






你好,我是悦创。最近实习然后一对一学员上课备课,所以有点耽搁更新文章了。下一篇,会在公众号:AI悦创,发布。敬请关注!
然后,手里有个单子,但是奈何自己实习公司事情太多。所以就把我一对一学员的项目,介绍给 Panda4u 。最后他遇到加密就头疼了,然后我就几十斤把这个加密稍微研究了一下,故这也是这篇文章的诞生!
本文将会对这个系列的爬虫进行分析和抓取。仅供学习交流使用!
近期爬取了私募排排网上的历史净值,写一下爬取过程中的一些心得体会。
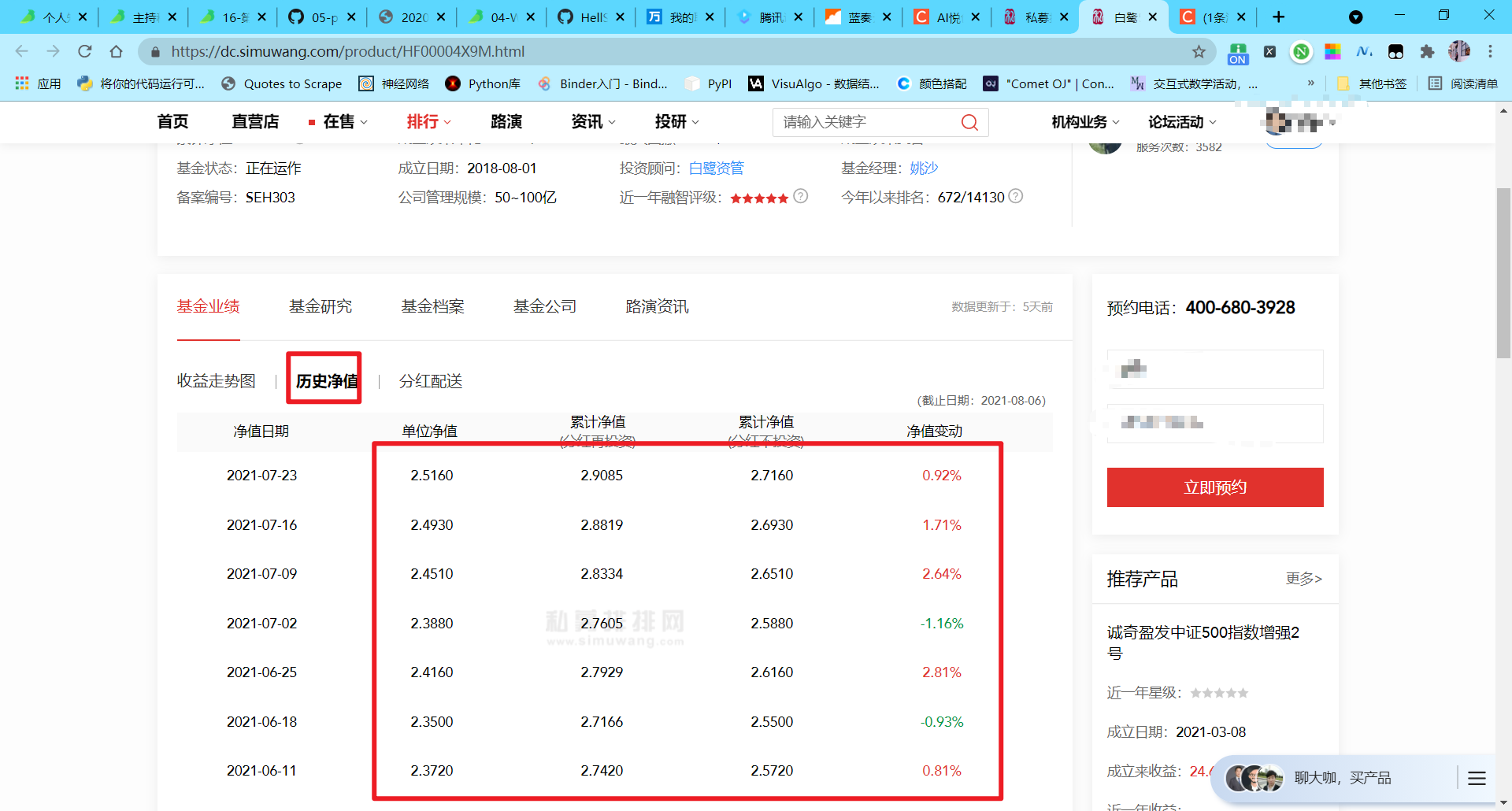
原本,思考的时候觉得,selenium 是“万能的”,应该可以一力破万法,结果果然栽跟头了。
上面有很多的难点,例如直接利用 selenium 会被检测出反爬、爬取的数值被加密(页面上看到的和 html 中不一样,多了一些隐藏值)等等。爬取的方法主要就是 selenium、正则、beautifulsoup、xpath。这里先把这里使用的库导入。
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
import pandas
import time
import re
from lxml import html
