






一、Spark是什么
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Spark是基于Scala语言开发的。
整个Spark框架模块包含:Spark Core、Spark SQL、Spark Streaming、Spark GraphX、Spark MLlib,后四项是建立在核心引擎上的。
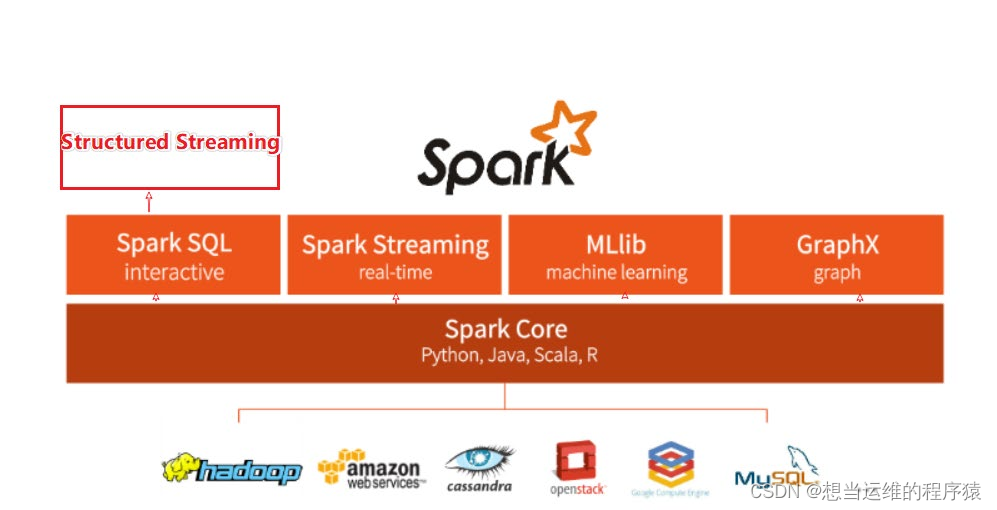
Spark Core是Spark的核心,是Spark运行的基础。
Spark SQL: 以SQL语言对数据进行处理,针对离线计算场景。基于Spark SQL,Spark提供了StructuredStreaming模块,可以进行流式计算。
Spark Steaming: 提供数据的流式计算功能(微批)
MLlib: 机器学习计算的库、api。
GraphX: 图计算的api。
二、Spark架构
2.1 Spark基础架构
Spark架构中共4种角色:Master、Worker、Driver、Executor
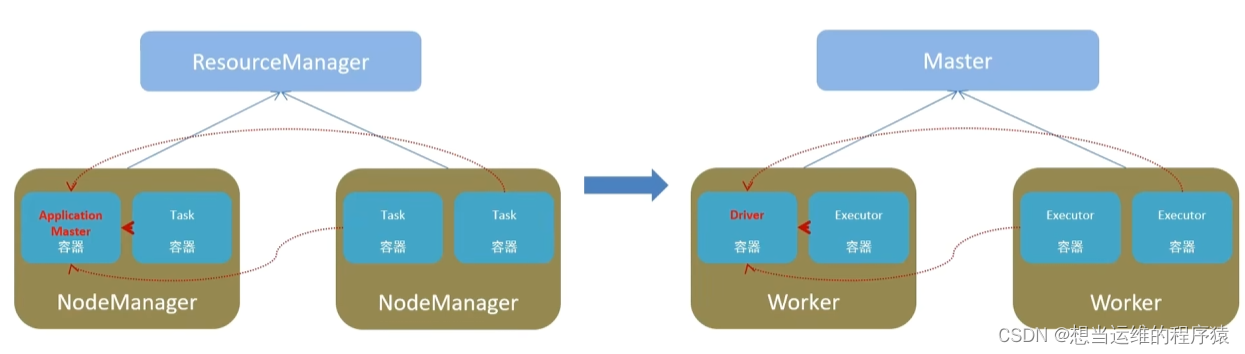
Master: 管理整个集群的资源,类比Yarn的ResourceManager
Worker: 管理单个服务器的资源,类比Yarn的NodeManager
Driver: 管理单个Spark程序的运行,类比Yarn的ApplicationMaster(比如mr的MRAppMaster)
Executor: 单个任务运行时的工作者,类比yarn中container中的task(比如MR的MapTask、ReduceTask)
2.2 Spark On Yarn
一般会将Spark运行到Yarn集群上,而不会再搭建Spark集群。(可以提高资源利用率并方便管理)
Spark中的Master由Yarn的ResourceManage担任
Spark中的Worker由Yarn的NodeManager担任
Driver运行在Yarn的Container容器内 或 提交任务的客户端进程中。
Excutor运行在Yarn的Container容器内
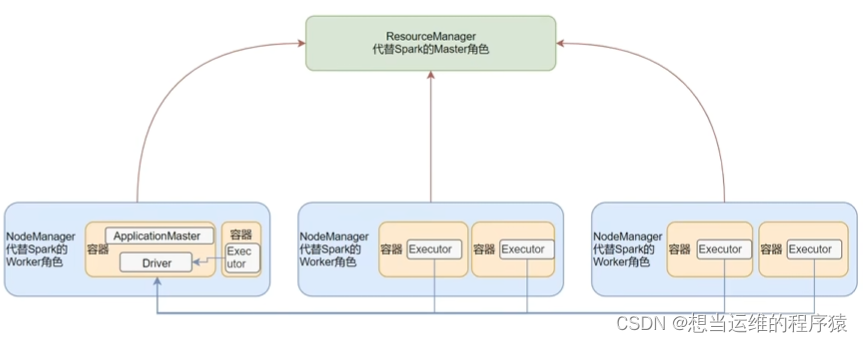
Spark On Yarn有两种运行模式,一种是Cluster模式,一种是Client模式。
Cluster模式: Driver运行在Yarn容器内部,和ApplicationMaster在同一个容器内。
Client模式: Driver运行在客户端进程中。
三、Spark程序的开发
Spark支持以Python、Java、Scala、R语言开发spark程序。
Spark RDD编程的程序入口对象是SparkContext对象(不论何种编程语言)
RDD(Resilient Distributed Dataset)指的是弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、其中元素可并行计算的集合。(Spark中抽象出来的数据集合)
- 弹性:RDD中的数据可以存储在内存或磁盘中。
- 分布式:RDD中的数据是分布式存储的,可用于分布式计算。
- 数据集:一个数据集合,用于存放数据的。
3.1 编程
以python开发Spark程序为例:
(1)导入pyspark包,import pyspark]
(2)创建SparkConf对象
(3)基于SparkConf对象,创建SparkContext对象
(4)用SparkContext对象的各种方法来开发具体处理逻辑
