




 本文解决Hadoop中出现的连接超时错误,涉及开放特定端口及datanode主机名配置,同时处理因本地hadoop.dll引发的NativeIO异常,通过删除文件解决。
本文解决Hadoop中出现的连接超时错误,涉及开放特定端口及datanode主机名配置,同时处理因本地hadoop.dll引发的NativeIO异常,通过删除文件解决。
问题一: Failed to connect to bioyuana/ip:1004 for block BP-1366618129-172.16.1.176-1576652184324:blk_1073760623_19803, add to deadNodes and continue.
20/05/13 11:40:32 WARN DFSClient: Failed to connect to bioyuana/ip:1004 for block BP-1366618129-172.16.1.176-1576652184324:blk_1073760623_19803, add to deadNodes and continue.
java.net.ConnectException: Connection timed out: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.hdfs.DFSClient.newConnectedPeer(DFSClient.java:2848)
at org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.nextTcpPeer(BlockReaderFactory.java:816)
at org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.getRemoteBlockReaderFromTcp(BlockReaderFactory.java:741)
at org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.build(BlockReaderFactory.java:379)
at org.apache.hadoop.hdfs.DFSInputStream.getBlockReader(DFSInputStream.java:644)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:575)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:757)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:829)
at java.io.DataInputStream.read(DataInputStream.java:149)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.fillBuffer(UncompressedSplitLineReader.java:62)
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:218)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:176)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.readLine(UncompressedSplitLineReader.java:94)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.skipUtfByteOrderMark(LineRecordReader.java:152)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:192)
at org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:39)
at org.apache.spark.sql.execution.datasources.HadoopFileLinesReader.hasNext(HadoopFileLinesReader.scala:69)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:103)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:183)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:103)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$11$$anon$1.hasNext(WholeStageCodegenExec.scala:619)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:255)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:247)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$24.apply(RDD.scala:836)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$24.apply(RDD.scala:836)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$11.apply(Executor.scala:407)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:413)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
问题解决:
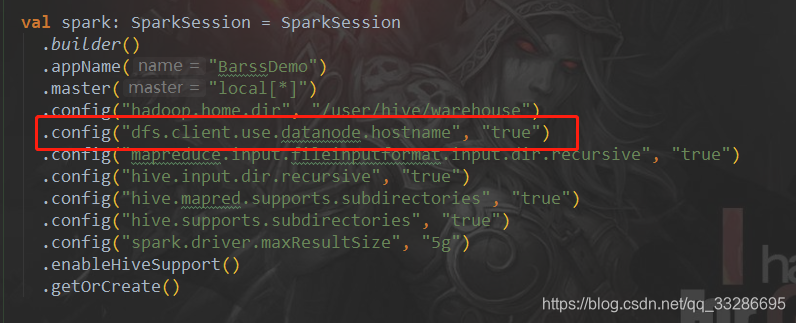
1、开放1004端口
2、添加datanode.hostname识别
问题二:org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
问题解决:
删除本地hadoo安装目录下的hadoop.dll文件

















 1939
1939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