from selenium.webdriver.common.action_chains import ActionChains # 导入鼠标事件库
总体流程:打开网页,然后登录,到达需要解析的页面,得到源码,然后破解加密,最后输出数据保存在 excel 中。
一、开启网页
有的网站直接使用 selenium 就可以开启,例如
from selenium import webdriver
driver = webdriver.Chrome() # 启动驱动器
driver.get('https://www.simuwang.com/user/option') # 加载网站
但是在这里就会出现以下情况,那是因为如果直接开启网页,就会被发现是爬虫。

解决这个问题要使用以下代码
driver = webdriver.Chrome() # 启动驱动器
# 谷歌浏览器 79和79版本后防止被检测
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get('https://www.simuwang.com/user/option') # 加载网站
最后就能完美的开启网页了。
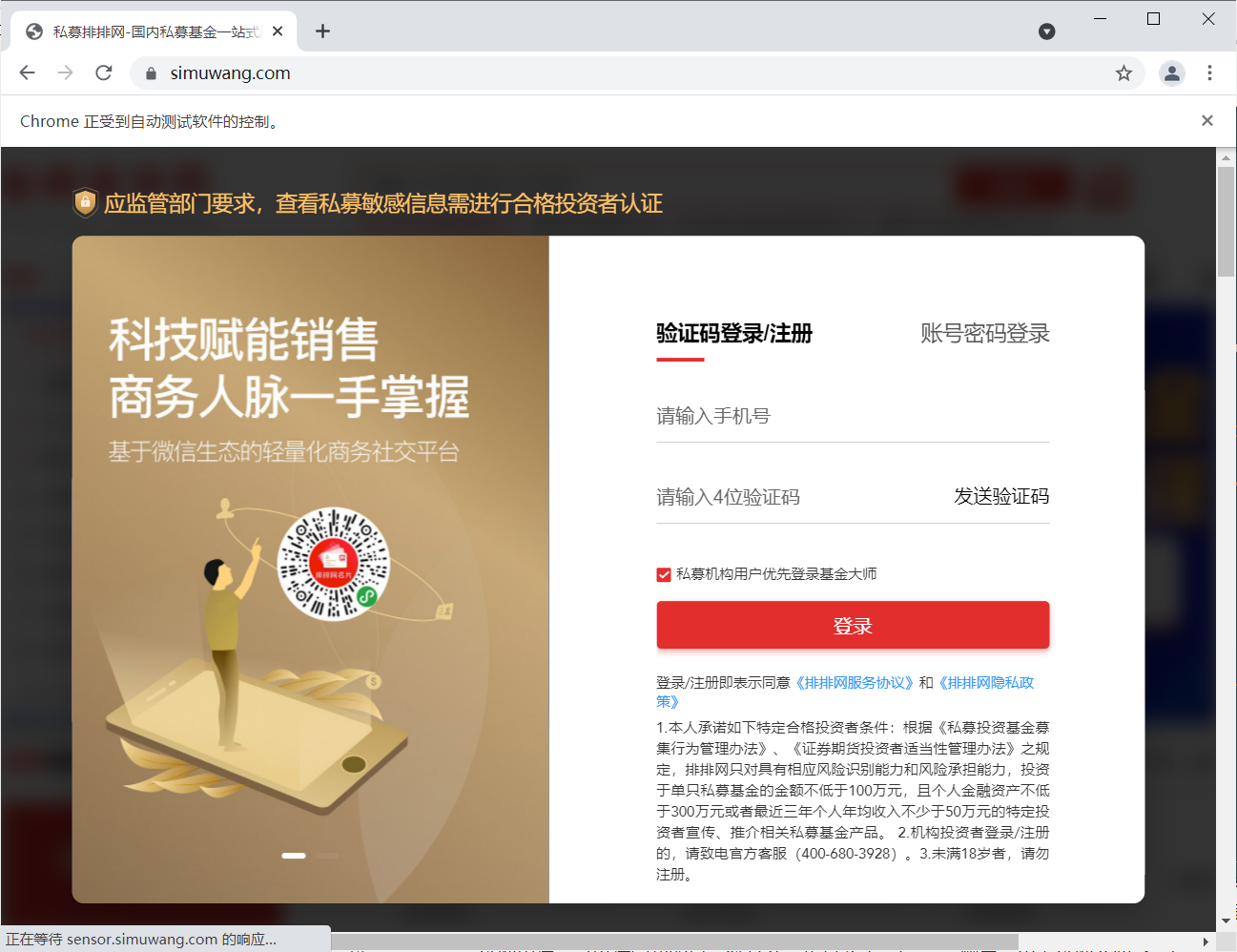
注意: 这里设置开发者模式也是不可行的!
二、selenium 定位元素解析网页
