







对于从事Android开发的人来说,如果从开发的维度来说,需要着重掌握两点:Java(Kotlin)开发语言和Android操作系统,虽然现在Kotlin的使用逐渐变得多了起来,但是对于Java的基础知识一直是面试的常客,而且Kotlin最终也是需要Java虚拟机来编译,因此并没有完全绕开Java,因此Java的基本功尤为重要;
为什么要开始写这个Android进阶宝典,因为现在网络上的碎片化信息太严重了,并没有一个成体系的文章,而自己也没有成体系地写过一个专题,这也算是给自己的一个挑战,所以最近半年时间,如果有时间就会继续更新,有需要的伙伴可随时领取,当然有问题也可以随时提出,我们一起探讨~
OK,闲话不再多说,开始coding
多线程
多线程一直是面试中常问的问题,为什么好多人答不上来,是因为在日常的开发中很少会涉及到多线程的使用,像我们使用到的OkHttp、Retrofit,已经在底层做好了多线程并发的封装我们只需要调用即可;如果在使用Kotlin时,甚至都不需要多线程,直接通过协程的方式来完成任务的调度,但是既然这个是一个难点,就需要我们一起去攻克它。
1 并发
什么时候会用到并发?我们知道的是,在Android App启动之后,会创建一个主线程,当前主线程并不是所有的活都能做,像一些耗时的操作,例如网络请求、图片加载、后台下载任务等等,这些都需要放在子线程中执行,只要创建了子线程,那么现在就是一个多线程的场景,就会涉及到并发。
1.1 并发的优势和弊端
那么并发有什么好处呢?
1 提效 一个任务采用多线程去执行,如果单线程执行完成需要10s,那么开启5个线程只需要2s
2 避免ANR 开启子线程完成耗时操作,不会阻塞主线程
既然有好处,那么自然有弊端
1 资源的占用 开启任意一个子线程,都会占用系统内存资源,而且频繁地创建销毁线程会导致提前GC
2 线程调度同步 开启的线程越多,那么就需要做好各个线程的同步问题,尤其是线程之间的通信,子线程与主线程的通信等
因此,设计一个好的并发框架并不容易
1.2 Android开发中的误操作
因为涉及到了多线程,很多开发人员对此会感到恐惧,而且还会有一些耗时并不太严重操作放在主线程,下面这些事情,我们可能都做过
1 加载图片,使用BitmapFactory.decodeFile
很多小伙伴就是这么做了,直接在主线程中通过BitmapFactory加载任意图片,得到Bitmap展示在ImageView中,这种方式其实是不可取的。有些图片确实很小,不到1M,加载速度确实很快没有任何影响;但是如果是4-5M图片,加载时间会达到100ms以上,如果是更大的图,可能会达到秒级别,如果累计起来很有可能发生ANR
2 SharedPreference本地数据存储
我们在存储本地数据时,经常会使用到SharedPreference,直接在主线程中commit,这个事情我就干过,如果涉及到频繁地读写操作,势必会造成卡顿;因此建议使用SharedPreference的apply异步提交
除此之外,像XML文件的读取,数据库数据读取等,当然这是优化点,在实际的开发中也要主动去避免这些
2 线程的概念
在面试中,很多人会问进程和线程的区别,这其实是一个老生常谈的问题了。什么是进程,当我们打开一个app的时候,例如微信,就会启动一个进程(微信是一个多进程的应用,这里只是距离说明),在进程内部,有最小的执行单元线程,一个进程中可以有多个线程,例如第一节中介绍的。
