







在上一篇的最后我们获取到了peer列表,那么接下去我们就要跟peer列表中的每个节点建立连接,然后请求获取文件分片的具体内容了。
请求文件
// Download downloads the torrent. This stores the entire file in memory.
func (t *Torrent) Download() ([]byte, error) {
log.Println("Starting download for", t.Name)
// Init queues for workers to retrieve work and send results
// 初始化队列供工作人员检索工作并发送结果
workQueue := make(chan *pieceWork, len(t.PieceHashes))
results := make(chan *pieceResult)
for index, hash := range t.PieceHashes {
// 计算每个分片的大小 最后一片大小可能小于 PieceSize
length := t.calculatePieceSize(index)
// 放入 工作队列
workQueue <- &pieceWork{index, hash, length}
}
// Start workers
for _, peer := range t.Peers {
go t.startDownloadWorker(peer, workQueue, results)
}
// Collect results into a buffer until full
// 将结果收集到缓冲区中直至充满
buf := make([]byte, t.Length)
donePieces := 0
for donePieces < len(t.PieceHashes) {
res := <-results
// 这一步提取 到 torrent 中
begin, end := t.calculateBoundsForPiece(res.index)
copy(buf[begin:end], res.buf)
donePieces++
percent := float64(donePieces) / float64(len(t.PieceHashes)) * 100
numWorkers := runtime.NumGoroutine() - 1 // subtract 1 for main thread
log.Printf("(%0.2f%%) Downloaded piece #%d from %d peers\n", percent, res.index, numWorkers)
}
close(workQueue)
return buf, nil
}
- 遍历hash列表,根据index据算出每个分片的大小(起始位置和结束位置),然后放入工作队列
- 根据获取到的peer节点列表,创建连接,并执行下载操作
- 收集下载的结果,并写入到内存中的一个
[]byte中
接下来我们一步步解析
下载
对于每个Peers我们要完成一下操作:
- 与Peers启动TCP连接
- 完成双向BitTorrent 握手
- 交换消息以下载片段
func (t *Torrent) startDownloadWorker(peer peers.Peer, workQueue chan *pieceWork, results chan *pieceResult) {
c, err := client.New(peer, t.PeerID, t.InfoHash)
if err != nil {
log.Printf("Could not handshake with %s. Disconnecting\n", peer.IP)
return
}
defer c.Conn.Close()
log.Printf("Completed handshake with %s\n", peer.IP)
c.SendUnchoke()
c.SendInterested()
for pw := range workQueue {
// bitfield 初始化状态是 255,255,255... 1111 1111
// 255>>(7-0)&1 != 0
// true -> 未下载
if !c.Bitfield.HasPiece(pw.index) {
// 当前 分片已经下载完成
workQueue <- pw // Put piece back on the queue
continue
}
// Download the piece
buf, err := attemptDownloadPiece(c, pw)
if err != nil {
log.Println("Exiting", err)
// 出错了,把任务放回队列
workQueue <- pw // Put piece back on the queue
return
}
// 校验 当前下载完成的分片
err = checkIntegrity(pw, buf)
if err != nil {
log.Printf("Piece #%d failed integrity check\n", pw.index)
workQueue <- pw // Put piece back on the queue
continue
}
// 告知已经下载完成
c.SendHave(pw.index)
results <- &pieceResult{pw.index, buf}
}
}
握手
建立TCP连接
conn, err := net.DialTimeout("tcp", peer.String(), 3*time.Second)
if err != nil {
return nil, err
}
BitTorrent握手由五个部分组成:
- 协议标识符的长度.始终为19 byte(十六进制为0x13)
- 协议标识符.称为pstr.始终为BitTorrent protocol
- 八个保留字节.都设置为0.我们会将其中一些翻转为1.以表示我们支持某些扩展.但是我们没有.所以我们将它们保持为0.
