






最近写毕业论文,用了Latex,然后就是用了bibtex作为文献管理,太折磨了,中国知网居然不能直接导出bibtex格式ANDbitex编译也太慢了吧!!!,于是我就想用bibitem,下面写了个py的脚本,奉献给被bibtex折磨疯的小伙伴。Python脚本自动排序\begin{thebibliography}引用自动排序脚本。
功能概述
1. 智能引用检测:递归扫描主文档及所有`\input`子文件
2. 自动排序:按实际引用顺序重排文献条目
3. 未引用标注:将未引用的文献条目转为注释,同时注释掉的被引用也能恢复
4. 安全备份:自动生成`.bak`备份文件
5. 编码支持:强制UTF-8编码处理,自己改改也能兼容其他。
配置修改
用文本编辑器打开脚本,修改这行:
processor = UTF8ReferenceProcessor(main_file="tutorial.tex") # 修改为你的主tex文件路径
把脚本和主tex文件放一个目录, 然后运行脚本就可以了,完事了,就是这么简单。
上代码
好了废话不多说,直接上代码!
import re
import os
import shutil
from collections import OrderedDict
#desinged by TangJianfu-2025.3
class UTF8ReferenceProcessor:
def __init__(self, main_file):
self.root_dir = os.path.dirname(main_file)
self.main_file = main_file
self.citation_order = OrderedDict()
self.bib_file = None
self.processed_files = set()
def resolve_path(self, input_path):
"""解析LaTeX输入路径"""
base_path = re.sub(r'\.tex$', '', input_path, flags=re.IGNORECASE)
for ext in ['', '.tex']:
full_path = os.path.normpath(os.path.join(self.root_dir, f"{base_path}{ext}"))
if os.path.exists(full_path):
return full_path
raise FileNotFoundError(f"文件未找到: {input_path}")
def parse_structure(self, file_path):
"""递归解析文档结构"""
if file_path in self.processed_files:
return
self.processed_files.add(file_path)
try:
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines() # 改为逐行读取
except UnicodeDecodeError as e:
raise ValueError(f"UTF-8解码失败: {file_path}") from e
# 捕获参考文献文件路径
if not self.bib_file:
for line in lines:
#通过判断begin{thebibliography}识别参考文献所在文件目录
match = re.search(r'\\begin{(.*?thebibliography*?)}', line, re.IGNORECASE)
if match:
self.bib_file = file_path
break
# 收集所有引用(新增逐行处理)
for line_num, line in enumerate(lines, 1):
# 注释检查,注释则跳过
if line.strip().startswith(('%', '%%')):#判断注释
continue
#寻找这行中的input,并递归处理input(保持原有逻辑)
content = ''.join(line)
for match in re.finditer(r'\\input{(.+?)}', line):
child_path = self.resolve_path(match.group(1))
self.parse_structure(child_path)
#寻找这行中的引用
for match in re.finditer(r'\\(?:cite[ptss]*|citess){([^}]+)}', line):
# 收集引用
for key in match.group(1).split(','):
clean_key = key.strip()
if clean_key and clean_key not in self.citation_order:
self.citation_order[clean_key] = None
def replace_between(self,bib_content, firstPos, finPos, newstr):
# 查找起始索引
start_index = bib_content.find(firstPos)
if start_index == -1:
return bib_content # firstPos未找到,返回原字符串或抛出异常
# 在start_index之后查找finPos的起始索引
end_index = bib_content.rfind(finPos, start_index)
if end_index == -1:
return bib_content # finPos未找到,返回原字符串或抛出异常
# 计算finPos的结束位置
end_index_end = end_index + len(finPos)
# 拼接新字符串
return bib_content[:start_index].strip('\n') + newstr + bib_content[end_index_end:].strip('\n')
def process_bibliography(self):
"""处理参考文献排序"""
if not self.bib_file:
raise ValueError("未检测到参考文献文件")
# 读取文献内容
try:
with open(self.bib_file, 'r', encoding='utf-8') as f:
bib_content = f.read()
except UnicodeDecodeError as e:
raise ValueError(f"参考文献文件非UTF-8编码: {self.bib_file}") from e
# 提取文献条目
entries = {}
item_pattern = re.compile(
r'(\\bibitem{([^}]+)}.*?)(?=\\bibitem{|\\end{thebibliography}|$)',
re.DOTALL
)
for match in item_pattern.finditer(bib_content):
entries[match.group(2)] = match.group(1).strip().strip('%').strip('\n').replace('\n%','\n')
# 生成排序后的内容
#被引用了的条目(排序后)
sorted_items = [entries[key] for key in self.citation_order if key in entries]
#未使用的条目
unused_items = [f"%{modified_entry}" for key, entry in entries.items() if key not in self.citation_order for modified_entry in [entry.replace('\n', '\n%')]]
firstPos= entries[list(entries.keys())[0]]#第一个bititem
finPos=entries[list(entries.keys())[-1]]#最后一个bititem
new_content= self.replace_between(bib_content, firstPos, finPos, "\n\n"+'\n\n'.join(sorted_items+unused_items)+'\n\n')
# 安全写入(保留备份)
backup_path = f"{self.bib_file}.bak"
shutil.copyfile(self.bib_file, backup_path)
with open(self.bib_file, 'w', encoding='utf-8') as f:
f.write(new_content)
def execute(self):
"""执行入口"""
self.parse_structure(self.main_file)
self.process_bibliography()
print(f"文献排序处理完成!已引用 {len(self.citation_order)} 篇文献;\n已经覆写文件{self.bib_file},原始文件备份于{self.bib_file}.bak")
if __name__ == "__main__":
processor = UTF8ReferenceProcessor(main_file="tutorial.tex")#主latex文件地址
processor.execute()#执行代码
这就完了?当然是实现自动一体化,如果你用的是vscode,在配置文件里修改。
"latex-workshop.latex.tools"里添加脚本:
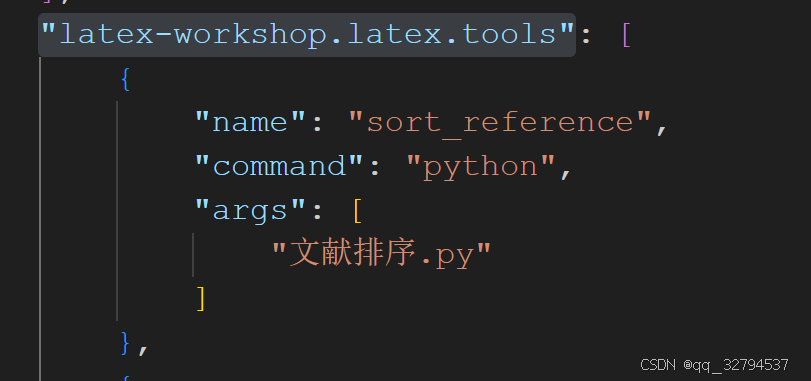
然后配置在latex编译前,先运行脚本,配置"latex-workshop.latex.recipes"。

