







-
安装过程不复杂,主要是由于没有接触过Hadoop,一下子进入Spark,有点不知所措,所以建议如果没有Hadoop经验,又想先搞Spark的同学,可以找一些视频入入门,先从一个总体的流程感知下Spark。
-
官网下载地址:
http://spark.apache.org/downloads.html
简单介绍一下:
自己测试的话其实随便哪个版本就行,但是如果当前环境已有hadoop的版本的话,需要谨慎选择,具体看官网的解释,注意下版本就行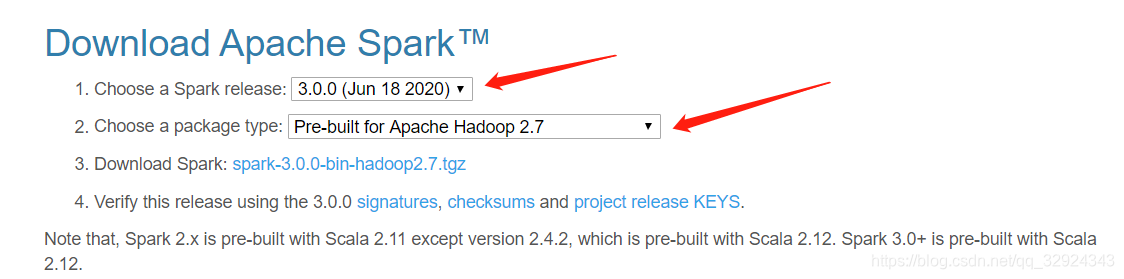
-
如果没有配置Java环境,请先配置Java的环境。
-
节点准备:192.168.2.142(master)192.168.2.143(worker)192.168.2.144(worker)。注意SSH必须先配置好,不然节点间通信要输入密码。
-
spark-env.sh.template 改成 spark-env.sh,配置如下参数:
export JAVA_HOME=/usr/local/jdk1.8.0_201
export SPARK_MASTER_HOST=192.168.2.142
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8084
export SPARK_SSH_OPTS="-p 61122"
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=3g
参数解释:
SPARK_MASTER_WEBUI_PORT 是spark的web界面的展示,能看见任务执行的情况
