







假设有一张demo表,主键为id,唯一索引是code
create table demo
(
id int auto_increment,
name int null,
gender int null,
age int null,
code int null,
constraint demo_pk
primary key (id)
);
create unique index demo_code_uindex
on demo (code);
方法一 replace into
replace into 会根据唯一索引或主键进行判断,如果存在则覆盖写入字段,如果不存在则新增。
此方法有坑,如果主键是自增的,且通过唯一索引来进行操作时,主键会变更,该方法底层是先进性delete,在insert
如果有子表依赖的话不建议使用。
replace into 事例
REPLACE INTO demo(id, name, gender, age, code) VALUES (1,'1',1,1,1)
通过主键修改,此时没有任何问题,id还是1

当我们通过唯一索引code来更改。
REPLACE INTO demo(name, gender, age, code) VALUES ('1',1,1,1)
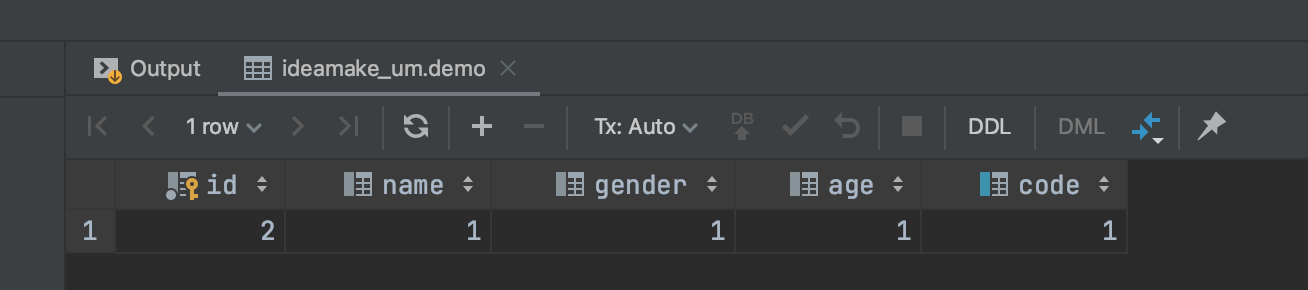
没执行一次 主键id都会自增。
方法二 on duplicate key
on duplicate key 如果遇到重复的唯一索引则会进行update,否则进行新增,没有replcae的坑,不会先进行delete 在进行 insert
on duplicate key 事例:
INSERT INTO demo(name, gender, age, code)
VALUES ('1',
1,
2,
2)
ON DUPLICATE KEY UPDATE name = values(name),
gender = values(gender),
age = values(age),
code = if(values(code) = 1,values(code), code)

无论执行多少次,主键值都是不会变的。
但是此方法也有坑,如果表中不止一个唯一索引的话,在特定版本的mysql中容易产生dead lock(死锁)
当mysql执行INSERT ON DUPLICATE KEY的 INSERT时,存储引擎会检查插入的行是否会产生重复键错误。如果是的话,它会将现有的
行返回给mysql,mysql会更新它并将其发送回存储引擎。当表具有多个唯一或主键时,此语句对存储引擎检查密钥的顺序非常敏感。根据这个顺序,
存储引擎可以确定不同的行数据给到mysql,因此mysql可以更新不同的行。存储引擎检查key的顺序不是确定性的。例如,InnoDB按照索引添加到
表的顺序检查键。
insert … on duplicate key 在执行时,innodb引擎会先判断插入的行是否产生重复key错误,如果存在,在对该现有的行加上S(共享锁)锁,如果返回该行数据给mysql,然后mysql执行完duplicate后的update操作,然后对该记录加上X(排他锁),最后进行update写入。
如果有两个事务并发的执行同样的语句,那么就会产生death lock















 2863
2863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