在进入网页之后,就开始元素定位。selenium 定位一共有八个 name , id ,link_text ,partial_link_text ,class_name ,xpath,css,tag_name 。其中最少也要掌握 xpath 或者 css 一种方法(使用这两种方法基本上能解决所有的定位)。后面,我会考虑出一个 Xpath 的提取视频教程,看大家的对于这篇文章的阅读量,如果过三百我就马上录。
详细用法,可以关注后续的文章,这里就不多赘述了。在这里就讲讲 selenium 这里的用法,我使用的方法是 xpath。
1. 输入账号和输入密码点击登录
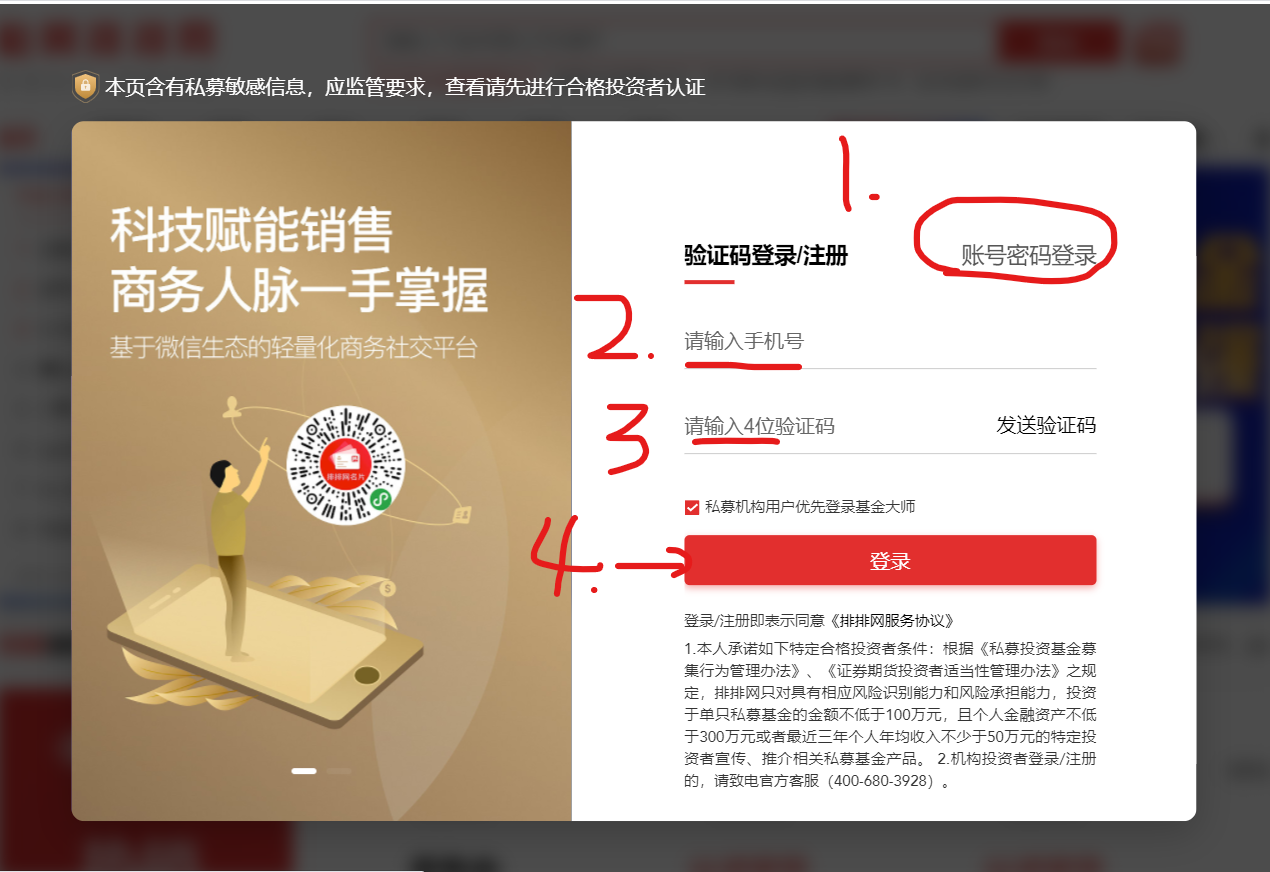
driver.find_element(By.XPATH,'//button[@class="comp-login-method comp-login-b2"]').click() #点击账号密码登录
driver.find_element(By.XPATH,'//input[@name="username"]').send_keys('xxxxxxxxxxxx') # 输入账号
driver.find_element(By.XPATH,'//input[@type="password"]').send_keys('xxxxxxxxxxxx') # 输入密码
