







前面的待总结
(压测结果与网络也有关系,例如我今天用自己的热点比连接m热点效果差很多,等明天路由器到了就能统一了)
商品查询
下面的优化措施都是层层递进的,在措施1的基础上运用措施2的优化,优上加优。
措施1:ngx服务器最初是与后端服务器短连接的,应使其为长连接,即keppalive


这是短链接下,1000个线程循环30次的压测报告:

这是长连接设置下的压测报告:

emmm从图中可以看出短连接下的平均耗时竟然比长连接下更短,可能是因为长连接下样本多了3000+的原因?但是显而易见长连接下的吞吐量大幅度优于短连接(也可能是因为样本的原因?)
或者是因为我的长连接没有设置正确??anyway,反正这是一个优化手段。
措施2:在查询过程中使用redis缓存中间件
同样的情况下,测试情况如图:

可见在样本达到19800+时,吞吐量达到了214.9/sec,显著提升。
并且样本总量稳定上升到了26939,显著增大。

措施3:在查询过程中增加本地热点缓存
使用谷歌的guava包的缓存对象,将热点数据直接存储到jvm内存中,就像hashmap一样。但是guava包里面的cache,不仅仅单纯的像hashmap,它还可以自定义一些参数,例如:

在商品查询的controller,采用了三级缓存,1首先在cache中查询,2.然后在redis中查询,3数据库查询,如图所示

emm因为之前截图没有命名保存信息,所有有些分辨不清哪张图对用那种方式的压测报告了·····anyway,记得这种优化措施就行。
措施3:使用ngx代理的缓存空间
ngx是离客户最近的地方,可以在ngx中开辟一片缓存区域,用来存放查询的数据
缓存的lua脚本:
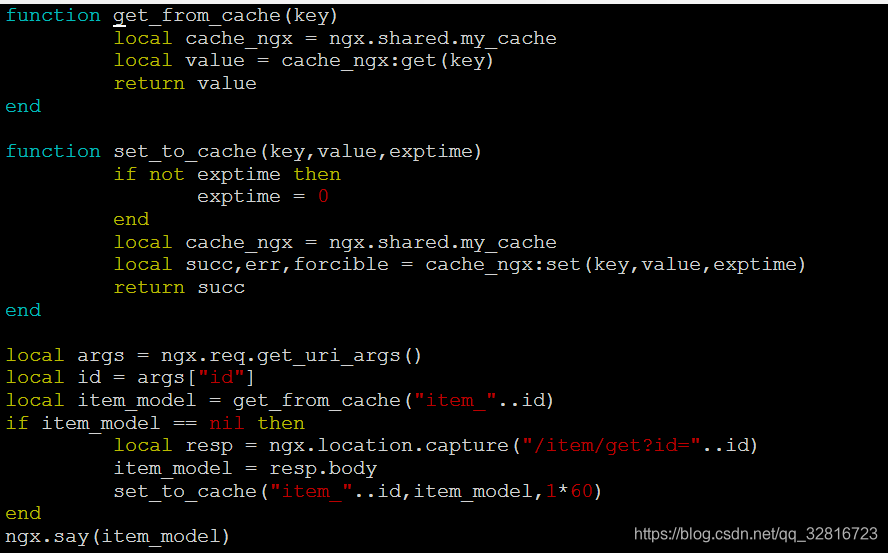
该脚本首先定义了两个函数,get_from_cache:用于从缓存空间中,根据key来获取对象的缓存对象。set_to_cache:用于向缓存中存储对象。这个脚步的功能:收到对象的查询商品命令时,首先向缓存中查询,若缓存中没有则发送请求的服务端查询数据库,然后将查询到的结果存放在缓存中。

同时在nginx.conf中定义了一块缓存空间:
![]()
压测报告如图:

可见吞吐量大幅提升

并且样本数量可以大幅增加到29555,十分接近我设置的30000个样本数量。此时的吞吐量也还算可以,平均耗时表现也还算可以。
措施3:使用ngx代理的缓存空间
可以让ngx与redis缓存连接起来,查询商品的时候先让ngx访问redis,若没有,则查询数据库,然后更新redis,此后的查询就可以直接使用redis中的数据。并且通过查询数据库的路径中,java代码的逻辑采用了三级缓存,首先会增加本地热点缓存,然后再更新redis。
对应的lua脚本:将ngx与另外一个服务器的redis连接起来

对应的nginx.conf配置访问uri路径。(上面一种优化方式,将下图中的/itemredis.lua换成/itemsharedic.lua即可)

在m热点的网络环境下压测报告如下:

似乎与上面一种方式区别不大。
能达到的最大样本数量:

此时的吞吐量比上一种优化方式对应的吞吐量要大
下单优化
在下单流程中,需要检验商品是否存在,之前是直接去数据库里查询,现在可以利用redis缓存优化。同理也需要检验用户的信息,也可以使用redis缓存。

如上图所示 是OrderServiceImpl类,里面对商品和用户信息使用添加redis中间件的检验。

然后OrderController里调用orderService的createOrder方法。不过我有个疑问,既然前面已经使用token校验了,为什么还要重复校验用户信息呢?
原版压测结果我没有截图,项目已经部署懒得回滚了,直接上优化后的压测结果

活动商品库存缓存
秒杀活动开启后,每次下单需要更新数据库的销量和库存,此处可做优化
优化措施1 使用redis缓存库存
以库存为例,我们首先编写一个接口,发布活动商品,同时把商品的库存信息缓存在redis中,后续对库存的变化直接对redis操作。
发布活动:

然后在下单减库存的流程中,直接对redis缓存进行操作:

但是这种方案并不可取,缺点如下:















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









