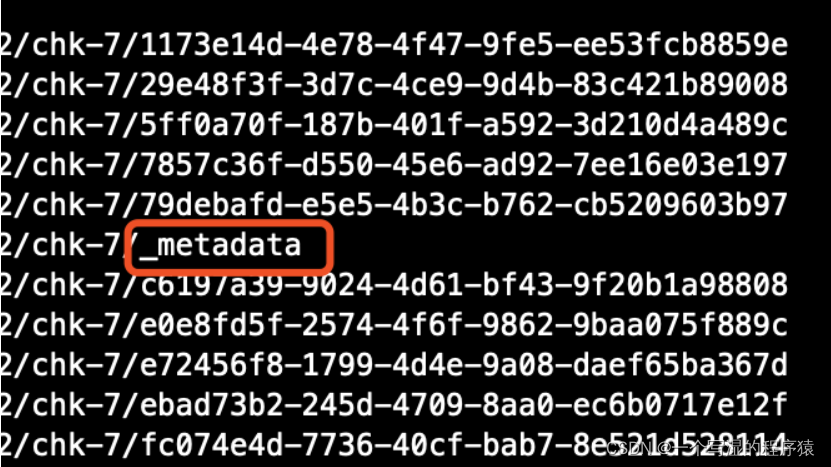
这里也分 keyed-state 和 operator-state 进行说明。Flink 会将 Checkpoint 数据存储在一个带有编号的 chk 目录中。
比如说一个 Flink 任务的 keyed-state 的 subTask 个数是 10,operator-state 对应的 subTask 也是 10,那么 chk 会存一个元数据文件 _metadata,10 个 keyed-state 文件,10 个 operator-state 的文件。
14.Flink Checkpoint 的恢复机制?
这里主要介绍两种类型 State 在并行度发生变化时的恢复机制,如下图所示:
⭐ keyed-state

⭐ operator-state
15.Flink SQL 的 State 使用?
其实 Flink SQL 发明出来就是为了屏蔽窗口、状态这些底层的东西的。
但是我们在使用 Flink SQL 时,70% 以上的场景都是不得不去关注 State 的!
举个 Flink SQL 的例子,下这个 SQL 用于计算每个 sessionId 的点击量:
SELECT
sessionId
, COUNT(*)
FROM clicks
GROUP BY
sessionId;
当 sessionId 为 1 亿时,或许还能够正常运行,但是 sessionId 为 10 亿时,State 将会变得很大,我们就不得不考虑是否要设置 State TTL 以防止无限增大的 State。
问题:哪些场景的 Flink SQL 会常常去考虑 State TTL 呢?
答案:相信大家通过上面的案例之后也能总结出来了。其实就是 unbounded Flink SQL 常常会考虑到,因为这类 Flink SQL 的 State 只会越变越大,如果没有设置合理的 State TTL 的话,任务可能会由于大 State 导致磁盘压力大,任务卡住。
16.Flink 状态的误用之痛?
⭐ 一定要分清楚 operator-state 和 keyed-state 的区别以及使用方式。博主有见过在 KeyedStream 后面错用 operator-state,operator-state 大 State 导致 OOM。建议 KeyedStream 上还是使用 keyed-state。
⭐ 一定要学会分场景使用 ValueState 和 MapState。个人有见过在 ValueState 中存储一个大 Map,并且使用 RocksDB,导致 State 访问非常慢(因为 RocksDB 访问 State 经过序列化),拖慢任务处理速度。两者的具体区别如下:
ValueState
-
应用场景:简单的一个变量存储,比如 Long\String 等。如果状态后端为 RocksDB,极其不建议在 ValueState 中存储一个大 Map,这种场景下序列化和反序列化的成本非常高,拖慢任务处理速度,这种常见适合使用 MapState。其实这种场景也是很多小伙伴一开始使用 State 的误用之痛,一定要避免。
-
TTL:针对整个 Value 起作用
MapState
-
应用场景:和 Map 使用方式一样一样的
-
TTL:针对 Map 的 key 生效,每个 key 一个 TTL
⭐ keyed-state 不能在 open 方法中访问、更新 state,这是不行的,因为 open 方法在执行时,还没有到正式的数据处理环节,上下文中是没有 key 的
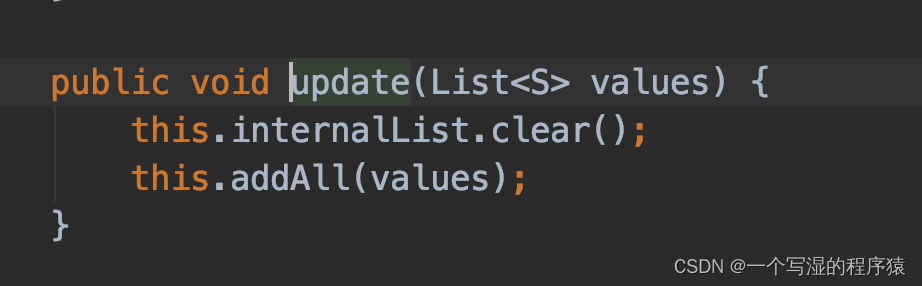
⭐ operator-state 中的 ListState 进行以下操作会有问题。因为当实例化的 state 为 PartitionableListState 时,会先把 list clear,然后再 add,这样就会把下图中的 items 给 clear 了。你会发现 state 一致为空
1.1 状态、状态后端、Checkpoint 三者之间的区别及关系?
结论:通俗形象的说,炒菜的锅好比状态后端,菜就是状态,Checkpoint 就是炒菜的动作。
⭐ 状态:本质来说就是数据,在 Flink 中,其实就是 Flink 提供给用户的状态编程接口。
比如 flink 中的 MapState,ValueState,ListState。
⭐ 状态后端:Flink 提供的用于管理状态的组件,状态后端决定了以什么样数据结构,什么样的存储方式去存储和管理我们的状态。
Flink 目前官方提供了 memory、filesystem,rocksdb 三种状态后端来存储我们的状态。
⭐ Checkpoint(状态管理):Flink 提供的用于定时将状态后端中存储的状态同步到远程的存储系统的组件或者能力。
为了防止长时间运行的 Flink 任务挂了导致状态丢失,产生数据质量问题,Flink 提供了状态管理(Checkpoint,Savepoint)的能力,把我们使用的状态给管理起来,定时的保存到远程。然后可以在 Flink 任务 failover 时,从远程把状态数据恢复到 Flink 任务中,保障数据质量。
1.2 把状态后端从 FileSystem 变为 RocksDB 后,Flink 任务状态存储会发生那些变化?
结论:是否使用 RocksDB 只会影响 Flink 任务中 keyed-state 存储的方式和地方,Flink 任务中的 operator-state 不会受到影响。
首先我们来看看,Flink 中的状态只会分为两类:
⭐ keyed-state:键值状态,如其名字,此类状态是以 k-v 的形式存储,状态值和 key 绑定。Flink 中的 keyby 之后紧跟的算子的 state 就是键值状态;
⭐ operator-state:算子状态,非 keyed-state 的 state 都是算子状态,非 k-v 结构,状态值和算子绑定,不和 key 绑定。
Flink 中的 kafka source 算子中用于存储 kafka offset 的 state 就是算子状态。
如下图所示是 3 种状态后端和 2 种 State 的对应存储关系:

1、⭐ 横向(行)来看,即 Flink 的状态分类。分为 Operator state-backend、Keyed state-backend;
2、⭐ 纵向(列)来看,即 Flink 的状态后端分类。用户可以配置 memory,filesystem,rocksdb 3 种状态后端,在 Flink 任务中生成 MemoryStateBackend,FsStateBackend,RocksdbStateBackend,其声明了整个任务的状态管理后端类型;
3、⭐ 每个格子中的内容就是用户在配置 xx 状态后端(列)时,给用户使用的状态(行)生成的状态后端实例,生成的这个实例就是在 Flink 中实际用于管理用户使用的状态的组件。
因此对应的结论就是:
⭐ Flink 任务中的 operator-state。无论用户配置哪种状态后端(无论是 memory,filesystem,rocksdb),都是使用 DefaultOperatorStateBackend 来管理的,状态数据都存储在内存中,做 Checkpoint 时同步到远程文件存储中(比如 HDFS)。
⭐ Flink 任务中的 keyed-state。
-
用户在配置
rocksdb时,会使用RocksdbKeyedStateBackend去管理状态; -
用户在配置
memory,filesystem时,会使用HeapKeyedStateBackend去管理状态。
因此就有了这个问题的结论,配置 rocksdb 只会影响 keyed-state 存储的方式和地方,operator-state 不会受到影响。
1.3 什么样的业务场景你会选择 filesystem,什么样的业务场景你会选 rocksdb 状态后端?
在回答这个问题前,我们先看看每种状态后端的特性:
⭐ MemoryStateBackend
原理:运行时所需的 State 数据全部保存在 TaskManager JVM 堆上内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到 JobManager 进程 的内存中。执行 Savepoint 时,可以把 State 存储到文件系统中。

