









一、Background
实体识别和关系提取的目标是从非结构化文本中发现实体提及的关系结构。传统的方法是以pipeline的方式分离两个子任务:NER和RE。这有两个缺点:错误传播和没有利用到关联信息。然后就开始做联合抽取的工作。刚开始的联合抽取依赖于手工特征;然后神经网络的兴起缓解了这个问题,但是一些工作依赖于外部工具。注意,上述工作检查关系提取的实体对,而不是直接对整个句子建模。这意味着不考虑同一句子中其他实体对的关系 - 这可能有助于确定特定对的关系类型。
二、Motivation
- 目前State-of-the-art的联合模型依赖外部的NLP工具提取特征,然而这些特征泛化性不行;
- pipeling的方法有两个缺点:错误传播、没有利用到两个任务的关联性。
- 之前的工作没有考虑multi-head problem,一个实体可能有多个关系。
因此作者提出了同时进行NER和RE的联合模型,解决了之前工作的几个问题:不依赖于外部NLP工具,手工特征;同时提取同一文本片段(通常是句子)内的实体和关系;一个实体可以同时参与多个关系。
三、Model
模型的架构如图一所示。模型包括以下结构:embedding layer,BiLSTM layer,CRF layer,sigmoid scoring layer。每个单词的模型输出有两部分:实体标签,比如I-PER;头实体以及关系的元组集合,比如:{(Center, Works for),(Atlanta, Lives in)}。为了消除实体冗余关系,在多个实体中最后一个词才能作为另一个实体的头部,比如‘John Smith’和‘Disease Control Center’存在‘Works for’关系,并不是所有实体连在一起,我们只连接‘Smith’和‘Center’。如果不存在关系,标签为N。
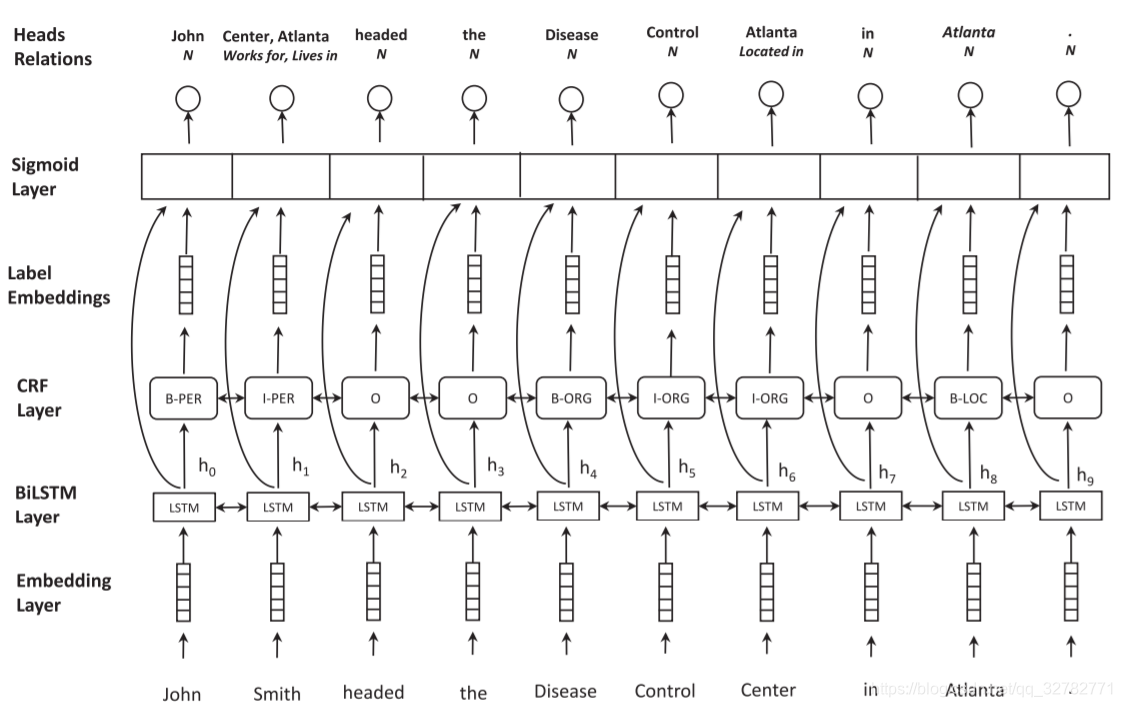
-
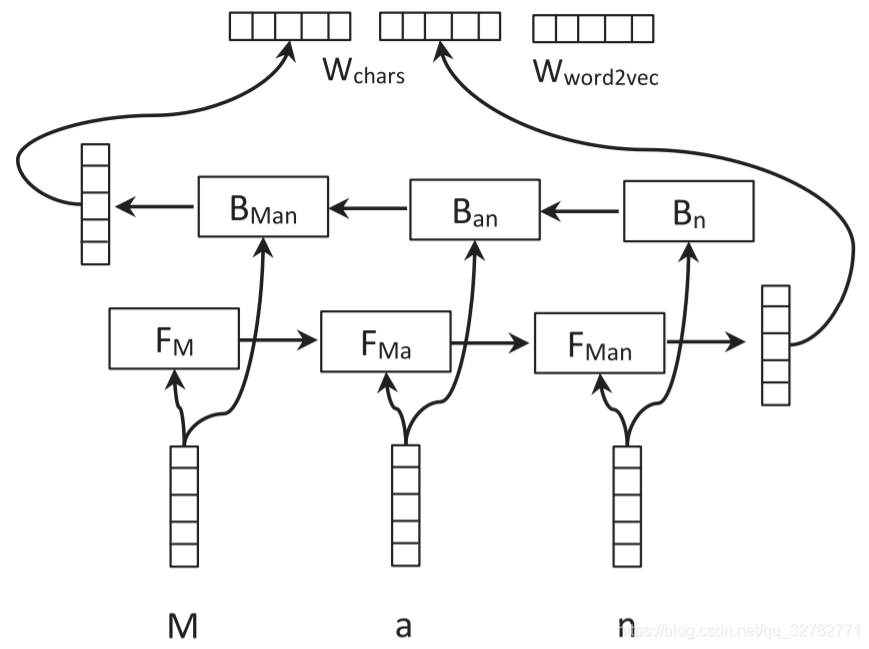
Embedding Layer: 字符级别的Embedding经过双向LSTM之后与词Embedding拼接在一起,得到词向量的最终表示。字符级Embedding在随着模型训练。
-
BiLSTM Layer: 使用双向LSTM获得词的上下文表示。
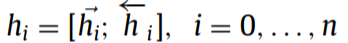
-
NER: 以序列标注的方法解决NER,使用BIO(Begining,Inside,Outside)标注机制。每个实体包含有一个或多个tokens,我们需要为每个token打上标签。这样我们就知道每个实体的开始结束位置以及实体类型。词向量经过双向LSTM之后,我们紧接着一个softmax层或CRF层计算每个token最可能的标签。我们计算每个token w i w_i wi的每个标签的分数:
s ( e ) ( h i ) = V ( e ) f ( U ( e ) h i + b ( e ) ) s^{(e)}(h_i)=V^{(e)}f(U^{(e)}h_i+b^(e)) s(e)(hi)=V(e)f(U(e)hi+b(e))
符号(e)表示NER任务的参数。f()是激活函数(relu,tanh), V ( e ) ∈ R p × l V^{(e)}\in R^{p\times l} V(e)∈Rp×l, U ( e ) ∈ R l × 2 d U^{(e)}\in R^{l\times 2d} U(e)∈Rl×2d, b ( e ) ∈ R l b^{(e)}\in R^{l} b(e)∈Rl,d是隐藏层单元数,p是NER的标签数,l是全连接层参数。计算概率: P R ( t a g ∣ w i ) = s o f t m a x ( s ( h i ) ) PR(tag|w_i)=softmax(s(h_i)) PR(tag∣wi)=softmax(s(hi)),softmax方法只用于实体分类任务,只需预测实体类型,假设实体边界给定。softmax方法独立地输出最高概率的标签,没有考虑到标签之间的依赖信息。在NER中,BIO机制就考虑到了标签依赖的情况,比如B-LOC后面不能接I-PER。假设词向量为w,LSTM的状态分数 s 1 ( e ) , . . . , s n ( e ) s_1^{(e)},...,s_n^{(e)} s1(e),...,sn(e),预测的标签序列 y 1 ( e ) , . . . , y n ( e ) y_1^{(e)},...,y_n^{(e)} y1(e),...,yn(e),线性链CRF的得分为: S ( y 1 ( e ) , . . . , y n ( e ) ) = ∑ i = 0 n s i , y i ( e ) ( e ) + ∑ i = 1 n − 1 T y i ( e ) , y i + 1 ( e ) S(y_1^{(e)},...,y_n^{(e)})=\sum_{i=0}^ns_{i,y_i^{(e)}}^{(e)}+\sum_{i=1}^{n-1}T_{y_i^{(e)},y_{i+1}^{(e)}} S(y1(e),...,yn(e))=∑i=0nsi,yi(e)(e)+∑i=1n−1Tyi(e),yi+1(e),所有可能的预测标签序列的概率为:
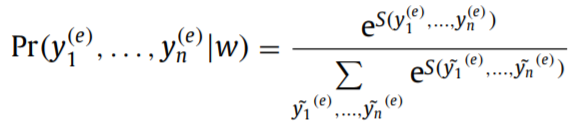
输入到关系抽取层有两个方面:LSTM的输出状态、学习到的label embedding表示。在训练过程中,使用正确的实体标签,在测试阶段,使用预测的实体标签作为输入传给下一词。总之,下一层的输入是LSTM的隐藏层状态 h i h_i hi和label embedding g i g_i gi的拼接:
z i = [ h i ; g i ] , i = 0 , . . . , n z_i=[h_i;g_i],i=0,...,n zi=[hi;gi],i=0,...,n -
Relation extraction as multi-head selection: 本篇论文中,作者将关系抽取任务建模为multi-head selection问题。每个单词 w i w_i wi可能有多个头(与其它词有多种关系)。对每个token w i w_i wi,我们预测元祖 ( y ^ i , c ^ i ) (\hat y_i,\hat c_i) (y^i,c^i), y ^ i \hat y_i y^i表示头向量, c ^ i \hat c_i c^i是对应的关系向量。这与之前标准头选择的依赖性解析方法不同,它扩展为预测多个头实体,头和关系的决策是共同作出的(而不是首先预测头实体,然后使用额外的分类器在下一步骤中预测关系)。给定单词序列w和关系标签集R,我们的目标是对于每个单词 w i w_i wi,确定它的最可能的头实体 y ^ i ⊆ w \hat y_i\subseteq w y^i⊆w以及最可能的相对应的关系标签 r ^ i ⊆ R \hat r_i\subseteq R r^i⊆R。我们根据 r k r_k rk计算 w i w_i wi和 w j w_j wj的分数:
s ( r ) ( z j , z i , r k ) = V ( r ) f ( U ( r ) z j + W ( r ) z i + b ( r ) ) s^{(r)}(z_j,z_i,r_k)=V^{(r)}f(U^{(r)}z_j+W^{(r)}z_i+b^{(r)}) s(r)(zj,zi,rk)=V(r)f(U(r)zj+W(r)zi+b(r))
其中符号®表示关系抽取的参数,f()函数是激活函数(relu,tanh), V ( r ) ∈ R l V^{(r)}\in R^{l} V(r)∈Rl, U ( r ) ∈ R l × ( 2 d + b ) U^{(r)}\in R^{l\times (2d+b)} U(r)∈Rl×(2d+b), W ( r ) ∈ R l × ( 2 d + b ) W^{(r)}\in R^{l\times (2d+b)} W(r)∈Rl×(2d+b), b ( e ) ∈ R l b^{(e)}\in R^{l} b(e)∈Rl,d是隐藏层单元数,b是label embedding的大小,l是全连接层参数。
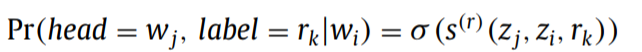
最小化交叉熵损失函数:
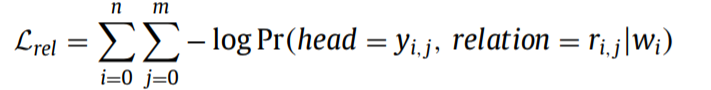

















 4109
4109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