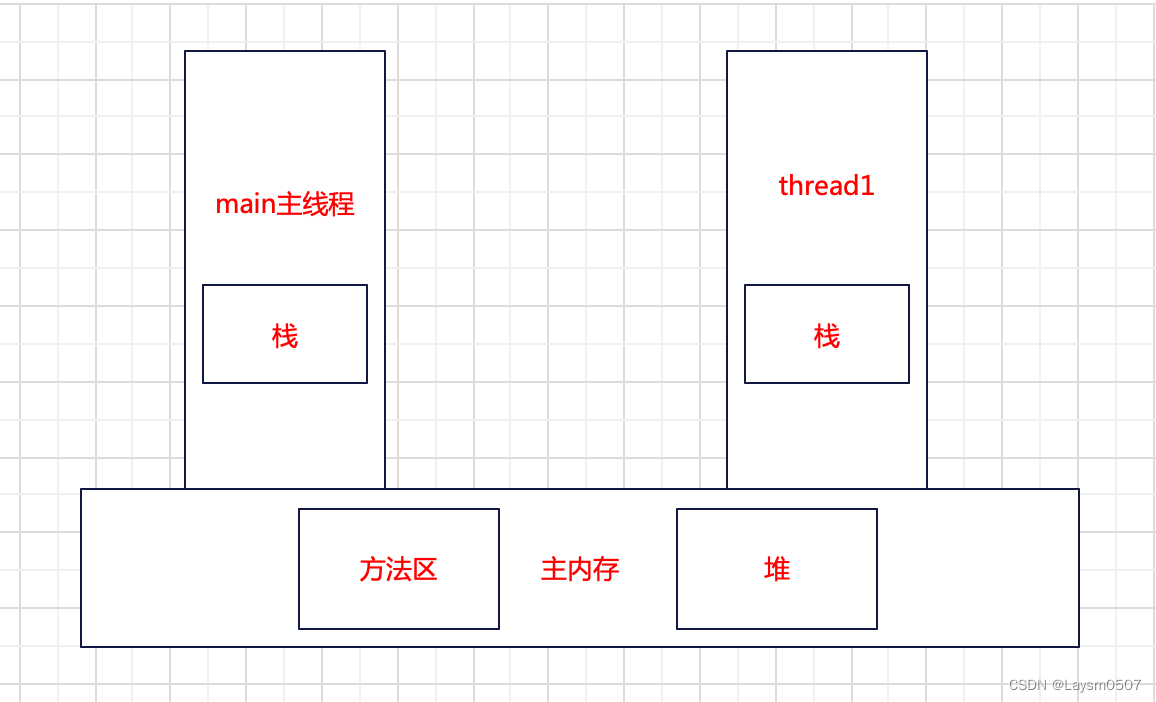
对于线程来说(这里涉及到一些JVM的知识),方法区和堆内存是所有线程共享的,程序计数器跟虚拟机栈是线程私有的,例如
public class ThreadTest {
public static void main(String[] args) {
int a;
}
}
在主线程中,创建一个变量a,这个变量是存在主线程的虚拟机栈中的;这个时候创建一个线程1,也创建一个变量b,这个b是存在线程1的虚拟机栈中的,但是线程1想访问主线程中的变量是没法直接访问的
public static void main(String[] args) {
int a;
new Thread(new Runnable() {
@Override
public void run() {
//访问a,访问不到
int b = a;
}
});
}
如果想访问a变量,有什么方式?
声明变量a为final,意味着a为常量,那么就会放在主内存的方法区,所有的线程都可以共享
public static void main(String[] args) {
final int a = 0;
new Thread(new Runnable() {
@Override
public void run() {
//访问a
int b = a;
}
});
}
如果是new出来的对象,是保存在堆内存中的,也是可以直接访问的
public static void main(String[] args) {
Bundle bundle = new Bundle();
new Thread(new Runnable() {
@Override
public void run() {
Bundle bundle1 = new Bundle();
bundle1 = bundle;
}
});
}
2.1 线程的生命周期
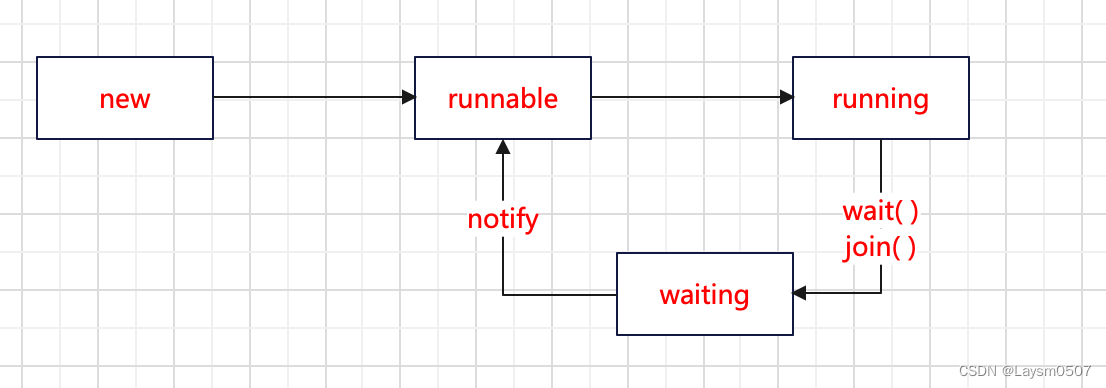
简单画了一下线程的生命周期,线程被new出来就是新建的状态,然后马上进入runnable(可运行)的状态,等待操作系统有空闲的CPU时,就将CPU分配给这个可运行状态的线程(这里留一个问题,如果存在多个可运行状态的线程,系统会优先将CPU分配给哪个线程?),线程进入运行状态;
当执行wait或者join方法后,线程会进入阻塞状态,只有当调用notify重新唤起线程后,线程才会重新进入runnable状态,当然也不会立即执行。
2.2 线程的本质
如果想要了解线程的本质,那么就从源码开始入手
Thread ## start
public synchronized void start() {
if (started)
throw new IllegalThreadStateException();
/* Notify the group that this thread is about to be started
* so that it can be added to the group's list of threads
