







概述
我们知道,在并发情况下,HashMap会出现问题,在扩容的时候,有可能会形成死循环.我们知道,HashTable这个集合是线程安全的,但是它是使用synchronized来保证线程安全的.在线程竞争激烈的情况下,HashTable效率是很低的,因为它锁表锁的是整张Hash表.而在多线程情况下,所有访问HashTable的线程都必须竞争同一把锁.这就造成了线程的阻塞或者轮询.
ConcurrentHashMap使用了锁分段技术,首先将数据分成一段一顿的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一段数据的时候,其他段的数据也能被其他线程访问到.另外ConcurrentHashMap可以做到读取数据不加锁,并且内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量小,不用对整个ConcurrentHashMap枷锁.
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成.Segment是一种可重用锁ReentrantLock,HashEntry用于存储键值对数据.一个ConcurrentHashMap中包含一个Segement数组,Segement结构和HashMap类似,是一种数组和链表结构.一个Segment里包含一个HashEntry数组,每一个HashEntry是一个链表结构,每当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁.
ConcurrentHashMap的内部结构
ConcurrentHashMap的结构我们可以看下面这张图来理解:
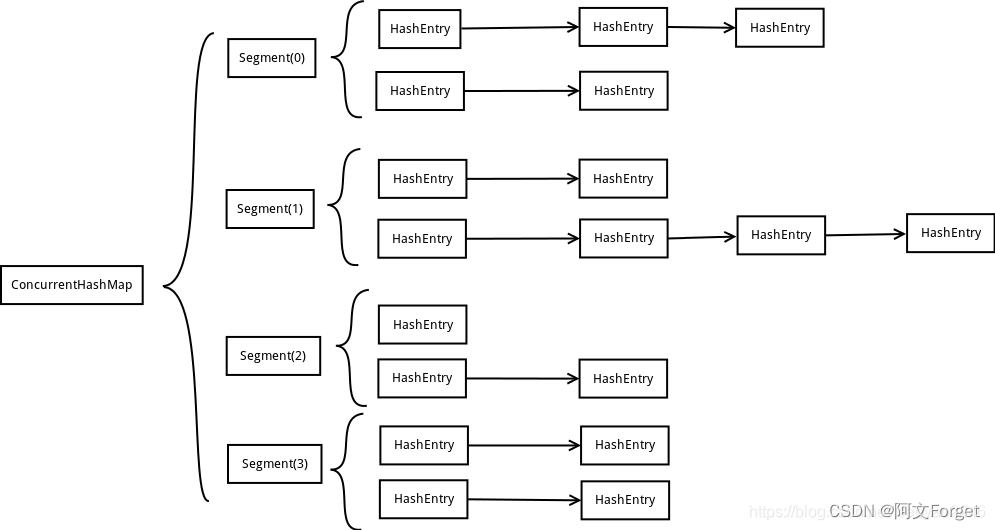
ConcurrentHashMap定位一个元素需要两次Hash操作,第一次Hash定位到Segement,第二次Hash定位到元素所在的链表的头部.这种结构下,Hash过程比普通的HashMap要久,但是写操作的时候,只对元素所在的Segement加锁即可,不会影响其他的Segement.在理想情况下,ConcurrentHashMap最高可以同时支持Segement数量大小的写操作.正因为这样,ConcurrentHashMap的并发能力得以提高.
Segment
static final class Segment<K,V> extends ReentrantLock implements Serializable {
//真正存放数据的HashEntry数组
transient volatile HashEntry<K,V>[] table;
//segemnt中元素的数量
transient int count;
//对table大小造成影响的操作的数量
transient int modCount;
//阈值,segement中的元素超过这个值会进行扩容
transient int threshold;
//负载因子
final float loadFactor;
}
count用来统计该段数据的个数,每次修改操作做了结构上的改变,如增加/删除节点,都要写count值,每次读操作开始都要读取count值.threshold用来表示需要进行rehash的界限值.
