






特点:
1、均匀性,离散性
2、每个输入对应唯一输出
3、每个输出对应的输入不唯一,即不同输入可能对应同一输出。
例子:
问题:Random pool .
插入,删除,随机取数 操作,均未O(1)
实现方法,建立两个相反的哈希表,即倒排索引的概念,删除时,用最后一项替换删除项,以保持哈希值的连续性。
位图
位图通过其他的数据类型实现,通过其他数组来拼成,对于仅需要两种状态的数组,可以极大的省空间。
如:
int[] arr =new int[10]; // 32bit * 10 =320 bits
int i =178;
//确定第几个int,以及int 的第几位
int numIndex=i/32;
int bitIndex=i%32;
//把对应bit上的状态0或1,变成了数值0和数值1,即取得了178位的状态。即将对应位移到第一位后与1相与。
int s=((arr(numIndex)>>(bitIndex))&1);
//将178位状态改为1,即将对应位于1相或
arr(numIndex)=arr(numIndex) |(1<<(bitIndex)) ;
布隆过滤器
大数据,大样本集,对一个集合中的项目做查询。正常方法,建立哈希表,对于内存空间的需求量很大。
布隆过滤器存在失误率。仅存在一种失误,宁可错杀三千,不可放过一个,绝不会放过一个坏人,但是可能冤枉好人,但是黑名单中的绝对不会通过。
实现:
一个样本用k个哈希函数,对应到k个位置。作为黑名单,对于任意一出现过的样本,其对应的K个位置必然全是占用的,若有一个未占用,则说明是新样本。布隆过滤器仅有添加操作,额米有删除操作。
哈希表长度M,哈希函数数目K.参数确定决定性能。
图片: https://uploader.shimo.im/f/eg4BoTmv5E4qmfEI.png

理论长度m(向上取整).对应实际空间占用m/8,实际值m’大于m.
图片: https://uploader.shimo.im/f/rQdQv7PI8LUJZdQr.png
k向上取整,m使用理 论值,得到实际k’。
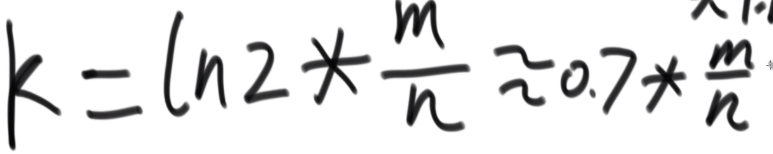
真实失误率:
图片: https://uploader.shimo.im/f/QMp7RzBaJyYStrTD.png
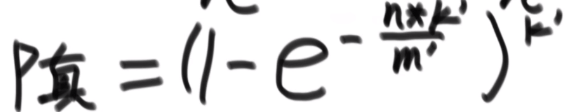
一致性哈希















 3722
3722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}