开发完成后使用spark-submit xxxx.py将程序提交到yarn上执行。
在Spark中,非任务处理部分由Driver执行(Driver只有一个,是单机执行)(非RDD代码)
任务处理部分由Executor执行(Executor很多,所以是分布式执行)(RDD代码)
Python On Spark执行原理:
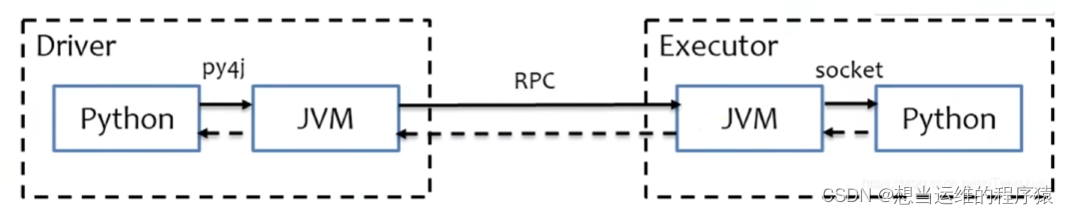
使用Java和Scala编写Spark程序,则Driver和Executor都直接运行在JVM上即可。
使用Python编写Spark程序,在Driver端需要通过py4j将Python代码翻译成Java代码,运行在JVM上,在Executor上JVM只做命令转发,实际由python解释器工作。
3.2 RDD的创建
通过sparkcontext对象创建RDD
可以将本地对象转成RDD 或 读取文件形成RDD
| 方法 | 参数 | 说明 |
|---|---|---|
| sparkcontext.parallelize(参数1, 参数2) | 参数1: 集合对象,比如list 参数2: 分区数 | 将本地集合 - > 分布式RDD,并指定分区数 |
| sparkcontext.textFile(参数1, 参数2) | 参数1: 文件路径 参数2: 分区数 | 读取本地数据/HDFS数据,参数1如传入文件夹则会读取文件夹下所有文件 |
| sparkcontext.wholeTextFile(参数1, 参数2) | 参数1: 文件路径 参数2: 分区数 | 与textFile用法相同,小文件读取专用 |
3.3 RDD算子
本地对象的API,叫做方法/函数。分布式对象的API,叫做算子。
RDD的算子分成2类:转换(Transformation)算子,动作(Action)算子。
转换算子: RDD的算子,返回仍为RDD,则称为转换算子
(转换算子是懒加载的,相当于是构建执行计划(准确讲是DAG),直到有动作算子,才会真正执行之前的所有转换算子)
动作算子: 返回值不是RDD,则称为动作算子
(1)RDD常用Transformation算子
Transformation算子返回值都是新的RDD
| 算子 | 说明 |
|---|---|
| rdd.map(func) | 将RDD的数据 一条条通过func函数处理,返回新的RDD |
| rdd.flatMap(func) | 将RDD的数据 一条条通过func函数处理,然后将其中集合展开(类似python中的*list展开数组) |
| rdd.reduceByKey(func) | 针对KV型RDD,按照key分组,通过func函数进行聚合func函数应有两个参数,一个返回值 |
| rdd.mapValues(func) | 针对二元元组RDD,对其内部的Value执行map操作(各Value经过func函数处理) |
| rdd.groupBy(func) | 将RDD的数据按照func函数的输出进行分组 |
| rdd.filter(func) | func函数返回是True的数据将保留 |
| rdd.distinct(参数1) | 对RDD中的数据进行去重,参数1表示按照几个分区去重,一般不用 |
| rdd.union(other_rdd) | 将2个RDD数据进行合并,数据类型可以不同 |
| rdd.join(other_rdd) leftOuterJoin() rightOuterJoin() | 针对二元元组RDD,按照二元元组的key进行关联join内连,leftOuterJoin左外连,rightOuterJoin右外连 |
