









迭代器模式的实例
假设,我们项目组接到一个需求,对电视机的电视频道、电影菜单进行统一管理,建立一个统一的菜单管理界面,能够看到所有的电视界面、电影界面。沈妍和杨强现在要做这件事情。分别就每个模块做开发工作,看他们都做了哪些工作。
public class MenuItem {
//编号
private Integer number;
//名称
private String name;
//描述
private String description;
}沈妍负责电视频道菜单的实现。她是基于数组实现的,她认为这样就可以非常方便的遍历菜单。
public class ShenYanArrayList<E> {
Object[] objects = new Object[10];
int index = 0;
public void add(E o) {
if (index == objects.length) {
Object[] newObjects = new Object[objects.length * 2];
System.arraycopy(objects, 0, newObjects, 0, objects.length);
objects = newObjects;
}
objects[index] = o;
index++;
}
public int size() {
return index;
}
}但是杨强不服,他就是不喜欢数组存储的结构,他喜欢玩链表,他认为这样就可以非常方便的扩展菜单
public class Node {
private Object data;
private Node next;
public Node(Object data, Node next) {
super();
this.data = data;
this.next = next;
}
}
public class YQLinkedList<E> {
Node head = null; //头指针
Node tail = null; //尾指针
int size = 0;
public void add(E o) {
Node n = new Node(o, null);
if (head == null) {
head = n;
tail = n;
}
tail.setNext(n);
tail = n;
size++;
}
public int size() {
return size;
}
}他们完成了各自菜单功能的实现。目前存在的问题:
考虑容器的可替换性,他们没有统一规范基础的方法,如:add、size等
解决:
public interface Collection<E> { void add(E o); int size(); }不同容器的遍历问题
当我在做三个菜单的统一显示时,由于实现的数据结构不同,我必须分别遍历,来取得他们各个菜单里面的值。显然每一种容器的遍历方式都是不同的,针对数组,我可以通过下标;针对链表我可以通过next指针域;针对二叉树,我可以去实现前序遍历(或者其他)………然而实际上数据结构可能会有很多种,我需要针对每一种结构都写一次新的遍历方法吗?显然这是一种弱智的行为。
是不是可以来封装循环呢?不错就是封装遍历。这就是迭代器模式的动机— 能够游走于聚合内的每一个元素,同时还可以提供多种不同的遍历方式。
要求每一个容器都去实现一个接口,iterator,具体的实现我交给了具体的容器,我只关心你是否提供了我想要的遍历方法。
public interface Collection<E> { void add(E o); int size(); Iterator iterator(); } public interface Iterator { Object next(); boolean hasNext(); }
于是针对接口这样的变动,沈妍的arrayList也赋予了新的生命:
public class ShenYanArrayList<E> implements Collection<E> {
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
Object[] objects = new Object[DEFAULT_CAPACITY];
int index = 0;
@Override
public void add(E o) {
if (index == objects.length) {
// ensureCapacityInternal(size + 1); // Increments modCount!! (jdk中的自增算法)
Object[] newObjects = new Object[objects.length * 2];
System.arraycopy(objects, 0, newObjects, 0, objects.length);
objects = newObjects;
}
objects[index] = o;
index++;
}
@Override
public int size() {
return index;
}
@Override
public Iterator iterator() {
return new ShenYanArrayListIterator();
}
private class ShenYanArrayListIterator implements Iterator {
private int currentIndex = 0;
@Override
public boolean hasNext() {
if (currentIndex >= index) return false;
else return true;
}
@Override
public Object next() {
Object o = objects[currentIndex];
currentIndex++;
return o;
}
}
}
于是现在,不论是对于哪种容器的遍历,我都有了统一的方法
//面向接口编程,不需要考虑具体的实现
Collection<MenuItem> menuItemList = new ShenYanArrayList<MenuItem>();
Iterator it = menuItemList.iterator();