适用场景:
-
基于内存的 StateBackend 在生产环境下不建议使用,因为 State 大小超过 JobManager 内存就 OOM 了,此种状态后端适合在本地开发调试测试,生产环境基本不用。
-
State 存储在 JobManager 的内存中。受限于 JobManager 的内存大小。
-
每个 State 默认 5MB,可通过 MemoryStateBackend 构造函数调整。每个 Stale 不能超过 Akka Frame 大小。
⭐ FSStateBackend
原理:运行时所需的 State 数据全部保存在 TaskManager 的内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到配置的文件系统中。TM 是异步将 State 数据写入外部存储。

适用场景:
- 适用于处理小状态、短窗口、或者小键值状态的有状态处理任务,不建议在大状态的任务下使用
FSStateBackend。比如 ETL 任务,小时间间隔的 TUMBLE 窗口 ,State 大小不能超过 TM 内存。
⭐ RocksDBStateBackend
原理:使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中。在执行 Checkpoint 的时候,会将整个 RocksDB 中保存的 State 数据全量或者增量持久化到配置的文件系统中。

适用场景:
-
最适合用于处理大状态、长窗口,或大键值状态的有状态处理任务。
-
RocksDBStateBackend 是目前唯一支持增量检查点的后端。
-
增量检查点非常适用于超大状态的场景。比如计算 DAU 这种大数据量去重,大状态的任务都建议直接使用 RocksDB 状态后端。
在生产环境中:
⭐ 如果状态很大,使用 Rocksdb;如果状态不大,使用 Filesystem。
⭐ Rocksdb 使用磁盘存储 State,所以会涉及到访问 State 磁盘序列化、反序列化,性能会收到影响,而 Filesystem 直接访问内存,单纯从访问状态的性能来说 Filesystem 远远好于 Rocksdb。生产环境中实测,相同任务使用 Filesystem 性能为 Rocksdb 的 n 倍,因此需要根据具体场景评估选择。
1.4 Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是 onReadAndWrite
⭐ 结论:Flink SQL API State TTL 的过期机制目前只支持 onCreateAndUpdate,DataStream API 两个都支持

⭐ 剖析:
-
onCreateAndUpdate:是在创建 State 和更新 State 时【更新 State TTL】 -
onReadAndWrite:是在访问 State 和写入 State 时【更新 State TTL】
⭐ 实际踩坑场景:Flink SQL Deduplicate 写法,row_number partition by user_id order by proctime asc,此 SQL 最后生成的算子只会在第一条数据来的时候更新 state,后续访问不会更新 state TTL,因此 state 会在用户设置的 state TTL 时间之后过期。
2 时间窗口
2.1 watermark 到底是干啥的?应用场景?
watermark 是用于缓解时间时间的乱序问题的。没错,这个观点是正确的。但是个人认为这只是 watermark 第二重要的作用,其更重要的作用在于可以标识一个 Flink 任务的事件 时间进度。
怎么理解 时间进度?
我们可以现象一下,一个事件时间窗口的任务,如果没有一个 东西 去标识其事件时间的进度,那么这个事件时间的窗口也就是不知道什么时候能够触发了,也就是说这个窗口永远不会触发并且输出结果。
所以要有一个 东西 去标识其事件时间的进度,从而让这个事件时间窗口知道,这个事件时间窗口已经结束了,可以触发计算了。在 Flink 中,这个 东西 就是 watermark。
⭐ 标识 Flink 任务的事件时间进度,从而能够推动事件时间窗口的触发、计算。
⭐ 解决事件时间窗口的乱序问题。
2.2 一个 Flink 任务中可以既有事件时间窗口,又有处理时间窗口吗?
结论:一个 Flink 任务可以同时有事件时间窗口,又有处理时间窗口。
为什么我们常见的 Flink 任务要么设置为事件时间语义,要么设置为处理时间语义?
确实,在生产环境中,我们的 Flink 任务一般不会同时拥有两种时间语义的窗口。那么怎么解释开头所说的结论呢?
这里从两个角度进行说明:
⭐ 我们其实没有必要把一个 Flink 任务和某种特定的时间语义进行绑定。
对于事件时间窗口来说,我们只要给它 watermark,能让 watermark 一直往前推进,让事件时间窗口能够持续触发计算就行。
对于处理时间来说更简单,只要窗口算子按照本地时间按照固定的时间间隔进行触发就行。无论哪种时间窗口,主要满足时间窗口的触发条件就行。
⭐ Flink 的实现上来说也是支持的。Flink 是使用一个叫做 TimerService 的组件来管理 timer 的,我们可以同时注册事件时间和处理时间的 timer,Flink 会自行判断 timer 是否满足触发条件,如果是,则回调窗口处理函数进行计算。
2.3 window 后面跟 aggregate 和 process 的两个窗口计算的区别是什么?
⭐ aggregate:是增量聚合,来一条数据计算完了存储在累加器中,不需要等到窗口触发时计算,性能较好;
⭐ process:全量函数,缓存全部窗口内的数据,满足窗口触发条件再触发计算,同时还提供定时触发,窗口信息等上下文信息;
⭐ 应用场景:aggregate 一个一个处理的聚合结果向后传递一般来说都是有信息损失的,而 process 则可以更加定制化的处理。
3 常见优化
3.1 为什么 Flink DataStream API 在函数入参或者出参有泛型时,不能使用 lambda 表达式?
Flink 类型信息系统是通过反射,获取到 Java class 的方法签名,去获取类型信息的。
以 FlatMap 为例,Flink 在通过反射时会检查及获取 FlatMap collector 的出参类型信息。
但是 lambda 表达式写的 FlatMap 逻辑,会导致反射方法获取类型信息时【直接获取不到】collector 的出参类型参数,所以才会报错。
3.2 Flink 为什么强调 function 实现时,实例化的变量要实现 serializable 接口?
其实这个问题可以延伸成 3 个问题:
1、为什么 Flink 要用到 Java 序列化机制。和 Flink 类型系统的数据序列化机制的用途有啥区别?
⭐ Flink 写的函数式编程代码或者说闭包,需要 Java 序列化从 JobManager 分发到 TaskManager,而 Flink 类型系统的数据序列化机制是为了分发数据,不是分发代码,可以用非Java的序列化机制,比如 Kyro。
2、非实例化的变量没有实现 Serializable 为啥就不报错,实例化就报错?
⭐ 编译期不做序列化,所以不实现 Serializable 不会报错,但是运行期会执行序列化动作,没实现 Serializable 接口的就报错了
3、为啥加 transient 就不报错?
⭐ Flink DataStream API 的 Function 作为闭包在网络传输,必须采用 Java 序列化,所以要通过 Serializable 接口标记,根据 Java 序列化的规定,内部成员变量要么都可序列化,要么通过 transient 关键字跳过序列化,否则 Java 序列化的时候会报错。静态变量不参与序列化,所以不用加 transient。
3.3 Flink 的并行度可以通过哪几种方式设置,优先级关系是什么?
代码中算子单独设置 > 代码中Env全局设置 > 提交参数 > 默认配置信息
上面的 Flink 并行度优先级由大变小。
3.4 你是怎么合理的评估 Flink 任务的并行度?
Flink 任务并行度合理行一般根据峰值流量进行压测评估,并且根据集群负载情况留一定量的 buffer 资源。
-
如果数据源已经存在,则可以直接消费进行测试
-
如果数据源不存在,需要自行造压测数据进行测试
对于一个 Flink 任务来说,一般可以按照以下方式进行细粒度设置并行度:
⭐ source 并行度配置:以 kafka 为例,source 的并行度一般设置为 kafka 对应的 topic 的分区数
⭐ transform(比如 flatmap、map、filter 等算子)并行度的配置:这些算子一般不会做太重的操作,并行度可以和 source 保持一致,使得算子之间可以做到 forward 传输数据,不经过网络传输
⭐ keyby 之后的处理算子:建议最大并行度为此算子并行度的整数倍,这样可以使每个算子上的 keyGroup 是相同的,从而使得数据相对均匀 shuffle 到下游算子,如下图为 shuffle 策略

