










缓存

简介
Redis是Nosql数据库中使用较为广泛的非关系型内存数据库,redis内部是一个key-value存储系统。它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set –有序集合)和hash(哈希类型,类似于Java中的map)。

应用场景
字符串
字符串类型是Redis最基础的数据结构,字符串类型可以是JSON、XML甚至是二进制的图片等数据,但是最大值不能超过512MB。
1.1 内部编码:
Redis会根据当前值的类型和长度决定使用哪种内部编码来实现。
字符串类型的内部编码有3种:
- int:8个字节的长整型。
- embstr:小于等于39个字节的字符串。
- raw:大于39个字节的字符串。
1.2 使用场景
1.2.1 缓存:
在web服务中,使用MySQL作为数据库,Redis作为缓存。由于Redis具有支撑高并发的特性,通常能起到加速读写和降低后端压力的作用。web端的大多数请求都是从Redis中获取的数据,如果Redis中没有需要的数据,则会从MySQL中去获取,并将获取到的数据写入redis。
1.2.2 计数:
Redis中有一个字符串相关的命令incr key,incr命令对值做自增操作。
比如文章的阅读量,视频的播放量等等都会使用redis来计数,每播放一次,对应的播放量就会加1,同时将这些数据异步存储到数据库中达到持久化的目的。
1.2.3 共享Session:
在分布式系统中,用户的每次请求会访问到不同的服务器,这就会导致session不同步的问题,假如一个用来获取用户信息的请求落在A服务器上,获取到用户信息后存入session。下一个请求落在B服务器上,想要从session中获取用户信息就不能正常获取了,因为用户信息的session在服务器A上,为了解决这个问题,使用redis集中管理这些session,将session存入redis,使用的时候直接从redis中获取就可以了。
1.2.4 限速:
为了安全考虑,有些网站会对IP进行限制,限制同一IP在一定时间内访问次数不能超过n次。
哈希
Redis中,哈希类型是指一个键值对的存储结构。
2.1 内部编码
哈希类型的内部编码有两种:
- ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)同时所有值都小于hash-max-ziplist-value配置(默认64字节)时使用。ziplist使用更加紧凑的结构实现多个元素的连续存储,所以比hashtable更加节省内存。
- hashtable(哈希表):当ziplist不能满足要求时,会使用hashtable。
2.2 使用场景
由于hash类型存储的是一个键值对,比如数据库有以下一个用户表结构

将以上信息存入redis,用表明:id作为key,用户属性作为值:
hset user:1 name Java旅途 age 18
使用哈希存储会比字符串更加方便直观
列表
列表类型用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素,列表的两端都可以插入和弹出元素。
3.1 内部编码
列表的内部编码有两种:
ziplist(压缩列表):当哈希类型元素个数小于list-max-ziplist-entries配置(默认512个)同时所有值都小于list-max-ziplist-value配置(默认64字节)时使用。ziplist使用更加紧凑的结构实现多个元素的连续存储,所以比hashtable更加节省内存。