while (it.hasNext()) {
Object menuItem = it.next();
System.out.print(menuItem + " ");
}问题:
为什么不把hasNext()和next()方法都放在collection接口里,抽出个iterator的意图是什么
基于迪米特法则(最少知道原则),对于collection,我只需要知道里面有遍历容器的方法叫做iterator,但是具体我是如何遍历容器(hasNext和next方法),这不是collection需要知道的,这是iterator应该了解的事情,所以我们在设计接口的时候,应当设计的越细越好,分工越明确越好。
概念小结
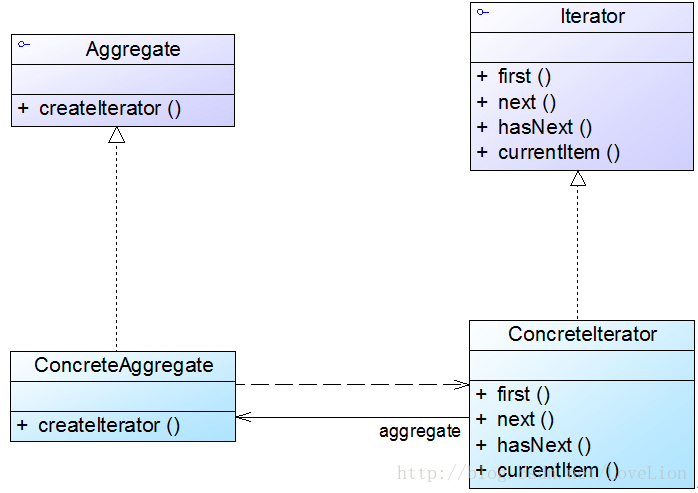
在迭代器模式结构图中包含如下几个角色:
● Iterator(抽象迭代器):它定义了访问和遍历元素的接口,声明了用于遍历数据元素的方法,例如:用于获取第一个元素的first()方法,用于访问下一个元素的next()方法,用于判断是否还有下一个元素的hasNext()方法,用于获取当前元素的currentItem()方法等,在具体迭代器中将实现这些方法。eg:
interface Iterator {
public void first(); //将游标指向第一个元素
public void next(); //将游标指向下一个元素
public boolean hasNext(); //判断是否存在下一个元素
public Object currentItem(); //获取游标指向的当前元素
}● ConcreteIterator(具体迭代器):它实现了抽象迭代器接口,完成对聚合对象的遍历,同时在具体迭代器中通过游标来记录在聚合对象中所处的当前位置,在具体实现时,游标通常是一个表示位置的非负整数。eg:
class ConcreteIterator implements Iterator {
private ConcreteAggregate objects; //维持一个对具体聚合对象的引用,以便于访问存储在聚合对象中的数据
private int cursor; //定义一个游标,用于记录当前访问位置
public ConcreteIterator(ConcreteAggregate objects) {
this.objects=objects;
}
public void first() { ...... }
public void next() { ...... }
public boolean hasNext() { ...... }
public Object currentItem() { ...... }
}● Aggregate(抽象聚合类):它用于存储和管理元素对象,声明一个createIterator()方法用于创建一个迭代器对象,充当抽象迭代器工厂角色。eg:
interface Aggregate {
Iterator createIterator();
}● ConcreteAggregate(具体聚合类):它实现了在抽象聚合类中声明的createIterator()方法,该方法返回一个与该具体聚合类对应的具体迭代器ConcreteIterator实例。eg:
class ConcreteAggregate implements Aggregate {
......
public Iterator createIterator() {
return new ConcreteIterator(this);
}
......
}在迭代器模式中,提供了一个外部的迭代器来对聚合对象进行访问和遍历,迭代器定义了一个访问该聚合元素的接口,并且可以跟踪当前遍历的元素,了解哪些元素已经遍历过而哪些没有。迭代器的引入,将使得对一个复杂聚合对象的操作变得简单。
迭代器模式的优缺点
迭代器模式是一种使用频率非常高的设计模式,通过引入迭代器可以将数据的遍历功能从聚合对象中分离出来,聚合对象只负责存储数据,而遍历数据由迭代器来完成。由于很多编程语言的类库都已经实现了迭代器模式,因此在实际开发中,我们只需要直接使用Java、C#等语言已定义好的迭代器即可,迭代器已经成为我们操作聚合对象的基本工具之一。
主要优点
迭代器模式的主要优点如下:
(1) 它支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法,我们也可以自己定义迭代器的子类以支持新的遍历方式。
(2) 迭代器简化了聚合类。由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
(3) 在迭代器模式中,由于引入了抽象层,增加新的聚合类和迭代器类都很方便,无须修改原有代码,满足“开闭原则”的要求。
主要缺点
迭代器模式的主要缺点如下:
(1) 由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
(2) 抽象迭代器的设计难度较大,需要充分考虑到系统将来的扩展,例如JDK内置迭代器Iterator就无法实现逆向遍历,如果需要实现逆向遍历,只能通过其子类ListIterator等来实现,而ListIterator迭代器无法用于操作Set类型的聚合对象。在自定义迭代器时,创建一个考虑全面的抽象迭代器并不是件很容易的事情。
适用场景
在以下情况下可以考虑使用迭代器模式:
(1) 访问一个聚合对象的内容而无须暴露它的内部表示。将聚合对象的访问与内部数据的存储分离,使得访问聚合对象时无须了解其内部实现细节。
(2) 需要为一个聚合对象提供多种遍历方式。
(3) 为遍历不同的聚合结构提供一个统一的接口,在该接口的实现类中为不同的聚合结构提供不同的遍历方式,而客户端可以一致性地操作该接口。
迭代器设计模式的应用(待删)
基于最近写的代码,以及对迭代器设计模式的思考,发现其实在项目开发过程中,很多地方都,只要涉及容器的运用与数据结构的存储都是可以引入迭代器的思想。
在先前开发超级搜索,表达式计算功能
/**
* 将原本jsonArray["date","value"]的格式转换为Map<date,value>的格式
* 返回Map<keyWord,Map<date,value>>
*
* @param originalDataMap
* @return
*/