* and the group's unstarted count can be decremented. */
group.add(this);
started = false;
try {
// Android-changed: Use Android specific nativeCreate() method to create/start thread.
// start0();
nativeCreate(this, stackSize, daemon);
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}
(1)线程启动调用start方法,首先会判断started标志位,默认是false,当线程调用start方法之后,started会被设置为true,当再次调用start方法时,就会抛出异常IllegalThreadStateException
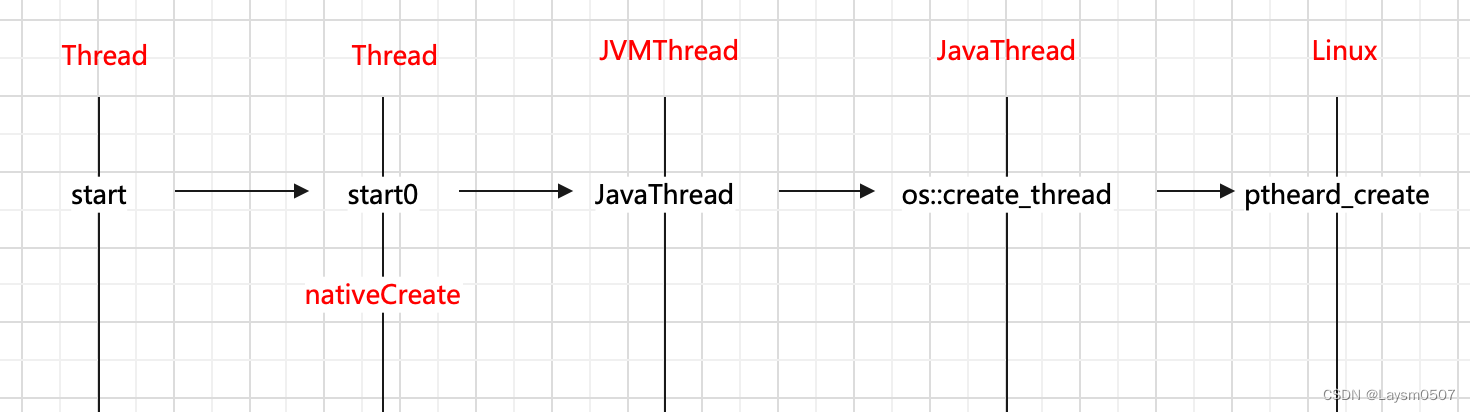
(2)线程真正的启动是调用nativeCreate方法,在此之前是start0方法,这两个方法都是native方法,我们需要看一下这个两个方法
## libcore/ojluni/src/main/native/Thread.c
static JNINativeMethod methods[] = {
{"start0", "(JZ)V", (void *)&JVM_StartThread},
{"setPriority0", "(I)V", (void *)&JVM_SetThreadPriority},
{"yield", "()V", (void *)&JVM_Yield},
{"sleep", "(Ljava/lang/Object;J)V", (void *)&JVM_Sleep},
{"currentThread", "()" THD, (void *)&JVM_CurrentThread},
{"interrupt0", "()V", (void *)&JVM_Interrupt},
{"isInterrupted", "(Z)Z", (void *)&JVM_IsInterrupted},
{"holdsLock", "(" OBJ ")Z", (void *)&JVM_HoldsLock},
{"setNativeName", "(" STR ")V", (void *)&JVM_SetNativeThreadName},
};
我现在看的是Android9.0的源码,目前还是使用的是start0方法,对应JVM中的函数是JVM_StartThread,那就先看这个方法
## hotspot/src/share/vm/prims/jvm.cpp
JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
JVMWrapper("JVM_StartThread");
JavaThread *native_thread = NULL;
bool throw_illegal_thread_state = false;
// We must release the Threads_lock before we can post a jvmti event
// in Thread::start.