linkedlist(链表):当ziplist不能满足要求时,会使用linkedlist。
3.2 使用场景
3.2.1 消息队列:
列表用来存储多个有序的字符串,既然是有序的,那么就满足消息队列的特点。使用lpush+rpop或者rpush+lpop实现消息队列。除此之外,redis支持阻塞操作,在弹出元素的时候使用阻塞命令来实现阻塞队列。
3.2.2 栈:
由于列表存储的是有序字符串,满足队列的特点,也就能满足栈先进后出的特点,使用lpush+lpop或者rpush+rpop实现栈。
3.2.3 文章列表:
因为列表的元素不但是有序的,而且还支持按照索引范围获取元素。因此我们可以使用命令lrange key 0 9分页获取文章列表
集合
集合类型也可以保存多个字符串元素,与列表不同的是,集合中不允许有重复元素并且集合中的元素是无序的。一个集合最多可以存储2^32-1个元素。
4.1 内部编码
集合类型的内部编码有两种:
- intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,redis会选用intset来作为集合的内部实现,从而减少内存的使用。
- hashtable(哈希表):当intset不能满足要求时,会使用hashtable。
4.2 使用场景
4.2.1 用户标签:
例如一个用户对篮球、足球感兴趣,另一个用户对橄榄球、乒乓球感兴趣,这些兴趣点就是一个标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同感兴趣的标签。给用户打标签的时候需要①给用户打标签,②给标签加用户,需要给这两个操作增加事务。
给用户打标签
sadd user:1:tags tag1 tag2
给标签添加用户
sadd tag1:users user:1
sadd tag2:users user:1
使用交集(sinter)求两个user的共同标签
sinter user:1:tags user:2:tags
4.2.2 抽奖功能:
集合有两个命令支持获取随机数,分别是:
- 随机获取count个元素,集合元素个数不变
srandmember key [count]
- 随机弹出count个元素,元素从集合弹出,集合元素个数改变
spop key [count]
用户点击抽奖按钮,参数抽奖,将用户编号放入集合,然后抽奖,分别抽一等奖、二等奖,如果已经抽中一等奖的用户不能参数抽二等奖则使用spop,反之使用srandmember。
有序集合
有序集合和集合一样,不能有重复元素。但是可以排序,它给每个元素设置一个score作为排序的依据。最多可以存储2^32-1个元素。
5.1 内部编码
有序集合类型的内部编码有两种:
- ziplist(压缩列表):当有序集合的元素个数小于list-max-ziplist-entries配置(默认128个)同时所有值都小于list-max-ziplist-value配置(默认64字节)时使用。ziplist使用更加紧凑的结构实现多个元素的连续存储,更加节省内存。
- skiplist(跳跃表):当不满足ziplist的要求时,会使用skiplist。
5.2 使用场景
5.2.1 排行榜:
用户发布了n篇文章,其他人看到文章后给喜欢的文章点赞,使用score来记录点赞数,有序集合会根据score排行。流程如下:
用户发布一篇文章,初始点赞数为0,即score为0
zadd user:article 0 a
有人给文章a点赞,递增1
zincrby user:article 1 a
查询点赞前三篇文章
zrevrangebyscore user:article 0 2
查询点赞后三篇文章
