







前言
好了,今天我们又来学sql。
第十二问
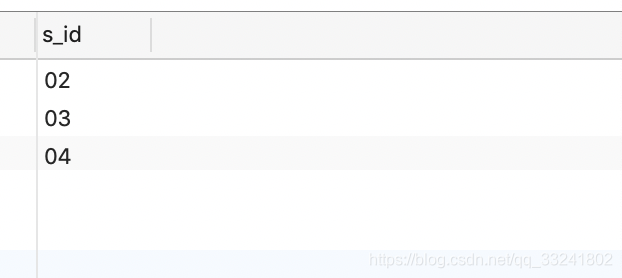
题目:查询和01号同学所学课程完全相同的其他同学的学号。
分析:看到完全相同,我们又想起之前张三老师上过的所有课,同样的这道题我们也采用同样的方式。
先查询出01学生所学过的所有课的c_id,以及课程数count(c_id),然后查询出score表中同样课程好的记录,然后按照学号聚合(group by 用 having),聚合之后看这些学生的课程数是否和01同学一致,如果一致说明学的课完全一样。
- 学号s_id
- 课程号c_id
- 课程数count(c_id)
看来这次一张表就能解决,代码如下
//所以要先查询出学过相同课程的s_id,然后判断s_id是否在其中
SELECT s1.s_id id
FROM
(
//记得把c_id字段也查出来,这样才能比较
SELECT s_id,c_id FROM score WHERE c_id
in
(SELECT c_id FROM score WHERE s_id = '01')
) s1
GROUP BY s1.s_id
HAVING
COUNT(c_id) = (SELECT COUNT(c_id) FROM score WHERE s_id = '01')
--如果要改正确的话在这边加上一句,筛选掉课程数包含且大于01同学的情况
--不过这样太冗余了
--AND COUNT(c_id) = (SELECT COUNT(c_id) FROM score GROUP BY s_id HAVING s_id = id)
AND
s1.s_id != '01'
事实证明上面这种写法是有问题的,当02学生的课程包含且大于01学生的课程的时候也会被筛选出来(多谢杰哥指出,杰哥牛逼 )。
正确的写法应该是这样:
SELECT s_id FROM score
-- 查询出上过和01同学不一样课的学生,剩下的学生上过的课一定包含于01学生
WHERE score.s_id NOT IN(
SELECT s_id FROM score
WHERE c_id NOT IN
(SELECT c_id FROM score WHERE s_id = '01')
)
AND s_id != '01'
GROUP BY s_id
HAVING COUNT(c_id) =
(SELECT COUNT(c_id) FROM score WHERE s_id = '01')
第十三问
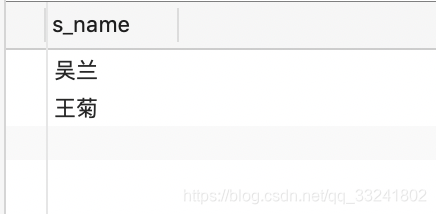
题目:查询没学过张三老师的任意一门课的学生的姓名。
分析:没学过任意一门,又是not in,先查询出张三老师教过的课,然后查询出学过这些课的学生的s_id,再然后在Student表中not in。
- 老师姓名t_name
- 学生姓名s_name
- 课程号c_id
- 学生学号s_id
SELECT s_name FROM Student WHERE s_id NOT IN
(
SELECT s_id FROM score
WHERE c_id
in
(
SELECT c_id FROM course JOIN teacher on course.t_id = teacher.t_id WHERE t_name = '张三'
)
)
第十四问
题目:查询两门及以上不及格课程的同学的学号、姓名、平均成绩
分析:
- 学号s_id
- 姓名s_name
- 平均成绩AVG(s_score)
两门以上不及格,我们可以先计算出s_score小于60的记录,然后使用group by聚类,然后使用count(c_id)就能获得有几门课程不及格。
SELECT score.s_id,Student.s_name,AVG(s_score)
FROM score
JOIN Student
on score.s_id = Student.s_id
WHERE score.s_score < 60
GROUP BY score.s_id
HAVING COUNT(score.c_id) > 1

附加题
题目:查询出总成绩排名前3的同学的学号
分析:这道题是我在今天面经中看到的题目,感觉TOPK的问题还没做到过,所以放到这里实现一下。
一般TOPK的问题都是采用order by排序,然后使用limit字段来进行限制。
SELECT s_id,SUM(s_score)
FROM score
GROUP BY s_id
ORDER BY SUM(s_score) DESC
//limit 3是指从0开始往后数3个
//如果要查询第二第三名就要使用limit 1,2
//意思是从1开始往后数2个
LIMIT 3

今天就练习到这里吧,感觉自己的sql操作越来越熟练了呢。
















 5258
5258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