driver.find_element(By.XPATH,'//button[@style="margin-top: 65px;"]').click() # 点击登录
补充:
-
以后使用定位最好都用 By(也就是以上的方法),而
driver.find_element_by_xpath(),因为后面的这种不利于封装。 -
元素定位是做什么的?我们为什么要定位元素?有什么用呢?
- 元素定位就是在 html 中找到我们在网页中看到内容对应的元素。
- 找到之后可以使用鼠标事事件和键盘事件,对网页进行人工模拟操作。
- 在这里就是简单的键盘事件
send_keys和鼠标事件click。
2. 叉掉广告,网页后退
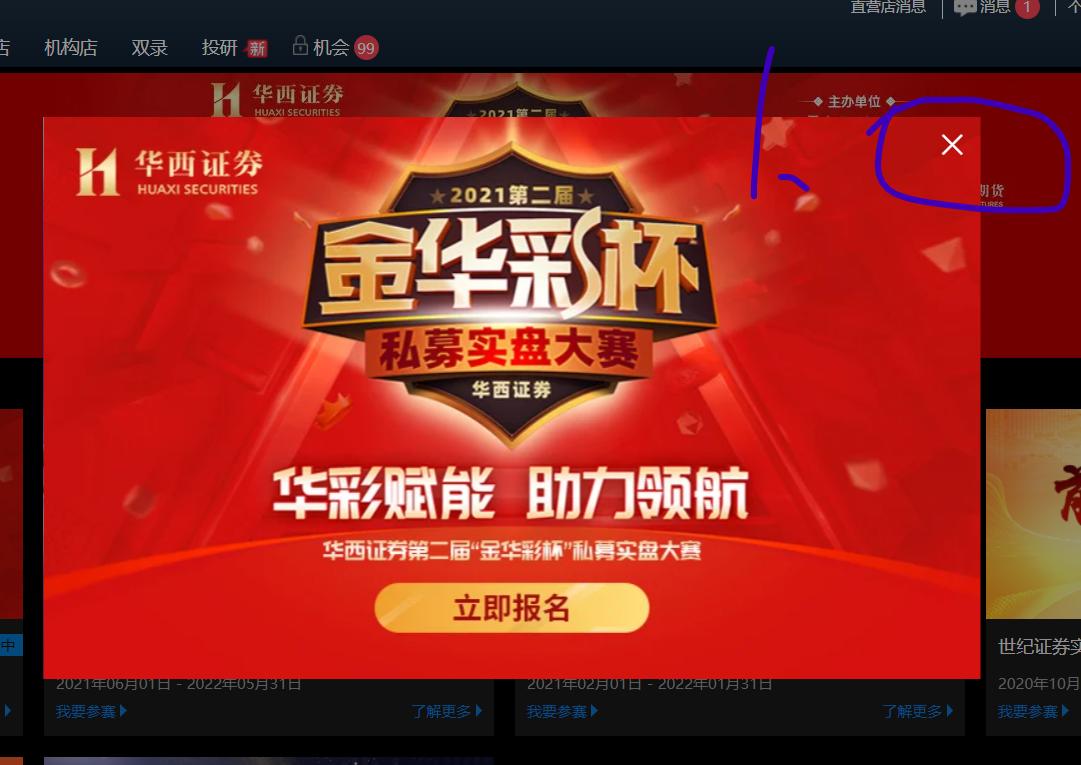
time.sleep(15) # 等待登录时间
driver.find_element(By.XPATH,'//span[@class="el-icon-close close-icon"]').click() # 叉掉广告
driver.back() # 网页后退
补充:
-
注意这里必须要 sleep 几秒。那是因为登录过程需要时间加载,不然会报错。
-
driver.back()是将当前页面返回上一级。那么driver.forward()前进到上一级。