- 我们之前计算出的信息哈希值.用于确定所需的文件
- 我们用来识别自己的Peer ID
构造一个表示握手的结构。并编写一些用于序列化和读取它们的方法
// 握手实体类的结构体
type Handshake struct {
Pstr string
InfoHash [20]byte
PeerID [20]byte
}
// 初始化数据封装
func New(infoHash, peerID [20]byte) *Handshake {
return &Handshake{
Pstr: "BitTorrent protocol",
InfoHash: infoHash,
PeerID: peerID,
}
}
// 进行序列化
func (h *Handshake) Serialize() []byte {
buf := make([]byte, len(h.Pstr)+49)
// 协议的长度
buf[0] = byte(len(h.Pstr))
curr := 1
// 协议名
curr += copy(buf[curr:], h.Pstr)
// 8 个 0
curr += copy(buf[curr:], make([]byte, 8)) // 8 reserved bytes
// info hash
curr += copy(buf[curr:], h.InfoHash[:])
// peerId
curr += copy(buf[curr:], h.PeerID[:])
return buf
}
// 响应数据反序列化
func Read(r io.Reader) (*Handshake, error) {
lengthBuf := make([]byte, 1)
// 填充满 lengthBuf
_, err := io.ReadFull(r, lengthBuf)
if err != nil {
return nil, err
}
pstrlen := int(lengthBuf[0])
if pstrlen == 0 {
err := fmt.Errorf("pstrlen cannot be 0")
return nil, err
}
// 根据协议 应该要有 48+19 个字节
handshakeBuf := make([]byte, 48+pstrlen)
_, err = io.ReadFull(r, handshakeBuf)
if err != nil {
return nil, err
}
var infoHash, peerID [20]byte
copy(infoHash[:], handshakeBuf[pstrlen+8:pstrlen+8+20])
copy(peerID[:], handshakeBuf[pstrlen+8+20:])
h := Handshake{
Pstr: string(handshakeBuf[0:pstrlen]),
InfoHash: infoHash,
PeerID: peerID,
}
return &h, nil
}
完成握手
// completeHandshake 完成握手
func completeHandshake(conn net.Conn, infohash, peerID [20]byte) (*handshake.Handshake, error) {
conn.SetDeadline(time.Now().Add(3 * time.Second))
defer conn.SetDeadline(time.Time{}) // Disable the deadline
req := handshake.New(infohash, peerID)
_, err := conn.Write(req.Serialize())
if err != nil {
return nil, err
}
// 从连接中读取 流
res, err := handshake.Read(conn)
if err != nil {
return nil, err
}
// 返回的 info hash != info hash
if !bytes.Equal(res.InfoHash[:], infohash[:]) {
return nil, fmt.Errorf("Expected infohash %x but got %x", res.InfoHash, infohash)
}
return res, nil
}
确认节点状态
在完成了握手之后,我们需要确认节点已经准备好给我们提供数据了。
如果对方没有准备好接受消息,那么在他们告诉我们他们已经准备好之前,我们无法发送任何消息。
在这种状态下,我们被其他Peer 认为choked。他们会向我们发送一条unchoke锁定的消息。
让我们知道可以开始向他们询问数据了。默认情况下,我们假设在没有其他证明之前被choked。
取消锁定后.我们就可以开始发送文件片段请求.他们可以向我们发送包含文件片段的消息.
消息的结构是 4byte 表示 Payload 长度,ID表示正在接收的Message Type。
const (
// MsgChoke chokes the receiver
MsgChoke messageID = 0
// MsgUnchoke unchokes the receiver
MsgUnchoke messageID = 1
// MsgInterested expresses interest in receiving data
MsgInterested messageID = 2
// MsgNotInterested expresses disinterest in receiving data
MsgNotInterested messageID = 3
// MsgHave alerts the receiver that the sender has downloaded a piece
MsgHave messageID = 4
// MsgBitfield encodes which pieces that the sender has downloaded
MsgBitfield messageID = 5
// MsgRequest requests a block of data from the receiver
MsgRequest messageID = 6
// MsgPiece delivers a block of data to fulfill a request