HashEnry
Segment中的元素是以HashEntry的形式存放在链表数组中的.Entry结构如下:
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
可以看到它是一个链表结构.
ConcurrentHashMap的初始化
下面是ConcurrentHashMap的源码,在这里都添加了注释.
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
//默认初始化容量
static final int DEFAULT_INITIAL_CAPACITY = 16;
//默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//默认支持的的线程并发数
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//最小的segment段数
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
//容许的最大segment段数
static final int MAX_SEGMENTS = 1 << 16; // slightly conservative
//段,每个段都是一个特殊的Hash表
final Segment<K,V>[] segments;
//构造一个容量为16 负载因子为0.75,段数为16的concurrentHashMap
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
//构造一个指定初始容量,默认负载因子和段数的concurrentHashMap
public ConcurrentHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
//构造一个指定初始容量和指定负载因子,默认段数的concurrentHashMap
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
//
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
//如果负载因子小于0,初始容量小于0 段数小于0 抛异常
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//如果segment段数大于最大阈值,那么就让其等于最大值
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
//ssize = ssize << 1;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
//如果初始容量大于最大容许容量,那么让其等于最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
//根据指定的map集合构建一个concurrentHashMap
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY),
DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
putAll(m);
}
我们主要来分析ConcurrentHashMap三个参数的构造方法:
ConcurrentHashMap的初始化一共有三个参数:
- initialCapacity 表示初始的容量
- loadFactor 表示负载因子
- concurrencyLevel 代表ConcurrentHashMap内部的Segement数量
concurrencyLevel在指定以后就不会改变了,后续如果map的元素数量增加导致map需要扩容,那么ConcurrentHashMap也不会增加Segment的数量,只会增加segment中链表数组的大小,这样做的好处是扩容过程不用对整个map做rehash,只需要对segment里面的元素做一次rehash就可以了.
在初始化方法中有两个参数比较重要:segmentShift和segmentMask,假设构造函数确定了Segment的数量是2的n次方,那么segmentShift就等于32减去n,而segmentMask就等于2的n次方减一。
ConcurrentHashMap的put操作
public V put(K key, V value) {
Segment<K,V> s;
//value不能为空
if (value == null)
throw new NullPointerException();
//第一次hash
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
//执行segement的put方法
return s.put(key, hash, value, false);
}
首先是通过key定位到要保存的具体的segment位置,然后执行segment的put方法:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//尝试获取锁,如果获取失败说明有其他线程竞争,则调用scanAndLockForPut自旋获取锁.
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
//确定链表头的位置
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
//循环链表
for (HashEntry<K,V> e = first;;) {
if (e != null) {
//如果链表不是空的,且找到了相同的key,则覆盖value,返回旧的value值
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
//如果链表为空,则创建一个HashEntry并加入到segment中,同时会判断是否需要扩容
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
//如果数量超过阈值则需要扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}
1、在put方法中,首先要加锁,如果获取锁失败就会通过自旋的方式阻塞保证能拿到锁.通过key的hash值来确定具体的链表头.
2、遍历该链表,如果不为空则判断传入的key和当前遍历的key是否相等,相等则覆盖value
3、如果链表为空则需要新建一个HashEntry并加入到Segment中,同时会先判断是否需要扩容.
4、最后会释放锁
ConcurrentHashMap的get操作
相比于put,get方法比较简单:
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
将要查找的key通过Hash定位到具体的segment,再通过一次Hash定位到具体的元素上,然后遍历链表元素,如果找到相同的key就返回对应的value.
总结
ConcurrentHashMap采用锁分段技术(1.7),内部为Segment数组来进行细分,而每个Segment又通过HashEntry数组来进行封装,当进行写操作的时候,只需要对这个key对应的segment进行加锁操作,这样就不会对其他的Segment造成影响.在默认情况下,每个ConcurrentHashMap包含了16个Segment,每个Segment包含16个HashEntry,对一个Segment进行加锁的时候,其他15个还能正常使用,因此性能比较高.














 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