3. 鼠标悬停点击自选
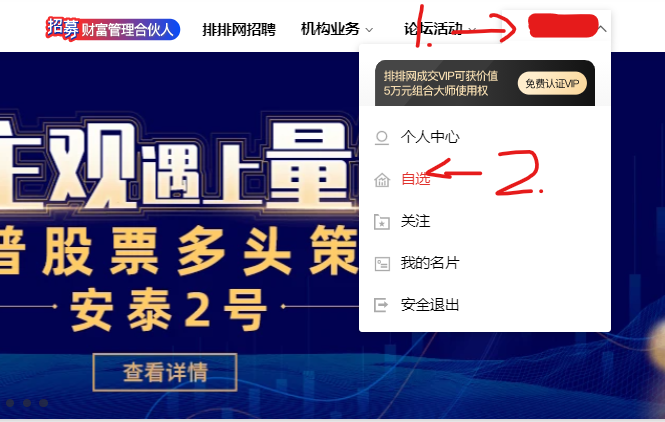
鼠标悬停在用户上,然后点击自选进入网页。
time.sleep(5) # 加载网页需要等待时间
mouse = driver.find_element(By.XPATH,'//div[@class="comp-header-nav-item fz14"]/div/span[@class="ellipsis"]')
ActionChains(driver).move_to_element(mouse).perform() # 悬停鼠标在名片
driver.find_element(By.XPATH,'//a[@class="comp-header-user-item icon-trade"]').click() # 点击自选
这里的悬停操作就是定位用户然后使用 ActionChains 进行悬停,在悬停中找到自选并点击。
4. 解析网页
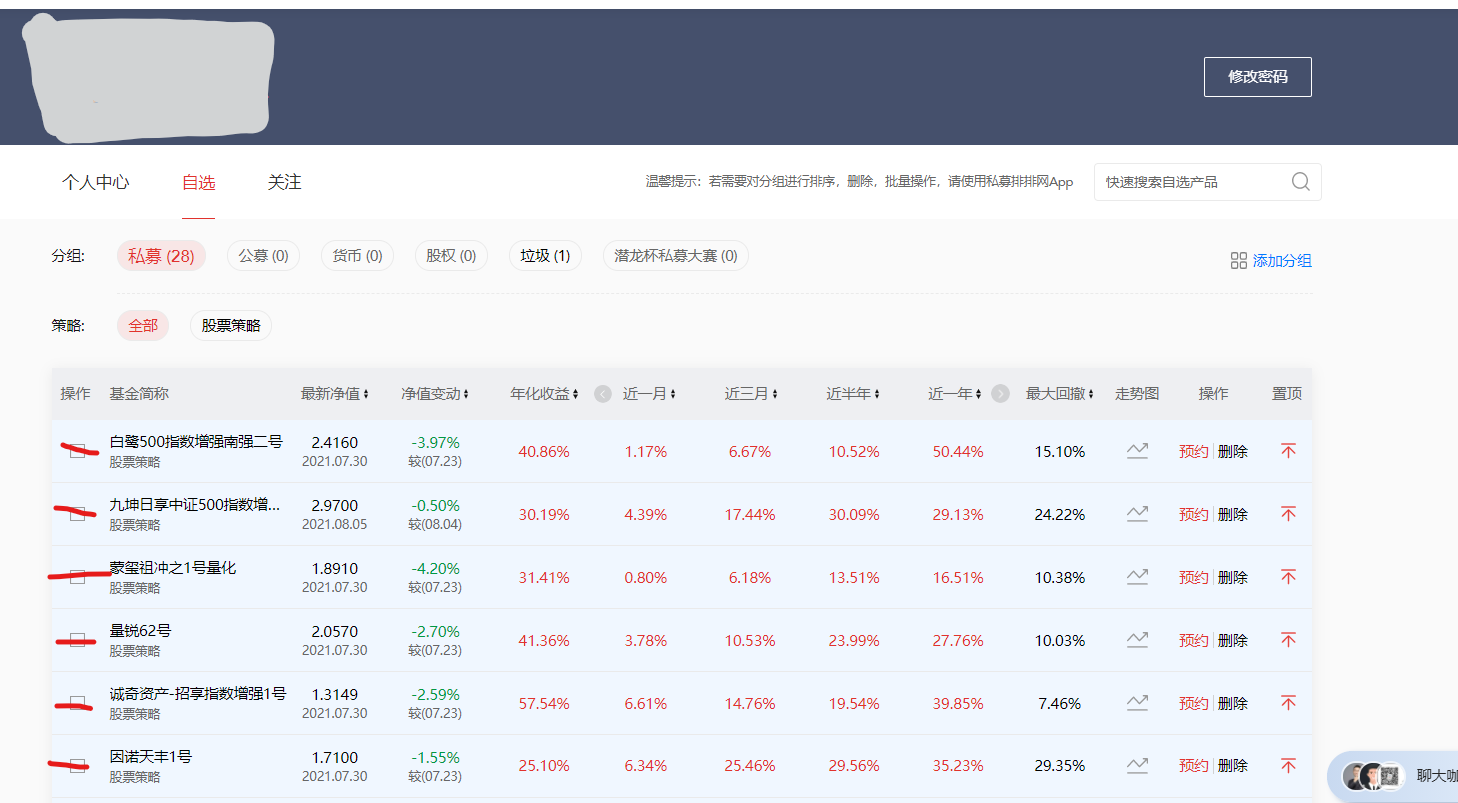
经历以上的步骤就来到了我们需要爬取数据的页面了。我们需要的数据在每一个基金里面的历史净值。所以我们先要得到每一个基金的网址,然后进入网站里面进行处理。
# 解析网页
page = driver.page_source
soup = BeautifulSoup(page,'html.parser')
list_url = [] # 用于保存目标网站
list_name = [] # 用于保存目标名称
url_a = soup.select('div:nth-child(2) > div.shortName > a') # 找到所爬取的网页
names = soup.select('div> div > div:nth-child(2) > div.shortName > a') # 找到名称
for u in url_a:
url = u['href'] # 得到网站
list_url.append(url)
for name in names:
list_name.append(name.get_text())
这里使用了 BeautifulSoup 对 page 进行解析,然后使用 select 定位找到每个基金的网址和基金名称。如果,有这个网站的爬虫需求可以联系我!这篇文章为上篇,下次继续!
AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。QQ、微信在线,随时响应!V:Jiabcdefh




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