| rdd.intersection(other_rdd) | 计算两个RDD的交集 |
| rdd.glom() | 无参数,将RDD数据加上嵌套,嵌套按照分区进行,一般用来查看分区的分布 |
| rdd.groupByKey() | 无参数,针对KV型RDD,按照Key进行分组 |
| rdd.sortBy(func, ascending, numPartitions) | 对RDD数据进行排序 func指定根据RDD中哪个元素排序,ascending用True指定升序,numPartitions指定在几个分区内排序(1则为全局排序) |
| rdd.sortByKey(ascending, numPartitions, keyfunc) | 针对KV型RDD,按照Key进行排序ascending和numPartitions用法与sortBy相同,keyfunc作用在key上,排序前对key进行处理 |
(2)RDD常用Action算子
| 算子 | 说明 |
|---|---|
| rdd.countByKey() | 一般用于KV型RDD,统计每个key出现的次数 |
| rdd.collect() | 将RDD各个分区的数据,统一收集到Driver中,形成一个List对象 |
| rdd.reduce(func) | RDD数据按照func函数进行聚合。func函数应有两个参数,一个返回值 |
| rdd.fold(value, func) | RDD数据按照func函数进行聚合 并加上初始值(每个分区内聚合都会加上初始值)。func函数应有两个参数,一个返回值 |
| rdd.first() | 取出RDD的第一个元素 |
| rdd.take(n) | 取出RDD的前n个元素 |
| rdd.top(n) | RDD降序排序,取RDD前n个元素 |
| rdd.count() | 计算RDD的元素个数 |
| rdd.takeSample(参数1,参数2,参数3) | 随机抽样RDD中的数据。参数1:是否允许取同一个数,参数2:抽样数量,参数3:随机数种子 |
| rdd.takeOrdered(n,func) | RDD按照func函数的返回值进行排序(不改变数据本身),取RDD前n个元素 |
| rdd.foreach(func) | 将RDD的数据 一条条通过func函数处理(与map算子相同),但这个没有返回值 |
| rdd.saveAsTextFile(路径) | 将RDD的数据写入 本地/HDFS 的文本文件中,RDD有几个分区就有几个文件 |
foreach和saveAsTextFile是由分区(Executor)直接执行的,不用发送到Driver中
其他的Action算子都会将结果发送到Driver
reduceByKey与groupByKey的区别:
(1)reduceByKey是分组并聚合,groupByKey只分组不聚合
(2)reduceByKey实现聚合效率更高,因为在Executor端进行了预聚合,而groupByKey+聚合逻辑是在Driver端完成的聚合操作
(3)RDD常用分区操作算子
| 算子 | 说明 |
|---|---|
| rdd.mapPartitions(func) | 与map算子类似,是个Transformation算子,也返回RDD,区别是一次处理一个分区的数据。func函数有一个参数,一个返回值,参数表示一个可迭代对象(分区) |