MsgPiece messageID = 7
// MsgCancel cancels a request
MsgCancel messageID = 8
)
type Message struct {
ID messageID
Payload []byte
}
Bitfield
当 messageID = 5 的时候代表这是一个Bitfield消息,Payload里的内容: 1个byte 对应 8个bit ,1个bit对应一个分片,0完成,1就是未完成。
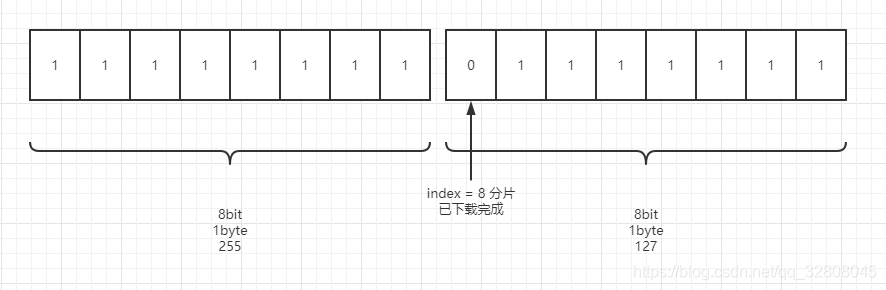
// recvBitfield 接收 Bitfield
func recvBitfield(conn net.Conn) (bitfield.Bitfield, error) {
conn.SetDeadline(time.Now().Add(5 * time.Second))
defer conn.SetDeadline(time.Time{}) // Disable the deadline
msg, err := message.Read(conn)
if err != nil {
return nil, err
}
if msg == nil {
err := fmt.Errorf("Expected bitfield but got %s", msg)
return nil, err
}
// 消息不是 MsgBitfield
if msg.ID != message.MsgBitfield {
err := fmt.Errorf("Expected bitfield but got ID %d", msg.ID)
return nil, err
}
return msg.Payload, nil
}
下载分片
// 尝试下载分片
func attemptDownloadPiece(c *client.Client, pw *pieceWork) ([]byte, error) {
// 进度
state := pieceProgress{
index: pw.index,
client: c,
buf: make([]byte, pw.length),
}
// Setting a deadline helps get unresponsive peers unstuck.
// 30 seconds is more than enough time to download a 262 KB piece
c.Conn.SetDeadline(time.Now().Add(30 * time.Second))
defer c.Conn.SetDeadline(time.Time{}) // Disable the deadline
// 已经下载的字节 当前分片的总长度
for state.downloaded < pw.length {
fmt.Println(state.index, state.downloaded)
// If unchoked, send requests until we have enough unfulfilled requests
if !state.client.Choked {
// 节点准备好了
// 保持一定数量的未完成请求.这样可以将连接的吞吐量提高一个数量级
// 此部分是单线程 所以 backlog 只会有当前线程修改
// 已经发送的 块 请求数量 == MaxBacklog && 已经发出 获取 分片总大小 == 当先分片大小,会读取剩余的请求
for state.backlog < MaxBacklog && state.requested < pw.length {
blockSize := MaxBlockSize
// Last block might be shorter than the typical block
// 最后一块可能比典型块短
if pw.length-state.requested < blockSize {
blockSize = pw.length - state.requested
}
// 发送需要下载的分片 index start end
err := c.SendRequest(pw.index, state.requested, blockSize)
if err != nil {
return nil, err
}
state.backlog++
state.requested += blockSize
}
}
// 一直读取 会获取节点状态
err := state.readMessage()
if err != nil {
return nil, err
}
}
return state.buf, nil
}
文件分片的逻辑
pieces 是所有分片的Hash列表,所以 len(pieces) 就是分片数量了。
文件(文件实际大小为 length )根据 pieces length 分成 len(pieces) 个分片,最后一个分片实际大小 >= pieces length ,因为文件不可能完美 对齐 分片长度,这个应该是好理解的。
在解析完.torrent文件之后,我们其实已经可以得到一个公式:
length = pieces length * (len(pieces) - 1) + (length % pieces length)
并且可以得出每个分片的在实际文件中的起始位置和结束位置。

start = 分片索引号 * 分片大小
end = (分片索引号 + 1) + 分片大小
最后一个分片的
end = (分片索引号 + 1) + (总大小 % 分片大小)
or
end = 总大小 - (分片索引号 * 分片大小)
这一块需要着重理解的原因是下载多文件种子的时候,分片需要写入其对应的文件的对应位置里面。
func TestPieces(t *testing.T) {
files := []FileInfo{{
FilePath: "/a/b/c/a.docx",
Length: 0,
Start: 0,
End: 0,
}, {
FilePath: "/a/CascadiaCode-2102.25.zip",
Length: 8666729,
Start: 0,
End: 8666729,
}, {
FilePath: "/a/a.txt",
Length: 10,
Start: 8666729,
End: 8666739,