private Map<String, Map<String, String>> parseJSONArray2Map(Map<String, JSONObject> originalDataMap) {
Map<String, Map<String, String>> resultMap = new HashMap<String, Map<String, String>>();
for (String keyWord : originalDataMap.keySet()) {
JSONArray jsonData = getDataList(originalDataMap.get(keyWord));
Map<String, String> cellMap = new HashMap<String, String>();
for (int i = 0; i < jsonData.size(); i++) {
JSONArray cellArray = (JSONArray) jsonData.get(i);
cellMap.put(cellArray.getString(0), cellArray.getString(1));
resultMap.put(keyWord, cellMap);
}
}
return resultMap;
}无非就是一个Map
private Map<String, Double> calculate(Map<String, Map<String, String>> mapData, List<String> keyWords, String expression) throws Exception {
Map<String, Double> calculateResult = new TreeMap<String, Double>();
//取数据的时间并集,获取时间序列(然后在获取时间序列的时候,我已经对其做了一次遍历)
TreeSet<String> timeSection = getTimeSeries(mapData);
for (String timeStamp : timeSection) {
List<Double> paramList = new ArrayList<Double>();
//然而在我生成paramList的时候,我又再次对其做了一次遍历
for (String key : keyWords) {
String value = mapData.get(key).get(timeStamp);
paramList.add(value == null ? null : Double.parseDouble(value));
}
Double result = ExpressionTreeUtil.getExpressionResult(expression, paramList);
calculateResult.put(timeStamp, result);
}
return caculateResult;
}这仅仅是一个两层的map,那如果是N层的呢?
//封装先前的数据结构
public class CalculateData implements Collection{
private Integer size = 0;
private Map<String, Map<String, String>> data;
public CalculateData(Map<String, JSONObject> originalDataMap){
this.data = parseJSONArray2Map(originalDataMap);
}
private JSONArray getDataList(JSONObject resultReponse) {
JSONObject dataObject = (JSONObject) resultReponse.get("result");
JSONArray dataList = (JSONArray) dataObject.get("data");
return dataList;
}
@Override
public void add(Object element) {
...
}
@Override
public int size() {
return size;
}
@Override
public Iterator iterator() {
return new CalculateDataIterator();
}
private class CalculateDataIterator implements Iterator{
@Override
public Object next() {
...
}
@Override
public boolean hasNext() {
...
}
}
}
//于是遍历变成
for (String timeStamp : timeSection) {
List<Double> paramList = new ArrayList<Double>();
Iterator it = mapData.iterator();
while(it.hasNext()){
String value = it.next().getValue(timeStamp);
//只要有一个值为null,则认为这个时间点,无法计算结果,返回null
paramList.add(value == null ? null : Double.parseDouble(value));
}
// 将参数集合转换为数组 考虑到toArray泛型转换会出现问题 所以手动转换为数组
Double result = ExpressionTreeUtil.getExpressionResult(expression, paramList);
calculateResult.put(timeStamp, result);
}虽然从代码量上看,并没有减少几行,但是规范了对calculateData的遍历方式与JDK统一了调用,对于长期的维护而言,后来者不用再去关心calculateData底层究竟是封装了什么数据结构,提高了代码的可读性,同时基于iterator接口,可以实现不同复杂的遍历以满足不同业务场景的需求。















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