{
// Ensure that the C++ Thread and OSThread structures aren't freed before
// we operate.
MutexLocker mu(Threads_lock);
// Since JD check for this
if (java_lang_Thread::thread(JNIHandles::resolve_non_null(jthread)) != NULL) {
throw_illegal_thread_state = true;
} else {
//在虚拟机中,声明堆栈的大小
jlong size = java_lang_Thread::stackSize(JNIHandles::resolve_non_null(jthread));
size_t sz = size > 0 ? (size_t) size : 0;
native_thread = new JavaThread(&thread_entry, sz);
......
Thread::start(native_thread);
JVM_END
(1)首先,在虚拟机中,声明当前线程的堆栈大小stackSize;
(2)创建一个JavaThread对象,这个一个native的线程;在JavaThread的构造方法中,会调用os的create_thread函数,os是Linux操作系统,最终调用到了Linux层的代码
## hotspot/src/share/vm/runtime/thread.cpp
JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz) :
Thread()
#if INCLUDE_ALL_GCS
, _satb_mark_queue(&_satb_mark_queue_set),
_dirty_card_queue(&_dirty_card_queue_set)
#endif // INCLUDE_ALL_GCS
{
......
os::create_thread(this, thr_type, stack_sz);
_safepoint_visible = false;
}
(3)在Linux底层中,如果传入的堆栈大小是0,那么就会生成一个默认的大小(8K),最终调用了pthread_create方法,通过Linux创建线程
## hotspot/src/os/linux/vm/os_linux.cpp
bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
......
// stack size
if (os::Linux::supports_variable_stack_size()) {
// calculate stack size if it's not specified by caller
if (stack_size == 0) {
stack_size = os::Linux::default_stack_size(thr_type);
switch (thr_type) {
case os::java_thread:
// Java threads use ThreadStackSize which default value can be
// changed with the flag -Xss
assert (JavaThread::stack_size_at_create() > 0, "this should be set");
stack_size = JavaThread::stack_size_at_create();
break;
case os::compiler_thread:
if (CompilerThreadStackSize > 0) {
stack_size = (size_t)(CompilerThreadStackSize * K);
break;
} // else fall through:
// use VMThreadStackSize if CompilerThreadStackSize is not defined
case os::vm_thread:
case os::pgc_thread:
case os::cgc_thread:
case os::watcher_thread:
if (VMThreadStackSize > 0) stack_size = (size_t)(VMThreadStackSize * K);
break;
}
}
stack_size = MAX2(stack_size, os::Linux::min_stack_allowed);
pthread_attr_setstacksize(&attr, stack_size);
} else {
// let pthread_create() pick the default value.