}, {
FilePath: "/1621924130",
Length: 295956,
Start: 8666739,
End: 8962695,
}, {
FilePath: "/a.txt",
Length: 10,
Start: 8962695,
End: 8962705,
}, {
FilePath: "/goTorrent_0.9.0_windows_64-bit.zip",
Length: 7974275,
Start: 8962705,
End: 16936980,
},
}
// 计算每个文件的 start end
// 分片大小 64KB
var pieceLength int64 = 65536
// 所有文件的比特,模拟 http 响应
bigBytePath := "../bit"
// 下载的目标文件夹
targetPath := "./pieces"
// 准备数据
genBigBytes(files, "C:\\Users\\Exler\\Desktop\\bit", bigBytePath)
// 可以删除文件夹
os.RemoveAll(targetPath)
Mkdir(targetPath)
// 计算文件大小
var length int64 = 0
for _, v := range files {
length += v.Length
}
// 分片数量 已知 也可以求出来
// pieces := 259
pieces := length / pieceLength
if length%pieceLength != 0 {
pieces++
}
fmt.Println("片大小", pieceLength)
fmt.Println("分片数", pieces)
temp, err := Reader(bigBytePath)
if err != nil {
fmt.Println(err.Error())
return
}
// 切割成小文件块
var i, end int64
for i = 0; i < pieces; i++ {
if i == pieces-1 && length%pieceLength != 0 {
// 最后一片 可能 没有对齐
// 总长度
end = length
} else {
end = (i + 1) * pieceLength
}
Writer(
fmt.Sprintf("%s/%d", targetPath, i),
temp[i*pieceLength:end])
}
// 在内存中构建 小Byte块
//var buf [][]byte
/* var i, end int64
for i = 0; i < pieces; i++ {
if i == pieces-1 && length%pieceLength != 0 {
end = length
} else {
end = (i + 1) * pieceLength
}
buf = append(buf, temp[i*pieceLength:end])
}
*/
// 计算文件占用的分片? 分片数
// 提前生成一遍所有文件
/*path := "./gen"
for _, f := range files {
dir := path + f.FilePath
os.MkdirAll(dir[:strings.LastIndex(dir, "/")], 0755)
Writer(path+f.FilePath, []byte{})
}
for index, piecesData := range buf {
WriteFile(path, piecesData, files, int64(index), pieceLength)
}*/
//for i, v := range files {
// 文件占用的分片数
//
// WriterOffset(
// fmt.Sprintf("%s/%d", targetPath, i),
// temp[0:0],
// i*pieces)
//}
}
// 寻找对应哪个文件
func WriteFile(path string, bytes []byte, files []FileInfo, index, pieceLength int64) {
start := index * pieceLength
// 最后一个分片不定长
end := start + int64(len(bytes))
// 已经消耗的字节数 跨文件用于重置写入start start - file.end
var consume int64 = 0
// 默认没有跨文件
var spanFileFlag bool
for _, v := range files {
// 重新查找默认 当前分片不跨文件
spanFileFlag = false
// 起始位置 小于 文件的结束位置
// v的结束位置是取不到的
if start < v.End {
// 比较结束位置查看是否跨文件
if end >= v.End {
// 分片end 文件end 相等或者大于 跨文件
// 修改start 继续往下写入
spanFileFlag = true
}
if spanFileFlag {
// 偏移量+已经消耗的 文件结尾
// 跨文件 确定文件的末尾 index
WriterOffset(path+v.FilePath, bytes[consume:v.End%pieceLength], (start+consume)-v.Start)
consume = v.End - start
if consume == pieceLength {
// 消耗的字符已经 等于了 片长度
break
}
continue
} else {
// 偏移量 分片的起始位置 - 文件的起始位置
WriterOffset(path+v.FilePath, bytes[consume:], (start+consume)-v.Start)
break
}
} else {
//文件下载完成
}
// 分片的起始位置>=文件的结束位置 校验下一个文件
}
}
全部代码的Gitee
不过没有做多文件的代码整合(demo已完成,果然没有业务驱动的项目就会流产,能不能“结顶”全凭程序员心情。。。。)














 2781
2781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









