







数组强制类型转换的效率问题
数组向下或向上强制类型转换的方式:
void t1() {
uint8_t *pt = (uint8_t *)text32;
uint32_t *pt2 = (uint32_t *)text;
for (int i = 0;i < 4; ++i)
pt[i] = sbox[pt[i]];
}
还有一种方式是t2
void t2() {
uint8_t b[4];
uint8_t pb[4];
b[0] = (uint8_t) (*text32 >> 24);
b[1] = (uint8_t) (*text32 >> 16);
b[2] = (uint8_t) (*text32 >> 8);
b[3] = (uint8_t) *text32;
for (int i = 0;i < 4; ++i)
pb[i] = sbox[b[i]];
*text32 = (uint32_t) pb[0] << 24 | (uint32_t) pb[1] << 16 | (uint32_t) pb[2] << 8 | (uint32_t) pb[3];
}
同样的对于数组赋值顺序和移位要注意大小端的问题。
以下是两者的汇编代码。
t1():
movzx eax, BYTE PTR text32[rip+3]
movzx esi, BYTE PTR text32[rip+2]
movzx ecx, BYTE PTR text32[rip+1]
movzx edx, BYTE PTR text32[rip]
movzx eax, BYTE PTR sbox[rax]
movzx esi, BYTE PTR sbox[rsi]
movzx ecx, BYTE PTR sbox[rcx]
movzx edx, BYTE PTR sbox[rdx]
sal eax, 8
or eax, esi
sal eax, 8
or eax, ecx
sal eax, 8
or eax, edx
mov DWORD PTR text32[rip], eax
ret
t2():
mov eax, DWORD PTR text32[rip]
mov edx, eax
mov ecx, eax
movzx esi, ah
movzx eax, al
movzx eax, BYTE PTR sbox[rax]
shr ecx, 16
movsx rsi, esi
shr edx, 24
movzx esi, BYTE PTR sbox[rsi]
movzx ecx, cl
movzx edx, BYTE PTR sbox[rdx]
sal eax, 8
movzx ecx, BYTE PTR sbox[rcx]
or eax, esi
sal eax, 8
or eax, ecx
sal eax, 8
or eax, edx
bswap eax
mov DWORD PTR text32[rip], eax
ret

根据此图可以看到两个函数的效率对比。t1是高于t2的。
根据汇编还可以写第三种方法。
void t3() {
uint8_t *pt = (uint8_t *)text32;
*text32 = (sbox[pt[0]] << 24) | (sbox[pt[1]] << 16) |( sbox[pt[2]] << 8 )| sbox[pt[3]];
}
效率对比如下
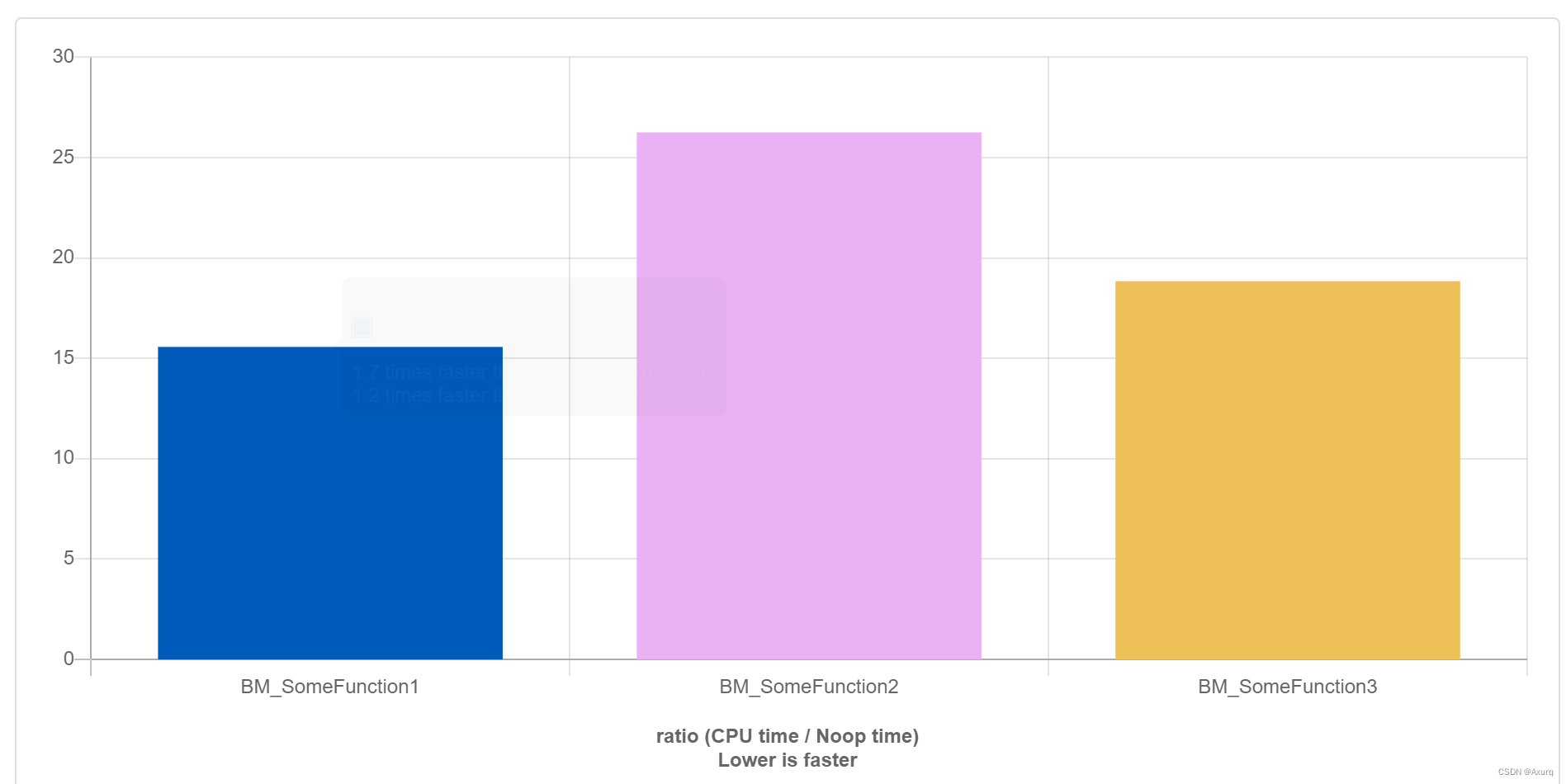
可以发现第三种方法效率高于第二种但依然低于第一种。
因为编译器对t1访存进行了集中优化。
t3汇编如下:
t3():
movzx eax, BYTE PTR text32[rip]
movzx edx, BYTE PTR text32[rip+1]
movzx eax, BYTE PTR sbox[rax]
movzx edx, BYTE PTR sbox[rdx]
sal eax, 24
sal edx, 16
or eax, edx
movzx edx, BYTE PTR text32[rip+3]
movzx edx, BYTE PTR sbox[rdx]
or eax, edx
movzx edx, BYTE PTR text32[rip+2]
movzx edx, BYTE PTR sbox[rdx]
sal edx, 8
or eax, edx
mov DWORD PTR text32[rip], eax
ret















 2519
2519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