zrangebyscore user:article 0 2
5.2.2 延迟消息队列
下单系统,下单后需要在15分钟内进行支付,如果15分钟未支付则自动取消订单。将下单后的十五分钟后时间作为score,订单作为value存入redis,消费者轮询去消费,如果消费的大于等于这笔记录的score,则将这笔记录移除队列,取消订单。
安装
下载、解压、编译
wget https://download.redis.io/releases/redis-6.0.10.tar.gz
tar -zvxf redis-6.0.10.tar.gz
mv redis-6.0.10 /usr/local/redis
cd /usr/local/redis
make
make PREFIX=/usr/local/redis install
#PREFIX= 这个关键字的作用是编译的时候用于指定程序存放的路径。比如我们现在就是指定了redis必须存放在/usr/local/redis目录。假设不添加该关键字Linux会将可执行文件存放在/usr/local/bin目录,库文件会存放在/usr/local/lib目录。配置文件会存放在/usr/local/etc目录。其他的资源文件会存放在usr/local/share目录。-------指定目录方便后续的卸载
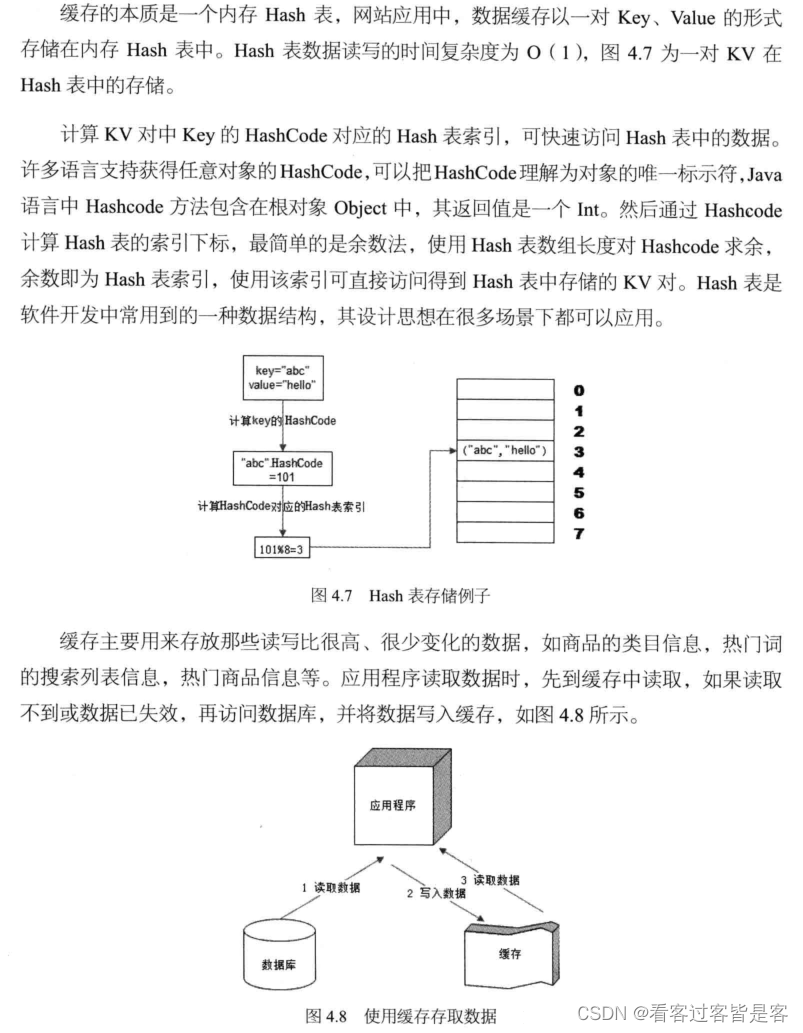
如果报错
yum install cpp binutils glibc glibc-kernheaders glibc-common glibc-devel gcc
#升级gcc
yum -y install centos-release-scl devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash
#设置永久升级
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
#重新make
make
修改配置文件
vi /usr/local/redis/redis.conf
daemonize yes
# bind 127.0.0.1 (注释掉该行)
protected-mode no
启动
/usr/local/bin/redis-server /usr/local/redis/redis.conf
redis-cli
开机启动配置
echo "/usr/local/bin/redis-server /usr/local/redis/redis.conf &" >> /etc/rc.local
[root@master redis]# ps -aux | grep redis
root 13246 0.0 0.4 162384 7892 ? Ssl 21:52 0:00 /usr/local/bin/redis-server *:6379
root 13259 0.0 0.0 112816 984 pts/0 S+ 21:52 0:00 grep --color=auto redis
简单测试
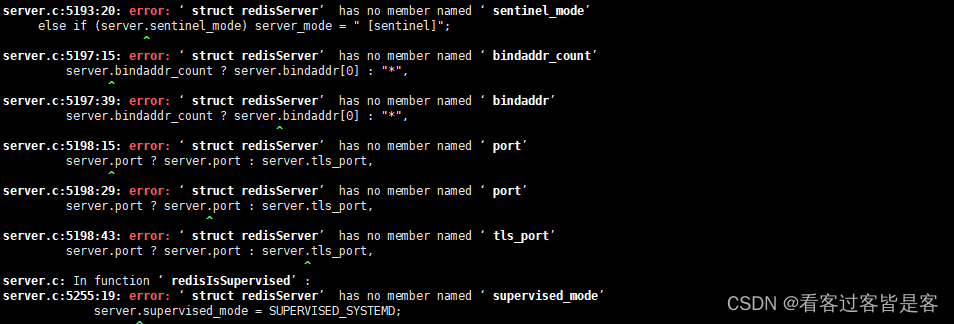
# 测试:100个并发连接 100000请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
Redis是单线程的,Redis是基于内存操作的。
- 所以Redis的性能瓶颈不是CPU,而是机器内存和网络带宽。
Redis为什么单线程还这么快?
- 误区1:高性能的服务器一定是多线程的?
- 误区2:多线程(CPU上下文会切换!)一定比单线程效率高!