SPARK_SSH_OPTS 是开放的端口,可能机器上不是使用的默认端口22,要配置一下,根据各自机器的情况配置 -
slaves.template 改成slaves,配置如下参数:
192.168.2.143
192.168.2.144 -
将配置拷贝到其他两台机器上去。
这里的配置和Hadoop没有任何关系,本人测试时机器上没有安装任何Hadoop的东西。Spark也是可以脱离Hadoop独立部署的。配置好之后就能启动了。
启动方式有两种
9. /sbin/start-all.sh 停止 /sbin/stop.sh
10. 先单独启动master /sbin/start-master.sh 然后启动 slaves /sbin/start-slaves.sh
11. 访问web页面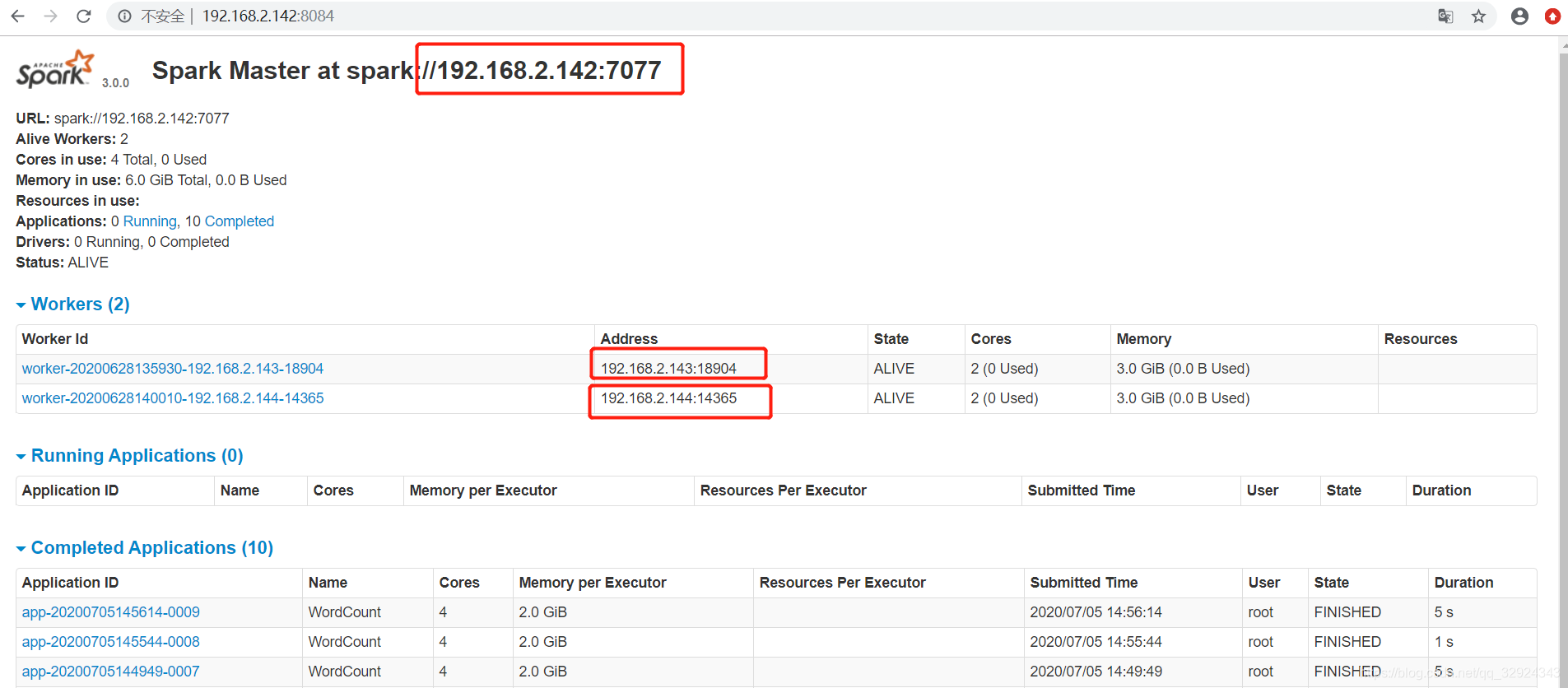
12.启动之后看下环境是不是启动成功了。可以执行examples下的例子
./bin/spark-submit --master spark://192.168.2.142:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.12-3.0.0.jar 10
简单介绍:
–master spark://192.168.2.142:7077 设置 master地址
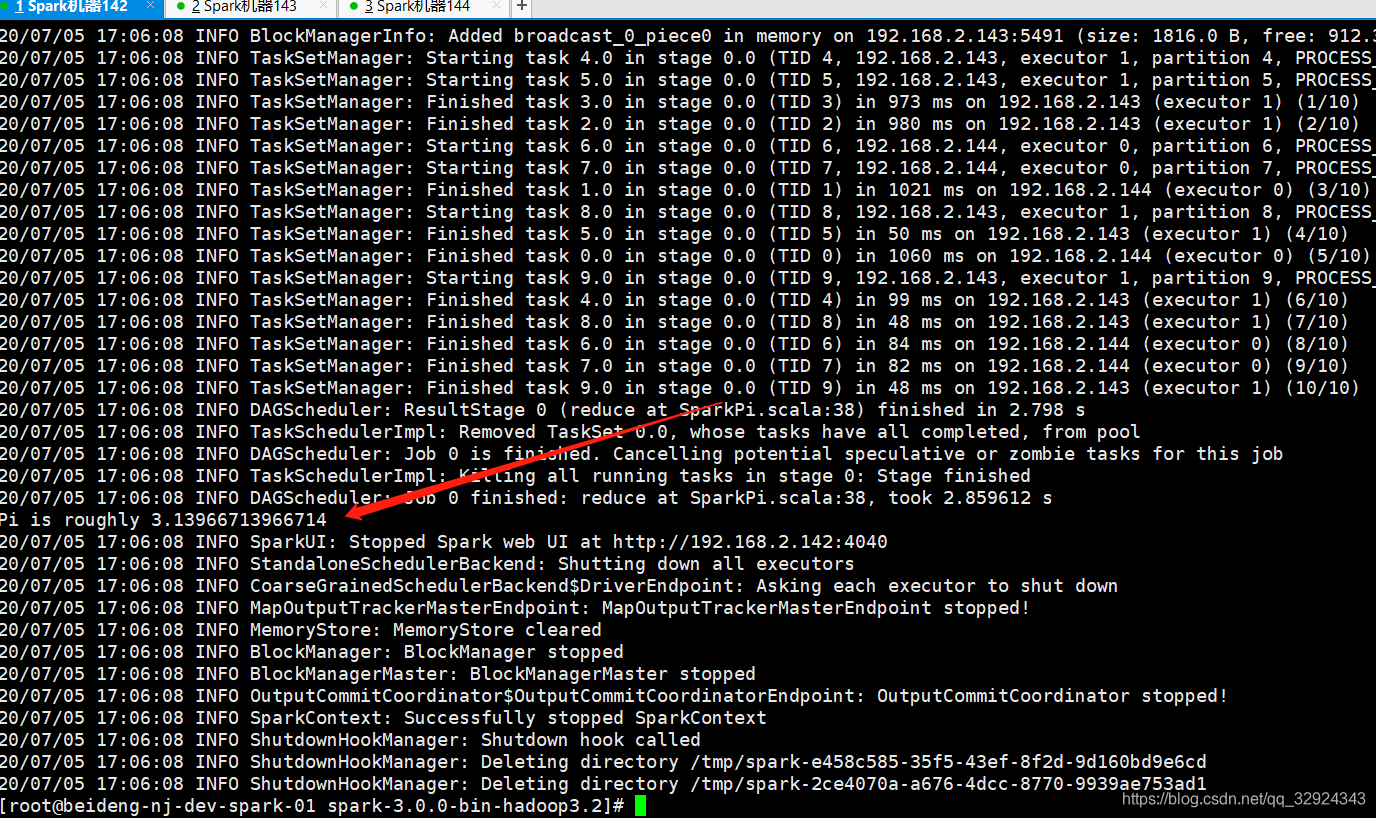
运行成功,(10是main函数的参数)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