| rdd.foreachPartitions(func) | 与foreach算子类似,是个Action算子,无返回值,区别是一次处理一个分区的数据 |
| rdd.partitionBy(n,func) | 对RDD进行自定义分区。 n指定分区后的个数,func自定义分区规则,返回值为int表示分区号 |
| rdd.repartition(n) | 对RDD重新分区,分为n个分区 |
| rdd.coalesce(n, shuffle) | 对RDD重新分区,分为n个分区 与repartition作用一样,区别仅在于增加分区时需手动指定shuffle=True才能生效 |
四、RDD的cache、CheckPoint
RDD之间通过Transformation算子进行相互迭代计算,新的RDD生成,则老的RDD消失。
即RDD的数据是过程数据,旧的RDD处理完成后从内存中清理,给后续的计算腾出内存空间。
由于上述特性,RDD被2次调用时,RDD就不存在了,只能基于该RDD的血缘关系,重新构建。
当一个RDD需要被运行多次Transformation算子时,为了防止重新计算该RDD,可以将RDD的数据保存起来。具体方式有两种,缓存和CheckPoint
4.1 RDD的缓存
缓存是分散存储在各个Executor对应服务器的内存/硬盘中的,若某一个服务器上的缓存丢失,则整个RDD需要被重新计算,因此缓存是保留RDD的血缘关系的。
# 缓存到内存中
rdd3.cache()
# 仅内存缓存,等价于cache()
rdd3.persist(StorageLevel.MEMORY_ONLY)
# 仅缓存磁盘上
rdd3.persist(StorageLevel.DISK_ONLY)
# 先放内存,不够再放硬盘
rdd3.persist(StorageLevel.MEMORY_AND_DISK)
# 清理缓存
rdd3.unpersist()
4.2 RDD的CheckPoint
CheckPoint只能保存到硬盘中,一般集中存储到HDFS上,不保留血缘关系。
# 设置数据的保存路径
sc.setCheckpointDir("hdfs://node1:8020/output/bj52ckp")
# 直接调用checkpoint算子进行保存数据
rdd.checkpoint()
| RDD数据保存方式 | 特点 |
|---|---|
| 缓存Cache | 支持内存/磁盘存储,分散存储,保留RDD的血缘关系 |
| CheckPoint | 仅支持磁盘存储,集中存储,不保留RDD的血缘关系 |
五、RDD的广播变量、累加器
5.1 广播变量
一个Executor中可以处理多个RDD分区,当分区处理逻辑中使用本地集合时,需要通过Driver传输获取本地集合的数据,那么会导致一个Executor中多次接收本地集合。
将本地集合包装成广播变量,则Driver给每个Executor发送本地集合数据时只会发送一份,可以降低内存占用并减少网络IO传输。
# 将本地list1 包装成广播变量
broadcast = sc.broadcast(list1)
# 使用list1时,通过value获取
value = broadcast.value
5.2 累加器
累加器用于解决分布式代码执行中,全局累加的问题。
分布式代码执行时,各变量在各个服务器中执行,相互不通,无法实现全局累加。
spark中提供了累加器,专门解决这类问题。
# 创建累加器变量,并赋初始值,后续在算子中直接使用该变量即可
acmlt = sc.accumulator(0)
六、Spark内核调度(面试重点!!)