⭐ sink 并行度的配置:sink 是数据流向下游的地方,可以根据 sink 的数据量及下游的服务抗压能力进行评估。
如果 sink 是 kafka,可以设为 kafka 对应 topic 的分区数。注意 sink 并行度最好和 kafka partition 成倍数关系,否则可能会出现如到 kafka partition 数据不均匀的情况。但是大多数情况下 sink 算子并行度不需要特别设置,只需要和整个任务的并行度相同就行。
3.5 你是怎么合理评估任务最大并行度?
⭐ 前提:并行度必须 <= 最大并行度
⭐ 最大并行度的作用:合理设置最大并行度可以缓解数据倾斜的问题
⭐ 根据具体场景的不同,最大并行度大小设置也有不同的方式:
-
在 key 非常多的情况下,最大并行度适合设置比较大(几千),不容易出现数据倾斜,以 Flink SQL 场景举例:row_number = 1 partition key user_id 的 Deduplicate 场景(user_id 一般都非常多)
-
在 key 不是很多的情况下,最大并行度适合设置不是很大,不然会加重数据倾斜,以 Flink SQL 场景举例:group by dim1,dim2 聚合并且维度值不多的 group agg 场景(dim1,dim2 可以枚举),如果依然有数据倾斜的问题,需要自己先打散数据,缓解数据倾斜
⭐ 最大并行度的使用限制:最大并行度一旦设置,是不能随意变更的,否则会导致检查点或保存点失效;最大并行度设置会影响 MapState 状态划分的 KeyGroup 数,并行度修改后再从保存点启动时,KeyGroup 会根据并行度的设定进行重新分布。
⭐ 最大并行度的设置:最大并行度可以自己设置,也可以框架默认生成;默认的算法是取当前算子并行度的 1.5 倍和 2 的 7 次方比较,取两者之间的最大值,然后用上面的结果和 2 的 15 次方比较,取其中的最小值为默认的最大并行度,非常不建议自动生成,建议用户自己设置。
3.6 生产环境中,如何快速判断哪个算子存在反压呢?或者说哪个算子出现了性能问题?
将这个问题拆解成多步来分析:
⭐ 如何知道算子是否有反压?
在 Flink web ui 中,定位到一个具体的算子之后,查看 BackPressure 模块,通过颜色和数值来判断任务的繁忙和反压情况。
若颜色为红色,表示当前算子繁忙,有反压的情况;若颜色为绿色,标识当前算子不繁忙,没有反压。

⭐ 举个实际 Flink 任务案例,这个 Flink 任务中有 Source、FlatMap、Sink 算子,如果 Source 算子有反压,那到底是哪个算子有性能问题呢?
上游算子在 web ui 显示有反压时,一般为下游算子存在性能问题。可以继续往下游排查,如果 FlatMap 也显示有反压,大概率是 Sink 算子存在性能问题;如果 FlatMap 没有显示有反压,大概率是 FlatMap 算子存在性能问题。
⭐ 大多数时候,Flink 会自动将算子 chain 在一起,那怎么判断具体是哪一个算子有问题?
第一种方式:Flink 提供了断开算子链的能力。
- DataStream API 中:可以使用
disableChaining()将 chain 在一起的算子链断开。或者配置pipeline.operator-chaining: false.process(xxx) .uid("process") .disableChaining() // 将算子链进行断开 .addSink(xxx) .uid("sink"); - SQL API 中:配置
pipeline.operator-chaining: falseCREATE TABLE source_table ( order_number BIGINT, price DECIMAL(32,2) ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.order_number.min' = '10', 'fields.order_number.max' = '11' ); CREATE TABLE sink_table ( order_number BIGINT, price DECIMAL(32,2) ) WITH ( 'connector' = 'print' ); insert into sink_table select * from source_table where order_number = 10;
来看 SQL 任务在配置 pipeline.operator-chaining: false 前后的差异。
在配置 pipeline.operator-chaining: false 前,可以看到所有算子都 chain 在一起:

在配置 pipeline.operator-chaining: false 后,可以看到所有算子都没有 chain 在一起:

第二种方式:在 Flink 1.13 中,提供了火焰图,可以通过火焰图定位问题。火焰图需要配置 rest.flamegraph.enabled: true 打开

3.7 反压有哪些危害?
⭐ 任务处理性能出现瓶颈:以消费 Kafka 为例,大概率会出现消费 Kafka Lag。
⭐ Checkpoint 时间长或者失败:因为某些反压会导致 barrier 需要花很长时间才能对齐,任务稳定性差。
⭐ 整个任务完全卡住。比如在 TUMBLE 窗口算子的任务中,反压后可能会导致下游算子的 input pool 和上游算子的 output pool 满了,这时候如果下游窗口的 watermark 一直对不齐,窗口触发不了计算的话,下游算子就永远无法触发窗口计算了。整个任务卡住。
3.8 经常碰到哪些问题会任务反压?
总结:算子的 sub-task 需要处理的数据量 > 能够处理的数据量。一般会实际中会有以下两种问题会导致反压。
⭐ 数据倾斜:当前算子的每个 sub-task 只能处理 1w qps 的数据,而由于数据倾斜,这个算子的其中一些 sub-task 平均算下来 1s 需要处理 2w 条数据,但是实际只能处理 1w 条,从而反压。比如有时候 keyby 的 key 设置的不合理。
⭐ 算子性能问题:下游整个整个算子 sub-task 的处理性能差,输入是 1w qps,当前算子的 sub-task 算下来平均只能处理 1k qps,因此就有反压的情况。比如算子需要访问外部接口,访问外部接口耗时长。
3.9 怎么缓解、解决任务反压的情况?
⭐ 事前:解决上述介绍到的 数据倾斜、算子性能 问题。
⭐ 事中:在出现反压时:
-
限制数据源的消费数据速度。比如在事件时间窗口的应用中,可以自己设置在数据源处加一些限流措施,让每个数据源都能够够匀速消费数据,避免出现有的 Source 快,有的 Source 慢,导致窗口 input pool 打满,watermark 对不齐导致任务卡住。
-
关闭 Checkpoint。关闭 Checkpoint 可以将 barrier 对齐这一步省略掉,促使任务能够快速回溯数据。我们可以在数据回溯完成之后,再将 Checkpoint 打开。
3.10 实时数据延迟是怎么监控的?报警策略又是怎么制定的?
Flink 消费 Source 的 Lag 监控,我们可以把这个监控项升级一下,即 Kafka 到 Flink 延迟。原因如下:
以 Flink 消费 Kafka 为例,几乎所有的任务性能问题都最终能反映到 Kafka 消费 Flink 延迟,所以几乎 100% 的任务性能问题都能由 Kafka 到 Flink 延迟 这个监控发现。
具体的实操时,监控项应该怎么设置呢?
回答:Flink 本地时间戳 - Kafka 中自带的时间戳。
这时候有小伙伴提到,这个只能反映出 Flink 消费 Kafka 的延迟,那具体数据上的延迟怎么反映出来呢。
回答:Flink 本地时间戳 - 数据事件时间戳。
3.11 通过什么样的监控及保障手段来保障实时指标的质量?
从 事前、事中、事后 x 任务层面、指标层面 进行监控、保障:
⭐ 事前:
-
任务层面:根据峰值流量进行压力测试,并且留一定 buffer,用于事前保障任务在资源层面没有瓶颈
-
指标层面:根据业务要求,上线实时指标前进行相同口径的实时、离线指标的验数,在实时指标的误差不超过业务阈值时,才达到上线要求
⭐ 事中:
-
任务层面:贴源层监控 Kafka 堆积延迟等报警检测手段,用于事中及时发现问题。比如的普罗米修斯监控 Lag 时长
-
指标层面:根据指标特点实时离线指标结果对比监控。检测到波动过大就报警。比如最简单的方式是可以通过将实时结果导入到离线,然后定时和离线指标对比
⭐ 事后:
-
任务层面:对于可能发生的故障类型,构建用于故障修复、数据回溯的实时任务备用链路
-
指标层面:构建指标修复预案,根据不同的故障类型,判断是否可以使用实时任务进行修复。如果实时无法修复,构建离线恢复链路,以便使用离线数据进行覆写修复
3.12 operator-state 和 keyed-state 两者的区别?
详细描述一下上面的问题:
operator-state 和 keyed-state 两者的区别?最大并行度又和它们有什么关系?举个生产环境中经常出现的案例,当用户停止任务、更新代码逻辑并且改变任务并发度时,两种 state 都是怎样进行恢复的?
⭐ 总结如下:

1、operator-state:

⭐ 状态适用算子:所有算子都可以使用 operator-state,没有限制。
⭐ 状态的创建方式:如果需要使用 operator-state,需要实现 CheckpointedFunction(建议) 或 ListCheckpointed 接口
⭐ DataStream API 中,operator-state 提供了 ListState、BroadcastState、UnionListState 3 种用户接口
⭐ 状态的存储粒度:以单算子单并行度粒度访问、更新状态
⭐ 并行度变化时:
- ListState:均匀划分到算子的每个 sub-task 上,比如 Flink Kafka Source 中就使用了 ListState 存储消费 Kafka 的 offset,其 rescale 如下图

- BroadcastState:每个 sub-task 的广播状态都一样
- UnionListState:将原来所有元素合并,合并后的数据每个算子都有一份全量状态数据

2、keyed-state:

⭐ 状态适用算子:keyed-stream 后的算子使用。注意就是大家会认为 keyby 后面跟的所有算子都使用的是 keyed-state,但这是错误的 ❌,比如有 keyby.process.flatmap,其中 flatmap 中使用状态的话是 operator-state
⭐ 状态的创建方式:从 context 接口获取具体的 keyed-state
⭐ DataStream API 中,keyed-state 提供了 ValueState、MapState、ListState 等用户接口,其中最常用 ValueState、MapState
⭐ 状态的存储粒度:以单 key 粒度访问、更新状态。
举例,当我们使用 keyby.process,在 process 中处理逻辑时,其实每一次 process 的处理 context 都会对应到一个 key,所以在 process 中的处理都是以 key 为粒度的。
这里经常会有个错误问题 ❌,比如想在 open 方法中访问、更新 state,这是不行的,因为 open 方法在执行时,还没有到正式的数据处理环节,上下文中是没有 key 的。
⭐ 并行度变化时:keyed-state 的重新划分是随着 key-group 进行的。其中 key-group 的个数就是最大并发度的个数。其中一个 key-group 处理一段区间 key 的数据,不同 key-group 处理的 key 是完全不同的。当任务并行度变化时,会将 key-group 重新划分到算子不同的 sub-task 上,任务启动后,任务数据在做 keyby 进行数据 shuffle 时,依然能够按照当前数据的 key 发到下游能够处理这个 key 的 key-group 中进行处理,如下图所示。
注意:最大并行度和 key-group 的个数绑定,所以如果想恢复任务 state,最大并行度是不能修改的。大家需要提前预估最大并行度个数。

3.13 你认为以后 Flink SQL 的发展趋势是 unbounded 类 SQL 为主还是窗口类 SQL 为主?原因?
unbounded 类 SQL。个人的观点如下:
⭐ 先来看看为什么最开始发明了窗口类的算子:窗口(可以叫做 bounded)和 unbounded 的差异就在于,unbounded 类产出的结果不是一个固定结果,因为有 retract 机制(即 retract 流);
窗口类的算子出现的最原始的目的就是解决 unbounded 类产出不固定结果的问题,是想要创造一个可以产出固定结果的算子(即 append 流,不考虑 allow_lateness),所以窗口算子类算子可以说是解决 unbounded 的存在的一个问题而诞生的,个人理解是流式任务在 SQL 上能力拓展。
⭐ 计算引擎(Flink)的流批一体:目前批中是没有时间窗口之类的概念的,所以如果想做到流批一体在计算引擎用户接口层的统一的话,unbounded SQL 可以做到这一点
⭐ 流式 SQL 的普及度,用户上手难易程度:目前大多数数据开发都还是离线数据开发,离线数据开发切换到实时数据开发使用 unbounded 类 SQL 的切换难度是会小,不用去学习窗口类的接口
但是在目前全链路 changelog 计算不是非常成熟的场景下,是没法完全摒弃窗口类应用的。目前业界做的好的就是阿里,阿里目前几乎不用窗口类应用,他们有一套成熟的 changelog 链路。
为什么阿里不用窗口类应用,因为窗口类应用天生有一个缺点就是会 丢数。
一、在实时数仓的分层设计中,具体的分层设计方案是怎样的?和离线数仓又有什么区别?你设计的实时数仓是怎么兼顾时效性和通用性的?
这个问题可以按照以下思路进行分析:
1、陈述事实:离线数仓的分层设计的目标以及一般的设计方式是怎样的?
2、分析差异:实时数仓和离线数仓的核心区别是怎样的?(只有我们准确的识别出这个区别,才能对实时数仓的分层设计有更准确的理解)
3、分析差异:构建实时数仓肯定会参考离线数仓构建方法,但是如果实时数仓按照离线数仓分层设计去做会存在什么问题?
4、解决方案:实时数仓怎么分层设计才能兼顾时效性和通用性?
接下来来看看具体答案:
1、离线数仓的分层设计的目标以及一般的设计方式是怎样的?
-
⭐ 清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
源系统间存在复杂的数据关系,比如客户信息同时存在于核心系统、信贷系统、理财系统、资金系统,取数时该如何决策呢?
数据仓库会对相同主题的数据进行统一建模,把复杂的数据关系梳理成条理清晰的数据模型,使用时就可避免上述问题了。
-
⭐ 数据血缘追踪:简单来讲可以这样理解,我们最终给业务呈现的是一能直接使用的业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
-
⭐ 数据复用,减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
数据的逐层加工原则,下层包含了上层数据加工所需要的全量数据,这样的加工方式避免了每个数据开发人员都重新从源系统抽取数据进行加工。
通过汇总层的引人,避免了下游用户逻辑的重复计算, 节省了用户的开发时间和精力,同时也节省了计算和存储。极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低存储和计算成本。
-
⭐ 把复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
-
⭐ 屏蔽原始数据、业务的影响:业务或系统发生变化时,不必改一次业务就需要重新接入数据。提高数据稳定性和连续性。
并且源头系统可能极为繁杂,而且表命名、字段命名 、字段含义等可能五花八门,通过数仓层来规范和屏蔽所有这些复杂性,保证下游数据用户使用数据的便捷和规范。
如果源头系统业务发生变更,相关的变更由数仓层来处理,对下游用户透明,无须改动下游用户的代码和逻辑。数据仓库的可维护性:分层的设计使得某一层的问题只在该层得到解决,无须更改下一层的代码和逻辑。
良好的数仓分层设计可以更好地组织和存储数据,以便在性能、成本、效率和质量之间取得最佳平衡!
2、实时数仓和离线数仓的核心区别是怎样的?
实时数仓相比离线数仓的特点其实就两个字:实时。
具体体现在:
-
产出速度比离线数仓快:离线 dwd,ads 通常都是小时、天延迟产出数据;相同的数据在实时数仓中,dwd 层常常是毫秒级别产出数据,ads 层常常是分钟级别产出数据。
-
数据时间粒度比离线数仓细:离线数据的时间粒度通常都是小时、天粒度,比如 ads 层计算 1 天的 GMV;实时数据,相同的 GMV 数据在实时数仓中,ads 数据聚合粒度通常为 1min 级别,比如当天实时GMV,实时的 ads 将会计算出 1440(1 天 1440 分钟)个点的数据,每一个点的结果都是当天 0 点到当前这一分钟的 GMV 总额。
3、构建实时数仓肯定会参考离线数仓构建方法,但是如果实时数仓按照离线数仓分层设计去做会存在什么问题?
如果你按照离线数仓分层方案去设计实时数仓分层后,并且尝试之后你就会发现实时数仓分层不适合特别多,因为:
-
分层太多,产出速度必然减慢。举例:
ods -> dwd -> dws(1min 窗口)-> dws(1min 窗口)-> ads(1min 窗口)。这样 ads 层数据产出延迟肯定在 3 min 以上。 -
分层太多,实时数据粒度又细,多种粒度的 dws 的数据量基本一样,不如不建。举例:
ods -> dwd -> dws1(uid\page\style\1min 粒度)-> dws2(uid\page\1min 粒度)-> ads(uid 1min 粒度),因为一个用户在 1min 内发生的行为很少,你可能会发现dws1\dws2\ads的 QPS(流量)都差不多;而离线适合多分层的原因在于离线通常都是 1 天的粒度,所以分这几层的数据量是会有骤减的,因此离线数仓分多层是有价值的。
4、实时数仓怎么分层设计才能兼顾时效性和通用性?
综合前面几个问题的答案,实时数仓分层不宜特别多。建议:
-
如果数据量不大,建立实时数仓只构建
ods -> dwd就足够使用。ods -> dwd是为了字段标准化,通用化,然后后面把 dwd 层导入到 OLAP 中进行查询使用;或者建立 ads 层,ads 层直接消费 dwd,这样时效性也可以得到保障。 -
如果数据量大,可以尝试进行 dws 聚合,聚合之后根据数据量(流量)缩减的实际效果来评估是否需要建立此 dws。
二、你们公司的实时数仓用到的维表都有哪些类型?分别是通过什么样的方式构建的?
依然还是上面的分析思路:
⭐ 描述现状:我们通常以为的实时数仓的实时维表是什么样的?
⭐ 场景分析:一般实时数仓中的维表应用的场景都有哪些?
⭐ 解决方案:针对这些场景,我们有哪些解决方案去构建实时维表?
1、我们通常以为的实时数仓的实时维表是什么样的?
很多小伙伴对于实时数仓的维表理解都是实时维表一定要实时。但是这个想法不是非常的全面,具体实时维表怎样构建还是需要看场景。
2、一般实时数仓中的维表应用的场景都有哪些?
一般的实时数仓中的维表按照使用场景可以分为两类。
-
缓慢变化维度的维表:比如用户画像,包含年龄、性别等维度的数据,其实很长时间用户的维度的变化都不明显。
举个例子,当已经判定一个用户的年龄在 18-25 之间时,其实基本上这个维度后续很长时间内就不会发生改变了。基于这个特点,其实实时任务访问
t-2\t-1或者实时构建的维表的差异是不大的,访问 t-2 和实时的维表产出的数据质量几乎是一样的,所以基于维表构建成本考虑的话,在实时数仓中,这类维表可以访问t-1\t-2的维表数据。 -
实时生成维度的维表:比如用户发生购买行为时,这个订单的维度信息。订单一般都是随着购买行为的发生而生成的,所以其维度信息也需要实时的构建生成,从而满足其他任务能够实时获取到这个订单的维度信息。基于这个特点,这种维表只能进行实时构建。
3、针对这些场景,我们有哪些解决方案去构建实时维表?
缓慢变化维度的维表:
-
应用场景:比如画像类维表,一般画像类基本很少发生变化,比如性别、年龄区间等,所以这类在实时数仓中常常是访问
t-1维表数据的就足够使用 -
常用存储介质:redis,hbase,mysql
-
维表构建方式:一般维表数据都存储在 hive 中,可以使用同步工具(比如 Apache SeaTunnel)定时调度(比如 Apache DolphinScheduler)将 hive 中的数据导入 redis,hbase,mysql 中
实时生成维度的维表:
-
应用场景:维度实时发生更新的,这类在实时数仓中需要访问最新的维度数据
-
常用存储介质:redis,hbase,mysql
-
维表构建方式:这种实时的维度数据一般是实时生成,存储在原始日志中,比如常见存储在 Kafka 这类消息队列中,可以通过 Flink 消费原始日志,然后实时构建维度数据写入 redis,hbase,mysql 中
三、你碰到过哪些数据倾斜的问题,又是怎么缓解或避免数据倾斜问题的?
1、业务数据本身的特点导致倾斜
场景:拿计算直播间的同时在线观看用户数来说,大 v 直播间的人数会比小直播间的任务多几个量级,因此如果计算一个直播间的数据需要注意这种业务数据倾斜的特点
解决方案:计算这种数据时,我们可以先按照直播间 id 将数据进行打散,如下 SQL 案例所示(DataStream 也是相同的解决方案),内层打散,外层合并:
select
id,
sum(bucket_uv) as uv
from (
select
id,
count(distinct uid) as bucket_uv
from source
group by
id,
mod(uid, 1000) -- 将大 v 分桶打散
)
group by id
2、数据任务处理时参数\代码处理逻辑导致倾斜
场景:比如有时候虽然用户已经按照 key 进行分桶计算,但是【最大并发度】设置为 150,【并发度】设置为 100,会导致 keygroup 在 sub-task 的划分不均匀(其中 50 个 sub-task 的 keygroup 为 2 个,剩下的 50 个 sub-task 为 1 个)导致数据倾斜。
解决方案:设置合理的【最大并发度】【并发度】,【最大并发度】最好为【并发度】的倍数关系,比如【最大并发度】1024,【并发度】512
3、我已经设置【数据分桶打散】+【最大并发为并发 n 倍】,为啥还出现数据倾斜?
场景:你的【数据分桶】和【最大并发数】之间可能是不均匀的。因为 Flink 会将 keyby 的 key 拿到之后计算 hash 值,然后根据 hash 值去决定发送到那个 sub-task 去计算。
这是就有可能出现你的【数据分桶】key 经过 hash 计算完成之后,并不能均匀的发到所有的 keygroup 中。
比如【最大并发数】4096,【数据分桶】key 只有 1024 个,那么这些数据必然最多只能到 1024 个 keygroup 中,有可能还少于 1024,从而导致剩下的 3072 个 keygroup 没有任何数据
解决方案:其实可以利用【数据分桶】key 和【最大并行度】两个参数,在 keyby 中实现和 Flink key hash 选择 keygroup 的算法一致的算法,在【最大并发数】4096,【数据分桶】为 4096 时,做到分桶值为 1 的数据一定会发送到 keygroup1 中,2 一定会发到 keygroup2 中,从而缓解数据倾斜。
四、你一般是将实时数据存储到哪里提供对外服务?有没有标准的数据服务方式?
很多人都能提到我们是将数据写入到 ClickHouse,Doris,MySQL 提供服务的。
但是其实这个问题是聚焦于是否有规范的数据服务方式。这里的规范的数据服务方式怎么理解呢?
举一个需求案例:
电商场景中需要要给商家出一个实时 GMV 的数据,这个数据服务的整体链路实时数仓 -> 后端 -> 前端。
那么实时数仓就是数据的提供方,后端就是数据的使用方。
-
后端作为数据的使用方来说,后端期望的能达到的最好的数据服务方式就是实时数仓能提供一个 RPC、HTTP 接口给我,后端只需要把商家 ID 传进去,这个接口就能把商家的实时 GMV 数据给我。
-
实时数仓作为数据的提供方来说,很多数据开发者都只具备数据开发的能力,不具备提供 RPC、HTTP 接口的能力。
那么为了解决上面这个实时数仓和后端之间数据服务的问题。就诞生了阿里的那套 OneService 能力。
五、你们公司在遇到大促时是怎么估算实时任务资源的,有没有成体系的方案可以参考?
一般有 3 种思路去成体系预估资源:
1、目前在线任务的资源占用情况评估
-
适用场景:目前存量(在线)任务要在大促中使用时的场景。
-
举例:比如历史大促时,流量是 n,资源会用 x,今年预估流量最大是 2n,则资源可以认为也是 2x 就足够。
-
预估的准确率:
高
2、按照目前很多云厂商提供的标准评估
-
适用场景:大促新开发的任务,并且没有之前的经验可以借鉴的场景。
-
举例:比如我们的 dwd 任务(简单业务),一般就 1CU 处理 1w qps 数据,复杂的清洗可能流量会讲到更低;dws,ads 任务(复杂任务)一般就 1CU 处理 5k qps 数据;涉及到访问外部接口时,则要使用访问外部接口的 qps / 接口请求时延评估。
-
预估准确率:
中。这些标准都是云厂商经过无数的测试、压测得到的,大家可以参考。