大功成告!后面就正常编译latex就可以啦,再也不用担心任何的排版引用和手动运行问题啦!
下面是AI生成的,随便看看,溜了溜了!!
🔍 工作原理
1. **文件解析**
- 通过正则表达式匹配`\cite`系列命令
- 支持`\input`嵌套文件的递归解析
- 自动跳过注释内容(以%开头的行)
2. **文献处理**
- 识别`thebibliography`环境位置
- 按首次引用顺序重排`\bibitem`
- 未引用条目添加`%`注释符
3. **安全机制**
- 自动创建`.bak`备份文件
- UTF-8编码强制校验
⚠️ 注意事项
1. **编码规范**
- 确保所有tex文件均为**UTF-8无BOM**格式
- 常见乱码问题解决方法:
```python
# 在VSCode中可通过"编码保存"功能转换
File -> Save with Encoding -> UTF-8
2. **文献规范**
- 仅支持原生`thebibliography`环境
- 如需处理`.bib`文件请使用BibTeX
3. **路径识别**
- 主文件路径需使用`/`或双反斜杠`\\`
- 示例:`main_file="D:/论文/正文.tex"`
📂 文件结构建议
```
论文项目/
├── 主文件.tex
├── chapters/
│ ├── 引言.tex
│ └── 实验.tex
└── 文献排序.py
```
💡 高级技巧
- **批量处理**:创建bat脚本实现一键运行
```bat
@echo off
python 文献排序.py
pause


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