Application->Job->Stage->Task 每一层都是1对n的关系
- Application:初始化一个SparkContext即生成一个Application;(可以理解为一个Spark程序)
- Job:一个Action算子即对应一个Job,对应一个DAG;
- Stage:Stage等于宽依赖的个数加1;
- Task:每个Stage阶段中最后一个RDD的分区数就是该Stage对应的Task个数;
6.1 DAG
DAG(Directed acyclic graph)称为有向无环图,用于表示Spark程序的逻辑执行流程。
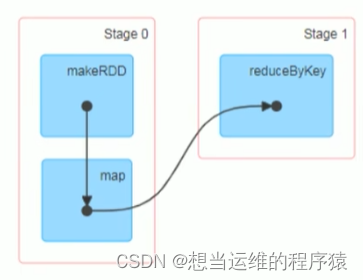
一个Action算子就对应一个DAG,一个DAG在程序运行时就对应一个Job。
1个Action = 1个DAG = 1个JOB
6.2 DAG的宽窄依赖、阶段划分、内存迭代计算
RDD之间的关系有两种:窄依赖、宽依赖
窄依赖:父RDD的一个分区,将数据全部给子RDD的一个分区(一个分区传到一个分区)
宽依赖:父RDD的一个分区,将数据全部给子RDD的多个分区(一个分区传到多个分区)
宽依赖也叫做shuffle
每个DAG根据宽窄依赖划分阶段,从后往前,遇到宽依赖就划分出一个Stage,每个Stage内都是窄依赖。
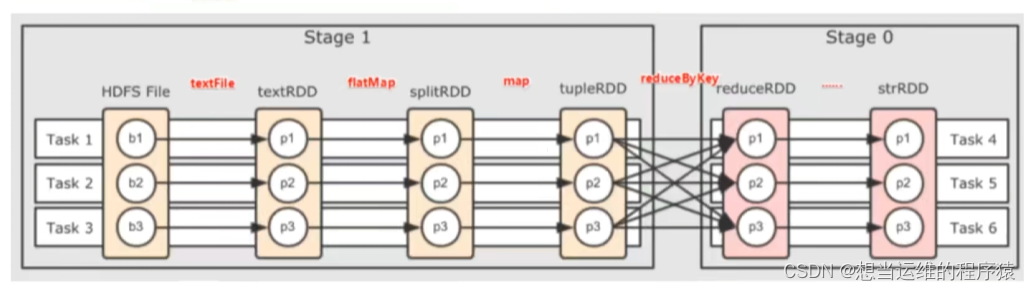
如上图,一个阶段的内部都是窄依赖,窄依赖内前后1:1的分区关系,产生许多内存迭代计算的管道,对应一个个Task
一个Task是一个具体的线程,一个线程内都是内存计算。
6.3 Spark并行度
Spark并行度指同一时间内,有多少个Task在执行
有n个Task,RDD就会被划分成n个分区
规划并行度,只看集群总CPU核数,因为一个CPU核心同一时间只能运行一个Task。
一般并行度设置为CPU总核心的2~10倍。(一个Task运行完,CPU可以继续运行下一个Task)
Executor的数量和并行度无关!!一个服务器上可以运行多个Executor,一个Executor中可以运行多个Task。
一个Executor是一个进程,一个Task是一个线程,一个CPU核心就可以运行一个Task。
6.4 Spark任务调度
Spark任务由Driver调度
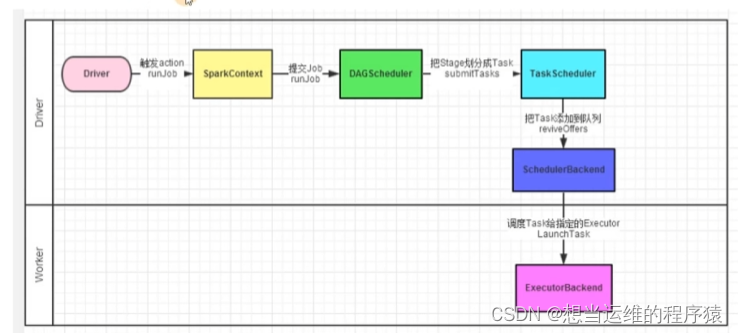
Spark程序调度流程:
(1)构建Driver
(2)构建SparkContext(执行环境入口)
(3)Driver基于DAG调度器规划Task
(4)Driver基于Task调度器将Task分配到各个Executor上干活,并监控它们执行
(5)Executor被Task调度器监控,定期向Task调度器汇报进度(Task调度器监控整个集群的执行)
Driver内的两个组件:
DAG调度器: 将逻辑DAG图进行处理,得到逻辑上Task的划分(确定有多少个Task,每个Task干什么)
Task调度器: 基于DAG调度器的结果,规划每个Task应该在哪个Executor上运行,并监控管理它们的运行。(监控整个Spark程序的执行)
七、Spark SQL
Spark SQL是Spark用于结构化数据(Structured data)处理的Spark模块
Spark SQL的数据抽象主要是有3种,主要是DataFrame:
- SchemaRDD对象(已废弃)
- DataSet对象: 可用于Java、Scala语言
- DataFrame对象: 可用于Java、Scala、Python语言

RDD和DataFrame的区别仅在于:RDD可以存储任意结构数据,DataFrame只能存储二维表结构数据