}
pthread_t tid;
//Linux创建线程
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) java_start, thread);
也就是说,在Java层调用了start方法,其实在Linux底层创建的线程
3 锁机制
在多线程并发中,为了保证线程安全,引入了锁的概念
public class Main implements Runnable{
public static int a = 0;
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
a++;
}
}
public static void main(String[] args) {
Main t1 = new Main();
Thread thread1 = new Thread(t1);
Thread thread2 = new Thread(t1);
thread1.start();
thread2.start();
try {
thread2.join();
thread1.join();
}catch (Exception e){
}
System.out.println("a==" + a);
}
}
3.1 对象锁和类锁
两个线程同时执行run方法,如果是线程安全,那么a将会累加20000次,但是最终的结果,并不是20000次,意味着当前的线程是不安全的。
@Override
public synchronized void run() {
for (int i = 0; i < 10000; i++) {
a++;
}
}
在run方法中添加synchronized关键字,当前synchronized修饰的是对象,所以当前锁是对象锁,而且两个线程拿到的是同一个对象,因此这两个线程将会竞争这一把对象锁
public static void main(String[] args) {
Main t1 = new Main();
Main t2 = new Main();
Thread thread1 = new Thread(t1);
Thread thread2 = new Thread(t2);
thread1.start();
thread2.start();
try {
thread2.join();
thread1.join();
}catch (Exception e){
}
System.out.println("a==" + a);
}
如果创建了2个对象,那么每个线程都持有不同的对象锁,那么又成了线程不安全的了;
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
add();
}
}
public synchronized static void add(){
a++;
}
现在使用synchronized修饰静态方法,那么锁住的是类,是类锁,而且类只有一个,哪怕持有不同的类对象,也是线程安全的;
总结:
(1)使用synchronized修饰普通方法,锁住的就是对象,如果保证线程安全,那么所有的线程必须持有同个对象;
(2)使用synchronized修饰静态方法,锁住的就是类,类只有一个,因此即便是多个线程持有不同对象,那么也是线程安全的
(3)使用synchronized修饰代码块,锁住的也是声明的对象object,但是还是达不到对象唯一性
public Object object = new Object();
public void add(){
synchronized (object){
a++;
}
}
3.2 synchronized关键字
synchronized是一个关键字,底层实现完全依赖于JVM虚拟机,那么既然想了解synchronized的原理,就需要深入了解一下数据在JVM中的存储
class Person{
//新增
int a;
}
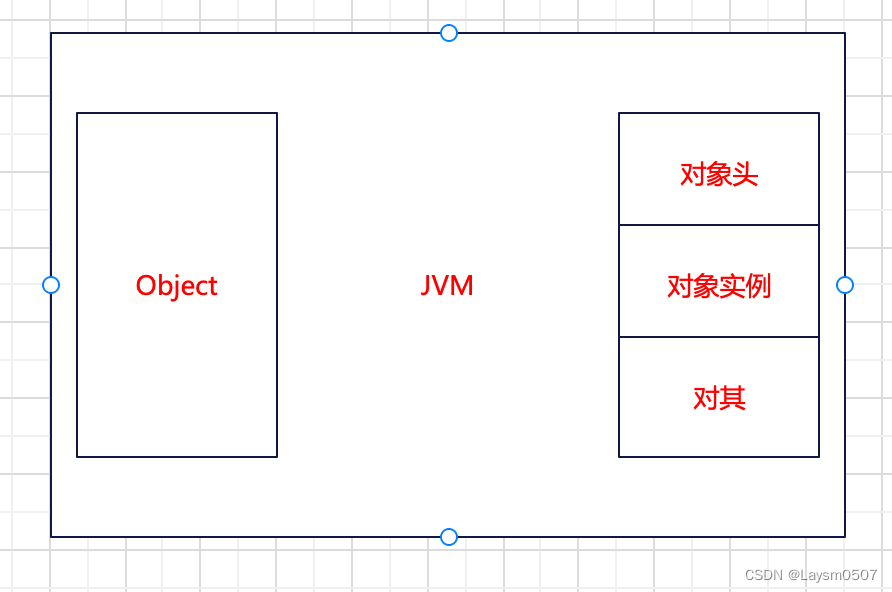
当我创建一个空的类对象,在JVM中的堆内存中存储,其objectSize大小为8K,也就是其对象头是8K,当添加一个int类型的参数后,其objectSize为12K,是因为增加了一个4K的Int数据,是放在对象实例中
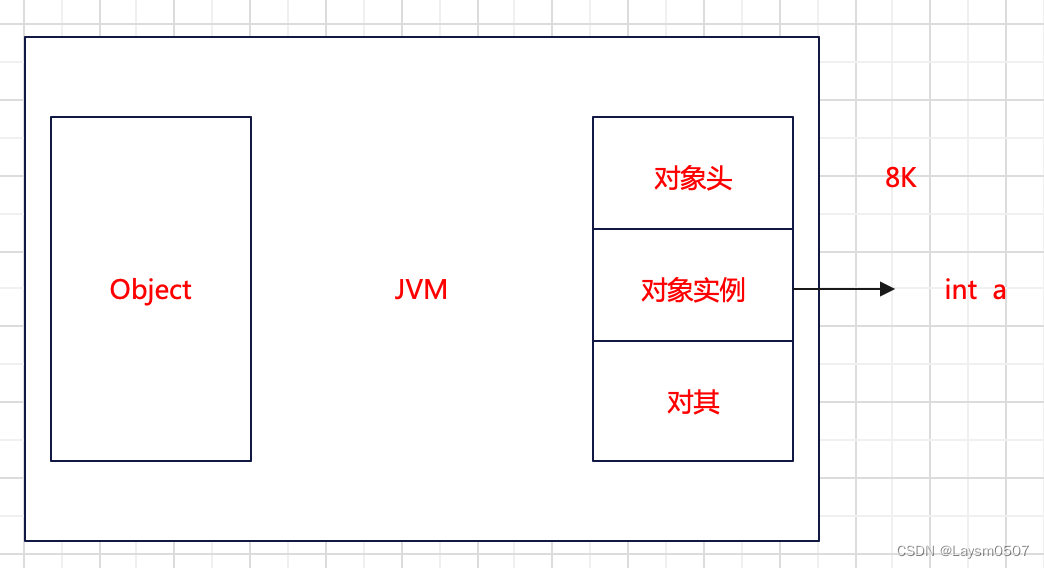
3.2.1 有锁和无锁状态下对象头的存储方式
那么我们之前使用到了锁,因为是在堆内存中,我们只说对象锁,那么锁的信息就是保存在对象头中,其实对象头中保存的信息还是挺多的,像锁信息、与GC相关的信息(新生代、老年代 age)等等
Person person = new Person();
//获取hashCode
person.hashCode();
我们拿32位操作系统来说,无锁状态下对象头的存储形态

当在无锁有锁的状态下,获取hashcode的方式是不一样的,那么在无锁状态下,是从0-25位中取值返回(从内存中取值)
public int hashCode() {
return identityHashCode(this);
}
// Package-private to be used by j.l.System. We do the implementation here
// to avoid Object.hashCode doing a clinit check on j.l.System, and also
// to avoid leaking shadow$_monitor_ outside of this class.
/* package-private */ static int identityHashCode(Object obj) {
int lockWord = obj.shadow$_monitor_;
final int lockWordStateMask = 0xC0000000; // Top 2 bits.
final int lockWordStateHash = 0x80000000; // Top 2 bits are value 2 (kStateHash).