3、新模块、新任务评估
-
适用场景:大促新开发的任务,之前的经验可以借鉴的场景。
-
举例:比如按照历史大促情况来看,一个模块、一类任务的处理能力。
比如分模块来说,历史经验 1 个模块基本需要 n cu(云厂商 1cu = 1core 4GB),当前有 5 个模块,则大致需要 5n cu;又比如分任务类型来说,历史经验 dwd 可以达到 1CU x qps,dws、ads 可以到达 1CU y qps,根据需求来看总共 3 dwd,每个 dwd 2x qps,5 ads,每个 ads 3y qps,则 dwd 总共需要 6CU,ads 总共需要 15CU
-
预估准确率:
高。这个一般都是自己公司内部的历史经验,所以可参考性更高。
六、ValueState 和 MapState 各自适合的应用场景?
1、ValueState
-
应用场景:简单的一个变量存储,比如
Long\String等。如果状态后端为 RocksDB,极其不建议在 ValueState 中存储一个大 Map,这种场景下序列化和反序列化的成本非常高,这种常见适合使用 MapState。其实这种场景也是很多小伙伴一开始使用 State 的误用之痛,一定要避免。 -
TTL:针对整个 Value 起作用
2、MapState
-
应用场景:和 Map 使用方式一样一样的
-
TTL:针对 Map 的 key 生效,每个 key 一个 TTL
七、Flink 任务 failover 之后,可能会重复写出数据到 Sink 中,你们公司是怎么做到端对端 exactly-once 的?
端对端 exactly-once 有 3 个条件:
-
Source 引擎可以重新消费,比如 Kafka 可以重置 offset 进行重新消费
-
Flink 任务配置 exactly-once,保证 Flink 任务 State 的 exactly-once
-
Sink 算子支持两阶段或者可重入,保证产出结果的 exactly-once
其中前两项一般大多数引擎都支持,我们需要关注的就是第 3 项,目前有两种常用方法:
1、Sink 两阶段:由于两阶段提交是随着 Checkpoint 进行的,假设 Checkpoint 是 5min 做一次,那么数据对下游消费方的可见性延迟至少也是 5min,所以会有数据延迟等问题,目前用的比较少。
2、Sink 支持可重入:举例:
-
Sink 为 MySQL:可以按照 key update 数据
-
Sink 为 Druid:聚合类型可以选用 longMax
-
Sink 为 ClickHouse:查询时使用 longMax 或者使用 ReplacingMergeTree 表引擎将重复写入的数据去重,这里有小伙伴会担心 ReplacingMergeTree 会有性能问题,但是博主认为其实性能影响不会很大,因为 failover 导致的数据重复其实一般情况下是小概率事件,并且重复的数据量也不会很大,也只是一个 Checkpoint 周期内的数据重复,所以使用 ReplacingMergeTree 是可以接受的)
-
Sink 为 Redis:按照 key 更新数据
八、OLAP 引擎那么多,是因为 ClickHouse 的哪个特点促使它的性能的突出?
一些我们能在其他 OLAP 引擎上面见到的优化有:
-
列存储
-
编码压缩
-
多索引
-
物化视图(Cube/Rollup)
在 ClickHouse 上特别突出的有:
-
应景优化
-
向量化执行
-
持续测试和持续改进
1.列存储
ClickHouse 采用列存储,这对于分析型请求非常高效。
行存储:从存储系统读取所有满足条件的行数据,然后在内存中过滤出需要的字段,速度较慢。比如,一个表有 10 列,我其实只查 1 列数据的话,行存储还是会把 10 列数据都扫描一遍。