DataFrame和DataSet基本相同,只是DataSet支持泛型特性,可以更好的支持Java、Scala语言。
SparkSQL中程序入口对象是SparkSession
(RDD中是SparkContext对象,Spark2.0后SparkContext对象也可以通过SparkSession获取)
7.1 DataFrame的组成
DataFrame的组成包括四部分:
StructType对象: 描述整个DataFrame的表结构,由多个StructField组成
StructField对象: 描述一个列的信息
Row对象: 记录一行数据
Column对象: 记录一列数据并包含该列的信息
StructType对象的创建:

7.2 DataFrame的创建
1. 将RDD 或 Pandas的DataFrame 转成DataFrame
| 方法 | 参数 | 说明 |
|---|---|---|
| sparksession.createDataFrame(参数1, 参数2) | 参数1: 被转换的RDD 参数2: 通过list按顺序指定列名 或 传入StructType对象指定列名 | RDD转成DataFrame |
| rdd.toDF(参数1) | 参数1: 通过list按顺序指定列名 或 传入StructType对象指定列名 | RDD转成DataFrame |
| sparksession.createDataFrame(参数1) | 参数1: pandas中的DataFrame对象 | 将Pandas的DataFrame转成SparkSQL中的DataFrame |
使用StructType指定列名与使用list指定列名的区别:
StructType对象中不仅指定了列名,还包含了每个列的类型,是否允许为空
如果仅通过list指定列名,则每列的类型由spark自动判断,是否允许为空默认为true
2. 通过SparkSQL的统一API 读取外部数据 创建DataFrame
通过以下API可以读取text、csv、json、parquet、orc等文件格式

7.3 DataFrame编程
DataFrame支持两种编程风格进行数据处理:DSL风格、SQL风格
DSL(Domain-Specific Language)领域特定语言
DSL风格实际上就是通过调用DataFrame的各种API(类似RDD的算子)来处理DataFrame数据
SQL风格就是使用SQL语句处理DataFrame数据
- DSL风格
# 指定查询某些列
df.select()
# 过滤条件
df.filter()
df.where()(与filter一样,使用哪个都可以)
# limit分页
df.limit()
# groupBy返回的不是DataFrame对象而是GroupedData对象
# GroupedData对象后面要跟sum、avg、min、max等聚合函数后才是DataFrame
df.groupBy()
# 展示DataFrame数据
df.show()
- SQL风格
# 创建一个临时表
df.createTempView("score")
# 创建一个临时表,如已存在则替换
df.createOrReplaceTempView("score")
# 注册一个全局表
df.createGlobalTempView("score")
# 全局表可以跨SparkSession使用(一般不用,因为一个Spark程序中一般只创建一个SparkSession对象)
# 临时表只能在当前SparkSession中使用
# 使用SQL语句查询对应的表
sparksession.sql('select * from score')