final int lockWordHashMask = 0x0FFFFFFF; // Low 28 bits.
if ((lockWord & lockWordStateMask) == lockWordStateHash) {
return lockWord & lockWordHashMask;
}
return identityHashCodeNative(obj);
}
那么除此之外,还有4位用来存储gc相关的信息,1位存储是否为偏向锁,剩下的2位存储锁的标志位(无锁、偏向锁、轻量级锁、重量级锁)
接下来介绍一下有锁状态下对象头的数据结构

public void add(){
synchronized (object){
object.hashCode();
}
}
从hashCode方法中可以看到,在有锁状态下,就不是从内存中取值,而是从_monitor_缓存中取出,所以对应的对象头数据结构也发生变化
首先前23位存储线程ID,这是与偏向锁有关的,因此当多个线程去竞争同一把锁,拿到锁的线程ID会被记录,下次再次竞争的时候,当前线程将会被优先指定获取,这也是偏向锁的概念。
除此之外,还会记录时间戳,用来记录超时时间,在到达超时时间之后,会去判断当前线程的状态(根据id判断),如果当前线程还存在,那么就会保持;如果当前线程已经不存在了,那么当前对象就会从有锁变成无锁的状态

如果存在第二个线程申请同一把对象锁,那么偏向锁就会升级为轻量级锁,这里只是申请,并不是竞争关系,意味着两者可以一前一后交替进行,那么在对象头中采用了30位用来记录代码的执行地址

与轻量级锁对应的,就是重量级锁,同一时间存在多个线程竞争,就会从轻量级锁升级,这个时候,就会切换内核态,由系统分配哪个线程获取这把锁,因此会额外带来系统开销;其中指向monitor的指针就是需要切换到内核态
3.2.2 objectMonitor维持线程
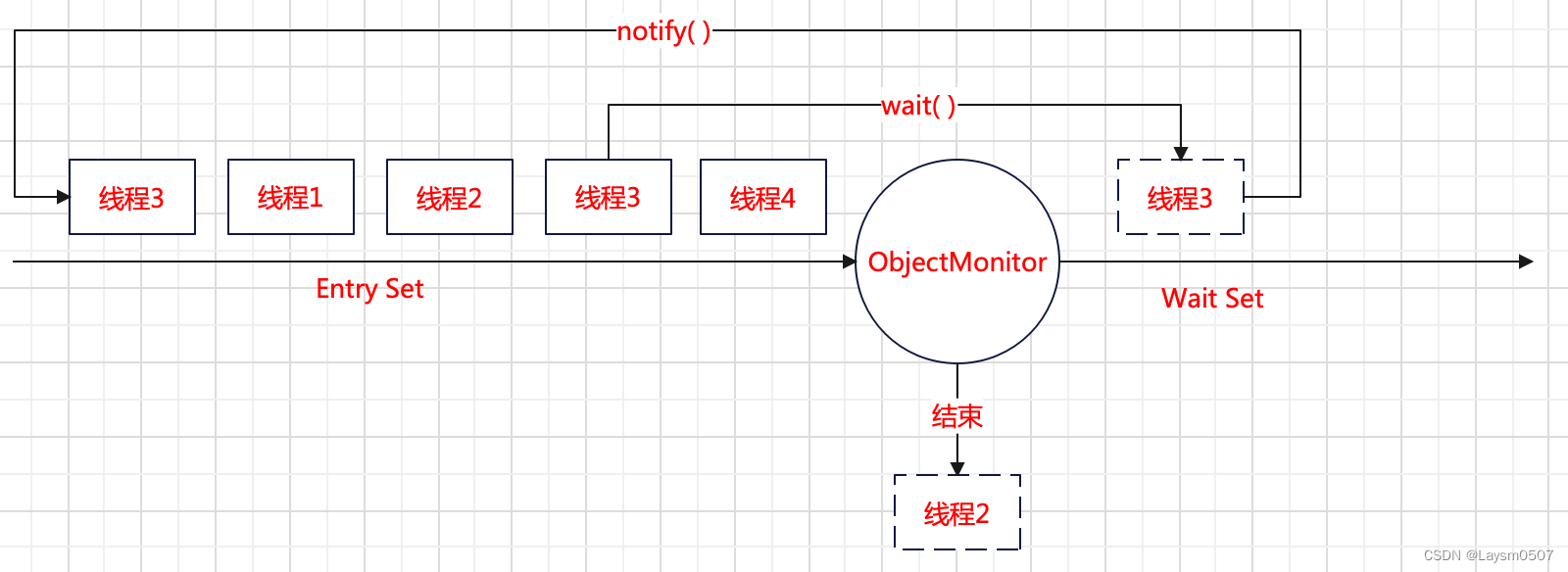
当有多个线程竞争同一个对象时,系统其实是通过ObjectMonitor来统一管理分配,当升级为重量级锁之后,ObjectMonitor会选择某个线程获取当前对象,其他等待获取锁对象的线程会置于Entry Set队列中;当该线程执行结束之后,就从队列中移除;当某个线程调用wait( )方法之后,让出CPU使用权,如果想继续持有该对象,那么会进入Wait Set队列中,当该线程被重新唤起之后,就排到Entry Set队列末尾等待被召唤;
那么这就意味着,一个线程可以多次获取这个锁对象,在ObjectMonitor中有count参数来记录线程重入的次数,获取1次 +1,释放1次 -1;所以为什么所有的Object对象都会有wait、notify、notifyAll方法,因此每个对象都有可能成为一把锁对象
















 1168
1168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