核心:Redis是将所有的数据放在内存中的,所以说使用单线程去操作效率就是最高的,多线程(CPU上下文会切换:耗时的操作!),对于内存系统来说,如果没有上下文切换效率就是最高的,多次读写都是在一个CPU上的,在内存存储数据情况下,单线程就是最佳的方案。
主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower), 数据的复制是单向的!只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
- 默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点。
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
- 故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
- 负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
- 高可用基石:主从复制还是哨兵和集群能够实施的基础。
为什么使用集群
- 单台服务器难以负载大量的请求
- 单台服务器故障率高,系统崩坏概率大
- 单台服务器内存容量有限
查看当前库的信息:
启动多个服务,就需要多个配置文件。每个配置文件对应修改以下信息:
- 端口号 port 6379
- pid文件名 pidfile /var/run/redis_6379.pad
- 日志文件名 logfile “6379.log”
- rdb文件名 dbfilename dump6379.rdb
cp redis.conf redis80.conf
cp redis.conf redis81.conf
vi redis80.conf
vi redis81.conf
/usr/local/bin/redis-server /usr/local/redis/redis80.conf
/usr/local/bin/redis-server /usr/local/redis/redis81.conf
ps -ef|grep redis
redis-cli -p 6380
slaveof 192.168.9.203 6379
redis-cli -p 6381
slaveof 192.168.9.203 6379


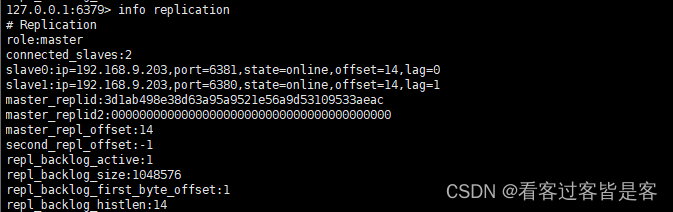
以上便是(命令行)一主多从的暂时性配置,重启就会变成主机,只能再次设置命令行成为主机,这时会自动进行全量复制/增量复制。若想永久配置,则需要在在从机的配置文件中进行配置
(replicaof <主的 IP 地址> <主 的 Redis 端口号>)。
--------------全量复制和增量复制---------
全量复制:第一次成为salve或重新成为salve,会进行一次全量复制数据。
1)主节点收到全量复制的命令后,执行bgsave,在后台生成RDB文件,并使用一个复制缓冲区记录从现在开始执行的所有写命令(防止rdb后的数据丢失)
2)主节点的bgsave执行完成后,将RDB文件发送给从节点;从节点首先清除自己的旧数据,然后载入接收的RDB文件,将数据库状态更新至主节点执行bgsave时的数据库状态
3)主节点将前述复制缓冲区中的所有写命令发送给从节点,从节点执行这些写命令,将数据库状态更新至主节点的最新状态
增量复制:后续的salve都是通过增量复制来同步master的数据
-------------让从节点再次变成主节点---------
通过命令:saveof no one
redis集群
redis集群是一个无中心的分布式Redis存储架构,可以在多个节点之间进行数据共享,解决了Redis高可用、可扩展等问题。redis集群提供了以下两个好处
- 将数据自动切分(split)到多个节点
- 当集群中的某一个节点故障时,redis还可以继续处理客户端的请求。
一个 Redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个。集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽。集群中的每一个节点负责处理一部分哈希槽。
集群中的主从复制
集群中的每个节点都有1个至N个复制品,其中一个为主节点,其余的为从节点,如果主节点下线了,集群就会把这个主节点的一个从节点设置为新的主节点,继续工作。这样集群就不会因为一个主节点的下线而无法正常工作。
注意:
- 如果某一个主节点和他所有的从节点都下线的话,redis集群就会停止工作了。redis集群不保证数据的强一致性,在特定的情况下,redis集群会丢失已经被执行过的写命令
- 使用异步复制(asynchronous replication)是 Redis
集群可能会丢失写命令的其中一个原因,有时候由于网络原因,如果网络断开时间太长,redis集群就会启用新的主节点,之前发给主节点的数据就会丢失。
创建的6个redis节点,其中三个为主节点,三个为从节点:
192.168.9.203:7000
192.168.9.203:7001
192.168.9.203:7002
192.168.9.203:7003
192.168.9.203:7004
192.168.9.203:7005
mkdir 7000
mkdir 7001
mkdir 7002
mkdir 7003
mkdir 7004
mkdir 7005
cp redis.conf 7000