7.4 DataFrame数据清洗API
| 作用 | 数据清洗相关API | 说明 |
|---|---|---|
| 数据清洗 - 数据去重 | df.dropDuplicates() | 对全部列联合起来进行去重,类似distinct |
| 数据清洗 - 数据去重 | df.dropDuplicates([‘age’, ‘job’]) | 对指定列联合起来进行去重 |
| 数据清洗 - 缺失值删除 | df.dropna() | 所有字段中任意一个为空,就删除该行数据 |
| 数据清洗 - 缺失值删除 | df.dropna(thresh=2, subset=[‘name’,‘age’]) | 在name和age中最少满足2个有效列,否则就删除该行数据 |
| 数据清洗 - 缺失值填充 | df.fillna(“loss”, subset=[“job”]) | job如果为空,则填充为"loss" |
| 数据清洗 - 缺失值填充 | df.fillna({“name”:“未知姓名”, “age”: 1}) | 通过字典指定填充规则 若name为空则填充为"未知姓名",age为空则填充为1 |
7.5 DataFrame数据写出
通过SparkSQL的统一API 进行DataFrame数据的写出
df.write.mode().format().option(K, V).save(PATH)
# mode,传入模式字符串可选:append追加,overwrite覆盖,ignore忽略,error重复就报异常(默认)
# format,传入格式字符串,可选:text,csv,json,parquet,orc,avro,jdbc
# 注意:text源只支持单列df写出
# option 设置属性,如.option("sep", ",")r
# save写出的路径,本地路径 or HDFS路径
7.6 Catalyst优化器
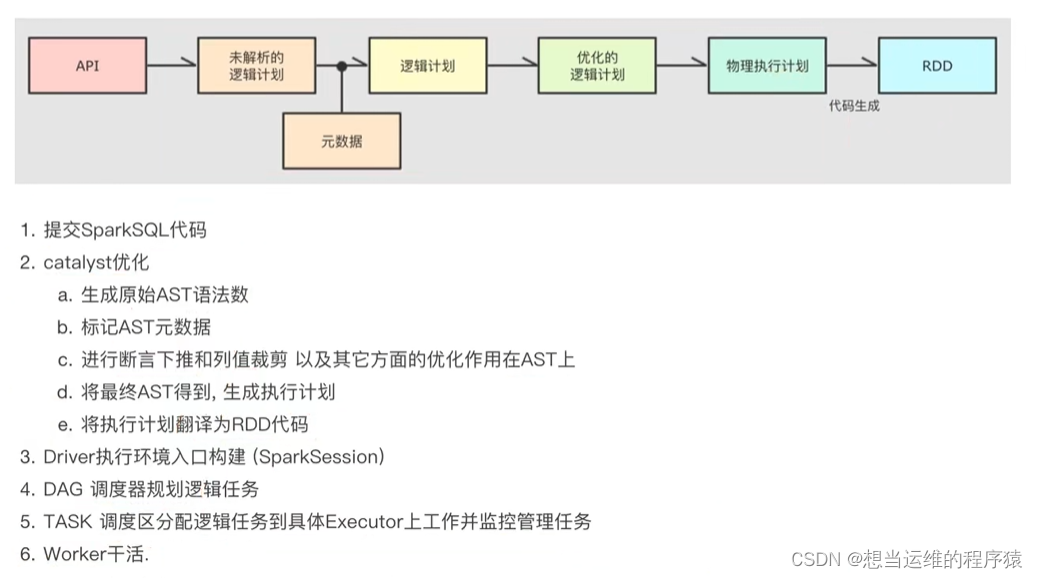
SparkSQL会通过Catalyst优化器对写完的Spark程序进行“自动优化”,提升代码运行效率。

Spark接受到SQL语句后,交给Catalyst,Catalyst解析SQL生成对应的RDD的执行计划,最终交给集群执行。
Catalyst主要优化点有2个:谓词下推、列值裁剪
谓词下推:将where提前,以减少join时的数据量
列值裁剪:只提取最终select查询相关的字段(减少查询的字段)

Catalyst主要流程:
1.解析SQL,生成原始AST语法树
2.标记AST元数据
3.进行谓词下推、列值裁剪等优化,得到优化后的AST
4.根据优化后的AST生成 物理执行计划
5.将物理执行计划翻译为RDD代码
7.7 SparkSQL执行流程
八、Hive On Spark与Spark On Hive
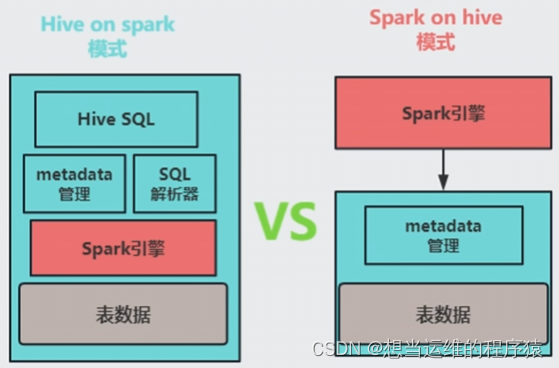
Hive On Spark中,仅仅是把Hive的底层计算引擎由MR换成了Spark,数据处理用的是HQL,使用者无需了解Spark,且由于使用的是Hive所以只支持离线处理。
Spark On Hive中,Spark仅仅是使用了Hive中的MetaStore服务来获取表的元数据,数据处理仍按Spark的方式进行,即能使用RDD丰富的算子或标准SQL来处理数据, 因此使用者需要熟悉Spark,且该模式既支持离线,也支持实时的数据处理(可以使用Structured Streaming进行实时处理)














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