列存储:仅从存储系统中读取必要的列数据,无用列不读取,速度非常快。相同的例子,一个表有 10 列,我其实只查 1 列数据的话,列存储就只扫描这一列数据

2. 编码压缩
由于 ClickHouse 采用列存储,相同列的数据连续存储,且底层数据在存储时是经过排序的,这样数据的局部规律性非常强,有利于获得更高的数据压缩比。
此外,ClickHouse 除了支持 LZ4、ZSTD 等通用压缩算法外,还支持 Delta、DoubleDelta、Gorilla 等专用编码算法,用于进一步提高数据压缩比。
其中 DoubleDelta、Gorilla 是 Facebook 专为时间序数据而设计的编码算法,理论上在列存储环境下,可接近专用时序存储的压缩比,详细可参考 Gorilla 论文。

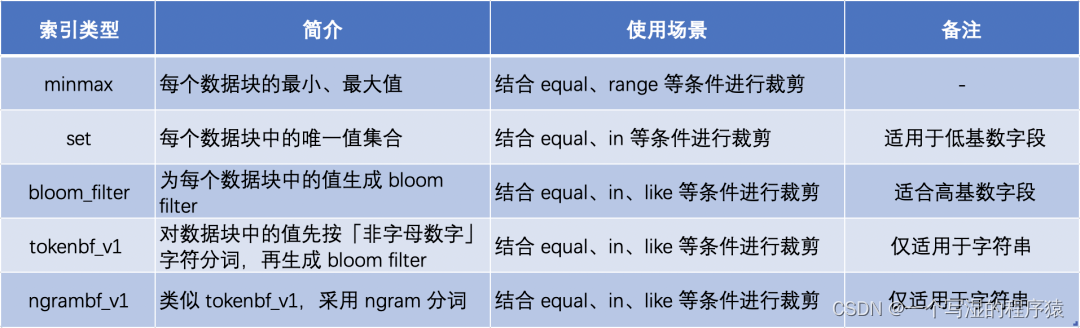
3.多索引
列存用于裁剪不必要的字段读取,而索引则用于裁剪不必要的记录读取。ClickHouse 支持丰富的索引,从而在查询时尽可能的裁剪不必要的记录读取,提高查询性能。
ClickHouse 中最基础的索引是主键索引。ClickHouse 的底层数据按建表时指定的 ORDER BY 列进行排序,并按 index_granularity 参数切分成数据块,然后抽取每个数据块的第一行形成一份稀疏的排序索引。
用户在查询时,如果查询条件包含主键列,则可以基于稀疏索引进行快速的裁剪。
ClickHouse 支持更多其他的索引类型,不同索引用于不同场景下的查询裁剪,具体汇总如下,更详细的介绍参考 ClickHouse 官方文档:
4.物化视图(Cube/Rollup)
OLAP 分析领域有两个典型的方向:
-
ROLAP:通过列存、索引等各类技术手段,提升查询时性能。
-
MOLAP:通过预计算提前生成聚合后的结果数据,降低查询读取的数据量,属于计算换性能方式。
前者更为灵活,但需要的技术栈相对复杂;后者实现相对简单,但要达到的极致性能,需要生成所有常见查询对应的物化视图,消耗大量计算、存储资源。
物化视图的原理如下图所示,可以在不同维度上对原始数据进行预计算汇总,这样我们查询时就可以直接查询到聚合好的数据上面,查询效率更高:

5.场景优化
其会在不同的场景使用不同的算法。
例如,在去重函数 uniqCombined 中,会根据数据量选择不同的算法:数据量比较少的时候,会选择使用 Array 来保存;数据量中等的时候,使用 HashSet;数据量很大的时候,会使用 HyperLogLog 算法。
并且表引擎很丰富,有 20 多种,每种表引擎都做了很多的优化,这个道理就和小伙伴萌工作时为每类工作场景专门设计对应的解决方案一样,效果当然是不错的。
6.向量化执行
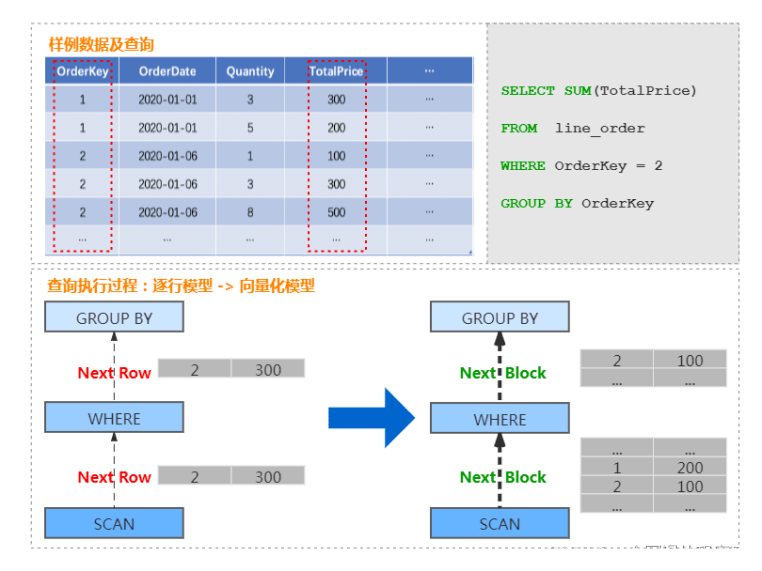
向量化执行。SIMD 被广泛地应用于文本转换、数据过滤、数据解压和 JSON 转换等场景。相对于单纯使用 CPU,利用寄存器暴力优化也算是一种降维打击,毕竟 “能用机器资源解决的问题就别手动优化”。
以商品订单数据为例,查询某个订单总价格的处理过程,由传统的按行遍历处理的过程,转换为按 Block 处理的过程。
具体如下图:
7.持续测试和持续改进
由于拥有 Yandex 的天然优势,经常会使用真实数据来进行测试,尝试使用于各个场景。也因此获得了快速的版本更新换代,基本维持在一个月一更新。
并且在业界有新的算法出现时,ClickHouse 的开发人员也会积极去测试。
九、ClickHouse 不支持高并发,这是真的吗?Redis支持高并发这也是真的吗?
其实这个问题主要是为了让大家不要陷入一个固有想法中。
举个例子:
-
ClickHouse 中一个表只有 1w 行数据,ClickHouse 的并发能力不会差
-
当 Redis 中存储 200MB value 的 string 时,Redis 的并发也上不去的
只是这些引擎尝尝被用于满足对应场景的需求。
比如 ClickHouse 用于大宽表的灵活 SQL 计算,这种场景的并发肯定不会很高。Redis 常被用于小 key 小 value set,get 场景,那么这种场景的并发肯定也不会低的。
每种引擎都有对应的瓶颈处,只要你没有达到这个瓶颈阈值,并发都不会低。
十、让你使用用户心跳日志(20s 上报一次)计算同时在线用户、DAU 指标,你怎么设计链路?
参考了其它的解决方案,大概分为几种:
1、⭐ 有提到 bitmap、hyberloglog、布隆过滤器、redis 等方法计算去重的
2、⭐ 有提到将用户上线标记为 1,下线标记为 0 的,然后将上线下线数据发到消息队列用实时计算引擎统计的
3、⭐ 有提到将用户心跳日志借助 Session Window Dynamic Gap 计算的
首先我们使用最简单直接的方式 2 个指标分拆开来计算:
1、同时在线用户:
-
输入:心跳日志
-
计算方法:
SQL:1min tumble window(count distinct 实际是 MapState)DataStream:1min tumble window(去重可用 bitmap、hyberloglog、布隆过滤器) -
输出:聚合结果数据
2、DAU:
-
输入:心跳日志
-
计算方法:
SQL:1day cumulate window(count distinct 实际是 MapState)DataStream:1day window + continous trigger(去重可用 bitmap、hyberloglog、布隆过滤器) -
输出:聚合结果数据
上面这个方法在 90% 的场景都没有啥问题,但是如果心跳日志数据 QPS 都很大,则每个任务都去消费一遍,链路稳定性差。
这里我们可以做一次优化,我们可以发现上面这 2 个指标其实是有先后顺序关系的。
1、同时在线用户:分钟级别去重
2、DAU:天级别去重
所以为了减少流量,其实同时在线用户可以作为 DAU 的输入。优化链路如下:
1、同时在线用户:
-
输入:心跳日志
-
计算方法:
SQL:row_number() over (partition by unix_time/60 order by proctime)允许一定误差,所以可以使用 proctimeDataStream:去重可用 bitmap、hyberloglog、布隆过滤器,输出这一分钟去重后的明细输出 -
输出:同时在线明细
2、DAU:
-
输入:【同时在线用户】明细数据
-
计算方法:
SQL:row_number() over (partition by unix_time/24/3600 order by proctime)DataStream:去重可用 bitmap、hyberloglog、布隆过滤器,输出这一分钟去重后的明细输出 -
输出:DAU 的明细
最终这样输出的数据无论是在来一个 ads 任务做聚合还是直接导入到 MySQL、ClickHouse、Druid 都可以,因为都只是计算 count 而已。
十一、Flink 配置 State TTL 时都有哪些配置项?每种配置项的作用?
Flink 对状态做了能力扩展,即 TTL。它的能力其实和 redis 的过期策略类似,举例:
-
支持 TTL 更新类型:更新 TTL 的时机
-
访问到已过期数据的时的数据可见性
-
过期时间语义:目前只支持处理时间
-
具体过期实现:lazy,后台线程
那么首先我们看下什么场景需要用到 TTL 机制呢?举例:
比如计算 DAU 使用 Flink MapState 进行去重,到第二天的时候,第一天的 MapState 就可以删除了,就可以用 Flink State TTL 进行自动删除(当然你也可以通过代码逻辑进行手动删除)。
其实在 Flink DataStream API 中,TTL 功能还是比较少用的。Flink State TTL 在 Flink SQL 中是被大规模应用的,几乎除了窗口类、ETL(DWD 明细处理任务)类的任务之外,SQL 任务基本都会用到 State TTL。
那么我们在要怎么开启 TTL 呢?这里分 DataStream API 和 SQL API:
1、⭐ DataStream API:
private final MapStateDescriptor<String, List<Item>> mapStateDesc =
new MapStateDescriptor<>(
"itemsMap",
BasicTypeInfo.STRING_TYPE_INFO,
new ListTypeInfo<>(Item.class));
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 使用 StateTtlConfig 开启 State TTL