cp redis.conf 7001
cp redis.conf 7002
cp redis.conf 7003
cp redis.conf 7004
cp redis.conf 7005
修改配置文件redis.conf
daemonize yes
port 6379 #端口不同
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
进入每个启动目录,以每个目录下的redis.conf文件启动
redis-server redis.conf
ps -ef | grep redis
yum install ruby rubygems
gem install redis
redis-trib.rb create --replicas 1 192.168.9.203:7000 192.168.9.203:7001 192.168.9.203:7002 192.168.9.203:7003 192.168.9.203:7004 192.168.9.203:7005
#进入集群
redis-cli -c -p 7000
redis-cli -c -p 7000 cluster nodes | grep master
集群添加节点
根据添加节点类型的不同,有两种方法来添加新节点
1、主节点:如果添加的是主节点,那么我们需要创建一个空节点,然后将某些哈希槽移动到这个空节点里面
2、从节点:如果添加的是从节点,我们也需要创建一个空节点,然后把这个新节点设置成集群中某个主节点的复制品。
添加节点:
1、首先把需要添加的节点启动
创建7006目录,拷贝7000中的redis.conf到7006中,然后修改端口port为7006,修改好后进入7006目录启动这个节点
2、执行以下命令,将这个新节点添加到集群中:
redis-trib.rb add-node 192.168.9.203:7006 192.168.9.203:7000
3、执行命令查看刚才新增的节点:redis-cli -c -p 7000 cluster nodes
4、增加了新的节点之后,这个新的节点可以成为主节点或者是从节点
4.1将这个新增节点变成从节点
让新节点成为192.168.9.203:7001的从节点,只需要执行下面的命令就可以了,命令后面的节点ID就是192.168.9.203:7001的节点ID。(注意,这个从节点哈希槽必须为空,如果不为空,则需要转移掉哈希槽使之为空)
redis-cli -c -p 7006 cluster replicate a246963893faf03c45cc19ef4188f82f5393bfef
使用下面命令来确认一下192.168.9.203:7006是否已经成为192.168.9.203:7001的从节点
redis-cli -p 7000 cluster nodes | grep slave | grep a246963893faf03c45cc19ef4188f82f5393bfef
4.2、将这个新增节点变成主节点:
使用redis-trib程序,将集群中的某些哈希槽移动到新节点里面,这个新节点就成为真正的主节点了。执行下面的命令对集群中的哈希槽进行移动:
redis-trib.rb reshard 192.168.9.203:7000
(1)命令执行后,系统会提示我们要移动多少哈希槽>>这里可以移动1000个
(2)然后还需要指定把这些哈希槽转移到哪个节点上>>输入我们刚才新增的节点的ID
(3)然后需要我们指定转移哪几个几点的哈希槽>>输入all 表示从所有的主节点中随机转移,凑够1000个哈希槽
(4)然后再输入yes,redis集群就开始分配哈希槽了。
一个新的主节点就添加完成了,执行命令查看现在的集群中节点的状态
redis-cli -c -p 7000 cluster nodes
集群删除节点:
1、如果删除的节点是主节点,这里我们删除192.168.33.130:7006节点,这个节点有1000个哈希槽
首先要把节点中的哈希槽转移到其他节点中,执行下面的命令:
redis-trib.rb reshard 192.168.9.203:7000
(1)系统会提示我们要移动多少哈希槽,这里移动1000个,因为192.168.9.203:7006节点有1000个哈希槽。
(2)然后系统提示我们输入要接收这些哈希槽的节点的ID,这里使用192.168.9.203:7001的节点ID
(3)然后要我们选择从那些节点中转出哈希槽,这里一定要输入192.168.9.203:7006这个节点的ID
(4)最后输入done表示输入完毕。
最后一步,使用下面的命令把这个节点删除
redis-trib.rb del-node 192.168.9.203:7000 d113e0f033c98e2f6b88fb93e6e98866256d85c4 //最后一个参数为需要删除的节点ID
2、如果是从节点,直接删除即可。
redis-trib.rb del-node 192.168.9.203:7000 d113e0f033c98e2f6b88fb93e6e98866256d85c4 //最后一个参数为需要删除节点的ID
容量不足怎么办?
- 可以按照项目的业务模块来拆分,一个业务使用一个Redis或多个业务使用一个Redis
- 准备一个Hash算法,对Key进行Hash计算,这个Hash值对Redis的个数计算取余,放到对应的Redis里















 173
173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









