







首先简单讲一下:其实我觉得这两个本质上是一样的 看了好多博客和论坛 发现每个人讲的都不一样,我直接去英文维基百科 特征缩放上查了Feature scaling 和 英文维基百科 标准化 才基本上明白
博客的最后 我会特别说一下 吴恩达老师在讲解PCA的时候 说的 均值标准化和特征缩放
这里直接翻译过来
特征缩放
目的
由于原始数据的值范围变化很大,在一些机器学习算法中,如果没有标准化,目标函数将无法正常工作。例如,大多数分类器按欧几里德距离计算两点之间的距离。如果其中一个要素具有宽范围的值,则距离将受此特定要素的控制。因此,应对所有特征的范围进行归一化,以使每个特征大致与最终距离成比例。
应用特征缩放的另一个原因是梯度下降与特征缩放比没有它时收敛得快得多。
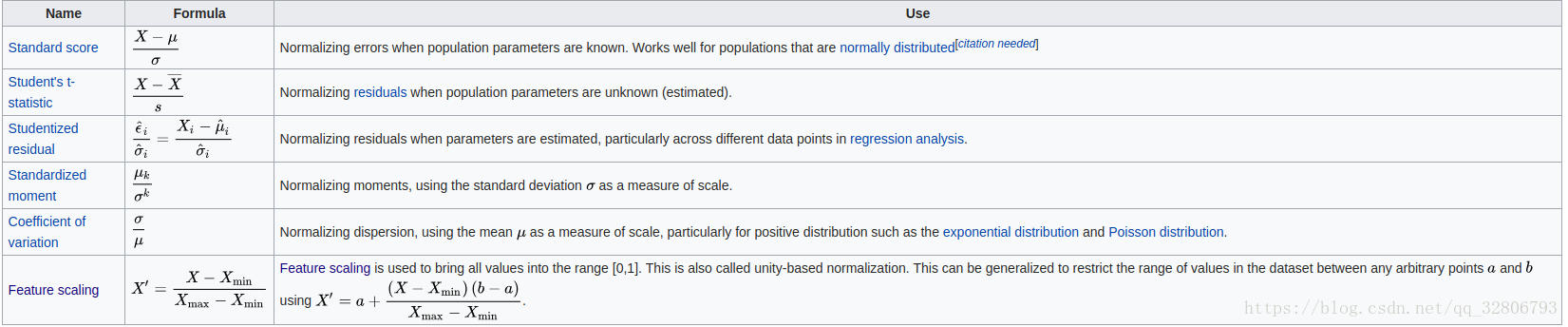
特征缩放的方法
min-max normalization)
X 是一个原始值,X’是标准化值。例如,假设我们有学生的体重数据,学生的体重跨度[160磅,200磅]。要重新调整此数据,我们首先从每个学生的体重中减去160,然后将结果除以40(最大和最小权重之间的差异)。

Mean normalization

Standardization
在机器学习中,我们可以处理各种类型的数据,例如音频信号和图像数据的像素值,并且该数据可以包括多个维度。特征标准化使得数据中每个特征的值具有零均值(当减去分子中的平均值时)和单位方差。该方法广泛用于许多机器学习算法(例如,支持向量机,逻辑回归和人工神经网络)的归一化。一般的计算方法是确定分布均值和标准差对于每个功能。接下来,我们从每个特征中减去平均值。然后我们将每个特征的值(平均值已被减去)除以其标准偏差。

Scaling to unit length(缩放到单位长度)
在机器学习中广泛使用的另一种选择是缩放特征向量的分量,使得完整向量具有长度1。这通常意味着将每个组件除以向量的欧几里德长度:
在一些应用中(例如直方图特征),使用特征向量的L1范数(即曼哈顿距离,城市块长度或出租车几何)可能更实际。如果在以下学习步骤中将标量度量用作距离度量,则这尤其重要。

应用
在随机梯度下降中,特征缩放有时可以提高算法的收敛速度。在支持向量机中,它可以减少查找支持向量的时间。请注意,特征缩放会更改SVM结果。
这里针对前者 直接给出两张图
未进行特征缩放的
事实上如果这些轮廓再被放大一些的话,如果你画的再夸张一些把它画的更细更长,那么可能情况会更糟糕,梯度下降的过程可能更加缓慢,需要花更长的时间反复来回振荡,最终才找到一条正确通往全局最小值的路。
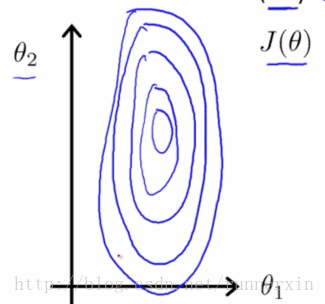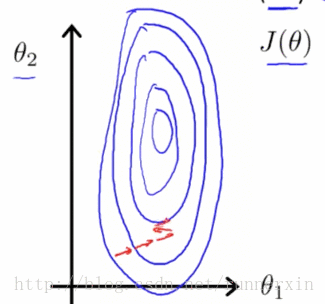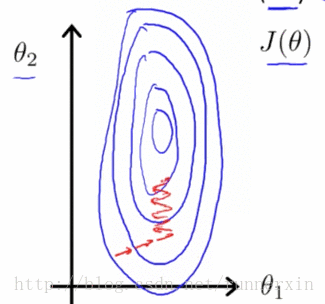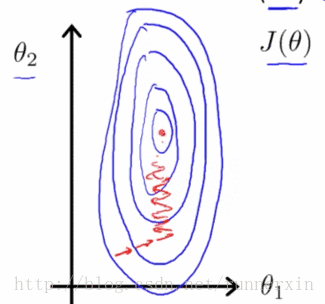
进行特征缩放的
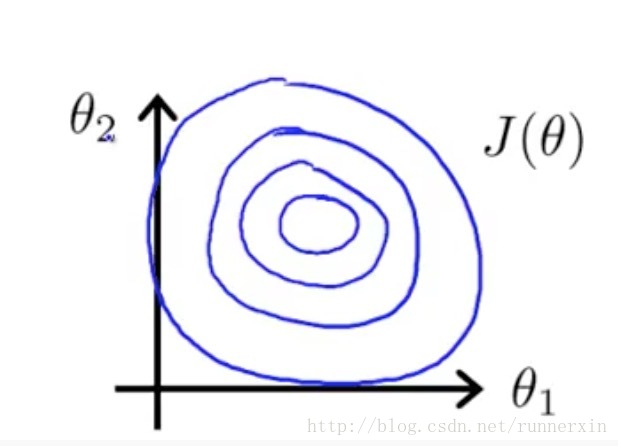
如果你用这样的代价函数来执行梯度下降的话,那么可以从数学上来证明梯度下降算法将会找到一条更捷径的路径通向全局最小,而不是像刚才那样 沿着一条让人摸不着头脑的路径,来找到全局最小值。
因此在这个例子中,通过特征缩放,我们最终得到的两个特征x1和 x2都在0和1之间,这样你得到的梯度下降算法就会更快地收敛。
标准化
这里真的不想多说什么,直接附上一张图
吴恩达 讲解的PCA时候说的 均值标准化 特征缩放
就是简单的将每一个特征减去它的均值,最后会使每个特征都具有0均值
特征缩放就是上面的最大-最小 特征缩放法















 980
980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