mapStateDesc.enableTimeToLive(StateTtlConfig
.newBuilder(Time.milliseconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupInRocksdbCompactFilter(10)
.build());
}
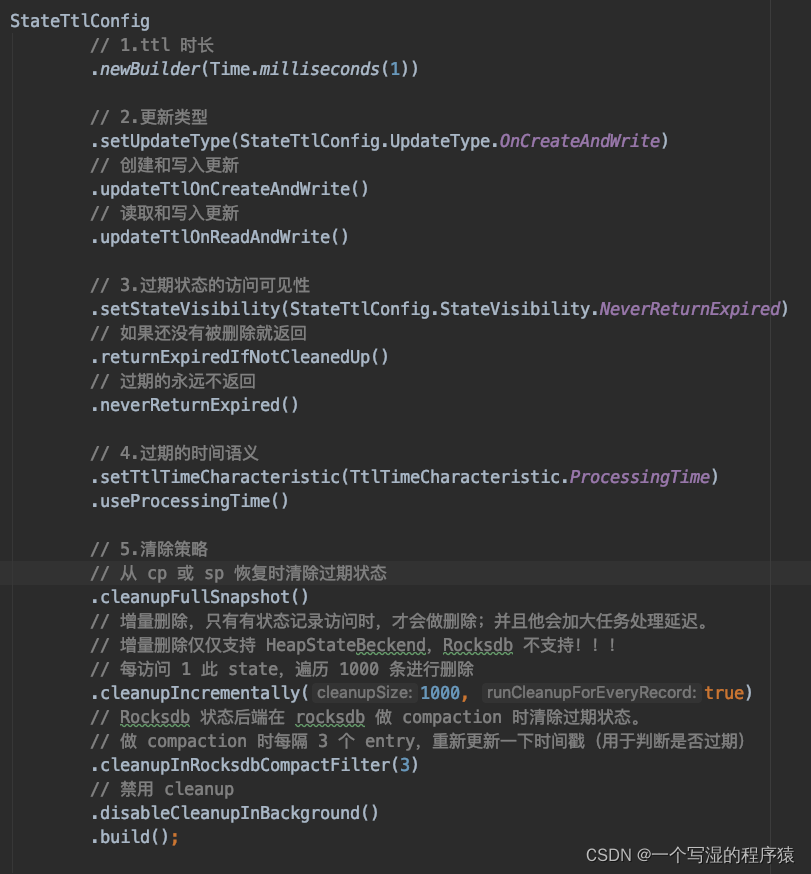
关于 StateTtlConfig 的每个配置项的功能如下图所示:
2、⭐ SQL API:
StreamTableEnvironment
.getConfig()
.getConfiguration()
.setString("table.exec.state.ttl", "180 s");
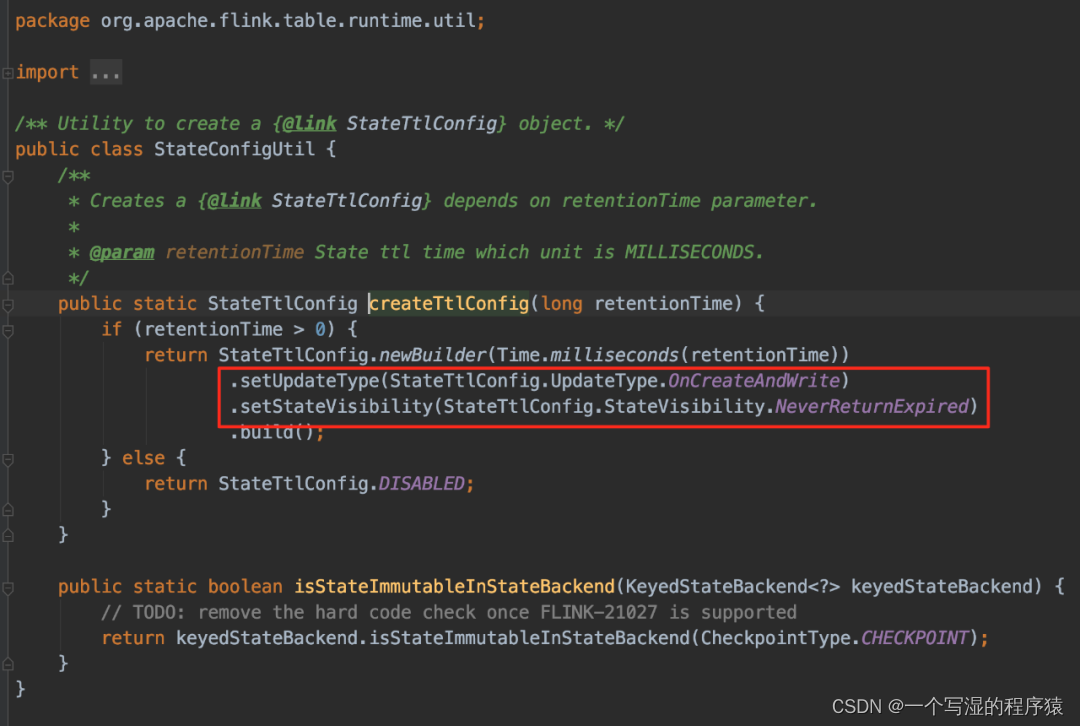
注意:SQL 中 TTL 的策略不如 DataStream 那么多,SQL 中 TTL 只支持下图所示策略:
十二、Flink State TTL 是怎么做到数据过期的?
首先我们来想想,要做到 TTL 的话,要具备什么条件呢?
想想 Redis 的 TTL 设置,如果我们要设置 TTL 则必然需要给一条数据给一个时间戳,只有这样才能判断这条数据是否过期了。
在 Flink 中设置 State TTL,就会有这样一个时间戳,具体实现时,Flink 会把时间戳字段和具体数据字段存储作为同级存储到 State 中。
举个例子,我要将一个 String 存储到 State 中时:
-
没有设置
State TTL时,则直接将 String 存储在 State 中 -
如果设置
State TTL时,则 Flink 会将 <String, Long> 存储在 State 中,其中 Long 为时间戳,用于判断是否过期。
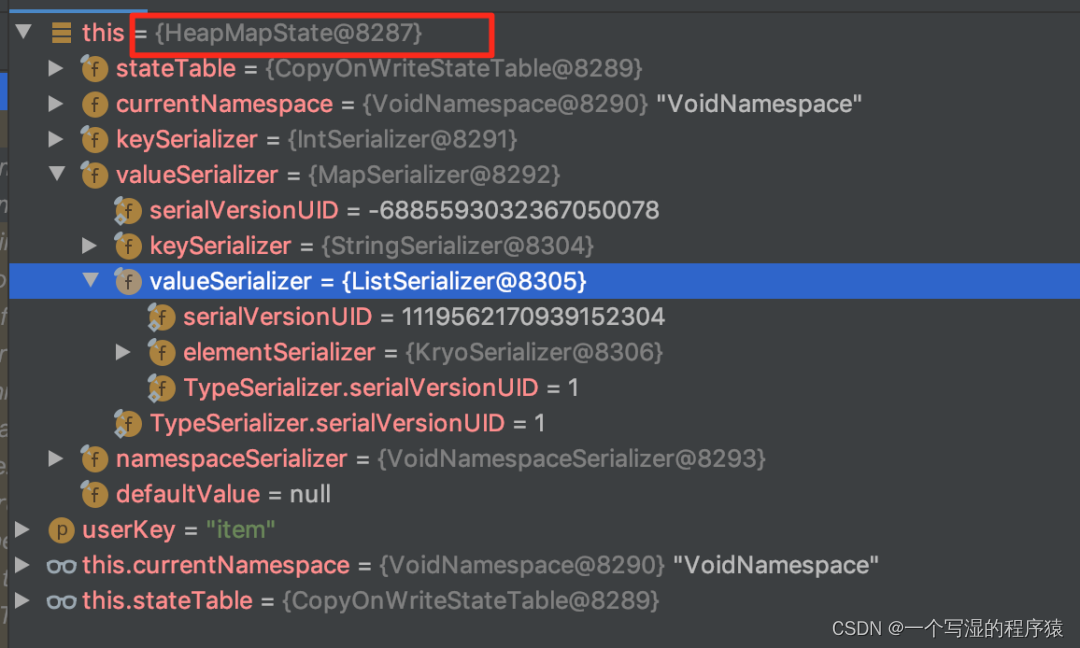
接下来以 FileSystem 状态后端下的 MapState 作为案例来说:
-
如果没有设置 State TTL,则生产的 MapState 的字段类型如下(可以看到生成的就是 HeapMapState 实例):
-
如果设置了 State TTL,则生成的 MapState 的字段类型如下(可以看到使用到了装饰器的设计模式生成是 TtlMapState):
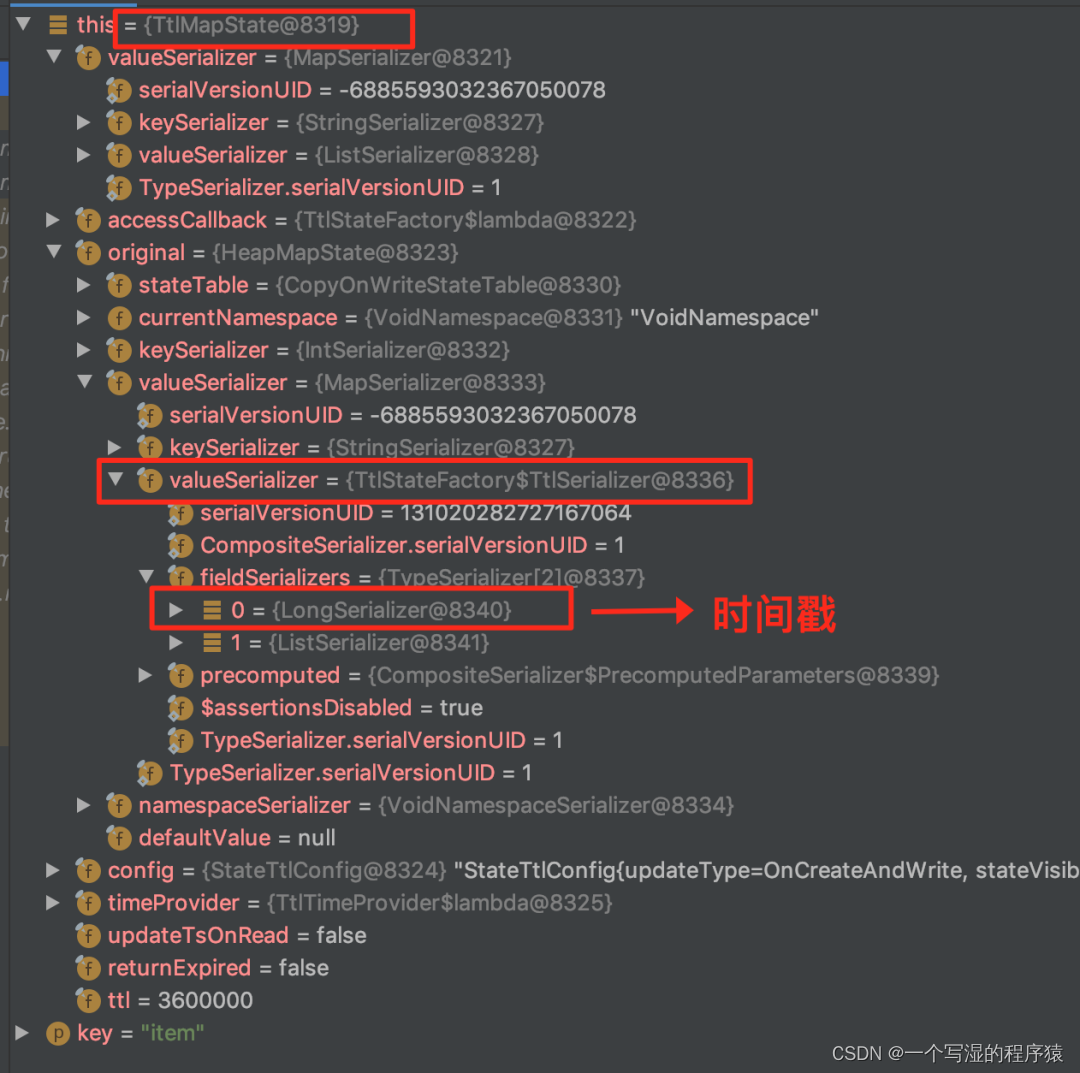
注意:
任务设置了 State TTL 和不设置 State TTL 的状态是不兼容的。这里大家在使用时一定要注意。防止出现任务从 Checkpoint 恢复不了的情况。但是你可以去修改 TTL 时长,因为修改时长并不会改变 State 存储结构。
了解了基础数据结构之后,我们再来看看 Flink 提供的 State 过期的 4 种删除策略:
-
lazy删除策略:就是在访问 State 的时候根据时间戳判断是否过期,如果过期则主动删除 State 数据 -
full snapshot cleanup删除策略:从状态恢复(checkpoint、savepoint)的时候采取做过期删除,但是不支持 rocksdb 增量 ck -
incremental cleanup删除策略:访问 state 的时候,主动去遍历一些 state 数据判断是否过期,如果过期则主动删除 State 数据 -
rocksdb compaction cleanup删除策略:rockdb 做 compaction 的时候遍历进行删除。仅仅支持 rocksdb
1.lazy 删除策略
访问 State 的时候根据时间戳判断是否过期,如果过期则主动删除 State 数据。以 MapState 为例,如下图所示,在 MapState.get(key) 时会进行判断是否过期:
这个删除策略是不需要用户进行配置的,只要你打开了 State TTL 功能,就会默认执行。
2.full snapshot cleanup 删除策略
从状态恢复(checkpoint、savepoint)的时候采取做过期删除,但是不支持 rocksdb 增量 checkpoint。
StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build()
3.incremental cleanup 删除策略
访问 state 的时候,主动去遍历一些 state 数据判断是否过期,如果过期则主动删除 State 数据。
StateTtlConfig
.newBuilder(Time.seconds(1))
// 每访问 1 此 state,遍历 1000 条进行删除
.cleanupIncrementally(1000, true)
.build()
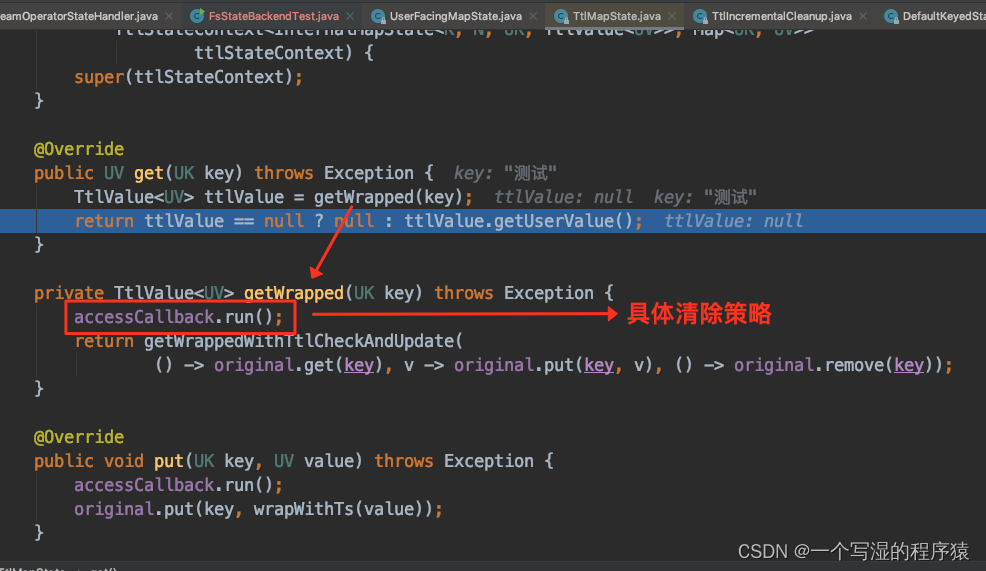
注意:
-
如果没有 state 访问,也没有处理数据,则不会清理过期数据。
-
增量清理会增加数据处理的耗时。
-
现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。
-
因为是遍历删除 State 机制,并且每次遍历的条目数是固定的,所以可能会出现部分过期的 State 很长时间都过期不掉导致 Flink 任务 OOM。
4.rocksdb compaction cleanup 删除策略
仅仅支持 rocksdb。在 rockdb 做 compaction 的时候遍历进行删除。
StateTtlConfig
.newBuilder(Time.seconds(1))
// 做 compaction 时每隔 3 个 entry,重新更新一下时间戳(这个时间戳是 Flink 用于和数据中的时间戳来比较判断是否过期)
.cleanupInRocksdbCompactFilter(3)
.build()
注意:rocksdb compaction 时调用 TTL 过滤器会降低 compaction 速度。因为 TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。对于集合型状态类型(比如 ListState 和 MapState),会对集合中每个元素进行检查。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









